Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come usare le Copy activity nelle pipeline di Azure Data Factory e Azure Synapse per copiare dati da e in Snowflake e usare Data Flow per trasformare i dati in Snowflake. Per altre informazioni, vedere l'articolo introduttivo per Data Factory o Azure Synapse Analytics.
Importante
Il connettore Snowflake V1 è in fase di rimozione. È consigliabile aggiornare il connettore Snowflake da V1 a V2.
Funzionalità supportate
Questo connettore Snowflake è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività Copy (origine/sink) | (1) (2) |
| Flusso di dati per mapping (origine/sink) | ① |
| Attività di Ricerca | (1) (2) |
| Attività script (applica la versione 1.1 quando si utilizza il parametro dello script) | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per il Copy activity, questo connettore Snowflake supporta le funzioni seguenti:
- Copia i dati dalla piattaforma Snowflake che utilizza il comando COPY into [location] per ottimizzare le prestazioni.
- Copia i dati in Snowflake utilizzando il comando COPY into [table] di Snowflake per ottenere prestazioni ottimali. Supporta Snowflake su Azure.
- Se è necessario un proxy per connettersi a Snowflake da un Integration Runtime self-hosted, è necessario configurare le variabili di ambiente per HTTP_PROXY e HTTPS_PROXY nell'host Integration Runtime.
Prerequisiti
Se l'archivio dati si trova all'interno di una rete locale, di una rete virtuale Azure o di Amazon Virtual Private Cloud, è necessario configurare un runtime di integrazione self-hosted per connettersi. Assicurarsi di aggiungere gli indirizzi IP usati dal runtime di integrazione self-hosted all'elenco consentito.
Se l'archivio dati è un servizio dati cloud gestito, è possibile usare il Azure Integration Runtime. Se l'accesso è limitato agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere Azure Integration Runtime IP all'elenco consentito.
L'account Snowflake usato per Source o Sink deve avere l'accesso USAGE necessario per il database e l'accesso in lettura/scrittura per lo schema e le tabelle/viste al suo interno. Inoltre, deve avere anche CREATE STAGE sullo schema per poter creare lo stadio esterno con l'URI SAS.
I valori delle proprietà account seguenti devono essere impostati
| Proprietà | Descrizione | Obbligatorio | Valore predefinito |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Specifica se è necessario un oggetto di integrazione dell'archiviazione come credenziale cloud durante la creazione di una 'stage' esterna nominata (utilizzando il comando CREATE STAGE) per accedere a un luogo di archiviazione cloud privato. | FALSE | FALSE |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Specifica se è necessario utilizzare una fase esterna specificata che fa riferimento a un oggetto di integrazione di archiviazione come credenziali cloud, quando si caricano o scaricano dati in un percorso di archiviazione cloud privato. | FALSE | FALSE |
Per altre informazioni sui meccanismi di sicurezza di rete e sulle opzioni supportate da Data Factory, vedere strategie di accesso ai dati.
Inizia
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento Copia Dati
- portale Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- modello Azure Resource Manager
Creare un servizio collegato a Snowflake usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Snowflake nell'interfaccia utente del portale di Azure.
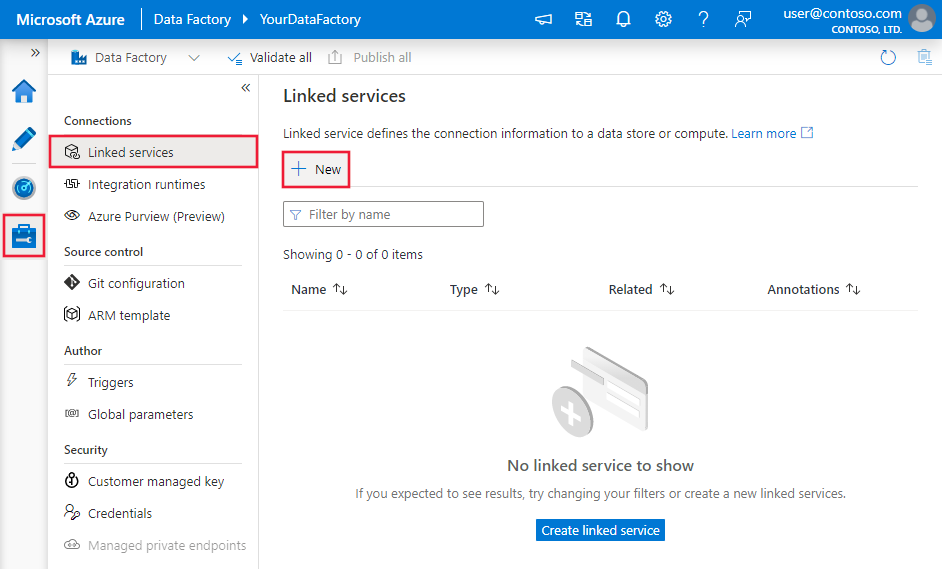
Passare alla scheda Gestisci nell'area di lavoro Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Snowflake e selezionare il connettore Snowflake.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
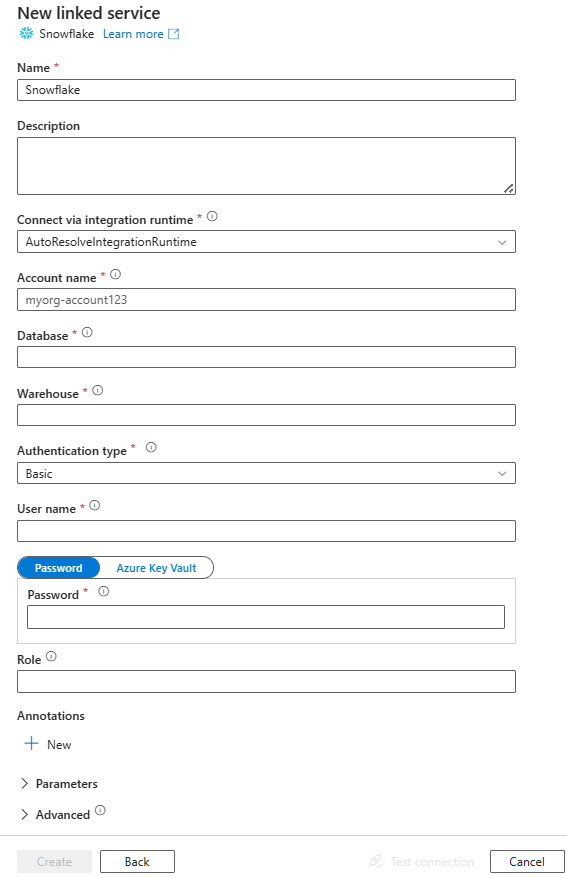
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà che definiscono entità specifiche di un connettore Snowflake.
Proprietà del servizio collegato
Queste proprietà generiche sono supportate per il servizio collegato Snowflake:
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| tipo | La proprietà type deve essere impostata su SnowflakeV2. | Sì |
| version | Versione specificata. È consigliabile eseguire l'aggiornamento alla versione più recente per sfruttare i miglioramenti più recenti. | Sì per la versione 1.1 |
| accountIdentifier | Nome dell'account insieme alla relativa organizzazione. Ad esempio, myorg-account123. | Sì |
| banca dati | Il database predefinito utilizzato dopo la connessione per la sessione. | Sì |
| magazzino | Il warehouse virtuale predefinito usato per la sessione dopo la connessione. | Sì |
| tipo di autenticazione | Tipo di autenticazione usato per connettersi al servizio Snowflake. I valori consentiti sono: Basic (Default) e KeyPair. Per maggiori informazioni sulle proprietà ed esempi, fare riferimento alle sezioni corrispondenti di seguito. | NO |
| ruolo | Ruolo di sicurezza predefinito usato per la sessione dopo la connessione. | NO |
| ospitante | Nome host dell'account Snowflake. Ad esempio: contoso.snowflakecomputing.com.
.cn è anche supportato. |
NO |
| connectVia | Il runtime di integrazione usato per connettersi all'archivio dati. È possibile usare il runtime di integrazione Azure o un runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, usa il runtime di integrazione Azure predefinito. | NO |
A seconda del caso, è possibile impostare le proprietà di connessione aggiuntive seguenti nel servizio collegato.
| Proprietà | Descrizione | Obbligatorio | Valore predefinito |
|---|---|---|---|
| UseUtcTimestamps | Specificarlo su false per restituire i tipi TIMESTAMP_LTZ e TIMESTAMP_TZ nel fuso orario corretto e il tipo TIMESTAMP_NTZ senza informazioni sul fuso orario. Impostarlo su true, per restituire tutti i tipi di timestamp Snowflake in formato UTC. |
NO | false |
| schema | Specifica lo schema per la sessione di query dopo la connessione. | NO | / |
Il connettore Snowflake supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti.
Autenticazione di base
Per usare l’autenticazione Basic, oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| utente | Nome di accesso per l'utente Snowflake. | Sì |
| parola d’ordine | Password per l'utente Snowflake. Contrassegnare questo campo come tipo SecureString per archiviarlo in modo sicuro. È anche possibile referenziare un segreto archiviato in Azure Key Vault. | Sì |
Esempio:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Password in Azure Key Vault:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticazione della coppia di chiavi
Per usare l'autenticazione della coppia di chiavi, è necessario configurare e creare un utente di autenticazione della coppia di chiavi in Snowflake facendo riferimento all'autenticazione della coppia di chiavi e alla rotazione della coppia di chiavi. Successivamente, prendere nota della chiave privata e della passphrase (facoltativa), che si usa per definire il servizio collegato.
Oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| utente | Nome di accesso per l'utente Snowflake. | Sì |
| chiave privata | Chiave privata usata per l'autenticazione della coppia di chiavi. Per assicurarsi che la chiave privata sia valida quando viene inviata a Azure Data Factory e considerando che il file privateKey include caratteri di nuova riga (\n), è essenziale formattare correttamente il contenuto privateKey nel formato letterale stringa. Questo processo comporta l'aggiunta esplicita di \n a ogni nuova riga. |
Sì |
| frase di accesso chiave privata | Passphrase usata per decrittografare la chiave privata, se crittografata. | NO |
Esempio:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Nota
Per i flussi di dati di mapping, è consigliabile generare una nuova chiave privata RSA usando lo standard PKCS#8 in formato PEM (file con estensione p8).
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati.
Per il set di dati Snowflake sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| tipo | La proprietà type del set di dati deve essere impostata su SnowflakeV2Table. | Sì |
| schema | Nome dello schema. Si noti che il nome dello schema fa distinzione tra maiuscole e minuscole. | No per l'origine, sì per il sink |
| tabella | Nome della tabella/vista. Tenere presente che il nome della tabella distingue maiuscole e minuscole. | No per l'origine, sì per il sink |
Esempio:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. In questa sezione viene fornito un elenco delle proprietà supportate dall'origine e dal sink Snowflake.
Snowflake come fonte
Il connettore Snowflake usa il comando COPY into [posizione] di Snowflake per ottenere prestazioni ottimali.
È possibile utilizzare l'attività Copia per copiare direttamente da Snowflake al sink se l'archivio dati sink e il formato sono supportati in modo nativo dal comando Snowflake COPY. Per informazioni dettagliate, vedere Copia diretta da Snowflake. In caso contrario, utilizzare la funzione integrata "Copia in fasi" di Snowflake.
Per copiare dati da Snowflake, nella sezione Copy activity source sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| tipo | La proprietà type dell'origine Copy activity deve essere impostata su SnowflakeV2Source. | Sì |
| quesito | Specifica la query SQL per leggere i dati da Snowflake. Se i nomi dello schema, della tabella e delle colonne contengono lettere minuscole, virgolette l'identificatore dell'oggetto nella query, ad esempio select * from "schema"."myTable".L'esecuzione di procedure memorizzate non è supportata. |
NO |
| impostazioni di esportazione | Impostazioni avanzate usate per recuperare i dati da Snowflake. È possibile configurare quelli supportati dal comando COPY into che il servizio passerà quando si richiama l'istruzione. | Sì |
| treatDecimalAsString | Specificare di trattare il tipo decimale come tipo stringa nelle attività di ricerca e script. Il valore predefinito è false.Questa proprietà è supportata solo nella versione 1.1. |
NO |
Sotto exportSettings: |
||
| tipo | Tipo di comando di esportazione, impostato su SnowflakeExportCopyCommand. | Sì |
| storageIntegration | Specificare il nome dell'integrazione di archiviazione creata in Snowflake. Per i passaggi preliminari dell'uso dell'integrazione dell'archiviazione, vedere Configurazione di un'integrazione dell'archiviazione Snowflake. | NO |
| Opzioni aggiuntive di copia | Opzioni di copia aggiuntive, fornite come dizionario di coppie chiave-valore. Esempi: MAX_FILE_SIZE, OVERWRITE. Per altre informazioni, vedere Opzioni di copia Snowflake. | NO |
| additionalFormatOptions | Opzioni di formato di file aggiuntive fornite al comando COPY come dizionario di coppie chiave-valore. Esempi: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT, NULL_IF. Per altre informazioni, vedere Opzioni del tipo di formato Snowflake. Quando si usa NULL_IF, il valore NULL in Snowflake viene convertito nel valore specificato (che deve essere racchiuso tra virgolette singole) durante la scrittura nel file di testo delimitato nell'archiviazione di staging. Questo valore specificato viene considerato NULL durante la lettura dal file di staging allo storage di destinazione. Il valore predefinito è 'NULL'. |
NO |
Nota
Assicurarsi di disporre dell'autorizzazione per eseguire il comando seguente e accedere allo schema INFORMATION_SCHEMA e alla tabella COLUMNS.
COPY INTO <location>
Copia diretta da Snowflake
Se l'archivio dati sink e il formato soddisfano i criteri descritti in questa sezione, è possibile usare l'attività di copia per copiare direttamente da Snowflake al sink. Il servizio controlla le impostazioni e non riesce l'esecuzione del Copy activity se i criteri seguenti non vengono soddisfatti:
Quando si specifica
storageIntegrationnell'origine:L'archivio dati sink è l'Archiviazione BLOB di Azure a cui si è fatto riferimento nella fase esterna in Snowflake. Prima di copiare i dati, è necessario completare i passaggi seguenti:
Creare un servizio collegato di Archiviazione BLOB di Azure per Archiviazione BLOB di Azure di sink con ogni tipo di autenticazione supportato.
Concedere almeno il ruolo Collaboratore ai dati del BLOB di archiviazione all'entità servizio Snowflake in Archiviazione BLOB di Azure di sink Controllo di accesso (IAM).
Quando non si specifica
storageIntegrationnell'origine:Il servizio collegato sink è Azure Blob Storage con autenticazione firma di accesso condiviso. Se si desidera copiare direttamente i dati in Azure Data Lake Storage Gen2 nel formato supportato seguente, è possibile creare un servizio collegato di Azure Blob Storage con l'autenticazione SAS per il tuo account Azure Data Lake Storage Gen2, per evitare di usare staged copy da Snowflake.
Il formato di dati sink è Parquet, testo delimitatoo JSON con le configurazioni seguenti:
- Per il formato Parquet , il codec di compressione è Nessuno, Snappy o Lzo.
- Per il formato testo delimitato:
-
rowDelimiterè \r\n, o qualsiasi singolo carattere. -
compressionpuò essere nessuna compressione, gzip, bzip2 o deflate. -
encodingNameè impostato sul valore predefinito o su utf-8. -
quoteCharè virgolette doppie, virgolette singole o stringa vuota (senza virgolette).
-
- Per il formato JSON, la copia diretta supporta solo il caso in cui il risultato della tabella Snowflake o della query di origine abbia solo una singola colonna e il tipo di dati di questa colonna sia VARIANT, OBJECT o ARRAY.
-
compressionpuò essere nessuna compressione, gzip, bzip2 o deflate. -
encodingNameè impostato sul valore predefinito o su utf-8. -
filePatternnel sink dell'attività Copy viene lasciato come predefinito o impostato su setOfObjects.
-
Nell'origine dell'attività di copia
additionalColumnsnon è specificato.Il mapping delle colonne non è specificato.
Esempio:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copia di staging da Snowflake
Se il tuo archivio dati sink o formato non è compatibile in modo nativo con il comando Snowflake COPY, come indicato nell'ultima sezione, abilita la copia integrata in più fasi utilizzando un'istanza temporanea di archiviazione Azure Blob. La funzionalità copia di staging assicura inoltre una migliore velocità effettiva. Il servizio esporta i dati da Snowflake nell'archiviazione di staging, quindi copia i dati nel sink e infine pulisce i dati temporanei dall'archiviazione di staging. Per informazioni dettagliate sulla copia dei dati utilizzando staging, vedere copia di dati utilizzando staging.
Per usare questa funzionalità, creare un servizio collegato di Archiviazione BLOB di Azure che faccia riferimento all'account di archiviazione di Azure come staging provvisorio. Specificare quindi le proprietà enableStaging e stagingSettings nel Copy activity.
Quando si specifica
storageIntegrationnell'origine, Archiviazione BLOB di Azure di staging provvisorio deve essere quello a cui si fa riferimento nella fase esterna in Snowflake. Verificare di creare un servizio collegato di Archiviazione BLOB di Azure con qualsiasi autenticazione supportata quando si usa l'Azure Integration Runtime, oppure con autenticazione anonima, chiave dell'account, autenticazione con firma di accesso condiviso o autenticazione con entità servizio quando si usa il runtime di integrazione self-hosted. Inoltre, concedere almeno il ruolo Collaboratore ai dati del BLOB di archiviazione all'entità servizio Snowflake in Archiviazione BLOB di Azure di staging Controllo di accesso (IAM).Quando non si specifica
storageIntegrationnell'origine, il servizio collegato di staging Azure Blob Storage deve usare l'autenticazione della firma di accesso condiviso, come richiesto dal comando Snowflake COPY. Assicurarsi di concedere l'autorizzazione di accesso appropriata a Snowflake nel Azure Blob Storage di gestione temporanea. Per altre informazioni, vedere questo articolo.
Esempio:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Quando si esegue una copia di staging da Snowflake, è fondamentale impostare il comportamento di copia sink su Unisci file. Questa impostazione garantisce che tutti i file partizionati vengano gestiti e uniti correttamente, impedendo che si verifichi un problema dovuto alla sola copia dell'ultimo file partizionato.
Configurazione di esempio
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Nota
Se non si imposta il comportamento di copia sink su Unisci file, è possibile che venga copiato solo l'ultimo file partizionato.
Snowflake come sink
Il connettore Snowflake usa il comando COPIA in [tabella] di Snowflake per ottenere prestazioni ottimali. Supporta la scrittura di dati in Snowflake in Azure.
Se l'archivio dati di origine e il formato sono supportati in modo nativo dal comando Snowflake COPY, è possibile usare il Copy activity per copiare direttamente dall'origine a Snowflake. Per i dettagli, vedere Copia diretta in Snowflake. In caso contrario, usare la copia con staging in Snowflake predefinita.
Per copiare i dati in Snowflake, nella sezione Copy activity sink sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| tipo | La proprietà tipo del sink dell'attività di copia deve essere impostata su SnowflakeV2Sink. | Sì |
| preCopyScript | Specificare una query SQL per il Copy activity da eseguire prima di scrivere dati in Snowflake in ogni esecuzione. Usare questa proprietà per pulire i dati precaricati. | NO |
| impostazioni di importazione | Impostazioni avanzate usate per scrivere dati in Snowflake. È possibile configurare quelli supportati dal comando COPY into che il servizio passerà quando si richiama l'istruzione. | Sì |
Sotto importSettings: |
||
| tipo | Tipo di comando di importazione, impostato su SnowflakeImportCopyCommand. | Sì |
| storageIntegration | Specificare il nome dell'integrazione di archiviazione creata in Snowflake. Per i passaggi preliminari dell'uso dell'integrazione dell'archiviazione, vedere Configurazione di un'integrazione dell'archiviazione Snowflake. | NO |
| Opzioni aggiuntive di copia | Opzioni di copia aggiuntive, fornite come dizionario di coppie chiave-valore. Esempi: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Per altre informazioni, vedere Opzioni di copia Snowflake. | NO |
| additionalFormatOptions | Opzioni di formato di file aggiuntive fornite al comando COPIA, fornite come dizionario di coppie chiave-valore. Esempi: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Per altre informazioni, vedere Opzioni del tipo di formato Snowflake. | NO |
Nota
Assicurarsi di disporre dell'autorizzazione per eseguire il comando seguente e accedere allo schema INFORMATION_SCHEMA e alla tabella COLUMNS.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Copia diretta su Snowflake
Se l'archivio dati di origine e il formato soddisfano i criteri descritti in questa sezione, è possibile usare il Copy activity per copiare direttamente dall'origine a Snowflake. Il servizio controlla le impostazioni e non riesce l'esecuzione del Copy activity se i criteri seguenti non vengono soddisfatti:
Quando si specifica
storageIntegrationnel sink:L'archivio dati di origine è il Azure Blob Storage a cui si fa riferimento nella fase esterna in Snowflake. Prima di copiare i dati, è necessario completare i passaggi seguenti:
Creare un servizio collegato Azure Blob Storage per il Azure Blob Storage di origine con qualsiasi tipo di autenticazione supportato.
Concedere almeno il ruolo Lettore dei dati del BLOB di archiviazione all'entità servizio Snowflake in Archiviazione BLOB di Azure di origine Controllo di accesso (IAM).
Quando non si specifica
storageIntegrationnel sink:Il servizio collegato di origine è Archiviazione BLOB di Azure con autenticazione di firma di accesso condiviso. Se si desidera copiare direttamente i dati da Azure Data Lake Storage Gen2 nel seguente formato supportato, è possibile creare un servizio collegato Azure Blob Storage con l'autenticazione SAS per utilizzare il proprio account Azure Data Lake Storage Gen2, per evitare di utilizzare la copia temporanea in Snowflake.
Il formato dei dati di origine è Parquet, ORC o Testo delimitato, con le configurazioni seguenti:
Per il formato Parquet, il codec di compressione è Nessuno o Snappy.
Per il formato testo delimitato:
-
rowDelimiterè \r\n, o qualsiasi singolo carattere. Se il delimitatore di riga non è "\r\n",firstRowAsHeaderdeve essere falseeskipLineCountnon è specificato. -
compressionpuò essere nessuna compressione, gzip, bzip2 o deflate. -
encodingNameviene lasciato come predefinito o impostato su "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255". -
quoteCharè virgolette doppie, virgolette singole o stringa vuota (senza virgolette).
-
Per il formato JSON, la copia diretta supporta solo il caso in cui la tabella Snowflake sink ha solo una colonna e il tipo di dati di questa colonna è VARIANT, OBJECT o ARRAY.
-
compressionpuò essere nessuna compressione, gzip, bzip2 o deflate. -
encodingNameè impostato sul valore predefinito o su utf-8. - Il mapping delle colonne non è specificato.
-
Nella sorgente dell'attività di copia
-
additionalColumnsnon è specificato. - Se l'origine è una cartella,
recursiveè impostata su true. -
prefix,modifiedDateTimeStart,modifiedDateTimeEndeenablePartitionDiscoverynon sono specificati.
-
Esempio:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Copia di staging in Snowflake
Quando l'archivio dati o il formato di origine non sono compatibili in modo nativo con il comando Snowflake COPY, come indicato nell'ultima sezione, abilitare la copia a fasi predefinita usando un'istanza di archiviazione BLOB temporanea Azure. La funzionalità copia di staging assicura inoltre una migliore velocità effettiva. Il servizio converte automaticamente i dati in modo da soddisfare i requisiti di formato dei dati di Snowflake. Richiama quindi il comando COPIA per caricare i dati in Snowflake. Infine, pulisce i dati temporanei dall'archiviazione BLOB. Per informazioni dettagliate sulla copia dei dati con staging, vedere Copia con staging.
Per usare questa funzionalità, creare un servizio collegato di Archiviazione BLOB di Azure che faccia riferimento all'account di archiviazione di Azure come staging provvisorio. Specificare quindi le proprietà enableStaging e stagingSettings nel Copy activity.
Quando si specifica
storageIntegrationnel sink, Archiviazione BLOB di Azure di staging provvisorio deve essere quello a cui si fa riferimento nella fase esterna in Snowflake. Verificare di creare un servizio collegato di Archiviazione BLOB di Azure con qualsiasi autenticazione supportata quando si usa l'Azure Integration Runtime, oppure con autenticazione anonima, chiave dell'account, autenticazione con firma di accesso condiviso o autenticazione con entità servizio quando si usa il runtime di integrazione self-hosted. Inoltre, concedere almeno il ruolo Lettore dei dati del BLOB di archiviazione all'entità servizio Snowflake in Archiviazione BLOB di Azure di staging Controllo di accesso (IAM).Quando non si specifica
storageIntegrationnel sink, il servizio collegato di Archiviazione BLOB di Azure di staging deve utilizzare l'autenticazione con firma di accesso condivisa secondo quanto richiesto dal comando COPY di Snowflake.
Esempio:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Mappatura delle proprietà del flusso di dati
Quando si trasformano i dati nel flusso di dati di mapping, è possibile leggere e scrivere nelle tabelle in Snowflake. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati di mapping. È possibile scegliere di usare un set di dati Snowflake o un set di dati inline come tipo di origine e sink.
Trasformazione della sorgente
Nella tabella seguente sono elencate le proprietà supportate dall'origine di Snowflake. È possibile modificare queste proprietà nella scheda Opzioni origine. Il connettore usa trasferimento dati interno di Snowflake.
| Nome | Descrizione | Obbligatorio | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Tabella | Se si seleziona Tabella come input, il flusso di dati recupera tutti i dati dalla tabella specificata nel set di dati Snowflake o nelle opzioni di origine quando si usa il set di dati inline. | NO | string |
(solo per set di dati inline) tableName schemaName |
| Quesito | Se si seleziona Query come input, immettere una query per recuperare i dati da Snowflake. Questa impostazione esegue l'override di qualsiasi tabella scelta nel set di dati. Se i nomi dello schema, della tabella e delle colonne contengono lettere minuscole, virgolette l'identificatore dell'oggetto nella query, ad esempio select * from "schema"."myTable". |
NO | string | quesito |
| Abilitare l'estrazione incrementale (anteprima) | Usare questa opzione per indicare ad ADF di elaborare solo le righe modificate dall'ultima esecuzione della pipeline. | NO | Boolean | enableCdc |
| Colonna incrementale | Quando si usa la funzionalità di estrazione incrementale, è necessario scegliere la colonna data/ora/numerica da usare come limite nella tabella di origine. | NO | string | waterMarkColumn |
| Abilitare il rilevamento delle modifiche di Snowflake (Anteprima) | Questa opzione consente ad ADFdi sfruttare la tecnologia CDC (Change Data Capture) di Snowflake per elaborare solo i dati delta dall'esecuzione precedente della pipeline. Questa opzione carica automaticamente i dati differenziali con operazioni di inserimento, aggiornamento ed eliminazione di righe senza richiedere alcuna colonna incrementale. | NO | Boolean | enableNativeCdc |
| Modifiche nette | Quando si usa il rilevamento delle modifiche Snowflake, è possibile usare questa opzione per ottenere le righe modificate deduplicate o le modifiche complete. Le righe modificate deduplicate mostreranno solo le versioni più recenti delle righe modificate da un determinato punto nel tempo, mentre le modifiche complete mostreranno tutte le versioni di ogni riga modificata, incluse quelle eliminate o aggiornate. Ad esempio, se si aggiorna una riga, verrà visualizzata una versione di eliminazione e una versione di inserimento in modifiche complete, ma solo la versione di inserimento nelle righe modificate deduplicate. A seconda del caso d'uso, è possibile scegliere l'opzione più adatta alle proprie esigenze. L'opzione predefinita è false, il che significa modifiche complete. | NO | Boolean | netChanges |
| Includere colonne di sistema | Quando si usa il rilevamento delle modifiche Snowflake, è possibile usare l'opzione systemColumns per controllare se le colonne del flusso di metadati fornite da Snowflake sono incluse o escluse nell'output del rilevamento delle modifiche. Per impostazione predefinita, systemColumns è impostato su true, ovvero le colonne del flusso di metadati sono incluse. È possibile impostare systemColumns su false se si desidera escluderli. | NO | Boolean | systemColumns |
| Iniziare a leggere dall'inizio | L'impostazione di questa opzione con l'estrazione incrementale e il rilevamento delle modifiche indicherà ad Azure Data Factory di leggere tutte le righe alla prima esecuzione di una pipeline con estrazione incrementale attivata. | NO | Boolean | skipInitialLoad |
Esempi di script di origine Snowflake
Quando si usa il set di dati Snowflake come tipo di origine, lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Se si usa un set di dati inline, lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Rilevamento modifiche nativo
Azure Data Factory ora supporta una funzionalità nativa in Snowflake nota come rilevamento delle modifiche, che implica il rilevamento delle modifiche sotto forma di log. Questa funzionalità di Snowflake consente di tenere traccia delle modifiche apportate ai dati nel tempo, rendendola utile per il caricamento e il controllo incrementali dei dati. Per utilizzare questa funzionalità, quando si abilita Change Data Capture e si seleziona Rilevamento modifiche di Snowflake, viene creato un oggetto Stream per la tabella di origine che abilita il rilevamento delle modifiche nella tabella snowflake di origine. Successivamente, viene usata la clausola MODIFICHE nella query per recuperare solo i dati nuovi o aggiornati dalla tabella di origine. È anche consigliabile pianificare la pipeline in modo che le modifiche vengano utilizzate entro l'intervallo di tempo di conservazione dei dati impostato per la tabella di origine snowflake. In caso contrario, l'utente potrebbe vedere un comportamento incoerente nelle modifiche acquisite.
Trasformazione sink
Nella tabella seguente sono elencate le proprietà supportate dal sink di Snowflake. È possibile modificare queste proprietà nella scheda Impostazioni. Quando si usa il set di dati inline, verranno visualizzate impostazioni aggiuntive, che corrispondono alle proprietà descritte nella sezione proprietà del set di dati. Il connettore usa il trasferimento interno dei dati di Snowflake.
| Nome | Descrizione | Obbligatorio | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Metodo di aggiornamento | Specificare le operazioni consentite nella destinazione di Snowflake. Per aggiornare, inserire o eliminare righe, è necessaria una Alter row transformation per contrassegnare le righe per queste azioni. |
Sì |
true oppure false |
eliminabile insertable aggiornabile upsertable |
| Colonne chiave | Per le operazioni di aggiornamento, upsert ed eliminazione è necessario impostare una o più colonne chiave per determinare quale riga modificare. | NO | Array | chiavi |
| Azione tabella | determina se ricreare o rimuovere tutte le righe dalla tabella di destinazione prima della scrittura. - Nessuna: non verrà eseguita alcuna azione sulla tabella. - Ricrea: la tabella verrà eliminata e ricreata. Questa opzione è obbligatoria se si crea una nuova tabella in modo dinamico. - Tronca: verranno rimosse tutte le righe della tabella di destinazione. |
NO |
true oppure false |
ricreare truncate |
Esempi di script sink Snowflake
Quando si usa il set di dati Snowflake come tipo di sink, lo script del flusso di dati associato è:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Se si usa un set di dati inline, lo script del flusso di dati associato è:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Ottimizzazione pushdown delle query
Impostando il livello di registrazione della pipeline su Nessuno, si esclude la trasmissione delle metriche di trasformazione intermedia, impedendo potenziali ostacoli alle ottimizzazioni spark e abilitando l'ottimizzazione pushdown delle query fornita da Snowflake. Questa ottimizzazione pushdown consente miglioramenti sostanziali delle prestazioni per tabelle Snowflake di grandi dimensioni con set di dati estesi.
Nota
Non sono supportate tabelle temporanee in Snowflake, perché sono locali per la sessione o per l'utente che li crea, rendendole inaccessibili ad altre sessioni e soggette a sovrascrivere come tabelle regolari da Snowflake. Anche se Snowflake offre tabelle temporanee come alternativa, accessibili a livello globale, richiedono l'eliminazione manuale, contraddicendo l'obiettivo principale dell'uso delle tabelle temp, evitando qualsiasi operazione di eliminazione nello schema di origine.
Mappatura dei tipi di dati per Snowflake V2
Quando si copiano dati da Snowflake, vengono usati i mapping seguenti dai tipi di dati Snowflake ai tipi di dati provvisori internamente al servizio. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
| Tipo di dati Snowflake | Tipo di dati provvisorio del servizio |
|---|---|
| NUMERO (p,0) | Decimal |
| NUMERO (p,s dove s>0) | Decimal |
| FLOAT | Double |
| VARCHAR | string |
| CHAR | string |
| BINARY | Byte[] |
| BOOLEAN | Boolean |
| DATTERO | Data e ora |
| TEMPO | TimeSpan |
| TIMESTAMP_LTZ | DateTimeOffset |
| TIMESTAMP_NTZ | DateTimeOffset |
| TIMESTAMP_TZ | DateTimeOffset |
| VARIANT | string |
| OBJECT | string |
| ARRAY | string |
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività di Ricerca.
Ciclo di vita e aggiornamento del connettore Snowflake
La tabella seguente illustra la fase di rilascio e i log delle modifiche per versioni diverse del connettore Snowflake:
| Versione | Fase di rilascio | Log delle modifiche |
|---|---|---|
| Snowflake V1 | Removed | Non applicabile. |
| Snowflake V2 (versione 1.0) | Versione GA disponibile | • Aggiungere il supporto per l'autenticazione della coppia di chiavi. • Aggiungere il supporto per storageIntegration in Copy activity. • Le accountIdentifier proprietà, warehouse, database, schema e role vengono utilizzate per stabilire una connessione anziché connectionstring proprietà.• Aggiungere il supporto per l'attività Decimal in Lookup. Il tipo NUMERO, come definito in Snowflake, verrà visualizzato come stringa nell'attività Lookup. Se si vuole coprirlo al tipo numerico in V2, è possibile usare il parametro della pipeline con la funzione int o la funzione float. Ad esempio int(activity('lookup').output.firstRow.VALUE), float(activity('lookup').output.firstRow.VALUE)• il tipo di dati timestamp in Snowflake viene letto come tipo di dati DateTimeOffset nell'attività Lookup e Script. Se è ancora necessario usare il valore Datetime come parametro nella pipeline dopo l'aggiornamento alla versione 2, è possibile convertire il tipo DateTimeOffset in tipo DateTime usando la funzione formatDateTime (scelta consigliata) o la funzione concat. Ad esempio: formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE), concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') • NUMERO (p,0) viene letto come tipo di dati Decimal. • TIMESTAMP_LTZ, TIMESTAMP_NTZ e TIMESTAMP_TZ viene letto come tipo di dati DateTimeOffset. • I parametri script non sono supportati nell'attività Script. In alternativa, usare espressioni dinamiche per i parametri di script. Per altre informazioni, vedere Espressioni e funzioni in Azure Data Factory e Azure Synapse Analytics. • L'esecuzione di più istruzioni SQL nell'attività script non è supportata. |
| Snowflake V2 (versione 1.1) | Versione GA disponibile | • Aggiungere il supporto per i parametri di script. • Aggiungere il supporto per l'esecuzione di più istruzioni nell'attività Script. • Aggiungere la proprietà treatDecimalAsString nelle attività Lookup e Script. • Aggiungere una proprietà di UseUtcTimestampsconnessione aggiuntiva. |
Aggiornare il connettore Snowflake da V1 a V2
Per aggiornare il connettore Snowflake da V1 a V2, è possibile eseguire un aggiornamento affiancato o un aggiornamento sul posto.
Aggiornamento affiancato
Per eseguire un aggiornamento affiancato, segui i passaggi seguenti:
- Creare un nuovo servizio collegato Snowflake e configurarlo facendo riferimento alle proprietà del servizio collegato V2.
- Creare un set di dati basato sul servizio collegato Snowflake appena creato.
- Sostituire il nuovo servizio collegato e il set di dati con quelli esistenti nelle pipeline che hanno come destinazione gli oggetti V1.
Aggiornamento sul posto
Per eseguire un aggiornamento sul posto, è necessario modificare il payload del servizio collegato esistente e aggiornare il set di dati per usare il nuovo servizio collegato.
Aggiornare il tipo da Snowflake a SnowflakeV2.
Modificare il payload del servizio collegato dal formato V1 alla versione 2. È possibile compilare ogni campo dall'interfaccia utente dopo aver modificato il tipo indicato in precedenza oppure aggiornare il payload direttamente tramite l'editor JSON. Per le proprietà di connessione supportate, vedere la sezione Proprietà del servizio collegato in questo articolo. Gli esempi seguenti illustrano le differenze nel payload per i servizi collegati V1 e V2 Snowflake:
Payload JSON del servizio collegato Snowflake V1:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Payload JSON del servizio collegato Snowflake V2:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Aggiornare il set di dati per usare il nuovo servizio collegato. È possibile creare un nuovo set di dati in base al servizio collegato appena creato oppure aggiornare la proprietà type di un set di dati esistente da SnowflakeTable a SnowflakeV2Table.
Nota
Quando si esegue la transizione dei servizi collegati, la sezione dei parametri del modello di override potrebbe visualizzare solo le proprietà del database. È possibile risolvere questo problema modificando manualmente i parametri. Dopo che la sezione Parametri modello di override visualizzerà le stringhe di connessione.
Aggiornare il connettore Snowflake V2 dalla versione 1.0 alla versione 1.1
Nella pagina Modifica servizio collegato selezionare 1.1 per la versione. Per altre informazioni, vedere Proprietà del servizio collegato.
Contenuto correlato
Per un elenco degli archivi di dati supportati come origini e destinazioni dall'attività di copia, vedere dati e formati supportati.