Gegevens kopiëren en transformeren in Azure Database for PostgreSQL met behulp van Azure Data Factory of Synapse Analytics
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt in Azure Data Factory- en Synapse Analytics-pijplijnen om gegevens van en naar Azure Database for PostgreSQL te kopiëren en Gegevensstroom te gebruiken om gegevens te transformeren in Azure Database for PostgreSQL. Lees de inleidende artikelen voor Azure Data Factory en Synapse Analytics voor meer informatie.
Deze connector is gespecialiseerd voor de Azure Database for PostgreSQL-service. Als u gegevens wilt kopiëren uit een algemene PostgreSQL-database die zich on-premises of in de cloud bevindt, gebruikt u de PostgreSQL-connector.
Ondersteunde mogelijkheden
Deze Azure Database for PostgreSQL-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR | Beheerd privé-eindpunt |
|---|---|---|
| Copy-activiteit (bron/sink) | (1) (2) | ✓ |
| Toewijzingsgegevensstroom (bron/sink) | (1) | ✓ |
| Activiteit Lookup | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
De drie activiteiten werken aan alle implementatieopties van Azure Database for PostgreSQL:
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde service maken voor Azure Database for PostgreSQL met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken voor Azure Database for PostgreSQL in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar PostgreSQL en selecteer de Azure-database voor PostgreSQL-connector.
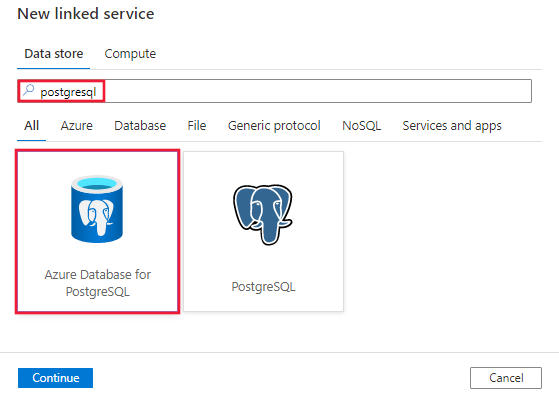
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
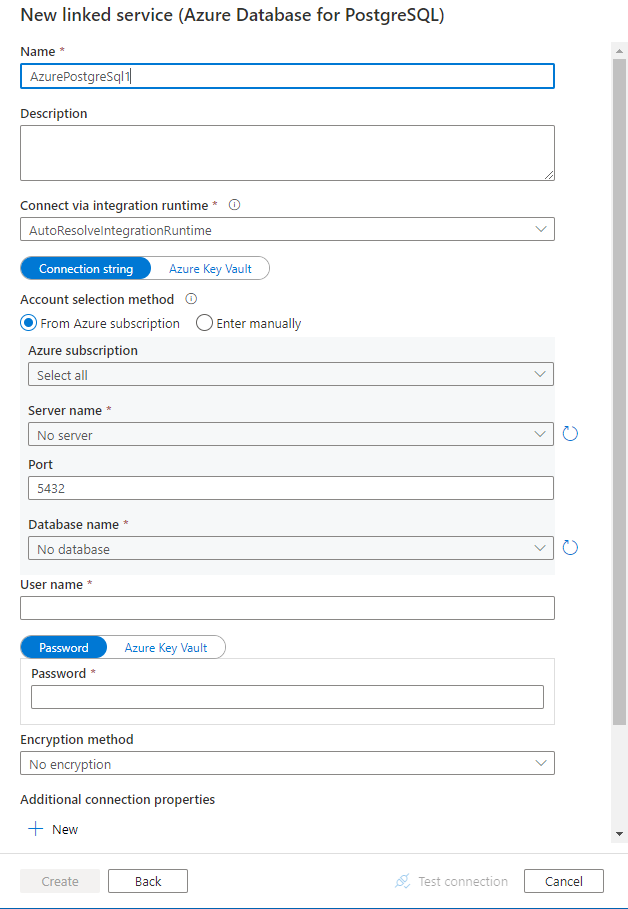
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt voor het definiëren van Data Factory-entiteiten die specifiek zijn voor Azure Database for PostgreSQL-connector.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Database for PostgreSQL-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op: AzurePostgreSql. | Ja |
| connectionString | Een ODBC-verbindingsreeks om verbinding te maken met Azure Database for PostgreSQL. U kunt ook een wachtwoord in Azure Key Vault plaatsen en de password configuratie uit de verbindingsreeks halen. Zie de volgende voorbeelden en sla referenties op in Azure Key Vault voor meer informatie. |
Ja |
| connectVia | Deze eigenschap vertegenwoordigt de integration runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt Azure Integration Runtime of zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Een typische verbindingsreeks is Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Hier volgen meer eigenschappen die u per geval kunt instellen:
| Eigenschappen | Beschrijving | Opties | Vereist |
|---|---|---|---|
| EncryptionMethod (EM) | De methode die het stuurprogramma gebruikt om gegevens te versleutelen die worden verzonden tussen het stuurprogramma en de databaseserver. Bijvoorbeeld EncryptionMethod=<0/1/6>; |
0 (geen versleuteling) (standaard) / 1 (SSL) / 6 (RequestSSL) | Nee |
| ValidateServerCertificate (VSC) | Bepaalt of het stuurprogramma het certificaat valideert dat door de databaseserver wordt verzonden wanneer SSL-versleuteling is ingeschakeld (Encryption Method=1). Bijvoorbeeld ValidateServerCertificate=<0/1>; |
0 (uitgeschakeld) (standaard) / 1 (ingeschakeld) | Nee |
Voorbeeld:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Voorbeeld:
Wachtwoord opslaan in Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Eigenschappen van gegevensset
Zie Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets. Deze sectie bevat een lijst met eigenschappen die azure Database for PostgreSQL ondersteunt in gegevenssets.
Als u gegevens uit Azure Database for PostgreSQL wilt kopiëren, stelt u de typeeigenschap van de gegevensset in op AzurePostgreSqlTable. De volgende eigenschappen worden ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AzurePostgreSqlTable | Ja |
| tableName | Naam van de tabel | Nee (als 'query' in de activiteitsbron is opgegeven) |
Voorbeeld:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Eigenschappen van de kopieeractiviteit
Zie Pijplijnen en activiteiten voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door een Azure Database for PostgreSQL-bron.
Azure Database for PostgreSql als bron
Als u gegevens wilt kopiëren uit Azure Database for PostgreSQL, stelt u het brontype in de kopieeractiviteit in op AzurePostgreSqlSource. De volgende eigenschappen worden ondersteund in de sectie bron van kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op AzurePostgreSqlSource | Ja |
| query | Gebruik de aangepaste SQL-query om gegevens te lezen. Bijvoorbeeld: SELECT * FROM mytable of SELECT * FROM "MyTable". Opmerking in PostgreSQL: de naam van de entiteit wordt behandeld als niet hoofdlettergevoelig als deze niet wordt geciteerd. |
Nee (als de eigenschap tableName in de gegevensset is opgegeven) |
| queryTimeout | De wachttijd voordat de poging om een opdracht uit te voeren wordt beëindigd en een fout genereert, is de standaardwaarde 120 minuten. Als de parameter voor deze eigenschap is ingesteld, zijn toegestane waarden tijdspanne, zoals '02:00:00' (120 minuten). Zie CommandTimeout voor meer informatie. | Nee |
| partitionOptions | Hiermee geeft u de opties voor gegevenspartitionering op die worden gebruikt voor het laden van gegevens uit Azure SQL Database. Toegestane waarden zijn: Geen (standaard), PhysicalPartitionsOfTable en DynamicRange. Wanneer een partitieoptie is ingeschakeld (dat wil niet None), wordt de mate van parallelle uitvoering om gegevens uit een Azure SQL Database gelijktijdig te laden, bepaald door de parallelCopies instelling voor de kopieeractiviteit. |
Nee |
| partitionSettings | Geef de groep van de instellingen voor gegevenspartitionering op. Toepassen wanneer de partitieoptie niet Noneis. |
Nee |
Onder partitionSettings: |
||
| partitionNames | De lijst met fysieke partities die moeten worden gekopieerd. Toepassen wanneer de partitieoptie is PhysicalPartitionsOfTable. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?AdfTabularPartitionName aan de WHERE-component. Zie de sectie Parallel kopiëren uit Azure Database for PostgreSQL voor een voorbeeld. |
Nee |
| partitionColumnName | Geef de naam op van de bronkolom in geheel getal of datum/datum/tijd -type (int, smallintbigint, date, of timestamp without time zonetimestamp with time zonetime without time zone) dat wordt gebruikt door bereikpartitionering voor parallelle kopie. Als deze niet is opgegeven, wordt de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als partitiekolom.Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?AdfRangePartitionColumnName aan de WHERE-component. Zie de sectie Parallel kopiëren uit Azure Database for PostgreSQL voor een voorbeeld. |
Nee |
| partitionUpperBound | De maximale waarde van de partitiekolom om gegevens te kopiëren. Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?AdfRangePartitionUpbound aan de WHERE-component. Zie de sectie Parallel kopiëren uit Azure Database for PostgreSQL voor een voorbeeld. |
Nee |
| partitionLowerBound | De minimale waarde van de partitiekolom om gegevens te kopiëren. Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?AdfRangePartitionLowbound aan de WHERE-component. Zie de sectie Parallel kopiëren uit Azure Database for PostgreSQL voor een voorbeeld. |
Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for PostgreSQL als sink
Als u gegevens wilt kopiëren naar Azure Database for PostgreSQL, worden de volgende eigenschappen ondersteund in de sectie sink voor kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de sink van de kopieeractiviteit moet worden ingesteld op AzurePostgreSQLSink. | Ja |
| preCopyScript | Geef in elke uitvoering een SQL-query op voor de kopieeractiviteit die moet worden uitgevoerd voordat u gegevens naar Azure Database for PostgreSQL schrijft. U kunt deze eigenschap gebruiken om de vooraf geladen gegevens op te schonen. | Nee |
| writeMethod | De methode die wordt gebruikt voor het schrijven van gegevens naar Azure Database for PostgreSQL. Toegestane waarden zijn: CopyCommand (standaard, wat beter presteert), BulkInsert. |
Nee |
| writeBatchSize | Het aantal rijen dat per batch in Azure Database for PostgreSQL is geladen. Toegestane waarde is een geheel getal dat het aantal rijen aangeeft. |
Nee (standaard is 1.000.000) |
| writeBatchTimeout | Wachttijd voordat de batchinvoegbewerking is voltooid voordat er een time-out optreedt. Toegestane waarden zijn tijdspantekenreeksen. Een voorbeeld is 00:30:00 (30 minuten). |
Nee (standaard is 00:30:00) |
Voorbeeld:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Parallel kopiëren vanuit Azure Database for PostgreSQL
De Azure Database for PostgreSQL-connector in kopieeractiviteit biedt ingebouwde gegevenspartitionering om gegevens parallel te kopiëren. U vindt opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.
Wanneer u gepartitioneerde kopie inschakelt, worden parallelle query's uitgevoerd op uw Azure Database for PostgreSQL-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de parallelCopies instelling voor de kopieeractiviteit. Als u bijvoorbeeld instelt op parallelCopies vier, genereert de service gelijktijdig vier query's en voert deze uit op basis van de opgegeven partitieoptie en -instellingen. Elke query haalt een deel van de gegevens op uit uw Azure Database for PostgreSQL.
U wordt aangeraden parallelle kopie met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens uit uw Azure Database for PostgreSQL laadt. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, is het raadzaam om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige belasting van grote tabellen, met fysieke partities. |
Partitieoptie: fysieke partities van de tabel. Tijdens de uitvoering detecteert de service automatisch de fysieke partities en kopieert de gegevens per partitie. |
| Volledige belasting van grote tabellen, zonder fysieke partities, terwijl met een kolom met gehele getallen voor gegevenspartitionering. |
Partitieopties: partitie dynamisch bereik. Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Als dit niet is opgegeven, wordt de primaire-sleutelkolom gebruikt. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, met fysieke partities. |
Partitieoptie: fysieke partities van de tabel. Query: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Partitienaam: geef de partitienaam(en) op waaruit u gegevens wilt kopiëren. Als dit niet is opgegeven, detecteert de service automatisch de fysieke partities in de tabel die u hebt opgegeven in de PostgreSQL-gegevensset. Tijdens de uitvoering wordt de service vervangen door ?AdfTabularPartitionName de werkelijke partitienaam en verzonden naar Azure Database for PostgreSQL. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, zonder fysieke partities, terwijl met een kolom geheel getal voor gegevenspartitionering. |
Partitieopties: partitie dynamisch bereik. Query: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. U kunt partitioneren op basis van de kolom met een geheel getal of een datum/datum/tijd-gegevenstype. Bovengrens en partitieondergrens partitioneren: geef op of u wilt filteren op partitiekolom om alleen gegevens op te halen tussen het onderste en bovenste bereik. Tijdens de uitvoering vervangt ?AdfRangePartitionColumnNamede service, ?AdfRangePartitionUpbounden ?AdfRangePartitionLowbound door de werkelijke kolomnaam en waardebereiken voor elke partitie en verzendt deze naar Azure Database for PostgreSQL. Als de partitiekolom 'ID' bijvoorbeeld is ingesteld met de ondergrens 1 en de bovengrens als 80, waarbij parallelle kopie is ingesteld als 4, haalt de service gegevens op met 4 partities. Hun id's liggen tussen [1.20], [21, 40], [41, 60] en [61, 80], respectievelijk. |
Aanbevolen procedures voor het laden van gegevens met partitieoptie:
- Kies een onderscheidende kolom als partitiekolom (zoals primaire sleutel of unieke sleutel) om scheeftrekken van gegevens te voorkomen.
- Als de tabel een ingebouwde partitie heeft, gebruikt u de partitieoptie Fysieke partities van de tabel om betere prestaties te krijgen.
- Als u Azure Integration Runtime gebruikt om gegevens te kopiëren, kunt u grotere 'Data-Integratie eenheden (DIU)' (>4) instellen om meer rekenresources te gebruiken. Controleer de toepasselijke scenario's daar.
- "Mate van kopieerparallellisme" bepaalt de partitienummers, stelt dit getal een beetje te groot voor de prestaties, raadt u aan dit getal in te stellen als (DIU of het aantal zelf-hostende IR-knooppunten) * (2 tot 4).
Voorbeeld: volledige belasting van grote tabellen met fysieke partities
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Voorbeeld: query met partitie dynamisch bereik
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Eigenschappen van toewijzingsgegevensstroom
Wanneer u gegevens transformeert in de toewijzingsgegevensstroom, kunt u tabellen lezen en schrijven vanuit Azure Database for PostgreSQL. Zie de brontransformatie en sinktransformatie in toewijzingsgegevensstromen voor meer informatie. U kunt ervoor kiezen om een Azure Database for PostgreSQL-gegevensset of een inlinegegevensset te gebruiken als bron- en sinktype.
Brontransformatie
De onderstaande tabel bevat de eigenschappen die worden ondersteund door de Bron van Azure Database for PostgreSQL. U kunt deze eigenschappen bewerken op het tabblad Bronopties .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Tabel | Als u Tabel als invoer selecteert, haalt de gegevensstroom alle gegevens op uit de tabel die is opgegeven in de gegevensset. | Nee | - |
(alleen voor inlinegegevensset) tableName |
| Query | Als u Query als invoer selecteert, geeft u een SQL-query op om gegevens op te halen uit de bron, waardoor elke tabel die u opgeeft in de gegevensset overschrijft. Het gebruik van query's is een uitstekende manier om rijen te verminderen voor tests of zoekacties. Order By-component wordt niet ondersteund, maar u kunt een volledige SELECT FROM-instructie instellen. U kunt ook door de gebruiker gedefinieerde tabelfuncties gebruiken. select * from udfGetData() is een UDF in SQL die een tabel retourneert die u in de gegevensstroom kunt gebruiken. Queryvoorbeeld: select * from mytable where customerId > 1000 and customerId < 2000 of select * from "MyTable". Opmerking in PostgreSQL: de naam van de entiteit wordt behandeld als niet hoofdlettergevoelig als deze niet wordt geciteerd. |
Nee | String | query |
| Schemanaam | Als u Opgeslagen procedure als invoer selecteert, geeft u een schemanaam van de opgeslagen procedure op of selecteert u Vernieuwen om de service te vragen de schemanamen te detecteren. | Nee | String | schemaName |
| Opgeslagen procedure | Als u Opgeslagen procedure als invoer selecteert, geeft u een naam op van de opgeslagen procedure om gegevens uit de brontabel te lezen of selecteert u Vernieuwen om de service te vragen de namen van de procedure te detecteren. | Ja (als u Opgeslagen procedure als invoer selecteert) | String | procedureNaam |
| Procedureparameters | Als u Opgeslagen procedure als invoer selecteert, geeft u invoerparameters op voor de opgeslagen procedure in de volgorde die in de procedure is ingesteld of selecteert u Importeren om alle procedureparameters te importeren met behulp van het formulier @paraName. |
Nee | Matrix | Ingangen |
| Batchgrootte | Geef een batchgrootte op om grote gegevens in batches te segmenteren. | Nee | Geheel getal | batchSize |
| Isolatieniveau | Kies een van de volgende isolatieniveaus: - Vastgelegd lezen - Niet-verzonden lezen (standaard) - Herhaalbare leesbewerking -Serializable - Geen (isolatieniveau negeren) |
Nee | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE GEEN |
isolationLevel |
Voorbeeld van azure Database for PostgreSQL-bronscript
Wanneer u Azure Database for PostgreSQL als brontype gebruikt, is het bijbehorende gegevensstroomscript:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Sinktransformatie
De onderstaande tabel bevat de eigenschappen die worden ondersteund door de Sink van Azure Database for PostgreSQL. U kunt deze eigenschappen bewerken op het tabblad Sink-opties .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Bijwerkingsmethode | Geef op welke bewerkingen zijn toegestaan op uw databasebestemming. De standaardinstelling is om alleen invoegingen toe te staan. Als u rijen wilt bijwerken, upsert of verwijderen, is een transformatie van een alter row vereist om rijen voor deze acties te taggen. |
Ja |
true of false |
te verwijderen invoegbaar kan worden bijgewerkt upsertable |
| Sleutelkolommen | Voor updates, upserts en verwijderingen moet sleutelkolom(en) worden ingesteld om te bepalen welke rij moet worden gewijzigd. De kolomnaam die u als sleutel kiest, wordt gebruikt als onderdeel van de volgende update, upsert, delete. Daarom moet u een kolom kiezen die bestaat in de sinktoewijzing. |
Nee | Matrix | keys |
| Schrijven van sleutelkolommen overslaan | Als u de waarde niet naar de sleutelkolom wilt schrijven, selecteert u 'Schrijfsleutelkolommen overslaan'. | Nee |
true of false |
skipKeyWrites |
| Tabelactie | Bepaalt of alle rijen uit de doeltabel opnieuw moeten worden gemaakt of verwijderd voordat ze worden geschreven. - Geen: Er wordt geen actie uitgevoerd voor de tabel. - Opnieuw maken: de tabel wordt verwijderd en opnieuw gemaakt. Vereist als u dynamisch een nieuwe tabel maakt. - Afkappen: alle rijen uit de doeltabel worden verwijderd. |
Nee |
true of false |
recreëren truncate |
| Batchgrootte | Geef op hoeveel rijen er in elke batch worden geschreven. Grotere batchgrootten verbeteren compressie en geheugenoptimalisatie, maar risico op geheugenuitzonderingen bij het opslaan van gegevens in de cache. | Nee | Geheel getal | batchSize |
| Gebruikersdatabaseschema selecteren | Standaard wordt er een tijdelijke tabel gemaakt onder het sinkschema als fasering. U kunt ook de optie Sink-schema gebruiken uitschakelen en in plaats daarvan een schemanaam opgeven waaronder Data Factory een faseringstabel maakt om upstreamgegevens te laden en deze automatisch op te schonen na voltooiing. Zorg ervoor dat u een tabelmachtiging hebt gemaakt in de database en dat u de machtiging voor het schema wijzigt. | Nee | String | stagingSchemaName |
| Pre- en post-SQL-scripts | Geef SQL-scripts met meerdere regels op die worden uitgevoerd vóór (voorverwerking) en na (naverwerking) gegevens naar uw Sink-database worden geschreven. | Nee | String | preSQLs postSQLs |
Tip
- Het is raadzaam om scripts met één batch met meerdere opdrachten in meerdere batches te splitsen.
- Alleen DDL-instructies (Data Definition Language) en DML-instructies (Data Definition Language) die een eenvoudig aantal updates retourneren, kunnen worden uitgevoerd als onderdeel van een batch. Meer informatie over het uitvoeren van batchbewerkingen
Incrementeel extraheren inschakelen: gebruik deze optie om ADF te laten weten dat alleen rijen moeten worden verwerkt die zijn gewijzigd sinds de laatste keer dat de pijplijn is uitgevoerd.
Incrementele kolom: Wanneer u de functie incrementeel extraheren gebruikt, moet u de datum/tijd of numerieke kolom kiezen die u wilt gebruiken als het watermerk in de brontabel.
Begin met lezen: Als u deze optie instelt met incrementeel uitpakken, wordt ADF geïnstrueerd om alle rijen te lezen bij de eerste uitvoering van een pijplijn, waarbij incrementeel extract is ingeschakeld.
Voorbeeld van azure Database for PostgreSQL-sinkscript
Wanneer u Azure Database for PostgreSQL als sinktype gebruikt, is het bijbehorende gegevensstroomscript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Eigenschappen van opzoekactiviteit
Zie Lookup-activiteit voor meer informatie over de eigenschappen.
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.