Zarchiwizowane informacje o wersji
Podsumowanie
Usługa Azure HDInsight jest jedną z najpopularniejszych usług wśród klientów korporacyjnych na potrzeby analizy typu open source na platformie Azure. Zasubskrybuj informacje o wersji usługi HDInsight, aby uzyskać aktualne informacje dotyczące usługi HDInsight i wszystkich wersji usługi HDInsight.
Aby zasubskrybować, kliknij przycisk "obejrzyj" na banerze i zwróć uwagę na wydania usługi HDInsight.
Informacje o wersji
Data wydania: 15 kwietnia 2024 r.
Ta uwaga dotycząca wersji dotyczy ![]() usługi HDInsight w wersji 5.1.
usługi HDInsight w wersji 5.1.
Wersja usługi HDInsight będzie dostępna we wszystkich regionach w ciągu kilku dni. Ta informacja o wersji ma zastosowanie do 2403290825 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Uwaga
System Ubuntu 18.04 jest obsługiwany w ramach rozszerzonej konserwacji zabezpieczeń (ESM) przez zespół ds. systemu Linux platformy Azure dla usługi Azure HDInsight z lipca 2023 r.
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz wersje składników usługi HDInsight 5.x.
Naprawione problemy
- Poprawki błędów dla bazy danych Ambari DB, kontrolera magazynu Hive (HWC), Spark, HDFS
- Poprawki błędów modułu usługi Log Analytics dla dzienników HDInsightSparkLogs
- CVE — poprawki dla dostawcy zasobów usługi HDInsight.
 Wkrótce
Wkrótce
- Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD).
- Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
- Powiadomienia o wycofaniu dla usług HDInsight 4.0 i HDInsight 5.0.
Jeśli masz więcej pytań, skontaktuj się z pomocą techniczną platformy Azure.
Zawsze możesz zapytać nas o usługę HDInsight w usłudze Azure HDInsight — Microsoft Q&A.
Słuchamy: Zapraszamy, aby dodać więcej pomysłów i innych tematów tutaj i głosować na nie — pomysły na usługę HDInsight i śledzić nas, aby uzyskać więcej aktualizacji w społeczności usługi AzureHDInsight.
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Data wydania: 15 lutego 2024 r.
Ta wersja dotyczy wersji HDInsight 4.x i 5.x. Wersja usługi HDInsight będzie dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2401250802 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Uwaga
System Ubuntu 18.04 jest obsługiwany w ramach rozszerzonej konserwacji zabezpieczeń (ESM) przez zespół ds. systemu Linux platformy Azure dla usługi Azure HDInsight z lipca 2023 r.
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
Nowe funkcje
- Obsługa platformy Apache Ranger dla usługi Spark SQL na platformie Spark 3.3.0 (HDInsight w wersji 5.1) z pakietem Enterprise Security. Więcej informacji na ten temat znajduje się tutaj.
Naprawione problemy
- Poprawki zabezpieczeń ze składników Ambari i Oozie
Wkrótce
- Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD).
- Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
Jeśli masz więcej pytań, skontaktuj się z pomocą techniczną platformy Azure.
Zawsze możesz zapytać nas o usługę HDInsight w usłudze Azure HDInsight — Microsoft Q&A
Słuchamy: Zapraszamy, aby dodać więcej pomysłów i innych tematów tutaj i głosować na nie — pomysły na usługę HDInsight i obserwuj nas, aby uzyskać więcej aktualizacji w społeczności usługi AzureHDInsight
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Następne kroki
- Azure HDInsight: Często zadawane pytania
- Konfigurowanie harmonogramu stosowania poprawek systemu operacyjnego dla klastrów usługi HDInsight opartych na systemie Linux
- Poprzednia informacja o wersji
Usługa Azure HDInsight jest jedną z najpopularniejszych usług wśród klientów korporacyjnych na potrzeby analizy typu open source na platformie Azure. Jeśli chcesz subskrybować informacje o wersji, obejrzyj wydania w tym repozytorium GitHub.
Data wydania: 10 stycznia 2024 r.
Ta wersja poprawki dotyczy wersji HDInsight 4.x i 5.x. Wersja usługi HDInsight będzie dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2401030422 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Uwaga
System Ubuntu 18.04 jest obsługiwany w ramach rozszerzonej konserwacji zabezpieczeń (ESM) przez zespół ds. systemu Linux platformy Azure dla usługi Azure HDInsight z lipca 2023 r.
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
Naprawione problemy
- Poprawki zabezpieczeń ze składników Ambari i Oozie
Wkrótce
- Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD).
- Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
Jeśli masz więcej pytań, skontaktuj się z pomocą techniczną platformy Azure.
Zawsze możesz zapytać nas o usługę HDInsight w usłudze Azure HDInsight — Microsoft Q&A
Słuchamy: Zapraszamy, aby dodać więcej pomysłów i innych tematów tutaj i głosować na nie — pomysły na usługę HDInsight i obserwuj nas, aby uzyskać więcej aktualizacji w społeczności usługi AzureHDInsight
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Data wydania: 26 października 2023 r.
Ta wersja dotyczy wersji HDInsight 4.x i 5.x usługi HDInsight będzie dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2310140056 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
Co nowego
Usługa HDInsight ogłasza ogólną dostępność usługi HDInsight 5.1 od 1 listopada 2023 r. Ta wersja udostępnia pełne odświeżanie stosu do składników typu open source i integracji firmy Microsoft.
- Najnowsze wersje open source — usługa HDInsight 5.1 jest dostępna z najnowszą stabilną wersją typu open source. Klienci mogą korzystać ze wszystkich najnowszych funkcji typu open source, ulepszeń wydajności firmy Microsoft i poprawek błędów.
- Bezpieczne — najnowsze wersje są dostarczane z najnowszymi poprawkami zabezpieczeń, zarówno poprawkami zabezpieczeń typu open source, jak i ulepszeniami zabezpieczeń firmy Microsoft.
- Niższy koszt całkowitego kosztu posiadania — dzięki ulepszeniom wydajności klienci mogą obniżyć koszty operacyjne wraz z ulepszonym skalowaniem automatycznym.
Uprawnienia klastra do bezpiecznego magazynu
- Klienci mogą określić (podczas tworzenia klastra), czy do łączenia konta magazynu należy użyć bezpiecznego kanału dla węzłów klastra usługi HDInsight.
Tworzenie klastra usługi HDInsight przy użyciu niestandardowych sieci wirtualnych.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
Microsoft Network/virtualNetworks/subnets/join/actionwykonywania operacji tworzenia. Jeśli ta kontrola nie jest włączona, klient może napotkać błędy tworzenia.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
Klastry inne niż ESP ABFS [Uprawnienia klastra dla programu Word do odczytu]
- Klastry ABFS inne niż ESP ograniczają użytkowników grup innych niż Hadoop do wykonywania poleceń hadoop na potrzeby operacji magazynu. Ta zmiana poprawia stan zabezpieczeń klastra.
Aktualizacja limitu przydziału w wierszu.
- Teraz możesz zażądać zwiększenia limitu przydziału bezpośrednio na stronie Mój limit przydziału, a bezpośrednie wywołanie interfejsu API jest znacznie szybsze. W przypadku niepowodzenia wywołania interfejsu API można utworzyć nowy wniosek o pomoc techniczną w celu zwiększenia limitu przydziału.
Wkrótce
Maksymalna długość nazwy klastra zostanie zmieniona na 45 z 59 znaków, aby poprawić stan zabezpieczeń klastrów. Ta zmiana zostanie wdrożona we wszystkich regionach, począwszy od nadchodzącej wersji.
Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD).
- Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
Jeśli masz więcej pytań, skontaktuj się z pomocą techniczną platformy Azure.
Zawsze możesz zapytać nas o usługę HDInsight w usłudze Azure HDInsight — Microsoft Q&A
Słuchamy: Zapraszamy, aby dodać więcej pomysłów i innych tematów tutaj i głosować na nie — pomysły na usługę HDInsight i obserwuj nas, aby uzyskać więcej aktualizacji w społeczności usługi AzureHDInsight
Uwaga
Ta wersja dotyczy następujących cves wydanych przez MSRC 12 września 2023 r. Akcja polega na aktualizacji do najnowszego obrazu 2308221128 lub 2310140056. Klienci powinni odpowiednio zaplanować.
| CVE | Ważność | Tytuł listy błędów CVE | Uwaga |
|---|---|---|---|
| CVE-2023-38156 | Ważne | Luka w zabezpieczeniach podniesienia uprawnień narzędzia Apache Ambari dla usługi Azure HDInsight | Uwzględniona w obrazach 2308221128 lub 2310140056 |
| CVE-2023-36419 | Ważne | Luka w zabezpieczeniach dotycząca podniesienia uprawnień za pomocą programu Apache Oozie harmonogramu pracy w usłudze Azure HDInsight | Stosowanie akcji skryptu w klastrach lub aktualizowanie do obrazu 2310140056 |
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Data wydania: 7 września 2023 r.
Ta wersja dotyczy wersji HDInsight 4.x i 5.x usługi HDInsight będzie dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2308221128 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
Ważne
Ta wersja dotyczy następujących cves wydanych przez MSRC 12 września 2023 r. Akcja polega na zaktualizowaniu do najnowszej 2308221128 obrazu. Klienci powinni odpowiednio zaplanować.
| CVE | Ważność | Tytuł listy błędów CVE | Uwaga |
|---|---|---|---|
| CVE-2023-38156 | Ważne | Luka w zabezpieczeniach podniesienia uprawnień narzędzia Apache Ambari dla usługi Azure HDInsight | Uwzględniony na obrazie 2308221128 |
| CVE-2023-36419 | Ważne | Luka w zabezpieczeniach dotycząca podniesienia uprawnień za pomocą programu Apache Oozie harmonogramu pracy w usłudze Azure HDInsight | Stosowanie akcji skryptu w klastrach |
Wkrótce
- Maksymalna długość nazwy klastra zostanie zmieniona na 45 z 59 znaków, aby poprawić stan zabezpieczeń klastrów. Ta zmiana zostanie wdrożona do 30 września 2023 r.
- Uprawnienia klastra do bezpiecznego magazynu
- Klienci mogą określić (podczas tworzenia klastra), czy do kontaktowania się z kontem magazynu należy użyć bezpiecznego kanału dla węzłów klastra usługi HDInsight.
- Aktualizacja limitu przydziału w wierszu.
- Żądania zwiększenia limitów przydziału bezpośrednio na stronie Mój limit przydziału, który będzie bezpośrednim wywołaniem interfejsu API, co jest szybsze. Jeśli wywołanie usługi APdI zakończy się niepowodzeniem, klienci muszą utworzyć nowy wniosek o pomoc techniczną w celu zwiększenia limitu przydziału.
- Tworzenie klastra usługi HDInsight przy użyciu niestandardowych sieci wirtualnych.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
Microsoft Network/virtualNetworks/subnets/join/actionwykonywania operacji tworzenia. Klienci musieliby odpowiednio zaplanować, ponieważ ta zmiana byłaby obowiązkowym sprawdzaniem, aby uniknąć błędów tworzenia klastra przed 30 września 2023 r.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
- Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD). Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
- Klastry inne niż ESP ABFS [Uprawnienia klastra dla programu Word do odczytu]
- Zaplanuj wprowadzenie zmian w klastrach innych niż ESP ABFS, które ograniczają użytkowników grup innych niż Hadoop do wykonywania poleceń hadoop na potrzeby operacji magazynu. Ta zmiana w celu poprawy stanu zabezpieczeń klastra. Klienci muszą zaplanować aktualizacje przed 30 września 2023 r.
Jeśli masz więcej pytań, skontaktuj się z pomocą techniczną platformy Azure.
Zawsze możesz zapytać nas o usługę HDInsight w usłudze Azure HDInsight — Microsoft Q&A
Zapraszamy do dodania kolejnych propozycji i pomysłów oraz innych tematów tutaj i głosowania na nie — społeczność usługi HDInsight (azure.com).
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Data wydania: 25 lipca 2023 r.
Ta wersja dotyczy wersji HDInsight 4.x i 5.x usługi HDInsight będzie dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2307201242 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
 Co nowego
Co nowego
- Usługa HDInsight 5.1 jest teraz obsługiwana w klastrze ESP.
- Uaktualniona wersja platformy Ranger 2.3.0 i Oozie 5.2.1 są teraz częścią usługi HDInsight 5.1
- Klaster Spark 3.3.1 (HDInsight 5.1) jest dostarczany z klastrem Hive Warehouse Connector (HWC) 2.1, który współpracuje z klastrem Interactive Query (HDInsight 5.1).
- System Ubuntu 18.04 jest obsługiwany przez zespół ds. zabezpieczeń platformy Azure dla usługi Azure HDInsight z lipca 2023 r. w wersji 2023.
Ważne
Ta wersja dotyczy następujących cves wydanych przez MSRC 8 sierpnia 2023 r. Akcja polega na zaktualizowaniu do najnowszego 2307201242 obrazu. Klienci powinni odpowiednio zaplanować.
| CVE | Ważność | Tytuł listy błędów CVE |
|---|---|---|
| CVE-2023-35393 | Ważne | Luka w zabezpieczeniach dotycząca fałszowania w usłudze Azure Apache Hive |
| CVE-2023-35394 | Ważne | Luka w zabezpieczeniach dotycząca fałszowania notesu Jupyter Notebook w usłudze Azure HDInsight |
| CVE-2023-36877 | Ważne | Luka w zabezpieczeniach dotycząca fałszowania platformy Azure Oozie |
| CVE-2023-36881 | Ważne | Luka w zabezpieczeniach dotycząca fałszowania na platformie Azure Apache Ambari |
| CVE-2023-38188 | Ważne | Luka w zabezpieczeniach dotycząca fałszowania w usłudze Azure Apache Hadoop |
Wkrótce
- Maksymalna długość nazwy klastra zostanie zmieniona na 45 z 59 znaków, aby poprawić stan zabezpieczeń klastrów. Klienci muszą zaplanować aktualizacje przed 30 września 2023 r.
- Uprawnienia klastra do bezpiecznego magazynu
- Klienci mogą określić (podczas tworzenia klastra), czy do kontaktowania się z kontem magazynu należy użyć bezpiecznego kanału dla węzłów klastra usługi HDInsight.
- Aktualizacja limitu przydziału w wierszu.
- Żądania zwiększenia limitów przydziału bezpośrednio na stronie Mój limit przydziału, który będzie bezpośrednim wywołaniem interfejsu API, co jest szybsze. Jeśli wywołanie interfejsu API zakończy się niepowodzeniem, klienci muszą utworzyć nowy wniosek o pomoc techniczną w celu zwiększenia limitu przydziału.
- Tworzenie klastra usługi HDInsight przy użyciu niestandardowych sieci wirtualnych.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
Microsoft Network/virtualNetworks/subnets/join/actionwykonywania operacji tworzenia. Klienci musieliby odpowiednio zaplanować, ponieważ ta zmiana byłaby obowiązkowym sprawdzaniem, aby uniknąć błędów tworzenia klastra przed 30 września 2023 r.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
- Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD). Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych z serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
- Klastry inne niż ESP ABFS [Uprawnienia klastra dla programu Word do odczytu]
- Zaplanuj wprowadzenie zmian w klastrach innych niż ESP ABFS, które ograniczają użytkowników grup innych niż Hadoop do wykonywania poleceń hadoop na potrzeby operacji magazynu. Ta zmiana w celu poprawy stanu zabezpieczeń klastra. Klienci muszą zaplanować aktualizacje przed 30 września 2023 r.
Jeśli masz więcej pytań, skontaktuj się z pomocą techniczną platformy Azure.
Zawsze możesz zapytać nas o usługę HDInsight w usłudze Azure HDInsight — Microsoft Q&A
Witamy, aby dodać więcej propozycji i pomysłów i innych tematów tutaj i głosować na nich — społeczność usługi HDInsight (azure.com) i śledzić nas, aby uzyskać więcej aktualizacji na twitterze
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Data wydania: 08 maja 2023 r.
Ta wersja dotyczy wersji HDInsight 4.x i 5.x usługi HDInsight jest dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2304280205 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
![]()
Zaktualizowano usługę Azure HDInsight 5.1 za pomocą polecenia
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Uwaga
- Wszystkie składniki są zintegrowane z usługą Hadoop 3.3.4 i ZK 3.6.3
- Wszystkie powyższe uaktualnione składniki są teraz dostępne w klastrach innych niż ESP w publicznej wersji zapoznawczej.
![]()
Rozszerzone autoskalowania dla usługi HDInsight
Usługa Azure HDInsight dokonała znaczących ulepszeń stabilności i opóźnień w skalowaniu automatycznym. Istotne zmiany obejmują ulepszoną pętlę opinii na potrzeby podejmowania decyzji dotyczących skalowania, znaczne ulepszenia opóźnienia skalowania i obsługi ponownego kommisji zlikwidowanych węzłów, dowiedz się więcej o ulepszeniach, sposobie konfigurowania i migrowania klastra do rozszerzonego skalowania automatycznego. Ulepszona funkcja automatycznego skalowania jest dostępna od 17 maja 2023 r. we wszystkich obsługiwanych regionach.
Usługa Azure HDInsight ESP dla platformy Apache Kafka 2.4.1 jest teraz ogólnie dostępna.
Usługa Azure HDInsight ESP dla platformy Apache Kafka 2.4.1 jest dostępna w publicznej wersji zapoznawczej od kwietnia 2022 r. Po istotnych ulepszeniach w poprawkach i stabilności cve usługa Azure HDInsight ESP Kafka 2.4.1 staje się teraz ogólnie dostępna i gotowa dla obciążeń produkcyjnych, dowiedz się więcej o sposobie konfigurowania i migrowania.
Zarządzanie limitami przydziału dla usługi HDInsight
Usługa HDInsight obecnie przydziela limit przydziału do subskrypcji klientów na poziomie regionalnym. Rdzenie przydzielone klientom są ogólne i nie są klasyfikowane na poziomie rodziny maszyn wirtualnych (na przykład ,
Dv2Ev3, ,Eav4itp.).Usługa HDInsight wprowadziła ulepszony widok, który zapewnia szczegółowy i klasyfikację przydziałów dla maszyn wirtualnych na poziomie rodziny, ta funkcja umożliwia klientom wyświetlanie bieżących i pozostałych przydziałów dla regionu na poziomie rodziny maszyn wirtualnych. Dzięki ulepszonym widokom klienci mają bogatszą widoczność, planowanie przydziałów i lepsze środowisko użytkownika. Ta funkcja jest obecnie dostępna w usługach HDInsight 4.x i 5.x dla regionu Wschodnie stany USA EUAP. Inne regiony do późniejszego użycia.
Aby uzyskać więcej informacji, zobacz Planowanie pojemności klastra w usłudze Azure HDInsight | Microsoft Learn
![]()
- Polska Środkowa
- Maksymalna długość nazwy klastra zmienia się na 45 z 59 znaków, aby zwiększyć poziom zabezpieczeń klastrów.
- Uprawnienia klastra do bezpiecznego magazynu
- Klienci mogą określić (podczas tworzenia klastra), czy do kontaktowania się z kontem magazynu należy użyć bezpiecznego kanału dla węzłów klastra usługi HDInsight.
- Aktualizacja limitu przydziału w wierszu.
- Żądania zwiększenia limitów przydziału bezpośrednio na stronie Mój limit przydziału, który jest bezpośrednim wywołaniem interfejsu API, co jest szybsze. Jeśli wywołanie interfejsu API zakończy się niepowodzeniem, klienci muszą utworzyć nowy wniosek o pomoc techniczną w celu zwiększenia limitu przydziału.
- Tworzenie klastra usługi HDInsight przy użyciu niestandardowych sieci wirtualnych.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
Microsoft Network/virtualNetworks/subnets/join/actionwykonywania operacji tworzenia. Klienci musieliby odpowiednio zaplanować, ponieważ byłoby to obowiązkowe sprawdzenie, aby uniknąć błędów tworzenia klastra.
- Aby poprawić ogólny stan zabezpieczeń klastrów usługi HDInsight, klastry usługi HDInsight korzystające z niestandardowych sieci wirtualnych muszą mieć pewność, że użytkownik musi mieć uprawnienia do
- Wycofanie maszyn wirtualnych z serii A w warstwie Podstawowa i Standardowa.
- 31 sierpnia 2024 r. wycofamy maszyny wirtualne z serii A w warstwie Podstawowa i Standardowa. Przed tą datą należy przeprowadzić migrację obciążeń do maszyn wirtualnych z serii Av2, które zapewniają większą ilość pamięci na procesor wirtualny i szybszy magazyn na dyskach półprzewodnikowych (SSD). Aby uniknąć przerw w działaniu usługi, przeprowadź migrację obciążeń z maszyn wirtualnych serii Podstawowa i Standardowa do maszyn wirtualnych z serii Av2 przed 31 sierpnia 2024 r.
- Klastry inne niż ESP ABFS [Uprawnienia klastra do odczytu na świecie]
- Zaplanuj wprowadzenie zmian w klastrach innych niż ESP ABFS, które ograniczają użytkowników grup innych niż Hadoop do wykonywania poleceń hadoop na potrzeby operacji magazynu. Ta zmiana w celu poprawy stanu zabezpieczeń klastra. Klienci muszą zaplanować aktualizacje.
Data wydania: 28 lutego 2023 r.
Ta wersja dotyczy usługi HDInsight 4.0. i 5.0, 5.1. Wersja usługi HDInsight jest dostępna we wszystkich regionach w ciągu kilku dni. Ta wersja ma zastosowanie do 2302250400 numeru obrazu. Jak sprawdzić numer obrazu?
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz
Ważne
Firma Microsoft wydała CVE-2023-23408, co zostało naprawione w bieżącej wersji, a klienci powinni uaktualnić klastry do najnowszej wersji.
![]()
HDInsight 5.1
Rozpoczęliśmy wdrażanie nowej wersji usługi HDInsight 5.1. Wszystkie nowe wersje typu open source dodane jako wersje przyrostowe w usłudze HDInsight 5.1.
Aby uzyskać więcej informacji, zobacz HDInsight 5.1.0 w wersji
![]()
Uaktualnienie platformy Kafka 3.2.0 (wersja zapoznawcza)
- Platforma Kafka 3.2.0 zawiera kilka znaczących nowych funkcji/ulepszeń.
- Uaktualniono dozorcę do wersji 3.6.3
- Obsługa strumieni platformy Kafka
- Silniejsze gwarancje dostarczania dla producenta platformy Kafka włączone domyślnie.
log4j1.x zastąpione ciągiemreload4j.- Wyślij wskazówkę do lidera partycji, aby odzyskać partycję.
JoinGroupRequestiLeaveGroupRequestmają dołączony powód.- Dodano metryki liczby brokerów8.
- Ulepszenia dublowania
Maker2.
Uaktualnienie bazy danych HBase 2.4.11 (wersja zapoznawcza)
- Ta wersja ma nowe funkcje, takie jak dodanie nowych typów mechanizmów buforowania dla pamięci podręcznej bloku, możliwość zmiany
hbase:meta tablei wyświetlaniahbase:metatabeli z internetowego interfejsu użytkownika HBase.
Uaktualnienie phoenix 5.1.2 (wersja zapoznawcza)
- Wersja Phoenix została uaktualniona do wersji 5.1.2 w tej wersji. To uaktualnienie obejmuje serwer Phoenix Query Server. Serwer proxy Phoenix Query Server jest standardowym sterownikiem Phoenix JDBC i zapewnia protokół przewodu zgodny z poprzednimi wersjami w celu wywołania tego sterownika JDBC.
Ambari CVEs
- Naprawiono wiele cvi ambari.
Uwaga
Usługa ESP nie jest obsługiwana w przypadku platform Kafka i bazy danych HBase w tej wersji.
![]()
Koniec wsparcia dla klastrów usługi Azure HDInsight na platformie Spark 2.4 z 10 lutego 2024 r. Aby uzyskać więcej informacji, zobacz Wersje platformy Spark obsługiwane w usłudze Azure HDInsight
Co dalej?
- Autoskaluj
- Automatyczne skalowanie z ulepszonym opóźnieniem i kilkoma ulepszeniami
- Ograniczenie zmiany nazwy klastra
- Maksymalna długość nazwy klastra zmienia się na 45 z 59 w obszarze Publiczne, Azure — Chiny i Azure Government.
- Uprawnienia klastra do bezpiecznego magazynu
- Klienci mogą określić (podczas tworzenia klastra), czy do kontaktowania się z kontem magazynu należy użyć bezpiecznego kanału dla węzłów klastra usługi HDInsight.
- Klastry inne niż ESP ABFS [Uprawnienia klastra do odczytu na świecie]
- Zaplanuj wprowadzenie zmian w klastrach innych niż ESP ABFS, które ograniczają użytkowników grup innych niż Hadoop do wykonywania poleceń hadoop na potrzeby operacji magazynu. Ta zmiana w celu poprawy stanu zabezpieczeń klastra. Klienci muszą zaplanować aktualizacje.
- Uaktualnienia typu open source
- Platformy Apache Spark 3.3.0 i Hadoop 3.3.4 są opracowywane w usłudze HDInsight 5.1 i zawierają kilka znaczących nowych funkcji, wydajności i innych ulepszeń.
Uwaga
Zalecamy klientom korzystanie z najnowszych wersji obrazów usługi HDInsight w miarę korzystania z najlepszych aktualizacji typu open source, aktualizacji platformy Azure i poprawek zabezpieczeń. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania.
Data wydania: 12 grudnia 2022 r.
Ta wersja dotyczy usługi HDInsight 4.0. i wersja 5.0 usługi HDInsight jest udostępniana wszystkim regionom w ciągu kilku dni.
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
Wersje systemu operacyjnego
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aby zapoznać się z wersjami specyficznymi dla obciążenia, zobacz tutaj.
![]()
- Log Analytics — klienci mogą włączyć monitorowanie klasyczne, aby uzyskać najnowszą wersję pakietu OMS w wersji 14.19. Aby usunąć stare wersje, wyłącz i włącz monitorowanie klasyczne.
- Automatyczne wylogowanie użytkownika systemu Ambari z powodu braku aktywności. Aby uzyskać więcej informacji, zobacz tutaj
- Spark — nowa i zoptymalizowana wersja platformy Spark 3.1.3 jest zawarta w tej wersji. Przetestowaliśmy platformę Apache Spark 3.1.2 (poprzednią wersję) i platformę Apache Spark 3.1.3 (bieżącą wersję) przy użyciu testu porównawczego TPC-DS. Test został przeprowadzony przy użyciu jednostki SKU E8 V3 dla platformy Apache Spark w obciążeniu 1 TB. Platforma Apache Spark 3.1.3 (bieżąca wersja) przekroczyła wydajność platformy Apache Spark 3.1.2 (poprzednia wersja) o ponad 40% w łącznym czasie wykonywania zapytań TPC-DS przy użyciu tych samych specyfikacji sprzętowych. Zespół platformy Microsoft Spark dodał optymalizacje dostępne w usłudze Azure Synapse w usłudze Azure HDInsight. Aby uzyskać więcej informacji, zobacz Przyspieszanie obciążeń danych za pomocą aktualizacji wydajności platformy Apache Spark 3.1.2 w usłudze Azure Synapse
![]()
- Katar Środkowy
- Niemcy Północne
![]()
Usługa HDInsight odeszła od zestawu Azul Zulu Java JDK 8 do
Adoptium Temurin JDK 8systemu , który obsługuje wysokiej jakości certyfikowane środowiska uruchomieniowe TCK i skojarzoną technologię do użycia w ekosystemie Java.Usługa HDInsight została zmigrowana do programu
reload4j. Zmianylog4jmają zastosowanie do- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Pheonix
![]()
Usługa HDInsight w celu zaimplementowania protokołu TLS1.2 w przyszłości, a wcześniejsze wersje są aktualizowane na platformie. Jeśli korzystasz z dowolnych aplikacji w usłudze HDInsight i używają protokołów TLS 1.0 i 1.1, przeprowadź uaktualnienie do protokołu TLS 1.2, aby uniknąć zakłóceń w usługach.
Aby uzyskać więcej informacji, zobacz Jak włączyć protokół Transport Layer Security (TLS)
![]()
Koniec wsparcia dla klastrów usługi Azure HDInsight w systemie Ubuntu 16.04 LTS od 30 listopada 2022 r. Usługa HDInsight rozpoczyna wydawanie obrazów klastra przy użyciu systemu Ubuntu 18.04 od 27 czerwca 2021 r. Zalecamy naszym klientom, którzy korzystają z klastrów korzystających z systemu Ubuntu 16.04, jest ponowne skompilowanie klastrów przy użyciu najnowszych obrazów usługi HDInsight do 30 listopada 2022 r.
Aby uzyskać więcej informacji na temat sprawdzania wersji klastra w systemie Ubuntu, zobacz tutaj
Wykonaj polecenie "lsb_release -a" w terminalu.
Jeśli wartość właściwości "Description" w danych wyjściowych to "Ubuntu 16.04 LTS", ta aktualizacja ma zastosowanie do klastra.
![]()
- Obsługa wyboru Strefy dostępności dla klastrów kafka i HBase (dostęp do zapisu).
Poprawki błędów typu open source
Poprawki błędów hive
| Poprawki błędów | Apache JIRA |
|---|---|
| HIVE-26127 | Błąd INSERT OVERWRITE — nie znaleziono pliku |
| HIVE-24957 | Nieprawidłowe wyniki, gdy podzapytywanie ma coalESCE w predykacie korelacji |
| HIVE-24999 | Funkcja HiveSubQueryRemoveRule generuje nieprawidłowy plan dla podzapytania IN z wieloma korelacjami |
| HIVE-24322 | Jeśli istnieje bezpośrednie wstawianie, identyfikator próby musi zostać sprawdzony podczas odczytywania manifestu kończy się niepowodzeniem |
| HIVE-23363 | Uaktualnianie zależności DataNucleus do wersji 5.2 |
| HIVE-26412 | Tworzenie interfejsu w celu pobierania dostępnych miejsc i dodawania wartości domyślnej |
| HIVE-26173 | Uaktualnij derby do wersji 10.14.2.0 |
| HIVE-25920 | Bump Xerce2 do 2.12.2. |
| HIVE-26300 | Uaktualnij wersję powiązania danych Jacksona z wersją 2.12.6.1 lub nowszą, aby uniknąć cve-2020-36518 |
Data wydania: 10.08.2022
Ta wersja dotyczy usługi HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni.
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
![]()
Nowa funkcja
1. Dołączanie dysków zewnętrznych w klastrach Hadoop/Spark w usłudze HDI
Klaster usługi HDInsight zawiera wstępnie zdefiniowane miejsce na dysku na podstawie jednostki SKU. Ta przestrzeń może nie być wystarczająca w dużych scenariuszach zadań.
Ta nowa funkcja umożliwia dodawanie większej liczby dysków w klastrze, które są używane jako katalog lokalny menedżera węzłów. Dodaj liczbę dysków do węzłów roboczych podczas tworzenia klastra HIVE i Spark, podczas gdy wybrane dyski są częścią katalogów lokalnych menedżera węzłów.
Uwaga
Dodane dyski są konfigurowane tylko dla katalogów lokalnych menedżera węzłów.
Aby uzyskać więcej informacji, zobacz tutaj
2. Analiza selektywnego rejestrowania
Analiza selektywnego rejestrowania jest teraz dostępna we wszystkich regionach w publicznej wersji zapoznawczej. Klaster można połączyć z obszarem roboczym usługi Log Analytics. Po włączeniu można wyświetlić dzienniki i metryki, takie jak dzienniki zabezpieczeń usługi HDInsight, usługa Yarn Resource Manager, metryki systemowe itp. Możesz monitorować obciążenia i zobaczyć, jak wpływają one na stabilność klastra. Selektywne rejestrowanie umożliwia włączanie/wyłączanie wszystkich tabel lub włączanie selektywnych tabel w obszarze roboczym usługi Log Analytics. Można dostosować typ źródła dla każdej tabeli, ponieważ w nowej wersji monitorowania Genewa jedna tabela ma wiele źródeł.
- System monitorowania Genewa używa demona mdsd(MDS), który jest agentem monitorowania i biegłym do zbierania dzienników przy użyciu ujednoliconej warstwy rejestrowania.
- Selektywne rejestrowanie używa akcji skryptu do wyłączania/włączania tabel i ich typów dzienników. Ponieważ nie otwiera żadnych nowych portów ani nie zmienia istniejącego ustawienia zabezpieczeń, nie ma żadnych zmian zabezpieczeń.
- Akcja skryptu jest uruchamiana równolegle we wszystkich określonych węzłach i zmienia pliki konfiguracji dotyczące wyłączania/włączania tabel i ich typów dzienników.
Aby uzyskać więcej informacji, zobacz tutaj
![]()
Stała
Analiza dzienników
Usługa Log Analytics zintegrowana z usługą Azure HDInsight z systemem OMS w wersji 13 wymaga uaktualnienia do wersji OMS w wersji 14 w celu zastosowania najnowszych aktualizacji zabezpieczeń. Klienci korzystający ze starszej wersji klastra z pakietem OMS w wersji 13 muszą zainstalować pakiet OMS w wersji 14, aby spełnić wymagania dotyczące zabezpieczeń. (Jak sprawdzić bieżącą wersję i zainstalować 14)
Jak sprawdzić bieżącą wersję pakietu OMS
- Zaloguj się do klastra przy użyciu protokołu SSH.
- Uruchom następujące polecenie w kliencie SSH.
sudo /opt/omi/bin/ominiserver/ --version

Jak uaktualnić WERSJĘ pakietu OMS z wersji 13 do 14
- Zaloguj się do witryny Azure Portal.
- W grupie zasobów wybierz zasób klastra usługi HDInsight
- Wybieranie akcji skryptu
- W panelu akcji Prześlij skrypt wybierz pozycję Typ skryptu jako niestandardowy
- Wklej następujący link w polu Adres URL skryptu powłoki Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Wybieranie typów węzłów
- Wybierz pozycję Utwórz
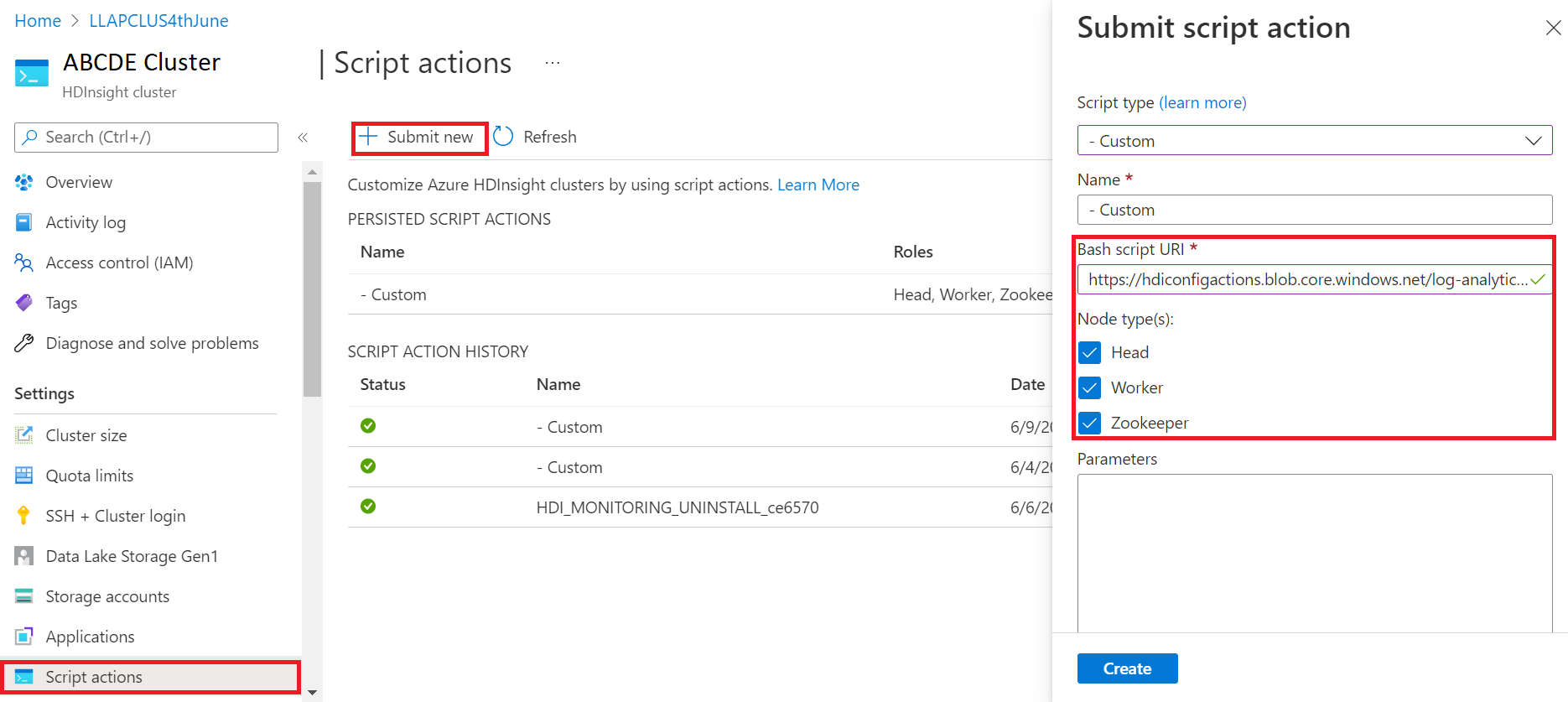
Sprawdź pomyślną instalację poprawki, wykonując następujące kroki:
Zaloguj się do klastra przy użyciu protokołu SSH.
Uruchom następujące polecenie w kliencie SSH.
sudo /opt/omi/bin/ominiserver/ --version
Inne poprawki błędów
- Interfejs wiersza polecenia dziennika usługi Yarn nie może pobrać dzienników, jeśli są
TFileuszkodzone lub puste. - Usunięto błąd nieprawidłowej jednostki usługi podczas pobierania tokenu OAuth z usługi Azure Active Directory.
- Ulepszona niezawodność tworzenia klastra po skonfigurowaniu 100+ węzłów roboczych.
Poprawki błędów typu open source
Poprawki błędów TEZ
| Poprawki błędów | Apache JIRA |
|---|---|
| Niepowodzenie kompilacji tez: nie znaleziono FileSaver.js | TEZ-4411 |
Nieprawidłowy wyjątek FS w przypadku magazynu i scratchdir znajdują się na różnych fs |
TEZ-4406 |
| TezUtils.createConfFromByteString w konfiguracji większej niż 32 MB zgłasza wyjątek com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils::createByteStringFromConf powinien używać przystawki zamiast DeflaterOutputStream | TEZ-4113 |
| Aktualizowanie zależności protobuf do wersji 3.x | TEZ-4363 |
Poprawki błędów hive
| Poprawki błędów | Apache JIRA |
|---|---|
| Optymalizacje wydajności w generacji podzielonej ORC | HIVE-21457 |
| Unikaj odczytywania tabeli jako ACID, gdy nazwa tabeli zaczyna się od "różnicy", ale tabela nie jest transakcyjna, a strategia podziału analizy biznesowej jest używana | HIVE-22582 |
| Usuwanie wywołania FS#exists z acidUtils#getLogicalLength | HIVE-23533 |
| Wektoryzowane orcAcidRowBatchReader.computeOffset i optymalizacja zasobnika | HIVE-17917 |
Znane problemy
Usługa HDInsight jest zgodna z programem Apache HIVE 3.1.2. Ze względu na usterkę w tej wersji wersja programu Hive jest wyświetlana jako wersja 3.1.0 w interfejsach hive. Nie ma jednak wpływu na funkcjonalność.
Data wydania: 10.08.2022
Ta wersja dotyczy usługi HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni.
Usługa HDInsight korzysta z bezpiecznych rozwiązań wdrażania, które obejmują stopniowe wdrażanie regionów. Udostępnienie nowej wersji we wszystkich regionach może potrwać do 10 dni roboczych.
![]()
Nowa funkcja
1. Dołączanie dysków zewnętrznych w klastrach Hadoop/Spark w usłudze HDI
Klaster usługi HDInsight zawiera wstępnie zdefiniowane miejsce na dysku na podstawie jednostki SKU. Ta przestrzeń może nie być wystarczająca w dużych scenariuszach zadań.
Ta nowa funkcja umożliwia dodawanie większej liczby dysków w klastrze, które będą używane jako katalog lokalny menedżera węzłów. Dodaj liczbę dysków do węzłów roboczych podczas tworzenia klastra HIVE i Spark, podczas gdy wybrane dyski są częścią katalogów lokalnych menedżera węzłów.
Uwaga
Dodane dyski są konfigurowane tylko dla katalogów lokalnych menedżera węzłów.
Aby uzyskać więcej informacji, zobacz tutaj
2. Analiza selektywnego rejestrowania
Analiza selektywnego rejestrowania jest teraz dostępna we wszystkich regionach w publicznej wersji zapoznawczej. Klaster można połączyć z obszarem roboczym usługi Log Analytics. Po włączeniu można wyświetlić dzienniki i metryki, takie jak dzienniki zabezpieczeń usługi HDInsight, usługa Yarn Resource Manager, metryki systemowe itp. Możesz monitorować obciążenia i zobaczyć, jak wpływają one na stabilność klastra. Selektywne rejestrowanie umożliwia włączanie/wyłączanie wszystkich tabel lub włączanie selektywnych tabel w obszarze roboczym usługi Log Analytics. Można dostosować typ źródła dla każdej tabeli, ponieważ w nowej wersji monitorowania Genewa jedna tabela ma wiele źródeł.
- System monitorowania Genewa używa demona mdsd(MDS), który jest agentem monitorowania i biegłym do zbierania dzienników przy użyciu ujednoliconej warstwy rejestrowania.
- Selektywne rejestrowanie używa akcji skryptu do wyłączania/włączania tabel i ich typów dzienników. Ponieważ nie otwiera żadnych nowych portów ani nie zmienia istniejącego ustawienia zabezpieczeń, nie ma żadnych zmian zabezpieczeń.
- Akcja skryptu jest uruchamiana równolegle we wszystkich określonych węzłach i zmienia pliki konfiguracji dotyczące wyłączania/włączania tabel i ich typów dzienników.
Aby uzyskać więcej informacji, zobacz tutaj
![]()
Stała
Analiza dzienników
Usługa Log Analytics zintegrowana z usługą Azure HDInsight z systemem OMS w wersji 13 wymaga uaktualnienia do wersji OMS w wersji 14 w celu zastosowania najnowszych aktualizacji zabezpieczeń. Klienci korzystający ze starszej wersji klastra z pakietem OMS w wersji 13 muszą zainstalować pakiet OMS w wersji 14, aby spełnić wymagania dotyczące zabezpieczeń. (Jak sprawdzić bieżącą wersję i zainstalować 14)
Jak sprawdzić bieżącą wersję pakietu OMS
- Zaloguj się do klastra przy użyciu protokołu SSH.
- Uruchom następujące polecenie w kliencie SSH.
sudo /opt/omi/bin/ominiserver/ --version
Jak uaktualnić WERSJĘ pakietu OMS z wersji 13 do 14
- Zaloguj się do witryny Azure Portal.
- W grupie zasobów wybierz zasób klastra usługi HDInsight
- Wybieranie akcji skryptu
- W panelu akcji Prześlij skrypt wybierz pozycję Typ skryptu jako niestandardowy
- Wklej następujący link w polu Adres URL skryptu powłoki Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Wybieranie typów węzłów
- Wybierz pozycję Utwórz
Sprawdź pomyślną instalację poprawki, wykonując następujące kroki:
Zaloguj się do klastra przy użyciu protokołu SSH.
Uruchom następujące polecenie w kliencie SSH.
sudo /opt/omi/bin/ominiserver/ --version
Inne poprawki błędów
- Interfejs wiersza polecenia dziennika usługi Yarn nie może pobrać dzienników, jeśli są
TFileuszkodzone lub puste. - Usunięto błąd nieprawidłowej jednostki usługi podczas pobierania tokenu OAuth z usługi Azure Active Directory.
- Ulepszona niezawodność tworzenia klastra po skonfigurowaniu 100+ węzłów roboczych.
Poprawki błędów typu open source
Poprawki błędów TEZ
| Poprawki błędów | Apache JIRA |
|---|---|
| Niepowodzenie kompilacji tez: nie znaleziono FileSaver.js | TEZ-4411 |
Nieprawidłowy wyjątek FS w przypadku magazynu i scratchdir znajdują się na różnych fs |
TEZ-4406 |
| TezUtils.createConfFromByteString w konfiguracji większej niż 32 MB zgłasza wyjątek com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils::createByteStringFromConf powinien używać przystawki zamiast DeflaterOutputStream | TEZ-4113 |
| Aktualizowanie zależności protobuf do wersji 3.x | TEZ-4363 |
Poprawki błędów hive
| Poprawki błędów | Apache JIRA |
|---|---|
| Optymalizacje wydajności w generacji podzielonej ORC | HIVE-21457 |
| Unikaj odczytywania tabeli jako ACID, gdy nazwa tabeli zaczyna się od "różnicy", ale tabela nie jest transakcyjna, a strategia podziału analizy biznesowej jest używana | HIVE-22582 |
| Usuwanie wywołania FS#exists z acidUtils#getLogicalLength | HIVE-23533 |
| Wektoryzowane orcAcidRowBatchReader.computeOffset i optymalizacja zasobnika | HIVE-17917 |
Znane problemy
Usługa HDInsight jest zgodna z programem Apache HIVE 3.1.2. Ze względu na usterkę w tej wersji wersja programu Hive jest wyświetlana jako wersja 3.1.0 w interfejsach hive. Nie ma jednak wpływu na funkcjonalność.
Data wydania: 06.03.2022
Ta wersja dotyczy usługi HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, poczekaj, aż wydanie będzie aktywne w Twoim regionie w ciągu kilku dni.
Najważniejsze informacje o wersji
Łącznik magazynu Hive (HWC) na platformie Spark w wersji 3.1.2
Łącznik magazynu Hive (HWC) umożliwia korzystanie z unikatowych funkcji technologii Hive i Spark w celu tworzenia zaawansowanych aplikacji danych big data. Funkcja HWC jest obecnie obsługiwana tylko w przypadku platformy Spark w wersji 2.4. Ta funkcja zwiększa wartość biznesową, umożliwiając transakcje ACID w tabelach Hive przy użyciu platformy Spark. Ta funkcja jest przydatna dla klientów korzystających zarówno z technologii Hive, jak i Platformy Spark w ich infrastrukturze danych. Aby uzyskać więcej informacji, zobacz Apache Spark & Hive — Łącznik magazynu Hive — Azure HDInsight | Microsoft Docs
Ambari
- Zmiany ulepszeń skalowania i aprowizacji
- Gałąź usługi HDI jest teraz zgodna z systemem operacyjnym w wersji 3.1.2
Wersja hdI Hive 3.1 została uaktualniona do programu Hive systemu operacyjnego 3.1.2. Ta wersja zawiera wszystkie poprawki i funkcje dostępne w wersji Hive 3.1.2 typu open source.
Uwaga
Spark
- Jeśli używasz interfejsu użytkownika platformy Azure do tworzenia klastra Spark dla usługi HDInsight, zobaczysz z listy rozwijanej inną wersję platformy Spark 3.1. (HDI 5.0) wraz ze starszymi wersjami. Ta wersja jest zmienioną wersją platformy Spark 3.1. (HDI 4.0). Jest to tylko zmiana na poziomie interfejsu użytkownika, która nie ma wpływu na istniejących użytkowników i użytkowników, którzy już korzystają z szablonu usługi ARM.
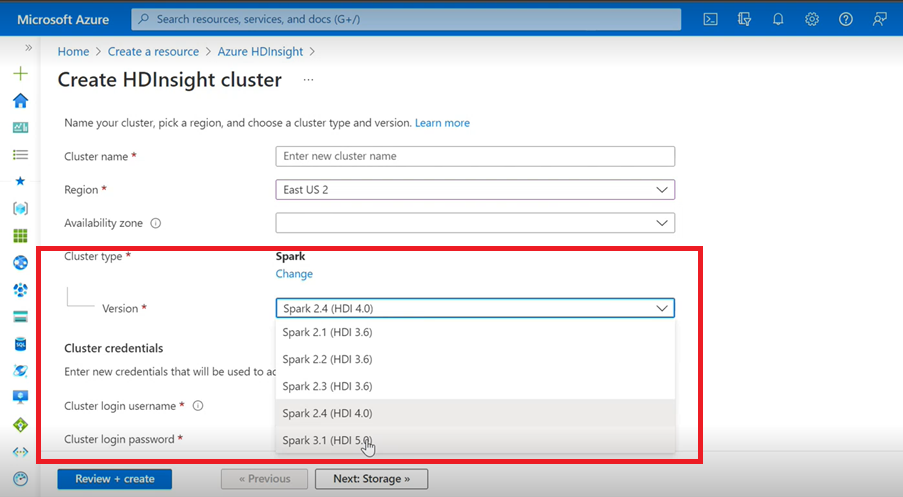
Uwaga
Zapytanie interakcyjne
- Jeśli tworzysz klaster zapytań interakcyjnych, zobaczysz z listy rozwijanej inną wersję jako Interactive Query 3.1 (HDI 5.0).
- Jeśli zamierzasz używać platformy Spark 3.1 wraz z programem Hive, które wymagają obsługi acid, musisz wybrać tę wersję Interactive Query 3.1 (HDI 5.0).
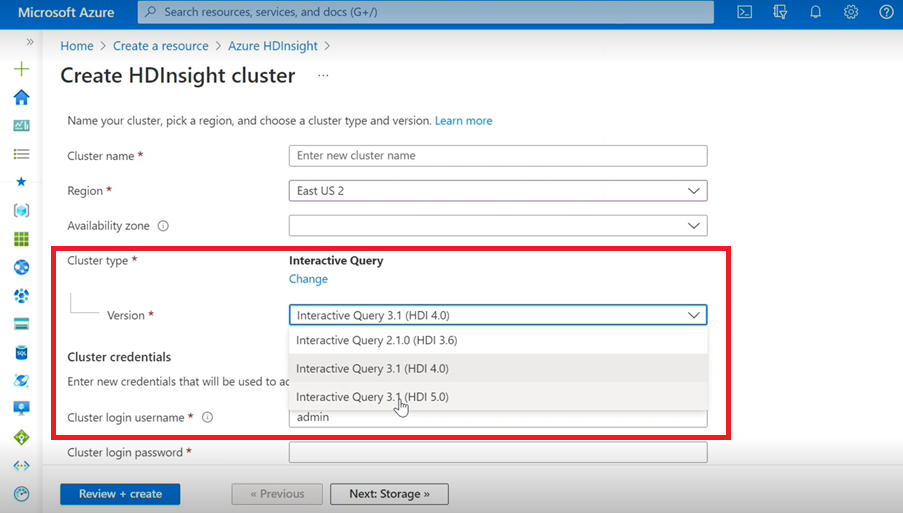
Poprawki błędów TEZ
| Poprawki błędów | Apache JIRA |
|---|---|
| TezUtils.createConfFromByteString w konfiguracji większej niż 32 MB zgłasza wyjątek com.google.protobuf.CodedInputStream | TEZ-4142 |
| Narzędzia TezUtils createByteStringFromConf powinny używać przystawki zamiast DeflaterOutputStream | TEZ-4113 |
Poprawki błędów bazy danych HBase
| Poprawki błędów | Apache JIRA |
|---|---|
TableSnapshotInputFormat powinien używać funkcji ReadType.STREAM do skanowania HFiles |
HBASE-26273 |
| Dodaj opcję wyłączania funkcji scanMetrics w tabeliSnapshotInputFormat | HBASE-26330 |
| Poprawka dotycząca elementu ArrayIndexOutOfBoundsException podczas wykonywania usługi Balancer | HBASE-22739 |
Poprawki błędów hive
| Poprawki błędów | Apache JIRA |
|---|---|
| NpE podczas wstawiania danych z klauzulą "distribute by" z optymalizacją sortowania dynpart | HIVE-18284 |
| Polecenie MSCK REPAIR z filtrowaniem partycji kończy się niepowodzeniem podczas upuszczania partycji | HIVE-23851 |
| Wystąpił nieprawidłowy wyjątek, jeśli pojemność<= 0 | HIVE-25446 |
| Obsługa ładowania równoległego dla tabel HastTables — interfejsy | HIVE-25583 |
| Domyślnie uwzględnij element MultiDelimitSerDe w serwerze HiveServer2 | HIVE-20619 |
| Usuń klasy glassfish.jersey i mssql-jdbc z pliku jdbc-standalone jar | HIVE-22134 |
| Wyjątek wskaźnika null podczas uruchamiania kompaktowania względem tabeli MM. | HIVE-21280 |
Zapytanie Hive o dużym rozmiarze za pośrednictwem kończy knox się niepowodzeniem z powodu niepowodzenia przerwanego zapisu potoku |
HIVE-22231 |
| Dodawanie przez użytkownika możliwości ustawiania powiązanego użytkownika | HIVE-21009 |
| Implementowanie funkcji zdefiniowanej przez użytkownika w celu interpretowania znacznika daty/godziny przy użyciu wewnętrznej reprezentacji i kalendarza hybrydowego Gregorian-Julian | HIVE-22241 |
| Opcja Beeline, aby pokazać/nie pokazać raportu wykonywania | HIVE-22204 |
| Tez: SplitGenerator próbuje wyszukać pliki planu, które nie istnieją dla tez | HIVE-22169 |
Usuwanie kosztownego rejestrowania z pamięci podręcznej LLAP hotpath |
HIVE-22168 |
| UDF: FunkcjaRegistry synchronizuje się z klasą org.apache.hadoop.hive.ql.udf.UDFType | HIVE-22161 |
| Zapobiegaj tworzeniu dołączania routingu zapytań, jeśli właściwość jest ustawiona na false | HIVE-22115 |
| Usuwanie synchronizacji między zapytaniami dla elementu partition-eval | HIVE-22106 |
| Pomiń konfigurowanie dir podstaw hive podczas planowania | HIVE-21182 |
| Pomiń tworzenie dirs podstaw dla tez, jeśli RPC jest włączony | HIVE-21171 |
przełączanie funkcji zdefiniowanych przez użytkownika programu Hive w celu korzystania z Re2J aparatu regularnego |
HIVE-19661 |
| Zmigrowane tabele klastrowane przy użyciu bucketing_version 1 w hive 3 używa bucketing_version 2 w przypadku wstawiania | HIVE-22429 |
| Zasobniki: zasobnik w wersji 1 jest niepoprawnie partycjonowanie danych | HIVE-21167 |
| Dodawanie nagłówka licencji ASF do nowo dodanego pliku | HIVE-22498 |
| Ulepszenia narzędzia schematu do obsługi mergeCatalog | HIVE-22498 |
| Usługa Hive z funkcją TEZ UNION ALL i UDTF powoduje utratę danych | HIVE-21915 |
| Dzielenie plików tekstowych, nawet jeśli nagłówek/stopka istnieje | HIVE-21924 |
| Funkcja MultiDelimitSerDe zwraca nieprawidłowe wyniki w ostatniej kolumnie, gdy załadowany plik ma więcej kolumn niż ten, który znajduje się w schemacie tabeli | HIVE-22360 |
| Klient zewnętrzny LLAP — należy zmniejszyć ślad LlapBaseInputFormat#getSplits() | HIVE-22221 |
| Nazwa kolumny z zastrzeżonym słowem kluczowym jest niewyobrażona, gdy zapytanie zawierające sprzężenia w tabeli z kolumną maski zostanie przepisane (Zoltan Matyus za pośrednictwem Zoltan Haindrich) | HIVE-22208 |
Zapobieganie zamykaniu protokołu LLAP w AMReporter powiązanym środowisku uruchomieniowymException |
HIVE-22113 |
| Sterownik usługi stanu LLAP może zostać zablokowany z nieprawidłowym identyfikatorem aplikacji Yarn | HIVE-21866 |
| OperationManager.queryIdOperation nie czyści prawidłowo wielu identyfikatorów queryId | HIVE-22275 |
| Przełączanie menedżera węzłów w dół blokuje ponowne uruchamianie usługi LLAP | HIVE-22219 |
| StackOverflowError podczas upuszczania dużej liczby partycji | HIVE-15956 |
| Sprawdzanie dostępu nie powiodło się po usunięciu katalogu tymczasowego | HIVE-22273 |
| Napraw nieprawidłowe wyniki/Wyjątek ArrayOutOfBound w lewym sprzężeniach mapy zewnętrznej w określonych warunkach granic | HIVE-22120 |
| Usuwanie tagu zarządzania dystrybucją z pom.xml | HIVE-19667 |
| Czas analizowania może być wysoki, jeśli istnieją głęboko zagnieżdżone podzapytania | HIVE-21980 |
W przypadku polecenia ALTER TABLE nie SET TBLPROPERTIES ('EXTERNAL'='TRUE'); TBL_TYPE zmiany atrybutów, które nie są odzwierciedlane dla innych niż CAPS |
HIVE-20057 |
JDBC: interfejsy odcieni log4j HiveConnection |
HIVE-18874 |
Aktualizowanie adresów URL repozytorium w gałęzi poms 3.1 |
HIVE-21786 |
DBInstall testy uszkodzone na serwerze głównym i gałęzi-3.1 |
HIVE-21758 |
| Ładowanie danych do tabeli zasobnikowej powoduje ignorowanie specyfikacji partycji i ładowanie danych do partycji domyślnej | HIVE-21564 |
| Zapytania z warunkiem sprzężenia o sygnaturę czasową lub sygnaturę czasową z lokalnym literałem strefy czasowej zgłaszają wyjątek SemanticException | HIVE-21613 |
| Analizowanie statystyk obliczeniowych dla kolumn pozostawinych za tymczasowym dir w systemie plików HDFS | HIVE-21342 |
| Niezgodna zmiana w obliczeniach zasobnika Hive | HIVE-21376 |
| Podaj rezerwowy autoryzator, gdy żaden inny autoryzator nie jest używany | HIVE-20420 |
| Niektóre wywołania alterPartitions zgłaszają wyjątek "NumberFormatException: null" | HIVE-18767 |
| HiveServer2: Wstępnie uwierzytelniony temat dla transportu http nie jest zachowywany przez cały czas trwania komunikacji http w niektórych przypadkach | HIVE-20555 |
Data wydania: 10.03.2022
Ta wersja dotyczy usługi HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, poczekaj, aż wydanie będzie aktywne w Twoim regionie w ciągu kilku dni.
Wersje systemu operacyjnego dla tej wersji to:
- HDInsight 4.0: Ubuntu 18.04.5
Platforma Spark 3.1 jest teraz ogólnie dostępna
Platforma Spark 3.1 jest teraz ogólnie dostępna w wersji HDInsight 4.0. Ta wersja zawiera
- Adaptacyjne wykonywanie zapytań,
- Konwertowanie sprzężenia scalania sortowania na sprzężenie skrótu emisji,
- Optymalizator Spark Catalyst,
- Dynamiczne oczyszczanie partycji,
- Klienci będą mogli tworzyć nowe klastry Spark 3.1, a nie klastry Spark 3.0 (wersja zapoznawcza).
Aby uzyskać więcej informacji, zobacz Apache Spark 3.1 jest teraz ogólnie dostępny w usłudze HDInsight — Microsoft Tech Community.
Aby uzyskać pełną listę ulepszeń, zobacz informacje o wersji platformy Apache Spark 3.1.
Aby uzyskać więcej informacji na temat migracji, zobacz przewodnik migracji.
Platforma Kafka 2.4 jest teraz ogólnie dostępna
Platforma Kafka 2.4.1 jest teraz ogólnie dostępna. Aby uzyskać więcej informacji, zobacz Informacje o wersji platformy Kafka 2.4.1. Inne funkcje obejmują dostępność mirrorMaker 2, nową kategorię metryk Partycja tematu AtMinIsr, Ulepszony czas uruchamiania brokera przez leniwy na żądanie mmap plików indeksu, Więcej metryk konsumentów w celu obserwowania zachowania ankiety użytkownika.
Mapuj typ danych w HWC jest teraz obsługiwany w usłudze HDInsight 4.0
Ta wersja obejmuje obsługę mapowania typu danych dla HWC 1.0 (Spark 2.4) za pośrednictwem aplikacji spark-shell oraz wszystkich innych klientów platformy Spark, które obsługuje HWC. Następujące ulepszenia są uwzględniane jak w przypadku innych typów danych:
Użytkownik może
- Utwórz tabelę Programu Hive z dowolną kolumną zawierającą typ danych mapy, wstaw do niej dane i odczytaj z niej wyniki.
- Utwórz ramkę danych platformy Apache Spark z typem mapy i wykonaj operacje odczytu i zapisu wsadowego/strumienia.
Nowe regiony
Usługa HDInsight rozszerzyła swoją obecność geograficzną na dwa nowe regiony: Chiny Wschodnie 3 i Chiny Północne 3.
Zmiany w zapleczu systemu operacyjnego
Backporty systemu operacyjnego, które znajdują się w programie Hive, w tym HWC 1.0 (Spark 2.4), które obsługują typ danych mapy.
Poniżej przedstawiono kopie zapasowe systemu operacyjnego Apache JIRAs dla tej wersji:
| Funkcja, której to dotyczy | Apache JIRA |
|---|---|
| Bezpośrednie zapytania SQL magazynu metadanych z funkcją IN/(NOT IN) powinny być podzielone na podstawie maksymalnych parametrów dozwolonych przez bazę danych SQL | HIVE-25659 |
Uaktualnij log4j 2.16.0 do wersji 2.17.0 |
HIVE-25825 |
Aktualizowanie Flatbuffer wersji |
HIVE-22827 |
| Obsługa natywnego typu danych mapy w formacie strzałki | HIVE-25553 |
| Klient zewnętrzny LLAP — obsługa wartości zagnieżdżonych, gdy struktura nadrzędna ma wartość null | HIVE-25243 |
| Uaktualnij wersję strzałki do wersji 0.11.0 | HIVE-23987 |
Powiadomienia o wycofaniu
Zestawy skalowania maszyn wirtualnych platformy Azure w usłudze HDInsight
Usługa HDInsight nie będzie już używać zestawów skalowania maszyn wirtualnych platformy Azure do aprowizowania klastrów, a zmiana powodująca niezgodność nie jest oczekiwana. Istniejące klastry usługi HDInsight w zestawach skalowania maszyn wirtualnych nie mają wpływu, żadne nowe klastry na najnowszych obrazach nie będą już korzystać z zestawów skalowania maszyn wirtualnych.
Skalowanie obciążeń bazy danych HBase w usłudze Azure HDInsight będzie teraz obsługiwane tylko przy użyciu skalowania ręcznego
Począwszy od 01 marca 2022 r., usługa HDInsight będzie obsługiwać tylko ręczną skalę bazy danych HBase. Nie ma to wpływu na uruchamianie klastrów. Nowe klastry HBase nie będą mogły włączyć skalowania automatycznego opartego na harmonogramie. Aby uzyskać więcej informacji na temat ręcznego skalowania klastra HBase, zapoznaj się z naszą dokumentacją dotyczącą ręcznego skalowania klastrów usługi Azure HDInsight
Data wydania: 27.01.2021
Ta wersja dotyczy usługi HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, poczekaj, aż wydanie będzie aktywne w Twoim regionie w ciągu kilku dni.
Wersje systemu operacyjnego dla tej wersji to:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Obraz usługi HDInsight 4.0 został zaktualizowany w celu ograniczenia Log4j luk w zabezpieczeniach zgodnie z opisem w artykule Odpowiedź firmy Microsoft na CVE-2021-44228 Apache Log4j 2.
Uwaga
- Wszystkie klastry HDI 4.0 utworzone po 27 grudnia 2021 r. 00:00 UTC są tworzone ze zaktualizowaną wersją obrazu, która ogranicza
log4jluki w zabezpieczeniach. W związku z tym klienci nie muszą stosować poprawek/ponownego uruchamiania tych klastrów. - W przypadku nowych klastrów usługi HDInsight 4.0 utworzonych między 16 grudnia 2021 r. o 01:15 UTC i 27 grudnia 2021 r. 00:00 UTC, HdInsight 3.6 lub w przypiętych subskrypcjach po 16 grudnia 2021 r. poprawka jest stosowana automatycznie w ciągu godziny, w której klaster jest tworzony, jednak klienci muszą następnie ponownie uruchomić węzły, aby poprawki zostały ukończone (z wyjątkiem węzłów zarządzania platformy Kafka, które są automatycznie uruchamiane ponownie).
Data wydania: 27.07.2021
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Wersje systemu operacyjnego dla tej wersji to:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nowe funkcje
Obsługa usługi Azure HDInsight dla ograniczonej łączności publicznej jest ogólnie dostępna 15 października 2021 r.
Usługa Azure HDInsight obsługuje teraz ograniczoną łączność publiczną we wszystkich regionach. Poniżej przedstawiono niektóre najważniejsze najważniejsze elementy tej funkcji:
- Możliwość odwrócenia dostawcy zasobów do komunikacji klastra w taki sposób, że jest on wychodzący z klastra do dostawcy zasobów
- Obsługa przenoszenia własnych zasobów z włączoną usługą Private Link (na przykład magazyn, SQL, magazyn kluczy) dla klastra usługi HDInsight w celu uzyskania dostępu tylko do zasobów za pośrednictwem sieci prywatnej
- Żadne publiczne adresy IP nie są aprowizowane zasób
Korzystając z tej nowej funkcji, można również pominąć reguły tagów tagów usługi sieciowej grupy zabezpieczeń dla ruchu przychodzącego dla adresów IP zarządzania usługą HDInsight. Dowiedz się więcej o ograniczaniu łączności publicznej
Obsługa usługi Azure HDInsight dla usługi Azure Private Link jest ogólnie dostępna 15 października 2021 r.
Teraz możesz używać prywatnych punktów końcowych do nawiązywania połączenia z klastrami usługi HDInsight za pośrednictwem łącza prywatnego. Link prywatny może być używany w scenariuszach obejmujących wiele sieci wirtualnych, w których komunikacja równorzędna sieci wirtualnych nie jest dostępna ani włączona.
Usługa Azure Private Link umożliwia dostęp do usług Azure PaaS (na przykład Azure Storage i SQL Database) oraz hostowanych przez klientów/partnerów platformy Azure za pośrednictwem prywatnego punktu końcowego w sieci wirtualnej.
Ruch między siecią wirtualną a usługą podróżuje siecią szkieletową firmy Microsoft. Udostępnianie usługi w publicznej sieci Internet nie jest już konieczne.
Pozwól więcej na włączanie łącza prywatnego.
Nowe środowisko integracji usługi Azure Monitor (wersja zapoznawcza)
Nowe środowisko integracji usługi Azure Monitor będzie w wersji zapoznawczej w regionach Wschodnie stany USA i Europa Zachodnia w tej wersji. Dowiedz się więcej o nowym środowisku usługi Azure Monitor tutaj.
Wycofanie
Wersja usługi HDInsight 3.6 jest przestarzała od 01 października 2022 r.
Zmiany zachowania
Interakcyjne zapytanie usługi HDInsight obsługuje tylko automatyczne skalowanie oparte na harmonogramie
W miarę zwiększania się bardziej dojrzałych i zróżnicowanych scenariuszy klientów zidentyfikowaliśmy pewne ograniczenia dotyczące skalowania automatycznego opartego na zapytaniu interaktywnym (LLAP). Te ograniczenia są spowodowane przez charakter dynamiki zapytań LLAP, przyszłych problemów z dokładnością przewidywania obciążenia i problemów w redystrybucji zadania harmonogramu LLAP. Ze względu na te ograniczenia użytkownicy mogą zobaczyć, że ich zapytania działają wolniej w klastrach LLAP po włączeniu autoskalowania. Wpływ na wydajność może przewyższać korzyści związane z kosztami skalowania automatycznego.
Od lipca 2021 r. obciążenie Interakcyjne zapytanie w usłudze HDInsight obsługuje tylko automatyczne skalowanie oparte na harmonogramie. Nie można już włączyć automatycznego skalowania opartego na obciążeniu w nowych klastrach zapytań interakcyjnych. Istniejące uruchomione klastry mogą nadal działać ze znanymi ograniczeniami opisanymi powyżej.
Firma Microsoft zaleca przejście do automatycznego skalowania opartego na harmonogramie dla protokołu LLAP. Bieżący wzorzec użycia klastra można analizować za pomocą pulpitu nawigacyjnego programu Grafana Hive. Aby uzyskać więcej informacji, zobacz Automatyczne skalowanie klastrów usługi Azure HDInsight.
Nadchodzące zmiany
Następujące zmiany są wprowadzane w nadchodzących wersjach.
Wbudowany składnik LLAP w klastrze ESP Spark zostanie usunięty
Klaster ESP Platformy SPARK w usłudze HDInsight 4.0 ma wbudowane składniki LLAP działające w obu węzłach głównych. Składniki LLAP w klastrze ESP Spark zostały pierwotnie dodane dla platformy Spark w usłudze HDInsight 3.6 ESP, ale nie ma rzeczywistego przypadku użytkownika dla platformy SPARK w usłudze HDInsight 4.0 ESP. W następnej wersji zaplanowanej w wrzu 2021 r. usługa HDInsight usunie wbudowany składnik LLAP z klastra PLATFORMy SPARK usługi HDInsight 4.0 ESP. Ta zmiana pomaga odciążyć obciążenie węzła głównego i uniknąć nieporozumień między typem klastra ESP Spark i ESP Interactive Hive.
Nowy region
- Zachodnie stany USA 3
JioIndie Zachodnie- Australia Środkowa
Zmiana wersji składnika
W tej wersji zmieniono następującą wersję składnika:
- Wersja ORC z wersji 1.5.1 do 1.5.9
Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Powrót portowanych umów JIRA
Poniżej przedstawiono kopię zapasową portowanych umów APACHE JIRA dla tej wersji:
| Funkcja, której to dotyczy | Apache JIRA |
|---|---|
| Znacznik daty/godziny | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORK | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Schemat tabeli | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Zarządzanie obciążeniem | HIVE-24201 |
| Zagęszczania | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Zmaterializowany widok | HIVE-22566 |
Korekta cen dla maszyn wirtualnych usługi HDInsight Dv2
Błąd cenowy został poprawiony 25 kwietnia 2021 r. dla Dv2 serii maszyn wirtualnych w usłudze HDInsight. Błąd cenowy spowodował obniżoną opłatę na rachunkach niektórych klientów przed 25 kwietnia, a z korektą ceny są teraz zgodne z reklamowanymi na stronie cennika usługi HDInsight i kalkulatorem cen usługi HDInsight. Błąd cenowy dotyczył klientów w następujących regionach, którzy używali Dv2 maszyn wirtualnych:
- Kanada Środkowa
- Kanada Wschodnia
- Azja Wschodnia
- Północna Republika Południowej Afryki
- Southeast Asia
- Środkowe Zjednoczone Emiraty Arabskie
Począwszy od 25 kwietnia 2021 r., skorygowana kwota dla Dv2 maszyn wirtualnych będzie znajdować się na Twoim koncie. Powiadomienia klientów zostały wysłane do właścicieli subskrypcji przed zmianą. Możesz użyć kalkulatora cen, strony cennika usługi HDInsight lub bloku Tworzenie klastra usługi HDInsight w witrynie Azure Portal, aby wyświetlić poprawione koszty maszyn Dv2 wirtualnych w twoim regionie.
Od Ciebie nie jest potrzebna żadna inna akcja. Korekta cen będzie stosowana tylko do użycia w dniu 25 kwietnia 2021 r. w określonych regionach, a nie do żadnego użycia przed tą datą. Aby upewnić się, że masz najbardziej wydajne i ekonomiczne rozwiązanie, zalecamy przejrzenie cen, vcPU i pamięci RAM dla Dv2 klastrów oraz porównanie Dv2 specyfikacji Ev3 z maszynami wirtualnymi, aby sprawdzić, czy rozwiązanie skorzysta z jednej z nowszych serii maszyn wirtualnych.
Data wydania: 06.02.2021
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Wersje systemu operacyjnego dla tej wersji to:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nowe funkcje
Uaktualnianie wersji systemu operacyjnego
Jak omówiono w cyklu wydania systemu Ubuntu, jądro Ubuntu 16.04 osiąga koniec życia (EOL) w kwietniu 2021 roku. Rozpoczęliśmy wdrażanie nowego obrazu klastra usługi HDInsight 4.0 uruchomionego w systemie Ubuntu 18.04 w tej wersji. Nowo utworzone klastry usługi HDInsight 4.0 działają domyślnie w systemie Ubuntu 18.04 po udostępnieniu. Istniejące klastry w systemie Ubuntu 16.04 działają zgodnie z pełną obsługą.
Usługa HDInsight 3.6 będzie nadal działać w systemie Ubuntu 16.04. Zmieni się ona na Podstawowa pomoc techniczna (od pomocy technicznej w warstwie Standardowa) od 1 lipca 2021 r. Aby uzyskać więcej informacji na temat dat i opcji pomocy technicznej, zobacz Wersje usługi Azure HDInsight. System Ubuntu 18.04 nie będzie obsługiwany w usłudze HDInsight 3.6. Jeśli chcesz użyć systemu Ubuntu 18.04, musisz przeprowadzić migrację klastrów do usługi HDInsight 4.0.
Należy usunąć i ponownie utworzyć klastry, jeśli chcesz przenieść istniejące klastry usługi HDInsight 4.0 do systemu Ubuntu 18.04. Planowanie tworzenia lub ponownego tworzenia klastrów po udostępnieniu obsługi systemu Ubuntu 18.04.
Po utworzeniu nowego klastra możesz połączyć się z klastrem za pomocą protokołu SSH i uruchomić sudo lsb_release -a polecenie , aby sprawdzić, czy działa on w systemie Ubuntu 18.04. Zalecamy przetestowanie aplikacji w subskrypcjach testowych przed przejściem do środowiska produkcyjnego.
Optymalizacje skalowania w klastrach przyspieszonych zapisów bazy danych HBase
Usługa HDInsight dokonała pewnych ulepszeń i optymalizacji skalowania dla klastrów z obsługą przyspieszonego zapisu HBase. Dowiedz się więcej o przyspieszonym zapisie bazy danych HBase.
Wycofanie
Brak wycofania w tej wersji.
Zmiany zachowania
Wyłączanie rozmiaru maszyny wirtualnej Stardard_A5 jako węzła głównego dla usługi HDInsight 4.0
Węzeł główny klastra usługi HDInsight jest odpowiedzialny za inicjowanie klastra i zarządzanie nim. Standard_A5 rozmiar maszyny wirtualnej ma problemy z niezawodnością jako węzeł główny dla usługi HDInsight 4.0. Począwszy od tej wersji, klienci nie będą mogli tworzyć nowych klastrów z Standard_A5 rozmiarem maszyny wirtualnej jako węzłem głównym. Możesz użyć innych dwurdzeniowych maszyn wirtualnych, takich jak E2_v3 lub E2s_v3. Istniejące klastry będą działać w następujący sposób. Czterordzeniowa maszyna wirtualna jest zdecydowanie zalecana dla węzła głównego, aby zapewnić wysoką dostępność i niezawodność produkcyjnych klastrów usługi HDInsight.
Zasób interfejsu sieciowego nie jest widoczny dla klastrów uruchomionych w zestawach skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight stopniowo migruje do zestawów skalowania maszyn wirtualnych platformy Azure. Interfejsy sieciowe dla maszyn wirtualnych nie są już widoczne dla klientów w przypadku klastrów korzystających z zestawów skalowania maszyn wirtualnych platformy Azure.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Interakcyjne zapytanie usługi HDInsight obsługuje tylko automatyczne skalowanie oparte na harmonogramie
W miarę zwiększania się bardziej dojrzałych i zróżnicowanych scenariuszy klientów zidentyfikowaliśmy pewne ograniczenia dotyczące skalowania automatycznego opartego na zapytaniu interaktywnym (LLAP). Te ograniczenia są spowodowane przez charakter dynamiki zapytań LLAP, przyszłych problemów z dokładnością przewidywania obciążenia i problemów w redystrybucji zadania harmonogramu LLAP. Ze względu na te ograniczenia użytkownicy mogą zobaczyć, że ich zapytania działają wolniej w klastrach LLAP po włączeniu autoskalowania. Wpływ na wydajność może przewyższać korzyści związane z kosztami skalowania automatycznego.
Od lipca 2021 r. obciążenie Interakcyjne zapytanie w usłudze HDInsight obsługuje tylko automatyczne skalowanie oparte na harmonogramie. Nie można już włączyć autoskalowania w nowych klastrach interakcyjnych zapytań. Istniejące uruchomione klastry mogą nadal działać ze znanymi ograniczeniami opisanymi powyżej.
Firma Microsoft zaleca przejście do automatycznego skalowania opartego na harmonogramie dla protokołu LLAP. Bieżący wzorzec użycia klastra można analizować za pomocą pulpitu nawigacyjnego programu Grafana Hive. Aby uzyskać więcej informacji, zobacz Automatyczne skalowanie klastrów usługi Azure HDInsight.
Nazwy hosta maszyny wirtualnej zostaną zmienione 1 lipca 2021 r.
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Usługa stopniowo migruje do zestawów skalowania maszyn wirtualnych platformy Azure. Ta migracja spowoduje zmianę formatu nazwy FQDN nazwy hosta klastra, a liczby w nazwie hosta nie będą gwarantowane w sekwencji. Jeśli chcesz uzyskać nazwy FQDN dla każdego węzła, zobacz Znajdowanie nazw hostów węzłów klastra.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Usługa będzie stopniowo migrowana do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Data wydania: 24.03.2021
Nowe funkcje
Spark 3.0 (wersja zapoznawcza)
Usługa HDInsight dodała obsługę platformy Spark 3.0.0 do usługi HDInsight 4.0 jako funkcji w wersji zapoznawczej.
Kafka 2.4 (wersja zapoznawcza)
Usługa HDInsight dodała obsługę platformy Kafka 2.4.1 do usługi HDInsight 4.0 jako funkcji w wersji zapoznawczej.
Eav4Obsługa serii
Usługa HDInsight dodała Eav4obsługę serii -series w tej wersji.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Usługa stopniowo migruje do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Wycofanie
Brak wycofania w tej wersji.
Zmiany zachowania
Domyślna wersja klastra została zmieniona na 4.0
Domyślna wersja klastra usługi HDInsight została zmieniona z 3.6 na 4.0. Aby uzyskać więcej informacji na temat dostępnych wersji, zobacz dostępne wersje. Dowiedz się więcej o nowościach w usłudze HDInsight 4.0.
Domyślne rozmiary maszyn wirtualnych klastra są zmieniane na Ev3-series
Domyślne rozmiary maszyn wirtualnych klastra są zmieniane z serii D na Ev3-series. Ta zmiana dotyczy węzłów głównych i węzłów roboczych. Aby uniknąć tej zmiany wpływającej na przetestowane przepływy pracy, określ rozmiary maszyn wirtualnych, które mają być używane w szablonie usługi ARM.
Zasób interfejsu sieciowego nie jest widoczny dla klastrów uruchomionych w zestawach skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight stopniowo migruje do zestawów skalowania maszyn wirtualnych platformy Azure. Interfejsy sieciowe dla maszyn wirtualnych nie są już widoczne dla klientów w przypadku klastrów korzystających z zestawów skalowania maszyn wirtualnych platformy Azure.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Interakcyjne zapytanie usługi HDInsight obsługuje tylko automatyczne skalowanie oparte na harmonogramie
W miarę zwiększania się bardziej dojrzałych i zróżnicowanych scenariuszy klientów zidentyfikowaliśmy pewne ograniczenia dotyczące skalowania automatycznego opartego na zapytaniu interaktywnym (LLAP). Te ograniczenia są spowodowane przez charakter dynamiki zapytań LLAP, przyszłych problemów z dokładnością przewidywania obciążenia i problemów w redystrybucji zadania harmonogramu LLAP. Ze względu na te ograniczenia użytkownicy mogą zobaczyć, że ich zapytania działają wolniej w klastrach LLAP po włączeniu autoskalowania. Wpływ na wydajność może przewyższać korzyści związane z kosztami skalowania automatycznego.
Od lipca 2021 r. obciążenie Interakcyjne zapytanie w usłudze HDInsight obsługuje tylko automatyczne skalowanie oparte na harmonogramie. Nie można już włączyć autoskalowania w nowych klastrach interakcyjnych zapytań. Istniejące uruchomione klastry mogą nadal działać ze znanymi ograniczeniami opisanymi powyżej.
Firma Microsoft zaleca przejście do automatycznego skalowania opartego na harmonogramie dla protokołu LLAP. Bieżący wzorzec użycia klastra można analizować za pomocą pulpitu nawigacyjnego programu Grafana Hive. Aby uzyskać więcej informacji, zobacz Automatyczne skalowanie klastrów usługi Azure HDInsight.
Uaktualnianie wersji systemu operacyjnego
Klastry usługi HDInsight są obecnie uruchomione w systemie Ubuntu 16.04 LTS. Zgodnie z opisem w cyklu wydania systemu Ubuntu, jądro Ubuntu 16.04 osiągnie koniec życia (EOL) w kwietniu 2021 roku. Rozpoczniemy wdrażanie nowego obrazu klastra usługi HDInsight 4.0 uruchomionego w systemie Ubuntu 18.04 w maju 2021 r. Nowo utworzone klastry usługi HDInsight 4.0 będą domyślnie uruchamiane w systemie Ubuntu 18.04 po udostępnieniu. Istniejące klastry w systemie Ubuntu 16.04 będą działać zgodnie z pełną obsługą.
Usługa HDInsight 3.6 będzie nadal działać w systemie Ubuntu 16.04. Do dnia 30 czerwca 2021 r. zakończy się wsparcie standardowe i zmieni się na wsparcie podstawowe, począwszy od 1 lipca 2021 r. Aby uzyskać więcej informacji na temat dat i opcji pomocy technicznej, zobacz Wersje usługi Azure HDInsight. System Ubuntu 18.04 nie będzie obsługiwany w usłudze HDInsight 3.6. Jeśli chcesz użyć systemu Ubuntu 18.04, musisz przeprowadzić migrację klastrów do usługi HDInsight 4.0.
Należy usunąć i ponownie utworzyć klastry, jeśli chcesz przenieść istniejące klastry do systemu Ubuntu 18.04. Planowanie tworzenia lub ponownego tworzenia klastra po udostępnieniu obsługi systemu Ubuntu 18.04. Wyślemy kolejne powiadomienie po udostępnieniu nowego obrazu we wszystkich regionach.
Zdecydowanie zaleca się przetestowanie akcji skryptu i niestandardowych aplikacji wdrożonych w węzłach brzegowych na maszynie wirtualnej z systemem Ubuntu 18.04 z wyprzedzeniem. Maszynę wirtualną z systemem Ubuntu Linux można utworzyć w wersji 18.04-LTS, a następnie utworzyć parę kluczy secure shell (SSH) na maszynie wirtualnej, aby uruchomić i przetestować akcje skryptu oraz niestandardowe aplikacje wdrożone w węzłach brzegowych.
Wyłączanie rozmiaru maszyny wirtualnej Stardard_A5 jako węzła głównego dla usługi HDInsight 4.0
Węzeł główny klastra usługi HDInsight jest odpowiedzialny za inicjowanie klastra i zarządzanie nim. Standard_A5 rozmiar maszyny wirtualnej ma problemy z niezawodnością jako węzeł główny dla usługi HDInsight 4.0. Począwszy od następnej wersji w maju 2021 r., klienci nie będą mogli tworzyć nowych klastrów z rozmiarem maszyny wirtualnej Standard_A5 jako węzłem głównym. Możesz użyć innych 2-rdzeniowych maszyn wirtualnych, takich jak E2_v3 lub E2s_v3. Istniejące klastry będą działać w następujący sposób. 4-rdzeniowa maszyna wirtualna jest zdecydowanie zalecana dla węzła głównego, aby zapewnić wysoką dostępność i niezawodność produkcyjnych klastrów usługi HDInsight.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
Dodano obsługę platform Spark 3.0.0 i Kafka 2.4.1 jako wersja zapoznawcza. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 02.05.2021
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Obsługa serii Dav4
Usługa HDInsight dodała obsługę serii Dav4 w tej wersji. Dowiedz się więcej o serii Dav4 tutaj.
Serwer proxy REST platformy Kafka ( ogólna dostępność)
Serwer proxy REST platformy Kafka umożliwia interakcję z klastrem Platformy Kafka za pośrednictwem interfejsu API REST za pośrednictwem protokołu HTTPS. Serwer proxy REST platformy Kafka jest ogólnie dostępny od tej wersji. Dowiedz się więcej o serwerze proxy REST platformy Kafka tutaj.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Usługa stopniowo migruje do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Wycofanie
Wyłączone rozmiary maszyn wirtualnych
Od 9 stycznia 2021 r. usługa HDInsight zablokuje wszystkim klientom tworzenie klastrów przy użyciu standand_A8, standand_A9, standand_A10 i rozmiarów maszyn wirtualnych standand_A11. Istniejące klastry będą działać w następujący sposób. Rozważ przejście do usługi HDInsight 4.0, aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zmiany zachowania
Domyślny rozmiar maszyny wirtualnej klastra zmienia się na Ev3-series
Domyślne rozmiary maszyn wirtualnych klastra zostaną zmienione z serii D na Ev3-series. Ta zmiana dotyczy węzłów głównych i węzłów roboczych. Aby uniknąć tej zmiany wpływającej na przetestowane przepływy pracy, określ rozmiary maszyn wirtualnych, które mają być używane w szablonie usługi ARM.
Zasób interfejsu sieciowego nie jest widoczny dla klastrów uruchomionych w zestawach skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight stopniowo migruje do zestawów skalowania maszyn wirtualnych platformy Azure. Interfejsy sieciowe dla maszyn wirtualnych nie są już widoczne dla klientów w przypadku klastrów korzystających z zestawów skalowania maszyn wirtualnych platformy Azure.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Domyślna wersja klastra zostanie zmieniona na 4.0
Od lutego 2021 r. domyślna wersja klastra usługi HDInsight zostanie zmieniona z 3.6 na 4.0. Aby uzyskać więcej informacji na temat dostępnych wersji, zobacz dostępne wersje. Dowiedz się więcej o nowościach w usłudze HDInsight 4.0.
Uaktualnianie wersji systemu operacyjnego
Usługa HDInsight uaktualnia wersję systemu operacyjnego z systemu Ubuntu 16.04 do wersji 18.04. Uaktualnienie zostanie ukończone przed kwietniem 2021 r.
Zakończenie wsparcia w usłudze HDInsight 3.6 w dniu 30 czerwca 2021 r.
Wsparcie dla usługi HDInsight 3.6 zostanie zakończone. Od 30 czerwca 2021 r. klienci nie mogą tworzyć nowych klastrów usługi HDInsight 3.6. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście do usługi HDInsight 4.0, aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 11.18.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Automatyczna rotacja kluczy na potrzeby szyfrowania kluczy zarządzanych przez klienta magazynowanych
Począwszy od tej wersji, klienci mogą używać adresów URL kluczy szyfrowania bez wersji usługi Azure KeyValut na potrzeby szyfrowania kluczy zarządzanych przez klienta magazynowanych. Usługa HDInsight automatycznie obraca klucze w miarę ich wygaśnięcia lub zastępowania nowymi wersjami. Dowiedz się więcej tutaj.
Możliwość wybierania różnych rozmiarów maszyn wirtualnych usługi Zookeeper dla usług Spark, Hadoop i ML
Wcześniej usługa HDInsight nie obsługiwała dostosowywania rozmiaru węzła zookeeper dla typów klastrów spark, Hadoop i ML Services. Domyślnie A2_v2/A2 rozmiary maszyn wirtualnych, które są udostępniane bezpłatnie. W tej wersji możesz wybrać rozmiar maszyny wirtualnej zookeeper, który jest najbardziej odpowiedni dla danego scenariusza. Za węzły zookeeper o rozmiarze maszyny wirtualnej inne niż A2_v2/A2 będą naliczane opłaty. maszyny wirtualne A2_v2 i A2 są nadal dostępne bezpłatnie.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Począwszy od tej wersji, usługa będzie stopniowo migrowana do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Wycofanie
Wycofanie klastra usług HDInsight 3.6 ML
Typ klastra usług ML w usłudze HDInsight 3.6 zostanie zakończony do 31 grudnia 2020 r. Klienci nie będą mogli tworzyć nowych klastrów usług ML 3.6 po 31 grudnia 2020 r. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Sprawdź wygaśnięcie pomocy technicznej dla wersji i typów klastrów usługi HDInsight tutaj.
Wyłączone rozmiary maszyn wirtualnych
Od 16 listopada 2020 r. usługa HDInsight zablokuje nowym klientom tworzenie klastrów przy użyciu standand_A8, standand_A9, standand_A10 i standand_A11 rozmiarów maszyn wirtualnych. Nie będzie to miało wpływu na istniejących klientów, którzy korzystali z tych rozmiarów maszyn wirtualnych w ciągu ostatnich trzech miesięcy. Od 9 stycznia 2021 r. usługa HDInsight zablokuje wszystkim klientom tworzenie klastrów przy użyciu standand_A8, standand_A9, standand_A10 i rozmiarów maszyn wirtualnych standand_A11. Istniejące klastry będą działać w następujący sposób. Rozważ przejście do usługi HDInsight 4.0, aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zmiany zachowania
Dodawanie sprawdzania reguł sieciowej grupy zabezpieczeń przed operacją skalowania
Usługa HDInsight dodała sieciowe grupy zabezpieczeń (NSG) i trasy zdefiniowane przez użytkownika (UDR) sprawdzające operację skalowania. Ta sama walidacja jest wykonywana w przypadku skalowania klastra poza tworzeniem klastra. Ta walidacja pomaga zapobiegać nieprzewidywalnym błędom. Jeśli walidacja nie zostanie przekazana, skalowanie zakończy się niepowodzeniem. Dowiedz się więcej na temat prawidłowego konfigurowania sieciowych grup zabezpieczeń i tras zdefiniowanych przez użytkownika, zapoznaj się z adresami IP zarządzania usługi HDInsight.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 11.09.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Usługa HDInsight Identity Broker (HIB) jest teraz ogólnie dostępna
Usługa HDInsight Identity Broker (HIB), która umożliwia uwierzytelnianie OAuth dla klastrów ESP, jest teraz ogólnie dostępna w tej wersji. Klastry HIB utworzone po tej wersji będą miały najnowsze funkcje HIB:
- Wysoka dostępność (HA)
- Obsługa uwierzytelniania wieloskładnikowego (MFA)
- Użytkownicy federacyjni logują się bez synchronizacji skrótów haseł w usłudze AAD-DS Aby uzyskać więcej informacji, zobacz dokumentację HIB.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Począwszy od tej wersji, usługa będzie stopniowo migrowana do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Wycofanie
Wycofanie klastra usług HDInsight 3.6 ML
Typ klastra usług ML w usłudze HDInsight 3.6 zostanie zakończony do 31 grudnia 2020 r. Klienci nie będą tworzyć nowych klastrów usług ML 3.6 po 31 grudnia 2020 r. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Sprawdź wygaśnięcie pomocy technicznej dla wersji i typów klastrów usługi HDInsight tutaj.
Wyłączone rozmiary maszyn wirtualnych
Od 16 listopada 2020 r. usługa HDInsight zablokuje nowym klientom tworzenie klastrów przy użyciu standand_A8, standand_A9, standand_A10 i standand_A11 rozmiarów maszyn wirtualnych. Nie będzie to miało wpływu na istniejących klientów, którzy korzystali z tych rozmiarów maszyn wirtualnych w ciągu ostatnich trzech miesięcy. Od 9 stycznia 2021 r. usługa HDInsight zablokuje wszystkim klientom tworzenie klastrów przy użyciu standand_A8, standand_A9, standand_A10 i rozmiarów maszyn wirtualnych standand_A11. Istniejące klastry będą działać w następujący sposób. Rozważ przejście do usługi HDInsight 4.0, aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zmiany zachowania
Brak zmian zachowania dla tej wersji.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Możliwość wybierania różnych rozmiarów maszyn wirtualnych usługi Zookeeper dla usług Spark, Hadoop i ML
Obecnie usługa HDInsight nie obsługuje dostosowywania rozmiaru węzła zookeeper dla typów klastrów spark, Hadoop i ML Services. Domyślnie A2_v2/A2 rozmiary maszyn wirtualnych, które są udostępniane bezpłatnie. W nadchodzącej wersji możesz wybrać rozmiar maszyny wirtualnej zookeeper, który jest najbardziej odpowiedni dla danego scenariusza. Za węzły zookeeper o rozmiarze maszyny wirtualnej inne niż A2_v2/A2 będą naliczane opłaty. maszyny wirtualne A2_v2 i A2 są nadal dostępne bezpłatnie.
Domyślna wersja klastra zostanie zmieniona na 4.0
Od lutego 2021 r. domyślna wersja klastra usługi HDInsight zostanie zmieniona z 3.6 na 4.0. Aby uzyskać więcej informacji na temat dostępnych wersji, zobacz obsługiwane wersje. Dowiedz się więcej o nowościach w usłudze HDInsight 4.0
Zakończenie wsparcia w usłudze HDInsight 3.6 w dniu 30 czerwca 2021 r.
Wsparcie dla usługi HDInsight 3.6 zostanie zakończone. Od 30 czerwca 2021 r. klienci nie mogą tworzyć nowych klastrów usługi HDInsight 3.6. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście do usługi HDInsight 4.0, aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Rozwiązano problem z ponownym uruchamianiem maszyn wirtualnych w klastrze
Problem z ponownym uruchamianiem maszyn wirtualnych w klastrze został rozwiązany. Aby ponownie uruchomić węzły w klastrze, można użyć programu PowerShell lub interfejsu API REST.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 10.08.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Klastry prywatne usługi HDInsight bez publicznego adresu IP i łącza prywatnego (wersja zapoznawcza)
Usługa HDInsight obsługuje teraz tworzenie klastrów bez publicznego adresu IP i dostępu łącza prywatnego do klastrów w wersji zapoznawczej. Klienci mogą używać nowych zaawansowanych ustawień sieci do tworzenia w pełni izolowanego klastra bez publicznego adresu IP i używania własnych prywatnych punktów końcowych w celu uzyskania dostępu do klastra.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Począwszy od tej wersji, usługa będzie stopniowo migrowana do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Wycofanie
Wycofanie klastra usług HDInsight 3.6 ML
Typ klastra usług ML w usłudze HDInsight 3.6 zostanie zakończony do 31 grudnia 2020 r. Po tym klienci nie będą tworzyć nowych klastrów usług ML w wersji 3.6. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Sprawdź wygaśnięcie pomocy technicznej dla wersji i typów klastrów usługi HDInsight tutaj.
Zmiany zachowania
Brak zmian zachowania dla tej wersji.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Możliwość wybierania różnych rozmiarów maszyn wirtualnych usługi Zookeeper dla usług Spark, Hadoop i ML
Obecnie usługa HDInsight nie obsługuje dostosowywania rozmiaru węzła zookeeper dla typów klastrów spark, Hadoop i ML Services. Domyślnie A2_v2/A2 rozmiary maszyn wirtualnych, które są udostępniane bezpłatnie. W nadchodzącej wersji możesz wybrać rozmiar maszyny wirtualnej zookeeper, który jest najbardziej odpowiedni dla danego scenariusza. Za węzły zookeeper o rozmiarze maszyny wirtualnej inne niż A2_v2/A2 będą naliczane opłaty. maszyny wirtualne A2_v2 i A2 są nadal dostępne bezpłatnie.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 28.09.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Automatyczne skalowanie zapytań interakcyjnych w usłudze HDInsight 4.0 jest teraz ogólnie dostępne
Automatyczne skalowanie dla typu klastra interakcyjnego zapytania jest teraz ogólnie dostępne dla usługi HDInsight 4.0. Wszystkie klastry Interactive Query 4.0 utworzone po 27 sierpnia 2020 r. będą obsługiwać automatyczne skalowanie.
Klaster HBase obsługuje usługę ADLS Gen2 w warstwie Premium
Usługa HDInsight obsługuje teraz usługę Premium ADLS Gen2 jako podstawowe konto magazynu dla klastrów HBase 3.6 i 4.0 usługi HDInsight. Wraz z przyspieszonymi zapisami można uzyskać lepszą wydajność klastrów HBase.
Dystrybucja partycji platformy Kafka w domenach błędów platformy Azure
Domena błędów to logiczna grupa bazowego sprzętu w centrum danych platformy Azure. Wszystkie domeny błędów korzystają ze wspólnego źródła zasilania i przełącznika sieciowego. Przed usługą HDInsight kafka może przechowywać wszystkie repliki partycji w tej samej domenie błędów. Począwszy od tej wersji, usługa HDInsight obsługuje teraz automatyczną dystrybucję partycji platformy Kafka na podstawie domen błędów platformy Azure.
Szyfrowanie podczas transferu
Klienci mogą włączyć szyfrowanie podczas przesyłania między węzłami klastra przy użyciu szyfrowania IPSec z kluczami zarządzanymi przez platformę. Tę opcję można włączyć w czasie tworzenia klastra. Zobacz więcej szczegółów na temat włączania szyfrowania podczas przesyłania.
Szyfrowanie na hoście
Po włączeniu szyfrowania na hoście dane przechowywane na hoście maszyny wirtualnej są szyfrowane w stanie spoczynku i przepływy szyfrowane do usługi magazynu. W tej wersji można włączyć szyfrowanie na hoście na dysku danych tymczasowych podczas tworzenia klastra. Szyfrowanie na hoście jest obsługiwane tylko w niektórych jednostkach SKU maszyn wirtualnych w ograniczonych regionach. Usługa HDInsight obsługuje następującą konfigurację węzła i jednostki SKU. Zobacz więcej szczegółów na temat włączania szyfrowania na hoście.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Począwszy od tej wersji, usługa będzie stopniowo migrowana do zestawów skalowania maszyn wirtualnych platformy Azure. Cały proces może potrwać miesiące. Po przeprowadzeniu migracji regionów i subskrypcji nowo utworzone klastry usługi HDInsight będą uruchamiane w zestawach skalowania maszyn wirtualnych bez akcji klienta. Nie oczekuje się żadnych zmian powodujących niezgodność.
Wycofanie
Brak wycofania tej wersji.
Zmiany zachowania
Brak zmian zachowania dla tej wersji.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Możliwość wybierania innej jednostki SKU usługi Zookeeper dla usług Spark, Hadoop i ML
Obecnie usługa HDInsight nie obsługuje zmieniania typu klastra usługi Zookeeper dla typów klastrów spark, Hadoop i ML Services. Używa A2_v2/A2 jednostki SKU dla węzłów usługi Zookeeper, a klienci nie są za nie naliczani opłat. W nadchodzącej wersji klienci mogą w razie potrzeby zmieniać jednostkę SKU usługi Zookeeper dla platform Spark, Hadoop i ML. Za węzły dozorców z jednostkami SKU innymi niż A2_v2/A2 będą naliczane opłaty. Domyślna jednostka SKU będzie nadal A2_V2/A2 i bezpłatnie.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 08.09.2020
Ta wersja dotyczy tylko usługi HDInsight 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Obsługa usługi SparkCruise
SparkCruise to automatyczny system ponownego użycia obliczeń dla platformy Spark. Wybiera typowe podwyrażenia, aby zmaterializować się na podstawie poprzedniego obciążenia zapytania. SparkCruise materializuje te podrażenia w ramach przetwarzania zapytań i ponownego użycia obliczeń jest automatycznie stosowane w tle. Możesz skorzystać z usługi SparkCruise bez żadnych modyfikacji kodu platformy Spark.
Obsługa widoku Hive dla usługi HDInsight 4.0
Widok hive apache Ambari został zaprojektowany tak, aby ułatwić tworzenie, optymalizowanie i wykonywanie zapytań Hive z przeglądarki internetowej. Widok Hive jest obsługiwany natywnie dla klastrów usługi HDInsight 4.0, począwszy od tej wersji. Nie ma zastosowania do istniejących klastrów. Aby uzyskać wbudowany widok Programu Hive, należy usunąć i ponownie utworzyć klaster.
Obsługa widoku Tez dla usługi HDInsight 4.0
Widok Apache Tez służy do śledzenia i debugowania wykonywania zadania Hive Tez. Widok Tez jest obsługiwany natywnie dla usługi HDInsight 4.0, począwszy od tej wersji. Nie ma zastosowania do istniejących klastrów. Aby uzyskać wbudowany widok Tez, należy usunąć i ponownie utworzyć klaster.
Wycofanie
Zakończenie obsługi platformy Spark 2.1 i 2.2 w klastrze platformy Spark w usłudze HDInsight 3.6
Od 1 lipca 2020 r. klienci nie mogą tworzyć nowych klastrów Spark z platformą Spark w wersji 2.1 i 2.2 w usłudze HDInsight 3.6. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.3 w usłudze HDInsight 3.6 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zakończenie obsługi platformy Spark 2.3 w klastrze platformy Spark w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie mogą tworzyć nowych klastrów Spark przy użyciu platformy Spark 2.3 w usłudze HDInsight 4.0. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.4 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zakończenie obsługi platformy Kafka 1.1 w klastrze platformy Kafka w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie będą mogli tworzyć nowych klastrów platformy Kafka przy użyciu platformy Kafka 1.1 w usłudze HDInsight 4.0. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Kafka 2.1 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zmiany zachowania
Zmiana wersji stosu systemu Ambari
W tej wersji wersja systemu Ambari zmienia się z wersji 2.x.x.x.x na 4.1. Wersję stosu (HDInsight 4.1) można sprawdzić w systemie Ambari: Wersje użytkowników > systemu Ambari>.
Nadchodzące zmiany
Brak nadchodzących zmian powodujących niezgodność, do których należy zwrócić uwagę.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Poniżej umów JIRA są z powrotem portowane dla programu Hive:
Poniżej umów JIRA są z powrotem portowane dla bazy danych HBase:
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Znane problemy
Rozwiązano problem w witrynie Azure Portal, w którym użytkownicy napotykali błąd podczas tworzenia klastra usługi Azure HDInsight przy użyciu typu uwierzytelniania SSH klucza publicznego. Po kliknięciu przycisku Przejrzyj i utwórz zostanie wyświetlony błąd "Nie może zawierać żadnych trzech kolejnych znaków z nazwy użytkownika SSH". Ten problem został rozwiązany, ale może wymagać odświeżenia pamięci podręcznej przeglądarki, naciskając CTRL + F5, aby załadować poprawiony widok. Obejście tego problemu było utworzeniu klastra przy użyciu szablonu usługi ARM.
Data wydania: 13.07.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Obsługa skrytki klienta dla platformy Microsoft Azure
Usługa Azure HDInsight obsługuje teraz usługę Azure Customer Lockbox. Udostępnia interfejs umożliwiający klientom przeglądanie i zatwierdzanie lub odrzucanie żądań dostępu do danych klientów. Jest on używany, gdy inżynier firmy Microsoft musi uzyskać dostęp do danych klienta podczas żądania pomocy technicznej. Aby uzyskać więcej informacji, zobacz Blokada klienta dla platformy Microsoft Azure.
Zasady punktu końcowego usługi dla magazynu
Klienci mogą teraz używać zasad punktu końcowego usługi (SEP) w podsieci klastra usługi HDInsight. Dowiedz się więcej o zasadach punktu końcowego usługi platformy Azure.
Wycofanie
Zakończenie obsługi platformy Spark 2.1 i 2.2 w klastrze platformy Spark w usłudze HDInsight 3.6
Od 1 lipca 2020 r. klienci nie mogą tworzyć nowych klastrów Spark z platformą Spark w wersji 2.1 i 2.2 w usłudze HDInsight 3.6. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.3 w usłudze HDInsight 3.6 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zakończenie obsługi platformy Spark 2.3 w klastrze platformy Spark w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie mogą tworzyć nowych klastrów Spark przy użyciu platformy Spark 2.3 w usłudze HDInsight 4.0. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.4 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zakończenie obsługi platformy Kafka 1.1 w klastrze platformy Kafka w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie będą mogli tworzyć nowych klastrów platformy Kafka przy użyciu platformy Kafka 1.1 w usłudze HDInsight 4.0. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Kafka 2.1 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zmiany zachowania
Nie trzeba zwracać uwagi na żadne zmiany zachowania.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Możliwość wybierania innej jednostki SKU usługi Zookeeper dla usług Spark, Hadoop i ML
Obecnie usługa HDInsight nie obsługuje zmieniania typu klastra usługi Zookeeper dla typów klastrów spark, Hadoop i ML Services. Używa A2_v2/A2 jednostki SKU dla węzłów usługi Zookeeper, a klienci nie są za nie naliczani opłat. W nadchodzącej wersji klienci będą mogli w razie potrzeby zmienić jednostkę SKU usługi Zookeeper dla platform Spark, Hadoop i ML. Za węzły dozorców z jednostkami SKU innymi niż A2_v2/A2 będą naliczane opłaty. Domyślna jednostka SKU będzie nadal A2_V2/A2 i bezpłatnie.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Rozwiązano problem z łącznikiem magazynu Hive
Wystąpił problem z użytecznością łącznika usługi Hive Warehouse w poprzedniej wersji. Problem został rozwiązany.
Rozwiązano problem z obcięciem notesu Zeppelin zerami wiodącymi
Zeppelin niepoprawnie obcinał zera wiodące w danych wyjściowych tabeli dla formatu ciągu. Rozwiązaliśmy ten problem w tej wersji.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć w tym dokumentie.
Data wydania: 11.06.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa maszyn wirtualnych platformy Azure do aprowizacji klastra. W tej wersji nowo utworzone klastry usługi HDInsight zaczynają korzystać z zestawu skalowania maszyn wirtualnych platformy Azure. Zmiana jest wdrażana stopniowo. Nie należy oczekiwać żadnych zmian powodujących niezgodność. Zobacz więcej na temat zestawów skalowania maszyn wirtualnych platformy Azure.
Ponowne uruchamianie maszyn wirtualnych w klastrze usługi HDInsight
W tej wersji obsługujemy ponowne uruchamianie maszyn wirtualnych w klastrze usługi HDInsight w celu ponownego uruchomienia węzłów, które nie odpowiadają. Obecnie można to zrobić tylko za pośrednictwem interfejsu API, programu PowerShell i interfejsu wiersza polecenia jest w drodze. Aby uzyskać więcej informacji na temat interfejsu API, zobacz ten dokument.
Wycofanie
Zakończenie obsługi platformy Spark 2.1 i 2.2 w klastrze platformy Spark w usłudze HDInsight 3.6
Od 1 lipca 2020 r. klienci nie mogą tworzyć nowych klastrów Spark z platformą Spark w wersji 2.1 i 2.2 w usłudze HDInsight 3.6. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.3 w usłudze HDInsight 3.6 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu/pomocy technicznej.
Zakończenie obsługi platformy Spark 2.3 w klastrze platformy Spark w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie mogą tworzyć nowych klastrów Spark przy użyciu platformy Spark 2.3 w usłudze HDInsight 4.0. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.4 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zakończenie obsługi platformy Kafka 1.1 w klastrze platformy Kafka w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie będą mogli tworzyć nowych klastrów platformy Kafka przy użyciu platformy Kafka 1.1 w usłudze HDInsight 4.0. Istniejące klastry będą działać bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Kafka 2.1 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zmiany zachowania
Zmiana rozmiaru węzła głównego klastra SPARK ESP
Minimalny dozwolony rozmiar węzła głównego klastra ESP Spark został zmieniony na Standard_D13_V2. Maszyny wirtualne z niskimi rdzeniami i pamięcią jako węzeł główny mogą powodować problemy z klastrem ESP z powodu stosunkowo niskiej pojemności procesora CPU i pamięci. Począwszy od wydania, użyj jednostek SKU wyższych niż Standard_D13_V2 i Standard_E16_V3 jako węzła głównego dla klastrów ESP Spark.
Minimalna 4-rdzeniowa maszyna wirtualna jest wymagana dla węzła głównego
Minimalna 4-rdzeniowa maszyna wirtualna jest wymagana dla węzła głównego, aby zapewnić wysoką dostępność i niezawodność klastrów usługi HDInsight. Od 6 kwietnia 2020 r. klienci mogą wybrać tylko 4-rdzeniową lub nowszą maszynę wirtualną jako węzeł główny dla nowych klastrów usługi HDInsight. Istniejące klastry będą nadal działać zgodnie z oczekiwaniami.
Zmiana aprowizacji węzła procesu roboczego klastra
Gdy 80% węzłów roboczych jest gotowych, klaster przechodzi do etapu operacyjnego . Na tym etapie klienci mogą wykonywać wszystkie operacje płaszczyzny danych, takie jak uruchamianie skryptów i zadań. Klienci nie mogą jednak wykonywać żadnych operacji płaszczyzny sterowania, takich jak skalowanie w górę/w dół. Obsługiwane jest tylko usunięcie.
Po etapie operacyjnym klaster czeka kolejne 60 minut na pozostałe 20% węzłów roboczych. Na koniec tego 60-minutowego okresu klaster przechodzi do etapu uruchamiania , nawet jeśli wszystkie węzły robocze są nadal niedostępne. Gdy klaster wejdzie do uruchomionego etapu, możesz użyć go w zwykły sposób. Operacje planu sterowania, takie jak skalowanie w górę/w dół, oraz operacje planu danych, takie jak uruchamianie skryptów i zadań, są akceptowane. Jeśli niektóre żądane węzły robocze nie są dostępne, klaster zostanie oznaczony jako częściowy sukces. Opłaty są naliczane za węzły, które zostały pomyślnie wdrożone.
Tworzenie nowej jednostki usługi za pomocą usługi HDInsight
Wcześniej podczas tworzenia klastra klienci mogą utworzyć nową jednostkę usługi w celu uzyskania dostępu do połączonego konta usługi ADLS Gen 1 w witrynie Azure Portal. Od 15 czerwca 2020 r. nowe tworzenie jednostki usługi nie jest możliwe w przepływie pracy tworzenia usługi HDInsight, obsługiwana jest tylko istniejąca jednostka usługi. Zobacz Tworzenie jednostki usługi i certyfikatów przy użyciu usługi Azure Active Directory.
Limit czasu akcji skryptu z tworzeniem klastra
Usługa HDInsight obsługuje uruchamianie akcji skryptu z tworzeniem klastra. W tej wersji wszystkie akcje skryptu z tworzeniem klastra muszą zakończyć się w ciągu 60 minut lub upłynął limit czasu. Nie ma to wpływu na akcje skryptu przesłane do uruchomionych klastrów. Dowiedz się więcej tutaj.
Nadchodzące zmiany
Brak nadchodzących zmian powodujących niezgodność, do których należy zwrócić uwagę.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
Baza HBase 2.0 do 2.1.6
Wersja HBase została uaktualniona z wersji 2.0 do wersji 2.1.6.
Spark 2.4.0 do 2.4.4
Wersja platformy Spark została uaktualniona z wersji 2.4.0 do wersji 2.4.4.
Kafka 2.1.0 do 2.1.1
Wersja platformy Kafka została uaktualniona z wersji 2.1.0 do wersji 2.1.1.
Bieżące wersje składników dla usługi HDInsight 4.0 ad HDInsight 3.6 można znaleźć w tym dokumentie
Znane problemy
Problem z łącznikiem magazynu Hive
W tej wersji występuje problem z łącznikiem magazynu Hive. Poprawka zostanie uwzględniona w następnej wersji. Nie ma to wpływu na istniejące klastry utworzone przed tą wersją. Unikaj usuwania i ponownego tworzenia klastra, jeśli to możliwe. Otwórz bilet pomocy technicznej, jeśli potrzebujesz dalszej pomocy dotyczącej tego problemu.
Data wydania: 01.09.2020
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i 4.0. Wydanie usługi HDInsight jest udostępniane wszystkim regionom w ciągu kilku dni. Data wydania w tym miejscu wskazuje datę wydania pierwszego regionu. Jeśli nie widzisz następujących zmian, zaczekaj na udostępnienie wersji w twoim regionie w ciągu kilku dni.
Nowe funkcje
Wymuszanie protokołu TLS 1.2
Transport Layer Security (TLS) i Secure Sockets Layer (SSL) to protokoły kryptograficzne, które zapewniają zabezpieczenia komunikacji za pośrednictwem sieci komputerowej. Dowiedz się więcej o protokole TLS. Usługa HDInsight używa protokołu TLS 1.2 w publicznych punktach końcowych PROTOKOŁU HTTP, ale protokół TLS 1.1 jest nadal obsługiwany w celu zapewnienia zgodności z poprzednimi wersjami.
W tej wersji klienci mogą zdecydować się na protokół TLS 1.2 tylko dla wszystkich połączeń za pośrednictwem publicznego punktu końcowego klastra. W tym celu wprowadzono nową właściwość minSupportedTlsVersion i można je określić podczas tworzenia klastra. Jeśli właściwość nie jest ustawiona, klaster nadal obsługuje protokoły TLS 1.0, 1.1 i 1.2, co jest takie samo jak dzisiejsze zachowanie. Klienci mogą ustawić wartość dla tej właściwości na wartość "1.2", co oznacza, że klaster obsługuje tylko protokół TLS 1.2 i nowsze. Aby uzyskać więcej informacji, zobacz Transport Layer Security.
Korzystanie z własnego klucza na potrzeby szyfrowania dysków
Wszystkie dyski zarządzane w usłudze HDInsight są chronione za pomocą szyfrowania usługi Azure Storage (SSE). Dane na tych dyskach są domyślnie szyfrowane przez klucze zarządzane przez firmę Microsoft. Począwszy od tej wersji, możesz użyć funkcji Bring Your Own Key (BYOK) na potrzeby szyfrowania dysków i zarządzania nim przy użyciu usługi Azure Key Vault. Szyfrowanie BYOK to jednoetapowa konfiguracja podczas tworzenia klastra bez innych kosztów. Wystarczy zarejestrować usługę HDInsight jako tożsamość zarządzaną w usłudze Azure Key Vault i dodać klucz szyfrowania podczas tworzenia klastra. Aby uzyskać więcej informacji, zobacz Szyfrowanie dysków klucza zarządzanego przez klienta.
Wycofanie
Brak wycofań dla tej wersji. Aby przygotować się do zbliżających się wycofań, zobacz Nadchodzące zmiany.
Zmiany zachowania
Brak zmian zachowania dla tej wersji. Aby przygotować się do nadchodzących zmian, zobacz Nadchodzące zmiany.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Zakończenie obsługi platformy Spark 2.1 i 2.2 w klastrze platformy Spark w usłudze HDInsight 3.6
Od 1 lipca 2020 r. klienci nie będą mogli tworzyć nowych klastrów Spark przy użyciu platformy Spark 2.1 i 2.2 w usłudze HDInsight 3.6. Istniejące klastry będą działać w obecnym stanie bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.3 w usłudze HDInsight 3.6 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zakończenie obsługi platformy Spark 2.3 w klastrze platformy Spark w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie będą mogli tworzyć nowych klastrów Spark przy użyciu platformy Spark 2.3 w usłudze HDInsight 4.0. Istniejące klastry będą działać w obecnym stanie bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Spark 2.4 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej.
Zakończenie obsługi platformy Kafka 1.1 w klastrze platformy Kafka w usłudze HDInsight 4.0
Od 1 lipca 2020 r. klienci nie będą mogli tworzyć nowych klastrów platformy Kafka przy użyciu platformy Kafka 1.1 w usłudze HDInsight 4.0. Istniejące klastry będą działać w obecnym stanie bez pomocy technicznej firmy Microsoft. Rozważ przejście na platformę Kafka 2.1 w usłudze HDInsight 4.0 do 30 czerwca 2020 r., aby uniknąć potencjalnych przerw w działaniu systemu lub pomocy technicznej. Aby uzyskać więcej informacji, zobacz Migrowanie obciążeń platformy Apache Kafka do usługi Azure HDInsight 4.0.
Baza HBase 2.0 do 2.1.6
W nadchodzącej wersji usługi HDInsight 4.0 baza HBase zostanie uaktualniona z wersji 2.0 do wersji 2.1.6
Spark 2.4.0 do 2.4.4
W nadchodzącej wersji usługi HDInsight 4.0 platforma Spark zostanie uaktualniona z wersji 2.4.0 do wersji 2.4.4.4
Kafka 2.1.0 do 2.1.1
W nadchodzącej wersji usługi HDInsight 4.0 platforma Kafka zostanie uaktualniona z wersji 2.1.0 do wersji 2.1.1.1
Minimalna 4-rdzeniowa maszyna wirtualna jest wymagana dla węzła głównego
Minimalna 4-rdzeniowa maszyna wirtualna jest wymagana dla węzła głównego, aby zapewnić wysoką dostępność i niezawodność klastrów usługi HDInsight. Od 6 kwietnia 2020 r. klienci mogą wybrać tylko 4-rdzeniową lub nowszą maszynę wirtualną jako węzeł główny dla nowych klastrów usługi HDInsight. Istniejące klastry będą nadal działać zgodnie z oczekiwaniami.
Zmiana rozmiaru węzła klastra ESP Spark
W nadchodzącej wersji minimalny dozwolony rozmiar węzła dla klastra ESP Spark zostanie zmieniony na Standard_D13_V2. Maszyny wirtualne serii A mogą powodować problemy z klastrem ESP ze względu na stosunkowo małą pojemność procesora CPU i pamięci. Maszyny wirtualne serii A zostaną wycofane do tworzenia nowych klastrów ESP.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. W nadchodzącej wersji usługa HDInsight będzie używać zestawów skalowania maszyn wirtualnych platformy Azure. Zobacz więcej na temat zestawów skalowania maszyn wirtualnych platformy Azure.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
Brak zmiany wersji składnika dla tej wersji. Bieżące wersje składników dla usługi HDInsight 4.0 ad HDInsight 3.6 można znaleźć tutaj.
Data wydania: 12.017.2019
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i 4.0.
Nowe funkcje
Tagi usługi
Tagi usług upraszczają zabezpieczenia maszyn wirtualnych platformy Azure i sieci wirtualnych platformy Azure, umożliwiając łatwe ograniczanie dostępu sieciowego do usług platformy Azure. Tagi usług można używać w regułach sieciowej grupy zabezpieczeń(NSG), aby zezwalać na ruch do określonej usługi platformy Azure lub blokować go globalnie lub w poszczególnych regionach świadczenia usługi platformy Azure. Platforma Azure zapewnia konserwację adresów IP bazowych dla każdego tagu. Tagi usługi HDInsight dla sieciowych grup zabezpieczeń to grupy adresów IP dla usług kondycji i zarządzania. Grupy te pomagają zminimalizować złożoność tworzenia reguł zabezpieczeń. Klienci usługi HDInsight mogą włączyć tag usługi za pośrednictwem witryny Azure Portal, programu PowerShell i interfejsu API REST. Aby uzyskać więcej informacji, zobacz Network security group (NSG) service tags for Azure HDInsight (Network security group, NSG) tags for Azure HDInsight (Sieciowe grupy zabezpieczeń tagi usługi dla usługi Azure HDInsight).
Niestandardowa baza danych Ambari
Usługa HDInsight umożliwia teraz korzystanie z własnej bazy danych SQL dla systemu Apache Ambari. Tę niestandardową bazę danych Ambari można skonfigurować w witrynie Azure Portal lub za pośrednictwem szablonu usługi Resource Manager. Ta funkcja umożliwia wybranie odpowiedniej bazy danych SQL dla potrzeb związanych z przetwarzaniem i pojemnością. Możesz również łatwo uaktualnić, aby dopasować wymagania dotyczące wzrostu biznesowego. Aby uzyskać więcej informacji, zobacz Konfigurowanie klastrów usługi HDInsight przy użyciu niestandardowej bazy danych Ambari.

Wycofanie
Brak wycofań dla tej wersji. Aby przygotować się do zbliżających się wycofań, zobacz Nadchodzące zmiany.
Zmiany zachowania
Brak zmian zachowania dla tej wersji. Aby przygotować się do nadchodzących zmian zachowania, zobacz Nadchodzące zmiany.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Wymuszanie protokołu Transport Layer Security (TLS) 1.2
Transport Layer Security (TLS) i Secure Sockets Layer (SSL) to protokoły kryptograficzne, które zapewniają zabezpieczenia komunikacji za pośrednictwem sieci komputerowej. Aby uzyskać więcej informacji, zobacz Transport Layer Security. Chociaż klastry usługi Azure HDInsight akceptują połączenia TLS 1.2 w publicznych punktach końcowych HTTPS, protokół TLS 1.1 jest nadal obsługiwany w celu zapewnienia zgodności z poprzednimi wersjami ze starszymi klientami.
Począwszy od następnej wersji, będzie można wyrazić zgodę i skonfigurować nowe klastry usługi HDInsight tak, aby akceptowały tylko połączenia TLS 1.2.
W dalszej części roku, począwszy od 30.06.2020 r., usługa Azure HDInsight będzie wymuszać protokół TLS 1.2 lub nowsze wersje dla wszystkich połączeń HTTPS. Zalecamy, aby upewnić się, że wszyscy klienci są gotowi do obsługi protokołu TLS 1.2 lub jego nowszych wersji.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Począwszy od lutego 2020 r. (dokładna data zostanie przekazana później), usługa HDInsight użyje zamiast tego zestawów skalowania maszyn wirtualnych platformy Azure. Zobacz więcej na temat zestawów skalowania maszyn wirtualnych platformy Azure.
Zmiana rozmiaru węzła klastra ESP Spark
W nadchodzącej wersji:
- Minimalny dozwolony rozmiar węzła dla klastra ESP Spark zostanie zmieniony na Standard_D13_V2.
- Maszyny wirtualne serii A zostaną wycofane w celu utworzenia nowych klastrów ESP, ponieważ maszyny wirtualne serii A mogą powodować problemy z klastrem ESP ze względu na stosunkowo małą pojemność procesora CPU i pamięci.
Baza HBase 2.0 do 2.1
W nadchodzącej wersji usługi HDInsight 4.0 baza HBase zostanie uaktualniona z wersji 2.0 do 2.1.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
Rozszerzono obsługę usługi HDInsight 3.6 do 31 grudnia 2020 r. Więcej szczegółów można znaleźć w temacie Obsługiwane wersje usługi HDInsight.
Brak zmiany wersji składnika dla usługi HDInsight 4.0.
Apache Zeppelin w usłudze HDInsight 3.6: 0.7.0-->0.7.3.
Z tego dokumentu można znaleźć najbardziej aktualne wersje składników.
Nowe regiony
Północne Zjednoczone Emiraty Arabskie
Adresy IP zarządzania ze Zjednoczonych Emiratów Zjednoczonych Emiratów Zjednoczonych to: 65.52.252.96 i 65.52.252.97.
Data wydania: 11.07.2019
Ta wersja dotyczy zarówno usług HDInsight 3.6, jak i 4.0.
Nowe funkcje
HDInsight Identity Broker (HIB) (wersja zapoznawcza)
Usługa HDInsight Identity Broker (HIB) umożliwia użytkownikom logowanie się do systemu Apache Ambari przy użyciu uwierzytelniania wieloskładnikowego (MFA) i uzyskiwanie wymaganych biletów protokołu Kerberos bez konieczności używania skrótów haseł w usługach Azure domena usługi Active Directory Services (AAD-DS). Obecnie HIB jest dostępna tylko dla klastrów wdrożonych za pośrednictwem szablonu usługi Azure Resource Management (ARM).
Serwer proxy interfejsu API REST platformy Kafka (wersja zapoznawcza)
Serwer proxy interfejsu API REST platformy Kafka zapewnia jedno kliknięcie wdrożenia serwera proxy REST o wysokiej dostępności z klastrem Kafka za pośrednictwem zabezpieczonej autoryzacji usługi Azure AD i protokołu OAuth.
Automatyczne skalowanie
Automatyczne skalowanie dla usługi Azure HDInsight jest teraz ogólnie dostępne we wszystkich regionach dla typów klastrów Apache Spark i Hadoop. Ta funkcja umożliwia zarządzanie obciążeniami analizy danych big data w bardziej ekonomiczny i wydajny sposób. Teraz możesz zoptymalizować korzystanie z klastrów usługi HDInsight i płacić tylko za potrzebne elementy.
W zależności od wymagań możesz wybierać między automatycznym skalowaniem opartym na obciążeniu i automatycznym skalowaniem opartym na harmonogramie. Skalowanie automatyczne oparte na obciążeniu może skalować rozmiar klastra w górę i w dół na podstawie bieżących potrzeb zasobów, podczas gdy skalowanie automatyczne oparte na harmonogramie może zmieniać rozmiar klastra na podstawie wstępnie zdefiniowanego harmonogramu.
Obsługa automatycznego skalowania dla obciążeń HBase i LLAP jest również publiczna wersja zapoznawcza. Aby uzyskać więcej informacji, zobacz Automatyczne skalowanie klastrów usługi Azure HDInsight.
Przyspieszone zapisy w usłudze HDInsight dla bazy danych Apache HBase
Funkcja przyspieszonych zapisów korzysta z dysków zarządzanych SSD w warstwie Azure Premium w celu zwiększenia wydajności usługi Apache HBase Write Ahead Log (WAL). Aby uzyskać więcej informacji, zobacz Usługa Azure HDInsight — przyspieszone zapisy dla oprogramowania Apache HBase.
Niestandardowa baza danych Ambari
Usługa HDInsight oferuje teraz nową pojemność umożliwiającą klientom korzystanie z własnej bazy danych SQL dla systemu Ambari. Teraz klienci mogą wybrać odpowiednią bazę danych SQL dla systemu Ambari i łatwo ją uaktualnić na podstawie własnych wymagań dotyczących wzrostu biznesowego. Wdrożenie odbywa się przy użyciu szablonu usługi Azure Resource Manager. Aby uzyskać więcej informacji, zobacz Konfigurowanie klastrów usługi HDInsight przy użyciu niestandardowej bazy danych Ambari.
Maszyny wirtualne serii F są teraz dostępne w usłudze HDInsight
Maszyny wirtualne serii F to dobry wybór, aby rozpocząć pracę z usługą HDInsight z wymaganiami dotyczącymi przetwarzania światła. Przy niższej cenie za godzinę seria F jest najlepszą wartością w cenie w portfolio platformy Azure na podstawie jednostki obliczeniowej Platformy Azure (ACU) na procesor wirtualny. Aby uzyskać więcej informacji, zobacz Wybieranie odpowiedniego rozmiaru maszyny wirtualnej dla klastra usługi Azure HDInsight.
Wycofanie
Wycofanie maszyny wirtualnej z serii G
W tej wersji maszyny wirtualne serii G nie są już oferowane w usłudze HDInsight.
Dv1 wycofanie maszyny wirtualnej
W tej wersji korzystanie z Dv1 maszyn wirtualnych z usługą HDInsight jest przestarzałe. Każde żądanie Dv1 klienta zostanie obsłużone Dv2 automatycznie. Nie ma różnicy cen między maszynami wirtualnymi Dv1 i Dv2 .
Zmiany zachowania
Zmiana rozmiaru dysku zarządzanego klastra
Usługa HDInsight zapewnia zarządzane miejsce na dysku w klastrze. W tej wersji rozmiar dysku zarządzanego każdego węzła w nowym utworzonym klastrze zostanie zmieniony na 128 GB.
Nadchodzące zmiany
W nadchodzących wersjach zostaną wprowadzone następujące zmiany.
Przenoszenie do zestawów skalowania maszyn wirtualnych platformy Azure
Usługa HDInsight używa teraz maszyn wirtualnych platformy Azure do aprowizowania klastra. Od grudnia usługa HDInsight będzie używać zestawów skalowania maszyn wirtualnych platformy Azure. Zobacz więcej na temat zestawów skalowania maszyn wirtualnych platformy Azure.
Baza HBase 2.0 do 2.1
W nadchodzącej wersji usługi HDInsight 4.0 baza HBase zostanie uaktualniona z wersji 2.0 do 2.1.
Wycofanie maszyny wirtualnej z serii A dla klastra ESP
Maszyny wirtualne serii A mogą powodować problemy z klastrem ESP ze względu na stosunkowo małą pojemność procesora CPU i pamięci. W nadchodzącej wersji maszyny wirtualne serii A zostaną wycofane do tworzenia nowych klastrów ESP.
Poprawki błędów
Usługa HDInsight nadal poprawia niezawodność i wydajność klastra.
Zmiana wersji składnika
W tej wersji nie ma zmiany wersji składnika. Bieżące wersje składników dla usług HDInsight 4.0 i HDInsight 3.6 można znaleźć tutaj.
Data wydania: 08.07.2019
Wersje składników
Poniżej podano oficjalne wersje apache wszystkich składników usługi HDInsight 4.0. Wymienione składniki to wersje najnowszych wersji stabilnych.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
Nowsze wersje składników apache są czasami powiązane w dystrybucji HDP oprócz wersji wymienionych powyżej. W takim przypadku te nowsze wersje są wymienione w tabeli Technical Previews i nie powinny zastępować wersji składników Apache powyższej listy w środowisku produkcyjnym.
Informacje o poprawce apache
Aby uzyskać więcej informacji na temat poprawek dostępnych w usłudze HDInsight 4.0, zobacz listę poprawek dla każdego produktu w poniższej tabeli.
| Nazwa produktu | Informacje o poprawce |
|---|---|
| Ambari | Informacje o poprawkach systemu Ambari |
| Hadoop | Informacje o poprawkach usługi Hadoop |
| HBase | Informacje o poprawce bazy danych HBase |
| Hive | Ta wersja udostępnia program Hive 3.1.0 bez dodatkowych poprawek apache. |
| Kafka | Ta wersja udostępnia platformę Kafka 1.1.1 bez dodatkowych poprawek apache. |
| Oozie | Informacje o poprawkach Oozie |
| Phoenix | Informacje o poprawkach Phoenix |
| Pig | Informacje o poprawkach pig |
| Ranger | Informacje o poprawkach platformy Ranger |
| platforma Spark | Informacje o poprawkach platformy Spark |
| Sqoop | Ta wersja udostępnia narzędzie Sqoop 1.4.7 bez dodatkowych poprawek apache. |
| Tez | Ta wersja udostępnia tez 0.9.1 bez dodatkowych poprawek apache. |
| Zeppelin | Ta wersja udostępnia program Zeppelin 0.8.0 bez dodatkowych poprawek apache. |
| Dozorca | Informacje o poprawkach dozorców |
Naprawiono typowe luki w zabezpieczeniach i ujawnieniach
Aby uzyskać więcej informacji na temat problemów z zabezpieczeniami rozwiązanych w tej wersji, zobacz Artykuł Hortonworks's Fixed Vulnerabilities and Exposures for HDP 3.0.1 (Stałe luki w zabezpieczeniach i narażenie na zagrożenia dla usługi HDP 3.0.1).
Znane problemy
Replikacja jest uszkodzona dla bezpiecznej bazy danych HBase z instalacją domyślną
W przypadku usługi HDInsight 4.0 wykonaj następujące czynności:
Włącz komunikację między klastrami.
Zaloguj się do aktywnego węzła głównego.
Pobierz skrypt, aby włączyć replikację za pomocą następującego polecenia:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shWpisz polecenie
sudo kinit <domainuser>.Wpisz następujące polecenie, aby uruchomić skrypt:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
W przypadku usługi HDInsight 3.6
Zaloguj się do aktywnego HMaster ZK.
Pobierz skrypt, aby włączyć replikację za pomocą następującego polecenia:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shWpisz polecenie
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Wpisz następujące polecenie:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Usługa Phoenix Sqlline przestaje działać po migracji klastra HBase do usługi HDInsight 4.0
Wykonaj poniższe kroki:
- Upuść następujące tabele Phoenix:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Jeśli nie możesz usunąć żadnej z tabel, uruchom ponownie bazę danych HBase, aby wyczyścić wszystkie połączenia z tabelami.
- Uruchom ponownie polecenie
sqlline.py. Firma Phoenix ponownie utworzy wszystkie tabele, które zostały usunięte w kroku 1. - Wygeneruj ponownie tabele i widoki Phoenix dla danych bazy danych HBase.
Usługa Phoenix Sqlline przestaje działać po replikowaniu metadanych HBase Phoenix z usługi HDInsight 3.6 do 4.0
Wykonaj poniższe kroki:
- Przed wykonaniem replikacji przejdź do docelowego klastra 4.0 i wykonaj polecenie
sqlline.py. To polecenie spowoduje wygenerowanie tabel Phoenix, takich jakSYSTEM.MUTEXiSYSTEM.LOGktóre istnieją tylko w wersji 4.0. - Upuść następujące tabele:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Uruchamianie replikacji bazy danych HBase
Wycofanie
Usługi Apache Storm i ML nie są dostępne w usłudze HDInsight 4.0.
Data wydania: 14.04.2019
Nowe funkcje
Nowe aktualizacje i możliwości należą do następujących kategorii:
Aktualizowanie projektów Hadoop i innych projektów open source — oprócz 1000+ poprawek błędów w ponad 20 projektach typu open source ta aktualizacja zawiera nową wersję platformy Spark (2.3) i platformę Kafka (1.0).
Zaktualizuj program R Server 9.1 do usług Machine Learning Services 9.3 — w tej wersji udostępniamy analitykom danych i inżynierom najlepsze rozwiązania typu open source ulepszone dzięki innowacjom algorytmicznym i łatwości operacji, wszystkim dostępnym w preferowanym języku z szybkością platformy Apache Spark. Ta wersja rozszerza możliwości oferowane w programie R Server z dodatkową obsługą języka Python, co prowadzi do zmiany nazwy klastra z programu R Server na usługi ML.
Obsługa usługi Azure Data Lake Storage Gen2 — HDInsight będzie obsługiwać wersję zapoznawcza usługi Azure Data Lake Storage Gen2. W dostępnych regionach klienci będą mogli wybrać konto usługi ADLS Gen2 jako magazyn podstawowy lub pomocniczy dla klastrów usługi HDInsight.
Aktualizacje pakietu HDInsight Enterprise Security (wersja zapoznawcza) — (wersja zapoznawcza) Obsługa punktów końcowych usługi sieci wirtualnej dla usługi Azure Blob Storage, ADLS Gen1, Azure Cosmos DB i Azure DB.
Wersje składników
Poniżej wymieniono oficjalne wersje apache wszystkich składników usługi HDInsight 3.6. Wszystkie wymienione tutaj składniki to oficjalne wersje platformy Apache z najnowszej stabilnej wersji dostępnej.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Nowsze wersje kilku składników apache są czasami powiązane w dystrybucji HDP oprócz wersji wymienionych powyżej. W takim przypadku te nowsze wersje są wymienione w tabeli Technical Previews i nie powinny zastępować wersji składników Apache powyższej listy w środowisku produkcyjnym.
Informacje o poprawce apache
Hadoop
Ta wersja udostępnia platformę Hadoop Common 2.7.3 i następujące poprawki apache:
HADOOP-13190: Wzmianka o loadBalancingKMSClientProvider w dokumentacji usługi KMS HA.
HADOOP-13227: Program AsyncCallHandler powinien używać architektury sterowanej zdarzeniami do obsługi wywołań asynchronicznych.
HADOOP-14104: Klient powinien zawsze prosić o nazwę węzła dla ścieżki dostawcy kms.
HADOOP-14799: Zaktualizuj nimbus-jose-jwt do wersji 4.41.1.
HADOOP-14814: Napraw niezgodną zmianę interfejsu API na fsServerDefaults na HADOOP-14104.
HADOOP-14903: dodaj jawnie plik json do pom.xml.
HADOOP-15042: Funkcja Azure PageBlobInputStream.skip() może zwracać wartość ujemną, gdy parametr numberOfPagesRemaining wynosi 0.
HADOOP-15255: obsługa konwersji wyższej/dolnej litery dla nazw grup w ldapGroupsMapping.
HADOOP-15265: wyklucz jawnie json-smart z pom.xml hadoop-auth.
HDFS-7922: ShortCircuitCache#close nie zwalnia klasy ScheduledThreadPoolExecutors.
HDFS-8496: Wywoływanie metody stopWriter() z blokadą FSDatasetImpl może blokować inne wątki (cmccabe).
HDFS-10267: Dodatkowe "zsynchronizowane" w fsDatasetImpl#recoverAppend i FsDatasetImpl#recoverClose.
HDFS-10489: Przestarzałe dfs.encryption.key.provider.uri dla stref szyfrowania HDFS.
HDFS-11384: Dodaj opcję dla usługi balancer w celu rozproszenia wywołań getBlocks, aby uniknąć rpc węzła NameNode. Skok CallQueueLength.
HDFS-11689: Nowy wyjątek zgłoszony przez
DFSClient%isHDFSEncryptionEnabledzłamanyhackykod hive.HDFS-11711: Dn nie powinien usuwać bloku Przy "Zbyt wielu otwartych plikach" Wyjątek.
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay często kończy się niepowodzeniem.
HDFS-12781: po
Datanodedół na karcie InterfejsNamenodeDatanodeużytkownika jest zgłaszany komunikat ostrzegawczy.HDFS-13054: Obsługa metody PathIsNotEmptyDirectoryException w
DFSClientwywołaniu usuwania.HDFS-13120: Różnice migawek mogą być uszkodzone po concat.
YARN-3742: YARN RM zostanie zamknięty, jeśli
ZKClientupłynął limit czasu tworzenia.YARN-6061: Dodaj program UncaughtExceptionHandler dla wątków krytycznych w usłudze RM.
YARN-7558: polecenie dzienników yarn nie może pobrać dzienników dla uruchomionych kontenerów, jeśli jest włączone uwierzytelnianie interfejsu użytkownika.
YARN-7697: Pobieranie dzienników dla zakończonej aplikacji kończy się niepowodzeniem, mimo że agregacja dzienników została ukończona.
Usługa HDP 2.6.4 udostępniała platformę Hadoop Common 2.7.3 i następujące poprawki apache:
HADOOP-13700: Usuń unthrown
IOExceptionz TrashPolicy#initialize i #getInstance podpisów.HADOOP-13709: Możliwość czyszczenia podprocesów zduplikowanych przez powłokę po zakończeniu procesu.
HADOOP-14059: błąd zmiany nazwy literówki
s3a(self, subdir).HADOOP-14542: Dodaj interfejs API rejestratora IOUtils.cleanupWithLogger, który akceptuje interfejs API rejestratora slf4j.
HDFS-9887: Limity czasu gniazd WebHdfs powinny być konfigurowalne.
HDFS-9914: Naprawiono konfigurowalny limit czasu łączenia/odczytu webhDFS.
MAPREDUCE-6698: Zwiększ limit czasu dla elementu TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550: Niektóre testy w środowisku TestContainerLanch kończą się niepowodzeniem w środowisku ustawień regionalnych innych niż angielski.
YARN-4717: TestResourceLocalizationService.testPublicResourceInitializesLocalDir przerywa się niepowodzeniem z powodu błędu IllegalArgumentException z czyszczenia.
YARN-5042: Zainstaluj /sys/fs/cgroup w kontenerach platformy Docker jako instalację readonly.
YARN-5318: Naprawiono sporadyczne niepowodzenie testu TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN-5641: Lokalizator pozostawia za tarballs po zakończeniu kontenera.
YARN-6004: Refaktoryzacja TestResourceLocalizationService#testDownloadingResourcesOnContainer, aby było mniej niż 150 wierszy.
YARN-6078: kontenery zablokowane w stanie lokalizowania.
YARN-6805: NPE w systemie LinuxContainerExecutor z powodu wartości null PrivilegedOperationException kodu zakończenia.
HBase
Ta wersja udostępnia program HBase 1.1.2 i następujące poprawki apache.
HBASE-13376: Ulepszenia modułu równoważenia obciążenia Stochastic.
HBASE-13716: Zatrzymaj korzystanie z fsConstants platformy Hadoop.
HBASE-13848: Uzyskiwanie dostępu do haseł SSL serwera InfoServer za pośrednictwem interfejsu API dostawcy poświadczeń.
HBASE-13947: Użyj usługi MasterServices zamiast serwera w narzędziu AssignmentManager.
HBASE-14135: HBase Backup/Restore Phase 3: Merge backup images (Faza 3: Scal obrazy kopii zapasowej).
HBASE-14473: Lokalne regiony obliczeniowe równolegle.
HBASE-14517: Pokaż
regionserver'swersję na stronie stanu wzorca.HBASE-14606: TestySecureLoadIncrementalHFiles upłynął limit czasu w kompilacji magistrali na platformie Apache.
HBASE-15210: Cofanie agresywnego rejestrowania modułu równoważenia obciążenia z dziesiątkami wierszy na milisekundę.
HBASE-15515: Improve LocalityBasedCandidateGenerator in Balancer (Zwiększanie wartości localityBasedCandidateGenerator w usłudze Balancer).
HBASE-15615: Niewłaściwy czas uśpienia, gdy
RegionServerCallabletrzeba ponowić próbę.HBASE-16135: Element PeerClusterZnode pod numerem rs usuniętego elementu równorzędnego nigdy nie może zostać usunięty.
HBASE-16570: Lokalizacja regionu obliczeniowego równolegle podczas uruchamiania.
HBASE-16810: Moduł równoważenia bazy danych HBase zgłasza wyjątek ArrayIndexOutOfBoundsException, gdy
regionserversznajdują się w węźle /hbase/opróżniania węzła znode i zwolnionym.HBASE-16852: TestDefaultCompactSelection nie powiodło się w gałęzi-1.3.
HBASE-17387: Zmniejsz obciążenie raportu wyjątku w regionie RegionActionResult dla funkcji multi().
HBASE-17850: Narzędzie do naprawy systemu kopii zapasowych.
HBASE-17931: Przypisywanie tabel systemowych do serwerów z najwyższą wersją.
HBASE-18083: Ustaw duży/mały plik jako czysty numer wątku konfigurowalny w HFileCleaner.
HBASE-18084: Ulepszanie narzędzia CleanerChore w celu oczyszczenia z katalogu, co zużywa więcej miejsca na dysku.
HBASE-18164: Znacznie szybsza funkcja kosztu lokalnego i generator kandydatów.
HBASE-18212: W trybie autonomicznym z lokalnym systemem plików HBase rejestruje komunikat ostrzegawczy: Nie można wywołać metody "unbuffer" w klasie org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808: Nieskuteczne ewidencjonowanie konfiguracji BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer powinien rozpoznać klasę CellComparatorImpl w gałęzi-1.x.
HBASE-19065: HRegion#bulkLoadHFiles() powinien poczekać na zakończenie współbieżnego regionu#flush().
HBASE-19285: Dodawanie histogramów opóźnień dla tabeli.
HBASE-19393: HTTP 413 FULL head podczas uzyskiwania dostępu do interfejsu użytkownika bazy danych HBase przy użyciu protokołu SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting kończy się niepowodzeniem z serwerem NPE.
HBASE-19421: gałąź-1 nie kompiluje się na platformie Hadoop 3.0.0.
HBASE-19934: HBaseSnapshotException, gdy repliki do odczytu są włączone, a migawka online jest wykonywana po podzieleniu regionu.
HBASE-20008: [backport] NullPointerException podczas przywracania migawki po podzieleniu regionu.
Hive
Ta wersja udostępnia program Hive 1.2.1 i Hive 2.1.0 oprócz następujących poprawek:
Poprawki Programu Hive 1.2.1 Apache:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor wykonuje wadliwą konwersję.
HIVE-11266: count(*) — nieprawidłowy wynik na podstawie statystyk tabeli dla tabel zewnętrznych.
HIVE-12245: obsługa komentarzy kolumn dla tabeli opartej na bazie HBase.
HIVE-12315: Napraw wektoryzowany podwójny podział przez zero.
HIVE-12360: Złe wyszukiwanie w nieskompresowanym ORC z predykatem.
HIVE-12378: Wyjątek w polu binarnym HBaseSerDe.serialize.
HIVE-12785: Widok z typem unii i funkcją UDF do struktury jest uszkodzony.
HIVE-14013: Opis tabeli nie pokazuje poprawnie unicode.
HIVE-14205: Hive nie obsługuje typu unii z formatem pliku AVRO.
HIVE-14421: FS.deleteOnExit przechowuje odwołania do plików _tmp_space.db.
HIVE-15563: Ignoruj wyjątek przejścia stanu nielegalnej operacji w pliku SQLOperation.runQuery, aby uwidocznić rzeczywisty wyjątek.
HIVE-15680: Nieprawidłowe wyniki, gdy hive.optimize.index.filter=true i ta sama tabela ORC jest przywoływana dwa razy w zapytaniu w trybie MR.
HIVE-15883: Tabela mapowana HBase w wstawieniu programu Hive kończy się niepowodzeniem dla liczby dziesiętnej.
HIVE-16232: Obsługa obliczeń statystyk dla kolumn w quotedIdentifier.
HIVE-16828: Po włączeniu funkcji CBO zapytanie w widokach podzielonych na partycje zgłasza wyjątek IndexOutOfBoundException.
HIVE-17013: Żądanie usuwania z podzapytaniem na podstawie wyboru w widoku.
HIVE-17063: wstawianie zastępowania partycji na tabeli zewnętrznej kończy się niepowodzeniem po pierwszym upuszczaniu partycji.
HIVE-17259: Hive JDBC nie rozpoznaje kolumn UNIONTYPE.
HIVE-17419: ANALIZUJ TABELĘ... W poleceniu COMPUTE STATISTICS FOR COLUMNS są wyświetlane obliczone statystyki dla zamaskowanych tabel.
HIVE-17530: KlasaCastException podczas konwertowania
uniontypeelementu .HIVE-17621: Ustawienia lokacji Hive są ignorowane podczas obliczania podziału HCatInputFormat.
HIVE-17636: Dodaj test multiple_agg.q dla elementu
blobstores.HIVE-17729: Dodawanie testów bazy danych i wyjaśnienie powiązanych testów magazynu obiektów blob.
HIVE-17731: dodaj opcję wstecz
compatdla użytkowników zewnętrznych do programu HIVE-11985.HIVE-17803: W przypadku wielu zapytań pig 2 HCatStorers zapisu w tej samej tabeli będzie deptać dane wyjściowe siebie nawzajem.
HIVE-17829: ArrayIndexOutOfBoundsException — tabele oparte na bazie HBASE ze schematem Avro w programie
Hive2.HIVE-17845: wstawianie kończy się niepowodzeniem, jeśli kolumny tabeli docelowej nie są małymi literami.
HIVE-17900: analizowanie statystyk kolumn wyzwalanych przez compactor generuje źle sformułowany kod SQL z 1 kolumną > partycji.
HIVE-18026: Optymalizacja konfiguracji głównej usługi Hive webhcat.
HIVE-18031: obsługa replikacji dla operacji Alter Database.
HIVE-18090: puls kwasu kończy się niepowodzeniem, gdy magazyn metadanych jest połączony za pośrednictwem poświadczeń usługi Hadoop.
HIVE-18189: zapytanie Hive zwraca nieprawidłowe wyniki po ustawieniu wartości hive.groupby.orderby.position.alias na true.
HIVE-18258: Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplikowane kolumny is broken.
HIVE-18293: Program Hive nie kompaktuje tabel zawartych w folderze, który nie jest własnością tożsamości z uruchomionym programem HiveMetaStore.
HIVE-18327: Usuń niepotrzebną zależność HiveConf dla usługi MiniHiveKdc.
HIVE-18341: Dodano obsługę ponownego ładowania w celu dodania "nieprzetworzonej" przestrzeni nazw dla funkcji TDE z tymi samymi kluczami szyfrowania.
HIVE-18352: wprowadzenie opcji METADATAONLY podczas wykonywania zrzutu REPL w celu umożliwienia integracji innych narzędzi.
HIVE-18353: CompactorMR powinien wywołać metodę jobclient.close(), aby wyzwolić czyszczenie.
HIVE-18390: IndexOutOfBoundsException podczas wykonywania zapytań względem widoku partycjonowanego w kolumnie ColumnPruner.
HIVE-18429: Kompaktowanie powinno obsługiwać przypadek, gdy nie generuje żadnych danych wyjściowych.
HIVE-18447: JDBC: umożliwia użytkownikom JDBC przekazywanie informacji o plikach cookie za pośrednictwem parametry połączenia.
HIVE-18460: Kompakt nie przekazuje właściwości tabeli do modułu zapisywania Orc.
HIVE-18467: obsługa całego zrzutu magazynu / ładowania + tworzenia/upuszczania zdarzeń bazy danych (Anishek Agarwal, z recenzją Sankar Hariappan).
HIVE-18551: Wektoryzacja: VectorMapOperator próbuje napisać zbyt wiele kolumn wektorów dla hybrydowej łaski.
HIVE-18587: wstawianie zdarzenia DML może próbować obliczyć sumę kontrolną dla katalogów.
HIVE-18613: Rozszerz JsonSerDe, aby obsługiwać typ BINARNY.
HIVE-18626: Ponowne ładowanie klauzuli "with" nie przekazuje konfiguracji do zadań podrzędnych.
HIVE-18660: PCR nie rozróżnia kolumn partycji i kolumn wirtualnych.
HIVE-18754: STAN REPL powinien obsługiwać klauzulę "with".
HIVE-18754: STAN REPL powinien obsługiwać klauzulę "with".
HIVE-18788: Czyszczenie danych wejściowych w JDBC PreparedStatement.
HIVE-18794: Ponowne ładowanie klauzuli "with" nie przekazuje konfiguracji do zadań dla tabel innych niż partycje.
HIVE-18808: Zwiększenie niezawodności kompaktowania w przypadku niepowodzenia aktualizacji statystyk.
HIVE-18817: Wyjątek ArrayIndexOutOfBounds podczas odczytu tabeli ACID.
HIVE-18833: Automatyczne scalanie kończy się niepowodzeniem podczas "wstawiania do katalogu jako pliku orcfile".
HIVE-18879: Nie zezwalaj na element osadzony w narzędziu UDFXPathUtil musi działać, jeśli xercesImpl.jar w ścieżce klasy.
HIVE-18907: Tworzenie narzędzia w celu rozwiązania problemu z indeksem kluczy kwaśnych z programu HIVE-18817.
Poprawki Apache Hive 2.1.0:
HIVE-14013: Opis tabeli nie pokazuje poprawnie unicode.
HIVE-14205: Hive nie obsługuje typu unii z formatem pliku AVRO.
HIVE-15563: Ignoruj wyjątek przejścia stanu nielegalnej operacji w pliku SQLOperation.runQuery, aby uwidocznić rzeczywisty wyjątek.
HIVE-15680: Nieprawidłowe wyniki, gdy hive.optimize.index.filter=true i ta sama tabela ORC jest przywoływana dwa razy w zapytaniu w trybie MR.
HIVE-15883: Tabela mapowana HBase w wstawieniu programu Hive kończy się niepowodzeniem dla liczby dziesiętnej.
HIVE-16757: Usuń wywołania przestarzałe AbstractRelNode.getRows.
HIVE-16828: Po włączeniu funkcji CBO zapytanie w widokach podzielonych na partycje zgłasza wyjątek IndexOutOfBoundException.
HIVE-17063: wstawianie zastępowania partycji na tabeli zewnętrznej kończy się niepowodzeniem po pierwszym upuszczaniu partycji.
HIVE-17259: Hive JDBC nie rozpoznaje kolumn UNIONTYPE.
HIVE-17530: KlasaCastException podczas konwertowania
uniontypeelementu .HIVE-17600: Make OrcFile's enforceBufferSize user-settable.
HIVE-17601: ulepszanie obsługi błędów w usłudze LlapServiceDriver.
HIVE-17613: usuwanie pul obiektów na potrzeby krótkich alokacji tego samego wątku.
HIVE-17617: Zestawienie pustego zestawu wyników powinno zawierać grupowanie pustego zestawu grupowania.
HIVE-17621: Ustawienia lokacji Hive są ignorowane podczas obliczania podziału HCatInputFormat.
HIVE-17629: CachedStore: ma zatwierdzoną/niezatwierdzoną konfigurację umożliwiającą selektywne buforowanie tabel/partycji i zezwalanie na odczyt podczas wstępnej instalacji.
HIVE-17636: Dodaj test multiple_agg.q dla elementu
blobstores.HIVE-17702: niepoprawna obsługa funkcji isRepeating w czytniku dziesiętnym w orc.
HIVE-17729: Dodawanie testów bazy danych i wyjaśnienie powiązanych testów magazynu obiektów blob.
HIVE-17731: dodaj opcję wstecz
compatdla użytkowników zewnętrznych do programu HIVE-11985.HIVE-17803: W przypadku wielu zapytań pig 2 HCatStorers zapisu w tej samej tabeli będzie deptać dane wyjściowe siebie nawzajem.
HIVE-17845: wstawianie kończy się niepowodzeniem, jeśli kolumny tabeli docelowej nie są małymi literami.
HIVE-17900: analizowanie statystyk kolumn wyzwalanych przez compactor generuje źle sformułowany kod SQL z 1 kolumną > partycji.
HIVE-18006: Optymalizowanie zużycia pamięci przez HLLDenseRegister.
HIVE-18026: Optymalizacja konfiguracji głównej usługi Hive webhcat.
HIVE-18031: obsługa replikacji dla operacji Alter Database.
HIVE-18090: puls kwasu kończy się niepowodzeniem, gdy magazyn metadanych jest połączony za pośrednictwem poświadczeń usługi Hadoop.
HIVE-18189: Kolejność według pozycji nie działa, gdy
cbojest wyłączona.HIVE-18258: Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplikowane kolumny is broken.
HIVE-18269: LLAP: Szybkie
llapoperacje we/wy z powolnym potokiem przetwarzania mogą prowadzić do OOM.HIVE-18293: Program Hive nie kompaktuje tabel zawartych w folderze, który nie jest własnością tożsamości z uruchomionym programem HiveMetaStore.
HIVE-18318: Czytnik rekordów LLAP powinien sprawdzać przerwanie nawet wtedy, gdy nie blokuje.
HIVE-18326: LLAP Tez scheduler — tylko wywłaszcza zadania, jeśli istnieje zależność między nimi.
HIVE-18327: Usuń niepotrzebną zależność HiveConf dla usługi MiniHiveKdc.
HIVE-18331: Dodaj ponowne rejestrowanie po wygaśnięciu biletu TGT i niektóre rejestrowanie/lambda.
HIVE-18341: Dodano obsługę ponownego ładowania w celu dodania "nieprzetworzonej" przestrzeni nazw dla funkcji TDE z tymi samymi kluczami szyfrowania.
HIVE-18352: wprowadzenie opcji METADATAONLY podczas wykonywania zrzutu REPL w celu umożliwienia integracji innych narzędzi.
HIVE-18353: CompactorMR powinien wywołać metodę jobclient.close(), aby wyzwolić czyszczenie.
HIVE-18384: ConcurrentModificationException w
log4j2.xbibliotece.HIVE-18390: IndexOutOfBoundsException podczas wykonywania zapytań względem widoku partycjonowanego w kolumnie ColumnPruner.
HIVE-18447: JDBC: umożliwia użytkownikom JDBC przekazywanie informacji o plikach cookie za pośrednictwem parametry połączenia.
HIVE-18460: Kompakt nie przekazuje właściwości tabeli do modułu zapisywania Orc.
HIVE-18462: (Wyjaśnienie sformatowane dla zapytań ze sprzężeniami mapowania zawiera kolumnęExprMap z niesformatowaną nazwą kolumny).
HIVE-18467: obsługa całego zrzutu magazynu / ładowania + tworzenia/upuszczania zdarzeń bazy danych.
HIVE-18488: Czytniki ORC LLAP brakuje niektórych testów null.
HIVE-18490: Zapytanie o istnieje i NIE ISTNIEJE z predykatem nieprzywiągowym może spowodować nieprawidłowy wynik.
HIVE-18506: LlapBaseInputFormat — indeks tablicy ujemnej.
HIVE-18517: Wektoryzacja: Fix VectorMapOperator w celu akceptowania baz danych VRB i sprawdzania flagi wektoryzowanej poprawnie w celu obsługi buforowania LLAP).
HIVE-18523: Napraw wiersz podsumowania w przypadku braku danych wejściowych.
HIVE-18528: Zagregowane statystyki w magazynie obiektów otrzymują nieprawidłowy wynik.
HIVE-18530: Replikacja powinna pominąć tabelę MM (na razie).
HIVE-18548: Napraw importowanie
log4j.HIVE-18551: Wektoryzacja: VectorMapOperator próbuje napisać zbyt wiele kolumn wektorów dla hybrydowej łaski.
HIVE-18577: SemanticAnalyzer.validate ma kilka bezsensownych wywołań magazynu metadanych.
HIVE-18587: wstawianie zdarzenia DML może próbować obliczyć sumę kontrolną dla katalogów.
HIVE-18597: LLAP: Zawsze pakuj plik JAR interfejsu
log4j2API dla elementuorg.apache.log4j.HIVE-18613: Rozszerz JsonSerDe, aby obsługiwać typ BINARNY.
HIVE-18626: Ponowne ładowanie klauzuli "with" nie przekazuje konfiguracji do zadań podrzędnych.
HIVE-18643: nie sprawdzaj zarchiwizowanych partycji dla operacji ACID.
HIVE-18660: PCR nie rozróżnia kolumn partycji i kolumn wirtualnych.
HIVE-18754: STAN REPL powinien obsługiwać klauzulę "with".
HIVE-18788: Czyszczenie danych wejściowych w JDBC PreparedStatement.
HIVE-18794: Ponowne ładowanie klauzuli "with" nie przekazuje konfiguracji do zadań dla tabel innych niż partycje.
HIVE-18808: Zwiększenie niezawodności kompaktowania w przypadku niepowodzenia aktualizacji statystyk.
HIVE-18815: Usuwanie nieużywanej funkcji w systemie HPL/SQL.
HIVE-18817: Wyjątek ArrayIndexOutOfBounds podczas odczytu tabeli ACID.
HIVE-18833: Automatyczne scalanie kończy się niepowodzeniem podczas "wstawiania do katalogu jako pliku orcfile".
HIVE-18879: Nie zezwalaj na element osadzony w narzędziu UDFXPathUtil musi działać, jeśli xercesImpl.jar w ścieżce klasy.
HIVE-18944: Pozycja zestawów grupowania jest niepoprawnie ustawiana podczas DPP.
Kafka
Ta wersja udostępnia platformę Kafka 1.0.0 i następujące poprawki apache.
KAFKA-4827: Połączenie platformy Kafka: błąd z znakami specjalnymi w nazwie łącznika.
KAFKA-6118: Błąd przejściowy w interfejsie kafka.api.SaslScramSslToEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156: Narzędzie JmxReporter nie może obsługiwać ścieżek katalogu w stylu systemu Windows.
KAFKA-6164: Wątki ClientQuotaManager uniemożliwiają zamknięcie podczas napotkania błędu podczas ładowania dzienników.
KAFKA-6167: Znacznik czasu w katalogu strumieni zawiera dwukropek, który jest niedozwolonym znakiem.
KAFKA-6179: RecordQueue.clear() nie czyści utrzymywanej listy minTimestampTracker.
KAFKA-6185: Przeciek pamięci selektora z dużym prawdopodobieństwem operacji OOM w przypadku konwersji w dół.
KAFKA-6190: GlobalKTable nigdy nie kończy przywracania podczas korzystania z komunikatów transakcyjnych.
KAFKA-6210: IllegalArgumentException, jeśli 1.0.0 jest używany dla wersji inter.broker.protocol.version lub log.message.format.version.
KAFKA-6214: Używanie replik rezerwowych z magazynem stanu pamięci powoduje awarię strumieni.
KAFKA-6215: KafkaStreamsTest kończy się niepowodzeniem w magistrali.
KAFKA-6238: Problemy z wersją protokołu podczas stosowania uaktualnienia stopniowego do wersji 1.0.0.
KAFKA-6260: AbstractCoordinator nie obsługuje wyraźnie wyjątku NULL.
KAFKA-6261: Rejestrowanie żądań zgłasza wyjątek, jeśli acks=0.
KAFKA-6274: Ulepszanie
KTableautomatycznie generowanych nazw magazynu stanów źródłowych.
Mahout
W usługach HDP-2.3.x i 2.4.x, zamiast wysyłać określoną wersję apache Mahout, zsynchronizowaliśmy się z określonym punktem poprawki na magistrali Apache Mahout. Ten punkt poprawki znajduje się po wersji 0.9.0, ale przed wersją 0.10.0. Zapewnia to dużą liczbę poprawek błędów i ulepszeń funkcjonalnych w wersji 0.9.0, ale zapewnia stabilną wersję funkcji Mahout przed zakończeniem konwersji na nową platformę Spark w wersji 0.10.0.
Punkt poprawki wybrany dla Mahout w HDP 2.3.x i 2.4.x pochodzi z gałęzi "mahout-0.10.x" Apache Mahout, od 19 grudnia 2014 r., poprawka 0f037cb03e7c096 w usłudze GitHub.
W usługach HDP-2.5.x i 2.6.x usunęliśmy bibliotekę "commons-httpclient" z Mahout, ponieważ postrzegamy ją jako przestarzałą bibliotekę z możliwymi problemami z zabezpieczeniami i uaktualniliśmy klienta Hadoop-Client w Mahout do wersji 2.7.3, tej samej wersji używanej w usłudze HDP-2.5. W efekcie:
Wcześniej skompilowane zadania Mahout muszą zostać ponownie skompilowane w środowisku HDP-2.5 lub 2.6.
Istnieje niewielka możliwość, że niektóre zadania Mahout mogą napotkać błędy "ClassNotFoundException" lub "nie można załadować klasy" związane z prefiksami "org.apache.commons.httpclient", "net.java.dev.jets3t" lub powiązanymi prefiksami nazw klas. Jeśli wystąpią te błędy, możesz rozważyć, czy ręcznie zainstalować wymagane pliki jar w ścieżce klasy dla zadania, jeśli ryzyko problemów z zabezpieczeniami w przestarzałej bibliotece jest akceptowalne w danym środowisku.
Istnieje jeszcze mniejsza możliwość, że niektóre zadania Mahout mogą napotkać awarie w wywołaniach kodu klienta hbase-client Mahout do bibliotek hadoop-common ze względu na problemy ze zgodnością binarną. Niestety, nie ma możliwości rozwiązania tego problemu z wyjątkiem przywracania do wersji HDP-2.4.2 Mahout, która może mieć problemy z zabezpieczeniami. Ponownie, powinno to być niezwykłe i jest mało prawdopodobne, aby wystąpić w każdym zestawie zadań Mahout.
Oozie
Ta wersja udostępnia program Oozie 4.2.0 z następującymi poprawkami apache.
OOZIE-2571: Dodaj właściwość spark.scala.binary.version Maven, aby można było użyć języka Scala 2.11.
OOZIE-2606: Ustaw plik spark.yarn.jars, aby naprawić platformę Spark 2.0 przy użyciu usługi Oozie.
OOZIE-2658: --driver-class-path może zastąpić ścieżkę klasy na platformie SparkMain.
OOZIE-2787: Oozie dystrybuuje plik JAR aplikacji dwa razy, co sprawia, że zadanie platformy Spark kończy się niepowodzeniem.
OOZIE-2792:
Hive2akcja nie analizuje identyfikatora aplikacji Platformy Spark z pliku dziennika prawidłowo, gdy hive jest na platformie Spark.OOZIE-2799: Ustawianie lokalizacji dziennika dla usługi Spark sql w gałęzi.
OOZIE-2802: Niepowodzenie akcji platformy Spark na platformie Spark 2.1.0 z powodu duplikatu
sharelibs.OOZIE-2923: Ulepszanie analizowania opcji platformy Spark.
OOZIE-3109: SCA: Skrypty między witrynami: odzwierciedlone.
OOZIE-3139: Oozie weryfikuje niepoprawnie przepływ pracy.
OOZIE-3167: uaktualnij wersję serwera tomcat w gałęzi Oozie 4.3.
Phoenix
Ta wersja zawiera rozwiązanie Phoenix 4.7.0 i następujące poprawki apache:
PHOENIX-1751: Wykonaj agregacje, sortowanie itp., w preScannerNext zamiast postScannerOpen.
PHOENIX-2714: Popraw oszacowanie bajtów w usłudze BaseResultIterators i uwidocznij jako interfejs.
PHOENIX-2724: Wykonywanie zapytań z dużą liczbą przewodników jest wolniejsze w porównaniu z brakiem statystyk.
PHOENIX-2855: Obejście inkrementacji TimeRange nie jest serializowane dla bazy HBase 1.2.
PHOENIX-3023: Niska wydajność, gdy zapytania limitu są wykonywane równolegle domyślnie.
PHOENIX-3040: Nie używaj przewodników do wykonywania zapytań szeregowo.
PHOENIX-3112: Skanowanie częściowe wierszy nie jest poprawnie obsługiwane.
PHOENIX-3240: KlasaCastException z modułu ładującego Pig.
PHOENIX-3452: WARTOŚĆ NULLS FIRST/NULL LAST nie powinna mieć wpływu na to, czy FUNKCJA GROUP BY zachowuje kolejność.
PHOENIX-3469: Niepoprawna kolejność sortowania klucza podstawowego DESC dla wartości NULLS LAST/NULLS FIRST.
PHOENIX-3789: Wykonaj wywołania konserwacji indeksu między regionami w pliku postBatchMutateIndispensably.
PHOENIX-3865: WARTOŚĆ IS NULL nie zwraca prawidłowych wyników, gdy rodzina pierwszej kolumny nie jest filtrowana.
PHOENIX-4290: Pełne skanowanie tabeli wykonane w celu usunięcia z tabelą o niezmiennych indeksach.
PHOENIX-4373: Klucz zmiennej długości zmiennej indeksu lokalnego może mieć końcowe wartości null podczas upserting.
PHOENIX-4466: java.lang.RuntimeException: kod odpowiedzi 500 — Wykonywanie zadania platformy Spark w celu nawiązania połączenia z serwerem zapytań phoenix i załadowania danych.
PHOENIX-4489: Wyciek połączenia HBase w Phoenix MR Jobs.
PHOENIX-4525: Przepełnienie całkowite w wykonaniu GroupBy.
PHOENIX-4560: FUNKCJA ORDER BY z GRUPĄ BY nie działa, jeśli w kolumnie znajduje się MIEJSCE
pk.PHOENIX-4586: FUNKCJA UPSERT SELECT nie uwzględnia operatorów porównania dla podzapytania.
PHOENIX-4588: Wyrażenie klonowania również wtedy, gdy jego dzieci mają Determinism.PER_INVOCATION.
Pig
Ta wersja udostępnia program Pig 0.16.0 z następującymi poprawkami apache.
PIG-5159: Naprawa Świnia nie zapisuje historii gruntu.
PIG-5175: uaktualnienie
jrubydo wersji 1.7.26.
Ranger
Ta wersja zawiera platformę Ranger 0.7.0 i następujące poprawki apache:
RANGER-1805: Ulepszanie kodu w celu stosowania najlepszych rozwiązań w języku js.
RANGER-1960: Weź pod uwagę nazwę tabeli migawki do usunięcia.
RANGER-1982: Poprawa błędu dla metryki analitycznej usługi Ranger Admin i Ranger KMS.
RANGER-1984: Rekordy dziennika inspekcji bazy danych HBase mogą nie pokazywać wszystkich tagów skojarzonych z dostępem do kolumny.
RANGER-1988: Naprawianie niezabezpieczonej losowości.
RANGER-1990: Dodaj jednokierunkową obsługę protokołu SSL MySQL w usłudze Ranger Admin.
RANGER-2006: Rozwiązywanie problemów wykrytych przez analizę kodu statycznego w module ranger
usersyncna potrzebyldapźródła synchronizacji.RANGER-2008: Ocena zasad kończy się niepowodzeniem w przypadku warunków zasad wielowierszowych.
Suwak
Ta wersja udostępnia suwak 0.92.0 bez dodatkowych poprawek apache.
platforma Spark
Ta wersja udostępnia platformę Spark 2.3.0 i następujące poprawki apache:
SPARK-13587: Obsługa virtualenv w pyspark.
SPARK-19964: Unikaj odczytywania z repozytoriów zdalnych w aplikacji SparkSubmitSuite.
SPARK-22882: test ML do przesyłania strumieniowego ze strukturą: ml.classification.
SPARK-22915: Testy przesyłania strumieniowego dla funkcji spark.ml.feature, od N do Z.
SPARK-23020: Napraw kolejny wyścig w teście uruchamiania procesu.
SPARK-23040: Zwraca iterator przerwalny dla czytnika mieszania.
SPARK-23173: Unikaj tworzenia uszkodzonych plików parquet podczas ładowania danych z formatu JSON.
SPARK-23264: Napraw scala. MatchError w literals.sql.out.
SPARK-23288: Naprawianie metryk wyjściowych za pomocą ujścia parquet.
SPARK-23329: Poprawiono dokumentację funkcji trygonometrycznych.
SPARK-23406: Włącz samoobsługowe sprzężenia strumienia strumienia dla gałęzi-2.3.
SPARK-23434: Platforma Spark nie powinna ostrzegać "katalogu metadanych" dla ścieżki pliku HDFS.
SPARK-23436: Wywnioskuj partycję jako datę tylko wtedy, gdy można ją rzutować na datę.
SPARK-23457: Najpierw zarejestruj odbiorniki ukończenia zadań w pliku ParquetFileFormat.
SPARK-23462: popraw brakujący komunikat o błędzie pola w elempcie "StructType".
SPARK-23490: Sprawdź identyfikator storage.locationUri z istniejącą tabelą w tabeli CreateTable.
SPARK-23524: Duże lokalne bloki mieszania nie powinny być sprawdzane pod kątem uszkodzenia.
SPARK-23525: Obsługa funkcji ALTER TABLE CHANGE COLUMN COMMENT dla zewnętrznej tabeli hive.
SPARK-23553: Testy nie powinny zakładać wartości domyślnej "spark.sql.sources.default".
SPARK-23569: zezwalaj pandas_udf na pracę z funkcjami typu typu w stylu python3.
SPARK-23570: Dodaj platformę Spark 2.3.0 w aplikacji HiveExternalCatalogVersionsSuite.
SPARK-23598: Utwórz metody w publicznej wersji BufferedRowIterator, aby uniknąć błędu środowiska uruchomieniowego dla dużego zapytania.
SPARK-23599: Dodaj generator UUID z pseudolosowych liczb.
SPARK-23599: użyj elementu RandomUUIDGenerator w wyrażeniu Uuid.
SPARK-23601: Usuwanie
.md5plików z wydania.SPARK-23608: Dodawanie synchronizacji w usłudze SHS między funkcjami attachSparkUI i detachSparkUI w celu uniknięcia współbieżnego problemu z modyfikacjami w programach obsługi jetty.
SPARK-23614: Napraw niepoprawną wymianę ponownego użycia podczas buforowania.
SPARK-23623: Unikaj współbieżnego używania buforowanych odbiorców w pamięci podręcznej CachedKafkaConsumer (gałąź-2.3).
SPARK-23624: Popraw dokument metody pushFilters w źródle danych W wersji 2.
SPARK-23628: funkcja calculateParamLength nie powinna zwracać wartości 1 i liczby wyrażeń.
SPARK-23630: zezwalaj na zastosowanie dostosowań konfiguracji hadoop użytkownika.
SPARK-23635: Zmienna env funkcji wykonawczej platformy Spark jest zastępowana przez tę samą nazwę zmiennej env am.
SPARK-23637: Yarn może przydzielić więcej zasobów, jeśli ten sam wykonawca zostanie zabity wielokrotnie.
SPARK-23639: Uzyskaj token przed zainicjowanie klienta magazynu metadanych w interfejsie wiersza polecenia platformy SparkSQL.
SPARK-23642: Podklasa akumulacjaV2 to Poprawkazero
scaladoc.SPARK-23644: użyj ścieżki bezwzględnej do wywołania REST w usłudze SHS.
SPARK-23645: Dodaj dokumenty RE "pandas_udf" przy użyciu args słów kluczowych.
SPARK-23649: Pomijanie znaków niedozwolonych w formacie UTF-8.
SPARK-23658: InProcessAppHandle używa niewłaściwej klasy w getLogger.
SPARK-23660: Napraw wyjątek w trybie klastra yarn, gdy aplikacja zakończyła się szybko.
SPARK-23670: Napraw przeciek pamięci na platformie SparkPlanGraphWrapper.
SPARK-23671: Naprawiono warunek umożliwiający włączenie puli wątków SHS.
SPARK-23691: użyj narzędzia sql_conf w testach PySpark tam, gdzie to możliwe.
SPARK-23695: Napraw komunikat o błędzie dla testów przesyłania strumieniowego Kinesis.
SPARK-23706: spark.conf.get(wartość, default=None) powinna wygenerować wartość None w PySpark.
SPARK-23728: Napraw testy ML z oczekiwanymi wyjątkami podczas uruchamiania testów przesyłania strumieniowego.
SPARK-23729: Uwzględnianie fragmentu identyfikatora URI podczas rozpoznawania globów.
SPARK-23759: Nie można powiązać interfejsu użytkownika platformy Spark z określoną nazwą hosta/adresem IP.
SPARK-23760: CodegenContext.withSubExprEliminationExprs powinien poprawnie zapisać/przywrócić stan CSE.
SPARK-23769: Usuń komentarze, które niepotrzebnie wyłączają
Scalastylesprawdzanie.SPARK-23788: Napraw wyścig w StreamingQuerySuite.
SPARK-23802: PropagateEmptyRelation może pozostawić plan zapytania w stanie nierozwiązanym.
SPARK-23806: Funkcja Broadcast.unpersist może spowodować wyjątek krytyczny w przypadku użycia z alokacją dynamiczną.
SPARK-23808: ustaw domyślną sesję platformy Spark w sesjach spark tylko testowych.
SPARK-23809: Aktywne sparkSession należy ustawić przez polecenie getOrCreate.
SPARK-23816: Zabite zadania powinny ignorować FetchFailures.
SPARK-23822: Popraw komunikat o błędzie dotyczący niezgodności schematu Parquet.
SPARK-23823: Zachowaj pochodzenie w transformExpression.
SPARK-23827: StreamingJoinExec powinien upewnić się, że dane wejściowe są podzielone na określoną liczbę partycji.
SPARK-23838: Uruchamianie zapytania SQL jest wyświetlane jako "ukończone" na karcie SQL.
SPARK-23881: Naprawa łuszczący test JobCancellationSuite". przerywany iterator czytnika shuffle".
Sqoop
Ta wersja udostępnia narzędzie Sqoop 1.4.6 bez dodatkowych poprawek apache.
Storm
Ta wersja udostępnia system Storm 1.1.1 i następujące poprawki apache:
STORM-2652: Wyjątek zgłoszony w metodzie open JmsSpout.
STORM-2841: testNoAcksIfFlushFails UT kończy się niepowodzeniem z powodu błędu NullPointerException.
STORM-2854: Uwidaczniaj IEventLogger, aby podłączyć dziennik zdarzeń.
STORM-2870: FileBasedEventLogger przecieka nieuprawdniającego wykonawcyservice, co uniemożliwia zakończenie procesu.
STORM-2960: Lepiej podkreślić znaczenie konfigurowania odpowiedniego konta systemu operacyjnego dla procesów Storm.
Tez
Ta wersja udostępnia tez 0.7.0 i następujące poprawki apache:
- TEZ-1526: Ładowaniecache dla usługi TezTaskID wolne w przypadku dużych zadań.
Zeppelin
Ta wersja zapewnia zeppelin 0.7.3 bez dodatkowych poprawek Apache.
ZEPPELIN-3072: Interfejs użytkownika zeppelin staje się powolny/nie odpowiada, jeśli istnieje zbyt wiele notesów.
ZEPPELIN-3129: Interfejs użytkownika zeppelin nie wylogowuje się w programie Internet Explorer.
ZEPPELIN-903: zastąp CXF ciągiem
Jersey2.
ZooKeeper
Ta wersja udostępnia usługę ZooKeeper 3.4.6 i następujące poprawki apache:
ZOOKEEPER-1256: Błąd ClientPortBindTest w systemie macOS X.
ZOOKEEPER-1901: [JDK8] Sortuj elementy podrzędne do porównania w testach AsyncOps.
ZOOKEEPER-2423: Uaktualnianie wersji netty z powodu luki w zabezpieczeniach (CVE-2014-3488).
ZOOKEEPER-2693: Atak DOS na wchp/wchc cztery litery słów (4lw).
ZOOKEEPER-2726: Patch wprowadza potencjalny stan wyścigu.
Naprawiono typowe luki w zabezpieczeniach i ujawnieniach
W tej sekcji opisano wszystkie typowe luki w zabezpieczeniach i zagrożenia (CVE), które zostały rozwiązane w tej wersji.
CVE-2017-7676
| Podsumowanie: Ocena zasad platformy Apache Ranger ignoruje znaki po znaku wieloznaczny "*" |
|---|
| Ważność: Krytyczne |
| Dostawca: Hortonworks |
| Wersje, których dotyczy problem: wersje usługi HDInsight 3.6, w tym Apache Ranger w wersji 0.5.x/0.6.x/0.7.0 |
| Użytkownicy, których dotyczy problem: środowiska korzystające z zasad ranger z znakami po symbolu wieloznacznymi "*" — na przykład mój*test, test*.txt |
| Wpływ: Matcher zasobów zasad ignoruje znaki po symbolu wieloznacznych "*", co może spowodować niezamierzone zachowanie. |
| Poprawka szczegółów: moduł dopasowania zasobów zasad platformy Ranger został zaktualizowany w celu poprawnego obsługi dopasowań z symbolami wieloznacznymi. |
| Zalecana akcja: uaktualnienie do usługi HDI 3.6 (z programem Apache Ranger 0.7.1 lub nowszym). |
CVE-2017-7677
| Podsumowanie: Autoryzator hive platformy Apache Ranger powinien sprawdzić uprawnienia RWX po określeniu lokalizacji zewnętrznej |
|---|
| Ważność: Krytyczne |
| Dostawca: Hortonworks |
| Wersje, których dotyczy problem: wersje usługi HDInsight 3.6, w tym Apache Ranger w wersji 0.5.x/0.6.x/0.7.0 |
| Użytkownicy, których dotyczy problem: środowiska korzystające z lokalizacji zewnętrznej dla tabel hive |
| Wpływ: W środowiskach korzystających z lokalizacji zewnętrznej dla tabel hive autoryzator Hive platformy Apache Ranger powinien sprawdzić uprawnienia RWX dla lokalizacji zewnętrznej określonej dla tabeli tworzenia. |
| Szczegóły poprawki: Autoryzator Hive programu Ranger został zaktualizowany w celu poprawnego obsługi sprawdzania uprawnień w lokalizacji zewnętrznej. |
| Zalecana akcja: użytkownicy powinni przeprowadzić uaktualnienie do usługi HDI 3.6 (z programem Apache Ranger 0.7.1 lub nowszym). |
CVE-2017-9799
| Podsumowanie: Potencjalne wykonanie kodu jako niewłaściwego użytkownika w systemie Apache Storm |
|---|
| Ważność: ważne |
| Dostawca: Hortonworks |
| Wersje, których dotyczy problem: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Użytkownicy, których dotyczy problem: użytkownicy korzystający z systemu Storm w trybie bezpiecznym i używają magazynu obiektów blob do dystrybucji artefaktów opartych na topologii lub dystrybuowania dowolnych zasobów topologii za pomocą magazynu obiektów blob. |
| Wpływ: W niektórych sytuacjach i konfiguracjach burzy teoretycznie jest możliwe, aby właściciel topologii skłonił nadzorcę do uruchomienia procesu roboczego jako inny, nie root, użytkownik. W najgorszym przypadku może to prowadzić do zabezpieczenia poświadczeń innego użytkownika, który został naruszony. Ta luka w zabezpieczeniach dotyczy tylko instalacji systemu Apache Storm z włączonymi zabezpieczeniami. |
| Środki zaradcze: uaktualnij do wersji HDP-2.6.2.1, ponieważ obecnie nie ma żadnych obejść. |
CVE-2016-4970
| Podsumowanie: program obsługi/ssl/OpenSslEngine.java w programie Netty 4.0.x przed 4.0.37. Final i 4.1.x przed 4.1.1. Final umożliwia zdalnym atakującym spowodowanie odmowy usługi (nieskończona pętla) |
|---|
| Ważność: Umiarkowana |
| Dostawca: Hortonworks |
| Wersje, których dotyczy problem: HDP 2.x.x od wersji 2.3.x |
| Użytkownicy, których dotyczy problem: wszyscy użytkownicy korzystający z systemu plików HDFS. |
| Wpływ: wpływ jest niski, ponieważ narzędzie Hortonworks nie używa OpenSslEngine.java bezpośrednio w bazie kodu platformy Hadoop. |
| Zalecana akcja: uaktualnienie do wersji HDP 2.6.3. |
CVE-2016-8746
| Podsumowanie: Problem z dopasowaniem ścieżki platformy Apache Ranger w ocenie zasad |
|---|
| Ważność: Normalna |
| Dostawca: Hortonworks |
| Wersje, których dotyczy problem: wszystkie wersje hdp 2.5, w tym Apache Ranger w wersji 0.6.0/0.6.1/0.6.2 |
| Użytkownicy, których dotyczy problem: wszyscy użytkownicy narzędzia administratora zasad platformy Ranger. |
| Wpływ: aparat zasad ranger niepoprawnie pasuje do ścieżek w określonych warunkach, gdy zasady zawierają symbole wieloznaczne i flagi cyklicznego. |
| Poprawka szczegółów: Naprawiono logikę oceny zasad |
| Zalecana akcja: użytkownicy powinni przeprowadzić uaktualnienie do wersji HDP 2.5.4 lub nowszej (z programem Apache Ranger 0.6.3 lub nowszym) lub HDP 2.6+ (z programem Apache Ranger 0.7.0 lub nowszym) |
CVE-2016-8751
| Podsumowanie: Problem z przechowywaniem skryptów między witrynami platformy Apache Ranger |
|---|
| Ważność: Normalna |
| Dostawca: Hortonworks |
| Wersje, których dotyczy problem: wszystkie wersje HDP 2.3/2.4/2.5, w tym Apache Ranger w wersji 0.5.x/0.6.0/0.6.1/6.2 |
| Użytkownicy, których dotyczy problem: wszyscy użytkownicy narzędzia administratora zasad platformy Ranger. |
| Wpływ: Platforma Apache Ranger jest podatna na przechowywanie skryptów między witrynami podczas wprowadzania niestandardowych warunków zasad. Użytkownicy administracyjni mogą przechowywać dowolny kod JavaScript wykonywany po zalogowaniu się i korzystaniu z zasad dostępu przez zwykłych użytkowników. |
| Poprawka szczegółów: Dodano logikę w celu oczyszczenia danych wejściowych użytkownika. |
| Zalecana akcja: użytkownicy powinni przeprowadzić uaktualnienie do wersji HDP 2.5.4 lub nowszej (z programem Apache Ranger 0.6.3 lub nowszym) lub HDP 2.6+ (z programem Apache Ranger 0.7.0 lub nowszym) |
Rozwiązano problemy dotyczące pomocy technicznej
Rozwiązano problemy reprezentują wybrane problemy, które zostały wcześniej zarejestrowane za pośrednictwem pomocy technicznej narzędzia Hortonworks, ale zostały rozwiązane w bieżącej wersji. Te problemy mogły zostać zgłoszone w poprzednich wersjach w sekcji Znane problemy; oznacza to, że zostały zgłoszone przez klientów lub zidentyfikowane przez zespół inżynierów ds. jakości Hortonworks.
Nieprawidłowe wyniki
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin -getGroups nie zwraca zaktualizowanych grup dla użytkownika |
| BUG-100058 | PHOENIX-2645 | Symbole wieloznaczne nie pasują do znaków nowego wiersza |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Wyniki są nieprawidłowe w przypadku indeksów lokalnych |
| BUG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | niepowodzenie zapytania36, niezgodność liczby wierszy |
| BUG-89765 | HIVE-17702 | niepoprawna obsługa isRepeating w czytniku dziesiętnym w ORC |
| BUG-92293 | HADOOP-15042 | Funkcja Azure PageBlobInputStream.skip() może zwracać wartość ujemną, gdy parametr numberOfPagesRemaining wynosi 0 |
| BUG-92345 | ATLAS-2285 | Interfejs użytkownika: zmieniono nazwę zapisanego wyszukiwania za pomocą atrybutu date. |
| BUG-92563 | HIVE-17495, HIVE-18528 | Zagregowane statystyki w obiekcie ObjectStore otrzymują nieprawidłowy wynik |
| BUG-92957 | HIVE-11266 | count(*) nieprawidłowy wynik na podstawie statystyk tabeli dla tabel zewnętrznych |
| BUG-93097 | RANGER-1944 | Filtr akcji dla inspekcji administratora nie działa |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q ma problem z nieprawidłowym wynikiem dla podwójnego obliczenia |
| BUG-93415 | HIVE-18258, HIVE-18310 | Wektoryzacja: zmniejszanie grupowania WEDŁUG SCALANIAPARTIAL z zduplikowanymi kolumnami jest uszkodzone |
| BUG-93939 | ATLAS-2294 | Dodatkowy parametr "description" dodany podczas tworzenia typu |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Zapytania Phoenix zwracają wartości null z powodu częściowych wierszy bazy danych HBase |
| BUG-94266 | HIVE-12505 | Wstawianie zastępowania w tej samej zaszyfrowanej strefie w trybie dyskretnym nie może usunąć niektórych istniejących plików |
| BUG-94414 | HIVE-15680 | Nieprawidłowe wyniki, gdy w zapytaniu występuje dwukrotne odwołanie do tabeli HIVe.optimize.index.filter=true i tej samej tabeli ORC |
| BUG-95048 | HIVE-18490 | Zapytanie z parametrem EXISTS i NOT EXISTS with non-equi predykate może wygenerować nieprawidłowy wynik |
| BUG-95053 | PHOENIX-3865 | Wartość IS NULL nie zwraca prawidłowych wyników, gdy rodzina pierwszej kolumny nie jest filtrowana względem |
| BUG-95476 | RANGER-1966 | Inicjalizacja aparatu zasad nie tworzy w niektórych przypadkach wzbogacenia kontekstu |
| BUG-95566 | SPARK-23281 | Zapytanie generuje wyniki w nieprawidłowej kolejności, gdy złożona kolejność według klauzuli odwołuje się zarówno do oryginalnych kolumn, jak i aliasów |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Rozwiązywanie problemów z usługą ORDER BY ASC, gdy zapytanie ma agregację |
| BUG-96389 | PHOENIX-4586 | FUNKCJA UPSERT SELECT nie uwzględnia operatorów porównania dla podzapytania. |
| BUG-96602 | HIVE-18660 | PcR nie rozróżnia między partycjami a kolumnami wirtualnymi |
| BUG-97686 | ATLAS-2468 | [Wyszukiwanie podstawowe] Problem z przypadkami OR, gdy NEQ jest używany z typami liczbowymi |
| BUG-97708 | HIVE-18817 | Wyjątek ArrayIndexOutOfBounds podczas odczytu tabeli ACID. |
| BUG-97864 | HIVE-18833 | Automatyczne scalanie kończy się niepowodzeniem, gdy "wstaw do katalogu jako plik orcfile" |
| BUG-97889 | RANGER-2008 | Ocena zasad kończy się niepowodzeniem w przypadku warunków zasad wielowierszowych. |
| BUG-98655 | RANGER-2066 | Dostęp do rodziny kolumn HBase jest autoryzowany przez otagowaną kolumnę w rodzinie kolumn |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer może przełączać stałe kolumny |
Inne
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100267 | HBASE-17170 | Baza HBase ponawia również próbę wykonania polecenia DoNotRetryIOException z powodu różnic modułu ładującego klasy. |
| BUG-92367 | YARN-7558 | Polecenie "dzienniki usługi yarn" nie może pobrać dzienników dla uruchomionych kontenerów, jeśli jest włączone uwierzytelnianie interfejsu użytkownika. |
| BUG-93159 | OOZIE-3139 | Oozie weryfikuje przepływ pracy niepoprawnie |
| BUG-93936 | ATLAS-2289 | Osadzony kod uruchamiania/zatrzymywania serwera kafka/zookeeper, który ma zostać przeniesiony z implementacji kafkaNotification |
| BUG-93942 | ATLAS-2312 | Użyj obiektów ThreadLocal DateFormat, aby uniknąć jednoczesnego użycia z wielu wątków |
| BUG-93946 | ATLAS-2319 | Interfejs użytkownika: usunięcie tagu, który na 25+ pozycji na liście tagów w strukturze płaskiej i drzewa wymaga odświeżenia, aby usunąć tag z listy. |
| BUG-94618 | YARN-5037, YARN-7274 | Możliwość wyłączenia elastyczności na poziomie kolejki liścia |
| BUG-94901 | HBASE-19285 | Dodawanie histogramów opóźnienia dla tabeli |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Aktualizowanie adls łącznika w celu korzystania z bieżącej wersji zestawu ADLS SDK |
| BUG-95619 | HIVE-18551 | Wektoryzacja: VectorMapOperator próbuje napisać zbyt wiele kolumn wektorów dla hybrydowej grace |
| BUG-97223 | SPARK-23434 | Platforma Spark nie powinna ostrzegać "katalogu metadanych" dla ścieżki pliku HDFS |
Wydajność
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Szybkie obliczenia lokalne w module równoważenia |
| BUG-91300 | HBASE-17387 | Zmniejsz obciążenie raportu wyjątku w regionie RegionActionResult dla funkcji multi() |
| BUG-91804 | TEZ-1526 | Ładowanie usługiCache dla identyfikatora TezTaskID wolne w przypadku dużych zadań |
| BUG-92760 | ACCUMULO-4578 | Anulowanie operacji kompaktowania FATE nie zwalnia blokady przestrzeni nazw |
| BUG-93577 | RANGER-1938 | Rozwiązanie Solr w przypadku konfiguracji inspekcji nie używa skutecznie plików DocValues |
| BUG-93910 | HIVE-18293 | Program Hive nie kompaktuje tabel zawartych w folderze, który nie jest własnością tożsamości z uruchomionym programem HiveMetaStore |
| BUG-94345 | HIVE-18429 | Kompaktowanie powinno obsługiwać przypadek, gdy nie generuje żadnych danych wyjściowych |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Obsługa żądaniaHedgingProxyProvider RetryAction order: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | Program CompactorMR powinien wywołać metodę jobclient.close(), aby wyzwolić czyszczenie |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Zażądano wiersza poza zakresem dla polecenia Get on HRegion dla lokalnej indeksowanej tabeli z solonego phoenix. |
| BUG-94928 | HDFS-11078 | Naprawianie serwera NPE w pliku LazyPersistFileScrubber |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Wiele poprawek protokołu LLAP |
| BUG-95669 | HIVE-18577, HIVE-18643 | Po uruchomieniu zapytania update/delete w tabeli partycjonowanej ACID moduł HS2 odczytuje wszystkie partycje. |
| BUG-96390 | HDFS-10453 | Wątek ReplicationMonitor może być zablokowany przez długi czas z powodu wyścigu między replikacją i usunięcia tego samego pliku w dużym klastrze. |
| BUG-96625 | HIVE-16110 | Przywracanie wartości "Vectorization: Support 2 Value CASE WHEN zamiast fallback to VectorUDFAdaptor" |
| BUG-97109 | HIVE-16757 | Użycie przestarzałej metody getRows() zamiast nowych wartości estimateRowCount(RelMetadataQuery...) ma poważny wpływ na wydajność |
| BUG-97110 | PHOENIX-3789 | Wykonywanie wywołań konserwacji indeksu między regionami w pliku postBatchMutateIndispensably |
| BUG-98833 | YARN-6797 | Funkcja TimelineWriter nie w pełni korzysta z odpowiedzi POST |
| BUG-98931 | ATLAS-2491 | Aktualizowanie punktu zaczepienia programu Hive w celu korzystania z powiadomień usługi Atlas w wersji 2 |
Potencjalna utrata danych
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-95613 | HBASE-18808 | Nieskuteczne ewidencjonowanie konfiguracji BackupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Łączenie nie powiodło się dla tabel niezarządzanych i transakcyjnych |
| BUG-97787 | HIVE-18460 | Kompakt nie przekazuje właściwości tabeli do modułu zapisywania orc |
| BUG-97788 | HIVE-18613 | Rozszerzanie funkcji JsonSerDe w celu obsługi typu binarnego |
Niepowodzenie zapytania
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Błąd asercji w obiekcie AggregatePullUpConstantsRule podczas dostosowywania indeksów agregujących |
| BUG-100422 | HIVE-19085 | Ustawienie parametru FastHiveDecimal abs(0) na +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException: requestSeek nie może być wywoływany w funkcji ReversedKeyValueHeap |
| BUG-102078 | HIVE-17978 | Zapytania TPCDS 58 i 83 generują wyjątki w wektoryzacji. |
| BUG-92483 | HIVE-17900 | analizowanie statystyk kolumn wyzwalanych przez kompaktor generuje źle sformułowany kod SQL z 1 kolumną > partycji |
| BUG-93135 | HIVE-15874, HIVE-18189 | Zapytanie Hive zwraca nieprawidłowe wyniki po ustawieniu wartości hive.groupby.orderby.position.alias na true |
| BUG-93136 | HIVE-18189 | Kolejność według pozycji nie działa, gdy cbo jest wyłączona |
| BUG-93595 | HIVE-12378, HIVE-15883 | Tabela mapowana przez bazę danych HBase w wstawienie programu Hive kończy się niepowodzeniem dla kolumn dziesiętnych i binarnych |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Zapytania Phoenix zwracają wartości null z powodu częściowych wierszy bazy danych HBase |
| BUG-94144 | HIVE-17063 | Wstawianie zastępowania partycji do tabeli zewnętrznej kończy się niepowodzeniem po pierwszym upuszczaniu partycji |
| BUG-94280 | HIVE-12785 | Widok z typem unii i funkcją UDF do rzutowania, struktura jest uszkodzona |
| BUG-94505 | PHOENIX-4525 | Przepełnienie całkowite w wykonaniu Grupuj według |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat — indeks tablicy ujemnej |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat: zapytanie Hive kończy się niepowodzeniem w aplikacji Tez z wyjątkiem java.lang.IllegalArgumentException |
| BUG-96762 | PHOENIX-4588 | Wyrażenie klonowania również wtedy, gdy jego elementy podrzędne mają Determinism.PER_INVOCATION |
| BUG-97145 | HIVE-12245, HIVE-17829 | Obsługa komentarzy kolumn dla tabeli opartej na bazie HBase |
| BUG-97741 | HIVE-18944 | Pozycja zestawów grupowania jest niepoprawnie ustawiana podczas DPP |
| BUG-98082 | HIVE-18597 | LLAP: Zawsze pakuj plik JAR interfejsu log4j2 API dla org.apache.log4j |
| BUG-99849 | Nie dotyczy | Tworzenie nowej tabeli z poziomu kreatora plików próbuje użyć domyślnej bazy danych |
Bezpieczeństwo
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100436 | RANGER-2060 | Knox serwer proxy z knox-sso programem nie działa w przypadku platformy Ranger |
| BUG-101038 | SPARK-24062 | Błąd zeppelin %Spark interpretera "Odmowa połączenia", "Należy określić klucz tajny..." błąd w serwerze HiveThriftServer |
| BUG-101359 | ACCUMULO-4056 | Aktualizacja wersji kolekcji commons-collection do wersji 3.2.2 po wydaniu |
| BUG-54240 | HIVE-18879 | Nie zezwalaj na działanie elementu osadzonego w narzędziu UDFXPathUtil, jeśli xercesImpl.jar w ścieżce klasy |
| BUG-79059 | OOZIE-3109 | Znaki specyficzne dla formatu HTML przesyłania strumieniowego w dzienniku ucieczki |
| BUG-90041 | OOZIE-2723 | JSON.org licencja jest teraz CatX |
| BUG-93754 | RANGER-1943 | Autoryzacja rozwiązania Ranger Solr jest pomijana, gdy kolekcja jest pusta lub ma wartość null |
| BUG-93804 | HIVE-17419 | ANALIZUJ TABELĘ... POLECENIE COMPUTE STATISTICS FOR COLUMNS (STATYSTYKI OBLICZENIOWE DLA KOLUMN) pokazuje obliczone statystyki dla zamaskowanych tabel |
| BUG-94276 | ZEPPELIN-3129 | Interfejs użytkownika zeppelin nie wylogowuje się w programie Internet Explorer |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Uaktualnianie netty |
| BUG-95483 | Nie dotyczy | Poprawka cve-2017-15713 |
| BUG-95646 | OOZIE-3167 | Uaktualnianie wersji serwera tomcat w gałęzi Oozie 4.3 |
| BUG-95823 | Nie dotyczy | Knox:Upgrade Beanutils |
| BUG-95908 | RANGER-1960 | Uwierzytelnianie bazy danych HBase nie uwzględnia przestrzeni nazw tabeli podczas usuwania migawki |
| BUG-96191 | FALCON-2322, FALCON-2323 | Uaktualnij wersje Jackson i Spring, aby uniknąć luk w zabezpieczeniach |
| BUG-96502 | RANGER-1990 | Dodawanie jednokierunkowej obsługi protokołu SSL MySQL w usłudze Ranger Admin |
| BUG-96712 | FLUME-3194 | uaktualnij derby do najnowszej wersji (1.14.1.0) |
| BUG-96713 | FLUME-2678 | Uaktualnij program xalan do wersji 2.7.2, aby dbać o lukę CVE-2014-0107 |
| BUG-96714 | FLUME-2050 | Uaktualnianie do log4j2 (gdy ogólna dostępność) |
| BUG-96737 | Nie dotyczy | Używanie metod systemu plików Java io do uzyskiwania dostępu do plików lokalnych |
| BUG-96925 | Nie dotyczy | Uaktualnianie serwera Tomcat z wersji 6.0.48 do 6.0.53 w usłudze Hadoop |
| BUG-96977 | FLUME-3132 | Uaktualnianie zależności biblioteki tomcat jasper |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Uaktualnianie biblioteki Nimbus-JOSE-JWT z wersją powyżej 4.39 |
| BUG-97101 | RANGER-1988 | Naprawianie niezabezpieczonej losowości |
| BUG-97178 | ATLAS-2467 | Uaktualnienie zależności dla platformy Spring i nimbus-jose-jwt |
| BUG-97180 | Nie dotyczy | Uaktualnij Nimbus-jose-jwt |
| BUG-98038 | HIVE-18788 | Czyszczenie danych wejściowych w JDBC PreparedStatement |
| BUG-98353 | HADOOP-13707 | Przywracanie polecenia "Jeśli protokół Kerberos jest włączony, gdy nie skonfigurowano protokołu HTTP SPNEGO, niektóre linki nie mogą być dostępne" |
| BUG-98372 | HBASE-13848 | Uzyskiwanie dostępu do haseł SSL serwera InfoServer za pośrednictwem interfejsu API dostawcy poświadczeń |
| BUG-98385 | ATLAS-2500 | Dodaj więcej nagłówków do odpowiedzi usługi Atlas. |
| BUG-98564 | HADOOP-14651 | Zaktualizuj wersję okhttp do wersji 2.7.5 |
| BUG-99440 | RANGER-2045 | Kolumny tabeli Hive bez jawnych zasad zezwalania są wyświetlane za pomocą polecenia "desc table" |
| BUG-99803 | Nie dotyczy | Oozie powinien wyłączyć ładowanie klas dynamicznych HBase |
Stabilność
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NpE w atlas Hive Hook |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification z limitem powinna używać mniejszej ilości pamięci |
| BUG-100072 | HIVE-19130 | Serwer NPE jest zgłaszany podczas ponownego ładowania zastosowanego zdarzenia partycji upuszczania. |
| BUG-100073 | Nie dotyczy | zbyt wiele połączeń close_wait z hiveserver węzła danych |
| BUG-100319 | HIVE-19248 | FUNKCJA REPL LOAD nie zgłasza błędu, jeśli kopiowanie pliku nie powiedzie się. |
| BUG-100352 | Nie dotyczy | CLONE — przeczyszczanie logiki RM skanuje /rejestr znode zbyt często |
| BUG-100427 | HIVE-19249 | Replikacja: klauzula WITH nie przekazuje konfiguracji do zadania we wszystkich przypadkach |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | Przyrostowy zrzut REPL powinien zgłaszać błąd, jeśli żądane zdarzenia są czyszczone. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Aktualizacja Spark2 do wersji 2.3.0+ (4/11) |
| BUG-100740 | HIVE-16107 | JDBC: Klient Httpclient powinien ponowić próbę jeszcze raz na noHttpResponseException |
| BUG-100810 | HIVE-19054 | Replikacja usługi Hive Functions kończy się niepowodzeniem |
| BUG-100937 | MAPREDUCE-6889 | Dodaj interfejs API zadania#zamknij, aby zamknąć usługi klienckie MR. |
| BUG-101065 | ATLAS-2587 | Ustaw listę ACL odczytu dla /apache_atlas/active_server_info węzła znode w wysokiej dostępności, Knox aby serwer proxy był odczytywany. |
| BUG-101093 | STORM-2993 | Śruba systemu plików HDFS systemu Storm zgłasza wyjątek ClosedChannelException, gdy są używane zasady rotacji czasu |
| BUG-101181 | Nie dotyczy | Narzędzie PhoenixStorageHandler nie obsługuje poprawnie predykatu AND |
| BUG-101266 | PHOENIX-4635 | Wyciek połączenia HBase w witrynie org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| BUG-101458 | HIVE-11464 | brak informacji o pochodzenia, jeśli istnieje wiele danych wyjściowych |
| BUG-101485 | Nie dotyczy | Interfejs API ograniczania magazynu metadanych hive działa wolno i powoduje przekroczenie limitu czasu klienta |
| BUG-101628 | HIVE-19331 | Replikacja przyrostowa hive do chmury nie powiodła się. |
| BUG-102048 | HIVE-19381 | Replikacja funkcji Hive do chmury kończy się niepowodzeniem z funkcją FunctionTask |
| BUG-102064 | Nie dotyczy | Testy replikacji \[ onprem to onprem \] hive nie powiodły się w narzędziu ReplCopyTask |
| BUG-102137 | HIVE-19423 | Testy replikacji \[ Onprem to Cloud \] hive nie powiodły się w narzędziu ReplCopyTask |
| BUG-102305 | HIVE-19430 | Zrzuty OOM magazynu metadanych HS2 i hive |
| BUG-102361 | Nie dotyczy | wiele wstawień powoduje zreplikowanie pojedynczego wstawiania do docelowego klastra hive ( onprem - s3 ) |
| BUG-87624 | Nie dotyczy | Włączenie rejestrowania zdarzeń storm powoduje, że pracownicy stale umierają |
| BUG-88929 | HBASE-15615 | Niewłaściwy czas uśpienia, gdy element RegionServerCallable wymaga ponowienia próby |
| BUG-89628 | HIVE-17613 | usuwanie pul obiektów dla krótkich alokacji tego samego wątku |
| BUG-89813 | Nie dotyczy | Analiza głównej przyczyny: Poprawność kodu: metoda niezsynchronizowana zastępuje zsynchronizowaną metodę |
| BUG-90437 | ZEPPELIN-3072 | Interfejs użytkownika zeppelin staje się powolny/nie odpowiada, jeśli istnieje zbyt wiele notesów |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() powinien poczekać na zakończenie współbieżnego regionu#flush() |
| BUG-91202 | HIVE-17013 | Żądanie usuwania z podzapytaniem na podstawie wyboru w widoku |
| BUG-91350 | KNOX-1108 | NiFiHaDispatch nie kończy się niepowodzeniem |
| BUG-92054 | HIVE-13120 | propagacja uczenia maszynowego podczas generowania podziałów ORC |
| BUG-92373 | FALCON-2314 | Bump TestNG w wersji do 6.13.1, aby uniknąć zależności programu BeanShell |
| BUG-92381 | Nie dotyczy | testContainerLogsWithNewAPI i testContainerLogsWithOldAPI UT kończy się niepowodzeniem |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT kończy się niepowodzeniem z powodu błędu NullPointerException |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Aktualizacja Spark2 do wersji 2.2.1 (16 stycznia) |
| BUG-92680 | ATLAS-2288 | Wyjątek NoClassDefFoundError podczas uruchamiania skryptu import-hive podczas tworzenia tabeli hbase za pośrednictwem programu Hive |
| BUG-92760 | ACCUMULO-4578 | Anulowanie operacji kompaktowania FATE nie zwalnia blokady przestrzeni nazw |
| BUG-92797 | HDFS-10267, HDFS-8496 | Zmniejszenie rywalizacji o blokadę węzła danych w niektórych przypadkach użycia |
| BUG-92813 | FLUME-2973 | Zakleszczenie w ujściu hdfs |
| BUG-92957 | HIVE-11266 | count(*) nieprawidłowy wynik na podstawie statystyk tabeli dla tabel zewnętrznych |
| BUG-93018 | ATLAS-2310 | W wysokiej dostępności węzeł pasywny przekierowuje żądanie z nieprawidłowym kodowaniem adresu URL |
| BUG-93116 | RANGER-1957 | Program Ranger Usersync nie synchronizuje użytkowników ani grup okresowo po włączeniu synchronizacji przyrostowej. |
| BUG-93361 | HIVE-12360 | Zły wyszukiwanie w nieskompresowanym ORC z predykatem pushdown |
| BUG-93426 | CALCITE-2086 | HTTP/413 w pewnych okolicznościach z powodu dużych nagłówków autoryzacji |
| BUG-93429 | PHOENIX-3240 | ClassCastException from Pig loader (KlasaCastException z modułu ładującego Pig) |
| BUG-93485 | Nie dotyczy | Nie można pobrać tabeli mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException: Nie można odnaleźć tabeli podczas uruchamiania tabeli analizy kolumn w usłudze LLAP |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: kod odpowiedzi 500 — Wykonywanie zadania platformy Spark w celu nawiązania połączenia z serwerem zapytań phoenix i załadowania danych |
| BUG-93550 | Nie dotyczy | Zeppelin %spark.r nie działa z platformą Spark1 z powodu niezgodności wersji scala |
| BUG-93910 | HIVE-18293 | Program Hive nie kompaktuje tabel zawartych w folderze, który nie jest własnością tożsamości z uruchomionym programem HiveMetaStore |
| BUG-93926 | ZEPPELIN-3114 | Notesy i interpretery nie są zapisywane w zeppelin po >testowaniu obciążenia 1d |
| BUG-93932 | ATLAS-2320 | klasyfikacja "*" z zapytaniem zgłasza wyjątek 500 Wewnętrzny serwer. |
| BUG-93948 | YARN-7697 | Nm spada z OOM z powodu wycieku w agregacji dzienników (część 1) |
| BUG-93965 | ATLAS-2229 | Wyszukiwanie DSL: atrybut nieciągowy orderby zgłasza wyjątek |
| BUG-93986 | YARN-7697 | Nm ulegnie awarii z powodu wycieku w agregacji dzienników (część 2) |
| BUG-94030 | ATLAS-2332 | Tworzenie typu z atrybutami z zagnieżdżonym typem danych kolekcji kończy się niepowodzeniem |
| BUG-94080 | YARN-3742, YARN-6061 | Obie maszyny RM są w stanie wstrzymania w bezpiecznym klastrze |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException w log4j2.x bibliotece |
| BUG-94168 | Nie dotyczy | Usługa Yarn RM ulega awarii z powodu błędu rejestru usług |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | System plików HDFS powinien obsługiwać wiele KMS Uris |
| BUG-94345 | HIVE-18429 | Kompaktowanie powinno obsługiwać przypadek, gdy nie generuje żadnych danych wyjściowych |
| BUG-94372 | ATLAS-2229 | Zapytanie DSL: hive_table name = ["t1","t2"] zgłasza nieprawidłowy wyjątek zapytania DSL |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Obsługa żądaniaHedgingProxyProvider RetryAction order: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | Program CompactorMR powinien wywołać metodę jobclient.close(), aby wyzwolić czyszczenie |
| BUG-94575 | SPARK-22587 | Zadanie platformy Spark kończy się niepowodzeniem, jeśli plik fs.defaultFS i plik jar aplikacji są innym adresem URL |
| BUG-94791 | SPARK-22793 | Wyciek pamięci na serwerze Spark Thrift |
| BUG-94928 | HDFS-11078 | Naprawianie serwera NPE w pliku LazyPersistFileScrubber |
| BUG-95013 | HIVE-18488 | W czytnikach ORC protokołu LLAP brakuje niektórych kontroli wartości null |
| BUG-95077 | HIVE-14205 | Program Hive nie obsługuje typu unii z formatem pliku AVRO |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend nie powinien ufać częściowo zaufanemu kanałowi |
| BUG-95201 | HDFS-13060 | Dodawanie elementu BlacklistBasedTrustedChannelResolver dla elementu TrustedChannelResolver |
| BUG-95284 | HBASE-19395 | [gałąź-1] Błąd TestEndToEndSplitTransaction.testMasterOpsWhileSplitting z serwerem NPE |
| BUG-95301 | HIVE-18517 | Wektoryzacja: Poprawiono VectorMapOperator, aby akceptować stosy VRB i sprawdzać flagę wektoryzowaną poprawnie w celu obsługi buforowania LLAP |
| BUG-95542 | HBASE-16135 | Element PeerClusterZnode pod numerem rs usuniętego elementu równorzędnego nigdy nie może zostać usunięty |
| BUG-95595 | HIVE-15563 | Ignoruj wyjątek przejścia stanu nielegalnej operacji w pliku SQLOperation.runQuery, aby uwidocznić rzeczywisty wyjątek. |
| BUG-95596 | YARN-4126, YARN-5750 | Niepowodzenie usługi TestClientRMService |
| BUG-96019 | HIVE-18548 | Naprawianie log4j importu |
| BUG-96196 | HDFS-13120 | Różnice migawek mogą być uszkodzone po concat |
| BUG-96289 | HDFS-11701 | Serwer NPE z nierozwiązanego hosta powoduje trwałe błędy dfSInputStream |
| BUG-96291 | STORM-2652 | Wyjątek zgłoszony w metodzie open JmsSpout |
| BUG-96363 | HIVE-18959 | Unikaj tworzenia dodatkowej puli wątków w ramach protokołu LLAP |
| BUG-96390 | HDFS-10453 | Wątek ReplicationMonitor może być zablokowany przez długi czas z powodu wyścigu między replikacją a usunięciem tego samego pliku w dużym klastrze. |
| BUG-96454 | YARN-4593 | Zakleszczenie w pliku AbstractService.getConfig() |
| BUG-96704 | FALCON-2322 | KlasaCastException podczas przesyłania kanału informacyjnegoAndSchedule |
| BUG-96720 | SLIDER-1262 | Testy functestów suwaka kończą się niepowodzeniem w Kerberized środowisku |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Aktualizacja Spark2 aktualna (19 lutego) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor wykonuje wadliwą konwersję |
| BUG-97244 | KNOX-1083 | Domyślny limit czasu httpClient powinien być rozsądną wartością |
| BUG-97459 | ZEPPELIN-3271 | Opcja wyłączania harmonogramu |
| BUG-97511 | KNOX-1197 | Funkcja AnonymousAuthFilter nie jest dodawana, gdy uwierzytelnianie=Anonimowe w usłudze |
| BUG-97601 | HIVE-17479 | Katalogi przejściowe nie są czyszczone dla zapytań aktualizacji/usuwania |
| BUG-97605 | HIVE-18858 | Właściwości systemu w konfiguracji zadania nie są rozpoznawane podczas przesyłania zadania mr |
| BUG-97674 | OOZIE-3186 | Oozie nie może użyć konfiguracji połączonej przy użyciu jceks://file/... |
| BUG-97743 | Nie dotyczy | java.lang.NoClassDefFoundError wyjątek podczas wdrażania topologii storm |
| BUG-97756 | PHOENIX-4576 | Naprawiono niepowodzenie testów LocalIndexSplitMergeIT |
| BUG-97771 | HDFS-11711 | Nazwa wyróżniająca nie powinna usuwać bloku W przypadku wyjątku "Zbyt wiele otwartych plików" |
| BUG-97869 | KNOX-1190 | Knox Obsługa logowania jednokrotnego dla usługi Google OIDC jest uszkodzona. |
| BUG-97879 | PHOENIX-4489 | Wyciek połączenia HBase w phoenix MR Jobs |
| BUG-98392 | RANGER-2007 | Nie można odnowić biletu protokołu Kerberos narzędzia ranger-tagsync |
| BUG-98484 | Nie dotyczy | Replikacja przyrostowa hive do chmury nie działa |
| BUG-98533 | HBASE-19934, HBASE-20008 | Przywracanie migawki bazy danych HBase kończy się niepowodzeniem z powodu wyjątku wskaźnika null |
| BUG-98555 | PHOENIX-4662 | Wyjątek NullPointerException w TableResultIterator.java ponownego wyślij do pamięci podręcznej |
| BUG-98579 | HBASE-13716 | Przestań używać fsConstants usługi Hadoop |
| BUG-98705 | KNOX-1230 | Wiele współbieżnych żądań powoduje Knox mangling adresu URL |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch nie kończy się niepowodzeniem |
| BUG-99107 | HIVE-19054 | Replikacja funkcji używa "hive.repl.replica.functions.root.dir" jako katalogu głównego |
| BUG-99145 | RANGER-2035 | Błędy podczas uzyskiwania dostępu do definicji usługi przy użyciu pustej klasy implClass z zapleczem Oracle |
| BUG-99160 | SLIDER-1259 | Suwak nie działa w środowiskach z wieloma domami |
| BUG-99239 | ATLAS-2462 | Importowanie sqoop dla wszystkich tabel zgłasza serwer NPE bez tabeli podanej w poleceniu |
| BUG-99301 | ATLAS-2530 | Newline na początku atrybutu name hive_process i hive_column_lineage |
| BUG-99453 | HIVE-19065 | Sprawdzanie zgodności klienta magazynu metadanych powinno obejmować synchronizacjęMetaStoreClient |
| BUG-99521 | Nie dotyczy | Usługa ServerCache dla funkcji HashJoin nie jest ponownie tworzona, gdy iteratory są ponownie potwierdzane |
| BUG-99590 | PHOENIX-3518 | Przeciek pamięci w renewLeaseTask |
| BUG-99618 | SPARK-23599, SPARK-23806 | Aktualizacja Spark2 do wersji 2.3.0+ (3/28) |
| BUG-99672 | ATLAS-2524 | Haczyk Hive z powiadomieniami w wersji 2 — niepoprawna obsługa operacji "alter view as" |
| BUG-99809 | HBASE-20375 | Usuwanie użycia polecenia getCurrentUserCredentials w module hbase-spark |
Możliwości obsługi
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-87343 | HIVE-18031 | Obsługa replikacji operacji Alter Database. |
| BUG-91293 | RANGER-2060 | Knox serwer proxy z knox-sso programem nie działa w przypadku platformy Ranger |
| BUG-93116 | RANGER-1957 | Program Ranger Usersync nie synchronizuje użytkowników ani grup okresowo po włączeniu synchronizacji przyrostowej. |
| BUG-93577 | RANGER-1938 | Rozwiązanie Solr w przypadku konfiguracji inspekcji nie używa skutecznie plików DocValues |
| BUG-96082 | RANGER-1982 | Ulepszenie błędu dla metryki analizy dla administratora ranger i platformy Ranger Kms |
| BUG-96479 | HDFS-12781 | Po Datanode dół na karcie Interfejs DatanodeNamenode użytkownika jest zgłaszany komunikat ostrzegawczy. |
| BUG-97864 | HIVE-18833 | Automatyczne scalanie kończy się niepowodzeniem, gdy "wstaw do katalogu jako plik orcfile" |
| BUG-98814 | HDFS-13314 | Węzeł NameNode powinien opcjonalnie zakończyć działanie, jeśli wykryje uszkodzenie fsImage |
Uaktualnienie
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100134 | SPARK-22919 | Przywracanie "Bump Apache httpclient versions" |
| BUG-95823 | Nie dotyczy | Knox:Upgrade Beanutils |
| BUG-96751 | KNOX-1076 | Zaktualizuj nimbus-jose-jwt do wersji 4.41.2 |
| BUG-97864 | HIVE-18833 | Automatyczne scalanie kończy się niepowodzeniem, gdy "wstaw do katalogu jako plik orcfile" |
| BUG-99056 | HADOOP-13556 | Zmień wartość Configuration.getPropsWithPrefix, aby użyć polecenia getProps zamiast iteratora |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Narzędzie migracji do eksportowania danych atlasu w grafowej bazie danych Titan |
Użyteczność
| Identyfikator usterki | Apache JIRA | Podsumowanie |
|---|---|---|
| BUG-100045 | HIVE-19056 | IllegalArgumentException w pliku FixAcidKeyIndex, gdy plik ORC ma 0 wierszy |
| BUG-100139 | KNOX-1243 | Normalizacja wymaganych nazw DN skonfigurowanych w KnoxToken usłudze |
| BUG-100570 | ATLAS-2557 | Poprawka umożliwiająca zezwalanie na lookup grupy hadoop ldap , gdy grupy z interfejsu UGI są niepoprawnie ustawione lub nie są puste |
| BUG-100646 | ATLAS-2102 | Ulepszenia interfejsu użytkownika usługi Atlas: strona wyników wyszukiwania |
| BUG-100737 | HIVE-19049 | Dodawanie obsługi polecenia Alter table add columns for Druid |
| BUG-100750 | KNOX-1246 | Zaktualizuj konfigurację usługi w programie Knox , aby obsługiwać najnowsze konfiguracje dla platformy Ranger. |
| BUG-100965 | ATLAS-2581 | Regresja przy użyciu powiadomień punktów zaczepienia Hive w wersji 2: Przenoszenie tabeli do innej bazy danych |
| BUG-84413 | ATLAS-1964 | Interfejs użytkownika: obsługa zamawiania kolumn w tabeli wyszukiwania |
| BUG-90570 | HDFS-11384, HDFS-12347 | Dodaj opcję dla usługi balancer w celu rozproszenia wywołań getBlocks, aby uniknąć rpc węzła NameNode. Skok callQueueLength |
| BUG-90584 | HBASE-19052 | FixedFileTrailer powinien rozpoznawać klasę CellComparatorImpl w gałęzi-1.x |
| BUG-90979 | KNOX-1224 | Knox Serwer proxy HADispatcher do obsługi usługi Atlas w wysokiej dostępności. |
| BUG-91293 | RANGER-2060 | Knox serwer proxy z logowaniem jednokrotnym knox-sso nie działa w przypadku platformy Ranger |
| BUG-92236 | ATLAS-2281 | Zapisywanie zapytań filtru atrybutów tagu/typu z filtrami o wartości null/nie null. |
| BUG-92238 | ATLAS-2282 | Zapisane ulubione wyszukiwanie jest wyświetlane tylko po odświeżeniu po utworzeniu, gdy istnieje 25+ ulubione wyszukiwania. |
| BUG-92333 | ATLAS-2286 | Wstępnie utworzony typ "kafka_topic" nie powinien deklarować atrybutu "topic" jako unikatowego |
| BUG-92678 | ATLAS-2276 | Wartość ścieżki dla jednostki typu hdfs_path jest ustawiona na małe litery z mostka hive. |
| BUG-93097 | RANGER-1944 | Filtr akcji dla inspekcji administratora nie działa |
| BUG-93135 | HIVE-15874, HIVE-18189 | Zapytanie Hive zwraca nieprawidłowe wyniki po ustawieniu wartości hive.groupby.orderby.position.alias na true |
| BUG-93136 | HIVE-18189 | Kolejność według pozycji nie działa, gdy cbo jest wyłączona |
| BUG-93387 | HIVE-17600 | Utwórz tabelę "enforceBufferSize" w pliku OrcFile. |
| BUG-93495 | RANGER-1937 | Usługa Ranger tagsync powinna przetwarzać ENTITY_CREATE powiadomienia, aby obsługiwać funkcję importowania usługi Atlas |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: kod odpowiedzi 500 — Wykonywanie zadania platformy Spark w celu nawiązania połączenia z serwerem zapytań phoenix i załadowania danych |
| BUG-93801 | HBASE-19393 | HTTP 413 FULL head podczas uzyskiwania dostępu do interfejsu użytkownika bazy danych HBase przy użyciu protokołu SSL. |
| BUG-93804 | HIVE-17419 | ANALIZUJ TABELĘ... POLECENIE COMPUTE STATISTICS FOR COLUMNS (STATYSTYKI OBLICZENIOWE DLA KOLUMN) pokazuje obliczone statystyki dla zamaskowanych tabel |
| BUG-93932 | ATLAS-2320 | klasyfikacja "*" z zapytaniem zgłasza wyjątek 500 Wewnętrzny serwer. |
| BUG-93933 | ATLAS-2286 | Wstępnie utworzony typ "kafka_topic" nie powinien deklarować atrybutu "topic" jako unikatowego |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | Aktualizacje interfejsu użytkownika dla klasyfikacji |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Podstawowe ulepszenia wyszukiwania w celu opcjonalnego wykluczania jednostek podtypu i podkatafikacyjnych typów |
| BUG-93944 | ATLAS-2318 | Interfejs użytkownika: po dwukrotnym kliknięciu tagu podrzędnego jest zaznaczony tag nadrzędny |
| BUG-93946 | ATLAS-2319 | Interfejs użytkownika: usunięcie tagu, który na 25+ pozycji na liście tagów w strukturze płaskiej i drzewa wymaga odświeżenia, aby usunąć tag z listy. |
| BUG-93977 | HIVE-16232 | Obsługa obliczeń statystyk dla kolumny w quotedIdentifier |
| BUG-94030 | ATLAS-2332 | Tworzenie typu z atrybutami z zagnieżdżonym typem danych kolekcji kończy się niepowodzeniem |
| BUG-94099 | ATLAS-2352 | Serwer Atlas powinien zapewnić konfigurację, aby określić ważność protokołu Kerberos DelegationToken |
| BUG-94280 | HIVE-12785 | Widok z typem unii i funkcją UDF do rzutowania, struktura jest uszkodzona |
| BUG-94332 | SQOOP-2930 | Plik exec zadania sqoop nie zastępuje zapisanych właściwości ogólnych zadania |
| BUG-94428 | Nie dotyczy | Dataplane Obsługa interfejsu API Knox REST agenta profilera |
| BUG-94514 | ATLAS-2339 | Interfejs użytkownika: modyfikacje w "kolumnach" w widoku wyników wyszukiwania podstawowego wpływają również na rozszerzenie DSL. |
| BUG-94515 | ATLAS-2169 | Żądanie usuwania kończy się niepowodzeniem po skonfigurowaniu usuwania twardego |
| BUG-94518 | ATLAS-2329 | Jeśli użytkownik kliknie inny tag, który jest niepoprawny, pojawi się wiele aktywów interfejsu użytkownika usługi Atlas |
| BUG-94519 | ATLAS-2272 | Zapisz stan przeciąganych kolumn przy użyciu interfejsu API zapisywania wyszukiwania. |
| BUG-94627 | HIVE-17731 | dodawanie opcji wstecz compat dla użytkowników zewnętrznych do programu HIVE-11985 |
| BUG-94786 | HIVE-6091 | Puste pipeout pliki są tworzone na potrzeby tworzenia/zamykania połączenia |
| BUG-94793 | HIVE-14013 | Opis tabeli nie pokazuje poprawnie unicode |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Ustaw plik spark.yarn.jars, aby naprawić platformę Spark 2.0 przy użyciu usługi Oozie |
| BUG-94901 | HBASE-19285 | Dodawanie histogramów opóźnienia dla tabeli |
| BUG-94908 | ATLAS-1921 | Interfejs użytkownika: wyszukiwanie przy użyciu atrybutów jednostki i cech: interfejs użytkownika nie wykonuje sprawdzania zakresu i umożliwia udostępnianie wartości poza granicami dla typów danych całkowitych i zmiennoprzecinkowych. |
| BUG-95086 | RANGER-1953 | ulepszenie listy stron grupy użytkowników |
| BUG-95193 | SLIDER-1252 | Agent suwaka kończy się niepowodzeniem z błędami weryfikacji protokołu SSL w języku Python 2.7.5-58 |
| BUG-95314 | YARN-7699 | queueUsagePercentage jest przychodzący jako INF dla getApp wywołania interfejsu API REST |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Przypisywanie tabel systemowych do serwerów z najwyższą wersją |
| BUG-95392 | ATLAS-2421 | Aktualizacje powiadomień do obsługi struktur danych w wersji 2 |
| BUG-95476 | RANGER-1966 | Inicjalizacja aparatu zasad nie tworzy w niektórych przypadkach wzbogacenia kontekstu |
| BUG-95512 | HIVE-18467 | obsługa całego zrzutu magazynu / ładowania + tworzenia/upuszczania zdarzeń bazy danych |
| BUG-95593 | Nie dotyczy | Rozszerzanie narzędzia Oozie DB w celu obsługi Spark2sharelib tworzenia |
| BUG-95595 | HIVE-15563 | Ignoruj wyjątek przejścia stanu nielegalnej operacji w pliku SQLOperation.runQuery, aby uwidocznić rzeczywisty wyjątek. |
| BUG-95685 | ATLAS-2422 | Eksportowanie: Obsługa eksportu opartego na typach |
| BUG-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Nie używaj przewodników do wykonywania zapytań szeregowo |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Widok podzielony na partycje kończy się niepowodzeniem z błędem: IndexOutOfBoundsException Index: 1, Rozmiar: 1 |
| BUG-96019 | HIVE-18548 | Naprawianie log4j importu |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Backport HBase Backup/Restore 2.0 |
| BUG-96313 | KNOX-1119 | Pac4J Jednostka OAuth/OpenID musi być konfigurowalna |
| BUG-96365 | ATLAS-2442 | Użytkownik z uprawnieniami tylko do odczytu w zasobie jednostki nie może wykonać wyszukiwania podstawowego |
| BUG-96479 | HDFS-12781 | Po Datanode dół na karcie Interfejs DatanodeNamenode użytkownika jest zgłaszany komunikat ostrzegawczy. |
| BUG-96502 | RANGER-1990 | Dodawanie jednokierunkowej obsługi protokołu SSL MySQL w usłudze Ranger Admin |
| BUG-96718 | ATLAS-2439 | Aktualizowanie punktu zaczepienia Sqoop w celu korzystania z powiadomień w wersji 2 |
| BUG-96748 | HIVE-18587 | wstawianie zdarzenia DML może próbować obliczyć sumę kontrolną dla katalogów |
| BUG-96821 | HBASE-18212 | W trybie autonomicznym z lokalnym systemem plików HBase rejestruje komunikat ostrzegawczy: Nie można wywołać metody "unbuffer" w klasie org.apache.hadoop.fs.FSDataInputStream |
| BUG-96847 | HIVE-18754 | STAN REPL powinien obsługiwać klauzulę "with" |
| BUG-96873 | ATLAS-2443 | Przechwyć wymagane atrybuty jednostki w wychodzących komunikatach DELETE |
| BUG-96880 | SPARK-23230 | Jeśli format hive.default.fileformat jest innym rodzajem typów plików, utwórz textfile tabelę powodującą serde błąd |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Ulepszanie analizowania opcji platformy Spark |
| BUG-97100 | RANGER-1984 | Rekordy dziennika inspekcji bazy danych HBase mogą nie pokazywać wszystkich tagów skojarzonych z dostępem do kolumny |
| BUG-97110 | PHOENIX-3789 | Wykonywanie wywołań konserwacji indeksu między regionami w pliku postBatchMutateIndispensably |
| BUG-97145 | HIVE-12245, HIVE-17829 | Obsługa komentarzy kolumn dla tabeli opartej na bazie HBase |
| BUG-97409 | HADOOP-15255 | Obsługa konwersji wyższej/małej litery dla nazw grup w ldapGroupsMapping |
| BUG-97535 | HIVE-18710 | rozszerzanie dziedziczyćPerms do ACID w Hive 2.X |
| BUG-97742 | OOZIE-1624 | Wzorzec wykluczeń dla sharelib reguł JAR |
| BUG-97744 | PHOENIX-3994 | Priorytet RPC indeksu nadal zależy od właściwości fabryki kontrolera w hbase-site.xml |
| BUG-97787 | HIVE-18460 | Kompakt nie przekazuje właściwości tabeli do modułu zapisywania orc |
| BUG-97788 | HIVE-18613 | Rozszerzanie funkcji JsonSerDe w celu obsługi typu binarnego |
| BUG-97899 | HIVE-18808 | Zwiększenie niezawodności kompaktowania w przypadku niepowodzenia aktualizacji statystyk |
| BUG-98038 | HIVE-18788 | Czyszczenie danych wejściowych w JDBC PreparedStatement |
| BUG-98383 | HIVE-18907 | Tworzenie narzędzia w celu rozwiązania problemu z indeksem kluczy kwasu z programu HIVE-18817 |
| BUG-98388 | RANGER-1828 | Dobra praktyka kodowania — dodawanie kolejnych nagłówków w ranger |
| BUG-98392 | RANGER-2007 | Nie można odnowić biletu protokołu Kerberos narzędzia ranger-tagsync |
| BUG-98533 | HBASE-19934, HBASE-20008 | Przywracanie migawki bazy danych HBase kończy się niepowodzeniem z powodu wyjątku wskaźnika null |
| BUG-98552 | HBASE-18083, HBASE-18084 | Ustaw duży/mały numer wątku na czysty wątek konfigurowalny w HFileCleaner |
| BUG-98705 | KNOX-1230 | Wiele współbieżnych żądań powoduje Knox mangling adresu URL |
| BUG-98711 | Nie dotyczy | Wysyłanie niFi nie może używać dwukierunkowego protokołu SSL bez service.xml modyfikacji |
| BUG-98880 | OOZIE-3199 | Zezwalaj na konfigurowanie ograniczeń właściwości systemowych |
| BUG-98931 | ATLAS-2491 | Aktualizowanie punktu zaczepienia programu Hive w celu korzystania z powiadomień usługi Atlas w wersji 2 |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch nie kończy się niepowodzeniem |
| BUG-99088 | ATLAS-2511 | Udostępnianie opcji selektywnego importowania bazy danych/tabel z programu Hive do usługi Atlas |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Zapytanie platformy Spark nie powiodło się z wyjątkiem "java.io.FileNotFoundException: hive-site.xml (odmowa uprawnień)" |
| BUG-99239 | ATLAS-2462 | Importowanie sqoop dla wszystkich tabel zgłasza serwer NPE bez tabeli podanej w poleceniu |
| BUG-99636 | KNOX-1238 | Naprawianie niestandardowych ustawień magazynu zaufania dla bramy |
| BUG-99650 | KNOX-1223 | Serwer proxy zeppelin Knox nie przekierowuje /api/ticket zgodnie z oczekiwaniami |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain i SparkMain nie powinny zastępować właściwości i plików konfiguracji lokalnie |
| BUG-99805 | OOZIE-2885 | Uruchamianie akcji platformy Spark nie powinno wymagać programu Hive na ścieżce klas |
| BUG-99806 | OOZIE-2845 | Zastąp kod oparty na odbiciu, który ustawia zmienną w programie HiveConf |
| BUG-99807 | OOZIE-2844 | Zwiększ stabilność akcji Oozie, gdy log4jbrakuje właściwości lub nie można ich odczytać |
| RMP-9995 | AMBARI-22222 | Przełącz druid, aby użyć katalogu /var/druid zamiast /apps/druid na dysku lokalnym |
Zmiany zachowań
| Składnik Apache | Apache JIRA | Podsumowanie | Szczegóły |
|---|---|---|---|
| Spark 2.3 | Nie dotyczy | Zmiany opisane w informacjach o wersji platformy Apache Spark | — Istnieje dokument "Wycofanie" i przewodnik "Zmiana zachowania", https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations — W części SQL istnieje inny szczegółowy przewodnik "Migracja" (od 2.2 do 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| platforma Spark | HIVE-12505 | Zadanie platformy Spark zostało ukończone pomyślnie, ale wystąpił pełny błąd przydziału dysku HDFS | Scenariusz: Uruchomienie wstawiania zastępuje się, gdy limit przydziału jest ustawiony w folderze Kosz użytkownika, który uruchamia polecenie. Poprzednie zachowanie: zadanie zakończy się pomyślnie, mimo że nie można przenieść danych do kosza. Wynik może błędnie zawierać niektóre dane, które wcześniej znajdują się w tabeli. Nowe zachowanie: gdy przejście do folderu Kosz nie powiedzie się, pliki zostaną trwale usunięte. |
| Kafka 1.0 | Nie dotyczy | Zmiany opisane w informacjach o wersji platformy Apache Spark | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/ Ranger | Inne zasady hive platformy ranger wymagane dla INSERT OVERWRITE | Scenariusz: Inne zasady hive platformy ranger wymagane dla INSERT OVERWRITE Poprzednie zachowanie: Zapytanie INSERT INSERT OVERWRITE programu Hive powiedzie się jak zwykle. Nowe zachowanie: zapytania INSERT INSERT programu Hive nieoczekiwanie kończą się niepowodzeniem po uaktualnieniu do wersji HDP-2.6.x z powodu błędu: Błąd podczas kompilowania instrukcji: FAILED: HiveAccessControlException Uprawnienie odrzucone: użytkownik jdoe nie ma uprawnień ZAPISU w /tmp/*(state=42000,code=40000) Od wersji HDP-2.6.0 zapytania INSERT OVERWRITE programu Hive wymagają zasad identyfikatora URI platformy Ranger, aby zezwolić na operacje zapisu, nawet jeśli użytkownik ma uprawnienia do zapisu przyznane za pomocą zasad systemu plików HDFS. Obejście/oczekiwane działanie klienta: 1. Utwórz nowe zasady w repozytorium Hive. 2. Na liście rozwijanej, na której zobaczysz pozycję Baza danych, wybierz pozycję Identyfikator URI. 3. Zaktualizuj ścieżkę (przykład: /tmp/*) 4. Dodaj użytkowników i grupę i zapisz. 5. Ponów próbę wstawienia zapytania. |
|
| HDFS | Nie dotyczy | System plików HDFS powinien obsługiwać wiele KMS Uris |
Poprzednie zachowanie: właściwość dfs.encryption.key.provider.uri została użyta do skonfigurowania ścieżki dostawcy usługi KMS. Nowe zachowanie: dfs.encryption.key.provider.uri jest teraz przestarzały na rzecz ścieżki hadoop.security.key.provider.path w celu skonfigurowania ścieżki dostawcy usługi KMS. |
| Zeppelin | ZEPPELIN-3271 | Opcja wyłączania harmonogramu | Składnik, którego dotyczy problem: Zeppelin-Server Poprzednie zachowanie: w poprzednich wersjach zeppelin nie było możliwości wyłączenia harmonogramu. Nowe zachowanie: domyślnie użytkownicy nie będą już widzieć harmonogramu, ponieważ jest on domyślnie wyłączony. Obejście/Oczekiwana akcja klienta: jeśli chcesz włączyć harmonogram, musisz dodać element azeppelin.notebook.cron.enable z wartością true w obszarze niestandardowej witryny zeppelin w ustawieniach rozwiązania Zeppelin z systemu Ambari. |
Znane problemy
Integracja usługi HDInsight z usługą ADLS Gen 2 Istnieją dwa problemy w klastrach ESP usługi HDInsight przy użyciu usługi Azure Data Lake Storage Gen 2 z katalogami użytkowników i uprawnieniami:
Katalogi główne dla użytkowników nie są tworzone w węźle głównym 1. Aby obejść ten problem, należy ręcznie utworzyć katalogi i zmienić własność na nazwę UPN odpowiedniego użytkownika.
Uprawnienia w katalogu /hdp nie są obecnie ustawione na 751. Należy ustawić tę opcję na
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Nieprawidłowy wynik spowodowany przez regułę OptimizeMetadataOnlyQuery
[SPARK-23406] Usterki w samodzielnych sprzężeniach strumienia
Przykładowe notesy platformy Spark nie są dostępne, gdy usługa Azure Data Lake Storage (Gen2) jest domyślnym magazynem klastra.
Pakiet Enterprise Security
- Serwer Spark Thrift nie akceptuje połączeń od klientów ODBC.
Kroki obejścia:
- Poczekaj około 15 minut po utworzeniu klastra.
- Sprawdź interfejs użytkownika ranger pod kątem istnienia hivesampletable_policy.
- Uruchom ponownie usługę Spark. Połączenie usługi STS powinno działać teraz.
- Serwer Spark Thrift nie akceptuje połączeń od klientów ODBC.
Kroki obejścia:
Obejście niepowodzenia sprawdzania usługi Ranger
RANGER-1607: Obejście niepowodzenia sprawdzania usługi Ranger podczas uaktualniania do usługi HDP 2.6.2 z poprzednich wersji usługi HDP.
Uwaga
Tylko wtedy, gdy usługa Ranger jest włączona za pomocą protokołu SSL.
Ten problem występuje podczas próby uaktualnienia do wersji HDP-2.6.1 z poprzednich wersji usługi HDP za pośrednictwem systemu Ambari. System Ambari używa wywołania curl do sprawdzania usługi Ranger w systemie Ambari. Jeśli wersja zestawu JDK używana przez ambari to JDK-1.7, wywołanie curl zakończy się niepowodzeniem z powodu następującego błędu:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failurePrzyczyną tego błędu jest wersja tomcat używana w środowisku Ranger to Tomcat-7.0.7*. Użycie zestawu JDK-1.7 powoduje konflikt z domyślnymi szyframi podanymi w pliku Tomcat-7.0.7*.
Ten problem można rozwiązać na dwa sposoby:
Zaktualizuj zestaw JDK używany w zestawie Ambari z zestawu JDK-1.7 do zestawu JDK-1.8 (zobacz sekcję Zmienianie wersji zestawu JDK w przewodniku referencyjnym systemu Ambari).
Jeśli chcesz kontynuować obsługę środowiska JDK-1.7:
Dodaj właściwość ranger.tomcat.ciphers w sekcji ranger-admin-site w konfiguracji narzędzia Ambari Ranger z następującą wartością:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Jeśli środowisko jest skonfigurowane dla usługi Ranger-KMS, dodaj właściwość ranger.tomcat.ciphers w sekcji theranger-kms-site w konfiguracji narzędzia Ambari Ranger z następującą wartością:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Uwaga
Zanotowane wartości są przykładami roboczymi i mogą nie wskazywać na środowisko. Upewnij się, że sposób ustawiania tych właściwości jest zgodny ze sposobem konfigurowania środowiska.
RangerUI: ucieczka tekstu warunku zasad wprowadzona w formularzu zasad
Składnik, którego dotyczy problem: Ranger
Opis problemu
Jeśli użytkownik chce utworzyć zasady z niestandardowymi warunkami zasad, a wyrażenie lub tekst zawiera znaki specjalne, wymuszanie zasad nie będzie działać. Znaki specjalne są konwertowane na ASCII przed zapisaniem zasad w bazie danych.
Znaki specjalne: & <> " '
Na przykład tagi warunku.attributes['type']='abc' zostaną przekonwertowane na następujące po zapisaniu zasad.
tags.attds[' dsds'] =' cssdfs'
Warunek zasad można wyświetlić z tymi znakami, otwierając zasady w trybie edycji.
Obejście
Opcja 1. Tworzenie/aktualizowanie zasad za pośrednictwem interfejsu API REST platformy Ranger
Adres URL REST: http://< host>:6080/service/plugins/policies
Tworzenie zasad z warunkiem zasad:
W poniższym przykładzie zostaną utworzone zasady z tagami jako "tags-test" i przypisze je do grupy "public" z warunkiem zasad astags.attr['type']=='abc", wybierając wszystkie uprawnienia składnika hive, takie jak select, update, create, drop, alter, index, lock, all.
Przykład:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Zaktualizuj istniejące zasady przy użyciu warunku zasad:
Poniższy przykład spowoduje zaktualizowanie zasad przy użyciu tagów jako "tags-test" i przypisanie ich do grupy "public" z warunkiem zasad astags.attr['type']=='abc", wybierając wszystkie uprawnienia składnika hive, takie jak select, update, create, drop, alter, index, lock, all.
Adres URL REST: http://< host-name>:6080/service/plugins/policies/<policy-id>
Przykład:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Opcja 2. Stosowanie zmian języka JavaScript
Procedura aktualizowania pliku JS:
Dowiedz się, PermissionList.js plik w obszarze /usr/hdp/current/ranger-admin
Zapoznaj się z definicją funkcji renderPolicyCondtion (nr wiersza: 404).
Usuń następujący wiersz z tej funkcji, tj. w obszarze funkcji display (nr wiersza: 434)
val = _.escape(val);//Line No:460
Po usunięciu powyższego wiersza interfejs użytkownika platformy Ranger umożliwi tworzenie zasad z warunkiem zasad, które mogą zawierać znaki specjalne i ocena zasad zakończy się pomyślnie dla tych samych zasad.
Integracja usługi HDInsight z usługą ADLS Gen 2: problemy z katalogami użytkowników i uprawnieniami w klastrach ESP 1. Katalogi główne dla użytkowników nie są tworzone w węźle głównym 1. Obejście polega na utworzeniu tych ręcznie i zmianie własności na nazwę UPN odpowiedniego użytkownika. 2. Uprawnienia w /hdp nie są obecnie ustawione na 751. Musi to być ustawione na a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Wycofanie
Portal pakietu OMS: usunęliśmy link ze strony zasobów usługi HDInsight, która wskazywała portal pakietu OMS. Dzienniki usługi Azure Monitor początkowo używały własnego portalu o nazwie portal pakietu OMS do zarządzania konfiguracją i analizowania zebranych danych. Wszystkie funkcje z tego portalu zostały przeniesione do witryny Azure Portal, w której będzie ona nadal opracowywana. Usługa HDInsight wycofała obsługę portalu pakietu OMS. Klienci będą używać integracji dzienników usługi HDInsight Azure Monitor w witrynie Azure Portal.
Zakończenie obsługi platformy Spark 2.3:Spark w wersji 2.3.0
Uaktualnianie
Wszystkie te funkcje są dostępne w usłudze HDInsight 3.6. Aby uzyskać najnowszą wersję platform Spark, Kafka i R Server (Machine Learning Services), wybierz wersję platformy Spark, platformy Kafka, usług ML podczas tworzenia klastra usługi HDInsight 3.6. Aby uzyskać obsługę usługi ADLS, możesz wybrać typ magazynu usługi ADLS jako opcję. Istniejące klastry nie zostaną automatycznie uaktualnione do tych wersji.
Wszystkie nowe klastry utworzone po czerwcu 2018 r. automatycznie przejdą do 1000+ poprawek błędów we wszystkich projektach typu open source. Postępuj zgodnie z tym przewodnikiem, aby uzyskać najlepsze rozwiązania dotyczące uaktualniania do nowszej wersji usługi HDInsight.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla