Eventi
31 mar, 23 - 2 apr, 23
Il più grande evento di apprendimento di Fabric, Power BI e SQL. 31 marzo - 2 aprile. Usare il codice FABINSIDER per salvare $400.
Iscriviti oggi stessoQuesto browser non è più supportato.
Esegui l'aggiornamento a Microsoft Edge per sfruttare i vantaggi di funzionalità più recenti, aggiornamenti della sicurezza e supporto tecnico.
Questo articolo descrive come utilizzare l'attività di copia nella pipeline di dati per copiare dati da e verso Archiviazione tabelle di Azure.
Per la configurazione di ogni scheda nell'attività di copia, consultare rispettivamente le sezioni seguenti.
Consultare la guida sulle Impostazioni generali per configurare la scheda Impostazioni generali.
Passare alla scheda Origine per configurare l'origine dell'attività di copia. Per la configurazione dettagliata, vedere il contenuto seguente.
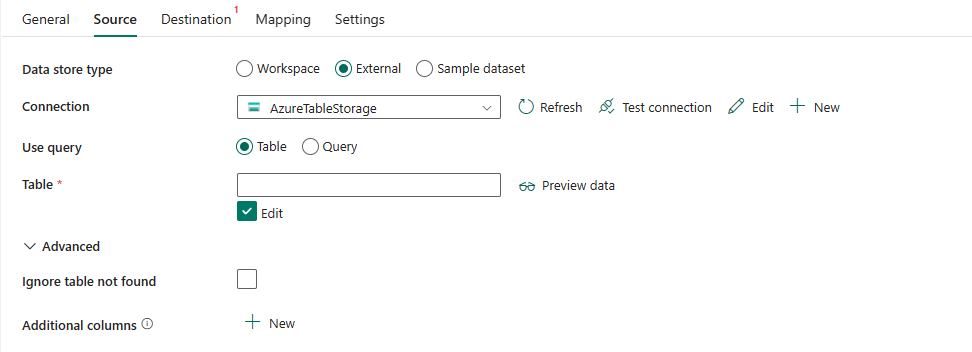
Le seguenti tre proprietà sono obbligatorie:
Tipo di archivio dati: selezionare Esterno.
Connessione: selezionare una connessione di Archiviazione tabelle di Azure dall'elenco delle connessioni. Se non esiste alcuna connessione, creare una nuova connessione di Archiviazione tabelle di Azure selezionando Nuovo.
Usa query: specifica il modo in cui leggere i dati. Selezionare Tabella per leggere i dati dalla tabella specificata oppure selezionare Query per leggere i dati usando le query.
Se si seleziona Tabella:

Se si seleziona Query:
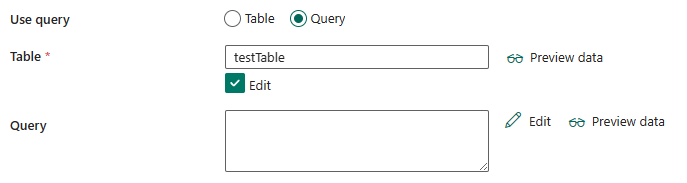
Tabella: specificare il nome della tabella nell'istanza di database di Archiviazione tabelle di Azure. Selezionare la tabella dall'elenco a discesa o immettere manualmente il nome selezionando Modifica.
Query: specificare la query di archiviazione tabella personalizzata per leggere i dati. La query di origine è una mappa diretta dall'opzione di query $filter supportata da Archiviazione tabelle di Azure; per ulteriori informazioni sulla sintassi, consulta questo articolo.
Nota
Il timeout dell'operazione di query di Tabella di Azure è di 30 secondi, secondo quanto applicato dal servizio tabelle di Azure. Per informazioni su come ottimizzare la query, vedere l'articolo Progettazione per le query.
In Avanzato è possibile specificare i seguenti campi:
Ignora tabella non trovata: specificare se consentire l'eccezione della tabella inesistente. È non selezionata per impostazione predefinita.
Colonne aggiuntive: aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. Per quest'ultimo è supportata l'espressione.
Passare alla scheda Destinazione per configurare la destinazione dell'attività di copia. Per la configurazione dettagliata, vedere il contenuto seguente.
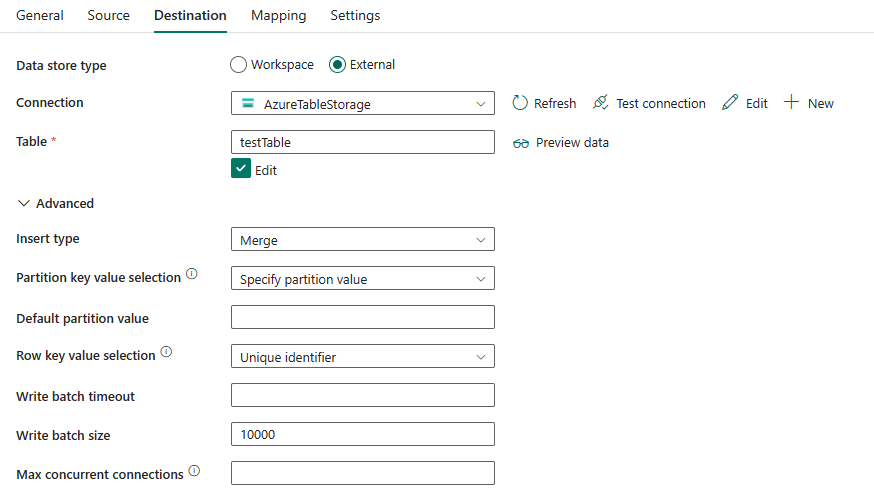
Le seguenti tre proprietà sono obbligatorie:
In Avanzato è possibile specificare i seguenti campi:
Tipo di inserimento: seleziona la modalità per inserire i dati nella tabella di Azure. Le modalità sono Unisci e Sostituisci. Questa proprietà verifica se per le righe esistenti nella tabella di output con chiavi di partizione e di riga corrispondenti i valori vengono sostituiti o uniti. Questa impostazione si applica a livello di riga e non a livello di tabella. Nessuna delle due opzioni consente di eliminare righe nella tabella di output che non esistono nell'input. Per scoprire come funzionano le impostazioni merge e replace, vedereInsert or Merge Entity (Inserire o unire un'entità) e Insert or Replace Entity (Inserire o sostituire un'entità).
Selezione del valore della chiave di partizione: selezionare tra Specifica il valore della partizione o Usa la colonna di destinazione. Il valore della chiave di partizione può essere un valore fisso oppure può accettare un valore da una colonna di destinazione.
Se si seleziona Specifica il valore della partizione:
Se si seleziona Usa colonna di destinazione:
Selezione del valore della chiave di riga: selezionare da Identificatore univoco o Usa colonna di destinazione. Il valore della chiave di riga può essere un identificatore univoco generato automaticamente oppure può accettare valore da una colonna di destinazione.
Se si seleziona Usa colonna di destinazione:
Dimensione batch di scrittura: inserisce i dati nella tabella di Azure quando viene raggiunta la dimensione del batch di scrittura specificata. I valori consentiti sono integer (numero di righe). Il valore predefinito è 10.000.
Timeout del batch di scrittura: inserisce i dati nella tabella di Azure quando viene raggiunto il timeout del batch di scrittura specificato. Il valore consentito è timespan.
Numero massimo di connessioni simultanee: limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee
Per la configurazione della scheda Mapping, vedere Configurare i mapping nella scheda Mapping.
Per la configurazione della scheda Impostazioni, vedere Configurare le altre impostazioni nella scheda Impostazioni.
La tabella seguente contiene altre informazioni sull'attività di copia in Archiviazione tabelle di Azure.
| Nome | Descrizione | valore | Richiesto | Proprietà dello script JSON |
|---|---|---|---|---|
| Tipo di archivio dati | Tipo di archivio dati. | Esterno | Sì | / |
| Connessione | Connessione all'archivio dati di origine. | < connessione di Archiviazione tabelle di Azure > | Sì | connection |
| Usa query | Modalità di lettura dei dati. Applicare Tabella per leggere i dati dalla tabella specificata o applicare Query per leggere i dati usando le query. | • Tabella • Query |
Sì | / |
| Tabella | Nome della tabella nell'istanza di database di Archiviazione tabelle di Azure. | < nome alla tabella > | Sì | tableName |
| Query | Specificare la query di Archiviazione della tabella personalizzata per leggere i dati. La query di origine è una mappa diretta dall'opzione di query $filter supportata da Archiviazione tabelle di Azure; per ulteriori informazioni sulla sintassi, consulta questo articolo. |
< query > | No | AzureTableSourceQuery |
| Ignora tabella non trovata | Indica se consentire l'eccezione di tabella non esistente. | selezionato o non selezionato (impostazione predefinita) | No | azureTableSourceIgnoreTableNotFound: true o false (valore predefinito) |
| Colonne aggiuntive | Aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. Per quest'ultimo è supportata l'espressione. | • Name • Valore |
No | additionalColumns: • nome • valore |
| Nome | Descrizione | valore | Richiesto | Proprietà dello script JSON |
|---|---|---|---|---|
| Tipo di archivio dati | Tipo di archivio dati. | Esterno | Sì | / |
| Connessione | Connessione all'archivio dati di destinazione. | < connessione di Archiviazione tabelle di Azure > | Sì | connection |
| Tabella | Nome della tabella nell'istanza di database di Archiviazione tabelle di Azure. | < nome alla tabella > | Sì | tableName |
| Tipo di inserimento | Modalità di inserimento dei dati in una tabella di Azure. Questa proprietà verifica se per le righe esistenti nella tabella di output con chiavi di partizione e di riga corrispondenti i valori vengono sostituiti o uniti. | • Unisci • Sostituisci |
No | azureTableInsertType: • unisci • sostituisci |
| Selezione del valore della chiave di partizione | Il valore della chiave di partizione può essere un valore fisso oppure può accettare un valore da una colonna di destinazione. | • Specifica il valore della partizione • Usa la colonna di destinazione |
No | / |
| Valore predefinito della partizione | Valore predefinito della chiave di partizione che può essere usato dalla destinazione | < valore predefinito della partizione > | No | azureTableDefaultPartitionKeyValue |
| Colonna chiave di partizione | Il nome della colonna i cui valori vengono usati come chiavi di partizione. Se non specificato, viene usato "AzureTableDefaultPartitionKeyValue" come chiave di partizione. | < colonna chiave di partizione > | No | azureTablePartitionKeyName |
| Selezione del valore della chiave di riga | Il valore della chiave di riga può essere un identificatore univoco generato automaticamente oppure può accettare valore da una colonna di destinazione. | • Identificatore univoco • Usa la colonna di destinazione |
No | / |
| Colonna chiave di riga | Il nome della colonna i cui valori vengono usati come chiave di riga. Se non specificato, usare un GUID per ogni riga. | < colonna chiave di riga > | No | azureTableRowKeyName |
| Dimensione del batch di scrittura | Inserisce i dati nella tabella di Azure quando viene raggiunta la dimensione del batch di scrittura. | integer (il valore predefinito è 10.000) |
No | writeBatchSize |
| Timeout del batch di scrittura | Inserisce i dati nella tabella di Azure quando viene raggiunto il timeout del batch di scrittura | timespan | No | writeBatchTimeout |
| Numero massimo di connessioni simultanee | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | < numero massimo di connessioni simultanee > | No | maxConcurrentConnections |
Eventi
31 mar, 23 - 2 apr, 23
Il più grande evento di apprendimento di Fabric, Power BI e SQL. 31 marzo - 2 aprile. Usare il codice FABINSIDER per salvare $400.
Iscriviti oggi stesso