適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新たに試用を開始する方法については、こちらをご覧ください。
この記事では、Hadoop 分散ファイル システム (HDFS) サーバーからデータをコピーする方法について説明します。 詳細については、Azure Data Factory および Synapse Analytics の概要記事を参照してください。
サポートされる機能
この HDFS コネクタでは、次の機能がサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/-) | ① ② |
| Lookup アクティビティ | ① ② |
| アクティビティを削除する | ① ② |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
具体的には、HDFS コネクタは以下をサポートします。
- Windows (Kerberos) または "匿名" 認証を使用するファイルのコピー。
- webhdfs プロトコルまたは "組み込みの DistCp" のサポートを使用するファイルのコピー。
- ファイルをそのままコピーするか、サポートされているファイル形式と圧縮コーデックを使用してファイルを解析または生成する。
前提条件
データ ストアがオンプレ ミスネットワーク、Azure 仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、それに接続するようセルフホステッド統合ランタイムを構成する必要があります。
データ ストアがマネージド クラウド データ サービスである場合は、Azure Integration Runtime を使用できます。 ファイアウォール規則で承認されている IP にアクセスが制限されている場合は、Azure Integration Runtime の IP を許可リストに追加できます。
また、Azure Data Factory のマネージド仮想ネットワーク統合ランタイム機能を使用すれば、セルフホステッド統合ランタイムをインストールして構成しなくても、オンプレミス ネットワークにアクセスすることができます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
注意
統合ランタイムが、Hadoop クラスターの "すべて" の [name node server]:[name node port] および [data node servers]:[data node port] にアクセスできることを確認します。 既定の [name node port] は 50070、既定の [data node port] は 50075 です。
はじめに
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して HDFS のリンク サービスを作成する
次の手順を使用して、Azure portal UI で HDFS のリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンクされたサービス] を選択して、[新規] をクリックします。
HDFS を検索し、HDFS コネクタを選択します。
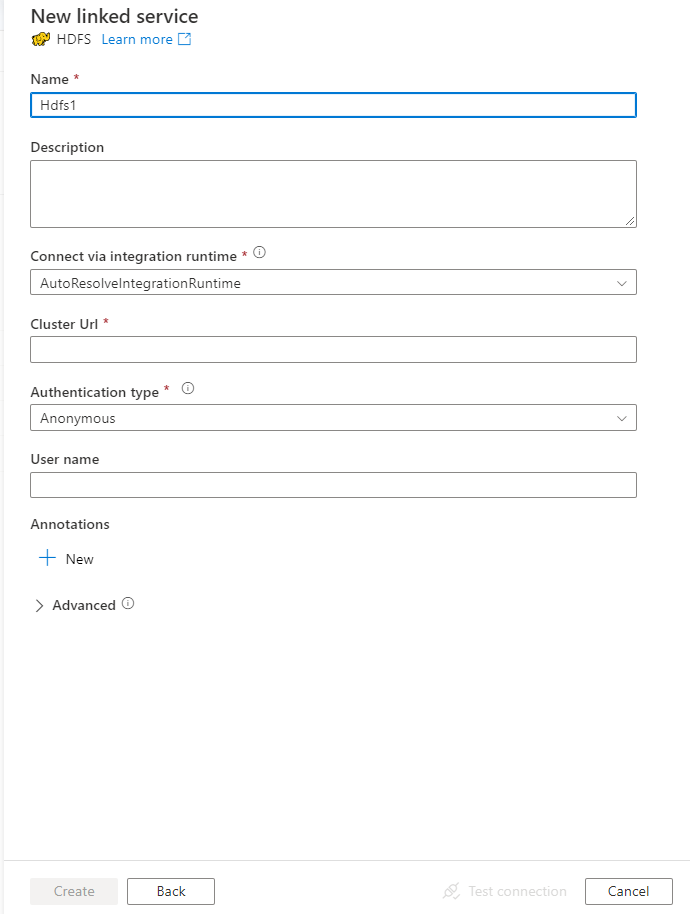
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、HDFS に固有の Data Factory エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
HDFS のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは Hdfs に設定する必要があります。 | はい |
| url | HDFS への URL | はい |
| authenticationType | 使用可能な値: Anonymous またはWindows。 オンプレミス環境を設定するには、「HDFS コネクタでの Kerberos 認証の使用」セクションを参照してください。 |
はい |
| userName | Windows 認証のユーザー名。 Kerberos 認証の場合は <username>@<domain>.com を指定します。 | はい (Windows 認証用) |
| password | Windows 認証のパスワード。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に保存されているシークレットを参照します。 | あり (Windows 認証用) |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 詳細については、「前提条件」セクションを参照してください。 統合ランタイムが指定されていない場合は、サービスでは既定の Azure Integration Runtime が使用されます。 | いいえ |
例: 匿名認証の使用
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: Windows 認証の使用
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
データセットの定義に使用できるセクションとプロパティの完全な一覧については、データセットに関するページをご覧ください。
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
HDFS では、形式ベースのデータセットの location 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの location の type プロパティは、HdfsLocation に設定する必要があります。 |
はい |
| folderPath | フォルダーへのパス。 ワイルドカードを使用してフォルダーをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定でパスを指定します。 | いいえ |
| fileName | 指定された folderPath の下のファイル名。 ワイルドカードを使用してファイルをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定でファイル名を指定します。 | いいえ |
例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインとアクティビティに関する記事を参照してください。 このセクションでは、HDFS ソースでサポートされるプロパティの一覧を示します。
ソースとしての HDFS
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
HDFS では、形式ベースのコピー ソースの storeSettings 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | storeSettings の type プロパティは HdfsReadSettings に設定する必要があります。 |
はい |
| コピーするファイルを特定する | ||
| オプション 1: 静的パス |
データセットに指定されているフォルダーまたはファイル パスからコピーします。 フォルダーからすべてのファイルをコピーする場合は、さらに * として wildcardFileName を指定します。 |
|
| オプション 2: ワイルドカード - wildcardFolderPath |
ソース フォルダーをフィルター処理するための、ワイルドカード文字を含むフォルダー パス。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。 実際のフォルダー名にワイルドカードまたは ^ が含まれている場合は、このエスケープ文字を使用してエスケープします。 他の例については、「フォルダーとファイル フィルターの例」を参照してください。 |
いいえ |
| オプション 2: ワイルドカード - wildcardFileName |
ソース ファイルをフィルター処理するための、指定された folderPath または wildcardFolderPath の下のワイルドカード文字を含むファイル名。 使用できるワイルドカードは、 * (0 個以上の文字に一致) と ? (0 個または 1 個の文字に一致) です。実際のファイル名にワイルドカードまたは ^ が含まれている場合は、このエスケープ文字を使用してエスケープします。 他の例については、「フォルダーとファイル フィルターの例」を参照してください。 |
はい |
| オプション 3: ファイルの一覧 - fileListPath |
指定されたファイル セットをコピーすることを示します。 コピーするファイルの一覧を含むテキスト ファイルをポイントします (データセットで構成されているパスへの相対パスを使用して、ファイルを 1 行につき 1 つずつ指定します)。 このオプションを使用する場合は、データセットにファイル名を指定しないでください。 その他の例については、「ファイル リストの例」を参照してください。 |
いいえ |
| 追加の設定 | ||
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive が true に設定されていて、シンクがファイル ベースのストアである場合、シンクでは空のフォルダーまたはサブフォルダーがコピーも作成もされません。 使用可能な値: true (既定値) および false。 fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| deleteFilesAfterCompletion | 宛先ストアに正常に移動した後、バイナリ ファイルをソース ストアから削除するかどうかを示します。 ファイルの削除はファイルごとに行われるので、コピー操作が失敗した場合、一部のファイルが既に宛先にコピーされソースからは削除されているが、他のファイルはまだソース ストアに残っていることがわかります。 このプロパティは、バイナリ ファイルのコピー シナリオでのみ有効です。 既定値: false。 |
いいえ |
| modifiedDatetimeStart | ファイルは、最終変更日時の属性に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は 2018-12-01T05:00:00Z の形式で UTC タイム ゾーンに適用されます。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。 modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値以下であるファイルが選択されます。fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| modifiedDatetimeEnd | 上記と同じです。 | |
| enablePartitionDiscovery | パーティション分割されているファイルの場合は、ファイル パスのパーティションを解析し、それを追加のソース列として追加するかどうかを指定します。 指定できる値は false (既定値) と true です。 |
いいえ |
| partitionRootPath | パーティション検出が有効になっている場合は、パーティション分割されたフォルダーをデータ列として読み取るための絶対ルート パスを指定します。 これが指定されていない場合は、既定で次のようになります。 - ソース上のデータセットまたはファイルの一覧内のファイル パスを使用する場合、パーティションのルート パスはそのデータセットで構成されているパスです。 - ワイルドカード フォルダー フィルターを使用する場合、パーティションのルート パスは最初のワイルドカードの前のサブパスです。 たとえば、データセット内のパスを "root/folder/year=2020/month=08/day=27" として構成するとします。 - パーティションのルート パスを "root/folder/year=2020" として指定した場合は、コピー アクティビティによって、ファイル内の列とは別に、それぞれ "08" と "27" の値を持つ month と day という 2 つの追加の列が生成されます。- パーティションのルート パスが指定されない場合、追加の列は生成されません。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
| DistCp 設定 | ||
| distcpSettings | HDFS DistCp を使用する場合に使用するプロパティ グループ。 | いいえ |
| resourceManagerEndpoint | YARN (Yet Another Resource Negotiator) エンドポイント | はい (DistCp を使用する場合) |
| tempScriptPath | 一時 DistCp コマンド スクリプトを格納するために使用するフォルダー パス。 スクリプト ファイルが生成され、コピー ジョブの完了後に削除されます。 | はい (DistCp を使用する場合) |
| distcpOptions | DistCp コマンドに指定する追加オプション。 | いいえ |
例:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
フォルダーとファイル フィルターの例
このセクションでは、ワイルドカード フィルターをフォルダー パスとファイル名とともに使用する場合の結果の動作について説明します。
| folderPath | fileName | recursive | ソースのフォルダー構造とフィルターの結果 (太字のファイルが取得されます) |
|---|---|---|---|
Folder* |
(空、既定値を使用) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(空、既定値を使用) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
ファイル リストの例
このセクションでは、コピー アクティビティのソースでファイル リスト パスを使用した結果の動作について説明します。 次のソース フォルダー構造があり、太字のファイルをコピーするものとします。
| サンプルのソース構造 | FileListToCopy.txt のコンテンツ | 構成 |
|---|---|---|
| root FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv メタデータ FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
データセット内: - フォルダー パス: root/FolderAコピー アクティビティ ソース内: - ファイル リストのパス: root/Metadata/FileListToCopy.txt ファイル リストのパスは、コピーするファイルの一覧を含む同じデータ ストア内のテキスト ファイルをポイントします (データセットで構成されているパスへの相対パスを使用して、1 行につき 1 つのファイルを指定します)。 |
DistCp を使用して HDFS からデータをコピーする
DistCp は、Hadoop クラスターにコピーを配布するための Hadoop のネイティブ コマンドライン ツールです。 DistCp でコマンドを実行すると、コピーされるファイルが最初にすべてリストされ、その後 Hadoop クラスターでいくつかの Map ジョブが作成されます。 それぞれの Map ジョブは、ソースからシンクへのバイナリ コピーを実行します。
コピー アクティビティでは、DistCp を使用した、Azure BLOB ストレージ (ステージング コピーを含む) または Azure データ レイク ストアへのファイルのそのままのコピーがサポートされています。 この場合、DistCp はセルフホステッド統合ランタイムを実行せず、ご使用のクラスターの機能を活用することができます。 特にクラスターが非常に強力な場合は、DistCp を使用することでコピーのスループットが向上します。 構成に基づき、Copy アクティビティによって DistCp コマンドが自動的に作成され、Hadoop クラスターに送信されて、コピー状態が監視されます。
前提条件
DistCp を使用して HDFS から Azure BLOB ストレージ (ステージング コピーを含む) または Azure データ レイク ストアにファイルをそのままコピーする場合は、Hadoop クラスターが次の要件を満たしていることを確認します。
MapReduce と YARN サービスが有効であること。
YARN のバージョンが 2.5 以降であること。
HDFS サーバーが、次の対象のデータ ストアと統合されていること。Azure BLOB ストレージまたは Azure Data Lake Store (ADLS Gen1) :
- Azure Blob ファイル システムは、Hadoop 2.7 以降、ネイティブにサポートされています。 Hadoop 環境構成で JAR のパスを指定するだけで十分です。
- Azure Data Lake Store ファイル システムは、Hadoop 3.0.0-alpha1 からパッケージ化されます。 ご使用の Hadoop クラスターのバージョンがそのバージョンよりも前のものである場合、Azure Data Lake Store 関連の JAR パッケージ (azure-datalake-store.jar) を、こちらからクラスターに手動でインポートし、Hadoop 環境構成で JAR ファイル パスを指定する必要があります。
HDFS 内に一時フォルダーが準備されていること。 この一時フォルダーは DistCp シェル スクリプトを格納するために使用されるため、KB レベルで領域を消費します。
HDFS のリンクされたサービスで提供されているユーザー アカウントに、次のアクセス許可が確実にあること。
- YARN でのアプリケーションの送信。
- 一時フォルダーでのサブフォルダーの作成と、ファイルの読み取りと書き込み。
構成
DistCp 関連の構成および例については、「ソースとしての HDFS」セクションを参照してください。
HDFS コネクタでの Kerberos 認証の使用
HDFS コネクタで Kerberos 認証を使用するようにオンプレミス環境を設定するためのオプションは 2 つあります。 自分の状況に適した方法を選択できます。
- オプション 1: セルフホステッド統合ランタイム コンピューターを Kerberos 領域に参加させる
- オプション 2:Windows ドメインと Kerberos 領域の間の相互信頼関係を有効にする
どちらのオプションでも、Hadoop クラスターに対して webhdfs を必ず有効にしてください。
webhdfs の HTTP プリンシパルと keytab を作成します。
重要
HTTP Kerberos プリンシパルは、Kerberos HTTP SPNEGO 仕様に従って、HTTP/ で始まる必要があります。 詳細については、こちらを参照してください。
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS 構成オプション:
hdfs-site.xmlに次の 3 つのプロパティを追加します。<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
オプション 1: セルフホステッド統合ランタイム コンピューターを Kerberos 領域に参加させる
必要条件
- セルフホステッド統合ランタイム コンピューターは Kerberos 領域に参加している必要があります。Windows ドメインには参加できません。
構成方法
KDC サーバーで:
プリンシパルを作成し、パスワードを指定します。
重要
ユーザー名にホスト名を含めることはできません。
Kadmin> addprinc <username>@<REALM.COM>
セルフホステッド統合ランタイム コンピューターで:
Ksetup ユーティリティを実行して、Kerberos Key Distribution Center (KDC) サーバーと領域を構成します。
Kerberos 領域は Windows ドメインとは異なるため、コンピューターをワークグループのメンバーとして構成する必要があります。 この構成は、次のコマンドを実行して Kerberos 領域を設定し、KDC サーバーを追加することによって達成できます。 REALM.COM は、実際の領域名で置き換えます。
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>これらのコマンドを実行した後、コンピューターを再起動します。
Ksetupコマンドを使用して構成を確認します。 出力は次のようになります。C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
データ ファクトリまたは Synapse ワークスペースで:
- Kerberos プリンシパル名とパスワードによる Windows 認証を行って HDFS データ ソースに接続するように HDFS コネクタを構成します。 構成の詳細については、HDFS のリンクされたサービスのプロパティのセクションを参照してください。
オプション 2: Windows ドメインと Kerberos 領域の間の相互信頼関係を有効にする
必要条件
- セルフホステッド統合ランタイム コンピューターは、Windows ドメインに参加している必要があります。
- ドメイン コントローラーの設定を更新するアクセス許可が必要です。
構成方法
注意
次のチュートリアルの REALM.COM と AD.COM を、実際の領域名とドメイン コントローラーに置き換えます。
KDC サーバーで:
krb5.conf ファイルの KDC 構成を編集して、KDC が次の構成テンプレートを参照して、Windows ドメインを信頼するようにします。 既定で、この構成は /etc/krb5.conf にあります。
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }ファイルを構成した後、KDC サービスを再起動します。
次のコマンドを使用して、krbtgt/REALM.COM@AD.COM という名前のプリンシパルを KDC サーバー内に準備します。
Kadmin> addprinc krbtgt/REALM.COM@AD.COMhadoop.security.auth_to_local HDFS サービス構成ファイルに
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//を追加します。
ドメイン コントローラーで:
次の
Ksetupコマンドを実行して、領域のエントリを追加します。C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMWindows ドメインから Kerberos 領域への信頼関係を確立します。 [password] は、krbtgt/REALM.COM@AD.COM プリンシパルのパスワードです。
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Kerberos で使用される暗号化アルゴリズムを選択します。
a. [サーバー マネージャー]>[グループ ポリシー管理]>[ドメイン]>[グループ ポリシー オブジェクト]>[既定のポリシー] または [Active Domain ポリシー] の順に選択し、さらに [編集] を選択します。
b. [グループ ポリシー管理エディター] ペインで、 [コンピューターの構成]>[ポリシー]>[Windows の設定]>[セキュリティの設定]>[ローカル ポリシー]>[セキュリティ オプション] を選択し、 [ネットワーク セキュリティ:Kerberos で許可する暗号化の種類を構成する] を構成します。
c. KDC サーバーに接続する際に使用する暗号化アルゴリズムを選択します。 すべてのオプションを選択できます。
!["[ネットワーク セキュリティ: Kerberos で許可される暗号化の種類の構成]" ペインのスクリーンショット](media/connector-hdfs/config-encryption-types-for-kerberos.png)
d.
Ksetupコマンドを使用して、指定された領域で使用される暗号化アルゴリズムを指定します。C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Windows ドメインで Kerberos プリンシパルを使用できるように、ドメイン アカウントと Kerberos プリンシパル間のマッピングを作成します。
a. [管理ツール]>[Active Directory ユーザーとコンピューター] を選択します。
b. [表示]>[高度な機能] の順に選択して、高度な機能を構成します。
c. [高度な機能] ペインでマッピングを作成するアカウントを右クリックし、 [名前のマッピング] ペインで [Kerberos 名] タブを選択します。
d. 領域からプリンシパルを追加します。
!["[セキュリティ ID のマッピング]" ペインのスクリーンショット](media/connector-hdfs/map-security-identity.png)
セルフホステッド統合ランタイム コンピューターで:
次の
Ksetupコマンドを実行して、領域のエントリを追加します。C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
データ ファクトリまたは Synapse ワークスペースで:
- ドメイン アカウントまたは Kerberos プリンシパルのいずれかを使用して Windows 認証を行って HDFS データ ソースに接続するように HDFS コネクタを構成します。 構成の詳細については、HDFS にリンクされたサービスのプロパティのセクションを参照してください。
Lookup アクティビティのプロパティ
Lookup アクティビティのプロパティについては、Lookup アクティビティに関する記事を参照してください。
Delete アクティビティのプロパティ
Delete アクティビティのプロパティについては、Delete アクティビティに関する記事を参照してください。
レガシ モデル
注意
次のモデルは、下位互換性のために引き続きそのままサポートされます。 作成 UI は新しいモデルを生成するように切り替えられているため、前に説明した新しいモデルを使用することをお勧めします。
レガシ データセット モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは FileShare に設定する必要があります | はい |
| folderPath | フォルダーへのパス。 ワイルドカード フィルターがサポートされています。 使用できるワイルドカードは、* (0 個以上の文字に一致) と ? (0 個または 1 個の文字に一致) です。実際のファイル名にワイルドカードまたは ^ が含まれている場合は、このエスケープ文字を使用してエスケープします。 例: ルートフォルダー/サブフォルダー。「フォルダーとファイル フィルターの例」の例を参照してください。 |
はい |
| fileName | 指定された "folderPath" にあるファイルの名前またはワイルドカード フィルター。 このプロパティの値を指定しない場合、データセットはフォルダー内のすべてのファイルをポイントします。 フィルターに使用できるワイルドカードは、 * (0 個以上の文字に一致) と ? (0 個または 1 個の文字に一致) です。- 例 1: "fileName": "*.csv"- 例 2: "fileName": "???20180427.txt"実際のフォルダー名にワイルドカードまたは ^ が含まれている場合は、このエスケープ文字を使用してエスケープします。 |
いいえ |
| modifiedDatetimeStart | ファイルは、最終変更日時の属性に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は 2018-12-01T05:00:00Z の形式で UTC タイム ゾーンに適用されます。 多数のファイルにファイル フィルターを適用する場合は、この設定を有効にすることで、データ移動の全体的なパフォーマンスが影響を受けることに注意してください。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。 modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値以下であるファイルが選択されます。 |
いいえ |
| modifiedDatetimeEnd | ファイルは、最終変更日時の属性に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は 2018-12-01T05:00:00Z の形式で UTC タイム ゾーンに適用されます。 多数のファイルにファイル フィルターを適用する場合は、この設定を有効にすることで、データ移動の全体的なパフォーマンスが影響を受けることに注意してください。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。 modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値以下であるファイルが選択されます。 |
いいえ |
| format | ファイルベースのストア間でファイルをそのままコピー (バイナリ コピー) する場合は、入力と出力の両方のデータセット定義で format セクションをスキップします。 特定の形式のファイルを解析する場合にサポートされるファイル形式の種類は、TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat です。 形式の type プロパティをいずれかの値に設定します。 詳細については、「テキスト形式」、「JSON 形式」、「AVRO 形式」、「ORC 形式」、Parquet 形式」の各セクションをご覧ください。 |
いいえ (バイナリ コピー シナリオのみ) |
| compression | データの圧縮の種類とレベルを指定します。 詳細については、サポートされるファイル形式と圧縮コーデックに関する記事を参照してください。 サポートされる種類は、Gzip、Deflate、Bzip2、ZipDeflate です。 サポートされるレベルは、Optimal と Fastest です。 |
いいえ |
ヒント
フォルダーの下のすべてのファイルをコピーするには、folderPath のみを指定します。
指定された名前の単一のファイルをコピーするには、フォルダー部分に folderPath、ファイル名に fileName を指定します。
フォルダーの下のファイルのサブセットをコピーするには、フォルダー部分で folderPath、ワイルドカード フィルターで fileName を指定します。
例:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
レガシのコピー アクティビティ ソース モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティ ソースの type プロパティは HdfsSource に設定する必要があります。 | はい |
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive が true に設定されていて、シンクがファイル ベースのストアである場合、空のフォルダーまたはサブフォルダーはシンクでコピーも作成もされません。 使用可能な値: true (既定値) および false。 |
いいえ |
| distcpSettings | HDFS DistCp を使用する場合のプロパティ グループ。 | いいえ |
| resourceManagerEndpoint | YARN リソース マネージャー エンドポイント | はい (DistCp を使用する場合) |
| tempScriptPath | 一時 DistCp コマンド スクリプトを格納するために使用するフォルダー パス。 スクリプト ファイルが生成され、コピー ジョブの完了後に削除されます。 | はい (DistCp を使用する場合) |
| distcpOptions | 追加のオプションが DistCp コマンドに指定されます。 | いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
例:DistCp を使用したコピー アクティビティでの HDFS ソース
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
関連するコンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。