Azure Virtual Desktop to kompleksowa usługa wirtualizacji pulpitu i aplikacji działająca na platformie Microsoft Azure. Usługa Virtual Desktop pomaga zapewnić bezpieczne środowisko pulpitu zdalnego, które pomaga organizacjom zwiększyć odporność biznesową. Zapewnia uproszczone zarządzanie, wielosesyjne systemy Windows 10 i 11 Enterprise oraz optymalizacje Aplikacje Microsoft 365 dla przedsiębiorstw. Za pomocą usługi Virtual Desktop możesz wdrażać i skalować pulpity i aplikacje systemu Windows na platformie Azure w ciągu kilku minut, zapewniając zintegrowane funkcje zabezpieczeń i zgodności, aby zapewnić bezpieczeństwo aplikacji i danych.
W miarę kontynuowania pracy zdalnej w organizacji za pomocą usługi Virtual Desktop ważne jest zrozumienie możliwości odzyskiwania po awarii i najlepszych rozwiązań. Te rozwiązania wzmacniają niezawodność w różnych regionach, aby zapewnić bezpieczeństwo danych i produktywność pracowników. Ten artykuł zawiera zagadnienia dotyczące wymagań wstępnych dotyczących ciągłości działania i odzyskiwania po awarii (BCDR), kroków wdrażania i najlepszych rozwiązań. Dowiesz się więcej na temat opcji, strategii i wskazówek dotyczących architektury. Zawartość tego dokumentu umożliwia przygotowanie pomyślnego planu BCDR i może pomóc zwiększyć odporność firmy podczas planowanych i nieplanowanych zdarzeń przestojów.
Istnieje kilka typów awarii i awarii, a każdy może mieć inny wpływ. Odporność i odzyskiwanie są szczegółowo omówione w przypadku zdarzeń lokalnych i regionalnych, w tym odzyskiwania usługi w innym regionie zdalnym platformy Azure. Ten typ odzyskiwania jest nazywany odzyskiwaniem po awarii geograficznej. Tworzenie architektury pulpitu wirtualnego w celu zapewnienia odporności i dostępności ma kluczowe znaczenie. Należy zapewnić maksymalną odporność lokalną, aby zmniejszyć wpływ zdarzeń awarii. Ta odporność zmniejsza również wymagania dotyczące wykonywania procedur odzyskiwania. Ten artykuł zawiera również informacje o wysokiej dostępności i najlepszych rozwiązaniach.
Płaszczyzna sterowania pulpitu wirtualnego
Usługa Virtual Desktop oferuje trasę BCDR dla swojej płaszczyzny sterowania, aby zachować metadane klientów podczas przestojów. Gdy wystąpi awaria w regionie, składniki infrastruktury usługi przełączą się w tryb failover do lokalizacji pomocniczej i będą nadal działać normalnie. Nadal możesz uzyskiwać dostęp do metadanych związanych z usługą, a użytkownicy nadal mogą łączyć się z dostępnymi hostami. Połączenia użytkowników końcowych pozostają w trybie online, jeśli środowisko dzierżawy lub hosty pozostaną dostępne. Lokalizacje danych usługi Azure Virtual Desktop różnią się od lokalizacji wdrożenia maszyn wirtualnych hostów sesji puli hostów. Można zlokalizować metadane usługi Virtual Desktop w jednym z obsługiwanych regionów, a następnie wdrożyć maszyny wirtualne w innej lokalizacji. Nie jest wymagana żadna inna akcja.

Cele i zakres
Cele tego przewodnika to:
- Zapewnij maksymalną dostępność, odporność i możliwość odzyskiwania po awarii geograficznej, jednocześnie minimalizując utratę danych dla ważnych wybranych danych użytkownika.
- Zminimalizuj czas odzyskiwania.
Te cele są również znane jako cel punktu odzyskiwania (RPO) i cel czasu odzyskiwania (RTO).
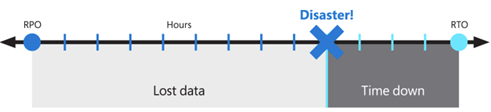
Proponowane rozwiązanie zapewnia lokalną wysoką dostępność, ochronę przed awarią pojedynczej strefy dostępności i ochronę przed awarią całego regionu świadczenia usługi Azure. Jest on oparty na nadmiarowym wdrożeniu w innym lub pomocniczym regionie świadczenia usługi Azure, aby odzyskać usługę. Chociaż nadal jest to dobra praktyka, usługa Virtual Desktop i technologia używana do tworzenia trasy BCDR nie wymagają sparowania regionów platformy Azure. Lokalizacje podstawowe i pomocnicze mogą być dowolną kombinacją regionów świadczenia usługi Azure, jeśli opóźnienie sieci na to zezwala.
Aby zmniejszyć wpływ awarii pojedynczej strefy dostępności, użyj odporności, aby zwiększyć wysoką dostępność:
- W warstwie obliczeniowej rozłóż hosty sesji usługi Virtual Desktop w różnych strefach dostępności.
- W warstwie magazynu użyj odporności strefy, gdy jest to możliwe.
- W warstwie sieciowej wdróż odporne na strefy bramy usługi Azure ExpressRoute i wirtualnej sieci prywatnej (VPN).
- Dla każdej zależności przejrzyj wpływ awarii pojedynczej strefy i zaplanuj środki zaradcze. Na przykład wdróż kontrolery domena usługi Active Directory i inne zasoby zewnętrzne dostępne przez użytkowników usługi Virtual Desktop w wielu strefach.
W zależności od liczby używanych stref dostępności należy ocenić nadmierną aprowizację hostów sesji, aby zrekompensować utratę jednej strefy. Na przykład nawet w przypadku dostępnych stref (n-1) można zapewnić środowisko użytkownika i wydajność.
Uwaga
Strefy dostępności platformy Azure to funkcja wysokiej dostępności, która może zwiększyć odporność. Nie należy jednak brać pod uwagę rozwiązania odzyskiwania po awarii, które może chronić przed awariami obejmującymi cały region.

Ze względu na możliwe kombinacje typów, opcji replikacji, możliwości usługi i ograniczeń dostępności w niektórych regionach składnik pamięci podręcznej w chmurze z fsLogixjest używany zamiast określonych mechanizmów replikacji magazynu.
Usługa OneDrive nie jest opisana w tym artykule. Aby uzyskać więcej informacji na temat nadmiarowości i wysokiej dostępności, zobacz Odporność danych programu SharePoint i usługi OneDrive na platformie Microsoft 365.
W pozostałej części tego artykułu poznasz rozwiązania dla dwóch różnych typów puli hostów usługi Virtual Desktop. Dostępne są również obserwacje, dzięki którym można porównać tę architekturę z innymi rozwiązaniami:
- Osobiste: W tym typie puli hostów użytkownik ma trwale przypisanego hosta sesji, który nigdy nie powinien ulec zmianie. Ponieważ jest ona osobista, ta maszyna wirtualna może przechowywać dane użytkownika. Założeniem jest użycie technik replikacji i tworzenia kopii zapasowych w celu zachowania i ochrony stanu.
- W puli: użytkownicy są tymczasowo przypisani do jednej z dostępnych maszyn wirtualnych hosta sesji z puli, bezpośrednio za pośrednictwem grupy aplikacji klasycznych lub przy użyciu aplikacji zdalnych. Maszyny wirtualne są bezstanowe, a dane i profile użytkowników są przechowywane w magazynie zewnętrznym lub w usłudze OneDrive.
Omówiono implikacje dotyczące kosztów, ale głównym celem jest zapewnienie efektywnego wdrożenia odzyskiwania po awarii geograficznej przy minimalnej utracie danych. Aby uzyskać więcej szczegółów bcDR, zobacz następujące zasoby:
- Zagadnienia dotyczące bcDR dotyczące usługi Virtual Desktop
- Odzyskiwanie po awarii usługi Virtual Desktop
Wymagania wstępne
Wdróż podstawową infrastrukturę i upewnij się, że jest ona dostępna w regionie podstawowym i pomocniczym platformy Azure. Aby uzyskać wskazówki dotyczące topologii sieci, możesz użyć topologii sieci platformy Azure Cloud Adoption Framework i modeli łączności :
- Tradycyjna topologia sieci platformy Azure
- Topologia sieci wirtualnej sieci WAN (zarządzana przez firmę Microsoft)
W obu modelach należy wdrożyć podstawową pulę hostów usługi Virtual Desktop i pomocnicze środowisko odzyskiwania po awarii w różnych sieciach wirtualnych szprych i połączyć je z każdym koncentratorem w tym samym regionie. Umieść jedno centrum w lokalizacji podstawowej, jedno centrum w lokalizacji pomocniczej, a następnie ustanów łączność między nimi.
Centrum ostatecznie zapewnia łączność hybrydową z zasobami lokalnymi, usługami zapory, zasobami tożsamości, takimi jak kontrolery domena usługi Active Directory i zasobami zarządzania, takimi jak Log Analytics.
Należy rozważyć wszelkie aplikacje biznesowe i dostępność zasobów zależnych po przejściu w tryb failover do lokalizacji pomocniczej.
Aktywny-aktywny a aktywny-pasywny
Jeśli różne zestawy użytkowników mają różne wymagania BCDR, firma Microsoft zaleca używanie wielu pul hostów z różnymi konfiguracjami. Na przykład użytkownicy z aplikacją o znaczeniu krytycznym mogą przypisywać w pełni nadmiarową pulę hostów z funkcjami odzyskiwania po awarii geograficznej. Jednak użytkownicy deweloperzy i testowi mogą używać oddzielnej puli hostów bez odzyskiwania po awarii.
Dla każdej pojedynczej puli hostów usługi Virtual Desktop można opierać strategię BCDR na modelu aktywne-aktywne lub aktywne-pasywne. W tym kontekście zakłada się, że ten sam zestaw użytkowników w jednej lokalizacji geograficznej jest obsługiwany przez określoną pulę hostów.
Aktywne-aktywne
Dla każdej puli hostów w regionie podstawowym należy wdrożyć drugą pulę hostów w regionie pomocniczym.
Ta konfiguracja zapewnia prawie zero celu czasu odzyskiwania, a cel punktu odzyskiwania ma dodatkowy koszt.
Nie musisz, aby administrator interweniował ani nie przejechał w tryb failover. Podczas normalnych operacji pomocnicza pula hostów udostępnia użytkownikowi zasoby usługi Virtual Desktop.
Każda pula hostów ma własne konto magazynu dla profilów trwałych użytkowników.
Należy ocenić opóźnienie na podstawie dostępnej lokalizacji fizycznej i łączności użytkownika. W przypadku niektórych regionów platformy Azure, takich jak Europa Zachodnia i Europa Północna, różnica może być niewielka w przypadku uzyskiwania dostępu do regionów podstawowych lub pomocniczych. Ten scenariusz można zweryfikować przy użyciu narzędzia do szacowania środowiska usługi Azure Virtual Desktop.
Użytkownicy są przypisywani do różnych grup aplikacji, takich jak aplikacje klasyczne i zdalne, zarówno w pulach hostów podstawowych, jak i pomocniczych. W takim przypadku będą one widzieć zduplikowane wpisy w kanale informacyjnym klienta usługi Virtual Desktop. Aby uniknąć nieporozumień, użyj oddzielnych obszarów roboczych usługi Virtual Desktop z przejrzystymi nazwami i etykietami, które odzwierciedlają przeznaczenie każdego zasobu. Poinformuj użytkowników o użyciu tych zasobów.
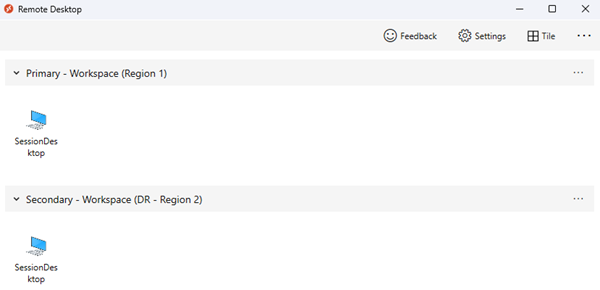
Jeśli potrzebujesz magazynu do zarządzania profilami FSLogix i kontenerami pakietu Office, użyj usługi Cloud Cache, aby zapewnić prawie zero celu punktu odzyskiwania.
- Aby uniknąć konfliktów profilów, nie zezwalaj użytkownikom na dostęp do obu pul hostów jednocześnie.
- Ze względu na aktywny-aktywny charakter tego scenariusza należy edukować użytkowników, jak korzystać z tych zasobów w odpowiedni sposób.
Aktywny-pasywny
- Podobnie jak aktywne-aktywne, dla każdej puli hostów w regionie podstawowym należy wdrożyć drugą pulę hostów w regionie pomocniczym.
- Ilość zasobów obliczeniowych aktywnych w regionie pomocniczym jest zmniejszana w porównaniu z regionem podstawowym, w zależności od dostępnego budżetu. Możesz użyć automatycznego skalowania, aby zapewnić większą pojemność obliczeniową, ale wymaga więcej czasu, a pojemność platformy Azure nie jest gwarantowana.
- Ta konfiguracja zapewnia wyższy cel czasu odzyskiwania w porównaniu z podejściem aktywny-aktywny, ale jest tańsza.
- Jeśli wystąpi awaria platformy Azure, potrzebna jest interwencja administratora w celu wykonania procedury trybu failover. Pomocnicza pula hostów zwykle nie zapewnia użytkownikom dostępu do zasobów usługi Virtual Desktop.
- Każda pula hostów ma własne konta magazynu dla profilów użytkowników trwałych.
- Użytkownicy korzystający z usług pulpitu wirtualnego z optymalnym opóźnieniem i wydajnością mają wpływ tylko wtedy, gdy wystąpi awaria platformy Azure. Ten scenariusz należy zweryfikować przy użyciu narzędzia do szacowania środowiska usługi Azure Virtual Desktop. Wydajność powinna być akceptowalna, nawet jeśli jest obniżona, dla pomocniczego środowiska odzyskiwania po awarii.
- Użytkownicy są przypisywani tylko do jednego zestawu grup aplikacji, takich jak pulpit i aplikacje zdalne. Podczas normalnych operacji te aplikacje znajdują się w podstawowej puli hostów. Podczas awarii i po przejściu w tryb failover użytkownicy są przypisywani do grup aplikacji w pomocniczej puli hostów. Żadne zduplikowane wpisy nie są wyświetlane w kanale informacyjnym klienta usługi Virtual Desktop użytkownika, mogą używać tego samego obszaru roboczego, a wszystko jest dla nich niewidoczne.
- Jeśli potrzebujesz magazynu do zarządzania profilami FSLogix i kontenerami pakietu Office, użyj usługi Cloud Cache, aby zapewnić prawie zero celu punktu odzyskiwania.
- Aby uniknąć konfliktów profilów, nie zezwalaj użytkownikom na dostęp do obu pul hostów jednocześnie. Ponieważ ten scenariusz jest aktywny-pasywny, administratorzy mogą wymuszać to zachowanie na poziomie grupy aplikacji. Dopiero po zakończeniu procedury trybu failover użytkownik może uzyskać dostęp do każdej grupy aplikacji w pomocniczej puli hostów. Dostęp jest odwołany w podstawowej grupie aplikacji puli hostów i ponownie przypisywany do grupy aplikacji w pomocniczej puli hostów.
- Wykonaj tryb failover dla wszystkich grup aplikacji. W przeciwnym razie użytkownicy korzystający z różnych grup aplikacji w różnych pulach hostów mogą powodować konflikty profilów, jeśli nie są skutecznie zarządzane.
- Można zezwolić określonym podzbiorowi użytkowników na selektywne przełączanie w tryb failover do pomocniczej puli hostów i zapewnienie ograniczonego zachowania aktywne-aktywne oraz możliwość testowania trybu failover. Istnieje również możliwość przełączania określonych grup aplikacji w tryb failover, ale należy edukować użytkowników, aby nie używali zasobów z różnych pul hostów w tym samym czasie.
W określonych okolicznościach można utworzyć jedną pulę hostów z kombinacją hostów sesji znajdujących się w różnych regionach. Zaletą tego rozwiązania jest to, że jeśli masz jedną pulę hostów, nie ma potrzeby duplikowania definicji i przypisań dla aplikacji klasycznych i zdalnych. Niestety, to rozwiązanie ma kilka wad.
- W przypadku pul hostów w puli nie można wymusić, aby użytkownik był hostem sesji w tym samym regionie.
- Użytkownik może mieć większe opóźnienie i nieoptymalną wydajność podczas nawiązywania połączenia z hostem sesji w regionie zdalnym.
- Jeśli potrzebujesz magazynu dla profilów użytkowników, potrzebna jest złożona konfiguracja do zarządzania przypisaniami hostów sesji w regionach podstawowych i pomocniczych.
- Możesz użyć trybu opróżniania, aby tymczasowo wyłączyć dostęp do hostów sesji znajdujących się w regionie pomocniczym. Jednak ta metoda wprowadza większą złożoność, nakłady pracy związane z zarządzaniem i nieefektywne wykorzystanie zasobów.
- Hosty sesji można obsługiwać w stanie offline w regionach pomocniczych, ale zwiększa złożoność i obciążenie związane z zarządzaniem.
Zagadnienia i zalecenia
Ogólne
Aby wdrożyć konfigurację aktywne-aktywne lub aktywne-pasywne przy użyciu wielu pul hostów i mechanizmu pamięci podręcznej chmury FSLogix, można utworzyć pulę hostów w tym samym obszarze roboczym lub innym, w zależności od modelu. Takie podejście wymaga zachowania wyrównania i aktualizacji, zachowywania synchronizacji obu pul hostów i na tym samym poziomie konfiguracji. Oprócz nowej puli hostów dla pomocniczego regionu odzyskiwania po awarii potrzebne są następujące elementy:
- Aby utworzyć nowe odrębne grupy aplikacji i powiązane aplikacje dla nowej puli hostów.
- Aby odwołać przypisania użytkowników do podstawowej puli hostów, a następnie ręcznie ponownie przypisać je do nowej puli hostów podczas pracy w trybie failover.
Zapoznaj się z opcjami ciągłości działania i odzyskiwania po awarii dla produktu FSLogix.
- W tym dokumencie nie opisano odzyskiwania profilu.
- Pamięć podręczna w chmurze (aktywna/pasywna) jest zawarta w tym dokumencie, ale jest implementowana przy użyciu tej samej puli hostów.
- Pamięć podręczna w chmurze (aktywna/aktywna) jest omówiona w pozostałej części tego dokumentu.
Istnieją pewne limity dla zasobów usługi Virtual Desktop. Aby uzyskać więcej informacji, zobacz Limity usługi Azure Virtual Desktop.
W przypadku diagnostyki i monitorowania użyj tego samego obszaru roboczego usługi Log Analytics zarówno dla podstawowej, jak i pomocniczej puli hostów.
Compute
W przypadku wdrażania obu pul hostów w regionach podstawowego i pomocniczego odzyskiwania po awarii należy użyć stref dostępności platformy Azure i rozłożyć flotę maszyn wirtualnych na wszystkie dostępne strefy. Jeśli strefy dostępności nie są dostępne w regionie lokalnym, możesz użyć zestawu dostępności platformy Azure.
Złoty obraz używany do wdrażania puli hostów w regionie odzyskiwania po awarii pomocniczej powinien być taki sam, jak w przypadku podstawowego. Obrazy należy przechowywać w galerii obliczeń platformy Azure i konfigurować wiele replik obrazów zarówno w lokalizacjach podstawowych, jak i pomocniczych. Każda replika obrazu może utrzymywać równoległe wdrożenie maksymalnej liczby maszyn wirtualnych i może wymagać więcej niż jednego na podstawie żądanego rozmiaru partii wdrożenia. Aby uzyskać więcej informacji, zobacz Przechowywanie i udostępnianie obrazów w galerii obliczeń platformy Azure.
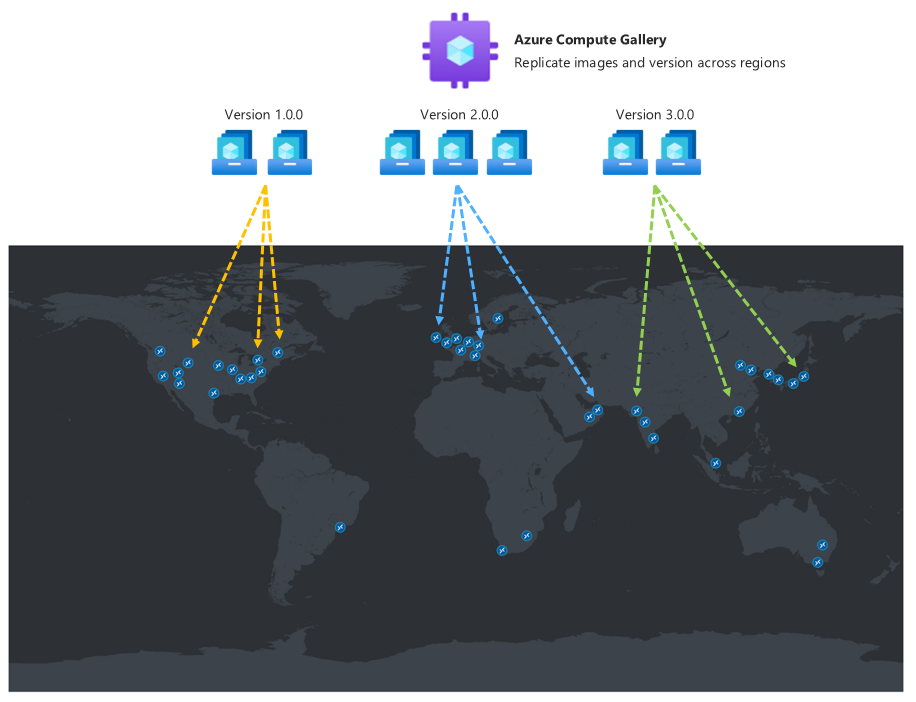
Galeria zasobów obliczeniowych platformy Azure nie jest zasobem globalnym, dlatego zaleca się posiadanie co najmniej galerii pomocniczej w regionie pomocniczym. Po utworzeniu w regionie podstawowym galerii definicja obrazu maszyny wirtualnej i wersja obrazu maszyny wirtualnej należy utworzyć te same trzy obiekty również w regionie pomocniczym. Podczas tworzenia wersji obrazu maszyny wirtualnej istnieje możliwość skopiowania wersji obrazu maszyny wirtualnej utworzonej w regionie podstawowym. Aby to osiągnąć, w regionie pomocniczym należy określić galerię, definicję obrazu maszyny wirtualnej i wersję obrazu maszyny wirtualnej używaną w regionie podstawowym, a platforma Azure skopiuje obraz i utworzy lokalną wersję obrazu maszyny wirtualnej. Tę operację można wykonać przy użyciu witryny Azure Portal lub polecenia interfejsu wiersza polecenia platformy Azure, jak opisano poniżej:
Nie wszystkie maszyny wirtualne hosta sesji w dodatkowych lokalizacjach odzyskiwania po awarii muszą być aktywne i działać przez cały czas. Najpierw należy utworzyć wystarczającą liczbę maszyn wirtualnych, a następnie użyć mechanizmu automatycznego skalowania, takiego jak plany skalowania. Dzięki tym mechanizmom można zachować większość zasobów obliczeniowych w stanie offline lub cofnięto przydział, aby zmniejszyć koszty.
Istnieje również możliwość użycia automatyzacji do tworzenia hostów sesji w regionie pomocniczym tylko wtedy, gdy jest to konieczne. Ta metoda optymalizuje koszty, ale w zależności od używanego mechanizmu może wymagać dłuższego celu czasu odzyskiwania. Takie podejście nie zezwala na testy trybu failover bez nowego wdrożenia i nie zezwala na selektywne przechodzenie w tryb failover dla określonych grup użytkowników.

Ważne
Należy włączyć każdą maszynę wirtualną hosta sesji przez kilka godzin co najmniej raz co 90 dni, aby odświeżyć token usługi Virtual Desktop wymagany do nawiązania połączenia z płaszczyzną sterowania pulpitu wirtualnego. Należy również rutynowo stosować poprawki zabezpieczeń i aktualizacje aplikacji.
- Posiadanie hostów sesji w trybie offline lub cofnięcie przydziału stanu w regionie pomocniczym nie gwarantuje dostępności pojemności w przypadku awarii całego regionu podstawowego. Ma również zastosowanie w przypadku wdrażania nowych sesji na żądanie w razie potrzeby oraz użycia usługi Site Recovery . Pojemność obliczeniowa może być gwarantowana, jeśli:
- Hosty sesji są przechowywane w stanie aktywnym w regionie pomocniczym.
- Używasz nowej funkcji platformy Azure Rezerwacja pojemności na żądanie.
Uwaga
Wystąpienia zarezerwowane maszyn wirtualnych platformy Azure nie zapewniają gwarantowanej pojemności, ale mogą one integrować się z rezerwacją pojemności na żądanie, aby zmniejszyć koszty.
- Ponieważ używasz usługi Cloud Cache:
Storage
W tym przewodniku użyjesz co najmniej dwóch oddzielnych kont magazynu dla każdej puli hostów usługi Virtual Desktop. Jeden jest przeznaczony dla kontenera profilów FSLogix, a drugi dotyczy danych kontenera pakietu Office. Potrzebujesz również jeszcze jednego konta magazynu dla pakietów MSIX . Obowiązują następujące zastrzeżenia:
- Jako alternatywy magazynu można użyć udziałów usługi Azure Files i usługi Azure NetApp Files .
- Udział usługi Azure Files może zapewnić odporność strefy przy użyciu opcji odporności magazynu replikowanego w strefie, jeśli jest ona dostępna w regionie.
- Funkcji magazynu geograficznie nadmiarowego nie można używać w następujących sytuacjach:
- Potrzebujesz regionu, który nie jest sparowany. Pary regionów dla magazynu geograficznie nadmiarowego są stałe i nie można ich zmienić.
- Używasz warstwy Premium.
- Cel punktu odzyskiwania i cel czasu odzyskiwania są wyższe w porównaniu z mechanizmem fsLogix Cloud Cache.
- Nie można łatwo przetestować trybu failover i powrotu po awarii w środowisku produkcyjnym.
- Usługa Azure NetApp Files wymaga dodatkowych zagadnień:
- Nadmiarowość strefy nie jest jeszcze dostępna. Jeśli wymaganie odporności jest ważniejsze niż wydajność, użyj udziału usługi Azure Files.
- Usługa Azure NetApp Files może być strefowa, czyli klienci mogą zdecydować, w której (pojedynczej) strefie dostępności platformy Azure należy przydzielić.
- Replikację między strefami można ustanowić na poziomie woluminu. Replikacja jest asynchronizuj (RPO>0) i wymaga ręcznego przejścia w tryb failover (RTO>0). Przed użyciem tej funkcji zalecamy zapoznanie się z wymaganiami i zagadnieniami z tego artykułu.
- Teraz możesz używać usługi Azure NetApp Files z strefowo nadmiarową siecią VPN i bramami usługi ExpressRoute, jeśli jest używana funkcja sieci Standardowa, której można użyć do odporności sieci. Aby uzyskać więcej informacji, zobacz Obsługiwane topologie sieci.
- Usługa Azure Virtual WAN jest teraz obsługiwana, ale wymaga funkcji sieci usługi Azure NetApp Files Standard. Aby uzyskać więcej informacji, zobacz Obsługiwane topologie sieci.
- Usługa Azure NetApp Files ma mechanizm replikacji między regionami, a zastosowanie mają następujące zagadnienia:
- Nie jest ona dostępna we wszystkich regionach.
- Pary regionów są stałe.
- Tryb failover nie jest niewidoczny, a powrót po awarii wymaga ponownej konfiguracji magazynu.
- Limity
- Istnieją limity rozmiaru, operacji wejścia/wyjścia na sekundę (IOPS), przepustowości MB/s dla udziałów usługi Azure Files i kont magazynu i woluminów usługi Azure NetApp Files . W razie potrzeby można użyć więcej niż jednej puli hostów w usłudze Virtual Desktop przy użyciu ustawień dla poszczególnych grup w programie FSLogix. Jednak ta konfiguracja wymaga więcej planowania i konfiguracji.
Konto magazynu używane dla pakietów aplikacji MSIX powinno być różne od innych kont dla kontenerów profilów i pakietu Office. Dostępne są następujące opcje odzyskiwania po awarii geograficznej:
- Jedno konto magazynu z włączonym magazynem geograficznie nadmiarowym w regionie podstawowym
- Region pomocniczy jest stały. Ta opcja nie jest odpowiednia dla dostępu lokalnego, jeśli istnieje tryb failover konta magazynu.
- Dwa oddzielne konta magazynu, jedno w regionie podstawowym i jedno w regionie pomocniczym (zalecane)
- Użyj magazynu strefowo nadmiarowego dla co najmniej regionu podstawowego.
- Każda pula hostów w każdym regionie ma dostęp do magazynu lokalnego do pakietów MSIX z małym opóźnieniem.
- Skopiuj pakiety MSIX dwa razy w obu lokalizacjach i zarejestruj pakiety dwa razy w obu pulach hostów. Przypisz użytkowników do grup aplikacji dwa razy.
FSLogix
Firma Microsoft zaleca korzystanie z następujących funkcji i konfiguracji fsLogix:
Jeśli zawartość kontenera profilu musi mieć oddzielne zarządzanie bcDR i ma różne wymagania w porównaniu z kontenerem pakietu Office, należy je podzielić.
- Kontener pakietu Office zawiera tylko zawartość buforowaną, która może zostać ponownie skompilowana lub ponownie wypełniona ze źródła, jeśli wystąpi awaria. W przypadku kontenera pakietu Office może nie być konieczne przechowywanie kopii zapasowych, co może obniżyć koszty.
- W przypadku korzystania z różnych kont magazynu można włączyć tylko kopie zapasowe w kontenerze profilu. Możesz też mieć różne ustawienia, takie jak okres przechowywania, używane miejsce do magazynowania, częstotliwość i cel czasu odzyskiwania/cel punktu odzyskiwania.
Usługa Cloud Cache to składnik FSLogix, w którym można określić wiele lokalizacji przechowywania profilów i asynchronicznie replikować dane profilów bez konieczności polegania na żadnych podstawowych mechanizmach replikacji magazynu. Jeśli pierwsza lokalizacja magazynu zakończy się niepowodzeniem lub nie jest osiągalna, usługa Cloud Cache automatycznie przejdzie w tryb failover w celu użycia pomocniczej i skutecznie doda warstwę odporności. Użyj pamięci podręcznej w chmurze, aby replikować zarówno kontenery profilu, jak i pakietu Office między różnymi kontami magazynu w regionach podstawowych i pomocniczych.
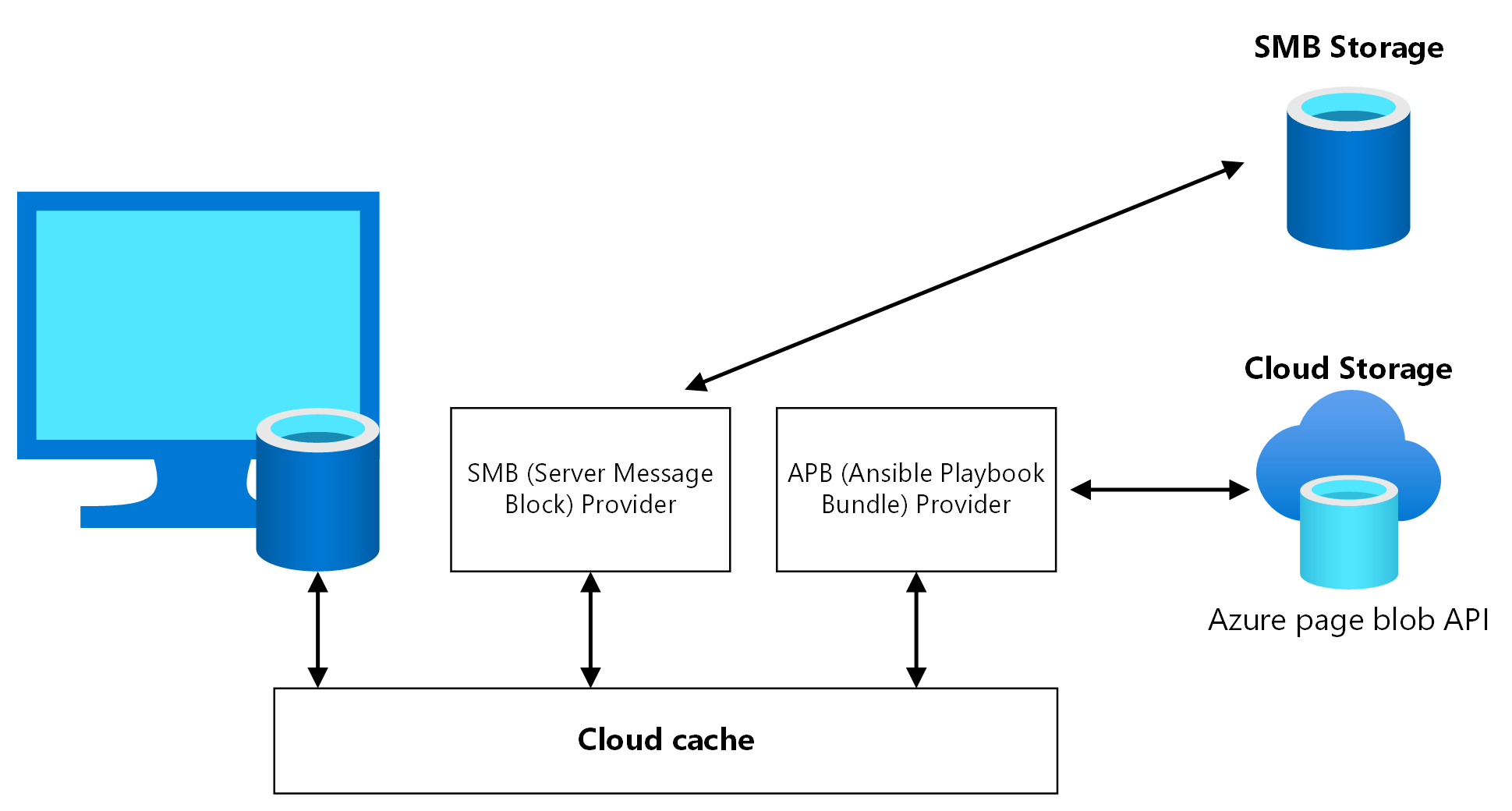
Należy dwukrotnie włączyć usługę Cloud Cache w rejestrze maszyn wirtualnych hosta sesji, raz dla kontenera profilu i raz dla kontenera pakietu Office. Nie można włączyć pamięci podręcznej w chmurze dla kontenera pakietu Office, ale nie włączenie go może spowodować niezgodność danych między podstawowym i pomocniczym regionem odzyskiwania po awarii, jeśli nastąpi przejście w tryb failover i powrót po awarii. Dokładnie przetestuj ten scenariusz przed użyciem go w środowisku produkcyjnym.
Usługa Cloud Cache jest zgodna zarówno z ustawieniami podziału profilu, jak i dla poszczególnych grup . Grupa wymaga starannego projektowania i planowania grup i członkostwa w usłudze Active Directory. Należy upewnić się, że każdy użytkownik jest częścią dokładnie jednej grupy, a ta grupa jest używana do udzielania dostępu do pul hostów.
Parametr CCDLocations określony w rejestrze dla puli hostów w regionie odzyskiwania po awarii pomocniczej jest przywracany w kolejności w porównaniu z ustawieniami w regionie podstawowym. Aby uzyskać więcej informacji, zobacz Samouczek: konfigurowanie pamięci podręcznej w chmurze w celu przekierowania kontenerów profilu lub kontenera biurowego do wielu dostawców.

W poniższym przykładzie przedstawiono konfigurację usługi Cloud Cache i powiązane klucze rejestru:
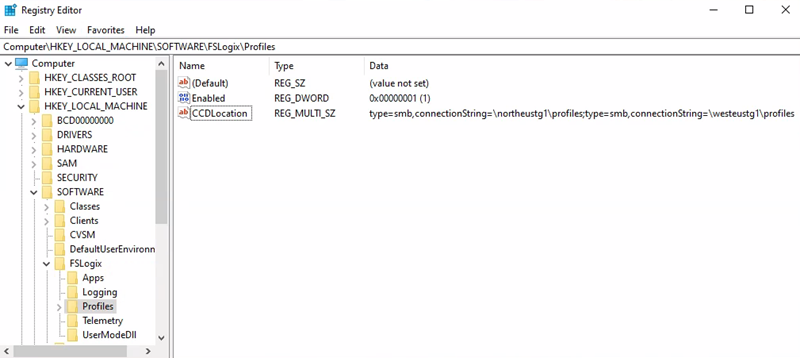
Region podstawowy = Europa Północna
Identyfikator URI konta magazynu kontenera profilu = \northeustg1\profiles
- Ścieżka klucza rejestru = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- WARTOŚĆ CCDLocations = type=smb,connectionString=\northeustg1\profiles; type=smb,connectionString=\westeustg1\profiles
Uwaga
Jeśli wcześniej pobrano szablony FSLogix, można wykonać te same konfiguracje za pomocą konsoli zarządzania zasadami grupy usługi Active Directory. Aby uzyskać więcej informacji na temat konfigurowania obiektu zasad grupy dla FSLogix, zapoznaj się z przewodnikiem Używanie plików szablonów zasad grupy FSLogix.
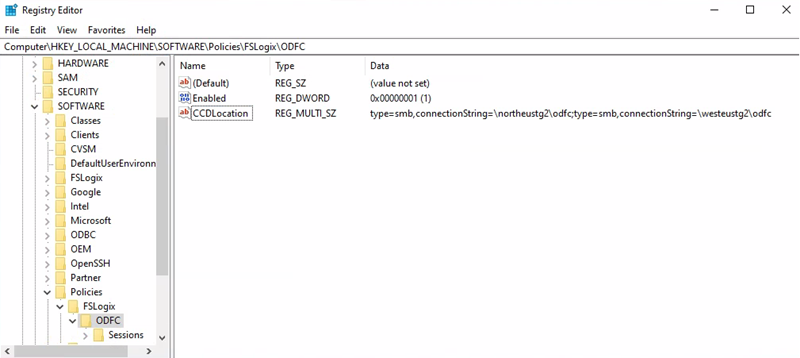
Identyfikator URI konta magazynu kontenera pakietu Office = \northeustg2\odcf
Ścieżka klucza rejestru = HKEY_LOCAL_MACHINE > ZASADY > OPROGRAMOWANIA >FSLogix > ODFC
WARTOŚĆ CCDLocations = type=smb,connectionString=\northeustg2\odfc; type=smb,connectionString=\westeustg2\odfc


Uwaga
Na powyższych zrzutach ekranu nie są zgłaszane wszystkie zalecane klucze rejestru dla usług FSLogix i Cloud Cache, aby uzyskać zwięzłość i prostotę. Aby uzyskać więcej informacji, zobacz Przykłady konfiguracji fsLogix.
Region pomocniczy = Europa Zachodnia
- Identyfikator URI konta magazynu kontenera profilu = \westeustg1\profiles
- Ścieżka klucza rejestru = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- WARTOŚĆ CCDLocations = type=smb,connectionString=\westeustg1\profiles; type=smb,connectionString=\northeustg1\profiles
- Identyfikator URI konta magazynu kontenera pakietu Office = \westeustg2\odcf
- Ścieżka klucza rejestru = HKEY_LOCAL_MACHINE > ZASADY > OPROGRAMOWANIA >FSLogix > ODFC
- CCDLocations value = type=smb,connectionString=\westeustg2\odfc; type=smb,connectionString=\northeustg2\odfc
Replikacja pamięci podręcznej w chmurze
Mechanizmy konfiguracji i replikacji usługi Cloud Cache gwarantują replikację danych profilu między różnymi regionami z minimalną utratą danych. Ponieważ ten sam plik profilu użytkownika można otworzyć w trybie ReadWrite tylko przez jeden proces, należy unikać współbieżnego dostępu, dlatego użytkownicy nie powinni jednocześnie otwierać połączenia z obiem pulami hostów.

Pobierz plik programu Visio z tą architekturą.
Przepływ danych
Użytkownik usługi Virtual Desktop uruchamia klienta usługi Virtual Desktop, a następnie otwiera opublikowaną aplikację pulpitu lub aplikacji zdalnej przypisaną do puli hostów regionu podstawowego.
FsLogix pobiera profil użytkownika i kontenery pakietu Office, a następnie instaluje bazowy dysk VHD/X magazynu z konta magazynu znajdującego się w regionie podstawowym.
Jednocześnie składnik usługi Cloud Cache inicjuje replikację między plikami w regionie podstawowym i plikami w regionie pomocniczym. W tym procesie usługa Cloud Cache w regionie podstawowym uzyskuje wyłączną blokadę odczytu i zapisu na tych plikach.
Ten sam użytkownik usługi Virtual Desktop chce teraz uruchomić inną opublikowaną aplikację przypisaną do puli hostów regionu pomocniczego.
Składnik FSLogix uruchomiony na hoście sesji usługi Virtual Desktop w regionie pomocniczym próbuje zainstalować pliki VHD/X profilu użytkownika z lokalnego konta magazynu. Jednak instalowanie kończy się niepowodzeniem, ponieważ te pliki są blokowane przez składnik usługi Cloud Cache uruchomiony na hoście sesji usługi Virtual Desktop w regionie podstawowym.
W domyślnej konfiguracji FSLogix i Cloud Cache użytkownik nie może się zalogować i w dziennikach diagnostycznych FSLogix jest śledzony błąd, ERROR_LOCK_VIOLATION 33 (0x21).


Tożsamość
Jedną z najważniejszych zależności dla usługi Virtual Desktop jest dostępność tożsamości użytkownika. Aby uzyskać dostęp do pulpitów wirtualnych i aplikacji zdalnych z hostów sesji, użytkownicy muszą mieć możliwość uwierzytelniania. Microsoft Entra ID to scentralizowana usługa tożsamości w chmurze firmy Microsoft, która umożliwia korzystanie z tej funkcji. Identyfikator Entra firmy Microsoft jest zawsze używany do uwierzytelniania użytkowników w usłudze Azure Virtual Desktop. Hosty sesji można dołączyć do tej samej dzierżawy firmy Microsoft Entra lub do domeny usługi Active Directory przy użyciu usług domena usługi Active Directory lub Microsoft Entra Domain Services (Microsoft Entra Domain Services), zapewniając wybór elastycznych opcji konfiguracji.
Tożsamość Microsoft Entra
- Jest to globalna usługa z wieloma regionami i odporna na błędy o wysokiej dostępności. W tym kontekście nie jest wymagana żadna inna akcja w ramach planu BCDR usługi Virtual Desktop.
Usługi Active Directory Domain Services
- Aby usługi domena usługi Active Directory były odporne i wysoce dostępne, nawet jeśli wystąpiła awaria w całym regionie, należy wdrożyć co najmniej dwa kontrolery domeny w podstawowym regionie świadczenia usługi Azure. Te kontrolery domeny powinny znajdować się w różnych strefach dostępności, jeśli to możliwe, i należy zapewnić odpowiednią replikację z infrastrukturą w regionie pomocniczym i ostatecznie lokalnie. Należy utworzyć co najmniej jeden kontroler domeny w regionie pomocniczym z katalogiem globalnym i rolami DNS. Aby uzyskać więcej informacji, zobacz Wdrażanie usług AD DS w sieci wirtualnej platformy Azure.
Microsoft Entra Połączenie
Jeśli używasz identyfikatora Entra firmy Microsoft z usługami domena usługi Active Directory, a następnie firma Microsoft Entra Połączenie synchronizować dane tożsamości użytkowników między domena usługi Active Directory Usługi i identyfikator Entra firmy Microsoft należy wziąć pod uwagę odporność i odzyskiwanie tej usługi w celu ochrony przed trwałą awarią.
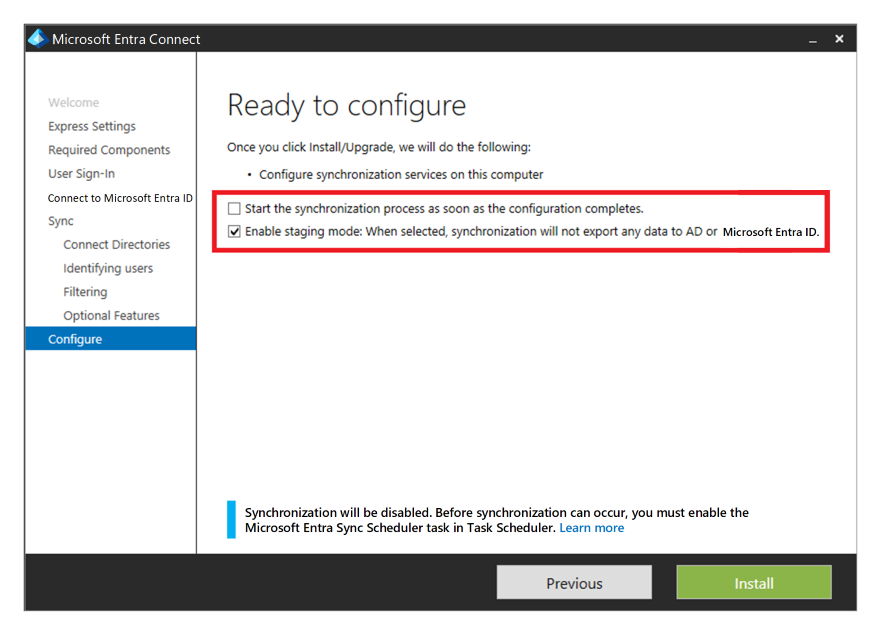
Wysoką dostępność i odzyskiwanie po awarii można zapewnić, instalując drugie wystąpienie usługi w regionie pomocniczym i włączając tryb przejściowy.
Jeśli istnieje odzyskiwanie, administrator musi podwyższyć poziom wystąpienia pomocniczego, usuwając go z trybu przejściowego. Muszą wykonać tę samą procedurę co umieszczenie serwera w trybie przejściowym. Do wykonania tej konfiguracji wymagane są poświadczenia Administracja istratora globalnego firmy Microsoft.
Usługi domenowe Microsoft Entra
- Usługi Microsoft Entra Domain Services można używać w niektórych scenariuszach jako alternatywy dla usług domena usługi Active Directory Services.
- Oferuje wysoką dostępność.
- Jeśli odzyskiwanie po awarii geograficznej znajduje się w zakresie scenariusza, należy wdrożyć inną replikę w regionie pomocniczym platformy Azure przy użyciu zestawu replik. Za pomocą tej funkcji można również zwiększyć wysoką dostępność w regionie podstawowym.
Diagramy architektury
Osobista pula hostów

Pobierz plik programu Visio z tą architekturą.
Pula hostów w puli

Pobierz plik programu Visio z tą architekturą.
Przechodzenie w tryb failover i powrót po awarii
Scenariusz puli hostów osobistych
Uwaga
W tej sekcji opisano tylko model aktywny-pasywny — aktywny-aktywny nie wymaga żadnej interwencji administratora ani trybu failover.
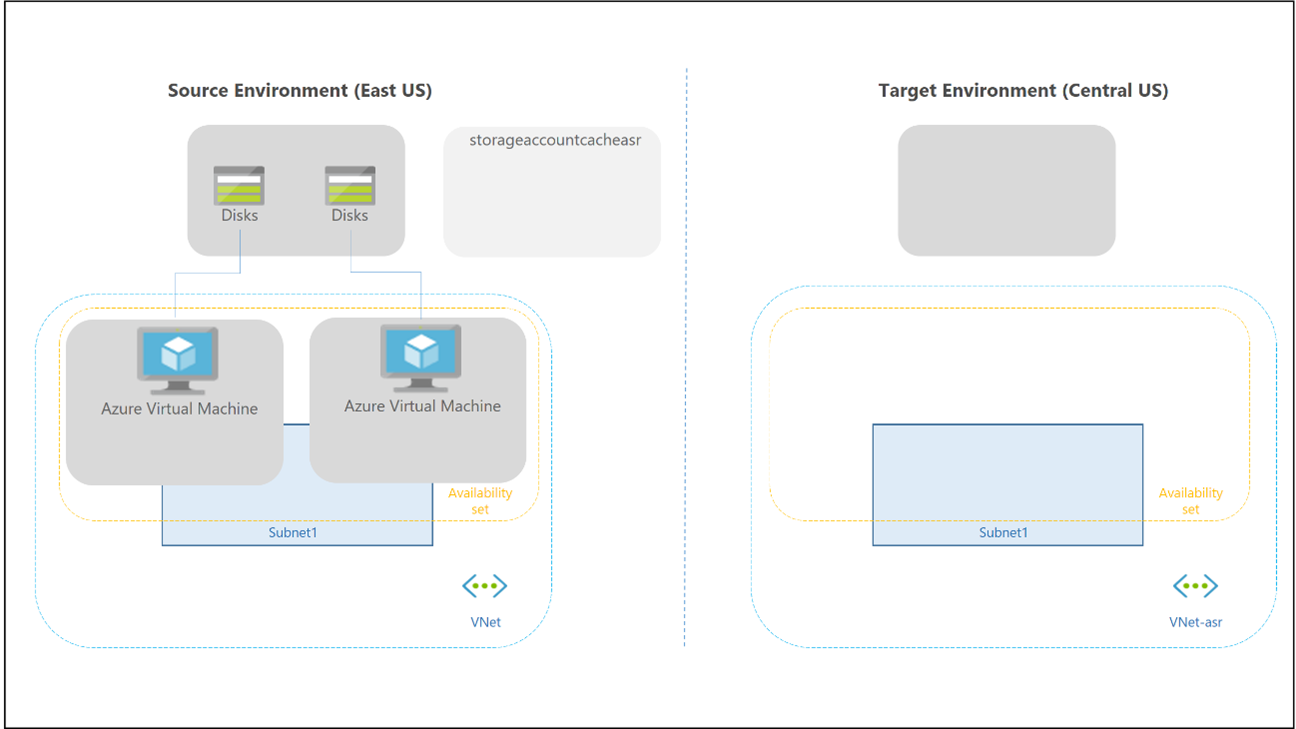
Tryb failover i powrót po awarii dla osobistej puli hostów różni się, ponieważ nie ma pamięci podręcznej w chmurze i magazynu zewnętrznego używanego dla kontenerów profilów i pakietu Office. Nadal można użyć technologii FSLogix, aby zapisać dane w kontenerze z hosta sesji. W regionie odzyskiwania po awarii nie ma dodatkowej puli hostów, więc nie ma potrzeby tworzenia większej liczby obszarów roboczych i zasobów usługi Virtual Desktop w celu replikacji i wyrównania. Za pomocą usługi Site Recovery można replikować maszyny wirtualne hosta sesji.
Usługi Site Recovery można używać w kilku różnych scenariuszach. W przypadku usługi Virtual Desktop użyj architektury odzyskiwania po awarii platformy Azure do platformy Azure w usłudze Azure Site Recovery.
Obowiązują następujące zagadnienia i zalecenia:
- Tryb failover usługi Site Recovery nie jest automatyczny — administrator musi go wyzwolić przy użyciu witryny Azure Portal lub programu PowerShell/interfejsu API.
- Za pomocą programu PowerShell można wykonywać skrypty i automatyzować całą konfigurację i operacje usługi Site Recovery.
- Usługa Site Recovery ma zadeklarowany cel czasu odzyskiwania w ramach umowy dotyczącej poziomu usług (SLA). W większości przypadków usługa Site Recovery może przejąć maszyny wirtualne w tryb failover w ciągu kilku minut.
- Usługi Site Recovery można używać z usługą Azure Backup. Aby uzyskać więcej informacji, zobacz Pomoc techniczna dotycząca używania usługi Site Recovery z usługą Azure Backup.
- Należy włączyć usługę Site Recovery na poziomie maszyny wirtualnej, ponieważ nie ma bezpośredniej integracji w środowisku portalu usługi Virtual Desktop. Musisz również wyzwolić tryb failover i powrót po awarii na poziomie pojedynczej maszyny wirtualnej.
- Usługa Site Recovery zapewnia możliwość testowania trybu failover w oddzielnej podsieci dla ogólnych maszyn wirtualnych platformy Azure. Nie używaj tej funkcji dla maszyn wirtualnych usługi Virtual Desktop, ponieważ w tym samym czasie będą używane dwa identyczne hosty sesji pulpitu wirtualnego wywołujące płaszczyznę sterowania pulpitu wirtualnego.
- Usługa Site Recovery nie obsługuje rozszerzeń maszyny wirtualnej podczas replikacji. Jeśli włączysz niestandardowe rozszerzenia dla maszyn wirtualnych hosta sesji usługi Virtual Desktop, musisz ponownie włączyć rozszerzenia po przejściu w tryb failover lub powrotu po awarii. Wbudowane rozszerzenia usługi Virtual Desktop joindomain i Microsoft.PowerShell.DSC są używane tylko podczas tworzenia maszyny wirtualnej hosta sesji. Po pierwszym przejściu w tryb failover można bezpiecznie je stracić.
- Zapoznaj się z macierzą obsługi odzyskiwania po awarii maszyny wirtualnej platformy Azure między regionami platformy Azure i sprawdź wymagania, ograniczenia i macierz zgodności dla scenariusza odzyskiwania po awarii z usługi Site Recovery z platformy Azure do platformy Azure, zwłaszcza obsługiwanych wersji systemu operacyjnego.
- Po przejściu maszyny wirtualnej w tryb failover z jednego regionu do drugiego maszyna wirtualna zostanie uruchomiona w docelowym regionie odzyskiwania po awarii w stanie niechronionym. Powrót po awarii jest możliwy, ale użytkownik musi ponownie włączyć ochronę maszyn wirtualnych w regionie pomocniczym, a następnie włączyć replikację z powrotem do regionu podstawowego.
- Wykonywanie okresowych testów trybu failover i procedur powrotu po awarii. Następnie udokumentować dokładną listę kroków i akcji odzyskiwania na podstawie określonego środowiska pulpitu wirtualnego.
Uwaga
Usługa Site Recovery jest teraz zintegrowana z rezerwacją pojemności na żądanie. Dzięki tej integracji możesz użyć możliwości rezerwacji pojemności w usłudze Site Recovery, aby zarezerwować pojemność obliczeniową w regionie odzyskiwania po awarii i zagwarantować przejście w tryb failover. Po przypisaniu grupy rezerwacji pojemności dla chronionych maszyn wirtualnych usługa Site Recovery przełączy maszyny wirtualne w tryb failover do tej grupy.
Scenariusz puli hostów w puli
Jedną z żądanych cech modelu odzyskiwania po awarii aktywne-aktywne jest to, że interwencja administratora nie jest wymagana do odzyskania usługi, jeśli wystąpi awaria. Procedury trybu failover powinny być konieczne tylko w architekturze aktywne-pasywnej.
W modelu aktywny-pasywny region odzyskiwania po awarii powinien być bezczynny, z minimalnymi skonfigurowanymi i aktywnymi zasobami. Konfiguracja powinna być zgodna z regionem podstawowym. W przypadku przejścia w tryb failover ponowne przypisanie wszystkich użytkowników do wszystkich grup pulpitów i aplikacji dla aplikacji zdalnych w pomocniczej puli hostów odzyskiwania po awarii jest wykonywane w tym samym czasie.
Istnieje możliwość posiadania aktywnego modelu i częściowego trybu failover. Jeśli pula hostów jest używana tylko do udostępniania grup pulpitu i aplikacji, można podzielić użytkowników w wielu nienakładających się grupach usługi Active Directory i ponownie przypisać grupę do grup komputerów i aplikacji w pulach hostów odzyskiwania po awarii podstawowej lub pomocniczej. Użytkownik nie powinien mieć dostępu do obu pul hostów jednocześnie. Jeśli istnieje wiele grup aplikacji i aplikacji, grupy użytkowników używane do przypisywania użytkowników mogą się nakładać. W takim przypadku trudno jest zaimplementować strategię aktywne-aktywne. Za każdym razem, gdy użytkownik uruchamia aplikację zdalną w podstawowej puli hostów, profil użytkownika jest ładowany przez usługę FSLogix na maszynie wirtualnej hosta sesji. Próba wykonania tej samej czynności w pomocniczej puli hostów może spowodować konflikt na bazowym dysku profilu.
Ostrzeżenie
Domyślnie ustawienia rejestru FSLogix uniemożliwiają współbieżny dostęp do tego samego profilu użytkownika z wielu sesji. W tym scenariuszu BCDR nie należy zmieniać tego zachowania i pozostawić wartość 0 dla klucza rejestru ProfileType.
Oto początkowe założenia dotyczące sytuacji i konfiguracji:
- Pule hostów w regionie podstawowym i pomocniczych regionach odzyskiwania po awarii są dopasowywane podczas konfiguracji, w tym w usłudze Cloud Cache.
- W pulach hostów są oferowane zarówno grupy aplikacji klasycznych DAG1, jak i APPG2 i APPG3 dla użytkowników.
- W puli hostów w regionie podstawowym grupy użytkowników usługi Active Directory GRP1, GRP2 i GRP3 są używane do przypisywania użytkowników do grup DAG1, APPG2 i APPG3. Te grupy mogą mieć nakładające się członkostwa użytkowników, ale ponieważ model w tym miejscu korzysta z trybu aktywny-pasywny z pełnym trybem failover, nie jest to problem.
Poniższe kroki opisują, kiedy nastąpi przejście w tryb failover po zaplanowanym lub nieplanowanym odzyskiwaniu po awarii.
- W podstawowej puli hostów usuń przypisania użytkowników według grup GRP1, GRP2 i GRP3 dla grup aplikacji DAG1, APPG2 i APPG3.
- Istnieje wymuszone rozłączenie dla wszystkich połączonych użytkowników z podstawowej puli hostów.
- W pomocniczej puli hostów, w której skonfigurowano te same grupy aplikacji, należy udzielić użytkownikowi dostępu do grup DAG1, APPG2 i APPG3 przy użyciu grup GRP1, GRP2 i GRP3.
- Przejrzyj i dostosuj pojemność puli hostów w regionie pomocniczym. W tym miejscu możesz użyć planu automatycznego skalowania, aby automatycznie włączyć hosty sesji. Możesz również ręcznie uruchomić niezbędne zasoby.
Kroki powrotu po awarii i przepływ są podobne, a cały proces można wykonać wiele razy. Usługa Cloud Cache i konfigurowanie kont magazynu gwarantuje, że dane kontenera profilu i pakietu Office są replikowane. Przed powrotem po awarii upewnij się, że konfiguracja puli hostów i zasoby obliczeniowe zostaną odzyskane. W przypadku części magazynu w przypadku utraty danych w regionie podstawowym usługa Cloud Cache zreplikuje dane profilu i kontenera pakietu Office z magazynu regionu pomocniczego.
Można również zaimplementować testowy plan pracy w trybie failover z kilkoma zmianami konfiguracji bez wpływu na środowisko produkcyjne.
- Utwórz kilka nowych kont użytkowników w usłudze Active Directory na potrzeby produkcji.
- Utwórz nową grupę usługi Active Directory o nazwie GRP-TEST i przypisz użytkowników.
- Przypisz dostęp do grup DAG1, APPG2 i APPG3 przy użyciu grupy GRP-TEST.
- Przekaż instrukcje użytkownikom w grupie GRP-TEST, aby przetestować aplikacje.
- Przetestuj procedurę trybu failover przy użyciu grupy GRP-TEST, aby usunąć dostęp z podstawowej puli hostów i udzielić dostępu do pomocniczej puli odzyskiwania po awarii.
Ważne zalecenia:
- Automatyzacja procesu trybu failover przy użyciu programu PowerShell, interfejsu wiersza polecenia platformy Azure lub innego dostępnego interfejsu API lub narzędzia.
- Okresowo testuje całą procedurę trybu failover i powrotu po awarii.
- Przeprowadź regularne sprawdzanie wyrównania konfiguracji, aby upewnić się, że pule hostów w regionie podstawowym i pomocniczym awarii są zsynchronizowane.
Wykonywanie kopii zapasowej
Założeniem w tym przewodniku jest to, że istnieje podział profilu i separacja danych między kontenerami profilu i kontenerami pakietu Office. FsLogix zezwala na tę konfigurację i użycie oddzielnych kont magazynu. Po utworzeniu oddzielnych kont magazynu można użyć różnych zasad tworzenia kopii zapasowych.
W przypadku kontenera pakietu Office, jeśli zawartość reprezentuje tylko dane buforowane, które można odtworzyć z lokalnego magazynu danych, takiego jak usługa Office 365, nie jest konieczne tworzenie kopii zapasowych danych.
Jeśli konieczne jest utworzenie kopii zapasowej danych kontenera pakietu Office, możesz użyć tańszego magazynu lub innego okresu przechowywania i częstotliwości tworzenia kopii zapasowych.
W przypadku typu osobistej puli hostów należy wykonać kopię zapasową na poziomie maszyny wirtualnej hosta sesji. Ta metoda ma zastosowanie tylko wtedy, gdy dane są przechowywane lokalnie.
Jeśli używasz usługi OneDrive i znanego przekierowania folderów, może zniknąć wymaganie zapisania danych wewnątrz kontenera.
Uwaga
Tworzenie kopii zapasowej w usłudze OneDrive nie jest brane pod uwagę w tym artykule i scenariuszu.
Jeśli nie ma innego wymagania, kopia zapasowa magazynu w regionie podstawowym powinna być wystarczająca. Tworzenie kopii zapasowej środowiska odzyskiwania po awarii nie jest zwykle używane.
W przypadku udziału usługi Azure Files użyj usługi Azure Backup.
- W przypadku typu odporności magazynu użyj magazynu strefowo nadmiarowego, jeśli magazyn kopii zapasowych poza lokacją lub regionem nie jest wymagany. Jeśli te kopie zapasowe są wymagane, użyj magazynu geograficznie nadmiarowego.
Usługa Azure NetApp Files udostępnia własne rozwiązanie do tworzenia kopii zapasowych. To rozwiązanie jest obecnie w wersji zapoznawczej i może zapewnić odporność magazynu strefowo nadmiarowego.
- Upewnij się, że sprawdzasz dostępność funkcji regionu wraz z wymaganiami i ograniczeniami.
Oddzielne konta magazynu używane na potrzeby msiX powinny być również objęte kopią zapasową, jeśli nie można łatwo skompilować repozytoriów pakietów aplikacji.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Ben Martin Baur | Architekt rozwiązań w chmurze
- Igor Pagliai | Główny inżynier rozwiązania FastTrack dla platformy Azure (FTA)
Inni współautorzy:
- Nelson Del Villar | Architekt rozwiązań w chmurze, infrastruktura podstawowa platformy Azure
- Jason Martinez | Składnik zapisywania technicznego
Następne kroki
- Plan odzyskiwania po awarii usługi Azure Virtual Desktop
- BCDR for Azure Virtual Desktop — Cloud Adoption Framework
- Usługa Cloud Cache w celu tworzenia odporności i dostępności