Copiare e trasformare i dati nel database SQL di Azure usando Azure Data Factory o Azure Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività di copia in Azure Data Factory o nelle pipeline di Azure Synapse per copiare dati da e nel database SQL di Azure e usare Flusso di dati per trasformare i dati nel database SQL di Azure. Per altre informazioni, vedere l'articolo introduttivo per Azure Data Factory o Azure Synapse Analytics.
Funzionalità supportate
Questo connettore di database SQL di Azure è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività di copia (origine/sink) | 7.3 | ✓ |
| Flusso di dati di mapping (origine/sink) | 1 | ✓ |
| Attività Lookup | 7.3 | ✓ |
| Attività GetMetadata | 7.3 | ✓ |
| Attività script | 7.3 | ✓ |
| Attività stored procedure | 7.3 | ✓ |
① Runtime di integrazione di Azure ② Runtime di integrazione self-hosted
Per l'attività Copy, questo connettore di database SQL di Azure supporta queste funzioni:
- La copia di dati tramite l'autenticazione SQL e l'autenticazione token dell'applicazione Microsoft Entra con un'entità servizio o identità gestite per le risorse di Azure.
- Come origine, recupero dati tramite una query SQL o una stored procedure. Per informazioni dettagliate, è anche possibile scegliere di eseguire la copia parallela da un'origine del database SQL di Azure. Per informazioni dettagliate, vedere la sezione Copia parallela dal database SQL.
- Come sink, la creazione automatica della tabella di destinazione se non esiste in base allo schema di origine; aggiunta di dati a una tabella o richiamo di una stored procedure con logica personalizzata durante la copia.
Se si usa il livello serverless del database SQL di Azure, si noti che, quando il server è in pausa, l'esecuzione dell'attività non riesce invece di attendere che la ripresa automatica sia pronta. È possibile aggiungere attività di ripetizione o concatenare attività aggiuntive per assicurarsi che il server sia attivo all'esecuzione effettiva.
Importante
Se si copiano dati usando il runtime di integrazione di Azure, configurare una regola del firewall a livello di server in modo che i servizi di Azure possano accedere al server. Se si copiano i dati tramite un runtime di integrazione self-hosted, configurare il firewall per consentire l'intervallo IP appropriato. Questo intervallo include l'indirizzo IP del computer usato per connettersi al database SQL di Azure.
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
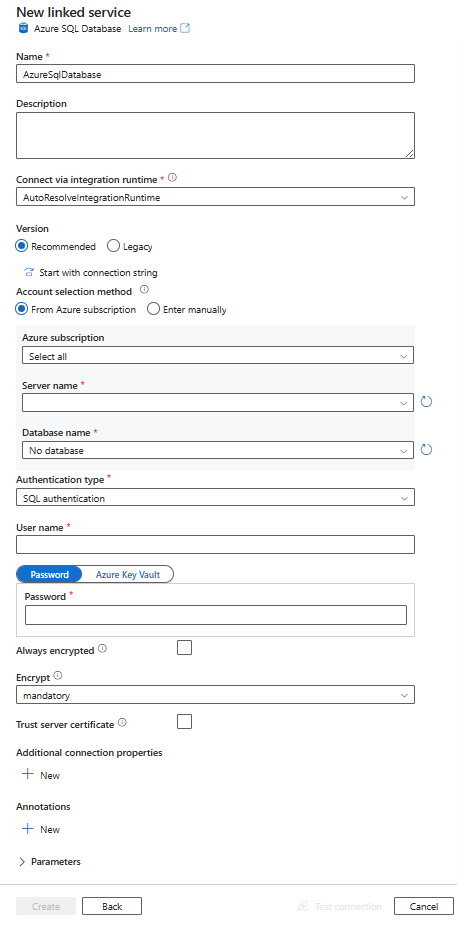
Creare un servizio collegato del database SQL di Azure usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato del database SQL di Azure nell'interfaccia utente del portale di Azure.
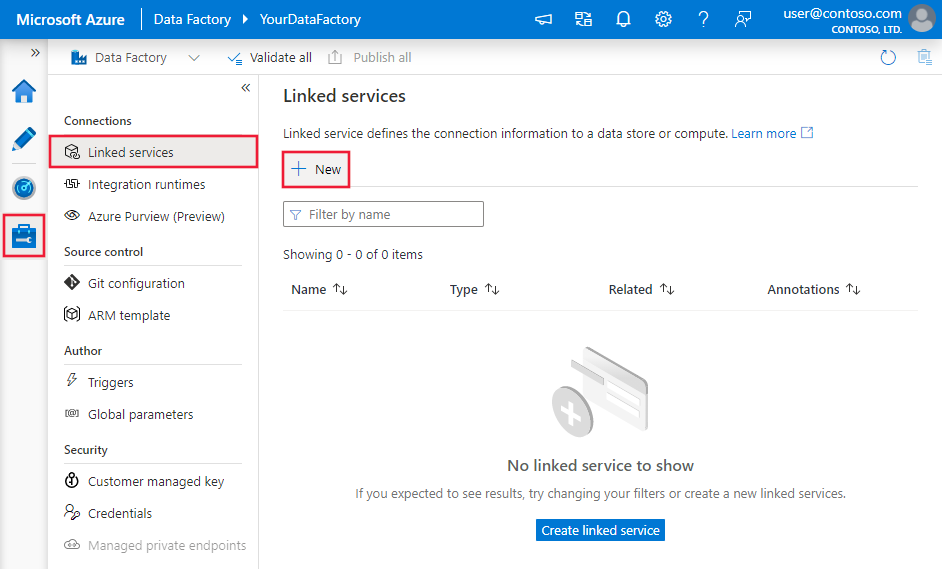
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare SQL e selezionare il connettore del database SQL di Azure.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità della pipeline di Azure Data Factory o Synapse specifiche di un connettore di database SQL di Azure.
Proprietà del servizio collegato
La versione consigliata del connettore di database SQL di Azure supporta TLS 1.3. Fare riferimento a questa sezione per aggiornare la versione del connettore di database SQL di Azure da quella Legacy. Per informazioni dettagliate sulla proprietà, vedere le sezioni corrispondenti.
Suggerimento
Se viene restituito l'errore con codice errore "UserErrorFailedToConnectToSqlServer" e un messaggio come "Il limite di sessioni per il database è XXX ed è stato raggiunto", aggiungere Pooling=false alla stringa di connessione e riprovare. Pooling=false è consigliato anche per la configurazione del servizio collegato di tipo SHIR (Self Hosted Integration Runtime). È possibile aggiungere pooling e altri parametri di connessione come nuovi nomi di parametri e valori nella sezione Proprietà di connessione aggiuntive del modulo di creazione del servizio collegato.
Versione consigliata
Queste proprietà generiche sono supportate per un servizio collegato del database SQL di Azure quando si applica la versione consigliata:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureSqlDatabase. | Sì |
| server | Nome o indirizzo di rete dell'istanza di SQL Server a cui connettersi. | Sì |
| database | Nome del database. | Sì |
| authenticationType | Tipo utilizzato per l'autenticazione. I valori consentiti sono SQL (impostazione predefinita), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Passare alla sezione relativa all'autenticazione in base a proprietà e prerequisiti specifici. | Sì |
| alwaysEncryptedSettings | Specificare le informazioni alwaysencryptedsettings necessarie per consentire ad Always Encrypted di proteggere i dati sensibili archiviati in SQL Server usando un'identità gestita o un'entità servizio. Per altre informazioni, vedere l'esempio JSON che segue la tabella e la sezione Uso di Always Encrypted. Se non specificato, l'impostazione predefinita per Always Encrypted è disabilitata. | No |
| crittografare | Indicare se la crittografia TLS è necessaria per tutti i dati inviati tra client e server. Opzioni: obbligatorio (per true, impostazione predefinita)/opzionale (per false)/strict. | No |
| trustServerCertificate | Indicare se il canale verrà crittografato bypassando la catena di certificati per convalidare l'attendibilità. | No |
| hostNameInCertificate | Nome host da usare quando viene convalidato il certificato del server per la connessione. Se non è specificato, per la convalida del certificato viene utilizzato il nome del server. | No |
| connectVia | Questo runtime di integrazione viene usato per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Per altre proprietà di connessione, vedere la tabella seguente:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| applicationIntent | Il tipo di carico di lavoro dell'applicazione in caso di connessione a un server. I valori consentiti sono ReadOnly e ReadWrite. |
No |
| connectTimeout | Tempo di attesa (in secondi) per una connessione al server prima della conclusione del tentativo e la generazione di un errore. | No |
| connectRetryCount | Numero di riconnessioni tentate dopo l'identificazione di un errore di connessione inattiva. Il valore deve essere un numero intero compreso tra 0 e 255. | No |
| connectRetryInterval | Intervallo di tempo, (espresso in secondi) tra ogni tentativo di riconnessione dopo l'identificazione di un errore di connessione inattiva. Il valore deve essere un numero intero compreso tra 1 e 60. | No |
| loadBalanceTimeout | Tempo minimo (in secondi) in cui la connessione rimane attiva nel pool di connessione prima di essere eliminata definitivamente. | No |
| commandTimeout | Tempo di attesa predefinito (in secondi) prima della conclusione del tentativo di esecuzione di un comando e della generazione di un errore. | No |
| integratedSecurity | I valori consentiti sono true o false. Quando si specifica false, indicare se userName e password sono specificati nella connessione. Quando si specifica true, indica se le credenziali dell'account di Windows corrente vengono usate per l'autenticazione. |
No |
| failoverPartner | Nome o indirizzo di rete del server partner a cui connettersi se il server primario è inattivo. | No |
| maxPoolSize | Numero massimo di connessioni consentite nel pool di connessioni per la connessione specifica. | No |
| minPoolSize | Numero minimo di connessioni consentite nel pool di connessioni per la connessione specifica. | No |
| multipleActiveResultSets | I valori consentiti sono true o false. Quando si specifica true, un'applicazione può gestire più insiemi di risultati attivi (MARS). Quando si specifica false, un'applicazione deve prima elaborare o annullare tutti gli insiemi di risultati da un batch per poter eseguire altri batch in tale connessione. |
No |
| multiSubnetFailover | I valori consentiti sono true o false. Se l'applicazione si connette a un gruppo di disponibilità (AG) AlwaysOn in subnet diverse, l'impostazione di questa proprietà su true garantisce una maggiore velocità di rilevamento e connessione al server attualmente attivo. |
No |
| packetSize | Dimensioni in byte dei pacchetti di rete usati per comunicare con un'istanza del server. | No |
| pooling | I valori consentiti sono true o false. Quando si specifica true, la connessione sarà in pool. Quando si specifica false, la connessione verrà aperta in modo esplicito ogni volta che è richiesta la connessione. |
No |
Autenticazione SQL
Per usare l’autenticazione SQL, oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| userName | Nome utente utilizzato per connettersi al server. | Sì |
| password | Password per il nome utente. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro. In alternativa, fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
Esempio: uso dell'autenticazione di SQL
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: password in Azure Key Vault
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: Usare Always Encrypted
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'entità servizio
Per usare l'autenticazione dell'entità servizio, oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| servicePrincipalId | Specificare l'ID client dell'applicazione. | Sì |
| servicePrincipalCredential | Credenziali dell'entità servizio. Specificare la chiave dell'applicazione. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro, oppure fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
| tenant | Specificare le informazioni sul tenant, ad esempio nome di dominio o ID tenant, in cui si trova l'applicazione. Recuperarlo passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| azureCloudType | Per l'autenticazione dell'entità servizio, specificare il tipo di ambiente cloud di Azure in cui è registrata l'applicazione Microsoft Entra. I valori consentiti sono AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Per impostazione predefinita, viene usato l'ambiente cloud della data factory o della pipeline Synapse. |
No |
È anche necessario seguire la procedura seguente:
Creare un'applicazione Microsoft Entra dal portale di Azure. Prendere nota del nome dell'applicazione e dei valori seguenti che definiscono il servizio collegato:
- ID applicazione
- Chiave applicazione
- ID tenant
Effettuare il provisioning di un amministratore di Microsoft Entra per il server nel portale di Azure, se non è già stato fatto. L'amministratore di Microsoft Entra deve essere un utente di Microsoft Entra o un gruppo Microsoft Entra, ma non può essere un'entità servizio. Questo passaggio viene eseguito in modo che, nel passaggio successivo, sia possibile usare un'identità di Microsoft Entra per creare un utente di database indipendente per l'entità servizio.
Creare utenti del database indipendente per l'entità servizio. Connettersi al database da o a cui si desidera copiare dati usando strumenti come SQL Server Management Studio, con un'identità di Microsoft Entra che dispone almeno dell'autorizzazione ALTER ANY USER. Eseguire il codice T-SQL seguente:
CREATE USER [your application name] FROM EXTERNAL PROVIDER;Concedere all'entità servizio le autorizzazioni necessarie, come si fa di norma per gli utenti SQL o altri utenti. Eseguire il codice seguente. Per altre opzioni, vedere questo documento.
ALTER ROLE [role name] ADD MEMBER [your application name];Configurare un servizio collegato database SQL di Azure in un'area di lavoro di Azure Data Factory o Synapse.
Esempio di servizio collegato tramite l'autenticazione basata su entità servizio
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"hostNameInCertificate": "<host name>",
"authenticationType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'identità gestita assegnata dal sistema
Una data factory o un'area di lavoro di Synapse può essere associata a un'identità gestita assegnata dal sistema per le risorse di Azure che rappresenta il servizio durante l'autenticazione ad altre risorse in Azure. È possibile usare questa identità gestita per l'autenticazione del database SQL di Azure. L'area di lavoro designata factory o Synapse può accedere e copiare dati da o nel database usando questa identità.
Per usare l'autenticazione dell'identità gestita assegnata dal sistema, specificare le proprietà generiche descritte nella sezione precedente e seguire questa procedura.
Effettuare il provisioning di un amministratore di Microsoft Entra per il server nel portale di Azure, se non è già stato fatto. L'amministratore di Microsoft Entra può essere un utente di Microsoft Entra o un gruppo Microsoft Entra. Se si concede al gruppo con identità gestita un ruolo di amministratore, ignorare i passaggi 3 e 4. L'amministratore ha accesso completo al database.
Creare utenti di database indipendenti per l'identità gestita. Connettersi al database da o a cui si desidera copiare dati usando strumenti come SQL Server Management Studio, con un'identità di Microsoft Entra che dispone almeno dell'autorizzazione ALTER ANY USER. Eseguire il codice T-SQL seguente:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Concedere le autorizzazioni necessarie per l'identità gestita, come si fa normalmente per gli utenti SQL e altri utenti. Eseguire il codice seguente. Per altre opzioni, vedere questo documento.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Configurare un servizio collegato al database SQL di Azure.
Esempio
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione dell'identità gestita assegnata dall'utente
Una data factory o un'area di lavoro di Synapse può essere associata a un'identità gestita assegnata dall'utente che rappresenta il servizio durante l'autenticazione ad altre risorse in Azure. È possibile usare questa identità gestita per l'autenticazione del database SQL di Azure. L'area di lavoro designata factory o Synapse può accedere e copiare dati da o nel database usando questa identità.
Per usare l'autenticazione dell'identità gestita assegnata dall'utente, oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| credentials | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
È anche necessario seguire la procedura seguente:
Effettuare il provisioning di un amministratore di Microsoft Entra per il server nel portale di Azure, se non è già stato fatto. L'amministratore di Microsoft Entra può essere un utente di Microsoft Entra o un gruppo Microsoft Entra. Se si concede al gruppo un ruolo di amministratore con identità gestita assegnata dall'utente, ignorare i passaggi 3. L'amministratore ha accesso completo al database.
Creare utenti di database indipendenti per l'identità gestita assegnata dall'utente. Connettersi al database da o a cui si desidera copiare dati usando strumenti come SQL Server Management Studio, con un'identità di Microsoft Entra che dispone almeno dell'autorizzazione ALTER ANY USER. Eseguire il codice T-SQL seguente:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Creare una o più identità gestite assegnate dall'utente e concedere le autorizzazioni necessarie per l'identità gestita assegnata dall'utente, come normalmente si fa per utenti SQL e altri utenti. Eseguire il codice seguente. Per altre opzioni, vedere questo documento.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Assegnare una o più identità gestite assegnate dall'utente alla data factory e creare le credenziali per ogni identità gestita assegnata dall'utente.
Configurare un servizio collegato al database SQL di Azure.
Esempio
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versione legacy
Queste proprietà generiche sono supportate per un servizio collegato del database SQL di Azure quando si applica la versione legacy:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureSqlDatabase. | Sì |
| connectionString | Specifica le informazioni necessarie per connettersi all'istanza del database SQL di Azure per la proprietà connectionString. È anche possibile inserire una password o una chiave dell'entità servizio in Azure Key Vault. Se si tratta dell'autenticazione SQL, eseguire il pull della configurazione password dalla stringa di connessione. Per altre informazioni, vedere Memorizzare credenziali in Azure Key Vault. |
Sì |
| alwaysEncryptedSettings | Specificare le informazioni alwaysencryptedsettings necessarie per consentire ad Always Encrypted di proteggere i dati sensibili archiviati in SQL Server usando un'identità gestita o un'entità servizio. Per altre informazioni, vedere la sezione Uso di Always Encrypted. Se non specificato, l'impostazione predefinita per Always Encrypted è disabilitata. | No |
| connectVia | Questo runtime di integrazione viene usato per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Per altri tipi di autenticazione, vedere le sezioni seguenti relative rispettivamente a proprietà e prerequisiti specifici:
- Autenticazione SQL per la versione legacy
- Autenticazione dell'entità servizio per la versione legacy
- Autenticazione dell'identità gestita assegnata dal sistema per la versione legacy
- Autenticazione dell'identità gestita assegnata dall'utente per la versione legacy
Autenticazione SQL per la versione legacy
Per usare l'autenticazione SQL, specificare le proprietà generiche descritte nella sezione precedente.
Autenticazione dell'entità servizio per la versione legacy
Per usare l'autenticazione dell'entità servizio, oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| servicePrincipalId | Specificare l'ID client dell'applicazione. | Sì |
| servicePrincipalKey | Specificare la chiave dell'applicazione. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro, oppure fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
| tenant | Specificare le informazioni sul tenant, ad esempio nome di dominio o ID tenant, in cui si trova l'applicazione. Recuperarlo passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| azureCloudType | Per l'autenticazione dell'entità servizio, specificare il tipo di ambiente cloud di Azure in cui è registrata l'applicazione Microsoft Entra. I valori consentiti sono AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Per impostazione predefinita, viene usato l'ambiente cloud della data factory o della pipeline Synapse. |
No |
È anche necessario seguire la procedura descritta in Autenticazione dell'entità servizio per concedere l'autorizzazione corrispondente.
Autenticazione dell'identità gestita assegnata dal sistema per la versione legacy
Per usare l'autenticazione dell'identità gestita assegnata dal sistema, seguire lo stesso passaggio per la versione consigliata in Autenticazione identità gestita assegnata dal sistema.
Autenticazione dell'identità gestita assegnata dall'utente per la versione legacy
Per usare l'autenticazione dell'identità gestita assegnata dall'utente, seguire lo stesso passaggio per la versione consigliata in Autenticazione identità gestita assegnata dall'utente.
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati.
Per il set di dati del database SQL di Azure sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su AzureSqlTable. | Sì |
| schema | Nome dello schema. | No per l'origine, Sì per il sink |
| table | Nome della tabella/vista. | No per l'origine, Sì per il sink |
| tableName | Nome della tabella/vista con schema. Questa proprietà è supportata per garantire la compatibilità con le versioni precedenti. Per i nuovi carichi di lavoro, usare schema e table. |
No per l'origine, Sì per il sink |
Esempio di proprietà dei set di dati
{
"name": "AzureSQLDbDataset",
"properties":
{
"type": "AzureSqlTable",
"linkedServiceName": {
"referenceName": "<Azure SQL Database linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink del database SQL di Azure.
Database SQL di Azure come origine
Suggerimento
Per caricare i dati dal database SQL di Azure in modo efficiente usando il partizionamento dei dati, vedere Copia parallela dal database SQL.
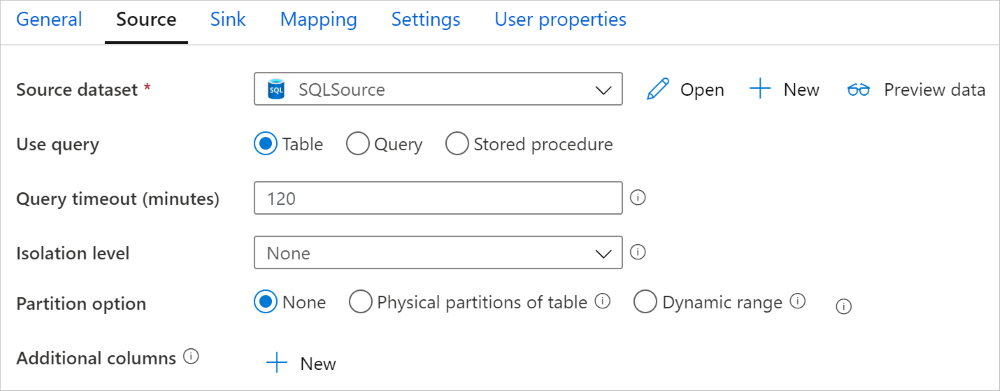
Per copiare dati dal database SQL di Azure, nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà tipo dell'origine dell'attività di copia deve essere impostata su AzureSqlSource. Il tipo "SqlSource" è ancora supportato per la compatibilità con le versioni precedenti. | Sì |
| sqlReaderQuery | Questa proprietà usa la query SQL personalizzata per leggere i dati. Un esempio è select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Nome della stored procedure che legge i dati dalla tabella di origine. L'ultima istruzione SQL deve essere un'istruzione SELECT nella stored procedure. | No |
| storedProcedureParameters | Parametri per la stored procedure. I valori consentiti sono coppie nome-valore. I nomi e le maiuscole/minuscole dei parametri devono corrispondere ai nomi e alle maiuscole/minuscole dei parametri della stored procedure. |
No |
| isolationLevel | Specifica il comportamento di blocco della transazione per l'origine SQL. Valori consentiti: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable e Snapshot. Se non specificato, viene utilizzato il livello di isolamento predefinito del database. Per altre informazioni dettagliate, vedere questo documento. | No |
| partitionOptions | Specifica le opzioni di partizionamento dei dati usate per caricare dati dal database SQL di Azure. Valori consentiti: None (predefinito), PhysicalPartitionsOfTable e DynamicRange. Quando è abilitata un'opzione di partizione (diversa da None), il grado di parallelismo per caricare simultaneamente i dati da un database SQL di Azure è controllato dall'impostazione parallelCopies nell'attività di copia. |
No |
| partitionSettings | Specifica il gruppo di impostazioni per il partizionamento dei dati. Applicare quando l'opzione di partizione non è None. |
No |
In partitionSettings: |
||
| partitionColumnName | Specificare il nome della colonna di origine nel tipo integer o date/datetime type (int, smallint, bigint, date, smalldatetime, datetime, datetime2 o datetimeoffset) che verrà usata nel partizionamento per intervalli per la copia parallela. Se non è specificato, l’indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione.Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?DfDynamicRangePartitionCondition nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela dal database SQL. |
No |
| partitionUpperBound | Valore massimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Si applica quando l'opzione di partizione è DynamicRange. Per un esempio, vedere la sezione Copia parallela dal database SQL. |
No |
| partitionLowerBound | Valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Si applica quando l'opzione di partizione è DynamicRange. Per un esempio, vedere la sezione Copia parallela dal database SQL. |
No |
Tenere presente quanto segue:
- Se la proprietà sqlReaderQuery è specificata per AzureSqlSource, l'attività di copia esegue questa query sull'origine del database SQL di Azure per ottenere i dati. In alternativa, è possibile specificare una stored procedure indicando i parametri sqlReaderStoredProcedureName e storedProcedureParameters, se la stored procedure accetta parametri.
- Quando si usa la stored procedure nell'origine per recuperare i dati, tenere presente che se la stored procedure è progettata come restituzione di uno schema diverso quando viene passato un valore di parametro diverso, è possibile che si verifichi un errore o un risultato imprevisto durante l'importazione dello schema dall'interfaccia utente o quando si copiano dati nel database SQL con la creazione automatica della tabella.
Esempio di query SQL
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Esempio di stored procedure
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definizione della stored procedure
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Database SQL di Azure come sink
Suggerimento
Altre informazioni sui comportamenti di scrittura, le configurazioni e le procedure consigliate supportate sono disponibili in Procedure consigliate per il caricamento dei dati nel database SQL di Azure.
Per copiare i dati nel database SQL di Azure, nella sezione sinkdell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del sink dell'attività di copia deve essere impostata su AzureSqlSink. Il tipo "SqlSink" è ancora supportato per la compatibilità con le versioni precedenti. | Sì |
| preCopyScript | Specificare una query SQL per l'attività di copia da eseguire prima di scrivere i dati nel database SQL di Azure. Viene richiamata solo una volta per ogni esecuzione della copia. Usare questa proprietà per pulire i dati precaricati. | No |
| tableOption | Specifica se creare automaticamente la tabella sink, se non esistente, in base allo schema di origine. La creazione automatica della tabella non è supportata quando il sink specifica la stored procedure. I valori consentiti sono: none (impostazione predefinita), autoCreate. |
No |
| sqlWriterStoredProcedureName | Il nome della stored procedure che definisce come applicare i dati di origine in una tabella di destinazione. Questa stored procedure viene richiamata per batch. Per operazioni che vengono eseguite una sola volta e che non riguardano dati di origine, ad esempio un'eliminazione o un troncamento, usare la proprietà preCopyScript.Vedere l’esempio in Richiamare una stored procedure da un sink SQL. |
No |
| storedProcedureTableTypeParameterName | Nome del parametro del tipo di tabella specificato nella stored procedure. | No |
| sqlWriterTableType | Tipo di tabella da usare nella stored procedure. Nel corso dell'attività di copia, i dati spostati vengono resi disponibili in una tabella temporanea di questo tipo. Il codice della stored procedure può quindi unire i dati di cui è in corso la copia con i dati esistenti. | No |
| storedProcedureParameters | Parametri per la stored procedure. I valori consentiti sono coppie nome-valore. I nomi e le maiuscole e minuscole dei parametri devono corrispondere ai nomi e alle maiuscole e minuscole dei parametri della stored procedure. |
No |
| writeBatchSize | Numero di righe da inserire nella tabella SQL per batch. Il valore consentito è integer (numero di righe). Per impostazione predefinita, il servizio determina in modo dinamico le dimensioni appropriate del batch in base alle dimensioni della riga. |
No |
| writeBatchTimeout | Tempo di attesa per il completamento dell'operazione insert, upsert e stored procedure prima del timeout. I valori consentiti sono relativi all'intervallo di tempo. Esempio: "00:30:00" per 30 minuti. Se non si specifica alcun valore, viene utilizzato il timeout predefinito: "00:30:00". |
No |
| disableMetricsCollection | Il servizio raccoglie metriche come le DTU del database SQL di Azure per l'ottimizzazione delle prestazioni di copia e le raccomandazioni, che introduce un accesso al database master aggiuntivo. Se questo comportamento non è desiderato, specificare true per disattivarlo. |
No (il valore predefinito è false) |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
| WriteBehavior | Specificare il comportamento di scrittura per l'attività di copia per caricare i dati nel database SQL di Azure. Valori consentiti: Insert e Upsert. Per impostazione predefinita, il servizio usa l’operazione insert per caricare dati. |
No |
| upsertSettings | Specificare il gruppo di impostazioni per il comportamento di scrittura. Applicare quando l'opzione WriteBehavior è Upsert. |
No |
In upsertSettings: |
||
| useTempDB | Specificare se utilizzare la tabella temporanea globale o quella fisica come tabella provvisoria per l’operazione upsert. Per impostazione predefinita, il servizio usa una tabella temporanea globale come tabella provvisoria. il valore è true. |
No |
| interimSchemaName | Specificare lo schema provvisorio per la creazione di una tabella provvisoria se viene utilizzata la tabella fisica. Nota: l'utente deve disporre dell'autorizzazione per la creazione e l'eliminazione della tabella. Per impostazione predefinita, la tabella provvisoria condividerà lo stesso schema della tabella sink. Applicare quando l'opzione useTempDB è False. |
No |
| keys | Specificare i nomi colonna per l'identificazione univoca delle righe. È possibile usare una singola chiave o una serie di chiavi. Se non specificato, viene usata la chiave primaria. | No |
Esempio 1: accodare dati
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Esempio 2: richiamare una stored procedure durante la copia
Per altre informazioni, vedere Richiamare una stored procedure da un sink SQL.
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Esempio 3: Upsert dei dati
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Copia parallela dal database SQL
Il connettore di database SQL di Azure nell'attività di copia fornisce il partizionamento dei dati predefinito per copiare i dati in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.
Quando si abilita la copia partizionata, l'attività di copia esegue query parallele sull'origine del database SQL di Azure per caricare i dati in base alle partizioni. Il grado di parallelismo è controllato dall'impostazione parallelCopies sull'attività di copia. Se, ad esempio, si imposta parallelCopies su quattro, il servizio simultaneamente genera ed esegue quattro query in base all'opzione partizione specificata e alle impostazioni, e ogni query recupera una porzione di dati dal database SQL di Azure.
Si consiglia di abilitare la copia parallela con il partizionamento dei dati, specialmente quando si caricano grandi quantità di dati dal database SQL di Azure. Di seguito sono riportate le configurazioni consigliate per i diversi scenari: Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come file multipli (specificare solo il nome della cartella); in tal caso, le prestazioni risultano migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, con partizioni fisiche. | Opzione di partizione: partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente le partizioni fisiche e copia i dati in base alle partizioni. Per controllare se la tabella contenga o meno una partizione fisica, è possibile fare riferimento a questa query. |
| Caricamento completo da una tabella di grandi dimensioni, senza partizioni fisiche, con una colonna integer o datetime per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Colonna partizione (facoltativo): specificare la colonna usata per il partizionamento dei dati. Se non specificato, viene utilizzata la colonna di indice o chiave primaria. Limite superiore partizione e limite inferiore partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Non si tratta di filtrare le righe nella tabella; tutte le righe della tabella verranno partizionate e copiate. Se non è specificato, l'attività di copia rileva automaticamente i valori. Ad esempio, se “ID” della colonna partizione include valori compresi tra 1 e 100 e si imposta come limite inferiore 20 e come limite superiore 80, con copia parallela 4, il servizio recupera i dati in base a 4 partizioni - ID nell'intervallo < = 20, [21, 50], [51, 80] e > = 81 rispettivamente. |
| Caricamento di notevoli quantità di dati utilizzando una query personalizzata, senza partizioni fisiche, con una colonna integer o date/datetime per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. Limite superiore partizione e limite inferiore partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Ciò non è utile a filtrare le righe nella tabella; tutte le righe del risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Ad esempio, se la colonna di partizione "ID" include valori compresi tra 1 e 100 e si imposta il limite inferiore su 20 e il limite superiore su 80, con copia parallela come 4 il servizio recupera i dati per 4 partizioni - ID nell'intervallo <=20, [21, 50], [51, 80], e >=81, rispettivamente. Di seguito sono riportate altre query di esempio per diversi scenari: 1. Eseguire una query sull'intera tabella: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Eseguire una query da una tabella con selezione colonne e filtri aggiuntivi per la clausola where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query con sottoquery: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query con partizione nella sottoquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedure consigliate per il caricamento di dati con opzione partizione:
- Scegliere una colonna distintiva come colonna partizione (ad esempio, chiave primaria o chiave univoca) per evitare l'asimmetria dei dati.
- Se la tabella include una partizione predefinita, usare l'opzione di partizione "Partizioni fisiche della tabella" per ottenere prestazioni migliori.
- Se si usa Azure Integration Runtime per copiare i dati, è possibile impostare "Unità di integrazione dati (DIU)" (>4) perché utilizzi più risorse di calcolo. Controllare gli scenari applicabili.
- “Grado di parallelismo copia” controlla i numeri partizione; se si imposta per questo numero un valore troppo grande, le prestazioni potrebbero talvolta risentirne. È preferibile impostare questo numero come (DIU o numero di nodi del runtime di integrazione self-hosted) * (2-4).
Esempio: caricamento completo da una tabella di grandi dimensioni con partizioni fisiche
"source": {
"type": "AzureSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Esempio: query con partizione a intervalli dinamici
"source": {
"type": "AzureSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Query di esempio per controllare la partizione fisica
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Se la tabella ha una partizione fisica, viene visualizzato "HasPartition" come "sì", come illustrato di seguito.

Procedura consigliata per il caricamento dei dati nel database SQL di Azure
Quando si copiano dati nel database SQL di Azure, potrebbe essere necessario un comportamento di scrittura diverso:
- Accodamento: i dati di origine hanno solo nuovi record.
- Upsert: i dati di origine hanno sia inserimenti che aggiornamenti.
- Sovrascrittura: si vuole ricaricare un'intera tabella delle dimensioni ogni volta.
- Scrittura con logica personalizzata: è necessaria un'elaborazione aggiuntiva prima dell'inserimento finale nella tabella di destinazione.
Fare riferimento alle rispettive sezioni su come configurare nel servizio e nelle procedure consigliate.
Accodare dati
L'aggiunta dei dati è il comportamento predefinito di questo connettore sink del database SQL di Azure. Il servizio esegue un inserimento bulk per scrivere nella tabella in modo efficiente. È possibile configurare opportunamente l'origine e il sink nell'attività di copia.
Eseguire l'upsert dei dati
L'attività di copia ora supporta il caricamento nativo dei dati in una tabella temporanea del database e quindi l'aggiornamento dei dati nella tabella sink, se la chiave esiste, altrimenti inserisce nuovi dati. Per altre informazioni sulle impostazioni upsert nelle attività di copia, vedere Database SQL di Azure come sink.
Sovrascrivere l'intera tabella
È possibile configurare la proprietà preCopyScript nel sink dell'attività di copia. In questo caso, per ogni attività di copia eseguita, il servizio esegue prima lo script. Quindi, esegue la copia per inserire i dati. Ad esempio, per sovrascrivere l'intera tabella con i dati più recenti, specificare uno script per eliminare tutti i record prima del caricamento bulk dei nuovi dati dall'origine.
Scrivere dati con logica personalizzata
I passaggi per scrivere i dati con una logica personalizzata sono simili a quelli descritti nella sezione Upsert dei dati. Quando è necessario applicare un'elaborazione aggiuntiva prima dell'inserimento finale dei dati di origine nella tabella di destinazione, è possibile caricare in una tabella di staging, quindi richiamare un'attività stored procedure oppure richiamare una stored procedure nel sink dell'attività di copia per applicare i dati o usare il flusso di dati di mapping.
Richiamare una stored procedure da un sink SQL
Quando si copiano dati in un database SQL di Azure, è anche possibile configurare e richiamare una stored procedure specificata dall'utente con parametri aggiuntivi in ogni batch della tabella di origine. La funzionalità di stored procedure sfrutta i parametri valutati a livello di tabella.
È possibile usare una stored procedure quando non si possono usare i meccanismi di copia predefiniti. Ad esempio, quando si desidera applicare un'elaborazione aggiuntiva prima dell'inserimento finale dei dati di origine nella tabella di destinazione. Alcuni esempi di elaborazione extra sono l’unione di colonne, la ricerca di valori aggiuntivi e l’inserimento in più di una tabella.
L'esempio seguente illustra come usare una stored procedure per eseguire un'operazione di upsert in una tabella del database SQL di Azure. Si presuppone che i dati di input e la tabella Marketing del sink abbiano tre colonne: ProfileID, Stato e Categoria. Eseguire l'operazione upsert nella colonna ProfileID e applicarla solo a una categoria specifica denominata “ProductA”.
Nel database, definire il tipo di tabella con lo stesso nome di sqlWriterTableType. Lo schema del tipo di tabella è identico allo schema restituito dai dati di input.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Nel database, definire la stored procedure con lo stesso nome di sqlWriterStoredProcedureName. che gestisce i dati di input dell'origine specificata e li unisce nella tabella di output. Il nome del parametro del tipo di tabella nella stored procedure deve essere identico al valore tableName definito nel set di dati.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDNella pipeline di Azure Data Factory o Synapse definire la sezione sink SQL nell'attività di copia come indicato di seguito:
"sink": { "type": "AzureSqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Quando si scrivono dati nel database SQL di Azure usando la stored procedure, il sink suddivide i dati di origine in mini batch e quindi esegue l'inserimento, in modo che la query aggiuntiva nella stored procedure possa essere eseguita più volte. Se è presente la query per l'esecuzione dell'attività di copia prima di scrivere dati nel database SQL di Azure, non è consigliabile aggiungerla alla stored procedure, aggiungerla nella casella Script di pre-copia.
Proprietà del flusso di dati per mapping
Durante la trasformazione dei dati in un flusso di dati per mapping è possibile leggere e scrivere in tabelle dal database SQL di Azure. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping.
Trasformazione origine
Le impostazioni specifiche del database SQL di Azure sono disponibili nella scheda Source Options (Opzioni origine) della trasformazione origine.
Input: specificare se l'origine deve puntare a una tabella (equivalente di Select * from <table-name>) oppure immettere una query SQL personalizzata.
Query: se si seleziona Query nel campo di input, immettere una query SQL per l'origine. Questa impostazione esegue l'override di qualsiasi tabella scelta nel set di dati. Le clausole Order By non sono supportate, ma è possibile impostare un'istruzione SELECT FROM completa. È possibile usare anche funzioni di tabella definite dall'utente. select * from udfGetData() è un UDF in SQL che restituisce una tabella. Questa query produrrà una tabella di origine che può essere usata nel flusso di dati. L'uso di query è anche un ottimo modo per ridurre le righe per i test o le ricerche.
Suggerimento
L’espressione di tabella comune (CTE) in SQL non è supportata nella modalità query del flusso di dati per mapping, poiché il prerequisito dell'uso di questa modalità consiste nel fatto che le query possono essere usate nella clausola FROM della query SQL, ma non è possibile eseguire questa operazione con CTE. L’uso di CTE richiede la creazione di una stored procedure tramite la query seguente:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Usare quindi la modalità Stored procedure nella trasformazione di origine del flusso di dati di mapping e impostare @query come l'esempio with CTE as (select 'test' as a) select * from CTE. A questo punto, l’uso di CTE è possibile come previsto.
Stored procedure: scegliere questa opzione se si desidera generare una proiezione e i dati di origine da una stored procedure eseguita dal database di origine. È possibile digitare lo schema, il nome della routine e i parametri oppure fare clic su Aggiorna per chiedere al servizio di individuare gli schemi e i nomi delle routine. È quindi possibile fare clic su Importa per importare tutti i parametri di routine usando il modulo @paraName.
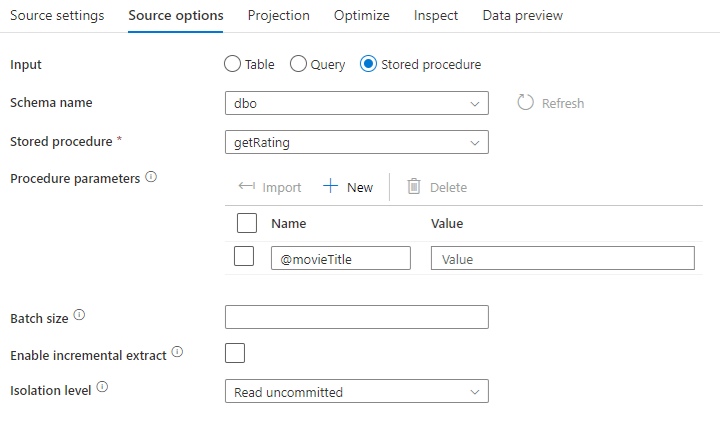
- Esempio SQL:
Select * from MyTable where customerId > 1000 and customerId < 2000 - Esempio SQL con parametri:
"select * from {$tablename} where orderyear > {$year}"
Dimensione batch: Immettere una dimensione batch per suddividere dati di grandi dimensioni in letture.
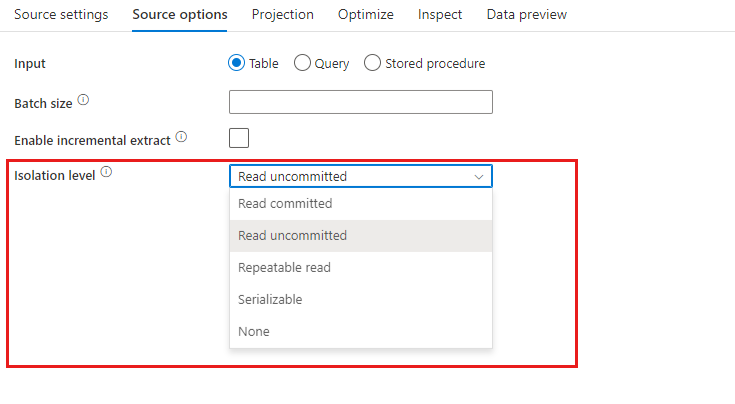
Livello di isolamento: il valore predefinito per le origini SQL nel flusso di dati per mapping è Read Uncommitted. È possibile cambiare il livello di isolamento in uno dei valori seguenti:
- Read Committed
- Read Uncommitted
- Repeatable Read
- Serializable
- None (ignora il livello di isolamento)
Abilita estrazione incrementale: usare questa opzione per indicare ad Azure Data Factory di elaborare solo le righe modificate dall'ultima esecuzione della pipeline. Per abilitare l'estrazione incrementale con deriva dello schema, scegliere tabelle basate su colonne incrementali/filigrane anziché tabelle abilitate per Native Change Data Capture.
Colonna incrementale: quando si usa la funzionalità di estrazione incrementale, è necessario scegliere la colonna data/ora o numerica da usare come filigrana nella tabella di origine.
Abilita Change Data Capture (anteprima) nativa: usare questa opzione per indicare ad ADF di elaborare solo i dati differenziali acquisiti dalla tecnologia SQL Change Data Capture dall'ultima esecuzione della pipeline. Con questa opzione, i dati delta che includono inserimento, aggiornamento ed eliminazione di righe verranno caricati automaticamente senza necessità di una colonna incrementale. È necessario abilitare Change Data Capture nel database SQL di Azure prima di usare questa opzione in Azure Data Factory. Per altre informazioni su questa opzione in Azure Data Factory, vedere acquisizione di dati delle modifiche nativa.
Iniziare a leggere dall'inizio: l'impostazione di questa opzione con l'estrazione incrementale indicherà ad ADF di leggere tutte le righe alla prima esecuzione di una pipeline con l'estrazione incrementale attivata.
Trasformazione sink
Le impostazioni specifiche del database SQL di Azure sono disponibili nella scheda Impostazioni della trasformazione sink.
Metodo update: determina le operazioni consentite nella destinazione del database. Per impostazione predefinita, sono consentiti solo gli inserimenti. Per eseguire operazioni di aggiornamento, upsert o eliminazione di righe, è necessaria una trasformazione alter-row che applichi alle righe i tag corrispondenti alle azioni. Per le operazioni di aggiornamento, upsert ed eliminazione è necessario impostare una o più colonne chiave per determinare quale riga modificare.
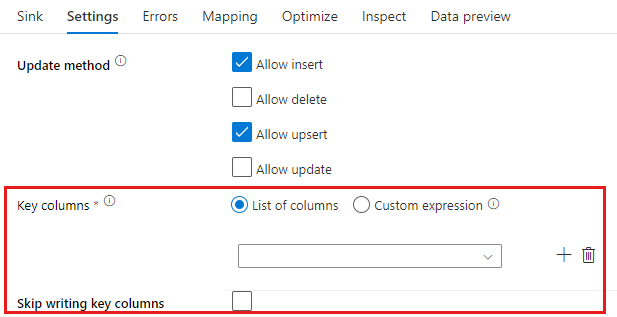
Il nome della colonna selezionato come chiave verrà usato dal servizio come parte dell'aggiornamento successivo, upsert, eliminazione. Pertanto, è necessario selezionare una colonna esistente nel mapping di sink. Se si desidera non scrivere il valore in questa colonna chiave, fare clic su "Ignora la scrittura di colonne chiave".
È possibile parametrizzare la colonna chiave usata qui per aggiornare la tabella di database SQL di Azure di destinazione. Se sono presenti più colonne per una chiave composita, fare clic su "Espressione personalizzata" e sarà possibile aggiungere contenuto dinamico usando il linguaggio delle espressioni del flusso di dati, che può includere una matrice di stringhe con nomi di colonna per una chiave composita.
Azione tabella: determina se ricreare o rimuovere tutte le righe dalla tabella di destinazione prima della scrittura.
- Nessuna: non verrà eseguita alcuna azione sulla tabella.
- Ricrea: la tabella verrà eliminata e ricreata. Questa opzione è obbligatoria se si crea una nuova tabella in modo dinamico.
- Tronca: verranno rimosse tutte le righe della tabella di destinazione.
Dimensioni batch: controlla il numero di righe scritte in ogni bucket. Dimensioni batch più grandi migliorano l'ottimizzazione della compressione e della memoria, ma rischiano di causare eccezioni di memoria insufficiente durante la memorizzazione nella cache dei dati.
Usare TempDB: per impostazione predefinita, il servizio userà una tabella temporanea globale per archiviare i dati come parte del processo di caricamento. In alternativa, è possibile deselezionare l'opzione "Usa TempDB" e chiedere al servizio di archiviare la tabella di archiviazione temporanea in un database utente situato nel database utilizzato per questo Sink.

Script Pre e Post SQL: immettere script SQL a più righe che verranno eseguiti prima (pre-elaborazione) e dopo (post-elaborazione) la scrittura dei dati nel database sink
Suggerimento
- È consigliabile suddividere singoli script batch con più comandi in più batch.
- Possono essere eseguite come parte di un batch solo le istruzioni DDL (Data Definition Language) e DML (Data Manipulation Language) che restituiscono un semplice conteggio di aggiornamento. Per altre informazioni, vedere Esecuzione di operazioni batch
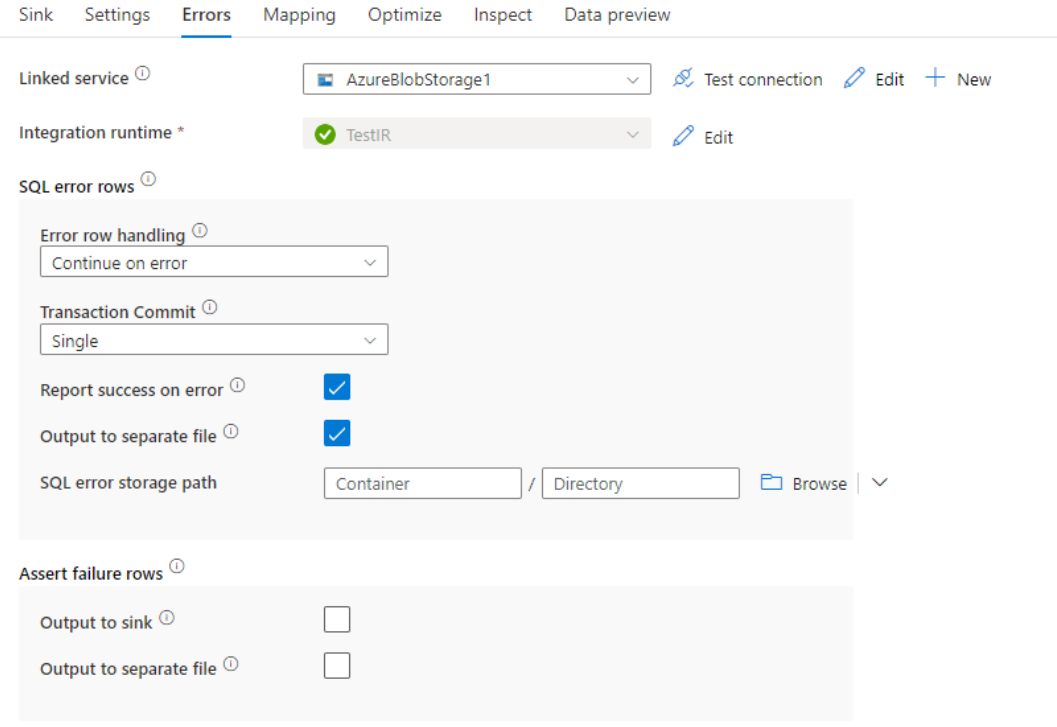
Gestione delle righe con errori
Durante la scrittura nel database SQL di Azure, alcune righe di dati potrebbero non riuscire a causa di vincoli impostati dalla destinazione. Di seguito sono riportati alcuni errori comuni:
- I dati di tipo string o binary verrebbero troncati nella tabella
- Impossibile inserire il valore NULL nella colonna
- Istruzione INSERT in conflitto con il vincolo CHECK
Per impostazione predefinita, un'esecuzione del flusso di dati avrà esito negativo al primo errore che riceve. È possibile scegliere Continua in caso di errore che consente il completamento del flusso di dati anche se le singole righe presentano errori. Il servizio offre diverse opzioni per gestire queste righe di errore.
Commit transazione: scegliere se i dati vengono scritti in una singola transazione o in batch. La singola transazione offrirà prestazioni peggiori, ma nessun dato scritto sarà visibile ad altri fino al completamento della transazione.
Output dei dati rifiutati: se abilitata, è possibile restituire le righe di errore in un file CSV in Archiviazione BLOB di Azure o in un account Azure Data Lake Storage Gen2 scelto. Verranno scritte le righe di errore con tre colonne aggiuntive: l'operazione SQL, ad esempio INSERIMENTO o AGGIORNAMENTO, il codice di errore del flusso di dati e il messaggio di errore nella riga.
Segnala l'esito positivo dell'errore: se abilitato, il flusso di dati verrà contrassegnato come operazione riuscita anche se vengono trovate righe di errore.
Mapping dei tipi di dati per il database SQL di Azure
Quando i dati vengono copiati da o verso il database SQL di Azure, vengono usati i mapping seguenti dai tipi di dati del database SQL di Azure ai tipi di dati provvisori di Azure Data Factory. Gli stessi mapping vengono usati dalla funzionalità della pipeline di Synapse, che implementa direttamente Azure Data Factory. Vedere Mapping dello schema e del tipo di dati per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink.
| Tipi di dati del database SQL di Azure | Tipo di dati provvisorio di Data Factory |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Booleano |
| char | String, Char[] |
| data | DataOra |
| Datetime | DataOra |
| datetime2 | Data/Ora |
| Datetimeoffset | DateTimeOffset |
| Decimale | Decimale |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| image | Byte[] |
| int | Int32 |
| money | Decimale |
| nchar | String, Char[] |
| ntext | String, Char[] |
| numeric | Decimale |
| nvarchar | String, Char[] |
| real | Singola |
| rowversion | Byte[] |
| smalldatetime | Data/Ora |
| smallint | Int16 |
| smallmoney | Decimale |
| sql_variant | Object |
| Testo | String, Char[] |
| Ora | TimeSpan |
| timestamp | Byte[] |
| tinyint | Byte |
| uniqueidentifier | GUID |
| varbinary | Byte[] |
| varchar | String, Char[] |
| xml | String |
Nota
Per i tipi di dati con mapping al tipo provvisorio Decimal, attualmente l’attività di copia supporta la precisione fino a 28. Se si hanno dati che richiedono una precisione maggiore di 28, è consigliabile convertirli in una stringa in una query SQL.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Proprietà dell'attività GetMetadata
Per altre informazioni sulle proprietà, vedere Attività GetMetadata
Uso di Always Encrypted
Quando si copiano dati da/verso il database SQL di Azure con Always Encrypted, seguire questa procedura:
Archiviare la chiave master della colonna (CMK) in un Azure Key Vault. Altre informazioni su come configurare Always Encrypted usando Azure Key Vault
Accertarsi di ottenere l'accesso all'insieme di credenziali delle chiavi in cui è archiviata la chiave master della colonna (CMK). Per le autorizzazioni necessarie, fare riferimento a questo articolo.
Creare un servizio collegato per connettersi al database SQL e abilitare la funzione "Always Encrypted" usando l'identità gestita o l'entità servizio.
Nota
Il database SQL di Azure Always Encrypted supporta gli scenari seguenti:
- Gli archivi dati di origine o sink usano un'identità gestita o un'entità servizio come tipo di autenticazione del provider di chiavi.
- Gli archivi dati di origine e sink usano l'identità gestita come tipo di autenticazione del provider di chiavi.
- Gli archivi dati di origine e sink usano la stessa entità servizio del tipo di autenticazione del provider di chiavi.
Nota
Attualmente, Il database SQL di Azure Always Encrypted è supportato solo per la trasformazione dell'origine nei flussi di dati di mapping.
Change Data Capture nativo
Azure Data Factory può supportare funzionalità Change Data Capture native per SQL Server, il database di Azure SQL e l'istanza gestita di Azure SQL. I dati modificati, inclusi l’inserimento, l’aggiornamento e l’eliminazione di righe in archivi SQL possono essere rilevati ed estratti automaticamente dal flusso di dati per mapping di ADF. Senza alcuna esperienza di coding nel flusso di dati per mapping, gli utenti possono ottenere facilmente uno scenario di replica dei dati da archivi SQL accodando un database come archivio di destinazione. Inoltre, gli utenti possono anche comporre qualsiasi logica di trasformazione dati intermedia per ottenere uno scenario ETL incrementale dagli archivi SQL.
Accertarsi di mantenere invariato il nome della pipeline e dell'attività, in modo che il checkpoint possa essere registrato da ADF per ottenere automaticamente i dati modificati dall'ultima esecuzione. Se si modifica il nome della pipeline o il nome dell'attività, il checkpoint verrà reimpostato, il che porta a ricominciare dall'inizio o a ottenere le modifiche da subito nella successiva esecuzione. Se si desidera modificare il nome della pipeline o il nome dell'attività mantenendo comunque il checkpoint per ottenere automaticamente i dati modificati dall'ultima esecuzione, usare la propria chiave checkpoint nell'attività del flusso di dati per ottenere tale risultato.
Quando si esegue il debug della pipeline, questa funzionalità funziona allo stesso modo. Tenere presente che il checkpoint verrà reimpostato quando si aggiorna il browser durante l'esecuzione del debug. Quando il risultato della pipeline dall'esecuzione del debug è soddisfacente, è possibile procedere alla pubblicazione e all'attivazione della pipeline. Al momento della prima attivazione della pipeline pubblicata, la pipeline viene riavviata automaticamente dall'inizio o ottiene le modifiche da tale momento in avanti.
Nella sezione di monitoraggio, è sempre possibile eseguire nuovamente una pipeline. Quando si esegue questa operazione, i dati modificati vengono sempre acquisiti dal checkpoint precedente dell'esecuzione della pipeline selezionata.
Esempio 1:
Quando si concatena direttamente una trasformazione di origine che fa riferimento al set di dati abilitato per SQL CDC, con una trasformazione sink che fa riferimento a un database in un flusso di dati per mapping, le modifiche apportate all'origine SQL verranno applicate automaticamente al database di destinazione, in modo da ottenere facilmente uno scenario di replica dei dati tra database. È possibile usare il metodo di aggiornamento nella trasformazione sink per selezionare se si desideri consentire l'inserimento, l'aggiornamento o l'eliminazione nel database di destinazione. Lo script di esempio nel flusso di dati di mapping è il seguente.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Esempio 2:
Se si desidera abilitare lo scenario ETL anziché la replica dei dati tra database tramite SQL CDC, è possibile usare espressioni nel flusso di dati per mapping isInsert(1), isUpdate(1) e isDelete(1) per distinguere le righe con tipi di operazione diversi. Di seguito è riportato uno degli script di esempio per il flusso di dati per mapping sulla derivazione di una colonna con il valore: 1 per indicare le righe inserite, 2 per indicare le righe aggiornate e 3 per indicare le righe eliminate per le trasformazioni downstream per l’elaborazione dei dati delta.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Limitazione nota:
- Solo modifiche nette da SQL CDC verrà caricato da ADF tramite cdc.fn_cdc_get_net_changes_.
Aggiornare la versione del database SQL di Azure
Per aggiornare la versione del database SQL di Azure, nella pagina Modifica servizio collegato, selezionare Consigliato in Versione e configurare il servizio collegato facendo riferimento a Proprietà del servizio collegato per la versione consigliata.
Differenze tra la versione consigliata e la versione legacy
La tabella seguente illustra le differenze tra il database SQL di Azure usando la versione consigliata e la versione legacy.
| Versione consigliata | Versione legacy |
|---|---|
Supportare TLS 1.3 tramite encrypt come strict. |
TLS 1.3 non è supportato. |
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati e formati supportati.