Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ punktu końcowego analizy SQL i magazynu danych w usłudze Microsoft Fabric
Pobieranie danych z jeziora danych jest kluczową operacją wejścia/wyjścia (I/O) mającą istotny wpływ na wydajność zapytań. Usługa Fabric Data Warehouse wykorzystuje wyrafinowane wzorce dostępu, aby zwiększyć odczyty danych z magazynu i zwiększyć szybkość wykonywania zapytań. Ponadto inteligentnie minimalizuje potrzebę zdalnego odczytu magazynu dzięki wykorzystaniu lokalnych pamięci podręcznych.
Buforowanie to technika, która poprawia wydajność aplikacji przetwarzających dane poprzez zmniejszenie liczby operacji wejścia-wyjścia. Buforowanie przechowuje często używane dane i metadane w szybszej warstwie magazynu, takiej jak pamięć lokalna lub lokalny dysk SSD, dzięki czemu kolejne żądania mogą być szybciej obsługiwane bezpośrednio z pamięci podręcznej. Jeśli określony zestaw danych był wcześniej uzyskiwany przez zapytanie, wszystkie kolejne zapytania pobierają te dane bezpośrednio z pamięci podręcznej w pamięci. Takie podejście znacznie zmniejsza opóźnienie IO, ponieważ operacje pamięci lokalnej są znacznie szybsze w porównaniu z pobieraniem danych z zdalnej pamięci masowej.
Buforowanie w pamięci i na dysku w magazynie danych Fabric jest w pełni przezroczyste dla użytkownika. Niezależnie od źródła, niezależnie od tego, czy jest to tabela magazynu, skrót OneLake, czy nawet skrót OneLake odwołujący się do usług innych niż azure, zapytanie buforuje wszystkie dane, do których uzyskuje dostęp.
Istnieją dwa typy pamięci podręcznych opisanych w dalszej części tego artykułu: pamięć podręczna w pamięci i pamięć podręczna dysku. Buforowanie zestawu wyników zostało omówione w innym artykule.
Cache w pamięci
Gdy zapytanie uzyskuje dostęp do magazynu i pobiera dane z niego, wykonuje proces przekształcania, który transkoduje dane z oryginalnego formatu opartego na plikach w wysoce zoptymalizowanych strukturach w pamięci podręcznej.

Dane w pamięci podręcznej są zorganizowane w skompresowanym formacie kolumnowym zoptymalizowanym pod kątem zapytań analitycznych. Każda kolumna danych jest przechowywana razem, oddzielona od pozostałych, umożliwiając lepszą kompresję, ponieważ podobne wartości danych są przechowywane razem, co prowadzi do zmniejszenia zużycia pamięci. Gdy zapytania muszą wykonywać operacje na określonej kolumnie, takiej jak agregacje lub filtrowanie, aparat może działać wydajniej, ponieważ nie musi przetwarzać niepotrzebnych danych z innych kolumn.
Ponadto ten magazyn kolumnowy sprzyja przetwarzaniu równoległego, co może znacznie przyspieszyć wykonywanie zapytań dla dużych zestawów danych. Aparat może wykonywać operacje na wielu kolumnach jednocześnie, korzystając z nowoczesnych procesorów wielordzeniowych.
Takie podejście jest szczególnie korzystne w przypadku obciążeń analitycznych, w których zapytania obejmują skanowanie dużych ilości danych w celu przeprowadzania agregacji, filtrowania i innych manipulacji danymi.
Pamięć podręczna dysku
Niektóre zestawy danych są zbyt duże, aby pomieścić je w pamięci podręcznej. Aby utrzymać wydajność szybkich zapytań dla tych zestawów danych, data warehouse wykorzystuje miejsce na dysku jako uzupełniające rozszerzenie do pamięci podręcznej. Wszelkie informacje ładowane do pamięci podręcznej w RAM są również serializowane do pamięci podręcznej SSD.
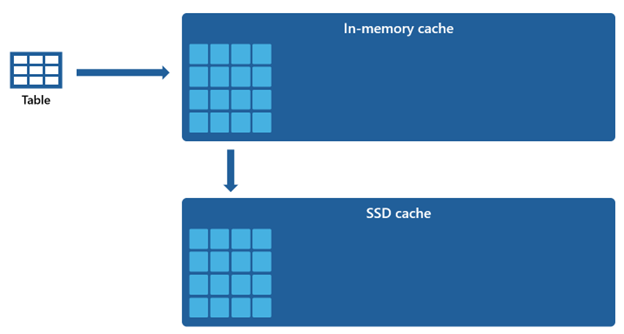
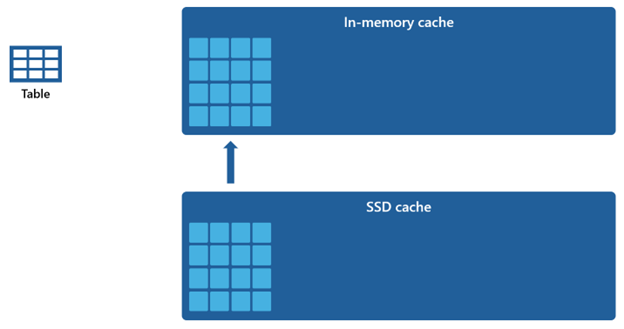
Biorąc pod uwagę, że pamięć podręczna w pamięci ma mniejszą pojemność w porównaniu z pamięcią podręczną SSD, dane usunięte z pamięci podręcznej w pamięci pozostają w pamięci podręcznej SSD przez dłuższy czas. Gdy kolejne zapytanie żąda tych danych, są one pobierane z pamięci podręcznej SSD do cache w pamięci operacyjnej znacznie szybciej niż w przypadku pobierania z magazynu zdalnego, co w efekcie zapewnia bardziej stabilną wydajność zapytań.
Zarządzanie pamięcią podręczną
Buforowanie pozostaje stale aktywne i działa bezproblemowo w tle, nie wymagając interwencji z Twojej strony. Wyłączenie buforowania nie jest potrzebne, ponieważ nieuchronnie doprowadziłoby to do zauważalnego pogorszenia wydajności zapytań.
Mechanizm buforowania jest zorganizowany i utrzymywany przez samą usługę Microsoft Fabric i nie oferuje użytkownikom możliwości ręcznego czyszczenia pamięci podręcznej.
Pełna spójność transakcyjna pamięci podręcznej gwarantuje, że po początkowym załadowaniu danych do pamięci podręcznej wszelkie modyfikacje danych w magazynie, na przykład operacjami DML (Data Manipulation Language), zapewnią spójność danych.
Gdy pamięć podręczna osiągnie próg pojemności, a świeże dane są odczytywane po raz pierwszy, obiekty, które pozostały nieużywane przez najdłuższy czas trwania, zostaną usunięte z pamięci podręcznej. Ten proces jest wprowadzany w celu utworzenia przestrzeni dla napływu nowych danych i utrzymania optymalnej strategii wykorzystania pamięci podręcznej.