Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La migrazione di database di livello Exadata ad alte prestazioni nel cloud sta diventando sempre più un imperativo per i clienti Microsoft. I pacchetti software della supply chain impostano in genere l'altezza della barra a causa delle intense richieste di I/O di archiviazione con un carico di lavoro di lettura e scrittura misto basato su un singolo nodo di calcolo. L'infrastruttura di Azure in combinazione con Azure NetApp Files è in grado di soddisfare le esigenze di questo carico di lavoro estremamente impegnativo. Questo articolo presenta un esempio di come questa richiesta è stata soddisfatta per un cliente e come Azure può soddisfare le esigenze dei carichi di lavoro Oracle critici.
Prestazioni Oracle su scala aziendale
Quando si esplorano i limiti superiori delle prestazioni, è importante riconoscere e ridurre eventuali vincoli che potrebbero falsare i risultati. Ad esempio, se lo scopo è di dimostrare le funzionalità di prestazioni di un sistema di archiviazione, il client deve essere configurato idealmente in modo che la CPU non diventi un fattore di mitigazione prima che vengano raggiunti i limiti delle prestazioni di archiviazione. A tale scopo, i test iniziati con il tipo di istanza E104ids_v5 perché questa macchina virtuale è dotata non solo di un'interfaccia di rete da 100 Gbps, ma con un limite di uscita pari a 100 Gbps.
Il test si è verificato in due fasi:
- La prima fase si è concentrata sui test usando lo strumento SLOB2 standard di settore di Kevin Closson (Silly Little Oracle Benchmark) versione 2.5.4. L'obiettivo è guidare il maggior numero possibile di I/O Oracle da una macchina virtuale a più volumi di Azure NetApp Files e quindi aumentare il numero di istanze usando più database per dimostrare il ridimensionamento lineare.
- Dopo aver testato i limiti di scalabilità, i test hanno votato per i test meno costosi ma quasi come in grado di E96ds_v5 per una fase cliente di test usando un vero carico di lavoro dell'applicazione Supply Chain e dati reali.
Prestazioni di aumento delle prestazioni di SLOB2
I grafici seguenti acquisisce il profilo delle prestazioni di una singola macchina virtuale di Azure E104ids_v5 che esegue un singolo database Oracle 19c su otto volumi di Azure NetApp Files con otto endpoint di archiviazione. I volumi vengono distribuiti tra tre gruppi di dischi ASM: dati, log e archivio. Cinque volumi sono stati allocati al gruppo di dischi dati, due volumi al gruppo di dischi di log e un volume al gruppo di dischi di archiviazione. Tutti i risultati acquisiti in questo articolo sono stati raccolti usando le aree di Azure di produzione e i servizi di Azure di produzione attivi.
Per distribuire Oracle in macchine virtuali di Azure usando più volumi di Azure NetApp Files in più endpoint di archiviazione, usare il gruppo di volumi di applicazioni per Oracle.
Architettura a host singolo
Il diagramma seguente illustra l'architettura su cui è stato completato il test; Si noti che il database Oracle è distribuito tra più volumi e endpoint di Azure NetApp Files.

I/O di archiviazione a host singolo
Il diagramma seguente mostra un carico di lavoro selezionato in modo casuale del 100% con un rapporto di riscontri nel buffer del database di circa l'8%. SLOB2 è stato in grado di guidare circa 850.000 richieste di I/O al secondo mantenendo al contempo una latenza di eventi di lettura sequenziale del file DB submillisecond. Con una dimensione del blocco di database pari a 8.000 MiB/s di circa 6.800 MiB/sec di velocità effettiva di archiviazione.

Velocità effettiva a host singolo
Il diagramma seguente illustra che, per carichi di lavoro di I/O sequenziali a elevato utilizzo di larghezza di banda, ad esempio analisi di tabelle complete o attività RMAN, Azure NetApp Files può offrire tutte le funzionalità di larghezza di banda della macchina virtuale E104ids_v5 stessa.

Nota
Poiché l'istanza di calcolo è al massimo teorico della larghezza di banda, l'aggiunta di una concorrenza aggiuntiva dell'applicazione comporta solo un aumento della latenza lato client. Ciò comporta che i carichi di lavoro SLOB2 superano l'intervallo di tempo di completamento di destinazione, pertanto il numero di thread è stato limitato a sei.
Prestazioni di scalabilità orizzontale SLOB2
I grafici seguenti acquisiscono il profilo delle prestazioni di tre macchine virtuali di Azure E104ids_v5 che eseguono un singolo database Oracle 19c e ognuno con il proprio set di volumi di Azure NetApp Files e un layout identico del gruppo di dischi ASM, come descritto nella sezione Prestazioni di aumento delle prestazioni. La grafica mostra che con Azure NetApp Files multi-volume/multi-endpoint, le prestazioni aumentano facilmente con coerenza e prevedibilità.
Architettura multi-host
Il diagramma seguente illustra l'architettura su cui è stato completato il test; Si notino i tre database Oracle distribuiti tra più volumi e endpoint di Azure NetApp Files. Gli endpoint possono essere dedicati a un singolo host, come illustrato con Oracle VM 1 o condivisi tra gli host, come illustrato con Oracle VM2 e Oracle VM 3.

I/O di archiviazione multi-host
Il diagramma seguente mostra un carico di lavoro selezionato in modo casuale del 100% con un rapporto di riscontri nel buffer del database di circa l'8%. SLOB2 è stato in grado di guidare circa 850.000 richieste di I/O al secondo in tutti e tre gli host singolarmente. SLOB2 è stato in grado di eseguire questa operazione durante l'esecuzione in parallelo a un totale collettivo di circa 2.500.000 richieste di I/O al secondo con ogni host che mantiene comunque una latenza di eventi di lettura sequenziale del file db submillisecond. Con dimensioni del blocco di database pari a 8.000, si tratta di circa 20.000 MiB/s tra i tre host.

Velocità effettiva multi-host
Il diagramma seguente illustra che per i carichi di lavoro sequenziali, Azure NetApp Files può comunque offrire le funzionalità di larghezza di banda complete della macchina virtuale E104ids_v5 stessa anche quando viene ridimensionata verso l'esterno. SLOB2 è stato in grado di guidare I/O in totale oltre 30.000 MiB/s tra i tre host durante l'esecuzione in parallelo.

Prestazioni reali
Dopo aver testato i limiti di scalabilità con SLOB2, i test sono stati eseguiti con una suite di applicazioni della supply chain reale su Oracle in Azure NetApp files con risultati eccellenti. I dati seguenti del report Oracle Automatic Workload Repository (AWR) sono evidenziati in che modo viene eseguito un processo critico specifico.
Questo database include operazioni di I/O aggiuntive significative oltre al carico di lavoro dell'applicazione a causa dell'abilitazione del flashback e con dimensioni di blocco del database pari a 16.000. Dalla sezione Profilo I/O del report AWR, è evidente che esiste un rapporto elevato tra le scritture rispetto alle letture.
| - | Lettura e scrittura al secondo | Lettura al secondo | Scrittura al secondo |
|---|---|---|---|
| Totale (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Nonostante l'evento di attesa sequenziale del file di database che mostra una latenza superiore a 2,2 ms rispetto ai test SLOB2, questo cliente ha visto una riduzione di quindici minuti nel tempo di esecuzione del processo proveniente da un database RAC in Exadata a un database a istanza singola in Azure.
Vincoli delle risorse di Azure
Tutti i sistemi raggiungono infine i vincoli delle risorse, tradizionalmente noti come chokepoint. I carichi di lavoro del database, in particolare quelli estremamente esigenti, ad esempio i gruppi di applicazioni della supply chain, sono entità a elevato utilizzo di risorse. Trovare questi vincoli di risorse e usarli è fondamentale per qualsiasi distribuzione riuscita. Questa sezione illumina vari vincoli che ci si può aspettare di incontrare in un ambiente di questo tipo e come usarli. In ogni sottosezione, aspettarsi di apprendere sia le procedure consigliate che la logica sottostante.
Macchine virtuali
Questa sezione descrive in dettaglio i criteri da considerare nella selezione delle macchine virtuali per ottenere prestazioni ottimali e la logica alla base delle selezioni effettuate per i test. Azure NetApp Files è un servizio NAS (Network Attached Storage), pertanto il dimensionamento della larghezza di banda di rete appropriato è fondamentale per ottenere prestazioni ottimali.
Chipset
Il primo argomento di interesse è la selezione del chipset. Assicurarsi che qualsiasi SKU di MACCHINA virtuale selezionato sia basato su un singolo chipset per motivi di coerenza. La variante Intel di E_v5 macchine virtuali viene eseguita su una configurazione Intel Xeon Platinum 8370C (Ice Lake) di terza generazione. Tutte le macchine virtuali in questa famiglia sono dotate di un'unica interfaccia di rete da 100 Gbps. Al contrario, la serie E_v3, menzionata per esempio, è basata su quattro chipset separati, con varie larghezze di banda di rete fisiche. I quattro chipset utilizzati nella famiglia E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) hanno velocità del processore diverse, che influiscono sulle caratteristiche delle prestazioni della macchina.
Leggere la documentazione di Calcolo di Azure prestando attenzione alle opzioni del chipset. Vedere anche le procedure consigliate per gli SKU delle macchine virtuali di Azure per Azure NetApp Files. La selezione di una macchina virtuale con un singolo chipset è preferibile per una coerenza ottimale.
Larghezza di banda della rete disponibile
È importante comprendere la differenza tra la larghezza di banda disponibile dell'interfaccia di rete della macchina virtuale e la larghezza di banda a consumo applicata allo stesso. Quando la documentazione di Calcolo di Azure indica i limiti della larghezza di banda di rete, questi limiti vengono applicati solo in uscita (scrittura). Il traffico in ingresso (lettura) non viene a consumo e, di conseguenza, è limitato solo dalla larghezza di banda fisica della scheda di interfaccia di rete stessa. La larghezza di banda di rete della maggior parte delle macchine virtuali supera il limite di uscita applicato al computer.
Poiché i volumi di Azure NetApp Files sono collegati alla rete, il limite di uscita può essere considerato applicato in modo specifico alle scritture, mentre il traffico in ingresso viene definito come letture e carichi di lavoro simili a lettura. Anche se il limite in uscita della maggior parte dei computer è maggiore della larghezza di banda di rete della scheda di interfaccia di rete, lo stesso non può essere detto per il E104_v5 usato nei test per questo articolo. Il E104_v5 ha una scheda di interfaccia di rete da 100 Gbps con il limite di uscita impostato anche a 100 Gbps. Per confronto, la E96_v5, con la scheda di interfaccia di rete da 100 Gbps ha un limite di uscita di 35 Gbps con ingresso senza limiti a 100 Gbps. Man mano che le macchine virtuali diminuiscono di dimensioni, i limiti in uscita diminuiscono, ma il traffico in ingresso rimane invariato dai limiti imposti logicamente.
I limiti di uscita sono a livello di macchina virtuale e vengono applicati come tali a tutti i carichi di lavoro basati sulla rete. Quando si usa Oracle Data Guard, tutte le scritture vengono raddoppiate nei log di archiviazione e devono essere fattorite per limitare le considerazioni relative al limite di uscita. Questo vale anche per il log di archiviazione con più destinazioni e RMAN, se usato. Quando si selezionano macchine virtuali, acquisire familiarità con tali strumenti da riga di comando come ethtool, che espongono la configurazione della scheda di interfaccia di rete perché Azure non documenta le configurazioni dell'interfaccia di rete.
Concorrenza di rete
Le macchine virtuali di Azure e i volumi di Azure NetApp Files sono dotati di quantità specifiche di larghezza di banda. Come illustrato in precedenza, purché una macchina virtuale disponga di un'elevata capacità di utilizzo della CPU, un carico di lavoro può in teoria usare la larghezza di banda resa disponibile per tale macchina virtuale entro i limiti della scheda di rete e o del limite di uscita applicato. In pratica, tuttavia, la quantità di velocità effettiva ottenibile viene predicata sulla concorrenza del carico di lavoro nella rete, ovvero il numero di flussi di rete ed endpoint di rete.
Per una maggiore comprensione, vedere la sezione limiti del flusso di rete della macchina virtuale nel documento relativo alla larghezza di banda di rete delle macchine virtuali. Il più ampio numero di flussi di rete che connettono il client all'archiviazione è più ricco delle potenziali prestazioni.
Oracle supporta due client NFS separati, Kernel NFS e Direct NFS (dNFS). Kernel NFS, fino a tardi, supportava un singolo flusso di rete tra due endpoint (calcolo - archiviazione). Direct NFS, più efficiente dei due, supporta un numero variabile di flussi di rete: i test hanno mostrato centinaia di connessioni univoce per endpoint, aumentando o riducendo le richieste di carico. A causa del ridimensionamento dei flussi di rete tra due endpoint, Direct NFS è molto preferibile rispetto a Kernel NFS e, di conseguenza, la configurazione consigliata. Il gruppo di prodotti Azure NetApp Files non consiglia l'uso di Kernel NFS con carichi di lavoro Oracle. Per altre informazioni, vedere Vantaggi dell'uso di Azure NetApp Files con Oracle Database.
Concorrenza di esecuzione
L'uso di Direct NFS, un singolo chipset per la coerenza e la comprensione dei vincoli di larghezza di banda di rete ti porta solo fino a questo momento. Alla fine, l'applicazione determina le prestazioni. I modelli di verifica che usano SLOB2 e i modelli di verifica che usano una suite di applicazioni della supply chain reale sui dati reali dei clienti sono stati in grado di generare quantità significative di velocità effettiva solo perché le applicazioni sono state eseguite a livelli elevati di concorrenza; il primo usa un numero significativo di thread per schema, il secondo usa più connessioni da più server applicazioni. In breve, il carico di lavoro delle unità di concorrenza, bassa velocità effettiva a concorrenza bassa, velocità effettiva elevata con concorrenza elevata, purché l'infrastruttura sia in grado di supportare lo stesso.
Rete accelerata
La funzionalità rete accelerata abilita Single Root I/O Virtualization (SR-IOV) per le VM, migliorandone le prestazioni di rete. Questo percorso a prestazioni elevate esclude l'host dal percorso dati, riducendo così la latenza, l'instabilità e l'utilizzo della CPU e può essere usato con i carichi di lavoro di rete più impegnativi nei tipi di macchina virtuale supportati. Quando si distribuiscono macchine virtuali tramite utilità di gestione della configurazione, ad esempio terraform o riga di comando, tenere presente che la rete accelerata non è abilitata per impostazione predefinita. Per ottenere prestazioni ottimali, abilitare la rete accelerata. Prendere nota: la rete accelerata è abilitata o disabilitata in base all'interfaccia di rete. La funzionalità di rete accelerata è una funzionalità che può essere abilitata o disabilitata in modo dinamico.
Nota
Questo articolo contiene riferimenti al termine SLAVE, che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
Un approccio autorevole alla conseguente rete accelerata è abilitato per una scheda di interfaccia di rete tramite il terminale Linux. Se la rete accelerata è abilitata per una scheda di interfaccia di rete, è presente una seconda scheda di interfaccia di rete virtuale associata alla prima scheda di interfaccia di rete. Questa seconda scheda di interfaccia di rete viene configurata dal sistema con il SLAVE flag abilitato. Se non è presente alcuna scheda di interfaccia di rete con il SLAVE flag , la rete accelerata non è abilitata per tale interfaccia.
Nello scenario in cui sono configurate più schede di interfaccia di rete, è necessario determinare quale SLAVE interfaccia è associata alla scheda di interfaccia di rete usata per montare il volume NFS. L'aggiunta di schede di interfaccia di rete alla macchina virtuale non ha alcun effetto sulle prestazioni.
Usare il processo seguente per identificare il mapping tra l'interfaccia di rete configurata e l'interfaccia virtuale associata. Questo processo convalida che la rete accelerata sia abilitata per una scheda di interfaccia di rete specifica nel computer Linux e visualizzi la velocità di ingresso fisico che la scheda di interfaccia di rete può potenzialmente ottenere.
- Eseguire il
ip acomando :
- Elencare la
/sys/class/net/directory dell'ID NIC che si sta verificando (eth0nell'esempio) egrepper la parola in basso:ls /sys/class/net/eth0 | grep lower lower_eth1 - Eseguire il
ethtoolcomando sul dispositivo Ethernet identificato come dispositivo inferiore nel passaggio precedente.
Macchina virtuale di Azure: limiti di larghezza di banda di rete e disco
Quando si legge la documentazione sui limiti delle prestazioni delle macchine virtuali di Azure, è necessario un livello di esperienza. Tenere presente quanto:
- I numeri di velocità effettiva e operazioni di I/O al secondo di archiviazione temporanea fanno riferimento alle funzionalità delle prestazioni dello spazio di archiviazione temporaneo collegato direttamente alla macchina virtuale.
- I numeri di I/O e velocità effettiva del disco non memorizzati nella cache fanno riferimento in modo specifico a Disco di Azure (Premium, Premium v2 e Ultra) e non hanno alcun impatto sull'archiviazione collegata alla rete, ad esempio Azure NetApp Files.
- L'associazione di schede di interfaccia di rete aggiuntive alla macchina virtuale non ha alcun impatto sui limiti di prestazioni o sulle funzionalità delle prestazioni della macchina virtuale (documentata e testata per essere vera).
- La larghezza di banda massima di rete si riferisce ai limiti in uscita( ovvero le scritture quando è coinvolto Azure NetApp Files) applicate alla larghezza di banda di rete della macchina virtuale. Non vengono applicati limiti di ingresso, ovvero le letture quando è coinvolto Azure NetApp Files. Data una CPU sufficiente, una concorrenza di rete sufficiente e endpoint sufficienti per una macchina virtuale potrebbe in teoria indirizzare il traffico in ingresso ai limiti della scheda di interfaccia di rete. Come indicato nella sezione Larghezza di banda di rete disponibile, usare strumenti di questo
ethtooltipo per visualizzare la larghezza di banda della scheda di interfaccia di rete.
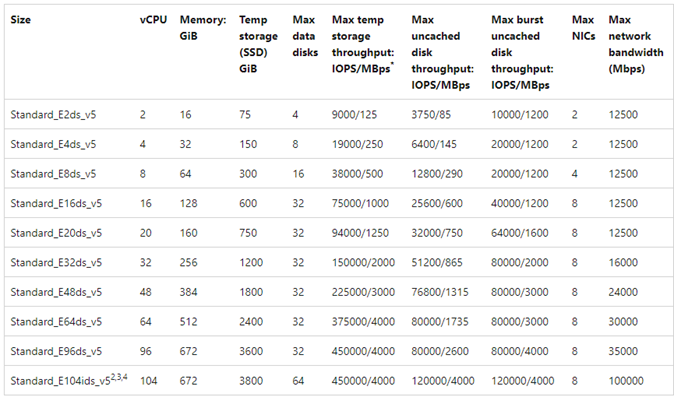
Per riferimento viene visualizzato un grafico di esempio:
Azure NetApp Files
Il servizio di archiviazione di Azure NetApp Files offre una soluzione di archiviazione completamente gestita a disponibilità elevata in grado di supportare i carichi di lavoro Oracle richiesti introdotti in precedenza.
Poiché i limiti delle prestazioni di archiviazione con scalabilità orizzontale in un database Oracle sono ben comprensibili, questo articolo è incentrato intenzionalmente sulle prestazioni di archiviazione con scalabilità orizzontale. La scalabilità orizzontale delle prestazioni di archiviazione implica l'accesso a una singola istanza Oracle a molti volumi di Azure NetApp Files in cui questi volumi vengono distribuiti su più endpoint di archiviazione.
Ridimensionando un carico di lavoro del database in più volumi in questo modo, le prestazioni del database non vengono connesse dai limiti superiori del volume e dell'endpoint. Con l'archiviazione che non impone più limitazioni delle prestazioni, l'architettura della macchina virtuale (limiti di CPU, scheda di interfaccia di rete e uscita della macchina virtuale) diventa il punto di connessione da affrontare. Come indicato nella sezione vm, la selezione delle istanze di E104ids_v5 e E96ds_v5 sono state prese in considerazione.
Se un database viene inserito in un singolo volume di capacità di grandi dimensioni o distribuito in più volumi più piccoli, il costo finanziario totale è lo stesso. Il vantaggio della distribuzione di I/O tra più volumi ed endpoint a differenza di un singolo volume e di un endpoint è l'evitare limiti di larghezza di banda, ovvero è possibile usare interamente ciò che si paga.
Importante
Per eseguire la distribuzione con Azure NetApp Files in una multiple volume:multiple endpoint configurazione, contattare lo specialista di Azure NetApp Files o Cloud Solution Architect per assistenza.
Banca dati
La versione 19c del database Oracle è la versione di rilascio a lungo termine corrente di Oracle e quella usata per produrre tutti i risultati dei test descritti in questo documento.
Per ottenere prestazioni ottimali, tutti i volumi di database sono stati montati usando Direct NFS, kernel NFS è consigliato a causa di vincoli di prestazioni. Per un confronto delle prestazioni tra i due client, vedere Prestazioni del database Oracle in volumi singoli di Azure NetApp Files. Si noti che sono state applicate tutte le patch dNFS pertinenti (ORACLE Support ID 1495104), come illustrato nel report Oracle Databases on Microsoft Azure using Azure NetApp Files (Procedure consigliate descritte nel report Oracle Databases on Microsoft Azure using Azure NetApp Files ).
Anche se Oracle e Azure NetApp Files supportano sia NFSv3 che NFSv4.1, poiché NFSv3 è il protocollo più maturo viene generalmente considerato come avere la maggiore stabilità ed è l'opzione più affidabile per gli ambienti altamente sensibili alle interruzioni. I test descritti in questo articolo sono stati completati in NFSv3.
Importante
Alcune delle patch consigliate che Oracle documenta in ID supporto 1495104 sono fondamentali per mantenere l'integrità dei dati quando si usa dNFS. L'applicazione di tali patch è fortemente consigliata per gli ambienti di produzione.
La gestione automatica dell'archiviazione (ASM) è supportata per i volumi NFS. Anche se in genere associato all'archiviazione basata su blocchi in cui ASM sostituisce la gestione dei volumi logici (LVM) e il file system, ASM svolge un ruolo prezioso negli scenari NFS multilicenza ed è degno di una forte considerazione. Uno di questi vantaggi di ASM, l'aggiunta online dinamica di e ribilanciamento tra i volumi e gli endpoint NFS appena aggiunti, semplifica la gestione consentendo l'espansione delle prestazioni e della capacità a volontà. Anche se ASM non è in e di se stesso aumentare le prestazioni di un database, il suo uso evita i file ad accesso frequente e la necessità di gestire manualmente la distribuzione dei file, un vantaggio facile da vedere.
Una configurazione ASM su dNFS è stata usata per produrre tutti i risultati dei test descritti in questo articolo. Il diagramma seguente illustra il layout del file ASM all'interno dei volumi di Azure NetApp Files e l'allocazione di file ai gruppi di dischi ASM.

Esistono alcune limitazioni con l'uso di ASM sui volumi montati NFS di Azure NetApp Files quando si tratta di snapshot di archiviazione che possono essere superati con alcune considerazioni sull'architettura. Per una revisione approfondita di queste considerazioni, contattare lo specialista di Azure NetApp Files o l'architetto di soluzioni cloud.
Strumenti di test sintetici e ottimizzabili
Questa sezione descrive l'architettura di test, i ottimizzabili e i dettagli di configurazione in specifiche. Anche se la sezione precedente è incentrata sui motivi per cui vengono prese decisioni di configurazione, questa sezione è incentrata in particolare sulle "cosa" delle decisioni di configurazione.
Distribuzione automatica
- Le macchine virtuali di database vengono distribuite usando script bash disponibili in GitHub.
- Il layout e l'allocazione di più volumi e endpoint di Azure NetApp Files vengono completati manualmente. Per assistenza, è necessario collaborare con lo specialista di Azure NetApp Files o Cloud Solution Architect.
- L'installazione della griglia, la configurazione ASM, la creazione e la configurazione del database e l'ambiente SLOB2 in ogni computer viene configurata usando Ansible per coerenza.
- Anche le esecuzioni di test SLOB2 parallele in più host vengono completate usando Ansible per coerenza ed esecuzione simultanea.
Configurazione della macchina virtuale
| Impostazione | Valore |
|---|---|
| Area di Azure | Europa occidentale |
| SKU di VM | E104ids_v5 |
| Numero di schede di interfaccia di rete | 1 NOTA: L'aggiunta di vNIC non ha alcun effetto sul conteggio dei sistemi |
| Larghezza di banda di rete in uscita massima (Mbps) | 100,000 |
| GiB di archiviazione temporanea (disco SSD) | 3,800 |
Configurazione del sistema
Tutte le impostazioni di configurazione di sistema necessarie per Oracle per la versione 19c sono state implementate in base alla documentazione oracle.
I parametri seguenti sono stati aggiunti al file di /etc/sysctl.conf sistema Linux:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Tutti i volumi di Azure NetApp Files sono stati montati con le opzioni di montaggio NFS seguenti.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parametri del database
| Parametri | Valore |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Configurazione di SLOB2
Tutta la generazione del carico di lavoro per i test è stata completata usando lo strumento SLOB2 versione 2.5.4.
Quattordici schemi SLOB2 sono stati caricati in uno spazio tabelle Oracle standard ed eseguiti su, che in combinazione con le impostazioni del file di configurazione slob elencate, inseriscono il set di dati SLOB2 a 7 TiB. Le impostazioni seguenti riflettono un'esecuzione di lettura casuale per SLOB2. Il parametro SCAN_PCT=0 di configurazione è stato modificato in SCAN_PCT=100 durante il test sequenziale.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
Per i test di lettura casuali sono state eseguite nove esecuzioni SLOB2. Il numero di thread è stato aumentato di sei con ogni iterazione di test a partire da uno.
Per i test sequenziali sono state eseguite sette esecuzioni SLOB2. Il numero di thread è stato aumentato di due con ogni iterazione di test a partire da una. Il numero di thread è stato limitato a sei a causa del raggiungimento dei limiti massimi della larghezza di banda di rete.
Metriche AWR
Tutte le metriche delle prestazioni sono state segnalate tramite oracle Automatic Workload Repository (AWR). Di seguito sono riportate le metriche presentate nei risultati:
- Velocità effettiva: la somma della velocità effettiva di lettura media e della velocità effettiva di scrittura dalla sezione Profilo di carico AWR
- Medie richieste di I/O in lettura dalla sezione Profilo di carico AWR
- db file sequenziale read wait time average wait time from the AWR Foreground Wait Events section
Migrazione da sistemi progettati appositamente progettati al cloud
Oracle Exadata è un sistema progettato, una combinazione di hardware e software considerata la soluzione più ottimizzata per l'esecuzione di carichi di lavoro Oracle. Anche se il cloud presenta vantaggi significativi nello schema complessivo del mondo tecnico, questi sistemi specializzati possono sembrare incredibilmente attraenti per coloro che hanno letto e visto le ottimizzazioni Che Oracle ha costruito intorno ai carichi di lavoro specifici.
Quando si tratta di eseguire Oracle in Exadata, esistono alcuni motivi comuni per cui viene scelto Exadata:
- 1-2 carichi di lavoro di I/O elevati che sono adatti alle funzionalità exadata e poiché questi carichi di lavoro richiedono funzionalità avanzate di Exadata, il resto dei database in esecuzione insieme a essi è stato consolidato in Exadata.
- Carichi di lavoro OLTP complessi o difficili che richiedono la scalabilità di RAC e sono difficili da progettare con hardware proprietario senza una conoscenza approfondita dell'ottimizzazione oracle o potrebbero non essere in grado di ottimizzare il debito tecnico.
- Exadata esistente sottoutilizzato con vari carichi di lavoro: questo esiste a causa di migrazioni precedenti, fine della vita in un exadata precedente o a causa di un desiderio di lavorare/testare un exadata internamente.
È essenziale comprendere qualsiasi migrazione da un sistema Exadata dal punto di vista dei carichi di lavoro e quanto sia semplice o complessa la migrazione. Una necessità secondaria è comprendere il motivo dell'acquisto di Exadata da una prospettiva di stato. Le competenze exadata e RAC sono in una domanda più elevata e potrebbero aver guidato l'indicazione di acquistare uno dagli stakeholder tecnici.
Importante
Indipendentemente dallo scenario, l'intero take-away dovrebbe essere, per qualsiasi carico di lavoro del database proveniente da un exadata, più funzionalità proprietarie di Exadata usate, più complessa è la migrazione e la pianificazione. Gli ambienti che non usano molto le funzionalità proprietarie di Exadata offrono opportunità per un processo di migrazione e pianificazione più semplice.
Sono disponibili diversi strumenti che possono essere usati per valutare queste opportunità di carico di lavoro:
- Repository automatico del carico di lavoro :The Automatic Workload Repository (AWR):
- Tutti i database Exadata sono concessi in licenza per usare report AWR e funzionalità di diagnostica e prestazioni connesse.
- È sempre attivo e raccoglie i dati che possono essere usati per visualizzare le informazioni cronologiche del carico di lavoro e valutare l'utilizzo. I valori di picco possono valutare l'utilizzo elevato nel sistema,
- I report AWR della finestra più grandi possono valutare il carico di lavoro complessivo, fornendo informazioni utili sull'utilizzo delle funzionalità e su come eseguire la migrazione del carico di lavoro a non Exadata in modo efficace. I report AWR di picco sono invece ideali per l'ottimizzazione e la risoluzione dei problemi relativi alle prestazioni.
- Il report AWR globale (RAC-Aware) per Exadata include anche una sezione specifica di Exadata, che esegue il drill-down in un utilizzo specifico delle funzionalità di Exadata e fornisce informazioni dettagliate preziose cache flash cache, registrazione flash, I/O e altri utilizzi delle funzionalità in base al nodo del database e della cella.
Disaccoppiamento da Exadata
Quando si identificano i carichi di lavoro Oracle Exadata di cui eseguire la migrazione al cloud, prendere in considerazione le domande e i punti dati seguenti:
- Il carico di lavoro utilizza più funzionalità di Exadata, al di fuori dei vantaggi hardware?
- Analisi intelligenti
- Indici di archiviazione
- Cache flash
- Registrazione flash
- Compressione a colonne ibride
- Il carico di lavoro usa l'offload exadata in modo efficiente? Negli eventi in primo piano, qual è il rapporto (più del 10% del tempo del database) del carico di lavoro usando:
- Analisi smart table cella (ottimale)
- Lettura fisica a più blocchi delle celle (meno ottimale)
- Lettura fisica a blocco singolo cella (minima ottimale)
- Compressione a colonne ibride (HCC/EHCC): che cos'è il rapporto compresso e non compresso:
- La spesa per il database è superiore al 10% del tempo di database per la compressione e la decompressione dei dati?
- Esaminare i miglioramenti delle prestazioni per i predicati usando la compressione nelle query: è il valore ottenuto rispetto all'importo salvato con la compressione?
- I/O fisico cella: esaminare i risparmi offerti da:
- quantità indirizzata al nodo del database per bilanciare la CPU.
- identificazione del numero di byte restituiti dall'analisi intelligente. Questi valori possono essere sottratti in I/O per la percentuale di letture fisiche a blocco singolo cella dopo la migrazione da Exadata.
- Si noti il numero di letture logiche dalla cache. Determinare se la cache flash sarà necessaria in una soluzione IaaS cloud per il carico di lavoro.
- Confrontare i byte totali di lettura e scrittura fisici con il totale eseguito nella cache. È possibile aumentare la memoria per eliminare i requisiti di lettura fisica (è comune ridurre SGA per forzare l'offload per Exadata)?
- In Statistiche di sistema identificare gli oggetti interessati dalla statistica. Se si ottimizza SQL, l'indicizzazione, il partizionamento o un'altra ottimizzazione fisica può ottimizzare notevolmente il carico di lavoro.
- Esaminare i parametri di inizializzazione per i parametri di sottolineatura (_) o deprecati, che devono essere giustificati a causa dell'impatto a livello di database che potrebbero causare prestazioni.
Configurazione del server Exadata
In Oracle versione 12.2 e successive, un'aggiunta specifica di Exadata verrà inclusa nel report globale AWR. Questo report include sezioni che forniscono un valore eccezionale a una migrazione da Exadata.
Versione di Exadata e dettagli di sistema
Dettagli degli avvisi dei nodi di cella
Dischi exadata nononline
Dati outlier per tutte le statistiche del sistema operativo Exadata
Giallo/Rosa: Di preoccupazione. Exadata non è in esecuzione in modo ottimale.
Rosso: le prestazioni di Exadata hanno un impatto significativo.
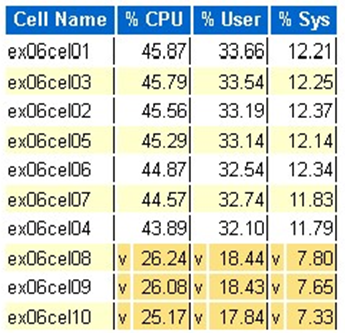
Statistica della CPU del sistema operativo exadata: celle principali
- Queste statistiche vengono raccolte dal sistema operativo nelle celle e non sono limitate a questo database o istanze
- Uno
vsfondo giallo scuro indica un valore outlier inferiore all'intervallo basso - Uno
^sfondo giallo chiaro indica un valore outlier sopra l'intervallo elevato - Le celle superiori per percentuale CPU vengono visualizzate e sono in ordine decrescente di CPU
- Media: 39,34% CPU, 28,57% utente, 10,77% sys
Letture di blocchi fisici a cella singola
Utilizzo della cache flash
I/O temp
Efficienza della cache a colonne
Database principale per velocità effettiva di I/O
Anche se è possibile eseguire valutazioni di ridimensionamento, esistono alcune domande sulle medie e sui picchi simulati integrati in questi valori per carichi di lavoro di grandi dimensioni. Questa sezione, trovata alla fine di un report AWR, è estremamente utile perché mostra sia l'utilizzo medio del flash che del disco dei primi 10 database in Exadata. Anche se molti possono presupporre che vogliano ridimensionare i database per ottenere prestazioni ottimali nel cloud, questo non ha senso per la maggior parte delle distribuzioni (oltre il 95% è compreso nell'intervallo medio; con un picco simulato calcolato in, l'intervallo medio è maggiore del 98%). È importante pagare ciò che è necessario, anche per i carichi di lavoro più elevati della domanda di Oracle e controllare i database principali in base alla velocità effettiva di I/O, per comprendere le esigenze delle risorse per il database.
Dimensioni corrette di Oracle con AWR in Exadata
Quando si esegue la pianificazione della capacità per i sistemi locali, è naturale avere un sovraccarico significativo incorporato nell'hardware. L'hardware sottoposto a provisioning eccessivo deve gestire il carico di lavoro Oracle per diversi anni, indipendentemente dalle aggiunte del carico di lavoro a causa dell'aumento dei dati, delle modifiche al codice o degli aggiornamenti.
Uno dei vantaggi del cloud è il ridimensionamento delle risorse in un host di macchine virtuali e l'archiviazione possono essere eseguiti in base all'aumento delle richieste. Ciò consente di risparmiare i costi del cloud e i costi di licenza associati all'utilizzo del processore (pertinente con Oracle).
Il ridimensionamento corretto comporta la rimozione dell'hardware dalla migrazione tradizionale in modalità lift-and-shift e l'uso delle informazioni sul carico di lavoro fornite dal repository AWR (Automatic Workload Repository) di Oracle per trasferire in modalità lift-and-shift il carico di lavoro in calcolo e archiviazione appositamente progettato per supportarlo nel cloud di propria scelta. Il processo di dimensionamento corretto garantisce che l'architettura in futuro elimini il debito tecnico dell'infrastruttura, la ridondanza dell'architettura che si verificherebbe se la duplicazione del sistema locale fosse replicata nel cloud e implementi i servizi cloud quando possibile.
Gli esperti in materia di Microsoft Oracle hanno stimato che oltre l'80% dei database Oracle viene sottoposto a over-provisioning e si riscontrano gli stessi costi o risparmi nel cloud se impiegano il tempo necessario per ridimensionare correttamente il carico di lavoro del database Oracle prima di eseguire la migrazione al cloud. Questa valutazione richiede agli specialisti del database del team di cambiare mentalità su come potrebbero aver eseguito la pianificazione della capacità in passato, ma vale la pena investire gli stakeholder nel cloud e nella strategia cloud dell'azienda.
Passaggi successivi
- Eseguire i carichi di lavoro Oracle più impegnativi in Azure senza sacrificare prestazioni o scalabilità
- Architetture di soluzioni con Azure NetApp Files - Oracle
- Progettare e implementare un database Oracle in Azure
- Strumento di stima per il ridimensionamento dei carichi di lavoro Oracle in macchine virtuali IaaS di Azure
- Architetture di riferimento per Oracle Database Enterprise Edition in Azure
- Informazioni sui gruppi di volumi di applicazioni di Azure NetApp Files per SAP HANA