Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come usare l'attività di copia nelle pipeline di Azure Data Factory e Azure Synapse per copiare dati da e in Salesforce. Si basa sull'articolo di panoramica dell'attività di copia che presenta informazioni generali sull'attività di copia.
Important
Il connettore Salesforce V1 è in fase di rimozione. È consigliabile aggiornare il connettore Salesforce da V1 a V2.
Funzionalità supportate
Questo connettore Salesforce è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività Copy (origine/sink) | (1) (2) |
| Attività di Ricerca | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink, vedere la tabella Archivi dati supportati.
In particolare, il connettore Salesforce supporta:
- Le edizioni Developer, Professional, Enterprise o Unlimited di Salesforce.
- Copia di dati da e verso un dominio personalizzato (il dominio personalizzato può essere configurato sia in ambienti di produzione che in ambienti sandbox).
È possibile impostare in modo esplicito la versione dell'API usata per leggere/scrivere dati tramite apiVersion proprietà nel servizio collegato. Quando si copiano dati in Salesforce, il connettore usa l'API BULK 2.0.
Prerequisites
In Salesforce deve essere abilitata l'autorizzazione API.
È necessario configurare le app connesse nel portale di Salesforce facendo riferimento a questo documento ufficiale o alle linee guida dettagliate riportate nei suggerimenti di questo articolo.
Important
- L'utente di esecuzione deve avere l'autorizzazione Solo API.
- L'ora di scadenza del token di accesso può essere modificata tramite i criteri di sessione anziché il token di aggiornamento.
Limiti dell'API Bulk 2.0 di Salesforce
Per eseguire query e inserire dati viene usata l'API Bulk 2.0 di Salesforce. Nell'API Bulk 2.0 i batch vengono creati automaticamente. È possibile inviare fino a 15.000 batch per periodo di 24 ore in sequenza. Se i batch superano il limite, si verificano errori.
Nell'API Bulk 2.0, solo i processi di inserimento consumano batch. Ciò non avviene per i processi di query. Per informazioni dettagliate, vedere Come vengono elaborate le richieste nella Guida per sviluppatori dell'API Bulk 2.0.
Per altre informazioni, vedere la sezione "Limiti generali" in Limiti per sviluppatori di Salesforce.
Get started
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento Copia Dati
- portale Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- modello Azure Resource Manager
Creare un servizio collegato a Salesforce tramite l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Salesforce nell'interfaccia utente del portale di Azure.
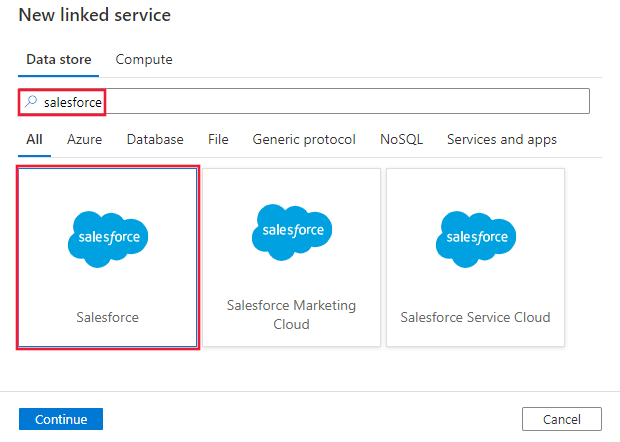
Passare alla scheda Gestisci nell'area di lavoro Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Salesforce e selezionare il connettore Salesforce.
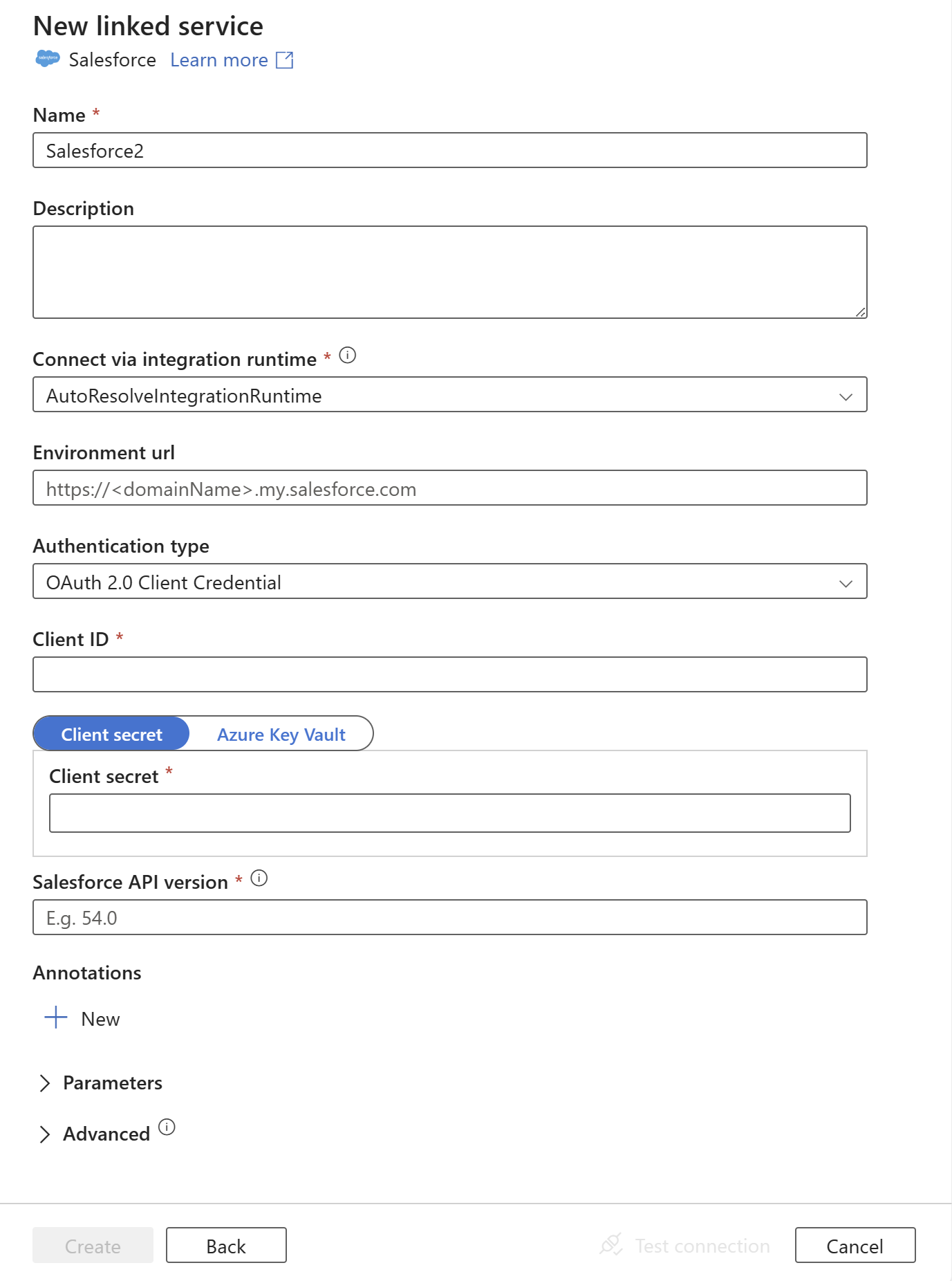
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà usate per definire entità specifiche per il connettore Salesforce.
Proprietà del servizio collegato
Per il servizio collegato di Salesforce sono supportate le proprietà seguenti.
| Property | Description | Required |
|---|---|---|
| type | La proprietà Tipo deve essere impostata su SalesforceV2. | Yes |
| environmentUrl | Specificare l'URL dell'istanza di Salesforce. Ad esempio, specificare "https://<domainName>.my.salesforce.com" per copiare dati dal dominio personalizzato. Per informazioni su come configurare o visualizzare il dominio personalizzato, vedere questo articolo. |
Yes |
| authenticationType | Tipo di autenticazione usato per connettersi a Salesforce. Il valore consentito è OAuth2ClientCredentials. |
Yes |
| clientId | Specificare l'ID client dell'app connessa OAuth 2.0 di Salesforce. Per altre informazioni, consultare questo articolo | Yes |
| clientSecret | Specificare il segreto client dell'app connessa OAuth 2.0 di Salesforce. Per altre informazioni, consultare questo articolo | Yes |
| apiVersion | Specificare la versione 2.0 dell'API Bulk di Salesforce da usare, ad esempio 52.0. L'API Bulk 2.0 supporta solo la versione API >= 47.0. Per informazioni sull'API Bulk 2.0, vedere l'articolo. Se si usa una versione dell'API precedente, si verifica un errore. |
Yes |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. Se non specificato, usa il Azure Integration Runtime predefinito. | No |
Esempio: archiviare le credenziali
{
"name": "SalesforceLinkedService",
"properties": {
"type": "SalesforceV2",
"typeProperties": {
"environmentUrl": "<environment URL>",
"authenticationType": "OAuth2ClientCredentials",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"apiVersion": "<API Version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: Archiviare le credenziali in Key Vault
{
"name": "SalesforceLinkedService",
"properties": {
"type": "SalesforceV2",
"typeProperties": {
"environmentUrl": "<environment URL>",
"authenticationType": "OAuth2ClientCredentials",
"clientId": "<client ID>",
"clientSecret": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of client secret in AKV>",
"store":{
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
}
},
"apiVersion": "<API Version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: Archiviare le credenziali in Key Vault, oltre a URL dell'ambiente e ID cliente
Archiviando le credenziali in Key Vault, oltre a environmentUrl e clientId, non è più possibile utilizzare l'interfaccia utente per modificare le impostazioni. La casella di controllo Specifica contenuti dinamici in formato JSON deve essere selezionata e questa configurazione deve essere eseguita manualmente. Il vantaggio di questo scenario è che è possibile derivare tutte le impostazioni di configurazione dal Key Vault invece di parametrizzare qualsiasi elemento qui.
{
"name": "SalesforceLinkedService",
"properties": {
"type": "SalesforceV2",
"typeProperties": {
"environmentUrl": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of environment URL in AKV>",
"store": {
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
},
},
"authenticationType": "OAuth2ClientCredentials",
"clientId": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of client ID in AKV>",
"store": {
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
},
},
"clientSecret": {
"type": "AzureKeyVaultSecret",
"secretName": "<secret name of client secret in AKV>",
"store":{
"referenceName": "<Azure Key Vault linked service>",
"type": "LinkedServiceReference"
}
},
"apiVersion": "<API Version>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati Salesforce.
Per copiare dati da e verso Salesforce, impostare la proprietà type del set di dati su SalesforceV2Object. Sono supportate le proprietà seguenti.
| Property | Description | Required |
|---|---|---|
| type | La proprietà Tipo deve essere impostata su SalesforceV2Object. | Yes |
| objectApiName | Nome dell'oggetto di Salesforce da cui recuperare i dati. La versione del runtime di integrazione self-hosted applicabile è 5.44.8984.1 o versioni successive. | No per l'origine (se nell'origine è specificato "query"), Sì per il sink |
| reportId | ID del report Salesforce da cui recuperare i dati. Non è supportato nel sink. Esistono limitazioni quando si usano i report. La versione del runtime di integrazione self-hosted applicabile è 5.44.8984.1 o versioni successive. | No per l'origine (se nell'origine è specificato "query"), non supporta il sink |
Important
La parte "__c" delnome dell'API è necessaria per qualsiasi oggetto personalizzato.
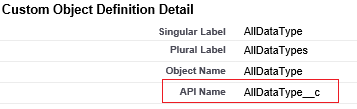
Example:
{
"name": "SalesforceDataset",
"properties": {
"type": "SalesforceV2Object",
"typeProperties": {
"objectApiName": "MyTable__c"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Salesforce linked service name>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine e dal sink Salesforce.
Salesforce come tipo di origine
Per copiare dati da Salesforce, impostare il tipo di origine nell'attività di copia su SalesforceV2Source. Nella sezione source dell'attività di copia sono supportate le proprietà seguenti.
| Property | Description | Required |
|---|---|---|
| type | La proprietà Tipo dell'origine dell'attività di copia deve essere impostata su SalesforceV2Source. | Yes |
| query | Usare la query personalizzata per leggere i dati. È possibile usare solo query SOQL (Salesforce Object Query Language). Se la query non viene specificata, tutti i dati dell'oggetto Salesforce specificato in "objectApiName/reportId" nel set di dati verranno recuperati. | No (se "objectApiName/reportId" è specificato nel set di dati) |
| includeDeletedObjects | Indica se eseguire query sui record esistenti o su tutti i record inclusi quelli eliminati. Se non specificato, il comportamento predefinito è falso. Valori consentiti: false (impostazione predefinita), true. |
No |
| preserveScaleFromSchema | Indica se abilitare o meno l'arrotondamento della scala decimale in base alla definizione di scala decimale nello schema. L'arrotondamento avviene solo quando la proprietà è impostata su true. Se non specificato, il comportamento predefinito è falso. Ad esempio, se una colonna è definita come decimal(18,3) nello schema, il valore 123.123789 viene arrotondato a 123.124 quando questa opzione è abilitata. Valori consentiti: false (impostazione predefinita), true. |
No |
| partitionOption | Offrire la possibilità di rilevare e applicare automaticamente l'algoritmo di partizionamento ottimale per ottimizzare la velocità effettiva di lettura, se applicabile. È consigliabile specificare AutoDetect per operazioni di copia a lunga durata che possono trarre vantaggio da letture multi-thread. Il valore predefinito è AutoDetect. |
No |
Important
La parte "__c" delnome dell'API è necessaria per qualsiasi oggetto personalizzato.
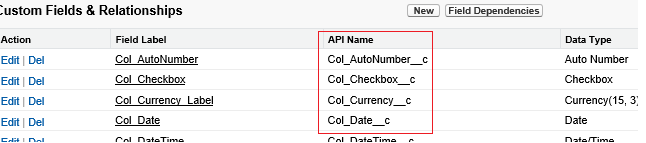
Example:
"activities":[
{
"name": "CopyFromSalesforce",
"type": "Copy",
"inputs": [
{
"referenceName": "<Salesforce input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SalesforceV2Source",
"query": "SELECT Col_Currency__c, Col_Date__c, Col_Email__c FROM AllDataType__c",
"includeDeletedObjects": false,
"preserveScaleFromSchema": false,
"partitionOption": "AutoDetect"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Salesforce come tipo di sink
Per copiare dati in Salesforce, impostare il tipo di sink nell'attività di copia su SalesforceV2Sink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti.
| Property | Description | Required |
|---|---|---|
| type | La proprietà Tipo del sink dell'attività di copia deve essere impostata su SalesforceV2Sink. | Yes |
| writeBehavior | Comportamento dell'azione di scrittura per l'operazione. I valori consentiti sono: Insert e Upsert. |
No (il valore predefinito è Insert) |
| externalIdFieldName | Nome del campo ID esterno per l'operazione upsert. Il campo specificato deve essere definito come "External ID Field" nell'oggetto di Salesforce. Non può includere valori NULL nei dati di input corrispondenti. | Sì per "Upsert" |
| writeBatchSize | Conteggio delle righe di dati scritti da Salesforce in ogni batch. Suggerire di impostare questo valore da 10.000 a 200.000. Un numero eccessivo di righe in ogni batch riduce le prestazioni di copia. Un numero eccessivo di righe in ogni batch può causare un timeout dell'API. | No (il valore predefinito è 100.000) |
| ignoreNullValues | Indica se ignorare i valori NULL dai dati di input durante un'operazione di scrittura. I valori consentiti sono true e false. - True: lasciare i dati nell'oggetto di destinazione invariati quando si esegue un'operazione di upsert o aggiornamento. Inserire un valore predefinito definito quando si esegue un'operazione di inserimento. - False: aggiornare i dati nell'oggetto di destinazione a NULL quando si esegue un'operazione di upsert o aggiornamento. Inserire un valore NULL quando si esegue un'operazione di inserimento. |
No (il valore predefinito è false) |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Esempio: Sink Salesforce in un'attività di copia
"activities":[
{
"name": "CopyToSalesforce",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Salesforce output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SalesforceV2Sink",
"writeBehavior": "Upsert",
"externalIdFieldName": "CustomerId__c",
"writeBatchSize": 10000,
"ignoreNullValues": true
}
}
}
]
Mapping dei tipi di dati per Salesforce
Quando si copiano dati da Salesforce, vengono usati i mapping seguenti tra i tipi di dati di Salesforce e i tipi di dati provvisori internamente al servizio. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
| Tipo di dati di Salesforce | Tipo di dati provvisorio del servizio |
|---|---|
| Numero automatico | String |
| Checkbox | Boolean |
| Currency | Decimal |
| Date | DateTime |
| Date/Time | DateTime |
| String | |
| ID | String |
| Relazione di ricerca | String |
| Elenco a selezione multipla | String |
| Number | Decimal |
| Percent | Decimal |
| Phone | String |
| Picklist | String |
| Text | String |
| Area di testo | String |
| Area di testo (Long) | String |
| Area di testo (Rich) | String |
| Testo (Crittografato) | String |
| URL | String |
Note
Il tipo Numero di Salesforce viene mappato al tipo Decimale in Azure Data Factory e nelle pipeline di Azure Synapse come tipo di dati intermedio del servizio. Il tipo decimale rispetta la precisione e la scala definite. Per i dati le cui posizioni decimali superano la scala definita, il relativo valore viene arrotondato nei dati di anteprima e nella copia. Per evitare di ottenere una tale perdita di precisione nelle pipeline di Azure Data Factory e Azure Synapse, è consigliabile aumentare le posizioni decimali a un valore ragionevolmente elevato nella pagina di Modifica definizione campo personalizzata di Salesforce.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Ciclo di vita e aggiornamento del connettore Salesforce
La tabella seguente illustra la fase di rilascio e i log delle modifiche per versioni diverse del connettore Salesforce:
| Version | Fase di rilascio | Log delle modifiche |
|---|---|---|
| Salesforce V1 | Removed | Non applicabile. |
| Salesforce V2 | Versione GA disponibile | • Supportare l'autenticazione OAuth2ClientCredentials anziché l'autenticazione di base. • Supporta solo query SOQL. Supporto di report tramite selezione di un ID report. • Supporto partitionOption nell'origine dell'attività di copia.• Supporto preserveScaleFromSchema nell'origine dell'attività di copia. • readBehavior viene sostituito con includeDeletedObjects nell'origine dell'attività di copia o nell'attività di ricerca. |
Aggiornare il connettore Salesforce da V1 a V2
Ecco i passaggi che consentono di aggiornare il connettore Salesforce:
Configurare le app connesse nel portale di Salesforce facendo riferimento ai Prerequisiti.
Creare un nuovo servizio collegato Salesforce e configurarlo facendo riferimento alle Proprietà del servizio collegato. È anche necessario aggiornare manualmente i set di dati esistenti che si basano sul servizio collegato precedente, modificando ogni set di dati per usare il nuovo servizio collegato.
Se si utilizza una query SQL nell'origine dell'attività di copia o nell'attività di ricerca che fa riferimento al servizio collegato V1, è necessario convertirli nella query SOQL. Altre informazioni sulla query SOQL da Salesforce come tipo di origine e Salesforce Object Query Language (SOQL).
Supporto
partitionOptionnell'origine dell'attività Copy. Per la configurazione dettagliata, vedere Salesforce come tipo di origine.Supporto
preserveScaleFromSchemanell'origine dell'attività Copy. Per la configurazione dettagliata, vedere Salesforce come tipo di origine.readBehaviorviene sostituito conincludeDeletedObjectsnell'origine dell'attività di copia o nell'attività di ricerca. Per la configurazione dettagliata, vedere Salesforce come tipo di origine.
Contenuti correlati
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.