Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym artykule opisano sposób używania działania kopiowania w Azure Data Factory do kopiowania danych z i do punktu końcowego REST. Artykuł opiera się na Copy Activity in Azure Data Factory ( ogólne omówienie działania kopiowania).
Różnica między tym łącznikiem REST, łącznikiem HTTP i łącznikiem tabel sieci Web jest następująca:
- Łącznik REST obsługuje kopiowanie danych z interfejsów API RESTful.
- Łącznik HTTP jest ogólny w celu pobrania danych z dowolnego punktu końcowego HTTP, na przykład w celu pobrania pliku. Przed wprowadzeniem tego łącznika REST mogłeś używać łącznika HTTP do kopiowania danych z API RESTful, co jest obsługiwane, ale mniej funkcjonalne w porównaniu do łącznika REST.
- Łącznik tabeli sieci Web wyodrębnia zawartość tabeli ze strony internetowej HTML.
Obsługiwane możliwości
Ten łącznik REST jest obsługiwany dla następujących funkcjonalności:
| Obsługiwane możliwości | środowisko IR |
|---|---|
| Copy activity (źródło/ujście) | (1) (2) |
| Mapowanie przepływu danych (źródło/ujście) | (1) |
(1) Środowisko uruchomieniowe Azure (2) Środowisko uruchomieniowe lokalnie hostowane
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia, zobacz Obsługiwane magazyny danych.
W szczególności ten ogólny łącznik REST obsługuje następujące elementy:
- Kopiowanie danych z punktu końcowego REST przy użyciu metod GET lub POST i kopiowanie danych do punktu końcowego REST przy użyciu metod POST, PUT lub PATCH .
- Kopiowanie danych przy użyciu jednego z następujących uwierzytelnień: anonimowe, podstawowe, główna usługa, poświadczenia klienta OAuth2, zarządzana tożsamość przypisana przez system, i zarządzana tożsamość przypisana przez użytkownika.
- Stronicowanie w interfejsach API REST.
- W przypadku użycia REST jako źródła należy skopiować odpowiedź JSON REST bez zmian lub przeanalizować ją przy użyciu mapowania schematu. Obsługiwany jest tylko ładunek odpowiedzi w formacie JSON .
Napiwek
Aby przetestować żądanie pobierania danych przed skonfigurowaniem łącznika REST w usłudze Data Factory, zapoznaj się ze specyfikacją interfejsu API dla wymagań nagłówka i treści. Do zweryfikowania można użyć narzędzi, takich jak Visual Studio, Invoke-RestMethod programu PowerShell lub przeglądarki internetowej.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować self-hosted Integration Runtime aby nawiązać z nim połączenie.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji zarządzanego środowiska wykonawczego zintegrowanej sieci wirtualnej w Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania lokalnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Wprowadzenie
Aby wykonać działanie kopiowania za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Portal Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- Szablon menedżera zasobów Azure
Tworzenie połączonej usługi REST przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę REST w interfejsie użytkownika portalu Azure.
Przejdź do karty Zarządzanie w obszarze roboczym Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie wybierz pozycję Nowe:
Wyszukaj REST i wybierz łącznik REST.
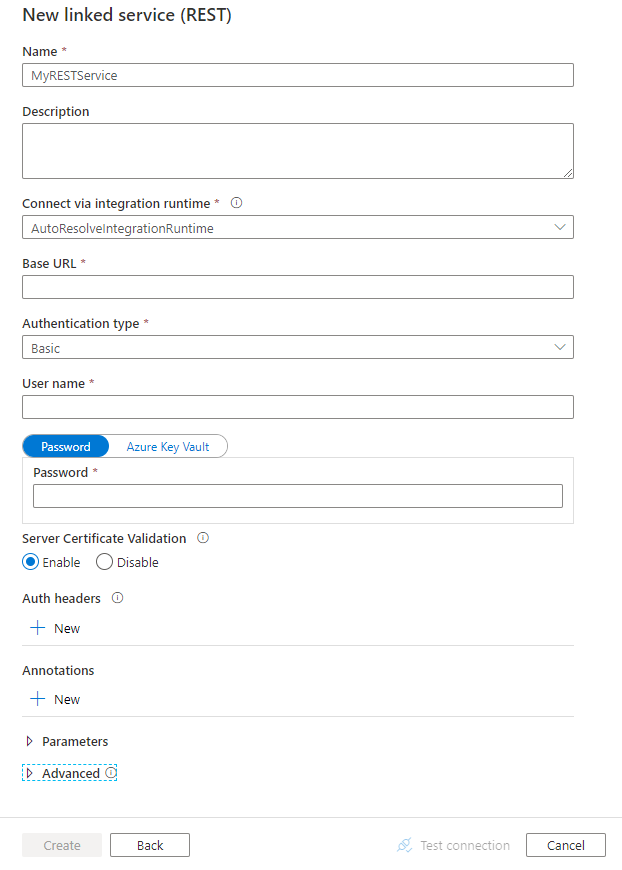
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach, których można użyć do definiowania jednostek usługi Data Factory specyficznych dla łącznika REST.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi REST:
| Własność | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type musi być ustawiona na RestService. | Tak |
| Adres URL | Podstawowy adres URL usługi REST. | Tak |
| włączWeryfikacjęCertyfikatuSerwera | Czy podczas nawiązywania połączenia z punktem końcowym należy zweryfikować certyfikat TLS/SSL po stronie serwera. | Nie. (wartość domyślna to true) |
| typ uwierzytelniania | Typ uwierzytelniania używanego do nawiązywania połączenia z usługą REST. Dozwolone wartości to Anonimowe, Podstawowe, AadServicePrincipal, OAuth2ClientCredential i ManagedServiceIdentity. Możesz dodatkowo skonfigurować nagłówki uwierzytelniania w właściwości authHeaders. Zapoznaj się z odpowiednimi sekcjami poniżej, aby uzyskać więcej właściwości i przykładów. |
Tak |
| authHeaders | Inne nagłówki żądań HTTP na potrzeby uwierzytelniania. Aby na przykład użyć uwierzytelniania klucza API, możesz wybrać typ uwierzytelniania jako "Anonimowy" i określić klucz API w nagłówku. |
Nie. |
| connectVia | Integration Runtime używać do nawiązywania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określona, ta właściwość używa Azure Integration Runtime domyślnej. | Nie. |
Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje dotyczące różnych typów uwierzytelniania.
- Uwierzytelnianie podstawowe
- Uwierzytelnianie głównej usługi
- Uwierzytelnianie poświadczeń klienta OAuth2
- Uwierzytelnianie zarządzanej tożsamości przydzielanej przez system
- Uwierzytelnianie za pomocą zarządzanej tożsamości przypisanej przez użytkownika
- Uwierzytelnianie anonimowe
Korzystanie z uwierzytelniania podstawowego
Ustaw właściwość authenticationType na Basic. Oprócz właściwości ogólnych opisanych w poprzedniej sekcji określ następujące właściwości:
| Własność | Opis | Wymagane |
|---|---|---|
| userName | Nazwa użytkownika używana do uzyskiwania dostępu do punktu końcowego REST. | Tak |
| hasło | Hasło użytkownika ( wartość userName ). Oznacz to pole jako typ SecureString , aby bezpiecznie przechowywać je w usłudze Data Factory. Możesz również odwołać się do sekretu przechowywanego w Azure Key Vault. | Tak |
Przykład
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Użyj uwierzytelniania podmiotu usługi
Ustaw właściwość authenticationType na AadServicePrincipal. Oprócz właściwości ogólnych opisanych w poprzedniej sekcji określ następujące właściwości:
| Własność | Opis | Wymagane |
|---|---|---|
| IdentyfikatorGłównegoSerwisu | Określ identyfikator klienta aplikacji Microsoft Entra. | Tak |
| typUwierzytelnieniaPodmiotuUsługi | Określ typ poświadczeń do użycia przy uwierzytelnianiu podmiotu usługi. Dozwolone wartości to ServicePrincipalKey i ServicePrincipalCert. |
Nie. |
| Dla klucza ServicePrincipalKey | ||
| klucz Głównego Usługodawcy | Określ klucz aplikacji Microsoft Entra. Oznacz to pole jako SecureString, aby bezpiecznie przechowywać je w usłudze Data Factory lub odwołuj się do tajemnicy przechowywanej w Azure Key Vault. | Nie. |
| Dla elementu ServicePrincipalCert | ||
| certyfikat osadzony głównego serwisu | Określ certyfikat zakodowany w formacie base64 aplikacji zarejestrowanej w Microsoft Entra ID i upewnij się, że typ zawartości certyfikatu jest PKCS #12. Oznacz to pole jako SecureString, aby przechowywać je bezpiecznie lub odwołaj się do tajemnicy przechowywanej w Azure Key Vault. Przejdź do tego section aby dowiedzieć się, jak zapisać certyfikat w Azure Key Vault. | Nie. |
| hasło certyfikatu osadzonego dla obiektu głównego usługi | Określ hasło certyfikatu, jeśli certyfikat jest zabezpieczony hasłem. Oznacz to pole jako SecureString, aby przechowywać je bezpiecznie lub odwołaj się do tajemnicy przechowywanej w Azure Key Vault. | Nie. |
| dzierżawa | Określ informacje o dzierżawie (nazwę domeny lub identyfikator dzierżawy), w ramach których znajduje się aplikacja. Pobierz go, umieszczając wskaźnik myszy w prawym górnym rogu portalu Azure. | Tak |
| aadResourceId | Określ, o autoryzację którego zasobu Microsoft Entra prosisz, na przykład https://management.core.windows.net. |
Tak |
| azureCloudType | W przypadku uwierzytelniania jednostki usługi określ typ środowiska Azure w chmurze, do którego zarejestrowano aplikację Microsoft Entra. Dozwolone wartości to AzurePublic, AzureChina, AzureUsGovernment i AzureGermany. Domyślnie używane jest środowisko chmury fabryki danych. |
Nie. |
Przykład 1: Używanie uwierzytelniania klucza jednostki usługi
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład 2: Używanie uwierzytelniania certyfikatu jednostki usługi
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Zapisywanie certyfikatu jednostki usługi w Azure Key Vault
Istnieją dwie opcje zapisywania certyfikatu jednostki usługi w Azure Key Vault:
Opcja 1
Przekonwertuj certyfikat jednostki usługi na ciąg base64. Dowiedz się więcej z tego artykułu.
Zapisz ciąg base64 jako wpis tajny w Azure Key Vault.
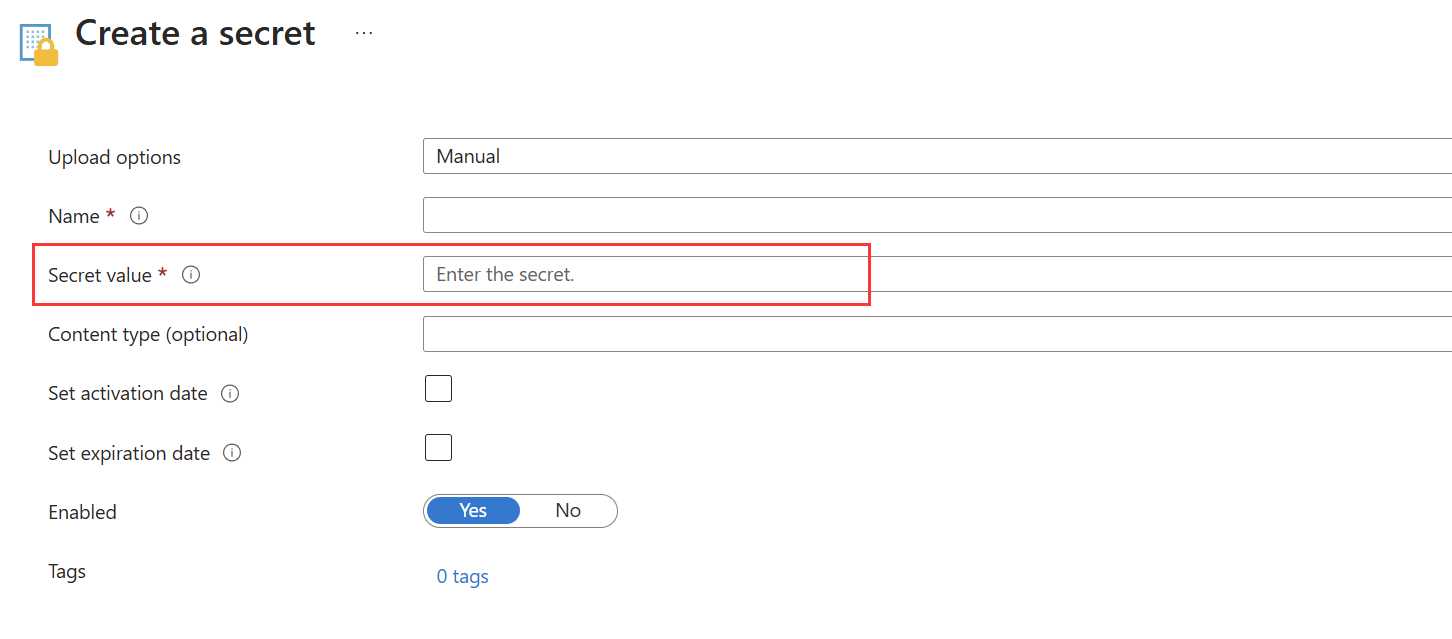
Opcja 2
Jeśli nie możesz pobrać certyfikatu z Azure Key Vault, możesz użyć tego szablonu, aby zapisać przekonwertowany certyfikat jednostki usługi jako wpis tajny w Azure Key Vault.

Korzystanie z uwierzytelniania poświadczeń klienta OAuth2
Ustaw właściwość authenticationType na OAuth2ClientCredential. Oprócz właściwości ogólnych opisanych w poprzedniej sekcji określ następujące właściwości:
| Własność | Opis | Wymagane |
|---|---|---|
| tokenEndpoint (punkt końcowy tokenu) | Punkt końcowy serwera autoryzacji do uzyskania tokenu dostępu. | Tak |
| clientId (identyfikator klienta) | Identyfikator klienta skojarzony z aplikacją. | Tak |
| tajemnica klienta | Tajemnica klienta skojarzona z twoją aplikacją. Oznacz to pole jako typ SecureString , aby bezpiecznie przechowywać je w usłudze Data Factory. Możesz również odwołać się do sekretu przechowywanego w Azure Key Vault. | Tak |
| zakres | Wymagany zakres dostępu. Opisuje on, jakiego rodzaju dostęp zostanie zażądany. | Nie. |
| zasób | Docelowa usługa lub zasób, do którego zostanie żądany dostęp. | Nie. |
Przykład
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Korzystanie z uwierzytelniania tożsamości zarządzanej przypisanej przez system
Ustaw właściwość authenticationType na ManagedServiceIdentity. Oprócz właściwości ogólnych opisanych w poprzedniej sekcji określ następujące właściwości:
| Własność | Opis | Wymagane |
|---|---|---|
| aadResourceId | Określ, o autoryzację którego zasobu Microsoft Entra prosisz, na przykład https://management.core.windows.net. |
Tak |
Przykład
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Użycie uwierzytelniania tożsamości zarządzanej przez użytkownika
Ustaw właściwość authenticationType na ManagedServiceIdentity. Oprócz właściwości ogólnych opisanych w poprzedniej sekcji określ następujące właściwości:
| Własność | Opis | Wymagane |
|---|---|---|
| aadResourceId | Określ, o autoryzację którego zasobu Microsoft Entra prosisz, na przykład https://management.core.windows.net. |
Tak |
| dane logowania | Określ tożsamość zarządzaną przypisaną przez użytkownika jako obiekt poświadczeń. | Tak |
Przykład
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Używanie nagłówków uwierzytelniania
Ponadto można skonfigurować nagłówki żądań na potrzeby uwierzytelniania wraz z wbudowanymi typami uwierzytelniania.
Przykład: używanie uwierzytelniania klucza interfejsu API
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Ta sekcja zawiera listę właściwości, które obsługuje zestaw danych REST.
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych i połączone usługi.
Aby skopiować dane z interfejsu REST, obsługiwane są następujące właściwości:
| Własność | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type zestawu danych musi być ustawiona na RestResource. | Tak |
| relativeUrl | Względny adres URL zasobu, który zawiera dane. Jeśli ta właściwość nie zostanie określona, zostanie użyty tylko adres URL określony w definicji połączonej usługi. Łącznik HTTP kopiuje dane z połączonego adresu URL: [URL specified in linked service]/[relative URL specified in dataset]. |
Nie. |
Jeśli ustawiłeś requestMethod, additionalHeaders, requestBody i paginationRules w zestawie danych, nadal jest obsługiwane as-is, jednak zaleca się użycie nowego modelu w przyszłości.
Przykład:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Ta sekcja zawiera listę właściwości obsługiwanych przez źródło REST i odbiornik.
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania aktywności, zobacz Pipelines.
REST jako źródło
Następujące właściwości są obsługiwane w sekcji źródło działania kopiowania:
| Własność | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type źródła działania kopiowania musi być ustawiona na RestSource. | Tak |
| requestMethod | Metoda HTTP. Dozwolone wartości to GET (wartość domyślna) i POST. | Nie. |
| dodatkowe nagłówki | Inne nagłówki żądań HTTP. | Nie. |
| treść żądania | Treść żądania HTTP. | Nie. |
| zasady paginacji | Reguły stronicowania do tworzenia żądań następnej strony. Zapoznaj się z sekcją wsparcia stronicowania dla szczegółów. | Nie. |
| Limit czasu żądania HTTP | Limit czasu ( wartość TimeSpan ) żądania HTTP w celu uzyskania odpowiedzi. Ta wartość jest limitem czasu, aby uzyskać odpowiedź, a nie limit czasu odczytu danych odpowiedzi. Wartość domyślna to 00:01:40. | Nie. |
| requestInterval | Czas oczekiwania przed wysłaniem żądania na następną stronę. Wartość domyślna to 00:00:01 | Nie. |
Uwaga
Łącznik REST ignoruje dowolny nagłówek "Akceptuj" określony w pliku additionalHeaders. Ponieważ obsługuje tylko odpowiedzi JSON, automatycznie ustawia nagłówek na Accept: application/json.
Stronicowanie nie jest obsługiwane w przypadku odpowiedzi interfejsu API REST, w których struktura najwyższego poziomu jest tablicą JSON.
Przykład 1. Używanie metody Get z podziałem na strony
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykład 2: Używanie metody Post
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST jako odbiornik
Następujące właściwości są obsługiwane w sekcji ujścia działania kopiowania:
| Własność | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type ujścia działania kopiowania musi być ustawiona na RestSink. | Tak |
| requestMethod | Metoda HTTP. Dozwolone wartości to POST (wartość domyślna), PUT i PATCH. | Nie. |
| dodatkowe nagłówki | Inne nagłówki żądań HTTP. | Nie. |
| Limit czasu żądania HTTP | Limit czasu ( wartość TimeSpan ) żądania HTTP w celu uzyskania odpowiedzi. Ta wartość to limit czasu na uzyskanie odpowiedzi, a nie limit czasu zapisu danych. Wartość domyślna to 00:01:40. | Nie. |
| requestInterval | Czas interwału między różnymi żądaniami w milisekundach. Wartość interwału żądania powinna być liczbą z zakresu od [10, 60000]. | Nie. |
| TypKompresjiHTTP | Typ kompresji HTTP do użycia podczas wysyłania danych z optymalnym poziomem kompresji. Dozwolone wartości to brak i gzip. | Nie. |
| writeBatchSize | Liczba rekordów do zapisu w ujściu REST na partię. Wartość domyślna to 10000. | Nie. |
Łącznik REST jako ujście współdziała z interfejsami API REST, które akceptują kod JSON. Dane zostaną wysłane w formacie JSON przy użyciu następującego wzorca. W razie potrzeby możesz użyć działania kopiowania mapowania schematu do przekształcenia danych źródłowych, aby pasowały do oczekiwanego ładunku dla interfejsu API REST.
[
{ <data object> },
{ <data object> },
...
]
Przykład:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Mapowanie właściwości przepływu danych
Interfejs REST jest obsługiwany w przepływach danych zarówno dla zestawów danych integracyjnych, jak i zestawów danych inline.
Przekształcanie źródła
| Własność | Opis | Wymagane |
|---|---|---|
| requestMethod | Metoda HTTP. Dozwolone wartości to GET i POST. | Tak |
| relativeUrl | Względny adres URL zasobu, który zawiera dane. Jeśli ta właściwość nie zostanie określona, zostanie użyty tylko adres URL określony w definicji połączonej usługi. Łącznik HTTP kopiuje dane z połączonego adresu URL: [URL specified in linked service]/[relative URL specified in dataset]. |
Nie. |
| dodatkowe nagłówki | Inne nagłówki żądań HTTP. | Nie. |
| Limit czasu żądania HTTP | Limit czasu ( wartość TimeSpan ) żądania HTTP w celu uzyskania odpowiedzi. Ta wartość to limit czasu na uzyskanie odpowiedzi, a nie limit czasu zapisu danych. Wartość domyślna to 00:01:40. | Nie. |
| requestInterval | Czas interwału między różnymi żądaniami w milisekundach. Wartość interwału żądania powinna być liczbą z zakresu od [10, 60000]. | Nie. |
| QueryParameters.request_query_parameter LUB QueryParameters['request_query_parameter'] | Element "request_query_parameter" jest zdefiniowany przez użytkownika, który odwołuje się do jednej nazwy parametru zapytania w następnym adresie URL żądania HTTP. | Nie. |
Przekształcenie zbiornika
| Własność | Opis | Wymagane |
|---|---|---|
| dodatkowe nagłówki | Inne nagłówki żądań HTTP. | Nie. |
| Limit czasu żądania HTTP | Limit czasu ( wartość TimeSpan ) żądania HTTP w celu uzyskania odpowiedzi. Ta wartość to limit czasu na uzyskanie odpowiedzi, a nie limit czasu zapisu danych. Wartość domyślna to 00:01:40. | Nie. |
| requestInterval | Czas interwału między różnymi żądaniami w milisekundach. Wartość interwału żądania powinna być liczbą z zakresu od [10, 60000]. | Nie. |
| TypKompresjiHTTP | Typ kompresji HTTP do użycia podczas wysyłania danych z optymalnym poziomem kompresji. Dozwolone wartości to brak i gzip. | Nie. |
| writeBatchSize | Liczba rekordów do zapisu w ujściu REST na partię. Wartość domyślna to 10000. | Nie. |
Można ustawić metody usuwania, wstawiania, aktualizowania i upsert, a także względne dane wierszy do wysyłania do ujścia REST dla operacji CRUD.
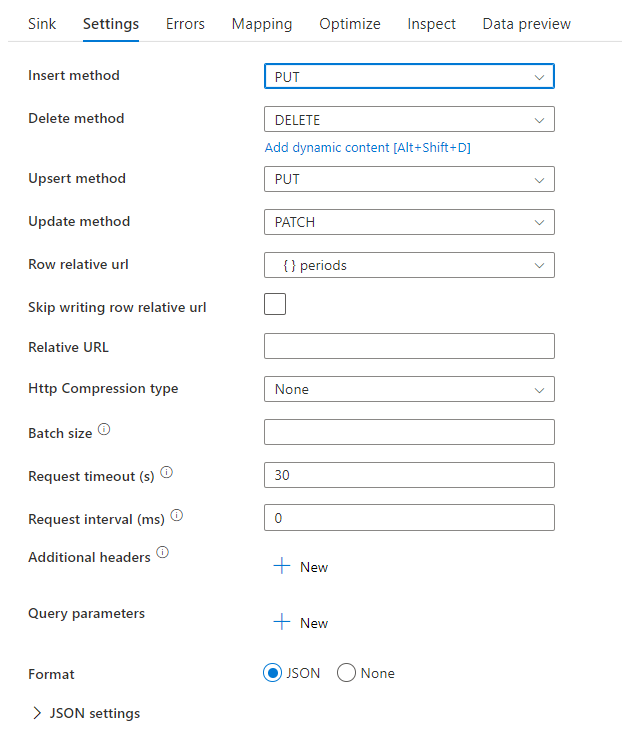
Przykładowy skrypt przepływu danych
Zwróć uwagę na użycie przekształcenia alter row przed elementem docelowym, aby poinstruować usługę ADF, jakiego typu akcji należy podjąć z elementem docelowym REST. Oznacza to, że wstawianie, aktualizowanie, upsert, usuwanie.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Uwaga
Data Flow generuje łącznie liczbę wywołań interfejsu API N+1 podczas przetwarzania N stron. Obejmuje to jedno początkowe wywołanie w celu wywnioskowania schematu, a następnie N wywołań odpowiadających liczbie stron pobranych ze źródła.
Obsługa stronicowania
Podczas kopiowania danych z interfejsów API REST zwykle interfejs API REST ogranicza rozmiar ładunku odpowiedzi pojedynczego żądania w rozsądnej liczbie; chociaż zwraca dużą ilość danych, dzieli wynik na wiele stron i wymaga od wywołujących wysyłania kolejnych żądań w celu uzyskania następnej strony wyniku. Zwykle żądanie jednej strony jest dynamiczne i składa się z informacji zwróconych z odpowiedzi poprzedniej strony.
Ten ogólny łącznik REST obsługuje następujące wzorce stronicowania:
- Adres URL następnego żądania, zarówno bezwzględny jak i względny, jest równy wartości właściwości w treści bieżącej odpowiedzi.
- Bezwzględny lub względny adres URL następnego żądania = wartość nagłówka w bieżących nagłówkach odpowiedzi
- Parametr zapytania następnego żądania = wartość właściwości w bieżącej treści odpowiedzi
- Parametr zapytania następnego żądania = wartość nagłówka w bieżących nagłówkach odpowiedzi
- Nagłówek następnego żądania = wartość właściwości w bieżącej treści odpowiedzi
- Nagłówek następnego żądania = wartość nagłówka w bieżących nagłówkach odpowiedzi
Reguły paginacji są definiowane jako słownik w zestawie danych, który zawiera co najmniej jedną parę klucz-wartość z uwzględnieniem wielkości liter. Konfiguracja zostanie użyta do wygenerowania żądania rozpoczynającego się od drugiej strony. Łącznik przestanie iterować, gdy otrzyma kod stanu HTTP 204 (Bez zawartości) lub gdy każde z wyrażeń JSONPath w "paginationRules" zwróci wartość null.
Obsługiwane klucze w regułach stronicowania:
| Klucz | Opis |
|---|---|
| AbsolutnyURL | Wskazuje adres URL do wystawienia następnego żądania. Może to być bezwzględny adres URL lub względny adres URL. |
| QueryParameters.request_query_parameter LUB QueryParameters['request_query_parameter'] | Element "request_query_parameter" jest zdefiniowany przez użytkownika, który odwołuje się do jednej nazwy parametru zapytania w następnym adresie URL żądania HTTP. |
| Nagłówki.request_header LUB Nagłówki['request_header'] | Element "request_header" jest zdefiniowany przez użytkownika, który odwołuje się do jednej nazwy nagłówka w następnym żądaniu HTTP. |
| KońcowyWarunek:end_condition | Element "end_condition" jest zdefiniowany przez użytkownika, który wskazuje warunek, który zakończy pętlę stronicowania w następnym żądaniu HTTP. |
| MaksymalnaLiczbaŻądań | Wskazuje maksymalny numer żądania stronicowania. Pozostaw ją jako pustą oznacza brak limitu. |
| SupportRFC5988 | Domyślnie jest ona ustawiona na wartość true, jeśli nie zdefiniowano reguły stronicowania. Tę regułę można wyłączyć, ustawiając supportRFC5988 wartość false lub usuń tę właściwość ze skryptu. |
Obsługiwane wartości w regułach stronicowania:
| Wartość | Opis |
|---|---|
| Nagłówki.response_header lub Nagłówki['response_header'] | Wartość "response_header" jest zdefiniowana przez użytkownika, która odwołuje się do jednej nazwy nagłówka w bieżącej odpowiedzi HTTP, której wartość będzie używana do wystawiania następnego żądania. |
| Wyrażenie JSONPath rozpoczynające się od "$" (reprezentujące korzeń treści odpowiedzi) | Treść odpowiedzi powinna zawierać tylko jeden obiekt JSON, ponieważ tablice obiektów jako treść odpowiedzi nie są obsługiwane. Wyrażenie JSONPath powinno zwrócić pojedynczą wartość pierwotną, która będzie używana do wystawiania następnego żądania. |
Uwaga
Reguły stronicowania przepływów mapowania danych różnią się od reguł kopiowania w następujących aspektach:
- Zakres nie jest obsługiwany w przepływach danych mapowania.
-
['']nie jest obsługiwany w przepływach danych mapowania. Zamiast tego użyj polecenia{}, aby uciec od znaku specjalnego. Na przykład,body.{@odata.nextLink}, którego węzeł JSON@odata.nextLinkzawiera specjalny znak.. - Warunek końcowy jest obsługiwany w przepływach danych mapowania, ale składnia warunku różni się od niego w działaniu kopiowania.
bodysłuży do wskazywania treści odpowiedzi zamiast$.headersłuży do wskazywania nagłówka odpowiedzi zamiastheaders. Oto dwa przykłady pokazujące tę różnicę:- Przykład 1:
Copy activity: "EndCondition:$.data": "Empty"
Mapowanie przepływów danych: "EndCondition:body.data": "Empty" - Przykład 2:
działanie Kopiuj: "EndCondition:headers.complete": "Exist"
Przepływy danych mapowania: "EndCondition:header.complete": "Istnieje"
- Przykład 1:
Przykłady reguł stronicowania
Ta sekcja zawiera listę przykładów ustawień reguł stronicowania.
Przykład 1: Zmienne w parametrach QueryParameters
W tym przykładzie przedstawiono kroki konfiguracji służące do wysyłania wielu żądań, których zmienne znajdują się w parametrach QueryParameters.
Wiele żądań:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Krok 1: Wprowadź sysparm_offset={offset} albo w podstawowym adresie URL lub względnym adresie URL, jak pokazano na poniższych zrzutach ekranu:
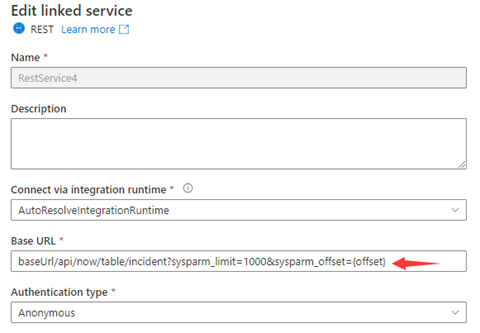
lub
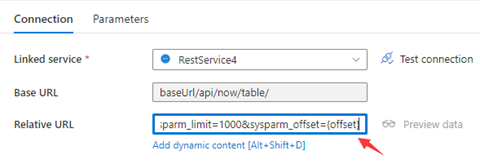
Krok 2. Ustaw reguły stronicowania jako opcję 1 lub 2:
Opcja1: "QueryParameters.{ offset}" : "RANGE:0:10000:1000"
Opcja2: "AbsoluteUrl.{ offset}" : "RANGE:0:10000:1000"
Przykład 2:Zmienne w pliku AbsoluteUrl
W tym przykładzie przedstawiono kroki konfiguracji służące do wysyłania wielu żądań, których zmienne znajdują się w pliku AbsoluteUrl.
Wiele żądań:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Krok 1: Dane wejściowe {id} w Podstawowym adresie URL na stronie konfiguracji połączonej usługi lub Względnym adresie URL w okienku połączenia zestawu danych.
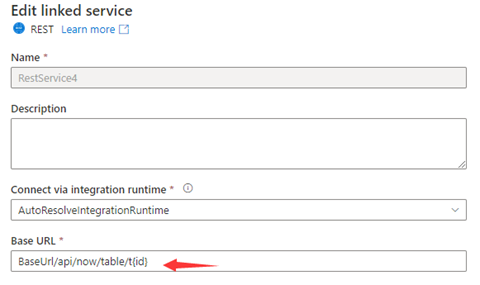
lub
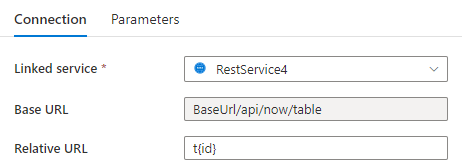
Krok 2: Ustaw reguły stronicowania jako "AbsoluteUrl.{id}" :"RANGE:1:100:1".
Przykład 3:Zmienne w nagłówkach
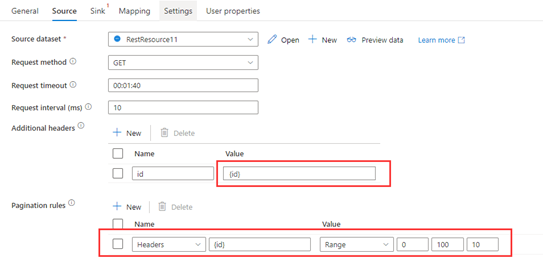
W tym przykładzie przedstawiono kroki konfiguracji służące do wysyłania wielu żądań, których zmienne znajdują się w nagłówkach.
Wiele żądań:
RequestUrl: https://example/table
Request 1: Header(id->0)
Request 2: Header(id->10)
......
Request 100: Header(id->100)
Krok 1. Wprowadzanie {id} w dodatkowych nagłówkach.
Krok 2: Ustaw zasady reguł stronicowania jako "Nagłówki.{id}" : "RANGE:0:100:10".
Przykład 4: Zmienne znajdują się w parametrach AbsoluteUrl/QueryParameters/Headers, zmienna końcowa nie jest wstępnie zdefiniowana, a warunek końcowy jest oparty na odpowiedzi
W tym przykładzie przedstawiono kroki konfiguracji służące do wysyłania wielu żądań, których zmienne znajdują się w parametrach AbsoluteUrl/QueryParameters/Headers, ale zmienna końcowa nie jest zdefiniowana. W przypadku różnych odpowiedzi różne ustawienia reguły warunku końcowego są wyświetlane w przykładzie 4.1-4.6.
Wiele żądań:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
W tym przykładzie napotkano dwie odpowiedzi:
Odpowiedź 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Odpowiedź 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Krok 1. Ustaw zakres reguł stronicowania na przykład 1 i pozostaw koniec zakresu pusty jako "AbsoluteUrl.{ offset}": "RANGE:0::1000".
Krok 2. Ustaw różne reguły warunków końcowych zgodnie z różnymi ostatnimi odpowiedziami. Zobacz poniższe przykłady:
Przykład 4.1: stronicowanie kończy się, gdy wartość określonego węzła w odpowiedzi jest pusta
Interfejs API REST zwraca ostatnią odpowiedź w następującej strukturze:
{ Data: [] }Ustaw regułę warunku końcowego na "EndCondition:$.data": "Empty", aby zakończyć paginację, gdy wartość określonego węzła w odpowiedzi jest pusta.

Przykład 4.2: Stronicowanie kończy się, gdy w odpowiedzi nie ma wartości dla określonego węzła
Interfejs API REST zwraca ostatnią odpowiedź w następującej strukturze:
{}Ustaw regułę końcową jako "EndCondition:$.data": "NonExist", aby zakończyć stronicowanie, gdy wartość określonego węzła w odpowiedzi nie istnieje.

Przykład 4.3: Stronicowanie zatrzymuje się, gdy w odpowiedzi pojawia się wartość określonego węzła
Interfejs API REST zwraca ostatnią odpowiedź w następującej strukturze:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Ustaw regułę warunku końcowego na "EndCondition:$.Complete": "Exist", aby zakończyć stronicowanie, gdy istnieje wartość określonego węzła w odpowiedzi.

Przykład 4.4: stronicowanie kończy się, gdy wartość określonego węzła w odpowiedzi jest wartością const zdefiniowaną przez użytkownika
Interfejs API REST zwraca odpowiedź w następującej strukturze:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
Ostatnia odpowiedź znajduje się w następującej strukturze:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Ustaw regułę warunku końcowego na "EndCondition:$.Complete": "Const:true", aby zakończyć stronicowanie, gdy wartość określonego węzła w odpowiedzi jest zdefiniowaną przez użytkownika wartością stałą.

Przykład 4.5: stronicowanie kończy się, gdy wartość klucza nagłówka w odpowiedzi jest równa wartości const zdefiniowanej przez użytkownika
Klucze nagłówków w odpowiedziach REST API są przedstawione w strukturze poniżej:
Nagłówek odpowiedzi 1:
header(Complete->0)
......
Nagłówek ostatniej odpowiedzi:header(Complete->1)Ustaw regułę warunku końcowego jako "EndCondition:headers. Complete": "Const:1" , aby zakończyć stronicowanie, gdy wartość klucza nagłówka w odpowiedzi jest równa wartości const zdefiniowanej przez użytkownika.

Przykład 4.6: stronicowanie kończy się, gdy klucz istnieje w nagłówku odpowiedzi
Klucze nagłówków w odpowiedziach REST API są przedstawione w strukturze poniżej:
Nagłówek odpowiedzi 1:
header()
......
Nagłówek ostatniej odpowiedzi:header(CompleteTime->20220920)Ustaw regułę warunku końcowego jako "EndCondition:headers.CompleteTime": "Istnieje", aby zakończyć stronicowanie, gdy klucz istnieje w nagłówku odpowiedzi.

Przykład 5: Ustawianie warunku końcowego w celu uniknięcia niekończących się żądań, gdy reguła zakresu nie jest zdefiniowana
W tym przykładzie przedstawiono kroki konfiguracji służące do wysyłania wielu żądań, gdy reguła zakresu nie jest używana. Warunek końcowy można ustawić, odwołując się do przykładów 4.1-4.6, aby uniknąć niekończących się żądań. Interfejs API REST zwraca odpowiedź w następującej strukturze, w której adres URL następnej strony jest reprezentowany w paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
Ostatnia odpowiedź to:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Krok 1. Ustaw reguły stronicowania jako "AbsoluteUrl": "$.paging.next".
Krok 2. Jeśli next w ostatniej odpowiedzi jest zawsze taki sam adres URL ostatniego żądania i nie jest pusty, żądania niekończące się będą wysyłane. Warunek końcowy może służyć do unikania niekończących się żądań. W związku z tym ustaw regułę warunku końcowego na przykład 4.1-4.6.
Przykład 6: Ustawianie maksymalnej liczby żądań, aby uniknąć niekończącego się żądania
Ustaw wartość MaxRequestNumber , aby uniknąć niekończącego się żądania, jak pokazano na poniższym zrzucie ekranu:

Przykład 7: Reguła stronicowania RFC 5988 jest domyślnie obsługiwana
Backend automatycznie pobierze następny adres URL na podstawie linków w stylu RFC 5988 w nagłówku.

Napiwek
Jeśli nie chcesz włączyć tej domyślnej reguły stronicowania, możesz ją ustawić supportRFC5988 na false lub po prostu usunąć w skrycie.
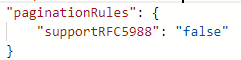
Przykład 8a: Następny adres URL żądania znajduje się w treści odpowiedzi podczas korzystania z stronicowania w przepływach danych mapowania
W tym przykładzie przedstawiono sposób ustawienia reguły stronicowania i reguły warunku końcowego w przepływach danych, gdy następny adres URL żądania pochodzi z treści odpowiedzi.
Schemat odpowiedzi jest pokazany poniżej:
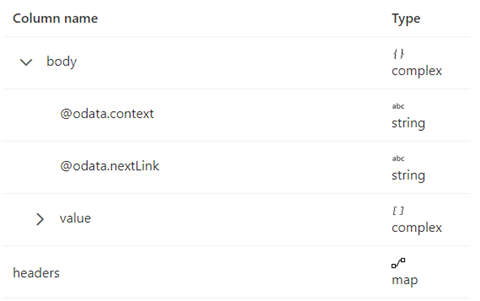
Reguły stronicowania powinny być zgodne z przedstawionym zrzutem ekranu.

Domyślnie stronicowanie zostanie zatrzymane, gdy treść. {@odata.nextLink}** ma wartość null lub jest pusta.
Jeśli jednak wartość @odata.nextLink w ostatniej treści odpowiedzi jest równa ostatniemu adresowi URL żądania, doprowadzi to do nieskończonej pętli. Aby uniknąć tego warunku, zdefiniuj reguły warunków końcowych.
Jeśli wartość w ostatniej odpowiedzi jest pusta, można ustawić regułę warunku końcowego w następujący sposób:

Jeśli wartość pełnego klucza w nagłówku odpowiedzi jest równa true i wskazuje koniec stronicowania, można ustawić regułę warunku końcowego w następujący sposób:
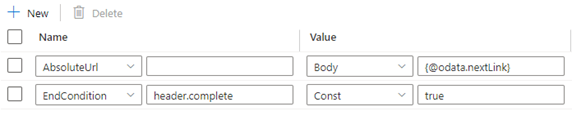
Przykład 8b: następny adres URL żądania znajduje się w treści odpowiedzi podczas korzystania z stronicowania w działaniu kopiowania
W tym przykładzie pokazano, jak ustawić regułę stronicowania w działaniu kopiowania, gdy następny adres URL żądania jest zawarty w treści odpowiedzi.
Schemat odpowiedzi jest pokazany poniżej:
Reguły stronicowania powinny być ustawione, jak pokazano na poniższym zrzucie ekranu:

Przykład 9: Format odpowiedzi to XML, a następny adres URL żądania pochodzi z treści odpowiedzi podczas używania paginacji w przepływach danych przy mapowaniu
W tym przykładzie przedstawiono sposób ustawiania reguły stronicowania w przepływach danych mapowania, gdy format odpowiedzi to XML, a następny adres URL żądania pochodzi z treści odpowiedzi. Jak pokazano na poniższym zrzucie ekranu, pierwszy adres URL to https://<user>.dfs.core.windows.NET/bugfix/test/movie_1.xml
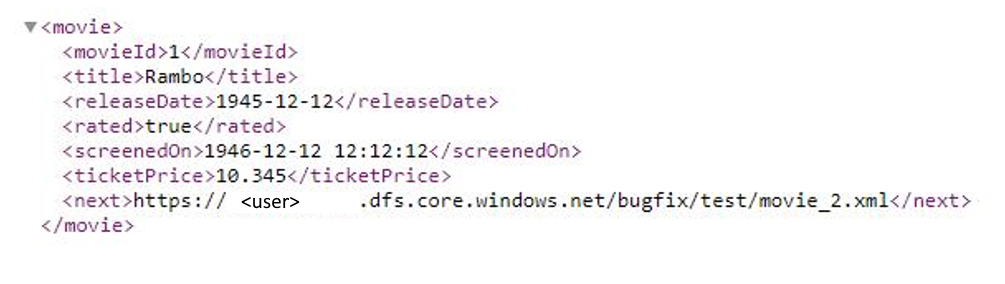
Schemat odpowiedzi jest pokazany poniżej:
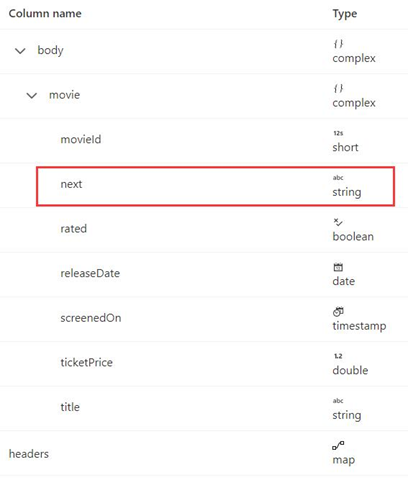
Składnia reguły stronicowania jest taka sama jak w przykładzie 8 i powinna być ustawiona jak poniżej w tym przykładzie:

Eksportuj odpowiedź JSON bez zmian
Łącznik REST umożliwia eksportowanie odpowiedzi JSON interfejsu API REST as-is do różnych systemów magazynowania opartych na plikach (ujściów). Aby włączyć to zachowanie niezależne od schematu kopiowania, użyj domyślnego mapowania schematu (nie należy definiować żadnego mapowania na karcie Mapowanie działania kopiowania).
Mapowanie schematu
Aby skopiować dane z punktu końcowego REST do ujścia tabelarycznego, zapoznaj się z schematem mapowania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych przez działanie kopiowania jako źródła i ujścia w Azure Data Factory, zobacz Obsługiwane magazyny danych i formaty.