Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
A seconda dell'origine dati, le informazioni sui tipi di dati e sui nomi delle colonne possono essere fornite o meno in modo esplicito. Le API REST OData gestiscono in genere questa operazione usando la definizione di $metadata e il metodo di Power Query OData.Feed gestisce automaticamente l'analisi di queste informazioni e l'applicazione ai dati restituiti da un'origine OData.
Molte API REST non hanno un modo per determinare a livello di codice lo schema. In questi casi è necessario includere una definizione di schema nel connettore.
Un approccio semplice hardcoded
L'approccio più semplice consiste nell'incorporare direttamente una definizione di schema nel tuo connettore. Questo è sufficiente per la maggior parte dei casi d'uso.
In generale, l'applicazione di uno schema sui dati restituiti dal connettore offre diversi vantaggi, ad esempio:
- Impostazione dei tipi di dati corretti.
- La rimozione di colonne che non devono essere visualizzate agli utenti finali ,ad esempio ID interni o informazioni sullo stato.
- Assicurarsi che ogni pagina di dati abbia la stessa forma aggiungendo tutte le colonne che potrebbero non essere presenti in una risposta (le API REST indicano in genere che i campi devono essere Null omettendoli completamente).
Visualizzazione dello schema esistente con Table.Schema
Si consideri il codice seguente che restituisce una tabella semplice dal servizio di esempio OData TripPin:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
Annotazioni
TripPin è un'origine OData, quindi realisticamente avrebbe più senso usare semplicemente la gestione automatica dello schema della funzione OData.Feed. In questo esempio si considererà l'origine come un'API REST tipica e si userà Web.Contents per illustrare la tecnica di hardcoding di uno schema a mano.
Questa tabella è il risultato:
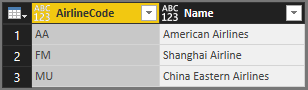
È possibile usare la funzione utile Table.Schema per controllare il tipo di dati delle colonne:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

Sia AirlineCode che Name sono di any tipo.
Table.Schema restituisce molti metadati sulle colonne di una tabella, inclusi nomi, posizioni, informazioni sul tipo e molte proprietà avanzate, ad esempio Precisione, Scala e MaxLength. Per il momento è consigliabile preoccuparsi solo del tipo ascritto (TypeName), del tipo primitivo (Kind) e se il valore della colonna potrebbe essere null (IsNullable).
Definizione di una tabella dello schema semplice
La tabella dello schema sarà composta da due colonne:
| colonna | Dettagli |
|---|---|
| Nome | Nome della colonna. Deve corrispondere al nome nei risultati restituiti dal servizio. |
| TIPO | Tipo di dati M da impostare. Può essere un tipo primitivo (text, number, datetime e così via) o un tipo ascritto (Int64.Type, Currency.Type e così via). |
La tabella dello schema hardcoded della tabella Airlines imposterà le colonne AirlineCode e Name su text e avrà il seguente aspetto:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
Quando esamini alcuni degli altri endpoint, considera le tabelle dello schema seguenti.
La Airports tabella contiene quattro campi da mantenere (incluso uno di tipo record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
La People tabella include sette campi, inclusi lists (Emails, AddressInfo), una colonna nullable (Gender) e una colonna con un tipo ascritto (Concurrency):
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
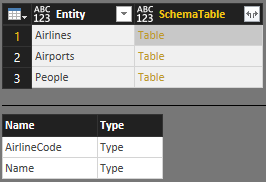
È possibile inserire tutte queste tabelle in una singola tabella SchemaTabledello schema master :
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
Funzione helper "SchemaTransformTable"
La SchemaTransformTablefunzione helper descritta di seguito verrà usata per applicare schemi ai dati. Accetta i parametri seguenti:
| Parametro | TIPO | Description |
|---|---|---|
| table | table | La tabella dei dati su cui si vuole applicare lo schema. |
| schema | table | Tabella dello schema da cui leggere le informazioni sulle colonne con il tipo seguente: type table [Name = text, Type = type]. |
| enforceSchema | numero | (facoltativo) Enumerazione che controlla il comportamento della funzione. Il valore predefinito ( EnforceSchema.Strict = 1) garantisce che la tabella di output corrisponda alla tabella dello schema fornita aggiungendo eventuali colonne mancanti e rimuovendo colonne aggiuntive. L'opzione EnforceSchema.IgnoreExtraColumns = 2 può essere usata per mantenere colonne aggiuntive nel risultato. Quando EnforceSchema.IgnoreMissingColumns = 3 viene usato, le colonne mancanti e le colonne aggiuntive verranno ignorate. |
La logica per questa funzione è simile alla seguente:
- Determinare se sono presenti colonne mancanti nella tabella di origine.
- Determinare se sono presenti colonne aggiuntive.
- Ignorare le colonne strutturate (di tipo
list,recordetable) e le colonne impostate sul tipoany. - Utilizzare
Table.TransformColumnTypesper impostare ogni tipo di colonna. - Riordinare le colonne in base all'ordine in cui vengono visualizzate nella tabella dello schema.
- Impostare il tipo nella tabella stessa usando
Value.ReplaceType.
Annotazioni
L'ultimo passaggio per impostare il tipo di tabella rimuoverà la necessità dell'interfaccia utente di Power Query di dedurre le informazioni sul tipo quando si visualizzano i risultati nell'editor di query, che a volte può comportare una doppia chiamata all'API.
Mettere tutto insieme
Nel contesto maggiore di un'estensione completa, la gestione dello schema verrà eseguita quando viene restituita una tabella dall'API. In genere questa funzionalità viene eseguita al livello più basso della funzione di paging (se presente), con le informazioni sull'entità passate da una tabella di navigazione.
Poiché gran parte dell'implementazione di paging e tabelle di spostamento è specifica del contesto, l'esempio completo di implementazione di un meccanismo di gestione dello schema hardcoded non verrà illustrato qui. In questo esempio TripPin viene illustrato l'aspetto di una soluzione end-to-end.
Approccio sofisticato
L'implementazione hardcoded descritta in precedenza offre un buon lavoro per assicurarsi che gli schemi rimangano coerenti per risposte JSON semplici, ma è limitato all'analisi del primo livello della risposta. I set di dati annidati in modo approfondito traggono vantaggio dall'approccio seguente, che sfrutta i tipi M.
Di seguito è riportato un aggiornamento rapido dei tipi nella lingua M dalla specifica del linguaggio:
Un valore tipo è un valore che classifica altri valori. Si dice che un valore classificato in base a un tipo sia conforme a quel tipo. Il sistema di tipi del linguaggio M è costituito dai tipi seguenti:
- I tipi primitivi, che classificano i valori primitivi (
binary,date,datetime,datetimezone,duration,list,logical,null,number,record,text,time,type) e includono anche diversi tipi astratti (function,table,any, enone).- Tipi di record, che classificano i valori dei record in base ai nomi dei campi e ai tipi valore.
- Tipi di elenco, che classificano gli elenchi usando un singolo tipo di base di elementi.
- Tipi di funzione, che classificano i valori delle funzioni in base ai tipi dei relativi parametri e valori restituiti.
- Tipi di tabella, che classificano i valori della tabella in base a nomi di colonna, tipi di colonna e chiavi.
- Tipi nullable, che classificano il valore Null oltre a tutti i valori classificati da un tipo di base.
- Tipi di tipi, che classificano valori che sono tipi.
Usando l'output JSON non elaborato che si ottiene (e/o cercando le definizioni nella $metadata del servizio), è possibile definire i tipi di record seguenti per rappresentare i tipi complessi OData:
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Si noti come LocationType fa riferimento a CityType e LocType per rappresentare le colonne strutturate.
Per le entità di primo livello che si desidera rappresentare come tabelle, è possibile definire i tipi di tabella:
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
È quindi possibile aggiornare la SchemaTable variabile (che è possibile usare come tabella di ricerca per i mapping da entità a tipo) per usare queste nuove definizioni di tipo:
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
È possibile fare affidamento su una funzione comune (Table.ChangeType) per applicare uno schema ai dati, in modo analogo a quello usato SchemaTransformTable nell'esercizio precedente. A differenza di SchemaTransformTable, Table.ChangeType accetta un tipo di tabella M effettivo come argomento e applicherà lo schema in modo ricorsivo per tutti i tipi annidati. La firma è:
Table.ChangeType = (table, tableType as type) as nullable table => ...
Annotazioni
Per una maggiore flessibilità, la funzione può essere usata nelle tabelle e negli elenchi di record (che è il modo in cui le tabelle vengono rappresentate in un documento JSON).
Sarà quindi necessario aggiornare il codice del connettore per modificare il schema parametro da a table a typee aggiungere una chiamata a Table.ChangeType. Anche in questo caso, i dettagli per farlo sono molto specifici dell'implementazione e quindi non vale la pena approfondire in dettaglio qui.
Questo esempio di connettore TripPin esteso illustra una soluzione end-to-end che implementa questo approccio più sofisticato alla gestione dello schema.