Sviluppare codice nei notebook di Databricks
Questa pagina descrive come sviluppare codice nei notebook di Databricks, tra cui completamento automatico, formattazione automatica per Python e SQL, combinazione di Python e SQL in un notebook e rilevamento della cronologia delle versioni del notebook.
Per altre informazioni sulle funzionalità avanzate disponibili con l'editor, ad esempio completamento automatico, selezione di variabili, supporto di più cursori e differenze side-by-side, vedere Usare il notebook e l'editor di file di Databricks.
Quando si usa il notebook o l'editor di file, Databricks Assistant è disponibile per facilitare la generazione, la spiegazione e il debug del codice. Per altre informazioni, vedere Usare Databricks Assistant .
I notebook di Databricks includono anche un debugger interattivo predefinito per i notebook Python. Vedere Usare il debugger interattivo di Databricks.
Ottenere assistenza per la scrittura del codice da Databricks Assistant
Databricks Assistant è un assistente di intelligenza artificiale compatibile con il contesto con cui è possibile interagire usando un'interfaccia conversazionale, rendendo più produttivi all'interno di Databricks. È possibile descrivere l'attività in inglese e consentire all'assistente di generare codice Python o query SQL, spiegare codice complesso e correggere automaticamente gli errori. L'assistente usa i metadati di Unity Catalog per comprendere le tabelle, le colonne, le descrizioni e gli asset di dati più diffusi nell'azienda per fornire risposte personalizzate.
Databricks Assistant consente di eseguire le attività seguenti:
- Generare codice.
- Eseguire il debug del codice, inclusa l'identificazione e la suggerimento di correzioni per gli errori.
- Trasformare e ottimizzare il codice.
- Spiegare il codice.
- Informazioni pertinenti sono disponibili nella documentazione di Azure Databricks.
Per informazioni sull'uso di Databricks Assistant per facilitare l'esecuzione del codice in modo più efficiente, vedere Usare Databricks Assistant. Per informazioni generali su Databricks Assistant, vedere Funzionalità basate su DatabricksIQ.
Accedere al notebook per la modifica
Per aprire un notebook, usare la funzione Di ricerca dell'area di lavoro o usare il browser dell'area di lavoro per passare al notebook e fare clic sul nome o sull'icona del notebook.
Esplorare i dati
Usare il browser dello schema per esplorare tabelle e volumi disponibili per il notebook. Fare clic ![]() sul lato sinistro del notebook per aprire il browser dello schema.
sul lato sinistro del notebook per aprire il browser dello schema.
Il pulsante Per l'utente visualizza solo le tabelle usate nella sessione corrente o contrassegnate in precedenza come Preferiti.
Durante la digitazione del testo nella casella Filtro , la visualizzazione cambia in modo da visualizzare solo gli elementi che contengono il testo digitato. Vengono visualizzati solo gli elementi attualmente aperti o aperti nella sessione corrente. La casella Filtro non esegue una ricerca completa dei cataloghi, degli schemi e delle tabelle disponibili per il notebook.
Per aprire il  menu kebab, posizionare il cursore sul nome dell'elemento, come illustrato di seguito:
menu kebab, posizionare il cursore sul nome dell'elemento, come illustrato di seguito:
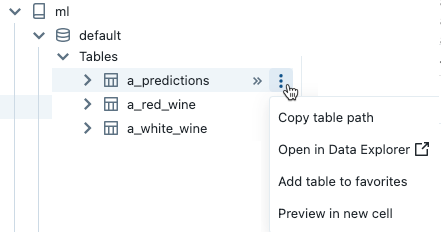
Se l'elemento è una tabella, è possibile eseguire le operazioni seguenti:
- Creare ed eseguire automaticamente una cella per visualizzare un'anteprima dei dati nella tabella. Selezionare Anteprima in una nuova cella dal menu kebab per la tabella.
- Visualizzare un catalogo, uno schema o una tabella in Esplora cataloghi. Selezionare Apri in Esplora cataloghi dal menu kebab. Verrà visualizzata una nuova scheda che mostra l'elemento selezionato.
- Ottenere il percorso di un catalogo, uno schema o una tabella. Selezionare Copia... percorso dal menu kebab per la voce.
- Aggiungere una tabella ai Preferiti. Selezionare Aggiungi tabella ai preferiti dal menu kebab per la tabella.
Se l'elemento è un catalogo, uno schema o un volume, è possibile copiare il percorso dell'elemento o aprirlo in Esplora cataloghi.
Per inserire direttamente un nome di tabella o di colonna in una cella:
- Fare clic sul cursore nella cella nella posizione in cui si vuole immettere il nome.
- Spostare il cursore sul nome della tabella o sulla colonna nel browser dello schema.
- Fare clic sulla doppia freccia
 visualizzata a destra del nome dell'elemento.
visualizzata a destra del nome dell'elemento.
Scelte rapide da tastiera
Per visualizzare i tasti di scelta rapida, selezionare Tasti di scelta rapida della Guida>. I tasti di scelta rapida disponibili dipendono dal fatto che il cursore si trova in una cella di codice (modalità di modifica) o meno (modalità di comando).
Ricerca e sostituzione di testo
Per trovare e sostituire il testo all'interno di un notebook, selezionare Modifica > trova e sostituisci. La corrispondenza corrente è evidenziata in arancione e tutte le altre corrispondenze sono evidenziate in giallo.
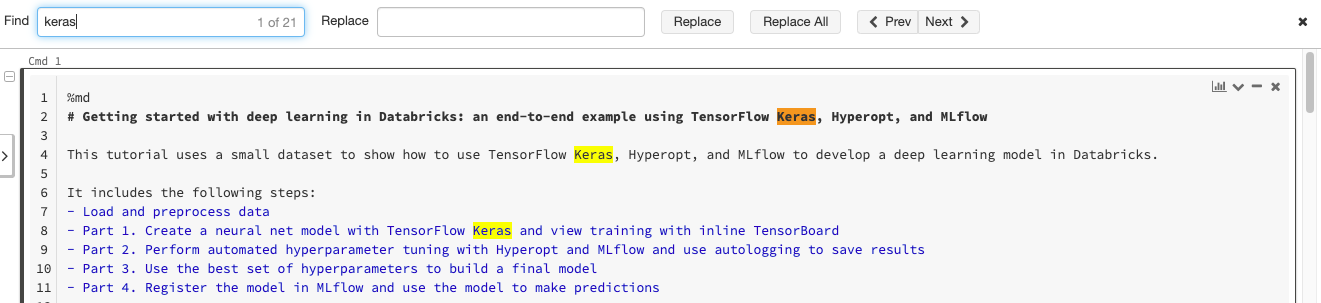
Per sostituire la corrispondenza corrente, fare clic su Sostituisci. Per sostituire tutte le corrispondenze nel notebook, fare clic su Sostituisci tutto.
Per spostarsi tra corrispondenze, fare clic sui pulsanti Prev e Avanti . È anche possibile premere MAIUSC+INVIO e immettere per passare rispettivamente alle corrispondenze precedenti e successive.
Per chiudere lo strumento trova e sostituisci, fare clic ![]() o premere ESC.
o premere ESC.
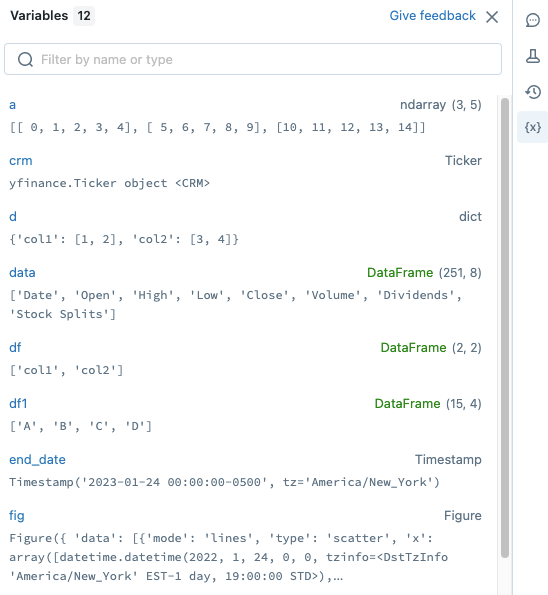
Esplora variabili
È possibile osservare direttamente le variabili Python, Scala e R nell'interfaccia utente del notebook. Per Python in Databricks Runtime 12.2 LTS e versioni successive, le variabili vengono aggiornate durante l'esecuzione di una cella. Per Scala, R e per Python in Databricks Runtime 11.3 LTS e versioni successive, le variabili vengono aggiornate al termine dell'esecuzione di una cella.
Per aprire Esplora variabili, fare clic ![]() sulla barra laterale destra. Si apre Esplora variabili, che mostra il valore e il tipo di dati, inclusa la forma, per ogni variabile attualmente definita nel notebook. La forma di un dataframe PySpark è '?', perché il calcolo della forma può essere dispendioso dal calcolo.
sulla barra laterale destra. Si apre Esplora variabili, che mostra il valore e il tipo di dati, inclusa la forma, per ogni variabile attualmente definita nel notebook. La forma di un dataframe PySpark è '?', perché il calcolo della forma può essere dispendioso dal calcolo.
Per filtrare la visualizzazione, immettere testo nella casella di ricerca. L'elenco viene filtrato automaticamente durante la digitazione.
I valori delle variabili vengono aggiornati automaticamente durante l'esecuzione delle celle del notebook.
Eseguire le celle selezionate
È possibile eseguire una singola cella o una raccolta di celle. Per selezionare una singola cella, fare clic in un punto qualsiasi della cella. Per selezionare più celle, tenere premuto il Command tasto in MacOS o il Ctrl tasto in Windows e fare clic nella cella all'esterno dell'area di testo, come illustrato nello screenshot.
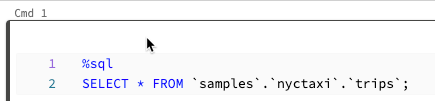
Per eseguire le celle selezionate, selezionare Esegui > celle selezionate.
Il comportamento di questo comando dipende dal cluster a cui è collegato il notebook.
- In un cluster che esegue Databricks Runtime 13.3 LTS o versione successiva, le celle selezionate vengono eseguite singolarmente. Se si verifica un errore in una cella, l'esecuzione continua con le celle successive.
- In un cluster che esegue Databricks Runtime 14.0 o versione successiva o in un'istanza di SQL Warehouse, le celle selezionate vengono eseguite come batch. Qualsiasi errore interrompe l'esecuzione e non è possibile annullare l'esecuzione di singole celle. È possibile usare il pulsante Interrupt per arrestare l'esecuzione di tutte le celle.
Modularizzare il codice
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Con Databricks Runtime 11.3 LTS e versioni successive, è possibile creare e gestire file di codice sorgente nell'area di lavoro di Azure Databricks e quindi importarli nei notebook in base alle esigenze.
Per altre informazioni sull'uso dei file di codice sorgente, vedere Condividere il codice tra i notebook di Databricks e Usare i moduli Python e R.
Eseguire il testo selezionato
È possibile evidenziare il codice o le istruzioni SQL in una cella del notebook ed eseguire solo tale selezione. Ciò è utile quando si vuole scorrere rapidamente il codice e le query.
Evidenziare le righe da eseguire.
Selezionare Esegui il testo selezionato oppure usare il tasto di scelta rapida
Ctrl++ShiftEnter.> Se non è evidenziato alcun testo, Esegui testo selezionato esegue la riga corrente.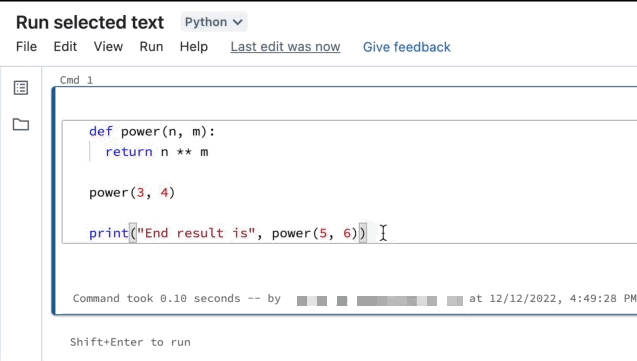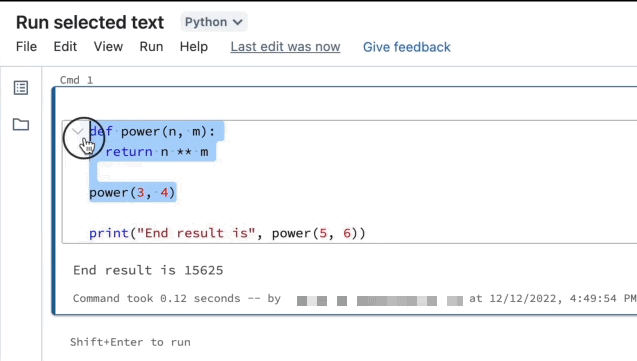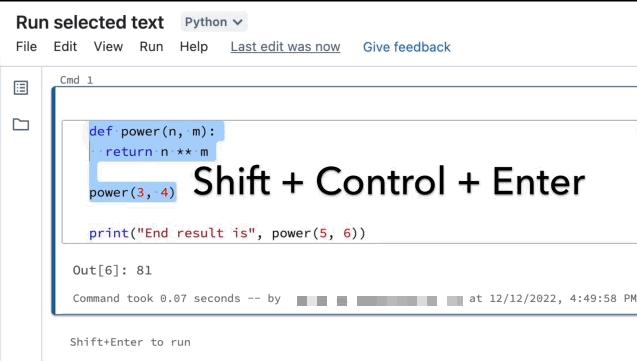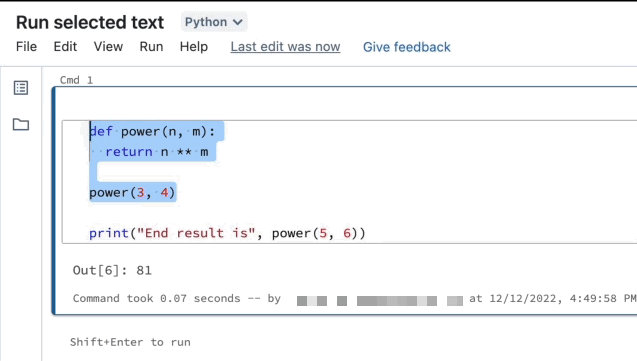
Se si usano lingue miste in una cella, è necessario includere la %<language> riga nella selezione.
Esegui testo selezionato esegue anche codice compresso, se presente nella selezione evidenziata.
Sono supportati comandi di cella speciali, %runad esempio , %pipe %sh .
Non è possibile usare Esegui testo selezionato nelle celle con più schede di output, ovvero celle in cui è stato definito un profilo dati o una visualizzazione.
Formattare le celle del codice
Azure Databricks offre strumenti che consentono di formattare codice Python e SQL nelle celle del notebook in modo rapido e semplice. Questi strumenti riducono lo sforzo di mantenere formattato il codice e consentono di applicare gli stessi standard di codifica nei notebook.
Formattare le celle Python
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Azure Databricks supporta la formattazione del codice Python usando Black all'interno del notebook. Il notebook deve essere collegato a un cluster con black e tokenize-rt i pacchetti Python installati e il formattatore Black viene eseguito nel cluster a cui è collegato il notebook.
In Databricks Runtime 11.3 LTS e versioni successive, Azure Databricks preinstalla black e tokenize-rt. È possibile usare direttamente il formattatore senza dover installare queste librerie.
In Databricks Runtime 10.4 LTS e versioni successive è necessario installare black==22.3.0 e tokenize-rt==4.2.1 da PyPI nel notebook o nel cluster per usare il formattatore Python. È possibile eseguire il comando seguente nel notebook:
%pip install black==22.3.0 tokenize-rt==4.2.1
o installare la libreria nel cluster.
Per altre informazioni sull'installazione delle librerie, vedere Gestione dell'ambiente Python.
Per i file e i notebook nelle cartelle Git di Databricks, è possibile configurare il formattatore Python in base al pyproject.toml file. Per usare questa funzionalità, creare un pyproject.toml file nella directory radice della cartella Git e configurarlo in base al formato di configurazione Black. Modificare la sezione [tool.black] nel file. La configurazione viene applicata quando si formattano file e notebook in tale cartella Git.
Come formattare le celle Python e SQL
È necessario disporre dell'autorizzazione CAN EDIT per il notebook per formattare il codice.
È possibile attivare il formattatore nei modi seguenti:
Formattare una singola cella
- Tasto di scelta rapida: premere CMD+MAIUSC+F.
- Menu di scelta rapida del comando:
- Formato cella SQL: selezionare Formatta SQL nel menu a discesa del contesto del comando di una cella SQL. Questa voce di menu è visibile solo nelle celle del notebook SQL o in quelle con un
%sqllinguaggio magic. - Formattare la cella Python: selezionare Formatta Python nel menu a discesa del contesto del comando di una cella Python. Questa voce di menu è visibile solo nelle celle del notebook Python o in quelle con un
%pythonlinguaggio magic.
- Formato cella SQL: selezionare Formatta SQL nel menu a discesa del contesto del comando di una cella SQL. Questa voce di menu è visibile solo nelle celle del notebook SQL o in quelle con un
- Menu Modifica notebook: selezionare una cella Python o SQL e quindi selezionare Modifica > celle di formato.
Formattare più celle
Selezionare più celle e quindi modifica celle formatta.select multiple cells and then select Edit > Format Cell(s). Se si selezionano celle di più linguaggio, vengono formattate solo le celle SQL e Python. Sono inclusi quelli che usano
%sqle%python.Formattare tutte le celle Python e SQL nel notebook
Selezionare Modifica > formato notebook. Se il notebook contiene più di un linguaggio, vengono formattate solo le celle SQL e Python. Sono inclusi quelli che usano
%sqle%python.
Limitazioni della formattazione del codice
- Black applica gli standard PEP 8 per il rientro a 4 spazi. Il rientro non è configurabile.
- La formattazione di stringhe Python incorporate all'interno di una funzione definita dall'utente SQL non è supportata. Analogamente, la formattazione di stringhe SQL all'interno di una funzione definita dall'utente Python non è supportata.
Cronologia delle versioni
I notebook di Azure Databricks mantengono una cronologia delle versioni dei notebook, consentendo di visualizzare e ripristinare gli snapshot precedenti del notebook. È possibile eseguire le azioni seguenti nelle versioni: aggiungere commenti, ripristinare ed eliminare versioni e cancellare la cronologia delle versioni.
È anche possibile sincronizzare il lavoro in Databricks con un repository Git remoto.
Per accedere alle versioni del notebook, fare clic  sulla barra laterale destra. Verrà visualizzata la cronologia delle versioni del notebook. È anche possibile selezionare Cronologia versioni file>.
sulla barra laterale destra. Verrà visualizzata la cronologia delle versioni del notebook. È anche possibile selezionare Cronologia versioni file>.
Aggiungi un commento
Per aggiungere un commento alla versione più recente:
Fare clic sulla versione.
Fare clic su Salva ora.
Nella finestra di dialogo Salva versione notebook immettere un commento.
Fare clic su Salva. La versione del notebook viene salvata con il commento immesso.
Ripristinare una versione
Per ripristinare una versione:
Fare clic sulla versione.
Fare clic su Ripristina questa versione.
Fare clic su Conferma. La versione selezionata diventa la versione più recente del notebook.
Eliminare una versione
Per eliminare una voce di versione:
Fare clic sulla versione.
Fare clic sull'icona
 del cestino.
del cestino.
Fare clic su Sì, cancellare. La versione selezionata viene eliminata dalla cronologia.
Cancellare la cronologia delle versioni
Impossibile recuperare la cronologia delle versioni dopo che è stata cancellata.
Per cancellare la cronologia delle versioni per un notebook:
- Selezionare File > Cancella cronologia delle versioni.
- Fare clic su Sì, deselezionare. La cronologia delle versioni del notebook viene cancellata.
Linguaggi di codice nei notebook
Impostare la lingua predefinita
La lingua predefinita per il notebook viene visualizzata accanto al nome del notebook.

Per modificare la lingua predefinita, fare clic sul pulsante lingua e selezionare la nuova lingua dal menu a discesa. Per assicurarsi che i comandi esistenti continuino a funzionare, i comandi della lingua predefinita precedente vengono preceduti automaticamente da un comando magic del linguaggio.
Combinazioni di lingue
Per impostazione predefinita, le celle usano la lingua predefinita del notebook. È possibile eseguire l'override della lingua predefinita in una cella facendo clic sul pulsante lingua e selezionando una lingua dal menu a discesa.
In alternativa, è possibile usare il comando %<language> magic del linguaggio all'inizio di una cella. I comandi magic supportati sono: %python, %r, %scalae %sql.
Nota
Quando si richiama un comando magic del linguaggio, il comando viene inviato a REPL nel contesto di esecuzione per il notebook. Le variabili definite in un linguaggio (e quindi nella LIBRERIA REPL per tale lingua) non sono disponibili in REPL di un'altra lingua. I REPOSITORY possono condividere lo stato solo tramite risorse esterne, ad esempio file in DBFS o oggetti nell'archiviazione oggetti.
I notebook supportano anche alcuni comandi magic ausiliari:
%sh: consente di eseguire il codice della shell nel notebook. Per interrompere la cella se il comando shell ha uno stato di uscita diverso da zero, aggiungere l'opzione-e. Questo comando viene eseguito solo sul driver Apache Spark e non sui ruoli di lavoro. Per eseguire un comando shell in tutti i nodi, usare uno script init.%fs: consente di usaredbutilsi comandi del file system. Ad esempio, per eseguire ildbutils.fs.lscomando per elencare i file, è possibile specificare%fs ls. Per altre informazioni, vedere Usare i file in Azure Databricks.%md: consente di includere vari tipi di documentazione, tra cui testo, immagini, formule matematiche ed equazioni. Vedi la sezione successiva.
Evidenziazione e completamento automatico della sintassi SQL nei comandi Python
L'evidenziazione della sintassi e il completamento automatico di SQL sono disponibili quando si usa SQL all'interno di un comando Python, ad esempio in un spark.sql comando.
Esplorare i risultati delle celle SQL nei notebook Python con Python
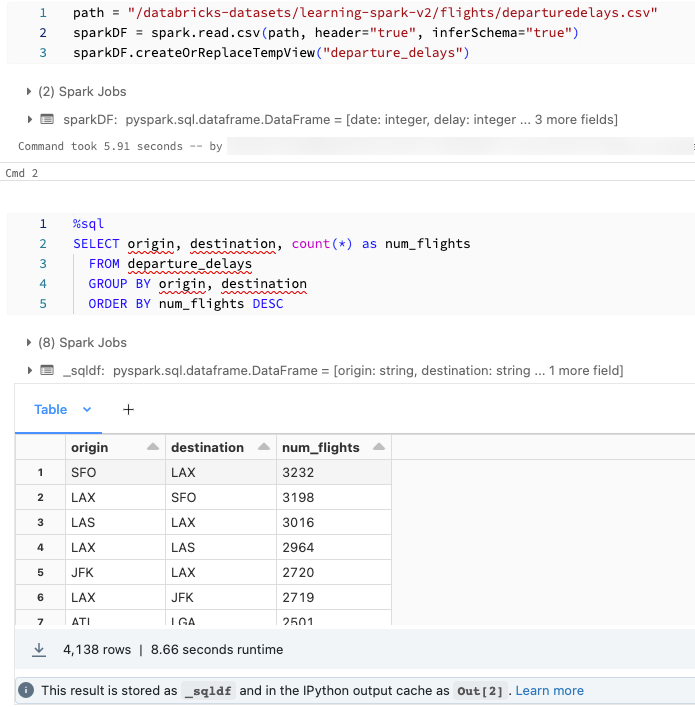
È possibile caricare i dati usando SQL ed esplorarli usando Python. In un notebook Python di Databricks i risultati della tabella di una cella del linguaggio SQL vengono resi automaticamente disponibili come dataframe Python assegnato alla variabile _sqldf.
In Databricks Runtime 13.3 LTS e versioni successive è anche possibile accedere al risultato del dataframe usando il sistema di memorizzazione nella cache di output di IPython. Il contatore del prompt viene visualizzato nel messaggio di output visualizzato nella parte inferiore dei risultati della cella. Per l'esempio illustrato, si fa riferimento al risultato come Out[2].
Nota
La variabile
_sqldfpuò essere riassegnata ogni volta che viene eseguita una%sqlcella. Per evitare di perdere il riferimento al risultato del dataframe, assegnarlo a un nuovo nome di variabile prima di eseguire la cella successiva%sql:new_dataframe_name = _sqldfSe la query usa un widget per la parametrizzazione, i risultati non sono disponibili come dataframe Python.
Se la query usa le parole chiave
CACHE TABLEoUNCACHE TABLE, i risultati non sono disponibili come dataframe Python.
Lo screenshot mostra un esempio:
Eseguire celle SQL in parallelo
Mentre un comando è in esecuzione e il notebook è collegato a un cluster interattivo, è possibile eseguire una cella SQL contemporaneamente con il comando corrente. La cella SQL viene eseguita in una nuova sessione parallela.
Per eseguire una cella in parallelo:
Fare clic su Esegui. La cella viene eseguita immediatamente.
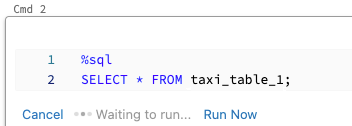
Poiché la cella viene eseguita in una nuova sessione, le visualizzazioni temporanee, le funzioni definite dall'utente e il dataframe Python implicito (_sqldf) non sono supportate per le celle eseguite in parallelo. Inoltre, i nomi predefiniti del catalogo e del database vengono usati durante l'esecuzione parallela. Se il codice fa riferimento a una tabella in un catalogo o un database diverso, è necessario specificare il nome della tabella usando lo spazio dei nomi a tre livelli (catalog.schema.table).
Eseguire celle SQL in un'istanza di SQL Warehouse
È possibile eseguire comandi SQL in un notebook di Databricks in un'istanza di SQL Warehouse, un tipo di calcolo ottimizzato per l'analisi SQL. Vedere Usare un notebook con un'istanza di SQL Warehouse.
Visualizzare immagini
Per visualizzare le immagini archiviate nell'archivio file, usare la sintassi seguente:
%md

Si supponga, ad esempio, di avere il file di immagine del logo Databricks in FileStore:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
Quando si include il codice seguente in una cella Markdown:

viene eseguito il rendering dell'immagine nella cella:

Visualizzare equazioni matematiche
I notebook supportano KaTeX per la visualizzazione di formule matematiche ed equazioni. ad esempio:
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
esegue il rendering come:
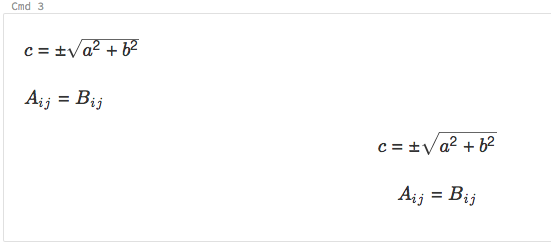
e
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
esegue il rendering come:
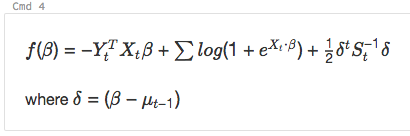
Includi HTML
È possibile includere HTML in un notebook usando la funzione displayHTML. Per un esempio di come eseguire questa operazione, vedere HTML, D3 e SVG nei notebook .
Nota
L'iframe displayHTML viene servito dal dominio databricksusercontent.com e la sandbox iframe include l'attributo allow-same-origin . databricksusercontent.com deve essere accessibile dal browser. Se è attualmente bloccato dalla rete aziendale, deve essere aggiunto a un elenco di elementi consentiti.
Collegamento ad altri notebook
È possibile collegarsi ad altri notebook o cartelle nelle celle Markdown usando percorsi relativi. Specificare l'attributo href di un tag di ancoraggio come percorso relativo, a partire da e $ quindi seguire lo stesso modello dei file system Unix:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>