AI dengan aliran data
Artikel ini memperlihatkan bagaimana Anda dapat menggunakan kecerdasan buatan (AI) dengan aliran data. Artikel ini menjelaskan:
- Cognitive Services
- Pembelajaran mesin otomatis
- Integrasi Azure Machine Learning
Penting
Pembuatan model Power BI Automated Pembelajaran Mesin (AutoML) untuk aliran data v1 telah dihentikan, dan tidak lagi tersedia. Pelanggan didorong untuk memigrasikan solusi Anda ke fitur AutoML di Microsoft Fabric. Untuk informasi selengkapnya, lihat pengumuman penghentian.
Cognitive Services di Power BI
Dengan Cognitive Services di Power BI, Anda dapat menerapkan algoritma yang berbeda dari Azure Cognitive Services untuk memperkaya data Anda dalam persiapan data layanan mandiri untuk Aliran Data.
Layanan yang didukung saat ini adalah Analisis Sentimen, Ekstraksi Frasa Kunci, Deteksi Bahasa, dan Pemberian Tag Gambar. Transformasi dijalankan pada layanan Power BI dan tidak memerlukan langganan Azure Cognitive Services. Fitur ini memerlukan Power BI Premium.
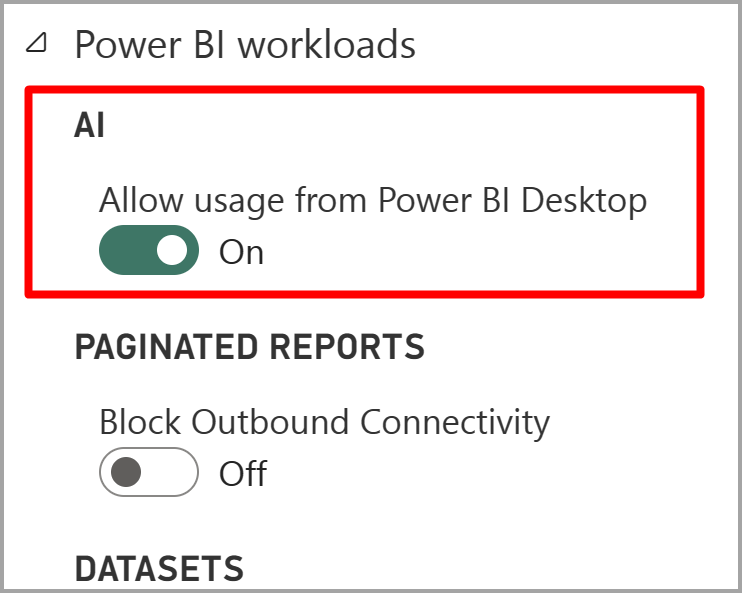
Mengaktifkan fitur AI
Layanan kognitif didukung untuk node kapasitas Premium EM2, A2, atau P1 dan node lainnya dengan lebih banyak sumber daya. Cognitive Services juga tersedia dengan lisensi Premium Per User (PPU). Beban kerja AI yang terpisah pada kapasitas digunakan untuk menjalankan layanan kognitif. Sebelum Anda menggunakan layanan kognitif di Power BI, beban kerja AI perlu diaktifkan di pengaturanKapasitas portal Admin. Anda dapat mengaktifkan beban kerja AI di bagian beban kerja.
Mulai menggunakan Cognitive Services di Power BI
Transformasi Cognitive Services adalah bagian dari Persiapan Data Layanan Mandiri untuk aliran data. Untuk memperkaya data Anda dengan Cognitive Services, mulailah dengan mengedit aliran data.
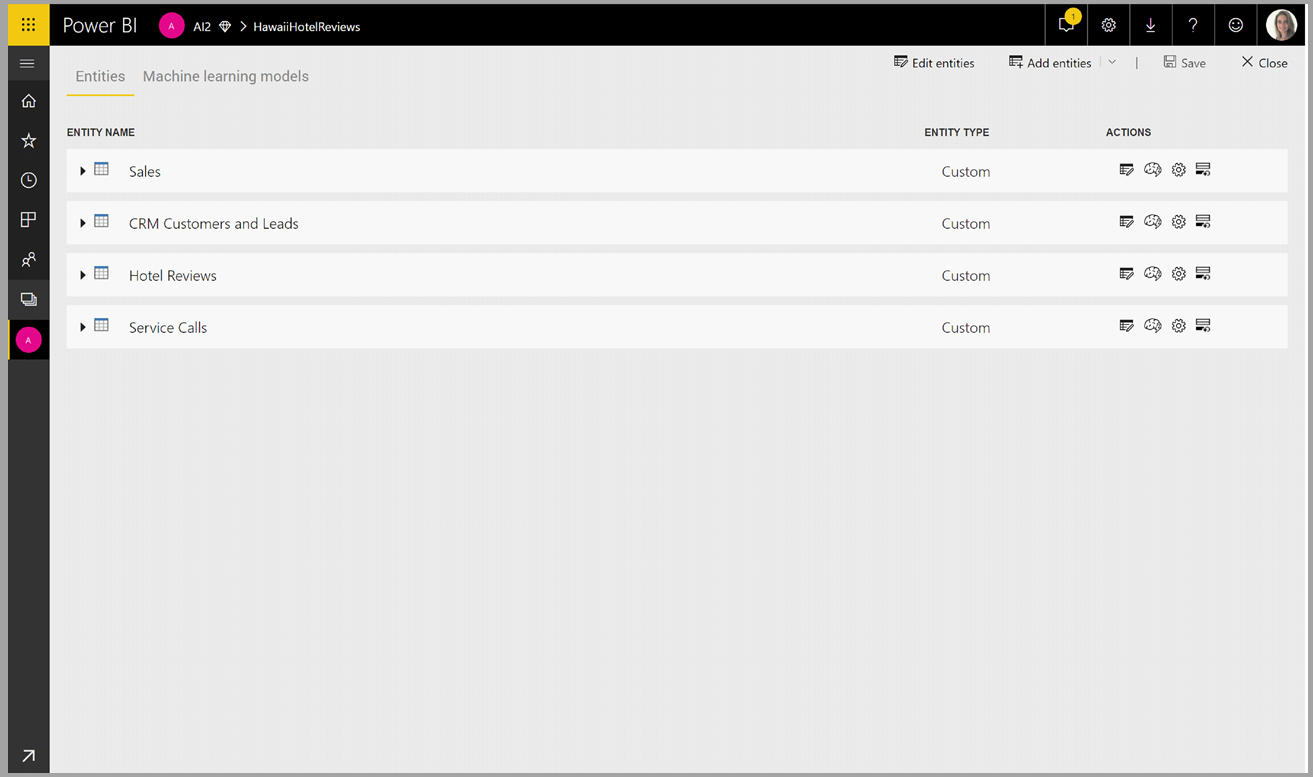
Pilih tombol Wawasan AI di pita atas Editor Power Query.
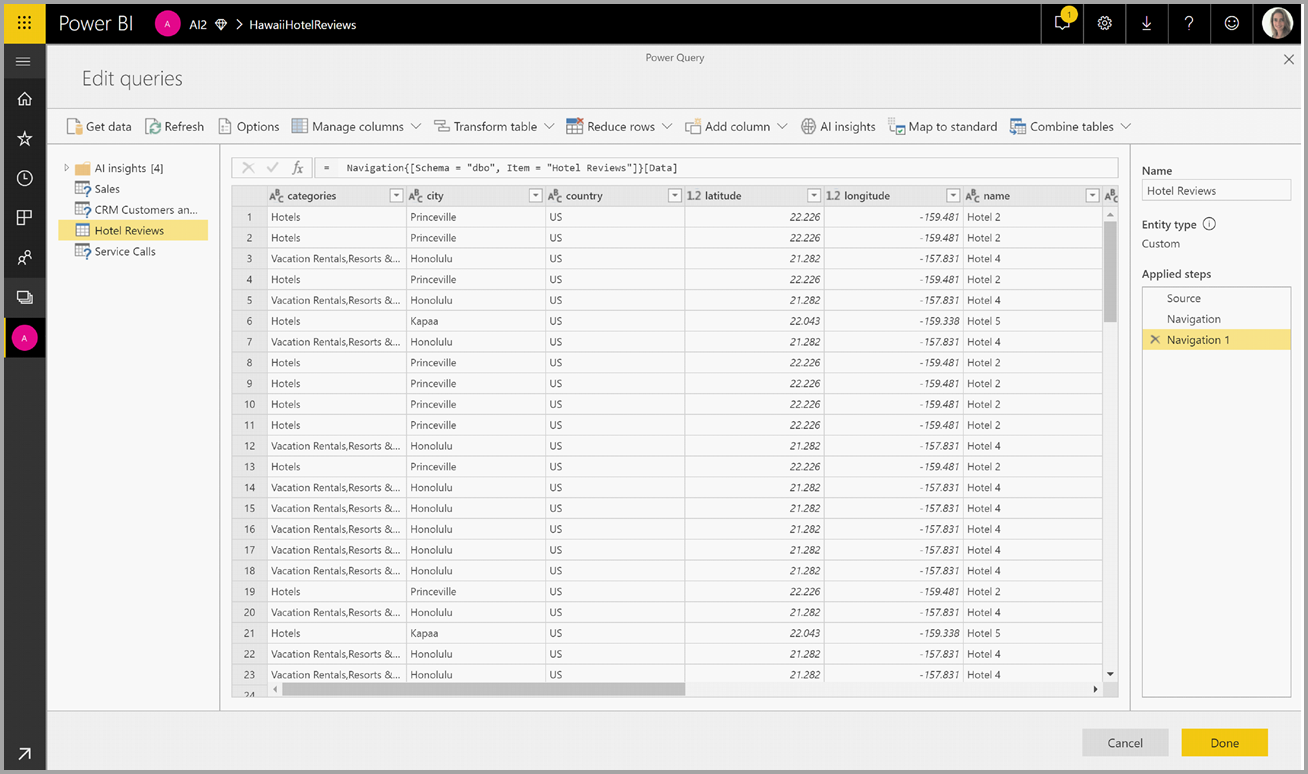
Di jendela pop-up, pilih fungsi yang ingin Anda gunakan dan data yang ingin Anda ubah. Contoh ini menilai sentimen kolom yang berisi teks ulasan.
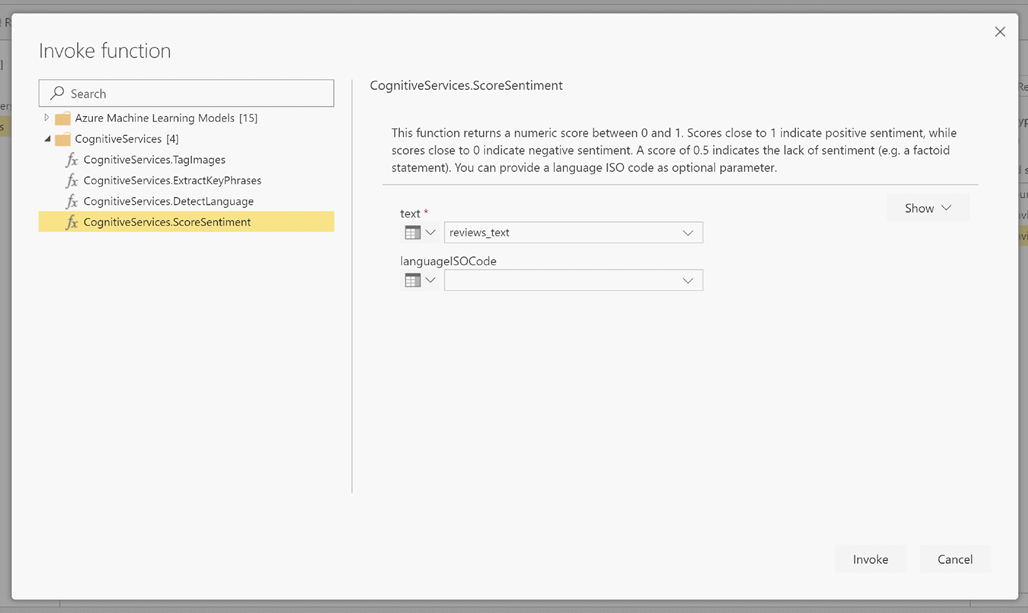
LanguageISOCode adalah input opsional untuk menentukan bahasa teks. Kolom ini mengharapkan kode ISO. Anda dapat menggunakan kolom sebagai input untuk LanguageISOCode, atau Anda bisa menggunakan kolom statis. Dalam contoh ini, bahasa ditentukan sebagai Bahasa Inggris (en) untuk seluruh kolom. Jika Anda membiarkan kolom ini kosong, Power BI secara otomatis mendeteksi bahasa sebelum menerapkan fungsi. Selanjutnya, pilih Jalankan.
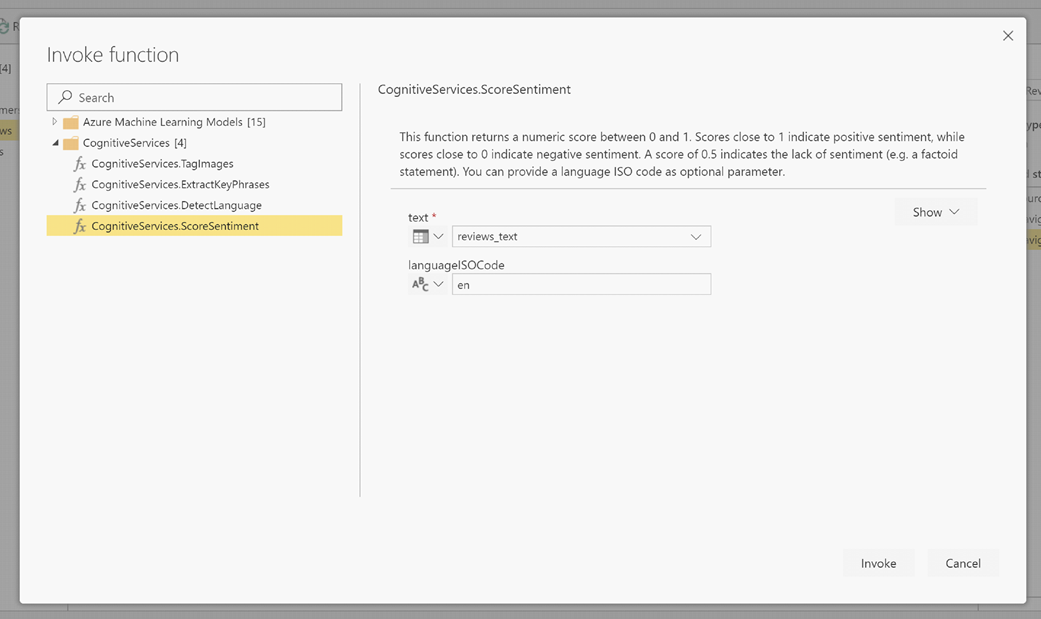
Setelah Anda memanggil fungsi, hasilnya ditambahkan sebagai kolom baru ke tabel. Transformasi juga ditambahkan sebagai langkah yang diterapkan dalam kueri.
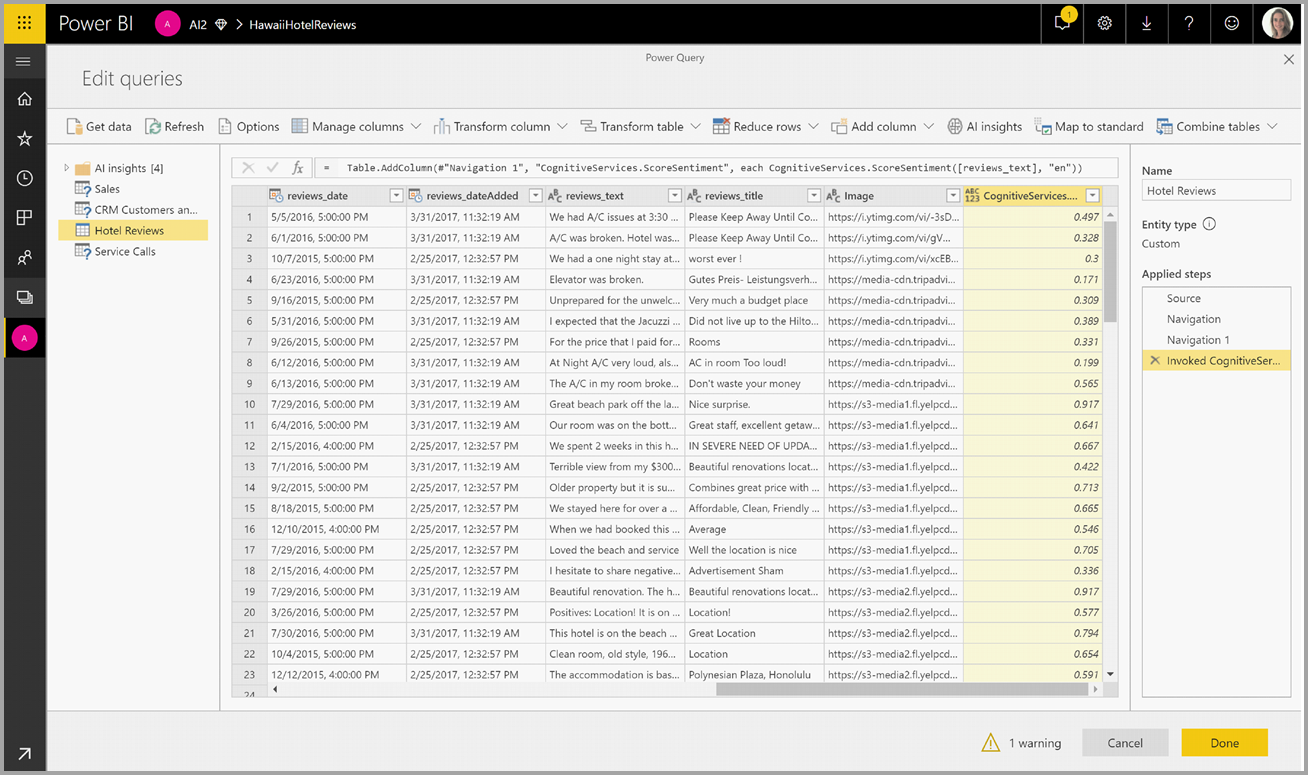
Jika fungsi mengembalikan beberapa kolom output, menjalankan fungsi akan menambahkan kolom baru dengan baris beberapa kolom output.
Gunakan opsi perluas untuk menambahkan satu atau kedua nilai sebagai kolom ke data Anda.
Fungsi yang tersedia
Bagian ini menjelaskan fungsi yang tersedia di Cognitive Services di Power BI.
Deteksi bahasa
Fungsi deteksi bahasa mengevaluasi input teks dan, untuk setiap kolom, mengembalikan nama bahasa dan pengidentifikasi ISO. Fungsi ini berguna untuk kolom data yang mengumpulkan teks arbitrer, saat bahasa tidak diketahui. Fungsi mengharapkan data dalam format teks sebagai input.
Analisis Teks mengenali hingga 120 bahasa. Untuk informasi selengkapnya, lihat Apa itu deteksi bahasa di Azure Cognitive Service for Language.
Ekstraksi Frasa Kunci
Fungsi Ekstraksi Frasa Kunci mengevaluasi teks yang tidak terstruktur dan, untuk setiap kolom teks, mengembalikan daftar frasa kunci. Fungsi ini memerlukan kolom teks sebagai input dan menerima input opsional untuk LanguageISOCode. Untuk informasi selengkapnya, lihat Memulai.
Ekstraksi frasa kunci berfungsi paling baik ketika Anda memberinya potongan teks yang lebih besar untuk dikerjakan, berlawanan dengan analisis sentimen. Analisis sentimen berkinerja lebih baik pada blok teks yang lebih kecil. Untuk mendapatkan hasil terbaik dari kedua operasi, pertimbangkan untuk membuat ulang input yang sesuai.
Sentimen Skor
Fungsi Sentimen Skor mengevaluasi input teks dan mengembalikan skor sentimen untuk setiap dokumen, mulai dari 0 (negatif) hingga 1 (positif). Fungsi ini berguna untuk mendeteksi sentimen positif dan negatif di media sosial, ulasan pelanggan, dan forum diskusi.
Analitik Teks menggunakan algoritme klasifikasi pembelajaran mesin untuk menghasilkan skor sentimen antara 0 dan 1. Skor lebih dekat ke 1 menunjukkan sentimen positif. Skor lebih dekat ke 0 menunjukkan sentimen negatif. Model ini telah dilatih sebelumnya dengan isi teks yang luas dengan asosiasi sentimen. Saat ini, tidak mungkin untuk memberikan data pelatihan Anda sendiri. Model ini menggunakan kombinasi teknik selama analisis teks, termasuk pemrosesan teks, analisis part-of-speech, penempatan kata, dan asosiasi kata. Untuk informasi selengkapnya tentang algoritma, lihat Pembelajaran Mesin dan Analitik Teks.
Analisis sentimen dilakukan pada seluruh kolom input, dibandingkan dengan mengekstrak sentimen untuk tabel tertentu dalam teks. Dalam praktiknya, ada kecenderungan untuk meningkatkan akurasi penilaian ketika dokumen berisi satu atau dua kalimat daripada jumlah teks yang besar. Selama fase penilaian objektivitas, model menentukan apakah kolom input secara keseluruhan objektif atau berisi sentimen. Kolom input yang sebagian besar objektif tidak maju ke frasa deteksi sentimen, menghasilkan skor 0,50, tanpa pemrosesan lebih lanjut. Untuk kolom input yang berlanjut dalam alur, fase berikutnya menghasilkan skor yang lebih besar atau kurang dari 0,50, tergantung pada tingkat sentimen yang terdeteksi di kolom input.
Saat ini, Analisis Sentimen mendukung bahasa Inggris, Jerman, Spanyol, dan Prancis. Bahasa lain sedang dalam pratinjau. Untuk informasi selengkapnya, lihat Apa itu deteksi bahasa di Azure Cognitive Service for Language.
Gambar Tag
Fungsi Gambar Tag mengembalikan tag berdasarkan lebih dari 2.000 objek, makhluk hidup, pemandangan, dan tindakan yang dapat dikenali. Saat tag bersifat ambigu atau bukan pengetahuan umum, output memberikan 'petunjuk' untuk memperjelas arti tag dalam konteks pengaturan yang diketahui. Tag tidak diatur sebagai taksonomi, dan tidak ada hierarki warisan. Kumpulan tag konten membentuk dasar untuk 'deskripsi' gambar yang ditampilkan sebagai bahasa yang dapat dibaca manusia yang diformat dalam kalimat lengkap.
Setelah mengunggah gambar atau menentukan URL gambar, algoritma Computer Vision mengeluarkan tag berdasarkan objek, makhluk hidup, dan tindakan yang diidentifikasi dalam gambar. Pemberian tag tidak terbatas pada subjek utama, seperti orang di latar depan, tetapi juga mencakup pengaturan (dalam ruangan atau luar ruangan), furnitur, peralatan, tanaman, hewan, aksesori, gawai/gadget yang digunakan, dll.
Fungsi ini memerlukan URL gambar atau kolom abase-64 sebagai input. Saat ini, pemberian tag gambar mendukung bahasa Inggris, Spanyol, Jepang, Portugis, dan Mandarin Sederhana. Untuk informasi selengkapnya, lihat Antarmuka ComputerVision.
Pembelajaran mesin otomatis di Power BI
Pembelajaran mesin otomatis (AutoML) untuk aliran data memungkinkan analis bisnis untuk melatih, memvalidasi, dan memanggil model pembelajaran mesin (ML) langsung di Power BI. Ini termasuk pengalaman sederhana untuk membuat model ML baru di mana analis dapat menggunakan aliran data mereka untuk menentukan data input untuk melatih model. Layanan ini secara otomatis mengekstrak fitur yang paling relevan, memilih algoritma yang sesuai, dan menyetel dan memvalidasi model ML. Setelah model dilatih, Power BI secara otomatis menghasilkan laporan performa yang menyertakan hasil validasi. Model kemudian dapat dijalankan pada data baru atau yang diperbarui dalam aliran data.
Pembelajaran mesin otomatis hanya tersedia untuk aliran data yang dihosting pada kapasitas Power BI Premium dan Embedded.
Bekerja dengan AutoML
Pembelajaran mesin dan AI mengalami peningkatan popularitas yang belum pernah terjadi sebelumnya dari industri dan bidang penelitian ilmiah. Bisnis juga mencari cara untuk mengintegrasikan teknologi baru ini ke dalam operasi mereka.
Aliran data menawarkan persiapan data layanan mandiri untuk data besar. AutoML diintegrasikan ke dalam aliran data dan memungkinkan Anda menggunakan upaya persiapan data untuk membangun model pembelajaran mesin, tepat di dalam Power BI.
AutoML di Power BI memungkinkan analis data menggunakan aliran data untuk membangun model pembelajaran mesin dengan pengalaman yang disederhanakan hanya dengan menggunakan keterampilan Power BI. Power BI mengotomatiskan sebagian besar ilmu data di balik pembuatan model ML. Ini memiliki pagar pembatas untuk memastikan bahwa model yang dihasilkan memiliki kualitas yang baik dan memberikan visibilitas ke dalam proses yang digunakan untuk membuat model ML Anda.
AutoML mendukung pembuatan Prediksi Biner, Klasifikasi, dan Model Regresi untuk aliran data. Fitur-fitur ini adalah jenis teknik pembelajaran mesin yang diawasi, yang berarti bahwa mereka belajar dari hasil pengamatan sebelumnya yang diketahui untuk memprediksi hasil pengamatan lain. Model semantik input untuk melatih model AutoML adalah sekumpulan baris yang diberi label dengan hasil yang diketahui.
AutoML di Power BI mengintegrasikan ML otomatis dari Azure Machine Learning untuk membuat model ML Anda. Namun, Anda tidak memerlukan langganan Azure untuk menggunakan AutoML di Power BI. layanan Power BI sepenuhnya mengelola proses pelatihan dan hosting model ML.
Setelah model ML dilatih, AutoML secara otomatis menghasilkan laporan Power BI yang menjelaskan kemungkinan performa model ML Anda. AutoML menekankan kemampuan penjelasan dengan menyoroti influencer utama di antara input Anda yang memengaruhi prediksi yang dikembalikan oleh model Anda. Laporan ini juga menyertakan metrik utama untuk model.
Halaman lain dari laporan yang dihasilkan menunjukkan ringkasan statistik model dan detail pelatihan. Ringkasan statistik menarik bagi pengguna yang ingin melihat langkah-langkah ilmu data standar performa model. Detail pelatihan merangkum semua iterasi yang dijalankan untuk membuat model Anda, dengan parameter pemodelan terkait. Ini juga menjelaskan bagaimana setiap input digunakan untuk membuat model ML.
Anda kemudian dapat menerapkan model ML ke data Anda untuk penilaian. Saat aliran data di-refresh, data Anda diperbarui dengan prediksi dari model ML Anda. Power BI juga menyertakan penjelasan individual untuk setiap prediksi tertentu yang dihasilkan model ML.
Membuat model pembelajaran mesin
Bagian ini menjelaskan cara membuat model AutoML.
Persiapan data untuk membuat model ML
Untuk membuat model pembelajaran mesin di Power BI, Anda harus terlebih dahulu membuat aliran data untuk data yang berisi informasi hasil historis, yang digunakan untuk melatih model ML. Anda juga harus menambahkan kolom terhitung untuk metrik bisnis apa pun yang mungkin prediktor kuat untuk hasil yang coba Anda prediksi. Untuk detail tentang mengonfigurasi aliran data Anda, lihat Mengonfigurasi dan menggunakan aliran data.
AutoML memiliki persyaratan data khusus untuk melatih model pembelajaran mesin. Persyaratan ini dijelaskan di bagian berikut, berdasarkan jenis model masing-masing.
Mengonfigurasi input model ML
Untuk membuat model AutoML, pilih ikon ML di kolom Tindakan pada tabel aliran data, dan pilih Tambahkan model pembelajaran mesin.
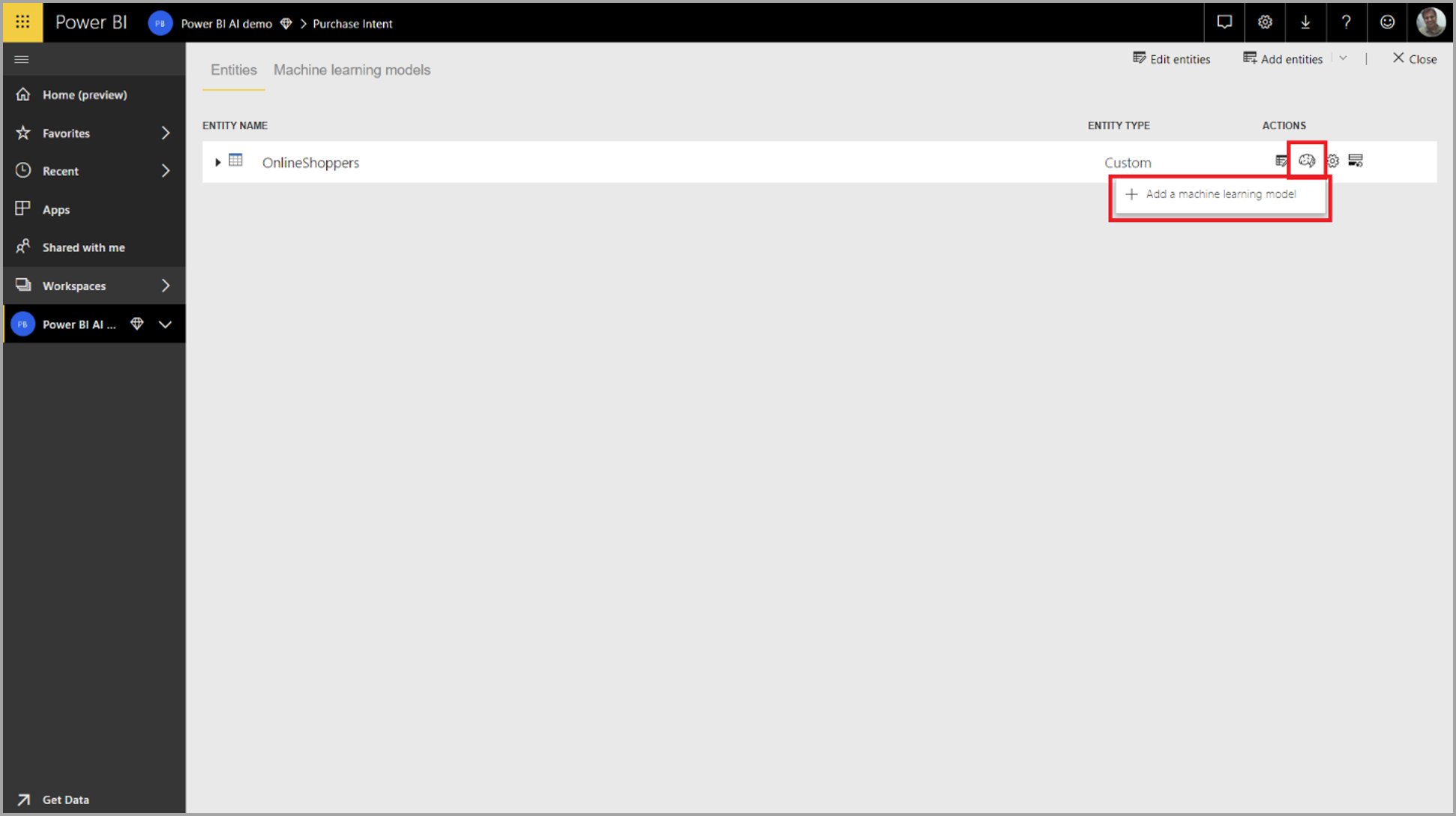
Pengalaman yang disederhanakan diluncurkan, yang terdiri dari wizard yang memandu Anda melalui proses pembuatan model ML. Wizard ini mencakup langkah-langkah sederhana berikut.
1. Pilih tabel dengan data historis, dan pilih kolom hasil yang Anda inginkan prediksinya
Kolom hasil mengidentifikasi atribut label untuk melatih model ML, yang diperlihatkan dalam gambar berikut.
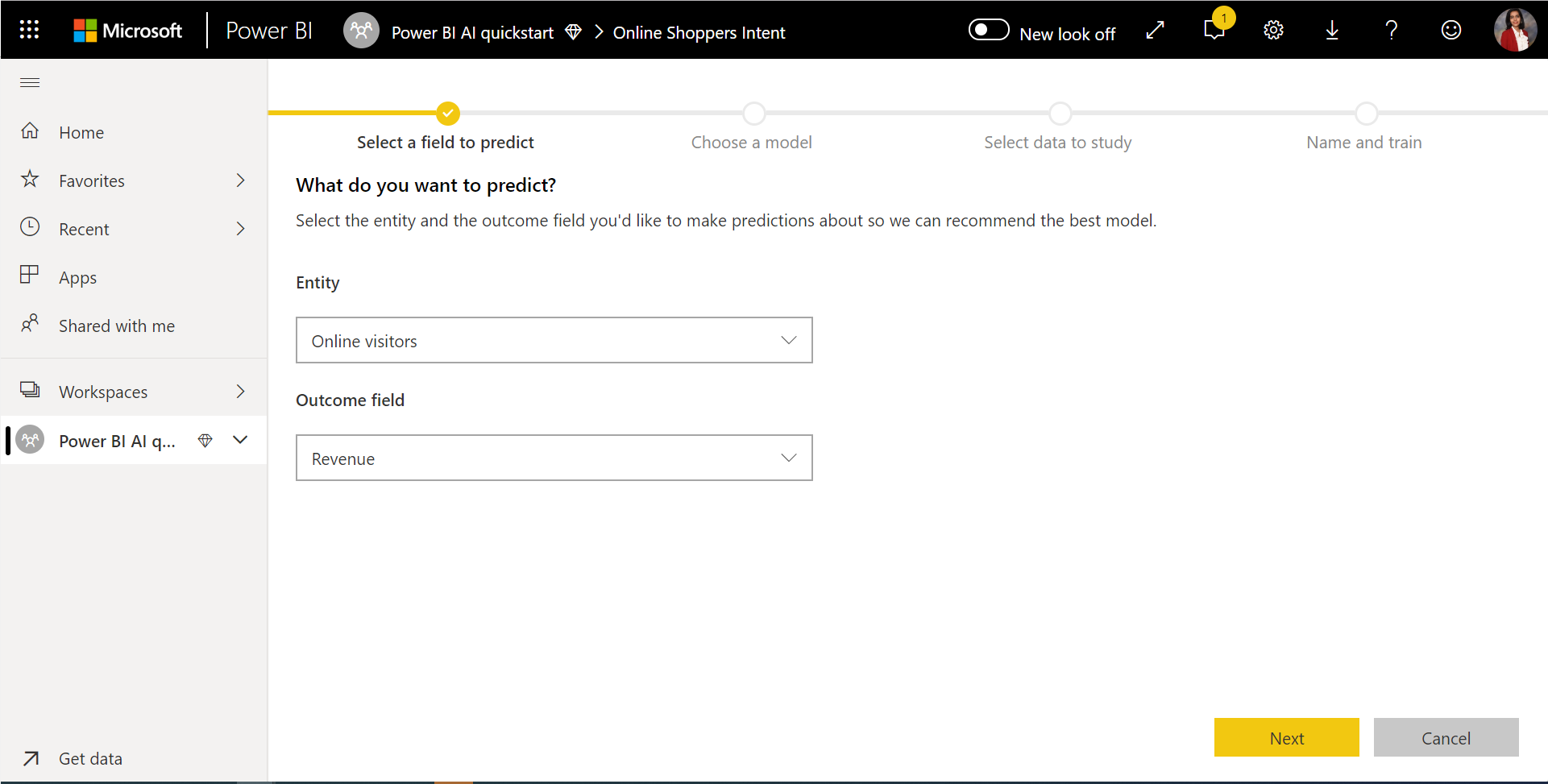
2. Pilih jenis model
Saat Anda menentukan kolom hasil, AutoML menganalisis data label untuk merekomendasikan jenis model ML yang paling mungkin dapat dilatih. Anda dapat memilih jenis model yang berbeda seperti yang ditunjukkan pada gambar berikut dengan mengklik Pilih model.
Catatan
Beberapa jenis model mungkin tidak didukung untuk data yang telah Anda pilih, sehingga akan dinonaktifkan. Dalam contoh sebelumnya, Regresi dinonaktifkan, karena kolom teks dipilih sebagai kolom hasil.
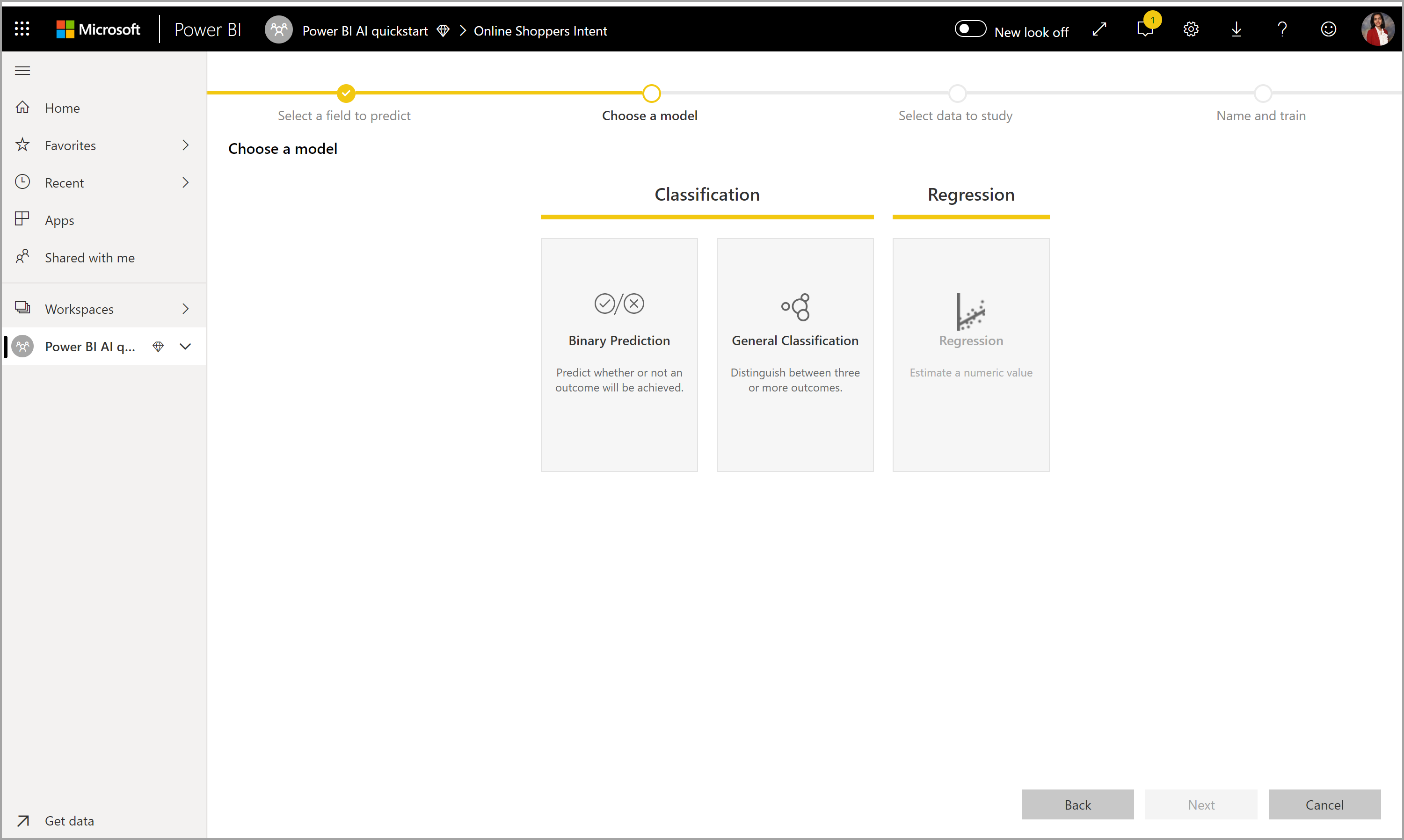
3. Pilih input yang Anda inginkan untuk digunakan model sebagai sinyal prediktif
AutoML menganalisis sampel tabel yang dipilih untuk menyarankan input yang dapat digunakan untuk melatih model ML. Penjelasan disediakan di samping kolom yang tidak dipilih. Jika kolom tertentu memiliki terlalu banyak nilai yang berbeda atau hanya satu nilai, atau korelasi rendah atau tinggi dengan kolom output, tidak disarankan.
Input apa pun yang bergantung pada kolom hasil (atau kolom label) tidak boleh digunakan untuk melatih model ML, karena memengaruhi performanya. Kolom tersebut ditandai memiliki "korelasi yang sangat tinggi dengan kolom output". Memperkenalkan kolom ini ke dalam data pelatihan menyebabkan kebocoran label, di mana model berkinerja baik pada validasi atau data pengujian tetapi tidak dapat mencocokkan performa tersebut saat digunakan dalam produksi untuk penilaian. Kebocoran label bisa menjadi perhatian yang mungkin dalam model AutoML ketika performa model pelatihan terlalu baik untuk menjadi kenyataan.
Rekomendasi fitur ini didasarkan pada sampel data, jadi Anda harus meninjau input yang digunakan. Anda dapat mengubah pilihan agar hanya menyertakan kolom yang ingin Anda pelajari modelnya. Anda juga dapat memilih semua kolom dengan memilih kotak centang di samping nama tabel.
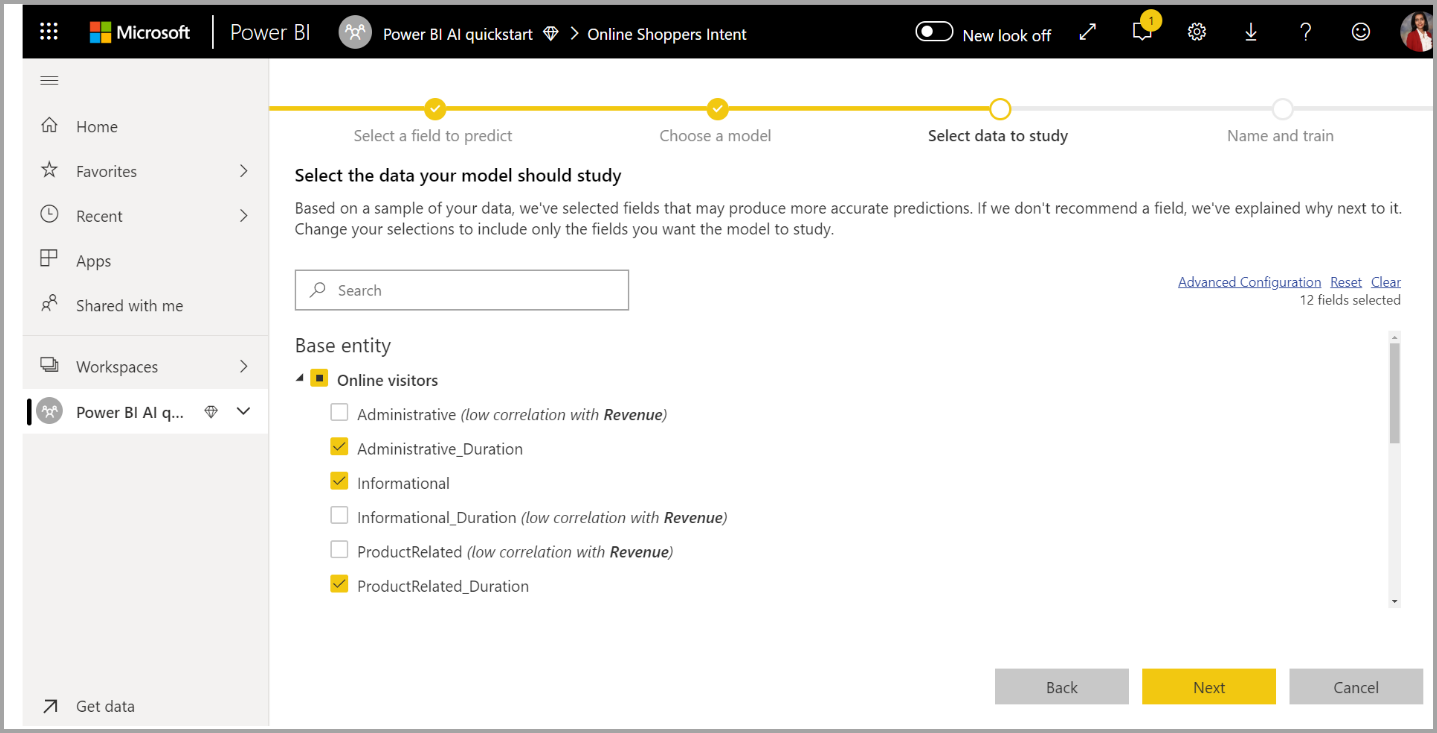
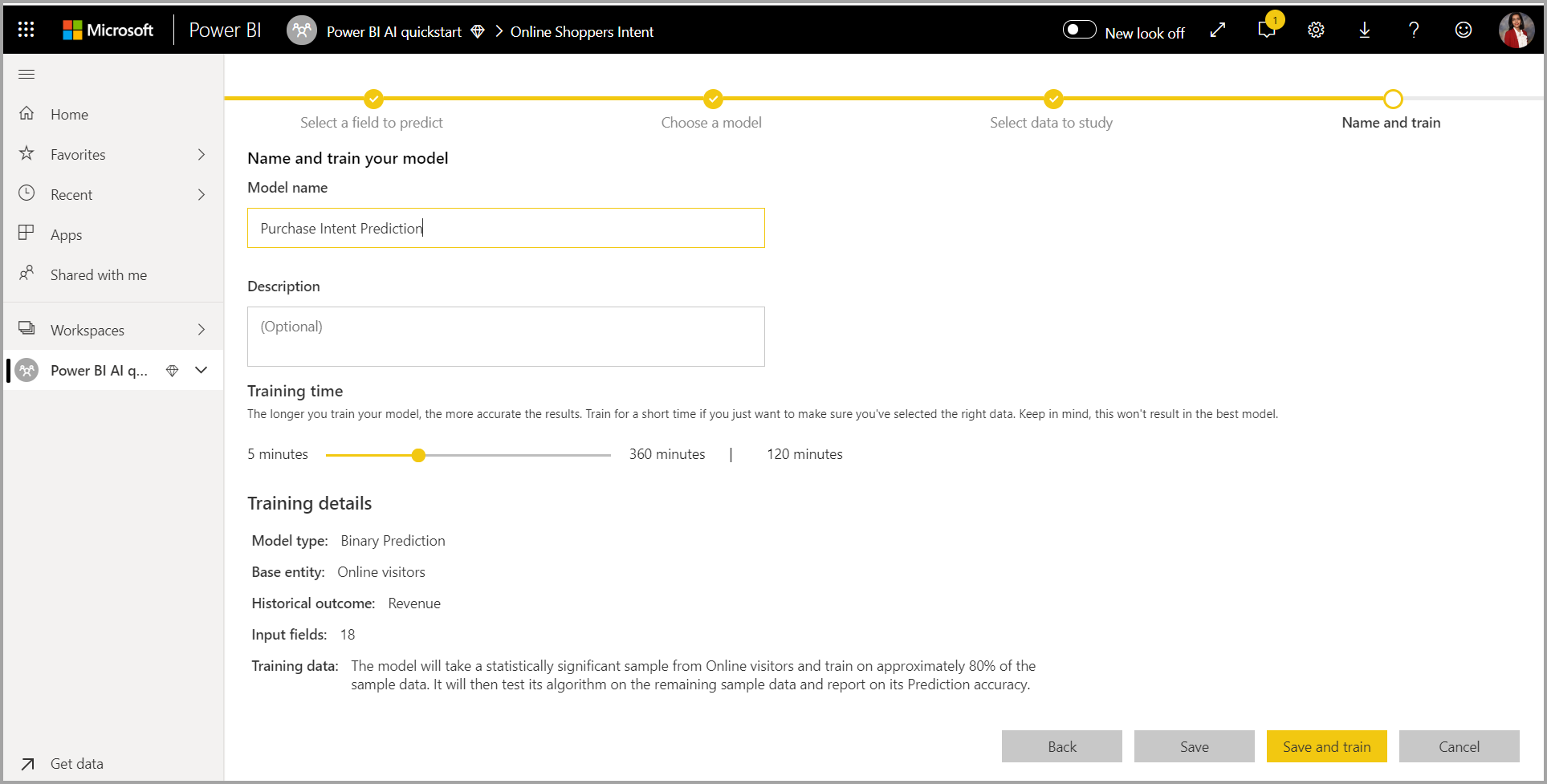
4. Beri nama model Anda dan simpan konfigurasi Anda
Pada langkah terakhir, Anda dapat memberi nama model, memilih Simpan, dan memilih mana yang mulai melatih model ML. Anda dapat memilih untuk mengurangi waktu pelatihan untuk melihat hasil cepat atau meningkatkan jumlah waktu yang dihabiskan dalam pelatihan untuk mendapatkan model terbaik.
Pelatihan model ML
Pelatihan model AutoML adalah bagian dari refresh aliran data. AutoML terlebih dahulu menyiapkan data Anda untuk pelatihan. AutoML membagi data historis yang Anda berikan ke dalam pelatihan dan pengujian model semantik. Model semantik pengujian adalah set holdout yang digunakan untuk memvalidasi performa model setelah pelatihan. Set ini diwujudkan sebagai tabel Pelatihan dan Pengujian dalam aliran data. AutoML menggunakan validasi silang untuk validasi model.
Selanjutnya, setiap kolom input dianalisis dan imputasi diterapkan, yang menggantikan nilai yang hilang dengan nilai pengganti. Beberapa strategi imputasi yang berbeda digunakan oleh AutoML. Untuk atribut input yang diperlakukan sebagai fitur numerik, rata-rata nilai kolom digunakan untuk imputasi. Untuk atribut input yang diperlakukan sebagai fitur kategoris, AutoML menggunakan mode nilai kolom untuk imputasi. Kerangka kerja AutoML menghitung rata-rata dan mode nilai yang digunakan untuk imputasi pada model semantik pelatihan subsampel.
Kemudian, pengambilan sampel dan normalisasi diterapkan ke data Anda sesuai kebutuhan. Untuk model klasifikasi, AutoML menjalankan data input melalui pengambilan sampel bertahap dan menyeimbangkan kelas untuk memastikan jumlah baris sama untuk semua.
AutoML menerapkan beberapa transformasi pada setiap kolom input yang dipilih berdasarkan jenis data dan properti statistiknya. AutoML menggunakan transformasi ini untuk mengekstrak fitur untuk digunakan dalam melatih model ML Anda.
Proses pelatihan untuk model AutoML terdiri dari hingga 50 iterasi dengan algoritma pemodelan yang berbeda dan pengaturan hiperparameter untuk menemukan model dengan performa terbaik. Pelatihan dapat berakhir lebih awal dengan iterasi yang lebih sedikit jika AutoML melihat bahwa tidak ada peningkatan performa yang diamati. AutoML menilai performa masing-masing model ini dengan memvalidasi dengan model semantik pengujian holdout. Selama langkah pelatihan ini, AutoML membuat beberapa alur untuk pelatihan dan validasi iterasi ini. Proses menilai performa model dapat memakan waktu, di mana saja dari beberapa menit, hingga beberapa jam, hingga waktu pelatihan yang dikonfigurasi dalam wizard. Waktu yang dibutuhkan tergantung pada ukuran model semantik Anda dan sumber daya kapasitas yang tersedia.
Dalam beberapa kasus, model akhir yang dihasilkan mungkin menggunakan pembelajaran ansambel, di mana beberapa model digunakan untuk memberikan performa prediktif yang lebih baik.
Kemampuan penjelasan model AutoML
Setelah model dilatih, AutoML menganalisis hubungan antara fitur input dan output model. Ini menilai besarnya perubahan pada output model untuk model semantik pengujian holdout untuk setiap fitur input. Hubungan ini dikenal sebagai kepentingan fitur. Analisis ini terjadi sebagai bagian dari refresh setelah pelatihan selesai. Oleh karena itu refresh Anda mungkin memakan waktu lebih lama dari waktu pelatihan yang dikonfigurasi dalam wizard.
Laporan model AutoML
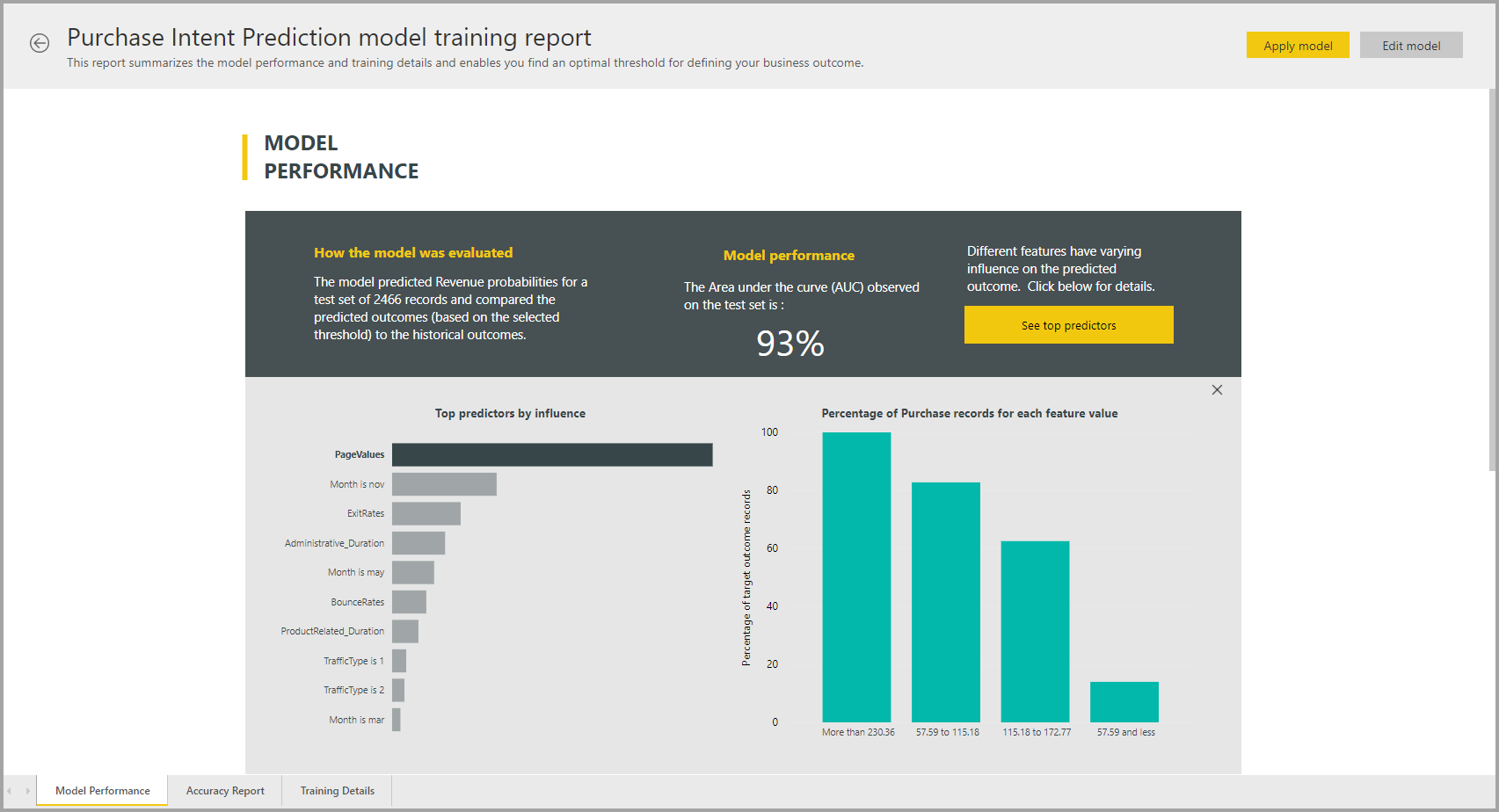
AutoML menghasilkan laporan Power BI yang meringkas performa model selama validasi, bersama dengan kepentingan fitur global. Laporan ini dapat diakses dari tab Model Pembelajaran Mesin setelah refresh aliran data berhasil. Laporan ini merangkum hasil dari menerapkan model ML ke data pengujian holdout dan membandingkan prediksi dengan nilai hasil yang diketahui.
Anda dapat meninjau laporan model untuk memahami performanya. Anda juga dapat memvalidasi bahwa influencer utama model selaras dengan wawasan bisnis tentang hasil yang diketahui.
Bagan dan pengukuran yang digunakan untuk menjelaskan performa model dalam laporan bergantung pada jenis model. Bagan dan pengukuran performa ini dijelaskan di bagian berikut.
Halaman lain dalam laporan mungkin menjelaskan langkah-langkah statistik tentang model dari perspektif ilmu data. Misalnya, laporan Prediksi Biner menyertakan bagan perolehan dan kurva ROC untuk model.
Laporan juga menyertakan halaman Detail Pelatihan yang menyertakan deskripsi tentang bagaimana model dilatih, dan bagan yang menjelaskan performa model atas setiap iterasi yang dijalankan.
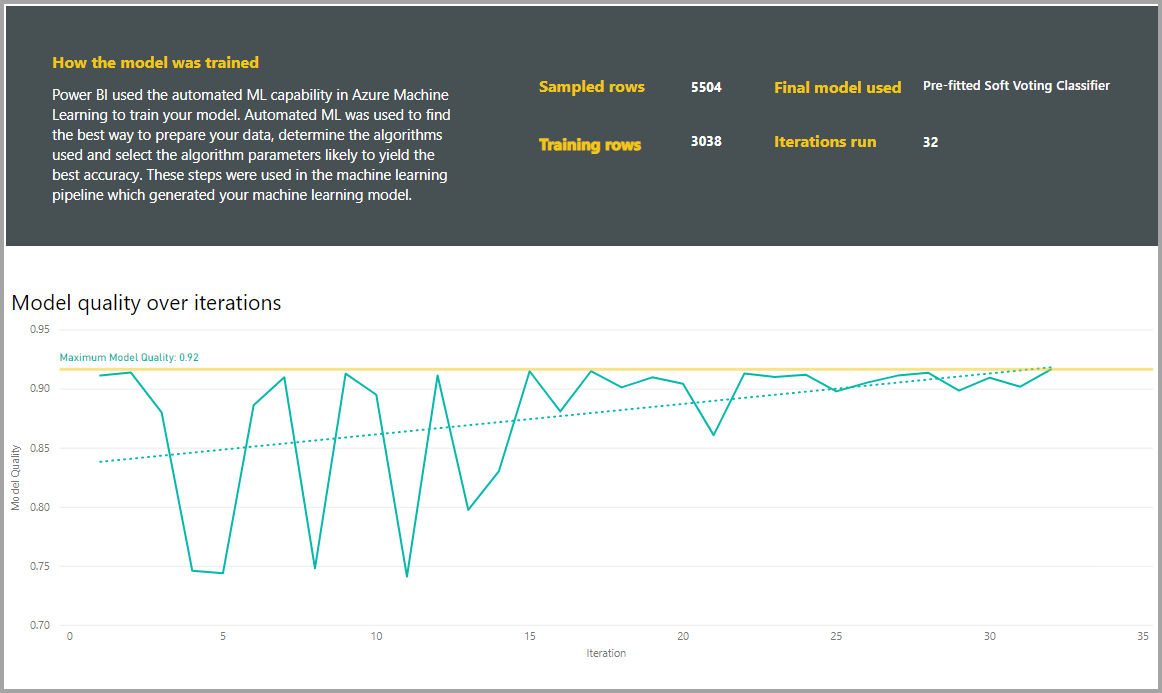
Bagian lain di halaman ini menjelaskan jenis kolom input dan metode imputasi yang terdeteksi yang digunakan untuk mengisi nilai yang hilang. Ini juga mencakup parameter yang digunakan oleh model akhir.
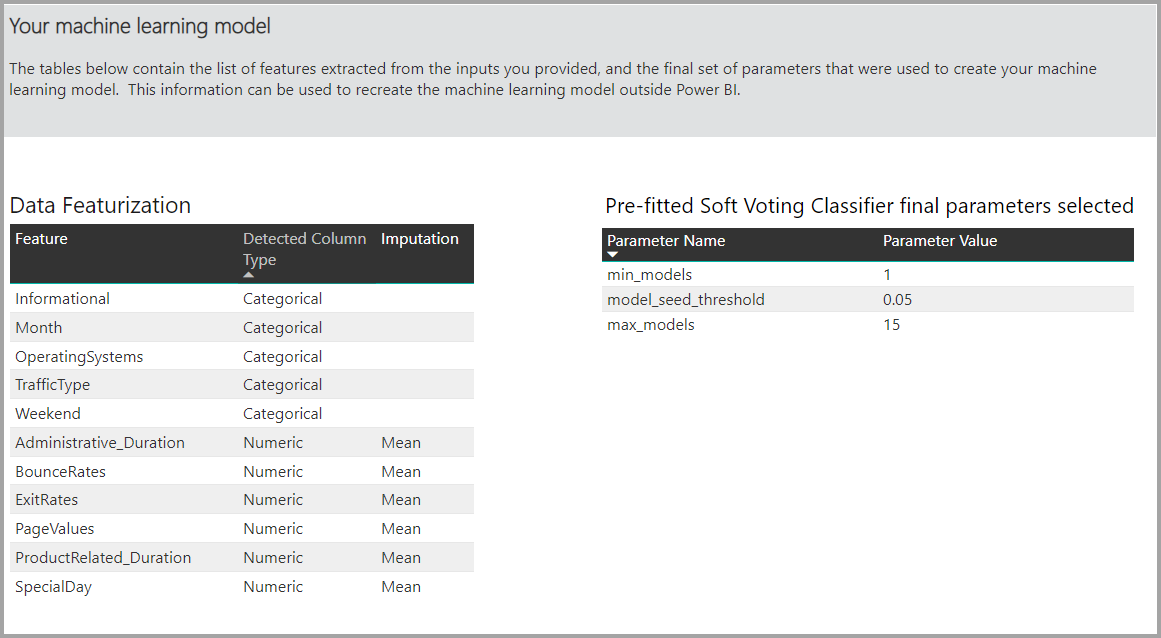
Jika model yang dihasilkan menggunakan pembelajaran ansambel, halaman Detail Pelatihan juga menyertakan bagan yang menunjukkan bobot setiap model konstituen dalam ansambel dan parameternya.

Menerapkan model AutoML
Jika Anda puas dengan performa model ML yang dibuat, Anda dapat menerapkannya ke data baru atau yang diperbarui saat aliran data Anda di-refresh. Dalam laporan model, pilih tombol Terapkan di sudut kanan atas atau tombol Terapkan Model ML di bawah tindakan di tab Model Pembelajaran Mesin.
Untuk menerapkan model ML, Anda harus menentukan nama tabel yang harus diterapkan dan awalan untuk kolom yang akan ditambahkan ke tabel ini untuk output model. Awalan default untuk nama kolom adalah nama model. Fungsi Terapkan mungkin menyertakan lebih banyak parameter khusus untuk jenis model.
Menerapkan model ML membuat dua tabel aliran data baru yang berisi prediksi dan penjelasan individual untuk setiap baris yang dinilainya dalam tabel output. Misalnya, jika Anda menerapkan model PurchaseIntent ke tabel OnlineShoppers, output menghasilkan tabel penjelasan PurchaseIntent dan OnlineShoppers yang diperkaya PurchaseIntent yang diperkaya. Untuk setiap baris dalam tabel yang diperkaya, Penjelasan dipecah menjadi beberapa baris dalam tabel penjelasan yang diperkaya berdasarkan fitur input. An ExplanationIndex membantu memetakan baris dari tabel penjelasan yang diperkaya ke baris dalam tabel yang diperkaya.
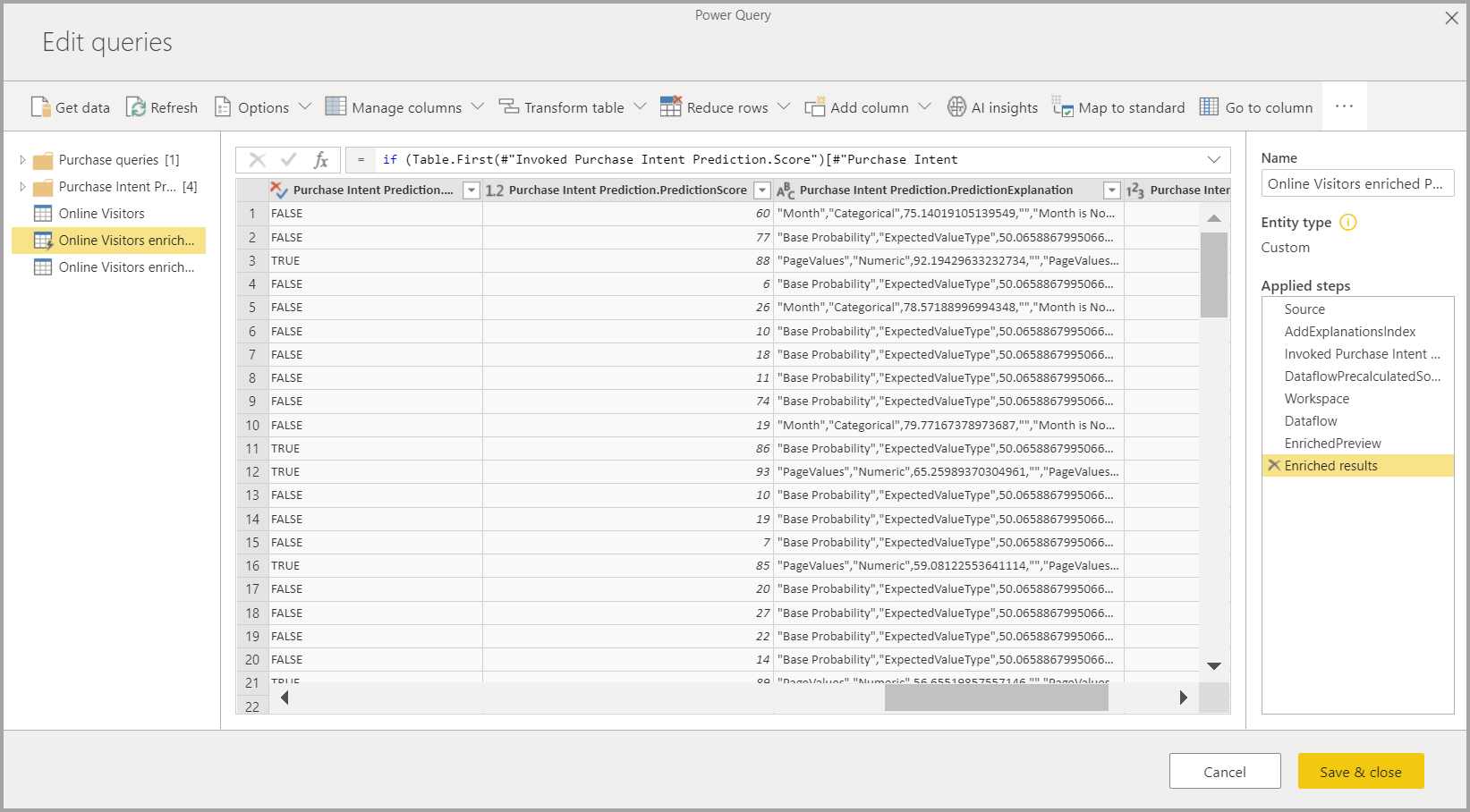
Anda juga dapat menerapkan model Power BI AutoML apa pun ke tabel di aliran data apa pun di ruang kerja yang sama dengan menggunakan Wawasan AI di browser fungsi PQO. Dengan cara ini, Anda dapat menggunakan model yang dibuat oleh orang lain di ruang kerja yang sama tanpa harus menjadi pemilik aliran data yang memiliki model. Power Query menemukan semua model ML Power BI di ruang kerja dan mengeksposnya sebagai fungsi Power Query dinamis. Anda dapat memanggil fungsi tersebut dengan mengaksesnya dari pita di Editor Power Query atau dengan memanggil fungsi M secara langsung. Fungsionalitas ini saat ini hanya didukung untuk aliran data Power BI dan untuk Power Query Online di layanan Power BI. Proses ini berbeda dengan menerapkan model ML dalam aliran data menggunakan wizard AutoML. Tidak ada tabel penjelasan yang dibuat dengan menggunakan metode ini. Kecuali Anda adalah pemilik aliran data, Anda tidak dapat mengakses laporan pelatihan model atau melatih kembali model. Selain itu, jika model sumber diedit dengan menambahkan atau menghapus kolom input atau model atau aliran data sumber dihapus, aliran data dependen ini akan rusak.
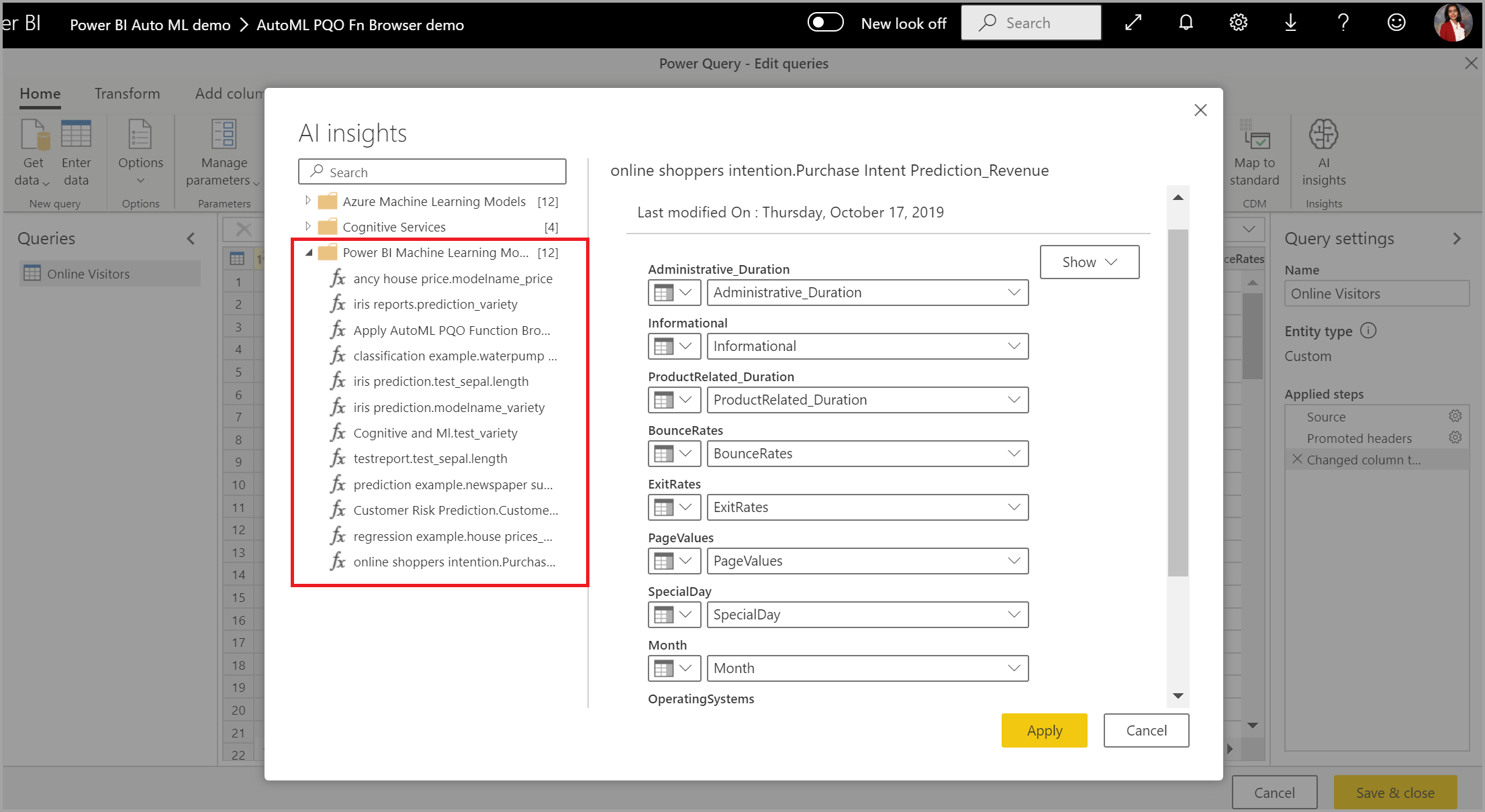
Setelah Anda menerapkan model, AutoML selalu memperbarui prediksi Anda setiap kali aliran data disegarkan.
Untuk menggunakan wawasan dan prediksi dari model ML dalam laporan Power BI, Anda bisa menyambungkan ke tabel output dari Power BI Desktop dengan menggunakan konektor aliran data.
Model Prediksi Biner
Model Prediksi Biner, yang lebih dikenal sebagai model klasifikasi biner, digunakan untuk mengklasifikasikan model semantik ke dalam dua grup. Mereka digunakan untuk memprediksi aktivitas yang dapat memiliki hasil biner. Misalnya, apakah peluang penjualan akan dikonversi, apakah akun akan hilang, apakah faktur akan dibayar tepat waktu, apakah transaksi penipuan, dan sebagainya.
Output model Prediksi Biner adalah skor probabilitas, yang mengidentifikasi kemungkinan hasil target akan dicapai.
Melatih model Prediksi Biner
Prasyarat:
- Diperlukan minimal 20 baris data historis untuk setiap kelas hasil
Proses pembuatan untuk model Prediksi Biner mengikuti langkah yang sama dengan model AutoML lainnya, yang dijelaskan di bagian sebelumnya, Mengonfigurasi input model ML. Satu-satunya perbedaan adalah pada langkah Pilih model tempat Anda dapat memilih nilai hasil target yang paling Anda minati. Anda juga dapat memberikan label ramah untuk hasil yang akan digunakan dalam laporan yang dihasilkan secara otomatis yang meringkas hasil validasi model.
Laporan model Prediksi Biner
Model Prediksi Biner menghasilkan sebagai output probabilitas bahwa baris akan mencapai hasil target. Laporan ini mencakup pemotong untuk ambang probabilitas, yang memengaruhi bagaimana skor lebih besar dan kurang dari ambang batas probabilitas ditafsirkan.
Laporan ini menjelaskan performa model dalam hal Positif Benar, Positif Palsu, Negatif Benar, dan Negatif Palsu. Positif Benar dan Negatif Benar adalah hasil yang diprediksi dengan benar untuk dua kelas dalam data hasil. Positif Palsu adalah baris yang diprediksi memiliki hasil Target tetapi sebenarnya tidak. Sebaliknya, Negatif Palsu adalah baris yang memiliki hasil target tetapi diprediksi bukan.
Langkah-langkah, seperti Presisi dan Pengenalan, menjelaskan efek ambang probabilitas pada hasil yang diprediksi. Anda dapat menggunakan pemotong ambang probabilitas untuk memilih ambang batas yang mencapai penyusupan seimbang antara Presisi dan Pengenalan.

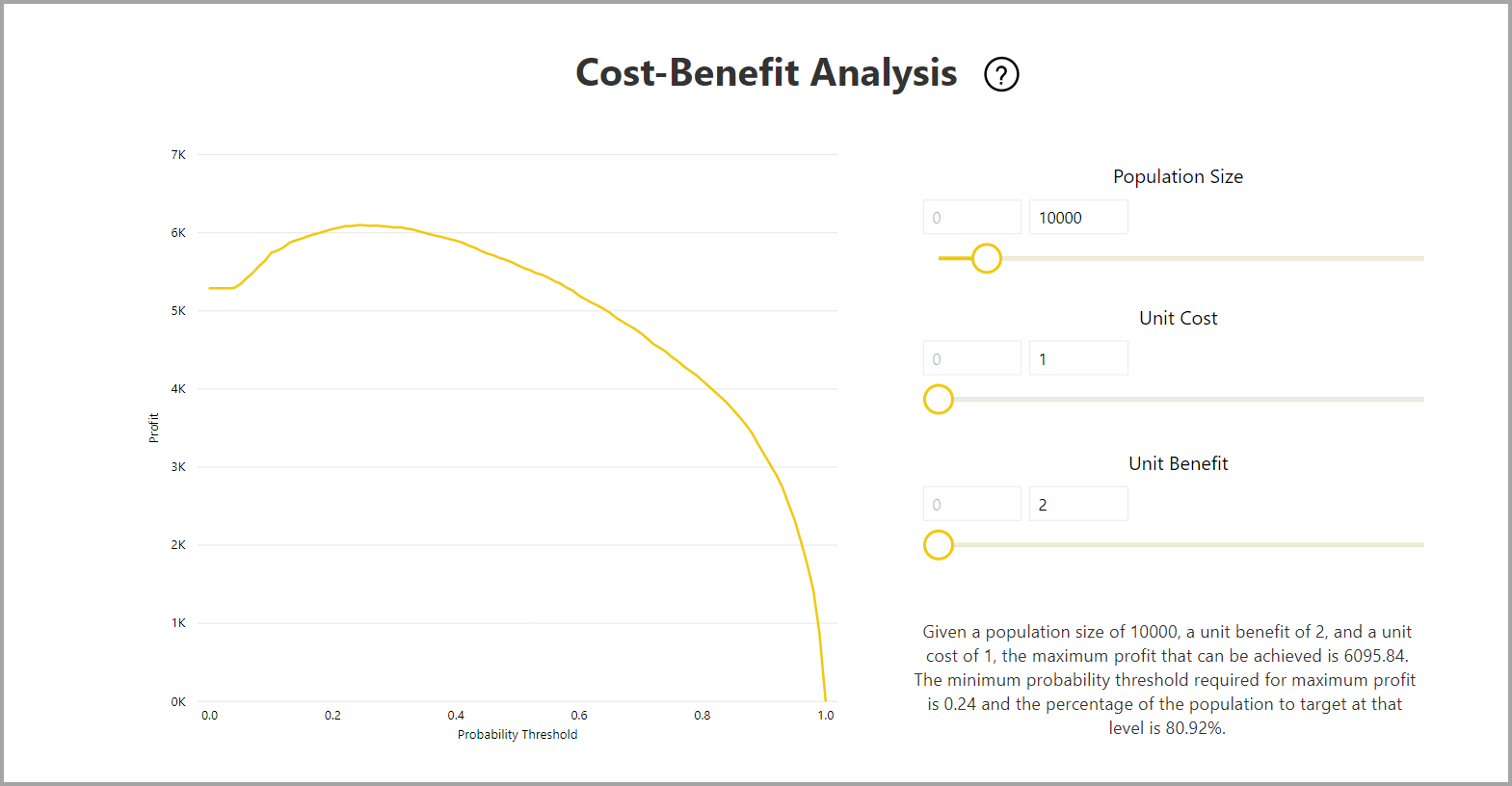
Laporan ini juga mencakup alat analisis Biaya-Manfaat untuk membantu mengidentifikasi subset populasi yang harus ditargetkan untuk menghasilkan laba tertinggi. Mengingat perkiraan biaya unit penargetan dan manfaat unit dari pencapaian hasil target, analisis Biaya-Manfaat mencoba memaksimalkan keuntungan. Anda dapat menggunakan alat ini untuk memilih ambang batas probabilitas Anda berdasarkan titik maksimum dalam grafik untuk memaksimalkan keuntungan. Anda juga dapat menggunakan grafik untuk menghitung keuntungan atau biaya untuk ambang batas probabilitas pilihan Anda.
Halaman Laporan Akurasi laporan model menyertakan bagan Keuntungan Kumulatif dan kurva ROC untuk model. Data ini menyediakan langkah-langkah statistik performa model. Laporan tersebut mencakup deskripsi grafik yang ditampilkan.
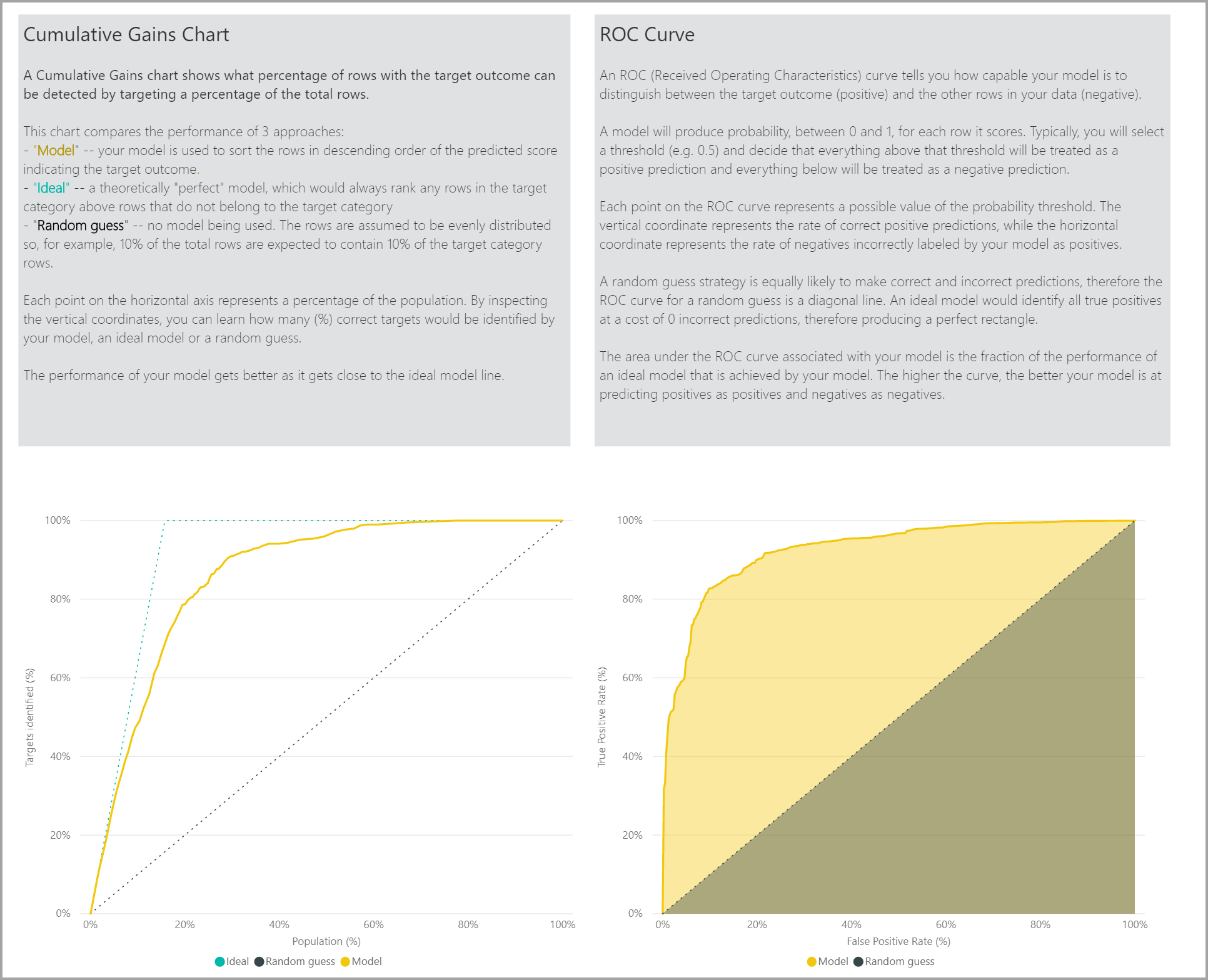
Menerapkan model Prediksi Biner
Untuk menerapkan model Prediksi Biner, Anda harus menentukan tabel dengan data yang ingin Anda terapkan prediksi dari model ML. Parameter lain termasuk awalan nama kolom output dan ambang probabilitas untuk mengklasifikasikan hasil yang diprediksi.
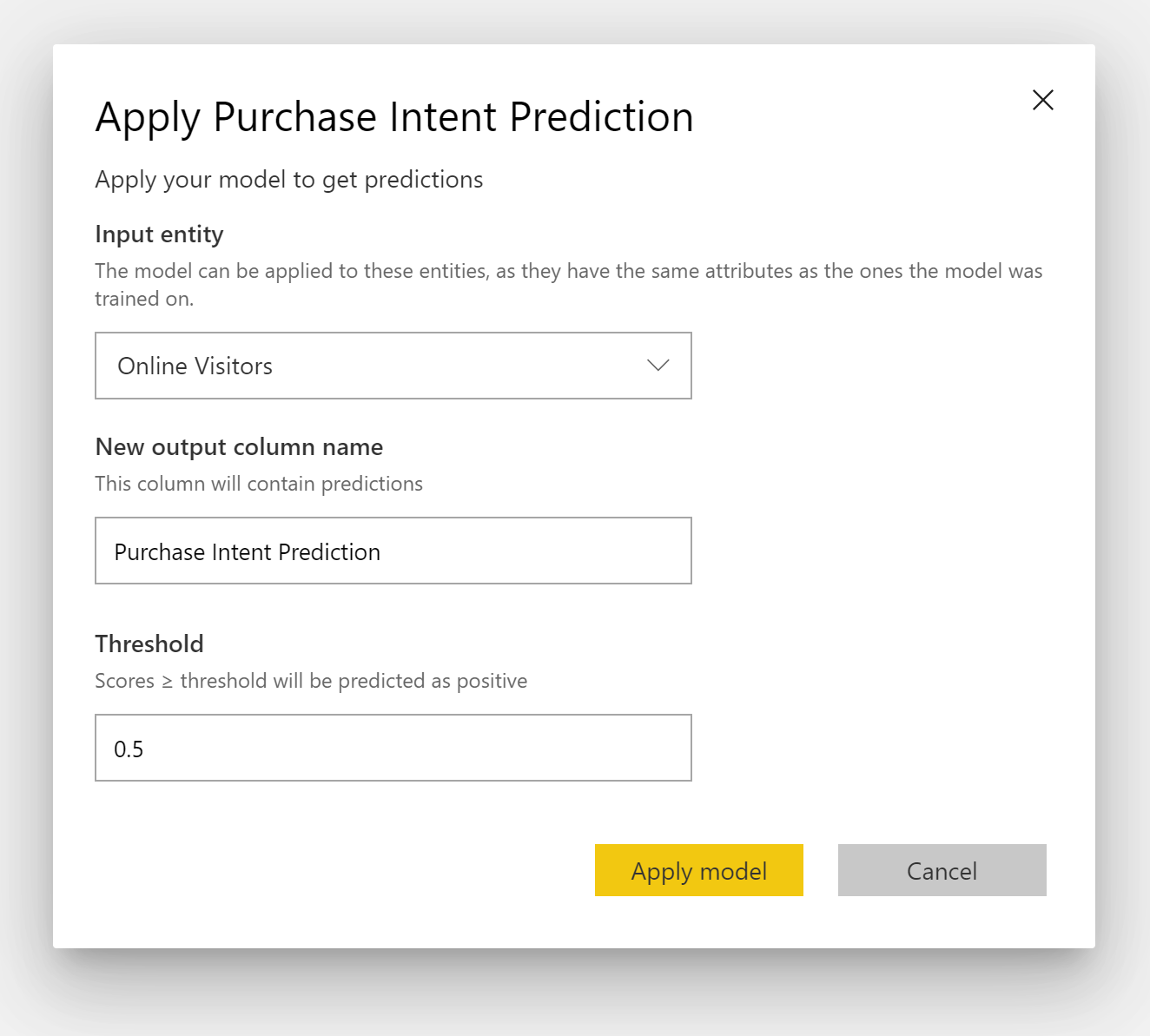
Saat model Prediksi Biner diterapkan, model menambahkan empat kolom output ke tabel output yang diperkaya: Hasil, PredictionScore, PredictionExplanation, dan ExplanationIndex. Nama kolom dalam tabel memiliki awalan yang ditentukan saat model diterapkan.
PredictionScore adalah probabilitas persentase, yang mengidentifikasi kemungkinan bahwa hasil target akan dicapai.
Kolom Hasil berisi label hasil yang diprediksi. Rekaman dengan probabilitas yang melebihi ambang batas diprediksi kemungkinan akan mencapai hasil target dan diberi label Benar. Rekaman yang kurang dari ambang batas diprediksi tidak mungkin mencapai hasil dan diberi label False.
Kolom PredictionExplanation berisi penjelasan dengan pengaruh spesifik yang dimiliki fitur input pada PredictionScore.
Model klasifikasi
Model klasifikasi digunakan untuk mengklasifikasikan model semantik ke dalam beberapa grup atau kelas. Mereka digunakan untuk memprediksi aktivitas yang dapat memiliki salah satu dari beberapa kemungkinan hasil. Misalnya, apakah pelanggan kemungkinan memiliki Nilai Seumur Hidup tinggi, sedang, atau rendah. Mereka juga dapat memprediksi apakah risiko default tinggi, sedang, rendah, dan sebagainya.
Output model Klasifikasi adalah skor probabilitas, yang mengidentifikasi kemungkinan baris akan mencapai kriteria untuk kelas tertentu.
Melatih model Klasifikasi
Tabel input yang berisi data pelatihan Anda untuk model klasifikasi harus memiliki string atau kolom bilangan bulat sebagai kolom hasil, yang mengidentifikasi hasil yang diketahui sebelumnya.
Prasyarat:
- Diperlukan minimal 20 baris data historis untuk setiap kelas hasil
Proses pembuatan untuk model klasifikasi mengikuti langkah yang sama dengan model AutoML lainnya, yang dijelaskan di bagian sebelumnya, Mengonfigurasi input model ML.
Laporan model klasifikasi
Power BI membuat laporan model klasifikasi dengan menerapkan model ML ke data pengujian holdout. Kemudian membandingkan kelas yang diprediksi untuk baris dengan kelas yang diketahui aktual.
Laporan model menyertakan bagan yang mencakup perincian baris yang diklasifikasikan dengan benar dan salah untuk setiap kelas yang diketahui.
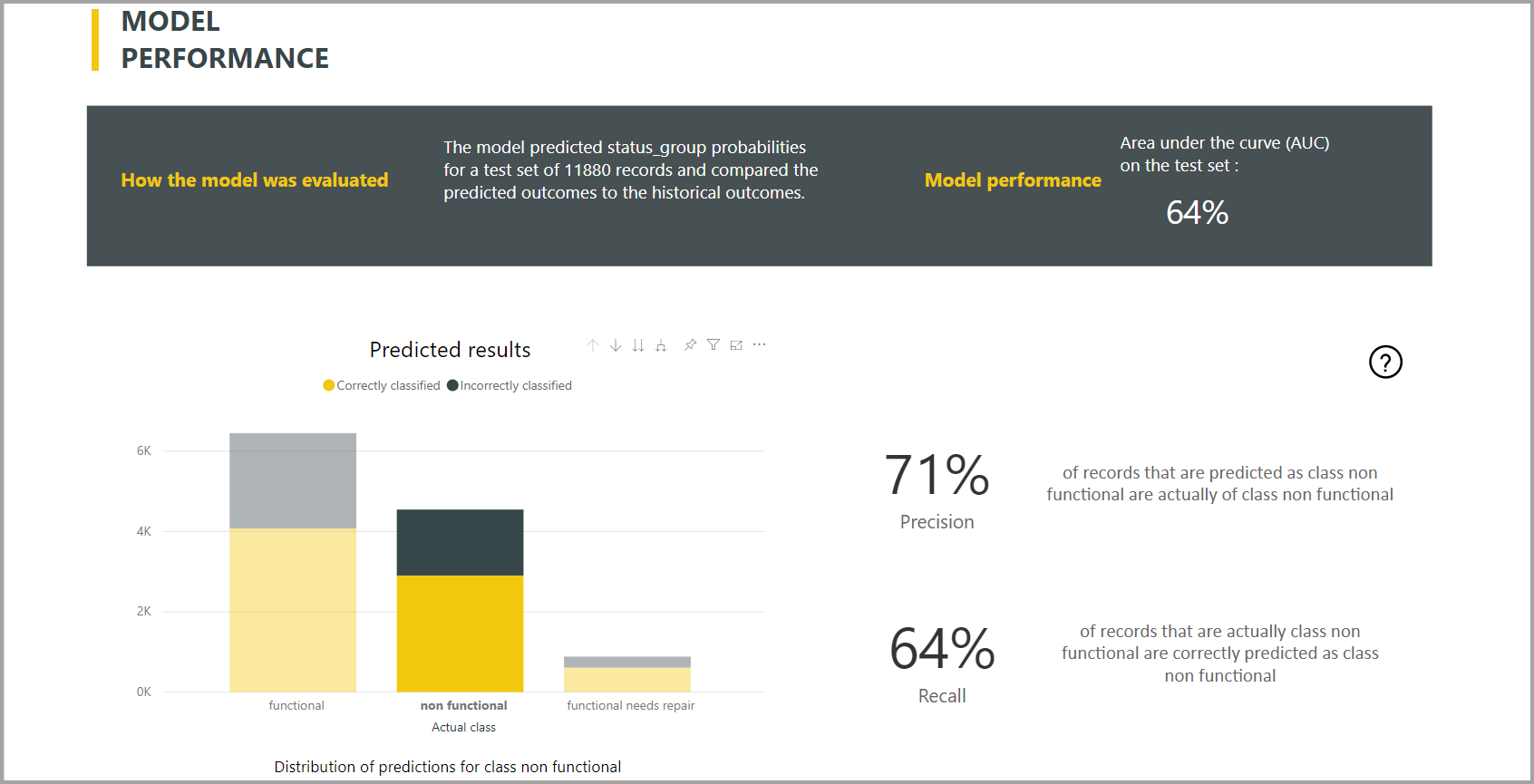
Tindakan penelusuran khusus kelas lebih lanjut memungkinkan analisis tentang bagaimana prediksi untuk kelas yang diketahui didistribusikan. Analisis ini menunjukkan kelas lain di mana baris kelas yang diketahui kemungkinan salah diklasifikasikan.
Penjelasan model dalam laporan juga mencakup prediktor teratas untuk setiap kelas.
Laporan model klasifikasi juga menyertakan halaman Detail Pelatihan yang mirip dengan halaman untuk jenis model lain, seperti yang dijelaskan sebelumnya, dalam laporan model AutoML.
Menerapkan model klasifikasi
Untuk menerapkan model ML klasifikasi, Anda harus menentukan tabel dengan data input dan awalan nama kolom output.
Saat model klasifikasi diterapkan, model tersebut menambahkan lima kolom output ke tabel output yang diperkaya: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities, dan ExplanationIndex. Nama kolom dalam tabel memiliki awalan yang ditentukan saat model diterapkan.
Kolom ClassProbabilities berisi daftar skor probabilitas untuk baris untuk setiap kemungkinan kelas.
ClassificationScore adalah probabilitas persentase, yang mengidentifikasi kemungkinan baris akan mencapai kriteria untuk kelas tertentu.
Kolom ClassificationResult berisi prediksi kelas yang paling mungkin untuk baris tersebut.
Kolom ClassificationExplanation berisi penjelasan dengan pengaruh spesifik yang dimiliki fitur input pada ClassificationScore.
Model regresi
Model regresi digunakan untuk memprediksi nilai numerik dan dapat digunakan dalam skenario seperti menentukan:
- Pendapatan kemungkinan akan direalisasikan dari kesepakatan penjualan.
- Nilai seumur hidup akun.
- Jumlah faktur piutang yang kemungkinan akan dibayar
- Tanggal di mana faktur mungkin dibayar, dan sebagainya.
Output model Regresi adalah nilai yang diprediksi.
Melatih model Regresi
Tabel input yang berisi data pelatihan untuk model Regresi harus memiliki kolom numerik sebagai kolom hasil, yang mengidentifikasi nilai hasil yang diketahui.
Prasyarat:
- Diperlukan minimal 100 baris data historis untuk model Regresi.
Proses pembuatan untuk model Regresi mengikuti langkah yang sama dengan model AutoML lainnya, yang dijelaskan di bagian sebelumnya, Mengonfigurasi input model ML.
Laporan model regresi
Seperti laporan model AutoML lainnya, laporan Regresi didasarkan pada hasil dari menerapkan model ke data pengujian holdout.
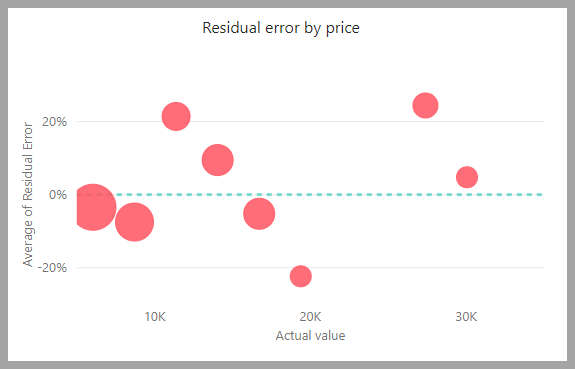
Laporan model menyertakan bagan yang membandingkan nilai yang diprediksi dengan nilai aktual. Dalam bagan ini, jarak dari diagonal menunjukkan kesalahan dalam prediksi.
Bagan kesalahan residu menunjukkan distribusi persentase kesalahan rata-rata untuk nilai yang berbeda dalam model semantik pengujian holdout. Sumbu horizontal mewakili rata-rata nilai aktual untuk grup. Ukuran gelembung menunjukkan frekuensi atau jumlah nilai dalam rentang tersebut. Sumbu vertikal adalah kesalahan residu rata-rata.
Laporan Model regresi juga menyertakan halaman Detail Pelatihan seperti laporan untuk jenis model lain, seperti yang dijelaskan di bagian sebelumnya, laporan model AutoML.
Menerapkan model regresi
Untuk menerapkan model ML Regresi, Anda harus menentukan tabel dengan data input dan awalan nama kolom output.
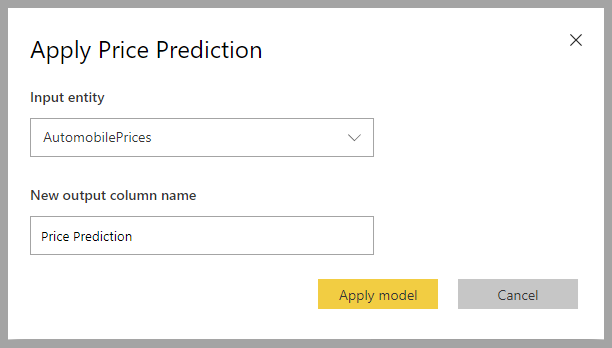
Saat model Regresi diterapkan, model menambahkan tiga kolom output ke tabel output yang diperkaya: RegressionResult, RegressionExplanation, dan ExplanationIndex. Nama kolom dalam tabel memiliki awalan yang ditentukan saat model diterapkan.
Kolom RegressionResult berisi nilai yang diprediksi untuk baris berdasarkan kolom input. Kolom RegressionExplanation berisi penjelasan dengan pengaruh spesifik yang dimiliki fitur input pada RegressionResult.
Integrasi Azure Machine Learning di Power BI
Banyak organisasi menggunakan model pembelajaran mesin untuk wawasan dan prediksi yang lebih baik tentang bisnis mereka. Anda dapat menggunakan pembelajaran mesin dengan laporan, dasbor, dan analitik lainnya untuk mendapatkan wawasan ini. Kemampuan untuk memvisualisasikan dan memanggil wawasan dari model ini dapat membantu menyebarkan wawasan ini kepada pengguna bisnis yang paling membutuhkannya. Power BI sekarang memudahkan untuk menggabungkan wawasan dari model yang dihosting di Azure Pembelajaran Mesin, dengan menggunakan gerakan titik dan klik yang mudah.
Untuk menggunakan kemampuan ini, ilmuwan data dapat memberikan akses ke model Azure Pembelajaran Mesin kepada analis BI dengan menggunakan portal Azure. Kemudian, pada awal setiap sesi, Power Query menemukan semua model Azure Pembelajaran Mesin tempat pengguna memiliki akses dan mengeksposnya sebagai fungsi Power Query dinamis. Pengguna kemudian dapat menjalankan fungsi tersebut dengan mengaksesnya dari pita di Editor Power Query, atau dengan menjalankan fungsi M secara langsung. Power BI juga secara otomatis membuat batch permintaan akses saat memanggil model Azure Pembelajaran Mesin untuk sekumpulan baris untuk mencapai performa yang lebih baik.
Fungsionalitas ini saat ini hanya didukung untuk aliran data Power BI dan untuk Power Query online di layanan Power BI.
Untuk mempelajari selengkapnya tentang aliran data, lihat Pengantar aliran data dan persiapan data layanan mandiri.
Untuk mempelajari selengkapnya tentang Azure Pembelajaran Mesin, lihat:
- Gambaran Umum: Apa itu Azure Machine Learning?
- Mulai Cepat dan Tutorial untuk Azure Machine Learning: Dokumentasi Azure Machine Learning
Memberikan akses ke model Azure Pembelajaran Mesin ke pengguna Power BI
Untuk mengakses model Azure Pembelajaran Mesin dari Power BI, pengguna harus memiliki akses Baca ke langganan Azure dan ruang kerja Pembelajaran Mesin.
Langkah-langkah dalam artikel ini menjelaskan cara memberikan akses pengguna Power BI ke model yang dihosting di layanan Azure Pembelajaran Mesin untuk mengakses model ini sebagai fungsi Power Query. Untuk informasi selengkapnya, lihat Menetapkan peran Azure menggunakan portal Microsoft Azure.
Masuk ke portal Azure.
Buka halaman Langganan. Anda dapat menemukan halaman Langganan melalui daftar Semua Layanan di menu panel navigasi portal Azure.
Pilih langganan Anda.

Pilih Kontrol Akses (IAM), lalu pilih tombol Tambahkan .
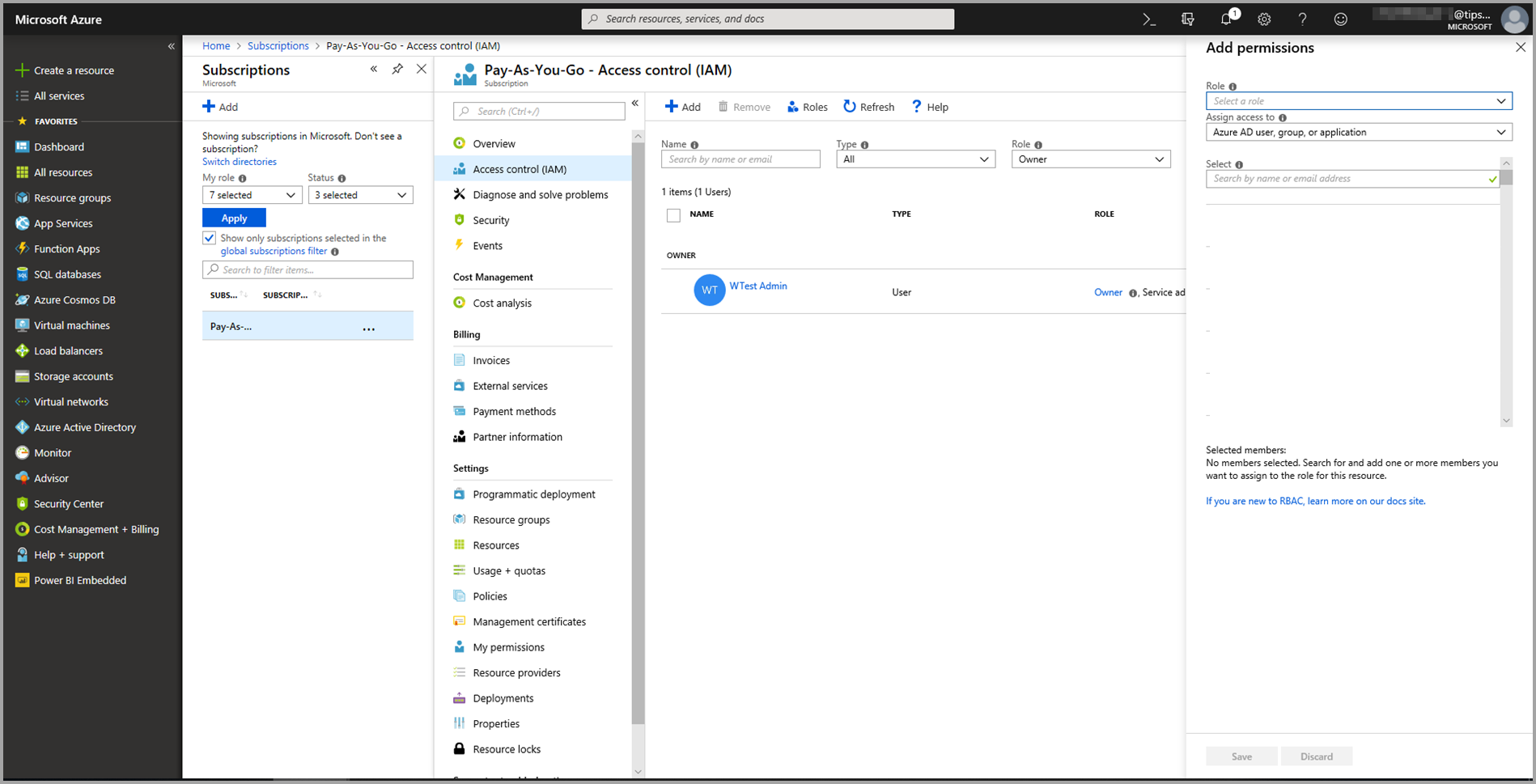
Pilih Pembaca sebagai Peran. Lalu pilih pengguna Power BI yang ingin Anda beri akses ke model Azure Pembelajaran Mesin.
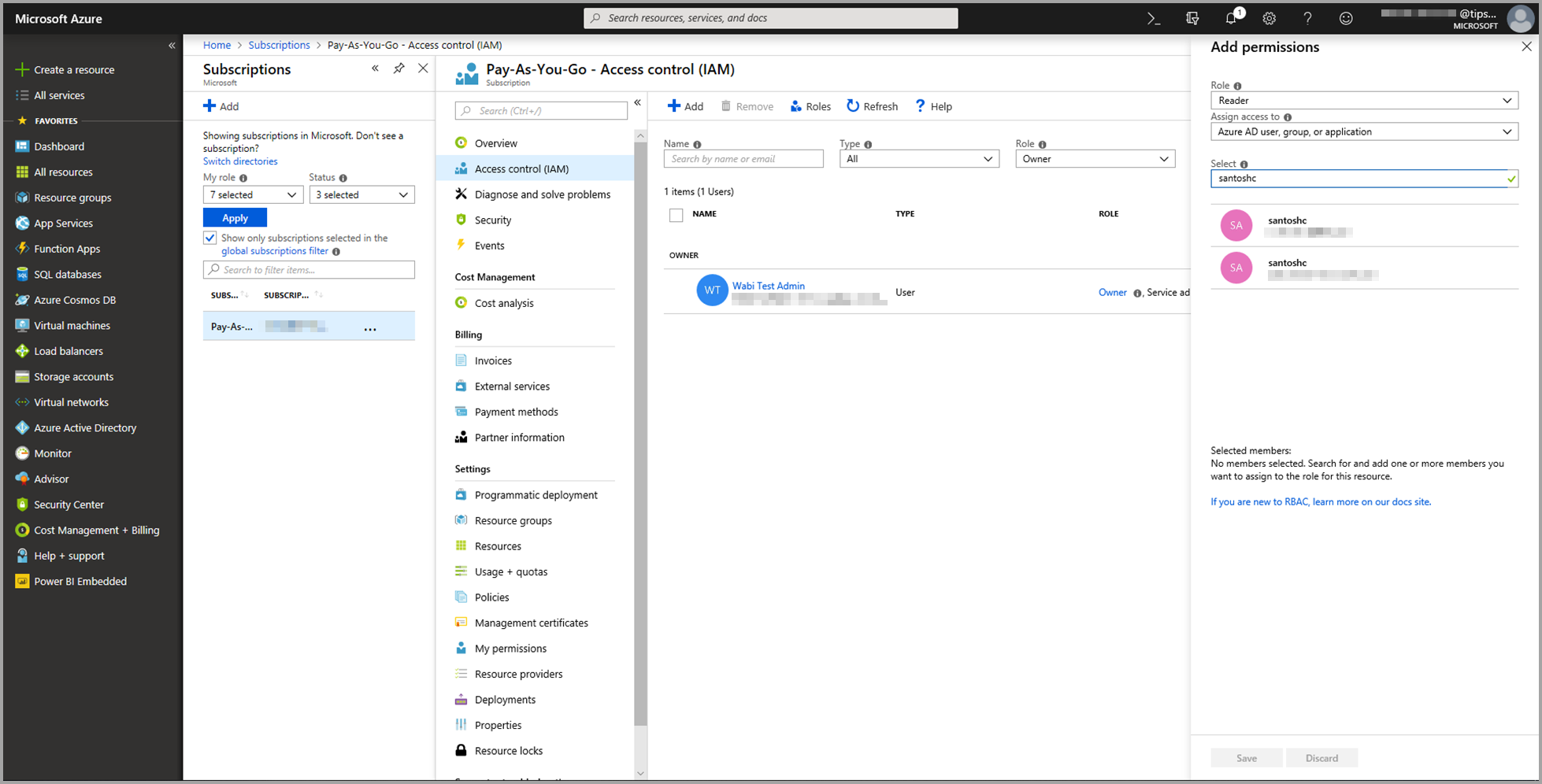
Pilih Simpan.
Ulangi langkah tiga hingga enam untuk memberikan akses Pembaca kepada pengguna untuk ruang kerja pembelajaran mesin tertentu yang menghosting model.




Penemuan skema untuk model pembelajaran mesin
Ilmuwan data terutama menggunakan Python untuk mengembangkan, dan bahkan menyebarkan, model pembelajaran mesin mereka untuk pembelajaran mesin. Ilmuwan data harus secara eksplisit menghasilkan file skema dengan menggunakan Python.
File skema ini harus disertakan dalam layanan web yang disebarkan untuk model pembelajaran mesin. Untuk menghasilkan skema untuk layanan web secara otomatis, Anda harus memberikan sampel input/output dalam skrip entri untuk model yang disebarkan. Untuk informasi selengkapnya, lihat Menyebarkan dan menilai model pembelajaran mesin dengan menggunakan titik akhir online. Tautan ini mencakup contoh skrip entri dengan pernyataan untuk pembuatan skema.
Secara khusus, fungsi @input_schema dan @output_schema dalam skrip entri mereferensikan format sampel input dan output dalam variabel input_sample dan output_sample . Fungsi menggunakan sampel ini untuk menghasilkan spesifikasi OpenAPI (Swagger) untuk layanan web selama penyebaran.
Instruksi untuk pembuatan skema ini dengan memperbarui skrip entri juga harus diterapkan ke model yang dibuat dengan menggunakan eksperimen pembelajaran mesin otomatis dengan Azure Pembelajaran Mesin SDK.
Catatan
Model yang dibuat dengan menggunakan antarmuka visual Azure Pembelajaran Mesin saat ini tidak mendukung pembuatan skema tetapi akan dalam rilis berikutnya.
Memanggil model Azure Pembelajaran Mesin di Power BI
Anda dapat memanggil model Azure Pembelajaran Mesin apa pun yang telah Anda berikan aksesnya, langsung dari Editor Power Query dalam aliran data Anda. Untuk mengakses model Azure Pembelajaran Mesin, pilih tombol Edit Tabel untuk tabel yang ingin Anda perkaya dengan wawasan dari model Azure Pembelajaran Mesin Anda, seperti yang ditunjukkan pada gambar berikut.

Memilih tombol Edit Tabel akan membuka Editor Power Query untuk tabel dalam aliran data Anda.

Pilih tombol Wawasan AI di pita, lalu pilih folder model Azure Machine Learning dari menu panel navigasi. Semua model Azure Pembelajaran Mesin yang dapat Anda akses tercantum di sini sebagai fungsi Power Query. Selain itu, parameter input untuk model Azure Pembelajaran Mesin secara otomatis dipetakan sebagai parameter fungsi Power Query yang sesuai.
Untuk memanggil model Azure Pembelajaran Mesin, Anda dapat menentukan salah satu kolom tabel yang dipilih sebagai input dari menu drop-down. Anda juga dapat menentukan nilai konstanta yang akan digunakan sebagai input dengan mengalihkan ikon kolom ke sebelah kiri dialog input.

Pilih Panggil untuk melihat pratinjau output model Azure Pembelajaran Mesin sebagai kolom baru dalam tabel. Pemanggilan model muncul sebagai langkah yang diterapkan untuk kueri.

Jika model mengembalikan beberapa parameter output, parameter tersebut dikelompokkan bersama sebagai baris di kolom output. Anda dapat memperluas kolom untuk menghasilkan parameter output individual dalam kolom terpisah.

Setelah Anda menyimpan aliran data, model secara otomatis dipanggil saat aliran data di-refresh, untuk baris baru atau yang diperbarui dalam tabel.
Pertimbangan dan batasan
- Aliran Data Gen2 saat ini tidak terintegrasi dengan pembelajaran mesin otomatis.
- Wawasan AI (model Cognitive Services dan Azure Pembelajaran Mesin) tidak didukung pada komputer dengan penyiapan autentikasi proksi.
- Model Azure Pembelajaran Mesin tidak didukung untuk pengguna Tamu.
- Ada beberapa masalah yang diketahui dengan menggunakan Gateway dengan AutoML dan Cognitive Services. Jika Anda perlu menggunakan gateway, sebaiknya buat aliran data yang mengimpor data yang diperlukan melalui gateway terlebih dahulu. Kemudian buat aliran data lain yang mereferensikan aliran data pertama untuk membuat atau menerapkan model dan fungsi AI ini.
- Jika AI Anda bekerja dengan aliran data gagal, Anda mungkin perlu mengaktifkan Gabungkan Cepat saat menggunakan AI dengan aliran data. Setelah Anda mengimpor tabel dan sebelum anda mulai menambahkan fitur AI, pilih Opsi dari pita Beranda, dan di jendela yang muncul pilih kotak centang di samping Izinkan menggabungkan data dari beberapa sumber untuk mengaktifkan fitur, lalu pilih OK untuk menyimpan pilihan Anda. Kemudian Anda dapat menambahkan fitur AI ke aliran data Anda.
Konten terkait
Artikel ini memberikan ringkasan Pembelajaran Mesin Otomatis untuk Aliran Data di layanan Power BI. Artikel berikut mungkin juga berguna.
- Tutorial: Membuat model Pembelajaran Mesin di Power BI
- Tutorial: Menggunakan Cognitive Services di Power BI
Artikel berikut ini menyediakan informasi selengkapnya tentang aliran data dan Power BI:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk