Copiare dati da e in Azure Databricks Delta Lake tramite Azure Data Factory o Azure Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività Copy in Azure Data Factory ed Azure Synapse per copiare dati da e in Azure Databricks Delta Lake. Si basa sull'articolo Attività Copy, che presenta informazioni generali sull'attività Copy.
Funzionalità supportate
Questo connettore Azure Databricks Delta Lake è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | ① ② |
| Flusso di dati per mapping (origine/sink) | ① |
| Attività Lookup | ① ② |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
In generale, il servizio supporta Delta Lake con le funzionalità seguenti per soddisfare le diverse esigenze.
- L'attività Copy supporta il connettore Azure Databricks Delta Lake per copiare dati da qualsiasi archivio dati di origine supportato nella tabella Delta Lake di Azure Databricks e dalla tabella Delta Lake a qualsiasi archivio dati sink supportato. Usa il cluster Databricks per eseguire lo spostamento dei dati. Vedere i dettagli nella sezione Prerequisiti.
- Il flusso di dati per mapping supporta il formato Delta generico in Archiviazione di Azure come origine e sink per leggere e scrivere file Delta per operazioni ETL senza codice e viene eseguito in Azure Integration Runtime gestito.
- Leattività di Databricks supportano l'orchestrazione del carico di lavoro ETL o Machine Learning incentrato sul Delta Lake.
Prerequisiti
Per usare questo connettore Azure Databricks Delta Lake, è necessario configurare un cluster in Azure Databricks.
- Per copiare dati in Delta Lake, l'attività Copy richiama il cluster Azure Databricks per leggere i dati da un'archiviazione di Azure, ovvero l'origine originale o un'area di staging in cui il servizio scrive prima i dati di origine tramite una copia di staging predefinita. Per altre informazioni, vedere Delta Lake come sink.
- In modo analogo, per copiare dati da Delta Lake, l'attività Copy richiama il cluster Azure Databricks per scrivere i dati in un'archiviazione di Azure, ovvero il sink originale o un'area di staging da cui il servizio continua a scrivere i dati nel sink finale tramite una copia di staging predefinita. Per altre informazioni, vedere Delta Lake come origine.
Il cluster Databricks deve avere accesso all'account BLOB di Azure o Azure Data Lake Storage Gen2, sia al contenitore di archiviazione/file system usato per origine/sink/staging che il contenitore/file system in cui si vogliono scrivere le tabelle Delta Lake.
Per usare Azure Data Lake Storage Gen2, è possibile configurare un'entità servizio nel cluster Databricks come parte della configurazione di Apache Spark. Seguire la procedura descritta in Accedere direttamente con un'entità servizio.
Per usare Archiviazione BLOB di Azure, è possibile configurare una chiave di accesso dell'account di archiviazione o un token di firma di accesso condiviso nel cluster Databricks come parte della configurazione di Apache Spark. Seguire la procedura descritta in Accedere all'archiviazione BLOB di Azure usando l'API RDD.
Durante l'esecuzione dell'attività Copy, se il cluster configurato è stato terminato, il servizio lo avvia automaticamente. Se si crea una pipeline usando l'interfaccia utente di creazione, per operazioni come l'anteprima dei dati, è necessario avere un cluster attivo, perché il servizio non avvierà il cluster per conto dell'utente.
Specificare la configurazione del cluster
Nell'elenco a discesa Modalità cluster selezionare Standard.
Nell'elenco a discesa Versione di Databricks Runtime selezionare una versione del runtime di Databricks.
Attivare Ottimizzazione automatica aggiungendo le proprietà seguenti alla configurazione di Spark:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueConfigurare il cluster in base alle esigenze di integrazione e scalabilità.
Per informazioni dettagliate sulla configurazione dei cluster, vedere Configurare cluster.
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
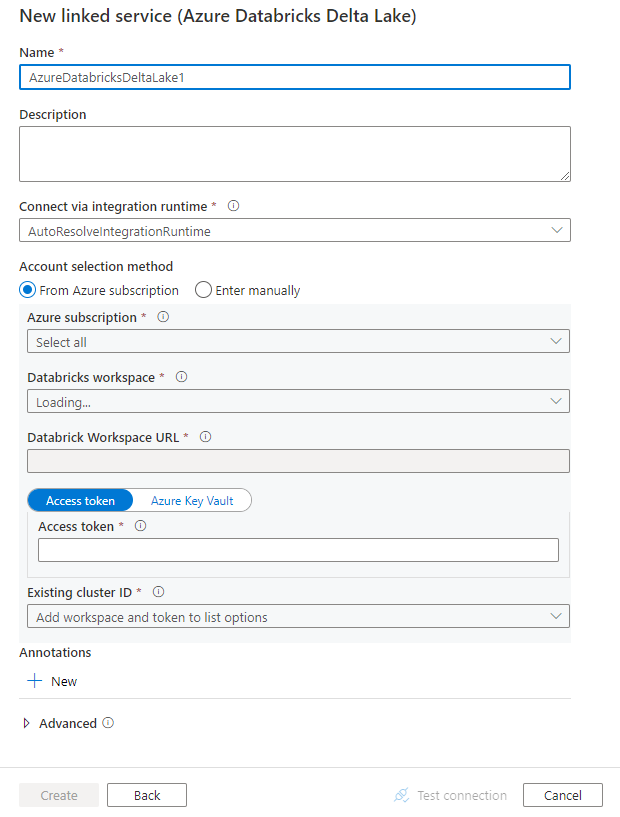
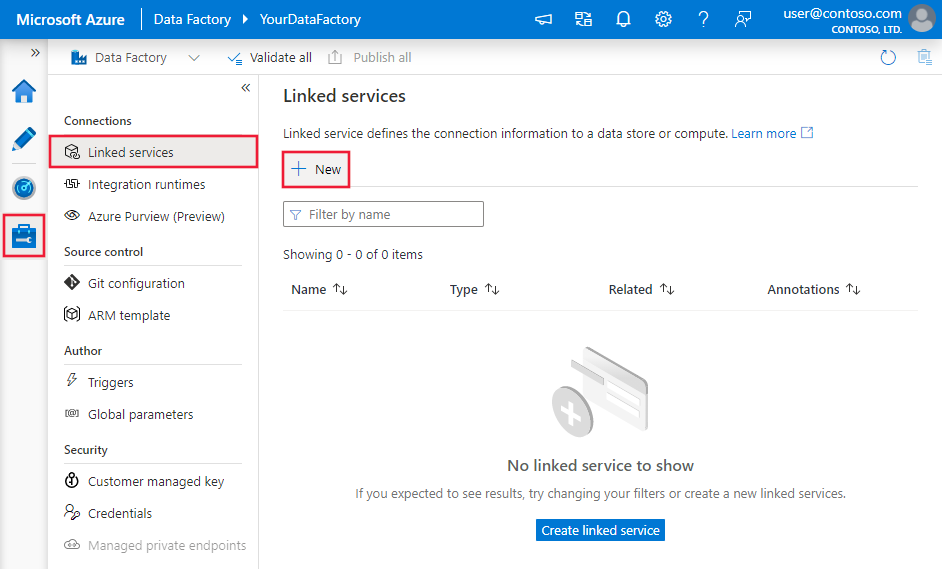
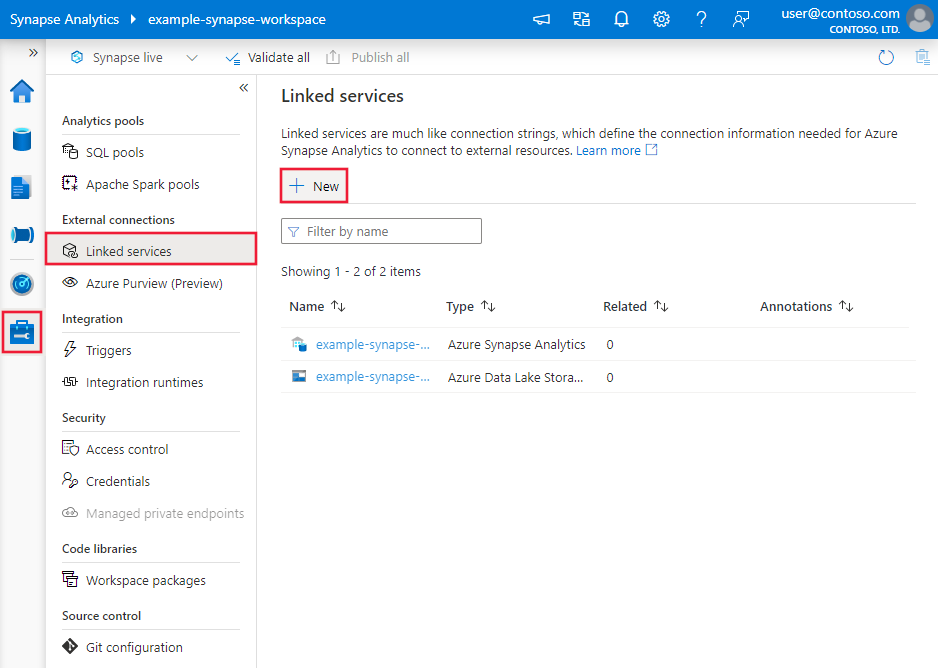
Creare un servizio collegato ad Azure Databricks Delta Lake usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato ad Azure Databricks Delta Lake nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare delta e selezionare il connettore Azure Databricks Delta Lake.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà che definiscono entità specifiche di un connettore Azure Databricks Delta Lake.
Proprietà del servizio collegato
Questo connettore Azure Databricks Delta Lake supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti.
- Token di accesso
- Autenticazione dell'identità gestita assegnata dal sistema
- Autenticazione dell'identità gestita assegnata dall'utente
Token di accesso
Per il servizio collegato ad Azure Databricks Delta Lake sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo deve essere impostata su AzureDatabricksDeltaLake. | Sì |
| dominio | Specificare l'URL dell'area di lavoro di Azure Databricks, ad esempio https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Specificare l'ID cluster di un cluster esistente. Dovrebbe essere un cluster interattivo già creato. È possibile trovare l'ID cluster di un cluster interattivo nell'area di lavoro di Databricks -> Cluster -> Nome cluster interattivo -> Configurazione -> Tag. Altre informazioni. |
|
| accessToken | Il token di accesso è obbligatorio per l'autenticazione del servizio con Azure Databricks. Deve essere generato dall'area di lavoro di Databricks. Per una procedura più dettagliata per trovare il token di accesso, fare clic qui. | |
| connectVia | Il runtime di integrazione usato per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Autenticazione dell'identità gestita assegnata dal sistema
Per altre informazioni sulle identità gestite assegnate dal sistema per le risorse di Azure, vedere Identità gestita assegnata dal sistema per le risorse di Azure.
Per usare l'autenticazione con identità gestita assegnata dal sistema, seguire questa procedura per concedere le autorizzazioni:
Recuperare le informazioni relative all'identità gestita copiando il valore di ID oggetto dell'identità gestita generato con l'area di lavoro di data factory o Synapse.
Concedere all'identità gestita le autorizzazioni corrette in Azure Databricks. In generale, è necessario concedere almeno il ruolo Collaboratore all'identità gestita assegnata dal sistema in Controllo di accesso (IAM) di Azure Databricks.
Per il servizio collegato ad Azure Databricks Delta Lake sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo deve essere impostata su AzureDatabricksDeltaLake. | Sì |
| dominio | Specificare l'URL dell'area di lavoro di Azure Databricks, ad esempio https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Sì |
| clusterId | Specificare l'ID cluster di un cluster esistente. Dovrebbe essere un cluster interattivo già creato. È possibile trovare l'ID cluster di un cluster interattivo nell'area di lavoro di Databricks -> Cluster -> Nome cluster interattivo -> Configurazione -> Tag. Altre informazioni. |
Sì |
| workspaceResourceId | Specificare l'ID risorsa dell'area di lavoro di Azure Databricks. | Sì |
| connectVia | Il runtime di integrazione usato per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'identità gestita assegnata dall'utente
Per altre informazioni sulle identità gestite assegnate dall'utente per le risorse di Azure, vedere Identità gestite assegnate dall'utente
Per usare l'autenticazione dell'identità gestita assegnata dall’utente, seguire questa procedura:
Creare una o più identità gestite assegnate dall'utente e concedere l'autorizzazione in Azure Databricks. In generale, è necessario concedere almeno il ruolo Collaboratore all'identità gestita assegnata dall'utente in Controllo di accesso (IAM) di Azure Databricks.
Assegnare una o più identità gestite assegnate dall'utente alla data factory o all'area di lavoro Synapse e creare le credenziali per ogni identità gestita assegnata dall'utente.
Per il servizio collegato ad Azure Databricks Delta Lake sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo deve essere impostata su AzureDatabricksDeltaLake. | Sì |
| dominio | Specificare l'URL dell'area di lavoro di Azure Databricks, ad esempio https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Sì |
| clusterId | Specificare l'ID cluster di un cluster esistente. Dovrebbe essere un cluster interattivo già creato. È possibile trovare l'ID cluster di un cluster interattivo nell'area di lavoro di Databricks -> Cluster -> Nome cluster interattivo -> Configurazione -> Tag. Altre informazioni. |
Sì |
| credentials | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
| workspaceResourceId | Specificare l'ID risorsa dell'area di lavoro di Azure Databricks. | Sì |
| connectVia | Il runtime di integrazione usato per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati.
Per il set di dati di Azure Databricks Delta Lake sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo del set di dati deve essere impostata su AzureDatabricksDeltaLakeDataset. | Sì |
| database | Nome del database di . | No per l'origine, sì per il sink |
| table | Nome della tabella Delta. | No per l'origine, sì per il sink |
Esempio:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink Azure Databricks Delta Lake.
Delta Lake come origine
Per copiare dati da Azure Databricks Delta Lake, nella sezione origine dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo dell'origine dell'attività Copy deve essere impostata su AzureDatabricksDeltaLakeSource. | Sì |
| query | Specificare la query SQL per leggere i dati. Per il controllo dello spostamento cronologico, seguire il modello seguente: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
No |
| exportSettings | Impostazioni avanzate usate per recuperare i dati dalla tabella Delta. | No |
In exportSettings: |
||
| type | Tipo di comando di esportazione, impostato su AzureDatabricksDeltaLakeExportCommand. | Sì |
| dateFormat | Formattare il tipo di data come stringa con un formato di data. I formati di data personalizzati seguono i formati del modello datetime. Se non viene specificato, usa il valore predefinito yyyy-MM-dd. |
No |
| timestampFormat | Formattare il tipo di timestamp come stringa con un formato timestamp. I formati di data personalizzati seguono i formati del modello datetime. Se non viene specificato, usa il valore predefinito yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Copia diretta da Delta Lake
Se l'archivio dati sink e il formato soddisfano i criteri descritti in questa sezione, è possibile usare l'attività Copy per copiare direttamente dalla tabella Delta di Azure Databricks al sink. Il servizio controlla le impostazioni e, se i criteri seguenti non vengono soddisfatti, l'esecuzione dell'attività Copy non riesce:
Il servizio collegato sink è archiviazione BLOB di Azure o Azure Data Lake Storage Gen2. Le credenziali dell'account devono essere preconfigurate nella configurazione del cluster di Azure Databricks. Per altre informazioni, vedere Prerequisiti.
Il formato di dati sink è Parquet, testo delimitato o Avro con le configurazioni seguenti e punta a una cartella anziché a un file.
- Per il formato Parquet, il codec di compressione è none, snappy o gzip.
- Per il formato testo delimitato:
rowDelimiterè qualsiasi carattere singolo.compressionpuò essere none, bzip2, gzip.encodingNameUTF-7 non è supportato.
- Per il formato Avro, il codec di compressione è none, deflate o snappy.
Nell'origine dell'attività Copy
additionalColumnsnon è specificato.Se si copiano dati in testo delimitato, nel sink dell'attività Copy
fileExtensiondeve essere ".csv".Nel mapping delle attività Copy la conversione dei tipi non è abilitata.
Esempio:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copia con staging da Delta Lake
Quando l'archivio dati sink o il formato non corrisponde ai criteri di copia diretta, come indicato nell'ultima sezione, abilitare la copia con staging predefinita usando un'istanza di archiviazione di Azure temporanea. La funzionalità copia di staging assicura inoltre una migliore velocità effettiva, Il servizio esporta i dati da Azure Databricks Delta Lake nell'archiviazione di staging, quindi copia i dati nel sink e infine pulisce i dati temporanei dall'archiviazione di staging. Per informazioni dettagliate sulla copia dei dati tramite staging, vedere Copia di staging.
Per usare questa funzionalità, creare un servizio collegato di archiviazione BLOB di Azure o un servizio collegato di Azure Data Lake Storage Gen2che fa riferimento all'account di archiviazione come staging provvisorio. Specificare quindi le proprietà enableStaging e stagingSettings nell'attività Copy.
Nota
Le credenziali dell'account di archiviazione di staging devono essere preconfigurate nella configurazione del cluster di Azure Databricks. Per altre informazioni, vedere Prerequisiti.
Esempio:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake come sink
Per copiare dati in Azure Databricks Delta Lake, nella sezione sink dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà del tipo del sink dell'attività Copy deve essere impostata su AzureDatabricksDeltaLakeSink. | Sì |
| preCopyScript | Specificare una query SQL per l'attività Copy da eseguire prima di scrivere i dati nella tabella Delta di Databricks in ogni esecuzione. Esempio: VACUUM eventsTable DRY RUN È possibile usare questa proprietà per pulire i dati precaricati o aggiungere una tabella troncata o un'istruzione Vacuum. |
No |
| importSettings | Impostazioni avanzate usate per scrivere dati nella tabella Delta. | No |
In importSettings: |
||
| type | Tipo di comando di importazione, impostato su AzureDatabricksDeltaLakeImportCommand. | Sì |
| dateFormat | Formattare la stringa con un tipo di data con un formato di data. I formati di data personalizzati seguono i formati del modello datetime. Se non viene specificato, usa il valore predefinito yyyy-MM-dd. |
No |
| timestampFormat | Formattare la stringa con un tipo di timestamp con un formato di timestamp. I formati di data personalizzati seguono i formati del modello datetime. Se non viene specificato, usa il valore predefinito yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
No |
Copia diretta in Delta Lake
Se l'archivio dati di origine e il formato soddisfano i criteri descritti in questa sezione, è possibile usare l'attività Copy per copiare direttamente dall'origine ad Azure Databricks Delta Lake. Il servizio controlla le impostazioni e, se i criteri seguenti non vengono soddisfatti, l'esecuzione dell'attività Copy non riesce:
Il servizio collegato di origine è archiviazione BLOB di Azure o Azure Data Lake Storage Gen2. Le credenziali dell'account devono essere preconfigurate nella configurazione del cluster di Azure Databricks. Per altre informazioni, vedere Prerequisiti.
Il formato di dati di origine è Parquet, testo delimitato o Avro con le configurazioni seguenti e punta a una cartella anziché a un file.
- Per il formato Parquet, il codec di compressione è none, snappy o gzip.
- Per il formato testo delimitato:
rowDelimiterè il valore predefinito, o qualsiasi singolo carattere.compressionpuò essere none, bzip2, gzip.encodingNameUTF-7 non è supportato.
- Per il formato Avro, il codec di compressione è none, deflate o snappy.
Nell'origine dell'attività Copy:
wildcardFileNamecontiene solo il carattere jolly*, ma non?ewildcardFolderNamenon è specificato.prefix,modifiedDateTimeStart,modifiedDateTimeEndeenablePartitionDiscoverynon sono specificati.additionalColumnsnon è specificato.
Nel mapping delle attività Copy la conversione dei tipi non è abilitata.
Esempio:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReadrQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Copia con staging in Delta Lake
Quando l'archivio dati di origine o il formato non corrisponde ai criteri di copia diretta, come indicato nell'ultima sezione, abilitare la copia con staging predefinita usando un'istanza di archiviazione di Azure temporanea. La funzionalità copia di staging assicura inoltre una migliore velocità effettiva, Il servizio converte automaticamente i dati in modo da soddisfare i requisiti di formato dei dati nell'archiviazione di staging, quindi carica i dati in Delta Lake da questa posizione. Infine, pulisce i dati temporanei dall'archiviazione. Per informazioni dettagliate sulla copia dei dati tramite staging, vedere Copia di staging.
Per usare questa funzionalità, creare un servizio collegato di archiviazione BLOB di Azure o un servizio collegato di Azure Data Lake Storage Gen2che fa riferimento all'account di archiviazione come staging provvisorio. Specificare quindi le proprietà enableStaging e stagingSettings nell'attività Copy.
Nota
Le credenziali dell'account di archiviazione di staging devono essere preconfigurate nella configurazione del cluster di Azure Databricks. Per altre informazioni, vedere Prerequisiti.
Esempio:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Monitoraggio
Viene fornita la stessa esperienza di monitoraggio dell'attività Copy come per altri connettori. Inoltre, poiché il caricamento dei dati da/a Delta Lake viene eseguito nel cluster di Azure Databricks, è anche possibile visualizzare i log dettagliati del cluster e monitorare le prestazioni.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
L'attività Lookup può restituire fino a 1000 righe. Se il set di risultati contiene più record, verranno restituite le prime 1000 righe.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati e formati supportati.