Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Microsoft Fabric menawarkan tiga jalur berbeda untuk Vendor Perangkat Lunak Independen (ISV) untuk diintegrasikan dengan mulus dengan Fabric. Bagi ISV yang memulai perjalanan ini, kami ingin menggali berbagai sumber daya yang tersedia di bawah masing-masing jalur tersebut.
Interoperabilitas dengan Fabric OneLake
Fokus utama dengan model Interop adalah mengaktifkan ISV untuk mengintegrasikan solusi mereka dengan OneLake Foundation. Untuk Interop dengan Microsoft Fabric, kami menyediakan integrasi menggunakan banyak konektor di Data Factory dan di Real-Time Intelligence. Kami juga menyediakan REST API untuk OneLake, memperpendek jalur di OneLake, berbagi data antarpenyewa Fabric, dan pencerminan basis data.

Bagian berikut menjelaskan beberapa cara Anda dapat memulai model ini.
API OneLake
- OneLake mendukung API dan SDK Gen2 Azure Data Lake Storage (ADLS) yang ada untuk interaksi langsung, memungkinkan pengembang membaca, menulis, dan mengelola data mereka di OneLake. Pelajari selengkapnya tentang API REST ADLS Gen2 dan cara menyambungkan ke OneLake.
- Karena tidak semua fungsionalitas dalam ADLS Gen2 dapat dipetakan langsung ke OneLake, OneLake juga memberlakukan struktur folder tertentu untuk mendukung ruang kerja dan item Fabric. Untuk daftar lengkap perilaku berbeda antara OneLake dan ADLS Gen2 saat memanggil API ini, lihat Paritas ONELake API.
- Jika Anda menggunakan Databricks dan ingin terhubung ke Microsoft Fabric, Databricks berfungsi dengan API ADLS Gen2. Integrasikan OneLake dengan Azure Databricks.
- Untuk memanfaatkan sepenuhnya apa yang dapat dilakukan format penyimpanan Delta Lake untuk Anda, tinjau dan pahami format, pengoptimalan tabel, dan V-Order. Pengoptimalan tabel Delta Lake dan V-Order.
- Setelah data berada di OneLake, jelajahi secara lokal menggunakan OneLake File Explorer. Penjelajah file OneLake dengan mulus mengintegrasikan OneLake dengan Windows File Explorer. Aplikasi ini secara otomatis menyinkronkan semua item OneLake yang dapat Anda akses di Windows File Explorer. Anda juga dapat menggunakan alat lain yang kompatibel dengan ADLS Gen2 seperti Azure Storage Explorer.

API Intelijen Waktu Nyata
Fabric Real-Time Intelligence adalah solusi komprehensif yang dirancang untuk mendukung seluruh siklus hidup data real-time—mulai dari penyerapan dan pemrosesan aliran hingga analitik, visualisasi, dan tindakan. Dibangun untuk menangani data streaming throughput tinggi, ia menawarkan kemampuan yang kuat untuk penyerapan data, transformasi, kueri, dan penyimpanan, memungkinkan organisasi membuat keputusan yang tepat waktu dan berbasis data.
- Eventstreams memungkinkan Anda membawa peristiwa real-time dari berbagai sumber dan merutekannya ke berbagai tujuan, seperti Lakehouses, database KQL di Eventhouse, dan Fabric Activator. Pelajari selengkapnya tentang Eventstreams dan Eventstreams API.
- Anda dapat menyerap data streaming ke Eventstreams melalui beberapa protokol termasuk. Kafka, Event Hubs, AMQP, dan daftar konektor yang berkembang tercantum di sini.
- Setelah memproses peristiwa yang diserap menggunakan pengalaman tanpa kode atau menggunakan operator SQL (Pratinjau), hasilnya dapat dirutekan ke beberapa tujuan Fabric atau ke titik akhir kustom. Pelajari selengkapnya tentang tujuan Eventstreams di sini.
- Eventhouses dirancang untuk data streaming, kompatibel dengan hub Real-Time, dan ideal untuk acara-acara yang berbasis pada waktu. Data secara otomatis diindeks dan dipartisi berdasarkan waktu penyerapan, memberi Anda kemampuan kueri analitik yang sangat cepat dan kompleks pada data granularitas tinggi yang dapat diakses di OneLake untuk digunakan di seluruh rangkaian pengalaman Fabric. Eventhouse mendukung API eventhouse dan SDK yang ada untuk interaksi langsung, memungkinkan pengembang membaca, menulis, dan mengelola data mereka di Eventhouses. Pelajari selengkapnya tentang REST API.
- Jika Anda menggunakan Databricks atau Jupyter Notebooks, Anda dapat menggunakan Pustaka Klien Kusto Python untuk bekerja dengan database KQL di Fabric. Pelajari lebih lanjut tentang Kusto Python SDK.
- Anda dapat menggunakan konektor Microsoft Logic Apps, Azure Data Factory, atau Microsoft Power Automate yang ada untuk berinteraksi dengan Eventhouses atau KQL Database Anda.
- Pintasan database dalam Real-Time Intelligence adalah referensi yang disematkan dalam eventhouse ke database sumber. Database sumber dapat berupa Database KQL dalam Kecerdasan Real Time atau database Azure Data Explorer. Pintasan dapat digunakan untuk berbagi data di tempat dalam penyewa yang sama atau di seluruh penyewa. Pelajari selengkapnya tentang mengelola pintasan database menggunakan API.

Data Factory di Fabric
- Alur Data membanggakan sekumpulan konektor yang luas, memungkinkan ISV untuk dengan mudah terhubung ke segudang penyimpanan data. Baik Anda berinteraksi dengan database tradisional atau solusi berbasis cloud modern, konektor kami memastikan proses integrasi yang lancar. Gambaran umum konektor.
- Dengan konektor Dataflow Gen2 yang didukung, ISV dapat memanfaatkan kekuatan Fabric Data Factory untuk mengelola alur kerja data yang kompleks. Fitur ini sangat bermanfaat bagi ISV yang ingin menyederhanakan tugas pemrosesan dan transformasi data. Konektor Dataflow Gen2 di Microsoft Fabric.
- Untuk daftar lengkap kemampuan yang didukung oleh Data Factory di Fabric, lihat Data Factory ini di Fabric Blog.

Pintasan Multicloud
Pintasan di Microsoft OneLake memungkinkan Anda menyatukan data di seluruh domain, cloud, dan akun dengan membuat satu data lake virtual untuk seluruh perusahaan Anda. Semua pengalaman Fabric dan mesin analitik dapat langsung menunjuk ke sumber data Anda yang ada seperti OneLake di penyewa yang berbeda, Azure Data Lake Storage (ADLS) Gen2, akun penyimpanan Amazon S3, Google Cloud Storage (GCS), sumber data yang Kompatibel S3, dan Dataverse melalui namespace terpadu. OneLake menyajikan ISV dengan solusi akses data transformatif, menjembatani integrasi dengan lancar di berbagai domain dan platform cloud.
- Pelajari selengkapnya tentang pintasan OneLake
- Pelajari lebih lanjut tentang satu salinan logis OneLake
- Pelajari selengkapnya tentang pintasan database KQL

Berbagi data
Data Sharing memungkinkan pengguna Fabric untuk berbagi data di berbagai penyewa Fabric tanpa menduplikasinya. Fitur ini meningkatkan kolaborasi dengan memungkinkan data dibagikan "di tempat" dari lokasi penyimpanan OneLake. Data dibagikan sebagai baca-saja, dapat diakses melalui berbagai mesin komputasi Fabric, termasuk model SQL, Spark, KQL, dan semantik. Untuk menggunakan fitur ini, admin Fabric harus mengaktifkannya di tenant yang berbagi dan tenant yang menerima. Proses ini mencakup pemilihan data dalam hub data OneLake atau ruang kerja, mengonfigurasi pengaturan berbagi, dan mengirim undangan ke penerima yang dimaksudkan.

Pencerminan Database
Mirroring in Fabric memberikan pengalaman yang mudah untuk menghindari ETL (Extract Transform Load) yang kompleks dan mengintegrasikan data yang ada ke OneLake dengan sisa data Anda di Microsoft Fabric. Anda dapat terus mereplikasi data yang ada langsung ke OneLake Fabric. Dalam Fabric, Anda dapat membuka skenario Kecerdasan Bisnis, Kecerdasan Buatan, Rekayasa Data, Ilmu Data, dan berbagi data yang kuat.
- Pelajari selengkapnya tentang pencerminan dan database yang didukung.

Pencerminan terbuka memungkinkan aplikasi apa pun menulis data perubahan langsung ke database cermin di Fabric. Pencerminan terbuka dirancang agar dapat diperluas, dapat disesuaikan, dan terbuka. Ini adalah fitur canggih yang memperluas penggandaan dalam Fabric berdasarkan format tabel terbuka Delta Lake. Setelah data mendarat di OneLake in Fabric, pencerminan terbuka menyederhanakan penanganan perubahan data yang kompleks, memastikan bahwa semua data yang dicerminkan terus diperbarui dan siap untuk analisis.
- Pelajari lebih lanjut tentang pencerminan terbuka dan kapan menggunakannya.
Kembangkan di Platform Fabric

Dengan menggunakan model Develop on Fabric, ISV dapat membangun produk dan layanan mereka di atas Fabric atau menyematkan fungsionalitas Fabric dengan mulus ke dalam aplikasi yang ada. Ini adalah transisi dari integrasi dasar ke menerapkan kemampuan yang ditawarkan Fabric secara aktif. Area permukaan integrasi utama adalah melalui REST API untuk berbagai pengalaman Fabric. Tabel berikut menunjukkan subset REST API yang dikelompokkan menurut pengalaman Fabric. Untuk daftar lengkapnya, lihat dokumentasi Fabric REST API.
| Pengalaman Kain | Antarmuka Pemrograman Aplikasi (API) |
|---|---|
| Gudang Data |
-
Gudang - Gudang Cermin |
| Rekayasa Data |
-
Lakehouse - Spark - Definisi Pekerjaan Spark - Tabel - Pekerjaan |
| Tetap "Data Factory" sebagai istilah khusus dan tambahkan catatan bahwa ini adalah layanan atau produk yang berhubungan dengan pengolahan data. |
-
DataPipeline |
| Kecerdasan Waktu Nyata |
-
Eventhouse - KQL Database - Set Kueri KQL - Eventstream |
| Ilmu data |
-
Laptop - Eksperimen ML - ML Model |
| OneLake |
-
Pintasan - API ADLS Gen2 |
| Power BI |
-
Laporan - Dashboard - Model Semantik |
Membangun beban kerja pada Fabric

Model beban kerja Fabric dirancang untuk memberdayakan Vendor Perangkat Lunak Independen (ISV) dalam menciptakan pengalaman kustom pada platform Fabric. Ini menyediakan ISV dengan alat dan kemampuan yang diperlukan untuk menyelaraskan penawaran mereka dengan ekosistem Fabric, mengoptimalkan kombinasi proposisi nilai unik mereka dengan kemampuan Fabric yang luas.
Kit Pengembangan Beban Kerja Microsoft Fabric menawarkan toolkit komprehensif bagi pengembang untuk mengintegrasikan aplikasi ke dalam hub Microsoft Fabric. Integrasi ini memungkinkan penambahan kemampuan baru langsung dalam ruang kerja Fabric, meningkatkan perjalanan analitik bagi pengguna. Ini memberi pengembang dan ISV dengan jalan baru untuk menjangkau pelanggan, memberikan pengalaman yang akrab dan baru, dan memanfaatkan aplikasi data yang ada. Admin Fabric memiliki kemampuan untuk mengelola siapa yang dapat menambahkan beban kerja dalam organisasi.
Pusat Beban Kerja
Workload Hub di Microsoft Fabric berfungsi sebagai antarmuka terpusat di mana pengguna dapat menjelajahi, mengelola, dan mengakses semua beban kerja yang tersedia. Setiap beban kerja di Fabric dikaitkan dengan jenis item tertentu yang dapat dibuat dalam ruang kerja Fabric. Dengan menavigasi melalui Workload Hub, pengguna dapat dengan mudah menemukan dan berinteraksi dengan berbagai beban kerja, meningkatkan kemampuan analitik dan operasional mereka.
Diagram 
Pengguna dapat memanfaatkan beban kerja mitra yang tercantum di bawah tab Lebih Banyak Beban Kerja dan menggunakannya dalam proyek analitik mereka. Administrator Fabric memiliki hak untuk mengelola ketersediaan beban kerja, sehingga dapat diakses di seluruh penyewa atau dalam kapasitas tertentu. Ekstensibilitas ini memastikan bahwa Fabric tetap menjadi platform yang fleksibel dan dapat diskalakan, memungkinkan organisasi untuk menyesuaikan lingkungan beban kerja mereka untuk memenuhi persyaratan data dan bisnis yang berkembang. Dengan mengintegrasikan dengan lancar dengan kerangka kerja keamanan dan tata kelola Fabric, Workload Hub menyederhanakan penyebaran dan manajemen beban kerja.
Diagram 
Saat ini, Workload Hub menawarkan lima beban kerja dalam Pratinjau Umum, memungkinkan organisasi untuk meningkatkan dan memperluas kemampuan Fabric. Setiap beban kerja dilengkapi dengan pengalaman uji coba bagi pengguna untuk memulai dengan cepat. Beban kerja yang tersedia ini meliputi:
2TEST: Beban kerja jaminan kualitas komprehensif yang mengotomatiskan pengujian dan pemeriksaan kualitas data.

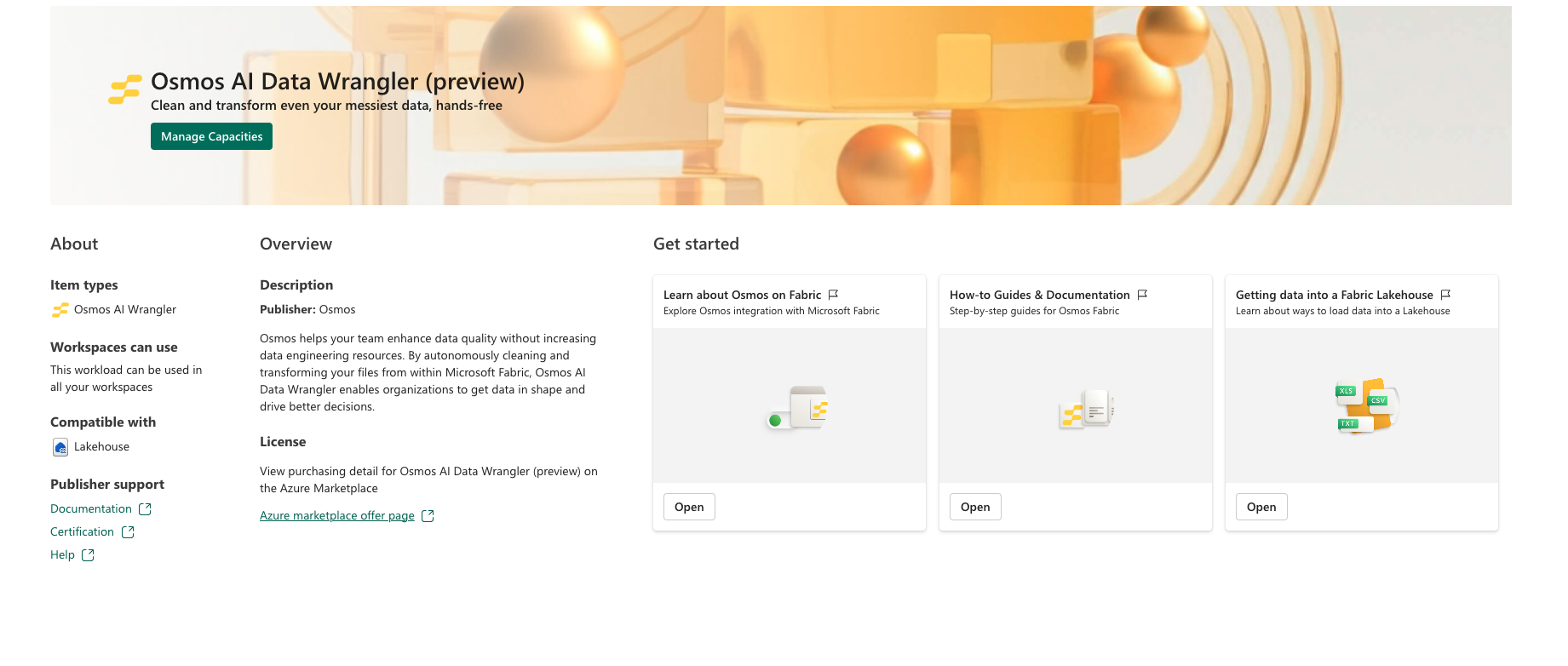
Osmos AI Data Wrangler: Mengotomatiskan persiapan data dengan pengolah data berbasis AI, memudahkan transformasi data.
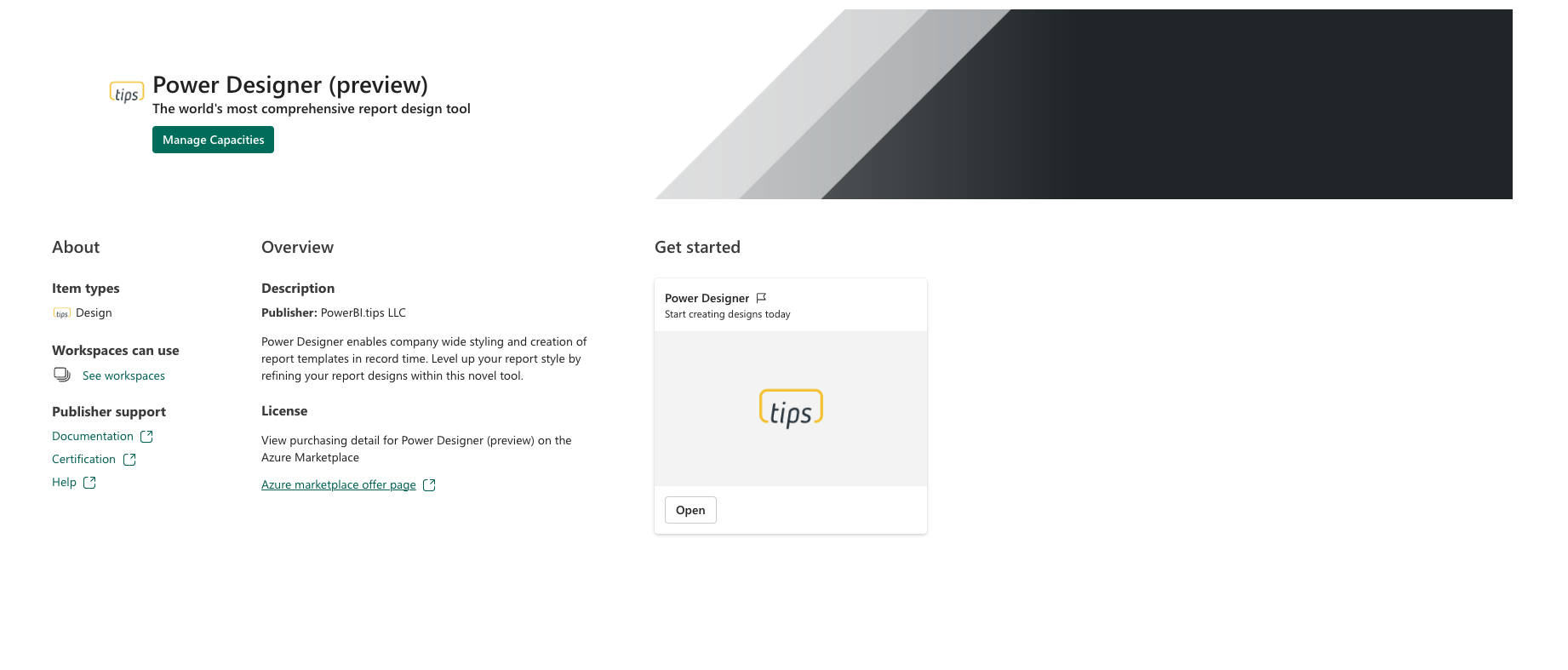
Power Designer: Alat untuk menciptakan gaya perusahaan secara menyeluruh dan membuat templat laporan, meningkatkan desain laporan Power BI.
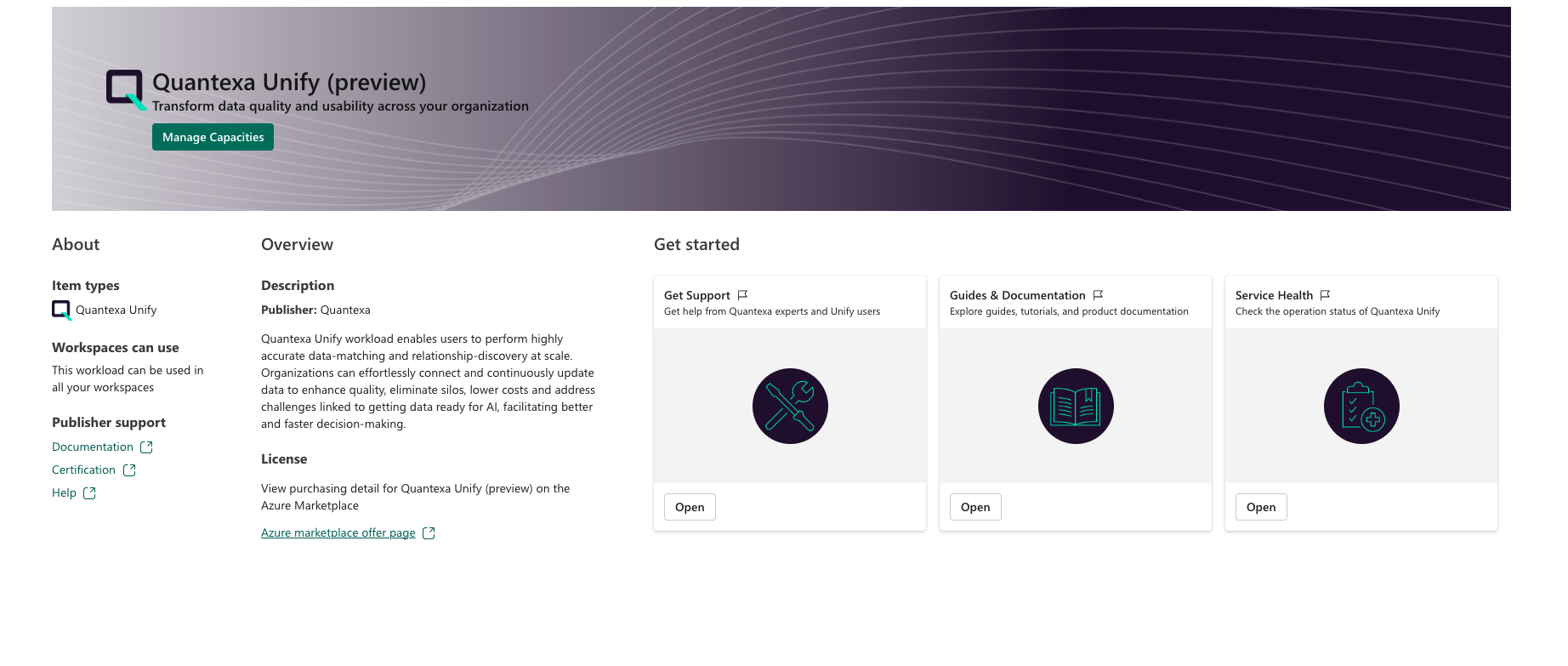
Quantexa Unify: Meningkatkan sumber data Microsoft OneLake dengan menyediakan tampilan 360 derajat dengan kemampuan resolusi data tingkat lanjut.
Teradata AI Unlimited: Menggabungkan mesin analitik Teradata dengan kemampuan manajemen data Microsoft Fabric melalui fungsi dalam database Teradata.





Ketika lebih banyak beban kerja tersedia, Workload Hub akan terus berfungsi sebagai ruang dinamis untuk menemukan kemampuan baru, memastikan bahwa pengguna memiliki alat yang mereka butuhkan untuk menskalakan dan mengoptimalkan solusi berbasis data mereka.