Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo presenta l'architettura medallion lake e descrive come implementare il modello di progettazione in Microsoft Fabric. È pensato per più gruppi di destinatari:
- Ingegneri dei dati: Personale tecnico che progetta, costruisce e gestisce infrastrutture e sistemi che consentono all'organizzazione di raccogliere, archiviare, elaborare e analizzare grandi volumi di dati.
- Team di eccellenza, IT e BI: I team responsabili della supervisione dell'analisi in tutta l'organizzazione.
- Amministratori dell'infrastruttura: Gli amministratori responsabili della supervisione di Fabric nell'organizzazione.
L'architettura medallion lakehouse, comunemente nota come architettura medallion, è un modello di progettazione usato dalle organizzazioni per organizzare logicamente i dati in una lakehouse. È l'approccio di progettazione consigliato per Fabric. Poiché OneLake è il data lake per Fabric, l'architettura medallion viene implementata creando lakehouse in OneLake.
L'architettura medallion comprende tre livelli distinti, detti anche zone. I tre livelli di medaglia sono: bronzo (dati non elaborati), argento (dati convalidati) e oro (dati arricchiti). Ogni livello indica la qualità dei dati archiviati nel lakehouse: i livelli più elevati rappresentano una qualità superiore. Questo approccio multi-livello consente di creare un'unica origine di riferimento per i prodotti di dati aziendali.
In particolare, l'architettura medallion garantisce atomicità, coerenza, isolamento e durabilità (ACID) man mano che i dati progrediscono attraverso i livelli. I dati iniziano in forma non elaborata, quindi una serie di convalide e trasformazioni prepara i dati per ottimizzarli per un'analisi efficiente mantenendo al tempo stesso le copie originali come fonte di verità.
Per altre informazioni, vedere Cos'è l'architettura medallion lakehouse?.
Architettura a medaglione in Fabric
L'obiettivo dell'architettura a medaglione è migliorare in modo incrementale e progressivo la struttura e la qualità dei dati man mano che procedono attraverso ogni passaggio.
L'architettura a medaglione è costituita da tre livelli distinti (o zone).
- Bronzo: Detto anche zona non elaborata, questo primo livello archivia i dati di origine nel formato originale, inclusi i tipi di dati non strutturati, semistrutturati o strutturati. I dati in questo livello sono in genere di solo accodamento e non modificabili. Conservando i dati non elaborati nel livello bronze, si mantiene una fonte di verità e si abilita la rielaborazione e il controllo in futuro.
- Argento: Detto anche zona arricchita, questo livello archivia i dati originati dal livello bronzo. I dati vengono puliti e standardizzati e ora sono strutturati come tabelle (righe e colonne). Potrebbe anche essere integrato con altri dati per offrire una visualizzazione aziendale di tutte le entità aziendali, ad esempio clienti, prodotti e altro ancora.
- Oro: Detto anche zona curata, questo livello finale archivia i dati provenienti dal livello silver. I dati vengono perfezionati per soddisfare specifici requisiti di analisi e business downstream. Le tabelle sono in genere conformi alla progettazione dello schema star, che supporta lo sviluppo di modelli di dati ottimizzati per prestazioni e usabilità.
Ogni settore deve essere suddiviso nel proprio lakehouse o data warehouse in OneLake, con i dati che si spostano tra i settori mentre vengono trasformati e perfezionati.
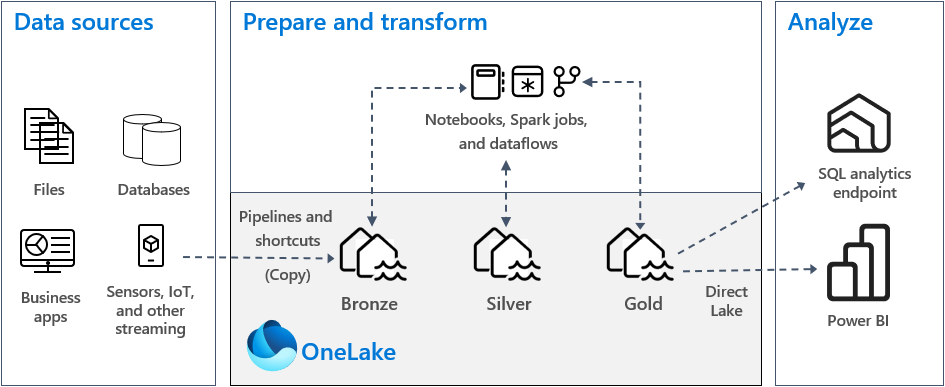
In un'implementazione tipica dell'architettura a medaglione in Fabric, la zona Bronze archivia i dati nello stesso formato dell'origine dati. Quando l'origine dati è un database relazionale, le tabelle Delta sono una scelta ottimale. Le zone silver e gold devono contenere tabelle Delta.
Suggerimento
Per informazioni su come creare un lakehouse, seguire il tutorial Scenario lakehouse end-to-end.
OneLake e lakehouse in Fabric
La base di un data warehouse moderno è un data lake. Microsoft OneLake è un singolo data lake unificato e logico per l'intera organizzazione. È configurato automaticamente con ogni tenant di Fabric ed è l'unico luogo per tutti i tuoi dati di analisi.
È possibile usare OneLake per:
- Rimuovere i silo e ridurre il lavoro di gestione. Tutti i dati dell'organizzazione vengono archiviati, gestiti e protetti all'interno di una risorsa data lake.
- Ridurre lo spostamento e la duplicazione dei dati. L'obiettivo di OneLake è archiviare solo una copia dei dati. Un minor numero di copie dei dati comporta un minor numero di processi di spostamento dati e ciò comporta miglioramenti nell'efficienza e riduzione della complessità. Usare i collegamenti per fare riferimento ai dati archiviati in altre posizioni, anziché copiarli in OneLake.
- Uso con molteplici motori analitici. I dati in OneLake vengono archiviati in un formato aperto. In questo modo, i dati possono essere sottoposti a query da vari motori analitici, tra cui Analysis Services (usato da Power BI), T-SQL e Apache Spark. Altre applicazioni non di infrastruttura possono usare API e SDK per accedere anche a OneLake .
Per archiviare i dati in OneLake, creare una lakehouse in Fabric. Un lakehouse è una piattaforma di architettura dei dati per l'archiviazione, la gestione e l'analisi di dati strutturati e non strutturati in un'unica posizione. Può essere ridimensionato in volumi di dati di grandi dimensioni e tipi di file e poiché i dati vengono archiviati in un'unica posizione, possono essere condivisi e riutilizzati nell'organizzazione.
Ogni lakehouse ha un endpoint di analisi SQL predefinito che sblocca le funzionalità del data warehouse senza la necessità di spostare i dati. Ciò significa che è possibile eseguire query sui dati nel lakehouse usando query SQL e senza alcuna configurazione speciale.
Per ulteriori informazioni, vedere Che cos'è una lakehouse in Microsoft Fabric?.
Tabelle e file
Quando si crea una lakehouse in OneLake, viene eseguito automaticamente il provisioning di due posizioni di archiviazione fisica:
- Le tabelle sono un'area gestita per l'archiviazione di tabelle di tutti i formati in Apache Spark (CSV, Parquet o Delta). Tutte le tabelle, create automaticamente o in modo esplicito, vengono riconosciute come tabelle nel lakehouse. Tutte le tabelle Delta, ovvero file di dati Parquet con un log delle transazioni basato su file, vengono riconosciute anche come tabelle.
- I file sono un'area non gestita per l'archiviazione dei dati in qualsiasi formato di file. Tutti i file Delta archiviati in questa area non vengono riconosciuti automaticamente come tabelle. Se si vuole creare una tabella su una cartella Delta Lake nell'area non gestita, creare un collegamento o una tabella esterna con un percorso che punta alla cartella non gestita che contiene i file Delta Lake in Apache Spark.
La distinzione principale tra l'area gestita (tabelle) e l'area non gestita (file) è il processo di individuazione e registrazione automatica delle tabelle. Questo processo viene eseguito su qualsiasi cartella creata solo nell'area gestita, ma non nell'area non gestita.
Nella zona bronze si archiviano i dati nel formato originale, che potrebbero essere tabelle o file. Se i dati di origine provengono da OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 o Google, creare un collegamento rapido nella zona di bronzo invece di copiare i dati.
Nelle zone silver e gold si archivia in genere i dati nelle tabelle Delta. Tuttavia, è anche possibile archiviare i dati in file Parquet o CSV. In questo caso, è necessario creare in modo esplicito un collegamento o una tabella esterna con un percorso che punta alla cartella non gestita che contiene i file Delta Lake in Apache Spark.
In Microsoft Fabric, Lakehouse Explorer fornisce una rappresentazione grafica unificata dell'intera Lakehouse per consentire agli utenti di spostarsi, accedere e aggiornare i dati.
Per altre informazioni sull'individuazione automatica delle tabelle, vedere Individuazione e registrazione automatica delle tabelle.
Archiviazione su Delta Lake
Delta Lake è un livello di archiviazione ottimizzato che fornisce le basi per l'archiviazione di dati e tabelle. Supporta transazioni ACID per carichi di lavoro di big data e per questo motivo è il formato di archiviazione predefinito in un lakehouse di Fabric.
Delta Lake offre affidabilità, sicurezza e prestazioni nella architettura lakehouse sia per lo streaming che per le operazioni batch. Internamente, archivia i dati in formato di file Parquet, ma mantiene anche i log delle transazioni e le statistiche che forniscono funzionalità e miglioramenti delle prestazioni rispetto al formato Parquet standard.
Il formato Delta Lake offre i vantaggi seguenti rispetto ai formati di file generici:
- Supporto per le proprietà ACID, in particolare la durabilità per evitare il danneggiamento dei dati.
- Query di lettura più veloci.
- Maggiore freschezza dei dati.
- Supporto per i carichi di lavoro in batch e in streaming.
- Supporto per il rollback dei dati usando il tempo di spostamento in Delta Lake.
- Conformità e controllo normativi migliorati tramite la cronologia delle tabelle Delta Lake.
Fabric standardizza il formato di file di archiviazione con Delta Lake. Per impostazione predefinita, ogni motore di carico di lavoro in Fabric crea tabelle Delta quando si scrivono dati in una nuova tabella. Per altre informazioni, vedere Tabelle Lakehouse e Delta Lake.
Modello di distribuzione
Per implementare l'architettura a medaglione in Fabric, è possibile usare lakehouse (una per ogni zona), un data warehouse o una combinazione di entrambi. La decisione deve essere basata sulle preferenze e sull'esperienza del team. Con Fabric è possibile usare motori di analisi diversi che funzionano su una copia dei dati in OneLake.
Ecco due modelli da considerare:
- Modello 1: Creare ogni zona come un "lakehouse". In questo caso, gli utenti aziendali accedono ai dati usando l'endpoint di analisi SQL.
- Modello 2: Creare le zone bronze e silver come lakehouse e la zona d'oro come data warehouse. In questo caso, gli utenti aziendali accedono ai dati usando l'endpoint del data warehouse.
Anche se è possibile creare tutti i lakehouse in un'unica Fabric workspace, è consigliabile creare ciascun lakehouse in un'area di lavoro separata. Questo approccio offre un maggiore controllo e una migliore governance a livello di zona.
Per la zona Bronze, è consigliabile archiviare i dati nel formato originale oppure usare Parquet o Delta Lake. Quando possibile, mantenere i dati nel formato originale. Se i dati di origine provengono da OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 o Google, creare un collegamento nella zona bronze invece di copiare i dati.
Per le zone Silver e Gold, è consigliabile usare tabelle Delta a causa delle capacità aggiuntive e dei miglioramenti delle prestazioni forniti. Fabric standardizza in formato Delta Lake e per impostazione predefinita ogni motore in Fabric scrive i dati in questo formato. Inoltre, questi motori usano l'ottimizzazione del tempo di scrittura V-order nel formato di file Parquet. Questa ottimizzazione consente letture rapide da motori di calcolo di Fabric, ad esempio Power BI, SQL, Apache Spark e altri. Per altre informazioni, vedere Ottimizzazione tabella Delta Lake e V-Order.
Infine, oggi molte organizzazioni affrontano una forte crescita dei volumi di dati, insieme a una crescente necessità di organizzare e gestire tali dati in modo logico, facilitando al contempo un uso e una governance più mirati ed efficienti. Ciò può portare a stabilire e gestire un'organizzazione di dati decentralizzata o federata con governance. Per soddisfare questo obiettivo, prendere in considerazione l'implementazione di un'architettura mesh di dati. La mesh di dati è un modello architetturale incentrato sulla creazione di domini dati che offrono dati come prodotto.
È possibile creare un'architettura per il mesh dei dati per il proprio patrimonio di dati in Fabric creando domini di dati. È possibile creare domini che eseguono il mapping ai domini aziendali, ad esempio marketing, vendite, inventario, risorse umane e altri. È quindi possibile implementare l'architettura a medaglione configurando zone di dati all'interno di ogni dominio. Per altre informazioni sui domini, vedere Domini.
Informazioni sull'archiviazione dei dati delle tabelle Delta
Questa sezione descrive altre linee guida relative all'implementazione di un'architettura lakehouse medallion in Fabric.
Dimensioni file
In genere, una piattaforma Big Data offre prestazioni migliori quando contiene alcuni file di grandi dimensioni anziché molti file di piccole dimensioni. La riduzione delle prestazioni si verifica quando il motore di calcolo ha molte operazioni sui metadati e sui file da gestire. Per migliorare le prestazioni delle query, è consigliabile puntare a file di dati di dimensioni di circa 1 GB.
Delta Lake ha una funzionalità denominata ottimizzazione predittiva. L'ottimizzazione predittiva automatizza le operazioni di manutenzione per le tabelle Delta. Quando questa funzionalità è abilitata, Delta Lake identifica le tabelle che potrebbero trarre vantaggio dalle operazioni di manutenzione e quindi ne ottimizza lo spazio di archiviazione. Anche se questa funzionalità deve far parte dell'eccellenza operativa e del lavoro di preparazione dei dati, Fabric può ottimizzare anche i file di dati durante la scrittura dei dati. Per altre informazioni, vedere Ottimizzazione predittiva per Delta Lake.
Conservazione cronologica
Per impostazione predefinita, Delta Lake mantiene una cronologia di tutte le modifiche apportate, quindi le dimensioni dei metadati cronologici aumentano nel tempo. In base ai requisiti aziendali, mantenere i dati cronologici solo per un determinato periodo di tempo per ridurre i costi di archiviazione. Valutare la possibilità di conservare i dati storici solo per l'ultimo mese o per un altro periodo di tempo appropriato.
È possibile rimuovere i dati cronologici precedenti da una tabella Delta usando il comando VACUUM. Per impostazione predefinita, tuttavia, non è possibile eliminare i dati cronologici negli ultimi sette giorni. Tale restrizione mantiene la coerenza nei dati. Configurare il numero predefinito di giorni con la proprietà della tabella delta.deletedFileRetentionDuration = "interval <interval>". Tale proprietà determina il periodo di tempo in cui un file deve essere eliminato prima che possa essere considerato un candidato per un'operazione vacuum.
Partizioni di tabella
Quando si archiviano i dati in ogni zona, è consigliabile usare una struttura di cartelle partizionata, laddove applicabile. Questa tecnica migliora la gestibilità dei dati e le prestazioni delle query. In genere, i dati partizionati in una struttura di cartelle consentono una ricerca più veloce di dati specifici grazie al pruning/eliminazione delle partizioni.
In genere, si aggiungono dati alla tabella di destinazione man mano che arrivano nuovi dati. Tuttavia, in alcuni casi, è possibile unire i dati perché è necessario aggiornare i dati esistenti allo stesso tempo. In tal caso, è possibile eseguire un'operazione upsert usando il comando MERGE. Quando la tabella di destinazione è partizionata, assicurarsi di usare un filtro di partizione per velocizzare l'operazione. In questo modo, il motore può eliminare le partizioni che non richiedono l'aggiornamento.
Accesso ai dati
È necessario pianificare e controllare chi deve accedere a dati specifici nel lakehouse. È anche necessario comprendere i vari criteri di transazione che verranno usati durante l'accesso a questi dati. È quindi possibile definire lo schema di partizionamento della tabella corretto e la collocazione dei dati con gli indici delta Lake Z order.
Contenuto correlato
Per altre informazioni sull'implementazione di un lakehouse di Fabric, vedere le risorse seguenti.
- Esercitazione: Scenario end-to-end di Lakehouse
- Tabelle Lakehouse e Delta Lake
- Guida alle decisioni di Microsoft Fabric: scegliere un archivio dati
- La necessità di ottimizzare la scrittura in Apache Spark
- Domande? Prova a chiedere alla community di Fabric.
- inviare suggerimenti, Contribuire con idee per migliorare Fabric.