Migrazione: pool SQL dedicati di Azure Synapse Analytics a Fabric
Si applica a: ![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
Questo articolo illustra in dettaglio la strategia, le considerazioni e i metodi di migrazione del data warehousing nei pool SQL dedicati di Azure Synapse Analytics in Microsoft Fabric Warehouse.
Introduzione alla migrazione
Come Microsoft ha introdotto Microsoft Fabric, una soluzione di analisi SaaS all-in-one per le aziende che offre una suite completa di servizi, tra cui Data Factory, Ingegneria dei dati, Archiviazione dati, data science, intelligence in tempo reale e Power BI.
Questo articolo è incentrato sulle opzioni per la migrazione dello schema (DDL), la migrazione del codice del database (DML) e la migrazione dei dati. Microsoft offre diverse opzioni e qui vengono illustrate in dettaglio ogni opzione e vengono fornite indicazioni su quali di queste opzioni è consigliabile prendere in considerazione per il proprio scenario. Questo articolo usa il benchmark del settore TPC-DS per illustrare e testare le prestazioni. Il risultato effettivo può variare a seconda di molti fattori, tra cui il tipo di dati, i tipi di dati, la larghezza delle tabelle, la latenza dell'origine dati e così via.
Preparare la migrazione
Pianificare attentamente il progetto di migrazione prima di iniziare e assicurarsi che lo schema, il codice e i dati siano compatibili con Fabric Warehouse. Esistono alcune limitazioni da considerare. Quantificare il lavoro di refactoring degli elementi incompatibili, nonché qualsiasi altra risorsa necessaria prima del recapito della migrazione.
Un altro obiettivo chiave della pianificazione è modificare la progettazione per garantire che la soluzione sfrutta appieno le prestazioni elevate delle query che Fabric Warehouse è progettato per offrire. La progettazione di data warehouse ai fini della scalabilità introduce modelli di progettazione unici, pertanto gli approcci tradizionali non si rivelano sempre ottimali. Esaminare le linee guida sulle prestazioni di Fabric Warehouse, perché anche se alcune modifiche alla progettazione possono essere apportate dopo la migrazione, le modifiche apportate in precedenza nel processo consentono di risparmiare tempo e impegno. La migrazione da una tecnologia/ambiente a un'altra è sempre un grande sforzo.
Il diagramma seguente illustra il ciclo di vita della migrazione che elenca i pilastri principali costituiti da valutazione e valutazione, pianificazione e progettazione, migrazione, monitoraggio e governance, ottimizzare e modernizzare i pilastri con le attività associate in ogni pilastro per pianificare e preparare la migrazione senza problemi.

Runbook per la migrazione
Considerare le attività seguenti come runbook di pianificazione per la migrazione dai pool SQL dedicati di Synapse a Fabric Warehouse.
- Valutare e valutare
- Identificare obiettivi e motivazioni. Stabilire risultati chiari desiderati.
- Individuazione, valutazione e baseline dell'architettura esistente.
- Identificare gli stakeholder e gli sponsor principali.
- Definire l'ambito degli elementi di cui eseguire la migrazione.
- Iniziare da piccolo e semplice, prepararsi per più migrazioni di piccole dimensioni.
- Iniziare a monitorare e documentare tutte le fasi del processo.
- Creare un inventario di dati e processi di cui eseguire la migrazione.
- Definire le modifiche al modello di dati (se presenti).
- Configurare l'area di lavoro infrastruttura.
- Qual è il tuo set di competenze/preferenza?
- Automatizzare laddove possibile.
- Usare gli strumenti e le funzionalità predefiniti di Azure per ridurre le attività di migrazione.
- Eseguire preventivamente il training del personale sulla nuova piattaforma.
- Identificare le esigenze di upskilling e gli asset di training, tra cui Microsoft Learn.
- Pianificare e progettare
- Definire l'architettura desiderata.
- Selezionare il metodo/strumenti per la migrazione per eseguire le attività seguenti:
- Estrazione dei dati dall'origine.
- Conversione dello schema (DDL), inclusi i metadati per tabelle e viste
- Inserimento dati, inclusi i dati cronologici.
- Se necessario, ricompiginare il modello di dati usando nuove prestazioni e scalabilità della piattaforma.
- Migrazione del codice del database (DML).
- Eseguire la migrazione o il refactoring di stored procedure e processi aziendali.
- Inventariare ed estrarre le funzionalità di sicurezza e le autorizzazioni per gli oggetti dall'origine.
- Progettare e pianificare la sostituzione/modifica dei processi ETL/ELT esistenti per il caricamento incrementale.
- Creare processi ETL/ELT paralleli nel nuovo ambiente.
- Preparare un piano di migrazione dettagliato.
- Eseguire il mapping dello stato corrente al nuovo stato desiderato.
- Migrazione
- Eseguire schema, dati, migrazione del codice.
- Estrazione dei dati dall'origine.
- Conversione dello schema (DDL)
- Inserimento dati
- Migrazione del codice del database (DML).
- Se necessario, ridimensionare temporaneamente le risorse del pool SQL dedicato per facilitare la velocità della migrazione.
- Applicare la sicurezza e le autorizzazioni.
- Eseguire la migrazione dei processi ETL/ELT esistenti per il caricamento incrementale.
- Eseguire la migrazione o il refactoring dei processi di caricamento incrementale ETL/ELT.
- Testare e confrontare i processi di carico con incrementi paralleli.
- Adattare il piano di migrazione dettaglio in base alle esigenze.
- Eseguire schema, dati, migrazione del codice.
- Monitorare e gestire
- Eseguire in parallelo, confrontare con l'ambiente di origine.
- Testare applicazioni, piattaforme di business intelligence e strumenti di query.
- Eseguire il benchmark delle prestazioni delle query e ottimizzarle.
- Monitorare e gestire costi, sicurezza e prestazioni.
- Benchmark e valutazione della governance.
- Eseguire in parallelo, confrontare con l'ambiente di origine.
- Ottimizzare e modernizzare
- Quando l'azienda è confortevole, eseguire la transizione di applicazioni e piattaforme di report primari a Fabric.
- Aumentare o ridurre le risorse man mano che il carico di lavoro passa da Azure Synapse Analytics a Microsoft Fabric.
- Creare un modello ripetibile dall'esperienza acquisita per le migrazioni future. Eseguire l’iterazione.
- Identificare le opportunità per l'ottimizzazione dei costi, la sicurezza, la scalabilità e l'eccellenza operativa
- Identificare le opportunità per modernizzare il patrimonio di dati con le funzionalità più recenti di Fabric.
- Quando l'azienda è confortevole, eseguire la transizione di applicazioni e piattaforme di report primari a Fabric.
'Lift and shift' o modernizzare?
In generale, esistono due tipi di scenari di migrazione, indipendentemente dallo scopo e dall'ambito della migrazione pianificata: lift-and-shift così come sono, o un approccio in più fasi che incorpora le modifiche dell'architettura e del codice.
Lift-and-shift
In una migrazione in modalità lift-and-shift, viene eseguita la migrazione di un modello di dati esistente con modifiche minime al nuovo warehouse di infrastruttura. Questo approccio riduce al minimo i rischi e i tempi di migrazione riducendo il nuovo lavoro necessario per sfruttare i vantaggi della migrazione.
La migrazione lift-and-shift è ideale per questi scenari:
- Si dispone di un ambiente esistente con un numero ridotto di data mart di cui eseguire la migrazione.
- Si dispone di un ambiente esistente con dati già in uno schema star o snowflake ben progettato.
- Si è sotto pressione sul tempo e i costi per passare a Fabric Warehouse.
In sintesi, questo approccio funziona bene per i carichi di lavoro ottimizzati con l'ambiente di pool SQL dedicati di Synapse corrente e pertanto non richiede modifiche importanti in Fabric.
Modernizzare in un approccio in più fasi con modifiche dell'architettura
Se un data warehouse legacy si è evoluto in un lungo periodo di tempo, potrebbe essere necessario riprogettarlo per mantenere i livelli di prestazioni necessari.
È anche possibile riprogettare l'architettura per sfruttare i nuovi motori e le nuove funzionalità disponibili nell'area di lavoro infrastruttura.
Differenze di progettazione: pool SQL dedicati di Synapse e Fabric Warehouse
Prendere in considerazione le differenze di data warehousing di Azure Synapse e Microsoft Fabric seguenti, confrontando i pool SQL dedicati con Fabric Warehouse.
Considerazioni sulle tabelle
Quando si esegue la migrazione di tabelle tra ambienti diversi, in genere solo i dati non elaborati e i metadati vengono migrati fisicamente. Altri elementi di database del sistema di origine, ad esempio gli indici, in genere non vengono trasferiti perché potrebbero non essere necessari o potrebbero essere implementati in modo diverso nel nuovo ambiente.
Le ottimizzazioni delle prestazioni nell'ambiente di origine, ad esempio gli indici, indicano dove è possibile aggiungere l'ottimizzazione delle prestazioni in un nuovo ambiente, ma ora Fabric si occupa automaticamente di questa funzionalità.
Considerazioni su T-SQL
Esistono diverse differenze di sintassi DML (Data Manipulation Language) da tenere presente. Fare riferimento all'area di attacco T-SQL in Microsoft Fabric. Si consideri anche una valutazione del codice quando si scelgono metodi di migrazione per il codice del database (DML).
A seconda delle differenze di parità al momento della migrazione, potrebbe essere necessario riscrivere parti del codice DML T-SQL.
Differenze di mapping dei tipi di dati
Esistono diverse differenze tra i tipi di dati in Fabric Warehouse. Per altre informazioni, vedere Tipi di dati in Microsoft Fabric.
La tabella seguente fornisce il mapping dei tipi di dati supportati dai pool SQL dedicati di Synapse a Fabric Warehouse.
| Pool SQL dedicati di Synapse | Magazzino infrastruttura |
|---|---|
| money | decimal(19,4) |
| smallmoney | decimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| nchar | char |
| nvarchar | varchar |
| tinyint | smallint |
| binary | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 non archivia le informazioni aggiuntive sulla differenza di fuso orario archiviate in. Poiché il tipo di dati datetimeoffset non è attualmente supportato in Fabric Warehouse, i dati di offset del fuso orario devono essere estratti in una colonna separata.
Metodi di migrazione dello schema, del codice e dei dati
Esaminare e identificare quali di queste opzioni si adattano allo scenario, ai set di competenze del personale e alle caratteristiche dei dati. Le opzioni scelte dipenderanno dall'esperienza, dalla preferenza e dai vantaggi offerti da ognuno degli strumenti. L'obiettivo è quello di continuare a sviluppare strumenti di migrazione che attenuano l'attrito e l'intervento manuale per rendere l'esperienza di migrazione senza problemi.
Questa tabella riepiloga le informazioni per lo schema dei dati (DDL), il codice del database (DML) e i metodi di migrazione dei dati. Più avanti in questo articolo si espande ulteriormente ogni scenario, collegato nella colonna Opzione .
| Numero opzione | Opzione | Funzione | Competenza/Preferenza | Scenario |
|---|---|---|---|---|
| 1 | Data Factory | Conversione dello schema (DDL) Estrazione dei dati Inserimento dati |
ADF/Pipeline | Tutto semplificato in uno schema (DDL) e migrazione dei dati. Consigliato per le tabelle delle dimensioni. |
| 2 | Data Factory con partizione | Conversione dello schema (DDL) Estrazione dei dati Inserimento dati |
ADF/Pipeline | L'uso delle opzioni di partizionamento per aumentare il parallelismo di lettura/scrittura fornisce una velocità effettiva 10 volte rispetto all'opzione 1, consigliata per le tabelle dei fatti. |
| 3 | Data Factory con codice accelerato | Conversione dello schema (DDL) | ADF/Pipeline | Convertire ed eseguire prima la migrazione dello schema (DDL), quindi usare CETAS per estrarre e COPIARE/Data Factory per inserire dati per ottenere prestazioni di inserimento complessive ottimali. |
| 4 | Codice accelerato delle stored procedure | Conversione dello schema (DDL) Estrazione dei dati Valutazione del codice |
T-SQL | Utente SQL che usa l'IDE con un controllo più granulare sulle attività da usare. Usare COPY/Data Factory per inserire dati. |
| 5 | estensione database SQL progetto per Azure Data Studio | Conversione dello schema (DDL) Estrazione dei dati Valutazione del codice |
SQL Project | database SQL Project per la distribuzione con l'integrazione dell'opzione 4. Usare COPY o Data Factory per inserire dati. |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | Estrazione dei dati | T-SQL | Estrarre dati convenienti e ad alte prestazioni in Azure Data Lake Storage (ADLS) Gen2. Usare COPY/Data Factory per inserire dati. |
| 7 | Eseguire la migrazione con dbt | Conversione dello schema (DDL) conversione del codice di database (DML) |
dbt | Gli utenti dbt esistenti possono usare l'adapter dbt Fabric per convertire il file DDL e DML. È quindi necessario eseguire la migrazione dei dati usando altre opzioni in questa tabella. |
Scegliere un carico di lavoro per la migrazione iniziale
Quando si decide dove iniziare il pool SQL dedicato di Synapse al progetto di migrazione fabric Warehouse, scegliere un'area del carico di lavoro in cui è possibile:
- Dimostra la redditività della migrazione a Fabric Warehouse offrendo rapidamente i vantaggi del nuovo ambiente. Iniziare da piccolo e semplice, prepararsi per più migrazioni di piccole dimensioni.
- Consentire al personale tecnico interno di acquisire esperienza pertinente con i processi e gli strumenti usati durante la migrazione ad altre aree.
- Creare un modello per altre migrazioni specifiche per l'ambiente Synapse di origine e gli strumenti e i processi disponibili.
Suggerimento
Creare un inventario degli oggetti di cui è necessario eseguire la migrazione e documentare il processo di migrazione dall'inizio alla fine, in modo che possa essere ripetuto per altri pool o carichi di lavoro SQL dedicati.
Il volume dei dati migrati in una migrazione iniziale deve essere sufficientemente grande da illustrare le funzionalità e i vantaggi dell'ambiente Fabric Warehouse, ma non troppo grande per illustrare rapidamente il valore. Una dimensione nell'intervallo da 1 a 10 terabyte è tipica.
Migrazione con Fabric Data Factory
In questa sezione vengono illustrate le opzioni che usano Data Factory per l'utente con poco codice o senza codice che ha familiarità con Azure Data Factory e Synapse Pipeline. Questa opzione di trascinamento della selezione dell'interfaccia utente fornisce un semplice passaggio per convertire il DDL ed eseguire la migrazione dei dati.
Fabric Data Factory può eseguire le attività seguenti:
- Convertire lo schema (DDL) nella sintassi fabric warehouse.
- Creare lo schema (DDL) in Fabric Warehouse.
- Eseguire la migrazione dei dati a Fabric Warehouse.
Opzione 1. Migrazione di schemi/dati - Copia guidata e attività di copia ForEach
Questo metodo usa l'assistente copia di Data Factory per connettersi al pool SQL dedicato di origine, convertire la sintassi DDL del pool SQL dedicato in Infrastruttura e copiare i dati in Fabric Warehouse. È possibile selezionare 1 o più tabelle di destinazione (per il set di dati TPC-DS sono presenti 22 tabelle). Genera il ciclo ForEach per scorrere l'elenco di tabelle selezionate nell'interfaccia utente e generare 22 thread di attività di copia parallela.
- 22 Le query SELECT (una per ogni tabella selezionata) sono state generate ed eseguite nel pool SQL dedicato.
- Assicurarsi di disporre della classe DWU e della risorsa appropriata per consentire l'esecuzione delle query generate. Per questo caso, è necessario un minimo di DWU1000 con
staticrc10per consentire un massimo di 32 query per gestire 22 query inviate. - La copia diretta di dati dal pool SQL dedicato a Fabric Warehouse richiede la gestione temporanea. Il processo di inserimento è costituito da due fasi.
- La prima fase consiste nell'estrarre i dati dal pool SQL dedicato in ADLS e viene definito staging.
- La seconda fase consiste nell'inserire i dati dalla gestione temporanea a Fabric Warehouse. La maggior parte dei tempi di inserimento dei dati è nella fase di gestione temporanea. In sintesi, la gestione temporanea ha un impatto enorme sulle prestazioni di inserimento.
Uso consigliato
L'uso della Copia guidata per generare un forEach fornisce un'interfaccia utente semplice per convertire DDL e inserire le tabelle selezionate dal pool SQL dedicato a Fabric Warehouse in un unico passaggio.
Tuttavia, non è ottimale con la velocità effettiva complessiva. Il requisito di usare la gestione temporanea, la necessità di parallelizzare la lettura e la scrittura per il passaggio "Da origine a fase" sono i fattori principali per la latenza delle prestazioni. È consigliabile usare questa opzione solo per le tabelle delle dimensioni.
Opzione 2. Migrazione DDL/Dati - Pipeline di dati tramite l'opzione di partizione
Per migliorare la velocità effettiva per caricare tabelle dei fatti di dimensioni maggiori usando la pipeline di dati di Fabric, è consigliabile usare l'attività di copia per ogni tabella dei fatti con l'opzione di partizione. Ciò garantisce prestazioni ottimali con attività Copy.
È possibile usare il partizionamento fisico della tabella di origine, se disponibile. Se la tabella non dispone del partizionamento fisico, è necessario specificare la colonna della partizione e specificare valori min/max per usare il partizionamento dinamico. Nello screenshot seguente le opzioni Origine pipeline di dati specificano un intervallo dinamico di partizioni in base alla ws_sold_date_sk colonna.
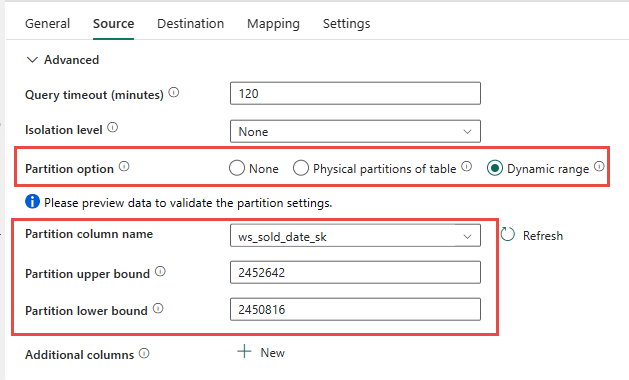
Anche se l'uso della partizione può aumentare la velocità effettiva con la fase di gestione temporanea, esistono alcune considerazioni per apportare le modifiche appropriate:
- A seconda dell'intervallo di partizioni, potrebbe potenzialmente usare tutti gli slot di concorrenza perché potrebbe generare più di 128 query nel pool SQL dedicato.
- È necessario ridimensionare fino a un minimo di DWU6000 per consentire l'esecuzione di tutte le query.
- Ad esempio, per la tabella TPC-DS
web_salessono state inviate 163 query al pool SQL dedicato. In DWU6000 sono state eseguite 128 query mentre sono state accodate 35 query. - La partizione dinamica seleziona automaticamente la partizione di intervallo. In questo caso, un intervallo di 11 giorni per ogni query SELECT inviata al pool SQL dedicato. Ad esempio:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Uso consigliato
Per le tabelle dei fatti, è consigliabile usare Data Factory con l'opzione di partizionamento per aumentare la velocità effettiva.
Tuttavia, per consentire l'esecuzione delle query di estrazione, le letture parallelizzate aumentate richiedono un pool SQL dedicato per la scalabilità fino a una DWU superiore. Sfruttando il partizionamento, la velocità è stata migliorata 10 volte su nessuna opzione di partizione. È possibile aumentare la DWU per ottenere una velocità effettiva aggiuntiva tramite risorse di calcolo, ma il pool SQL dedicato ha un massimo di 128 query attive consentite.
Opzione 3. Migrazione DDL - Copia guidata Attività di copia foreach
Le due opzioni precedenti sono opzioni di migrazione dei dati ideali per i database più piccoli . Tuttavia, se è necessaria una velocità effettiva più elevata, è consigliabile usare un'opzione alternativa:
- Estrarre i dati dal pool SQL dedicato ad ADLS, riducendo quindi il sovraccarico delle prestazioni della fase.
- Usare Data Factory o il comando COPY per inserire i dati in Fabric Warehouse.
Uso consigliato
È possibile continuare a usare Data Factory per convertire lo schema (DDL). Usando la Copia guidata è possibile selezionare la tabella specifica o Tutte le tabelle. Per impostazione predefinita, esegue la migrazione dello schema e dei dati in un unico passaggio, estraendo lo schema senza righe, usando la condizione false, TOP 0 nell'istruzione di query.
L'esempio di codice seguente illustra la migrazione dello schema (DDL) con Data Factory.
Esempio di codice: migrazione dello schema (DDL) con Data Factory
È possibile usare pipeline di dati di Infrastruttura per eseguire facilmente la migrazione tramite DDL (schemi) per oggetti tabella da qualsiasi database SQL di Azure di origine o pool SQL dedicato. Questa pipeline di dati esegue la migrazione dello schema (DDL) per le tabelle del pool SQL dedicato di origine a Fabric Warehouse.
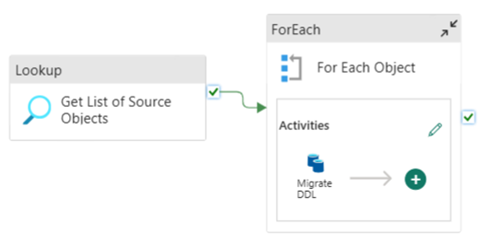
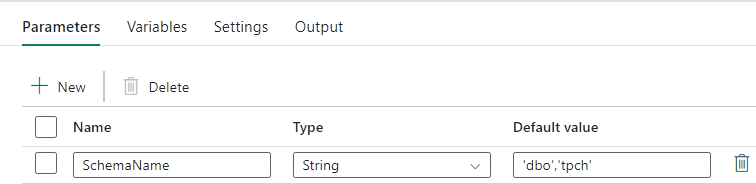
Progettazione della pipeline: parametri
Questa pipeline di dati accetta un parametro SchemaName, che consente di specificare gli schemi di cui eseguire la migrazione. Lo dbo schema è l'impostazione predefinita.
Nel campo Valore predefinito immettere un elenco delimitato da virgole dello schema di tabella che indica gli schemi di cui eseguire la migrazione: 'dbo','tpch' per fornire due schemi e dbo tpch.
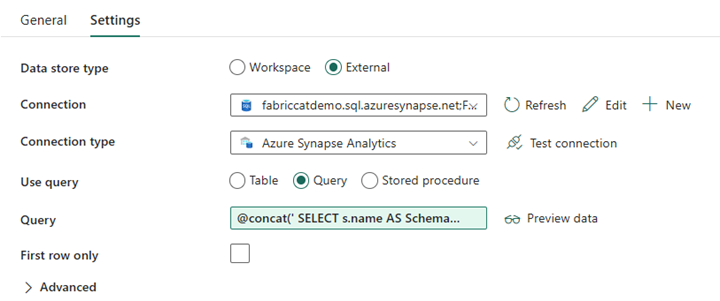
Progettazione della pipeline: attività di ricerca
Creare un'attività di ricerca e impostare Connessione in modo che punti al database di origine.
Nella scheda Impostazioni :
Impostare Tipo di archivio dati su Esterno.
La connessione è il pool SQL dedicato di Azure Synapse. Il tipo di connessione è Azure Synapse Analytics.
Usare la query è impostata su Query.
Il campo Query deve essere compilato usando un'espressione dinamica, consentendo l'uso del parametro SchemaName in una query che restituisce un elenco di tabelle di origine di destinazione. Selezionare Query e quindi Aggiungi contenuto dinamico.
Questa espressione all'interno dell'attività LookUp genera un'istruzione SQL per eseguire query sulle viste di sistema per recuperare un elenco di schemi e tabelle. Fa riferimento al parametro SchemaName per consentire il filtro per gli schemi SQL. L'output di si tratta di una matrice di tabelle e schema SQL che verranno usate come input nell'attività ForEach.
Usare il codice seguente per restituire un elenco di tutte le tabelle utente con il nome dello schema.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
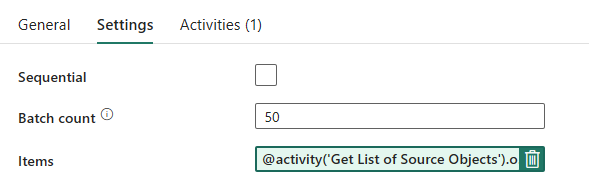
Progettazione della pipeline: Ciclo ForEach
Per ciclo ForEach, configurare le opzioni seguenti nella scheda Impostazioni :
- Disabilitare Sequenziale per consentire l'esecuzione simultanea di più iterazioni.
- Impostare Conteggio batch su
50, limitando il numero massimo di iterazioni simultanee. - Il campo Items deve usare il contenuto dinamico per fare riferimento all'output dell'attività LookUp. Usare il frammento di codice seguente:
@activity('Get List of Source Objects').output.value
Progettazione della pipeline: attività di copia all'interno del ciclo ForEach
All'interno dell'attività ForEach aggiungere un'attività di copia. Questo metodo usa il linguaggio delle espressioni dinamiche all'interno di Pipeline di dati per compilare un SELECT TOP 0 * FROM <TABLE> oggetto per eseguire la migrazione solo dello schema senza dati in un'istanza di Fabric Warehouse.
Nella scheda Origine :
- Impostare Tipo di archivio dati su Esterno.
- La connessione è il pool SQL dedicato di Azure Synapse. Il tipo di connessione è Azure Synapse Analytics.
- Impostare Usa query su Query.
- Nel campo Query incollare nella query del contenuto dinamico e usare questa espressione che restituirà zero righe, ma solo lo schema della tabella:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Nella scheda Destinazione :
- Impostare Tipo di archivio dati su Area di lavoro.
- Il tipo di archivio dati dell'area di lavoro è Data Warehouse e il data warehouse è impostato su Fabric Warehouse.
- Lo schema e il nome della tabella di destinazione vengono definiti usando il contenuto dinamico.
- Lo schema fa riferimento al campo dell'iterazione corrente, SchemaName con il frammento di codice:
@item().SchemaName - La tabella fa riferimento a TableName con il frammento di codice:
@item().TableName
- Lo schema fa riferimento al campo dell'iterazione corrente, SchemaName con il frammento di codice:

Progettazione della pipeline: sink
Per Sink scegliere Warehouse e fare riferimento allo schema di origine e al nome della tabella.
Dopo aver eseguito questa pipeline, il data warehouse verrà popolato con ogni tabella nell'origine con lo schema appropriato.
Migrazione tramite stored procedure nel pool SQL dedicato di Synapse
Questa opzione usa stored procedure per eseguire la migrazione dell'infrastruttura.
È possibile ottenere gli esempi di codice in microsoft/fabric-migration in GitHub.com. Questo codice viene condiviso come open source, quindi è possibile contribuire a collaborare e aiutare la community.
Operazioni che le stored procedure di migrazione possono eseguire:
- Convertire lo schema (DDL) nella sintassi fabric warehouse.
- Creare lo schema (DDL) in Fabric Warehouse.
- Estrarre dati dal pool SQL dedicato di Synapse ad ADLS.
- Contrassegna la sintassi dell'infrastruttura non supportata per i codici T-SQL (stored procedure, funzioni, viste).
Uso consigliato
Questa è un'ottima opzione per coloro che:
- Familiarità con T-SQL.
- Si vuole usare un ambiente di sviluppo integrato, ad esempio SQL Server Management Studio (SSMS).
- Si vuole un controllo più granulare sulle attività su cui si vuole lavorare.
È possibile eseguire la stored procedure specifica per la conversione dello schema (DDL), l'estrazione di dati o la valutazione del codice T-SQL.
Per la migrazione dei dati, è necessario usare COPY INTO o Data Factory per inserire i dati in Fabric Warehouse.
Migrazione con database SQL Progetto
Microsoft Fabric Data Warehouse è supportato nell'estensione progetti database SQL disponibile all'interno di Azure Data Studio e Visual Studio Code.
Questa estensione è disponibile in Azure Data Studio e Visual Studio Code. Questa funzionalità abilita le funzionalità per il controllo del codice sorgente, il test del database e la convalida dello schema.
Uso consigliato
Questa è un'ottima opzione per coloro che preferiscono usare database SQL Project per la distribuzione. Questa opzione essenzialmente ha integrato le stored procedure di migrazione dell'infrastruttura nel progetto database SQL per offrire un'esperienza di migrazione senza problemi.
Un progetto database SQL può:
- Convertire lo schema (DDL) nella sintassi fabric warehouse.
- Creare lo schema (DDL) in Fabric Warehouse.
- Estrarre dati dal pool SQL dedicato di Synapse ad ADLS.
- Contrassegna la sintassi non supportata per i codici T-SQL (stored procedure, funzioni, viste).
Per la migrazione dei dati, si userà quindi COPY INTO o Data Factory per inserire i dati in Fabric Warehouse.
L'aggiunta al supporto di Azure Data Studio a Fabric, il team CAT di Microsoft Fabric ha fornito un set di script di PowerShell per gestire l'estrazione, la creazione e la distribuzione dello schema (DDL) e del codice del database (DML) tramite un progetto database SQL. Per una procedura dettagliata sull'uso del progetto database SQL con gli script di PowerShell utili, vedere microsoft/fabric-migration on GitHub.com.
Per altre informazioni sui progetti database SQL, vedere Introduzione all'estensione progetti database SQL e Compilare e pubblicare un progetto.
Migrazione dei dati con CETAS
Il comando T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) fornisce il metodo più conveniente e ottimale per estrarre i dati dai pool SQL dedicati di Synapse ad Azure Data Lake Storage (ADLS) Gen2.
Cosa può fare CETAS:
- Estrarre dati in ADLS.
- Questa opzione richiede agli utenti di creare lo schema (DDL) in Fabric Warehouse prima di inserire i dati. Prendere in considerazione le opzioni in questo articolo per eseguire la migrazione dello schema (DDL).
I vantaggi di questa opzione sono:
- Viene inviata solo una singola query per tabella nel pool SQL dedicato di Synapse di origine. Questo non userà tutti gli slot di concorrenza e quindi non bloccherà le ETL/query simultanee di produzione dei clienti.
- Il ridimensionamento a DWU6000 non è necessario, perché per ogni tabella viene usato un solo slot di concorrenza, in modo che i clienti possano usare DWU inferiori.
- L'estrazione viene eseguita in parallelo in tutti i nodi di calcolo e questa è la chiave per il miglioramento delle prestazioni.
Uso consigliato
Usare CETAS per estrarre i dati in ADLS come file Parquet. I file Parquet offrono il vantaggio di un'efficiente archiviazione dei dati con compressione a colonne che richiederà meno larghezza di banda per spostarsi attraverso la rete. Inoltre, poiché Fabric ha archiviato i dati come formato Parquet Delta, l'inserimento dati sarà 2,5 volte più veloce rispetto al formato di file di testo, poiché non è presente alcuna conversione al sovraccarico del formato Delta durante l'inserimento.
Per aumentare la velocità effettiva CETAS:
- Aggiungere operazioni CETAS parallele, aumentando l'uso di slot di concorrenza, ma consentendo una maggiore velocità effettiva.
- Ridimensionare la DWU nel pool SQL dedicato di Synapse.
Migrazione tramite dbt
In questa sezione viene descritta l'opzione dbt per i clienti che usano già dbt nell'ambiente del pool SQL dedicato di Synapse corrente.
Operazioni che dbt può eseguire:
- Convertire lo schema (DDL) nella sintassi fabric warehouse.
- Creare lo schema (DDL) in Fabric Warehouse.
- Convertire il codice del database (DML) nella sintassi dell'infrastruttura.
Il framework dbt genera DDL e DML (script SQL) in tempo reale con ogni esecuzione. Con i file di modello espressi nelle istruzioni SELECT, il DDL/DML può essere convertito immediatamente in qualsiasi piattaforma di destinazione modificando il profilo (stringa di connessione) e il tipo di adattatore.
Uso consigliato
Il framework dbt è un approccio code-first. È necessario eseguire la migrazione dei dati usando le opzioni elencate in questo documento, ad esempio CETAS o COPY/Data Factory.
L'adapter dbt per Microsoft Fabric Synapse Data Warehouse consente la migrazione dei progetti dbt esistenti destinati a piattaforme diverse, ad esempio pool SQL dedicati di Synapse, Snowflake, Databricks, Google Big Query o Amazon Redshift per la migrazione a un'istanza di Fabric Warehouse con una semplice modifica della configurazione.
Per iniziare a usare un progetto dbt destinato a Fabric Warehouse, vedere Esercitazione: Configurare dbt per Fabric Data Warehouse. Questo documento elenca anche un'opzione per spostarsi tra magazzini/piattaforme diversi.
Inserimento dati in Fabric Warehouse
Per l'inserimento in Fabric Warehouse, usare COPY INTO o Fabric Data Factory, a seconda delle preferenze. Entrambi i metodi sono le opzioni consigliate e migliori, poiché hanno una velocità effettiva delle prestazioni equivalente, dato il prerequisito che i file sono già estratti in Azure Data Lake Storage (ADLS) Gen2.
Diversi fattori da notare per poter progettare il processo per ottenere prestazioni massime:
- Con Fabric non è presente alcuna contesa di risorse durante il caricamento simultaneo di più tabelle da ADLS a Fabric Warehouse. Di conseguenza, non si verifica alcuna riduzione delle prestazioni durante il caricamento di thread paralleli. La velocità effettiva massima per l'inserimento sarà limitata solo dalla potenza di calcolo della capacità di Infrastruttura.
- La gestione del carico di lavoro dell'infrastruttura offre la separazione delle risorse allocate per il carico e la query. Non esiste alcuna contesa di risorse mentre le query e il caricamento dei dati vengono eseguiti contemporaneamente.
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per