Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule pokazano, jak można używać sztucznej inteligencji (AI) z przepływami danych. W tym artykule opisano:
- Cognitive Services
- Zautomatyzowane uczenie maszynowe
- Integracja z usługą Azure Machine Learning
Ważne
Tworzenie modeli zautomatyzowanego uczenia maszynowego (AutoML) usługi Power BI dla przepływów danych w wersji 1 zostało wycofane i nie jest już dostępne. Zachęcamy klientów do migrowania rozwiązania do funkcji automatycznego uczenia maszynowego w usłudze Microsoft Fabric. Aby uzyskać więcej informacji, zobacz ogłoszenie o wycofaniu.
Usługi Cognitive Services w usłudze Power BI
Za pomocą usług Cognitive Services w usłudze Power BI można zastosować różne algorytmy usług Azure Cognitive Services , aby wzbogacić dane w ramach samoobsługowego przygotowywania danych dla przepływów danych.
Obecnie obsługiwane usługi to analiza tonacji, wyodrębnianie kluczowych fraz, wykrywanie języka i tagowanie obrazów. Przekształcenia są wykonywane na usługa Power BI i nie wymagają subskrypcji usług Azure Cognitive Services. Ta funkcja wymaga usługi Power BI Premium.
Włączanie funkcji sztucznej inteligencji
Usługi Cognitive Services są obsługiwane w przypadku węzłów pojemności Premium EM2, A2, P1 lub F64 i innych węzłów z większą ilością zasobów. Usługi Cognitive Services są również dostępne z licencją Premium na użytkownika (PPU). Oddzielne obciążenie sztucznej inteligencji w pojemności jest używane do uruchamiania usług Cognitive Services. Przed rozpoczęciem korzystania z usług Cognitive Services w usłudze Power BI obciążenie sztucznej inteligencji musi być włączone w ustawieniach pojemności portalu administracyjnego. Obciążenie sztucznej inteligencji można włączyć w sekcji obciążenia.
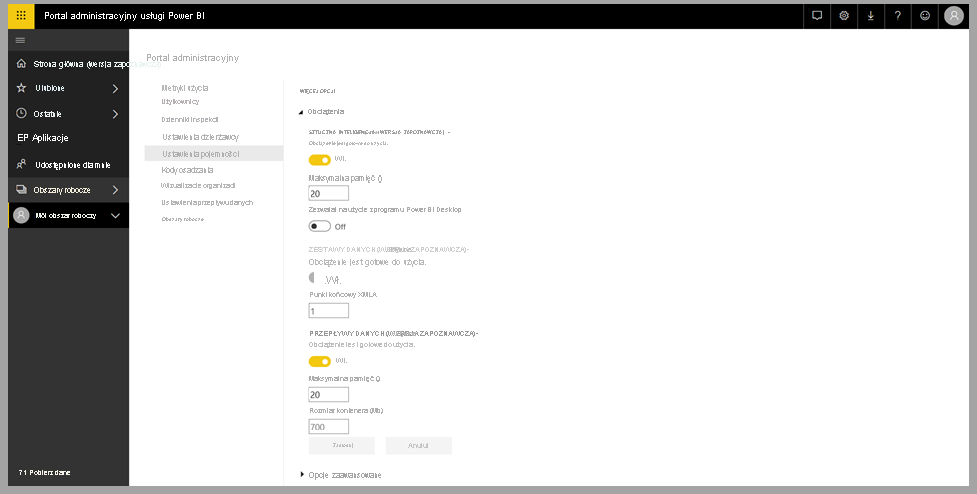
Wprowadzenie do usług Cognitive Services w usłudze Power BI
Przekształcenia usług Cognitive Services są częścią samoobsługowego przygotowywania danych dla przepływów danych. Aby wzbogacić dane za pomocą usług Cognitive Services, zacznij od edytowania przepływu danych.
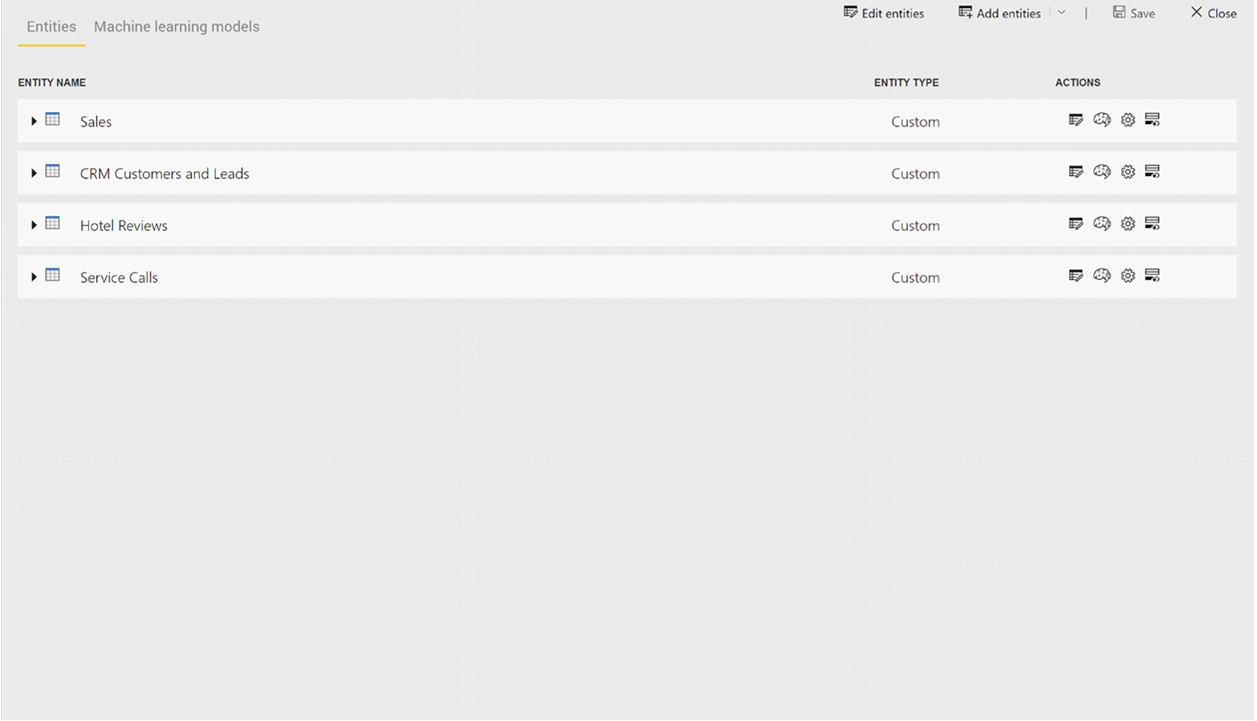
Wybierz przycisk AI Insights na górnej wstążce Edytor Power Query.
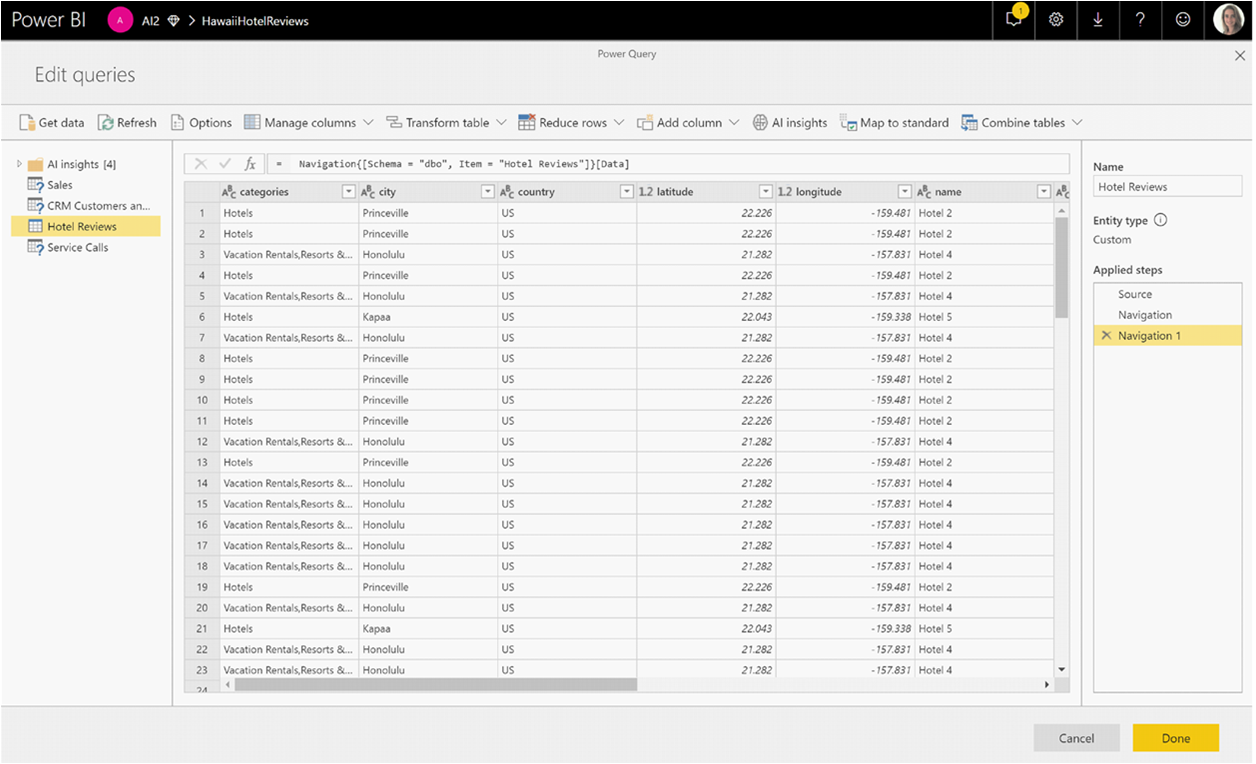
W oknie podręcznym wybierz funkcję, której chcesz użyć, i dane, które chcesz przekształcić. W tym przykładzie jest oceniana tonacja kolumny zawierającej tekst recenzji.
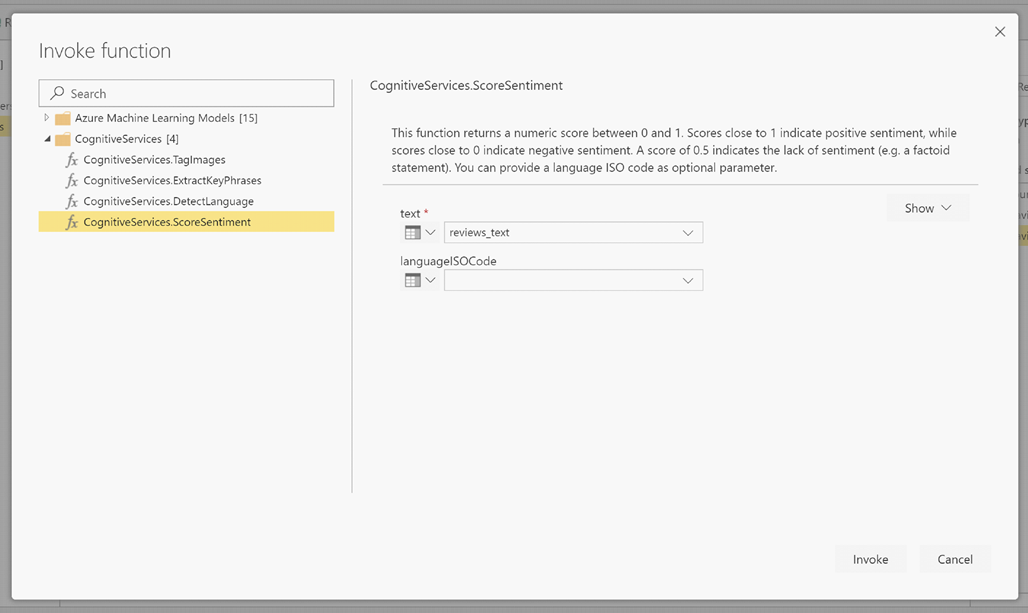
LanguageISOCode to opcjonalne dane wejściowe określające język tekstu. Ta kolumna oczekuje kodu ISO. Możesz użyć kolumny jako danych wejściowych dla elementu LanguageISOCode lub użyć kolumny statycznej. W tym przykładzie język jest określany jako angielski (en) dla całej kolumny. Jeśli pozostawisz tę kolumnę pustą, usługa Power BI automatycznie wykryje język przed zastosowaniem funkcji. Następnie wybierz pozycję Wywołaj.
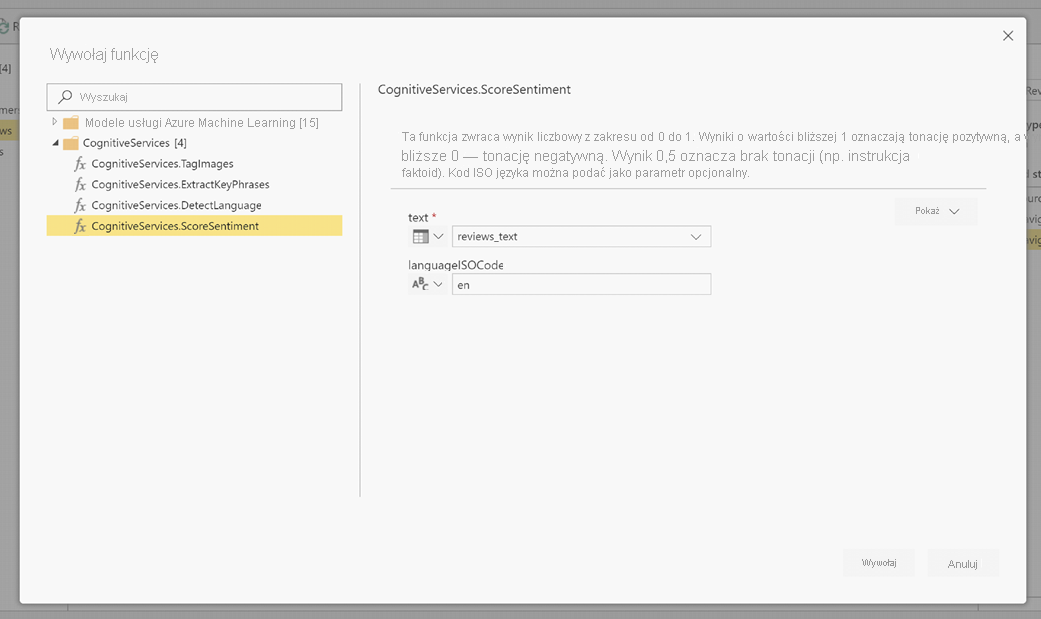
Po wywołaniu funkcji wynik zostanie dodany jako nowa kolumna do tabeli. Przekształcenie jest również dodawane jako zastosowany krok w zapytaniu.
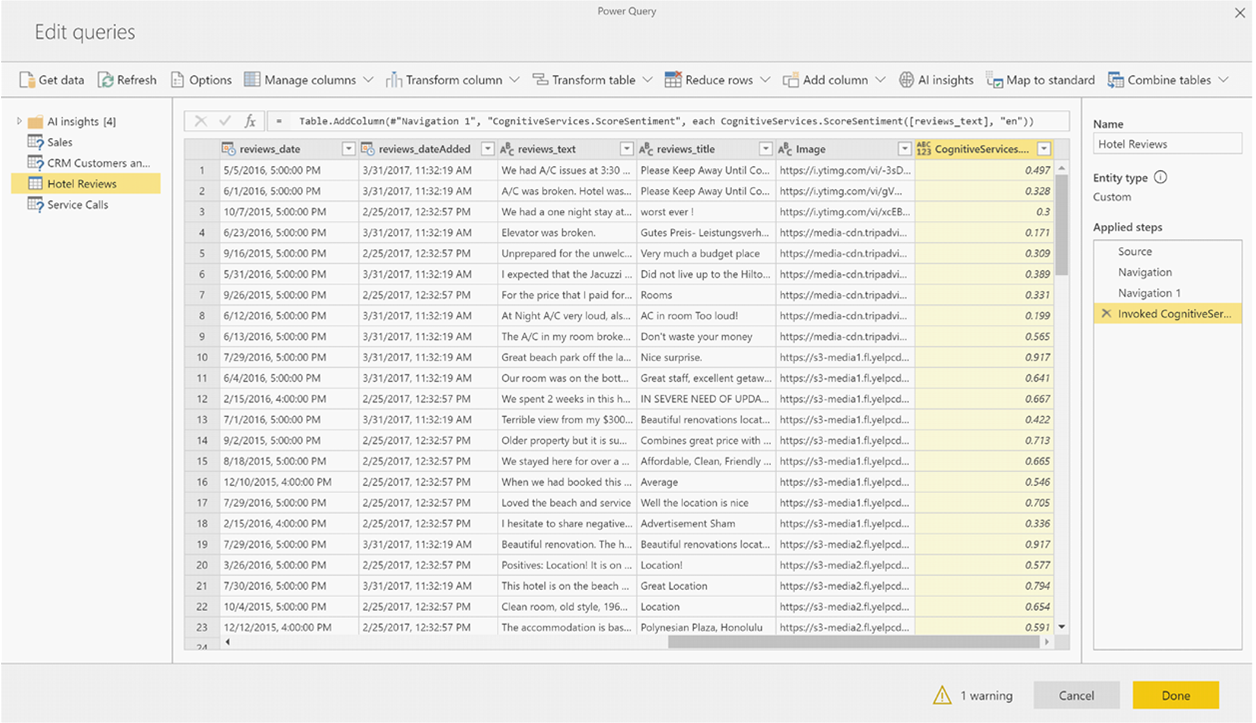
Jeśli funkcja zwraca wiele kolumn wyjściowych, wywołanie funkcji dodaje nową kolumnę z wierszem wielu kolumn wyjściowych.
Użyj opcji rozwijania, aby dodać jedną lub obie wartości jako kolumny do danych.
Dostępne funkcje
W tej sekcji opisano dostępne funkcje w usługach Cognitive Services w usłudze Power BI.
Wykrywanie języka
Funkcja wykrywania języka ocenia wprowadzanie tekstu, a dla każdej kolumny zwraca nazwę języka i identyfikator ISO. Ta funkcja jest przydatna w przypadku kolumn danych, które zbierają dowolny tekst, gdzie język jest nieznany. Funkcja oczekuje danych w formacie tekstowym jako danych wejściowych.
Analiza tekstu rozpoznaje maksymalnie 120 języków. Aby uzyskać więcej informacji, zobacz Co to jest wykrywanie języka w usłudze Azure Cognitive Service for Language.
Wyodrębnianie kluczowych fraz
Funkcja wyodrębniania kluczowych fraz ocenia tekst bez struktury, a dla każdej kolumny tekstowej zwraca listę kluczowych fraz. Funkcja wymaga kolumny tekstowej jako danych wejściowych i akceptuje opcjonalne dane wejściowe dla elementu LanguageISOCode. Aby uzyskać więcej informacji, zobacz Wprowadzenie.
Wyodrębnianie kluczowych fraz działa najlepiej, gdy nadajesz większe fragmenty tekstu do pracy, a nie z analizy tonacji. Analiza tonacji działa lepiej na mniejszych blokach tekstu. Aby uzyskać najlepsze wyniki dla obu operacji, rozważ odpowiednią zmianę struktury danych wejściowych.
Ocenianie tonacji
Funkcja Score Sentiment (Ocena tonacji) ocenia wprowadzanie tekstu i zwraca wynik tonacji dla każdego dokumentu, od 0 (ujemny) do 1 (dodatni). Ta funkcja jest przydatna do wykrywania pozytywnych i negatywnych tonacji w mediach społecznościowych, recenzjach klientów i forach dyskusyjnych.
Analiza tekstu używa algorytmu klasyfikacji uczenia maszynowego do wygenerowania oceny opinii z zakresu od 0 do 1. Wyniki zbliżone do 1 wskazują pozytywną tonację. Wyniki zbliżone do 0 wskazują negatywną tonację. Model jest wstępnie wytrenowany za pomocą obszernej treści tekstu ze skojarzeniami tonacji. Obecnie nie można podać własnych danych szkoleniowych. Model używa kombinacji technik podczas analizy tekstu, w tym przetwarzania tekstu, analizy części mowy, rozmieszczenia słów i skojarzeń słów. Aby uzyskać więcej informacji na temat algorytmu, zobacz Uczenie maszynowe i analiza tekstu.
Analiza tonacji jest wykonywana na całej kolumnie wejściowej, w przeciwieństwie do wyodrębniania tonacji dla określonej tabeli w tekście. W praktyce istnieje tendencja do poprawiania dokładności oceniania, gdy dokumenty zawierają jedno lub dwa zdania, a nie duży blok tekstu. W fazie oceny obiektywności model określa, czy kolumna wejściowa jako całość jest obiektywna, czy zawiera tonację. Kolumna wejściowa, która jest głównie celem, nie przechodzi do frazy wykrywania tonacji, co powoduje wynik 0,50 bez dalszego przetwarzania. W przypadku kolumn wejściowych w potoku następna faza generuje wynik większy lub mniejszy niż 0,50 w zależności od stopnia tonacji wykrytego w kolumnie wejściowej.
Aktualnie analiza tonacji obsługuje angielski, niemiecki, hiszpański i francuski. Inne języki są dostępne w wersji zapoznawczej. Aby uzyskać więcej informacji, zobacz Co to jest wykrywanie języka w usłudze Azure Cognitive Service for Language.
Tagowanie obrazów
Funkcja Tag Images zwraca tagi na podstawie ponad 2000 rozpoznawalnych obiektów, żywych istot, scenerii i akcji. Gdy tagi są niejednoznaczne lub nie są powszechnie znane, dane wyjściowe zawierają "wskazówki", aby wyjaśnić znaczenie tagu w kontekście znanego ustawienia. Tagi nie są zorganizowane jako taksonomia i nie istnieją hierarchie dziedziczenia. Kolekcja tagów zawartości stanowi podstawę „opisu” obrazu wyświetlanego jako język zrozumiały dla użytkownika w formie pełnych zdań.
Po przekazaniu obrazu lub określeniu adresu URL obrazu przetwarzanie obrazów algorytmy wyjściowe tagów na podstawie obiektów, istot żywych i akcji zidentyfikowanych na obrazie. Tagowanie nie jest ograniczone do głównego tematu, na przykład do osoby na pierwszym planie, ale uwzględnia także otoczenie (wewnątrz lub na zewnątrz), meble, narzędzia, rośliny, zwierzęta, akcesoria, gadżety itd.
Ta funkcja wymaga adresu URL obrazu lub kolumnybase-64 jako danych wejściowych. Obecnie tagowanie obrazów obsługuje język angielski, hiszpański, japoński, portugalski i chiński uproszczony. Aby uzyskać więcej informacji, zobacz ComputerVision Interface (Interfejs ComputerVision).
Zautomatyzowane uczenie maszynowe w usłudze Power BI
Zautomatyzowane uczenie maszynowe (AutoML) dla przepływów danych umożliwia analitykom biznesowym trenowanie, weryfikowanie i wywoływanie modeli uczenia maszynowego bezpośrednio w usłudze Power BI. Obejmuje to proste środowisko tworzenia nowego modelu uczenia maszynowego, w którym analitycy mogą używać swoich przepływów danych do określania danych wejściowych na potrzeby trenowania modelu. Usługa automatycznie wyodrębnia najbardziej odpowiednie funkcje, wybiera odpowiedni algorytm, a następnie weryfikuje model uczenia maszynowego. Po wytrenowanym modelu usługa Power BI automatycznie generuje raport wydajności zawierający wyniki weryfikacji. Następnie można wywołać model na dowolnych nowych lub zaktualizowanych danych w przepływie danych.
Zautomatyzowane uczenie maszynowe jest dostępne tylko dla przepływów danych hostowanych w pojemnościach Power BI Premium i Embedded.
Praca z rozwiązaniem AutoML
Uczenie maszynowe i sztuczna inteligencja widzą bezprecedensowy wzrost popularności branż i dziedzin badań naukowych. Firmy szukają również sposobów integrowania tych nowych technologii z operacjami.
Przepływy danych oferują samoobsługowe przygotowywanie danych na potrzeby danych big data. Rozwiązanie AutoML jest zintegrowane z przepływami danych i umożliwia korzystanie z nakładu pracy nad przygotowywaniem danych do tworzenia modeli uczenia maszynowego bezpośrednio w usłudze Power BI.
Rozwiązanie AutoML w usłudze Power BI umożliwia analitykom danych używanie przepływów danych do tworzenia modeli uczenia maszynowego z uproszczonym środowiskiem przy użyciu tylko umiejętności usługi Power BI. Usługa Power BI automatyzuje większość nauki o danych za tworzeniem modeli uczenia maszynowego. Ma zabezpieczenia, aby upewnić się, że utworzony model ma dobrą jakość i zapewnia wgląd w proces używany do tworzenia modelu uczenia maszynowego.
Rozwiązanie AutoML obsługuje tworzenie modeli przewidywania binarnego, klasyfikacji i regresji dla przepływów danych. Są to typy nadzorowanych technik uczenia maszynowego, co oznacza, że uczą się na podstawie znanych wyników wcześniejszych obserwacji w celu przewidywania wyników innych obserwacji. Model semantyczny danych wejściowych do trenowania modelu automatycznego uczenia maszynowego to zestaw wierszy oznaczonych znanymi wynikami.
Rozwiązanie AutoML w usłudze Power BI integruje zautomatyzowane uczenie maszynowe z usługi Azure Machine Learning w celu tworzenia modeli uczenia maszynowego. Nie potrzebujesz jednak subskrypcji platformy Azure do korzystania z rozwiązania AutoML w usłudze Power BI. Usługa Power BI całkowicie zarządza procesem trenowania i hostowania modeli uczenia maszynowego.
Po wytrenowanym modelu uczenia maszynowego rozwiązanie AutoML automatycznie generuje raport usługi Power BI, który wyjaśnia prawdopodobną wydajność modelu uczenia maszynowego. Rozwiązanie AutoML podkreśla możliwość wyjaśnienia, wyróżniając kluczowe elementy mające wpływ między danymi wejściowymi, które wpływają na przewidywania zwracane przez model. Raport zawiera również kluczowe metryki dla modelu.
Inne strony wygenerowanego raportu zawierają podsumowanie statystyczne modelu i szczegóły trenowania. Podsumowanie statystyczne jest interesujące dla użytkowników, którzy chcą zobaczyć standardowe miary nauki o danych wydajności modelu. Szczegóły trenowania zawierają podsumowanie wszystkich iteracji, które zostały uruchomione w celu utworzenia modelu wraz ze skojarzonymi parametrami modelowania. Opisano również sposób użycia poszczególnych danych wejściowych do utworzenia modelu uczenia maszynowego.
Następnie możesz zastosować model uczenia maszynowego do danych w celu oceniania. Po odświeżeniu przepływu danych dane są aktualizowane przy użyciu przewidywań z modelu uczenia maszynowego. Usługa Power BI zawiera również zdywidualizowane wyjaśnienie poszczególnych przewidywań generowanych przez model uczenia maszynowego.
Tworzenie modelu uczenia maszynowego
W tej sekcji opisano sposób tworzenia modelu rozwiązania AutoML.
Przygotowywanie danych do tworzenia modelu uczenia maszynowego
Aby utworzyć model uczenia maszynowego w usłudze Power BI, musisz najpierw utworzyć przepływ danych dla danych zawierających informacje o wyniku historycznym, który jest używany do trenowania modelu uczenia maszynowego. Należy również dodać kolumny obliczeniowe dla wszystkich metryk biznesowych, które mogą być silnymi predyktorami dla wyniku, który próbujesz przewidzieć. Aby uzyskać szczegółowe informacje na temat konfigurowania przepływu danych, zobacz Konfigurowanie i używanie przepływu danych.
Rozwiązanie AutoML ma określone wymagania dotyczące danych na potrzeby trenowania modelu uczenia maszynowego. Te wymagania opisano w poniższych sekcjach na podstawie odpowiednich typów modeli.
Konfigurowanie danych wejściowych modelu uczenia maszynowego
Aby utworzyć model automatycznego uczenia maszynowego, wybierz ikonę uczenia maszynowego w kolumnie Akcje tabeli przepływu danych i wybierz pozycję Dodaj model uczenia maszynowego.
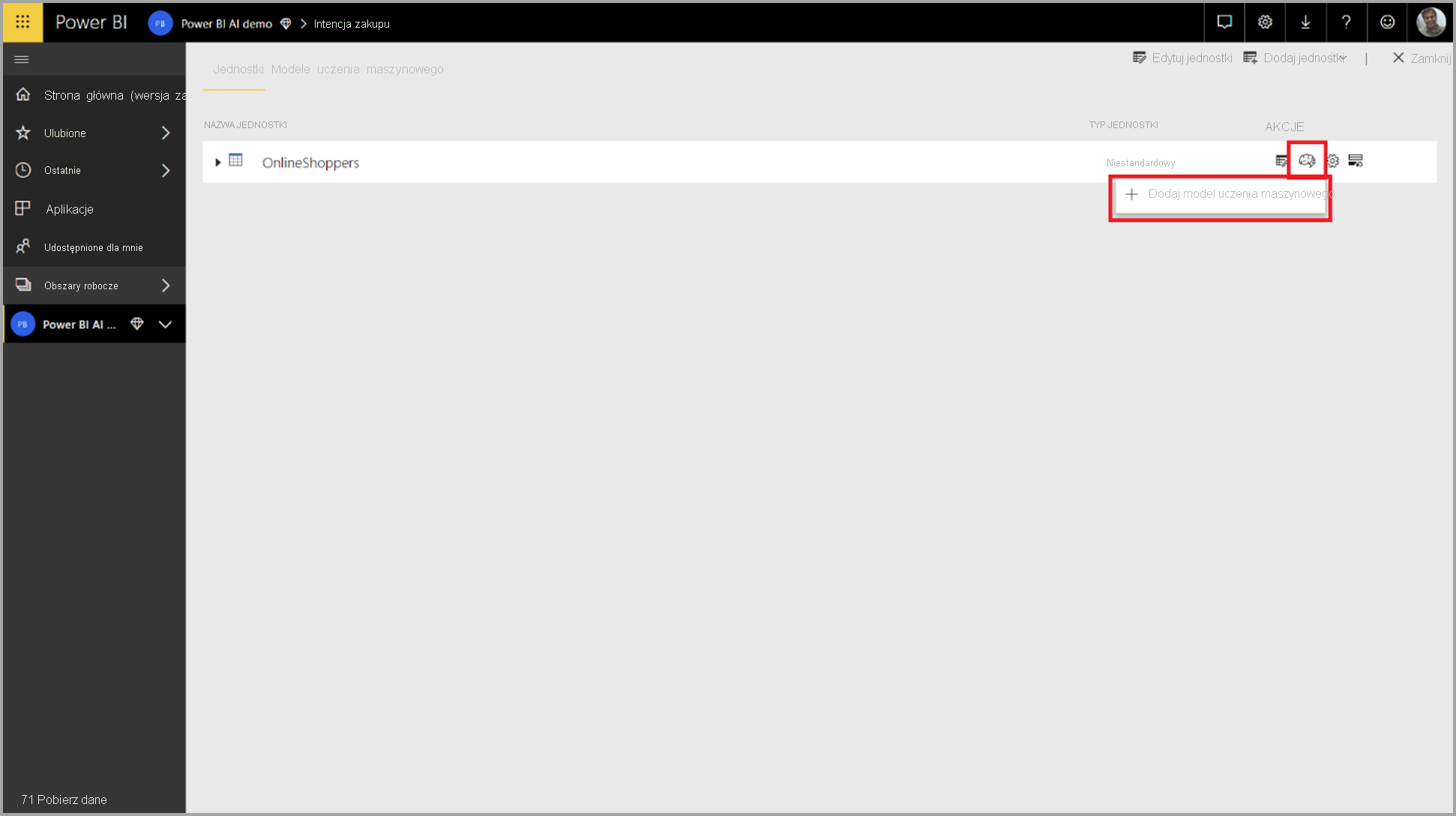
Uproszczone uruchamianie środowiska składającego się z kreatora, który przeprowadzi Cię przez proces tworzenia modelu uczenia maszynowego. Kreator zawiera następujące proste kroki.
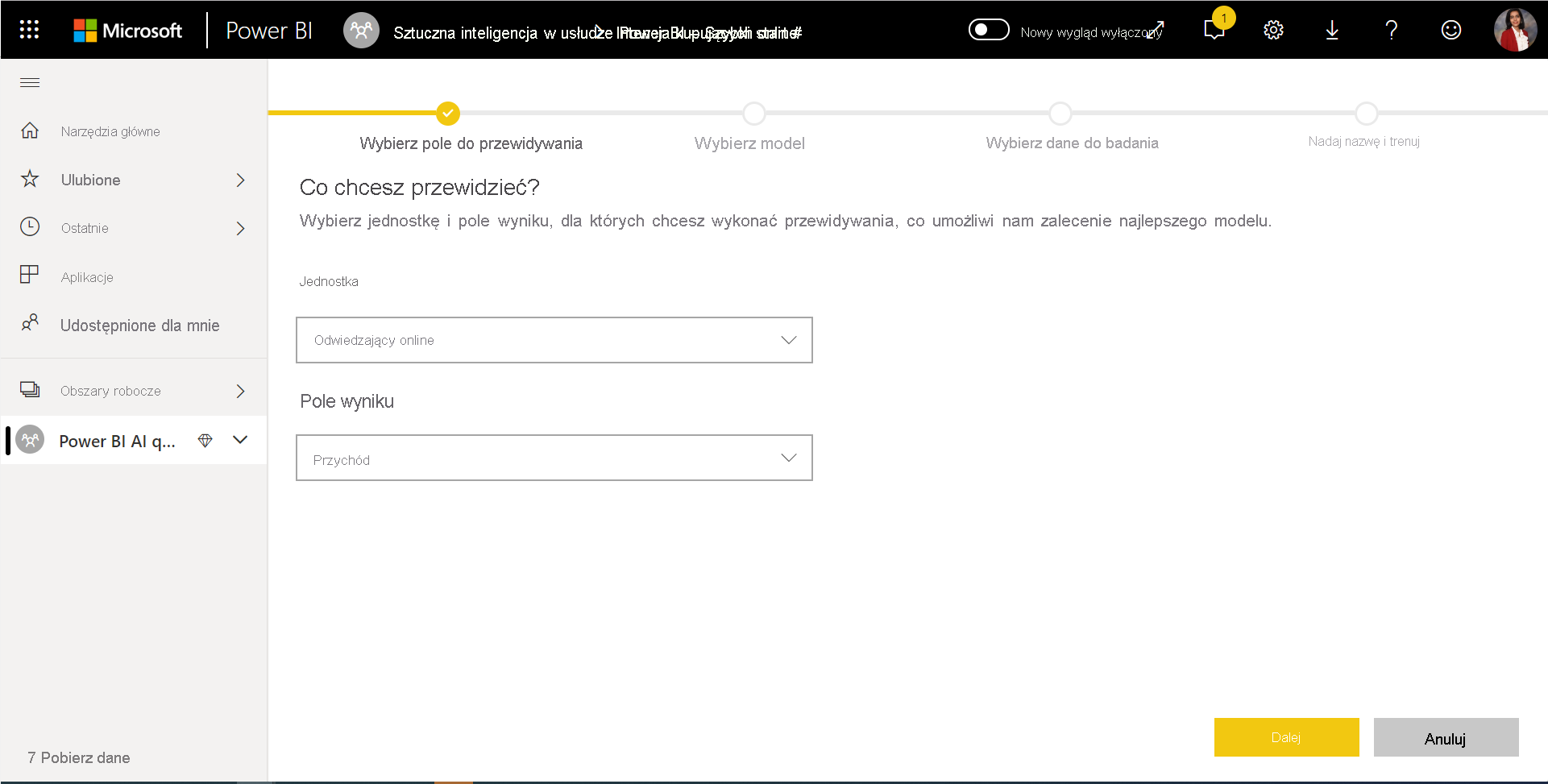
1. Wybierz tabelę z danymi historycznymi i wybierz kolumnę wyniku, dla której chcesz przewidzieć
Kolumna wyniku identyfikuje atrybut etykiety do trenowania modelu uczenia maszynowego, pokazany na poniższej ilustracji.
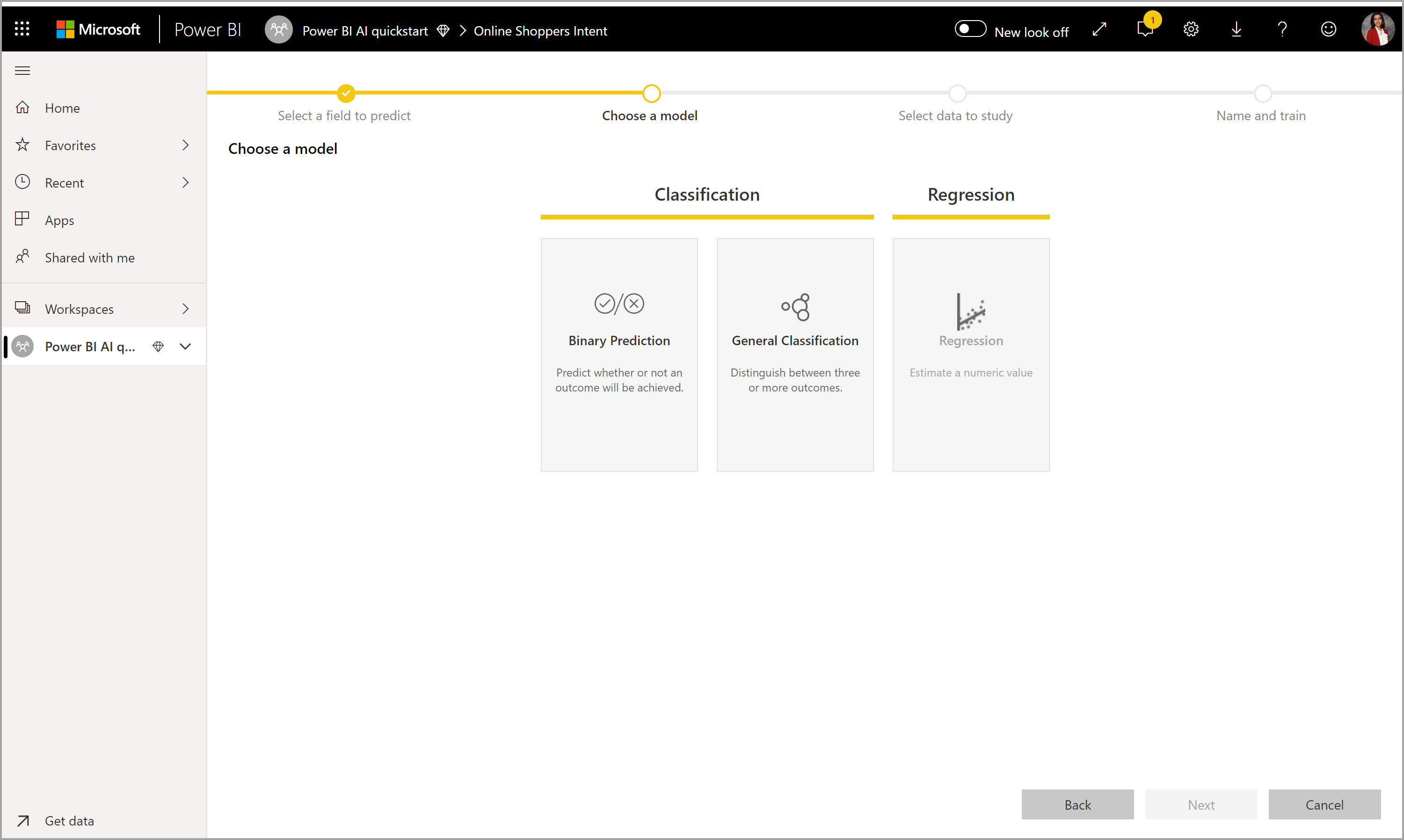
2. Wybierz typ modelu
Po określeniu kolumny wyników rozwiązanie AutoML analizuje dane etykiet, aby zalecić najbardziej prawdopodobny typ modelu uczenia maszynowego, który można wytrenować. Możesz wybrać inny typ modelu, jak pokazano na poniższej ilustracji, klikając pozycję Wybierz model.
Uwaga
Niektóre typy modeli mogą nie być obsługiwane dla wybranych danych, a więc byłoby wyłączone. W poprzednim przykładzie regresja jest wyłączona, ponieważ kolumna tekstowa jest zaznaczona jako kolumna wyniku.
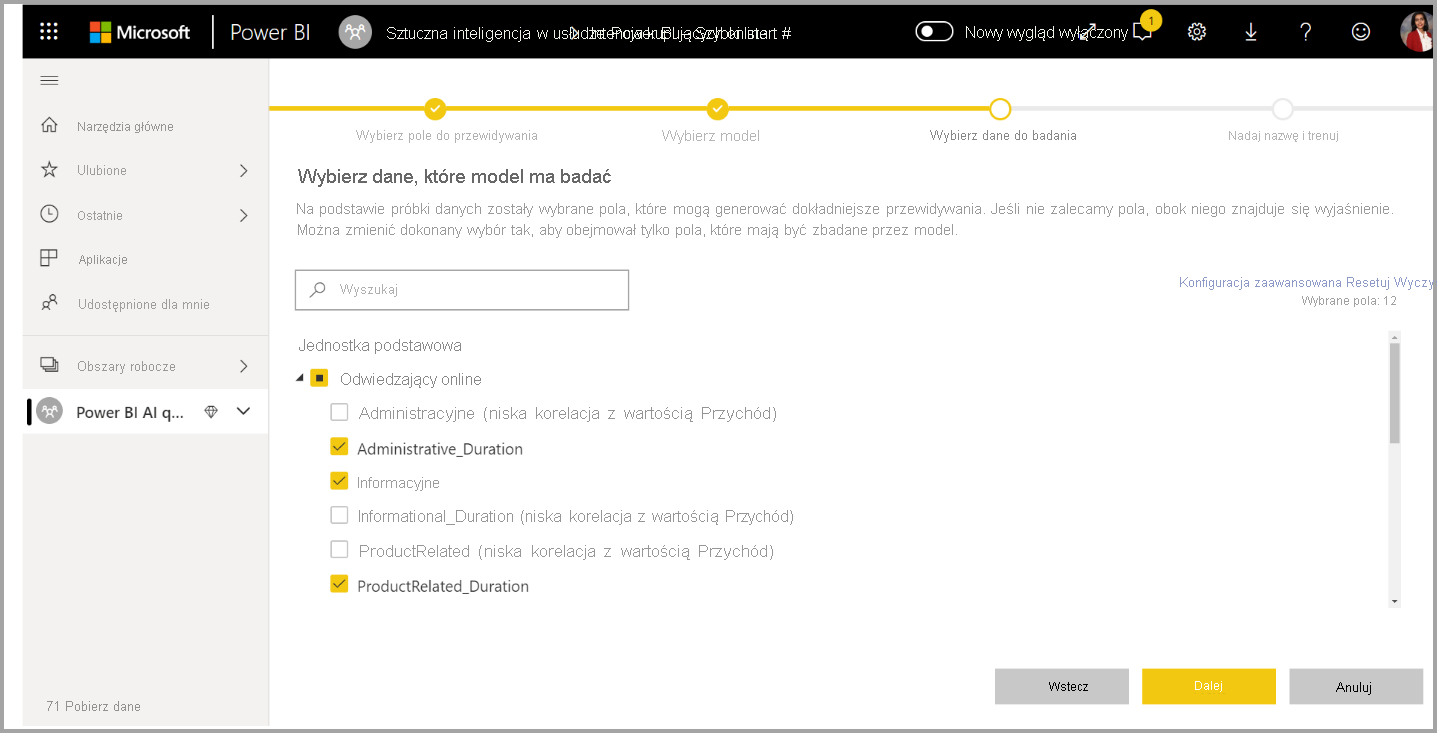
3. Wybierz dane wejściowe, których model ma używać jako sygnałów predykcyjnych
Rozwiązanie AutoML analizuje próbkę wybranej tabeli, aby zasugerować dane wejściowe, których można użyć do trenowania modelu uczenia maszynowego. Wyjaśnienia są udostępniane obok kolumn, które nie są zaznaczone. Jeśli określona kolumna ma zbyt wiele odrębnych wartości lub tylko jedną wartość albo niską lub wysoką korelację z kolumną wyjściową, nie jest to zalecane.
Wszelkie dane wejściowe zależne od kolumny wyniku (lub kolumny etykiety) nie powinny być używane do trenowania modelu uczenia maszynowego, ponieważ wpływają one na jego wydajność. Takie kolumny są oflagowane jako "podejrzanie wysoka korelacja z kolumną wyjściową". Wprowadzenie tych kolumn do danych treningowych powoduje wyciek etykiety, gdzie model działa dobrze na danych sprawdzania poprawności lub testowania, ale nie może dopasować tej wydajności w środowisku produkcyjnym do oceniania. Wyciek etykiet może być możliwym problemem w modelach rozwiązania AutoML, gdy wydajność modelu trenowania jest zbyt dobra.
To zalecenie dotyczące funkcji jest oparte na przykładzie danych, dlatego należy przejrzeć użyte dane wejściowe. Możesz zmienić wybrane opcje tak, aby zawierały tylko kolumny, które mają być badane przez model. Możesz również zaznaczyć wszystkie kolumny, zaznaczając pole wyboru obok nazwy tabeli.
4. Nadaj modelowi nazwę i zapisz konfigurację
W ostatnim kroku możesz nazwać model, wybrać pozycję Zapisz i wybrać, który rozpoczyna trenowanie modelu uczenia maszynowego. Możesz skrócić czas trenowania, aby wyświetlić szybkie wyniki lub zwiększyć ilość czasu spędzonego w szkoleniu, aby uzyskać najlepszy model.
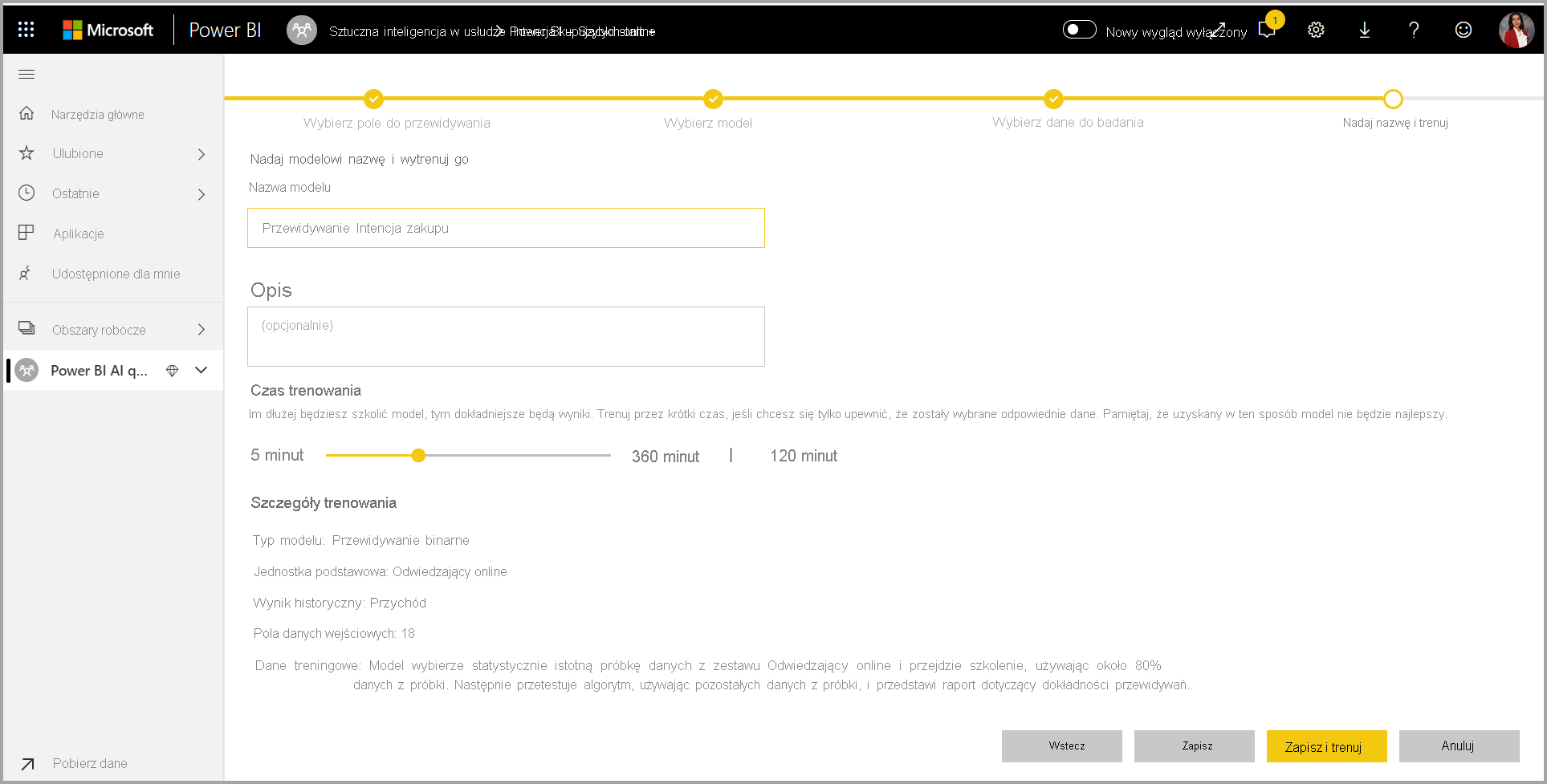
Trenowanie modelu uczenia maszynowego
Trenowanie modeli automatycznego uczenia maszynowego jest częścią odświeżania przepływu danych. Rozwiązanie AutoML najpierw przygotowuje dane do trenowania. Rozwiązanie AutoML dzieli dane historyczne, które podajesz na modele semantyczne trenowania i testowania. Model semantyczny testowy to zestaw blokady używany do weryfikowania wydajności modelu po trenowaniu. Te zestawy są realizowane jako tabele Trenowanie i testowanie w przepływie danych. Rozwiązanie AutoML używa krzyżowej walidacji na potrzeby walidacji modelu.
Następnie każda kolumna wejściowa jest analizowana i stosowana jest imputacja, która zastępuje wszystkie brakujące wartości wartościami zastępczymi. Kilka różnych strategii imputacji jest używanych przez rozwiązanie AutoML. W przypadku atrybutów wejściowych traktowanych jako cechy liczbowe średnia wartości kolumny jest używana do imputacji. W przypadku atrybutów wejściowych traktowanych jako funkcje kategorialne rozwiązanie AutoML używa trybu wartości kolumn do imputacji. Struktura automatycznego uczenia maszynowego oblicza średnią i tryb wartości używanych do imputacji w podprzykładowym modelu semantycznym trenowania.
Następnie próbkowanie i normalizacja są stosowane do danych zgodnie z potrzebami. W przypadku modeli klasyfikacji rozwiązanie AutoML uruchamia dane wejściowe za pośrednictwem próbkowania warstwowego i równoważy klasy, aby upewnić się, że liczby wierszy są równe dla wszystkich.
Rozwiązanie AutoML stosuje kilka przekształceń w każdej wybranej kolumnie wejściowej na podstawie typu danych i właściwości statystycznych. Rozwiązanie AutoML używa tych przekształceń do wyodrębniania funkcji do użycia w trenowaniu modelu uczenia maszynowego.
Proces trenowania modeli AutoML składa się z maksymalnie 50 iteracji z różnymi algorytmami modelowania i ustawieniami hiperparametrów w celu znalezienia modelu o najlepszej wydajności. Trenowanie może zakończyć się na wczesnym etapie z mniejszymi iteracjami, jeśli rozwiązanie AutoML zauważy, że nie zaobserwowano poprawy wydajności. Rozwiązanie AutoML ocenia wydajność każdego z tych modeli, sprawdzając poprawność za pomocą semantycznego modelu testów holdout. Podczas tego kroku trenowania rozwiązanie AutoML tworzy kilka potoków na potrzeby trenowania i walidacji tych iteracji. Proces oceny wydajności modeli może zająć trochę czasu, od kilku minut do kilku godzin, aż do czasu trenowania skonfigurowanego w kreatorze. Czas potrzebny zależy od rozmiaru modelu semantycznego i dostępnych zasobów pojemności.
W niektórych przypadkach wygenerowany ostatni model może korzystać z uczenia zespołowego, w którym wiele modeli jest używanych do zapewnienia lepszej wydajności predykcyjnej.
Objaśnienie modelu automl
Po wytrenowanym modelu rozwiązanie AutoML analizuje relację między funkcjami wejściowymi a danymi wyjściowymi modelu. Ocenia wielkość zmian w danych wyjściowych modelu dla semantycznego modelu testowego wstrzymania dla każdej funkcji wejściowej. Ta relacja jest znana jako ważność funkcji. Ta analiza odbywa się w ramach odświeżania po zakończeniu trenowania. W związku z tym odświeżanie może trwać dłużej niż czas trenowania skonfigurowany w kreatorze.
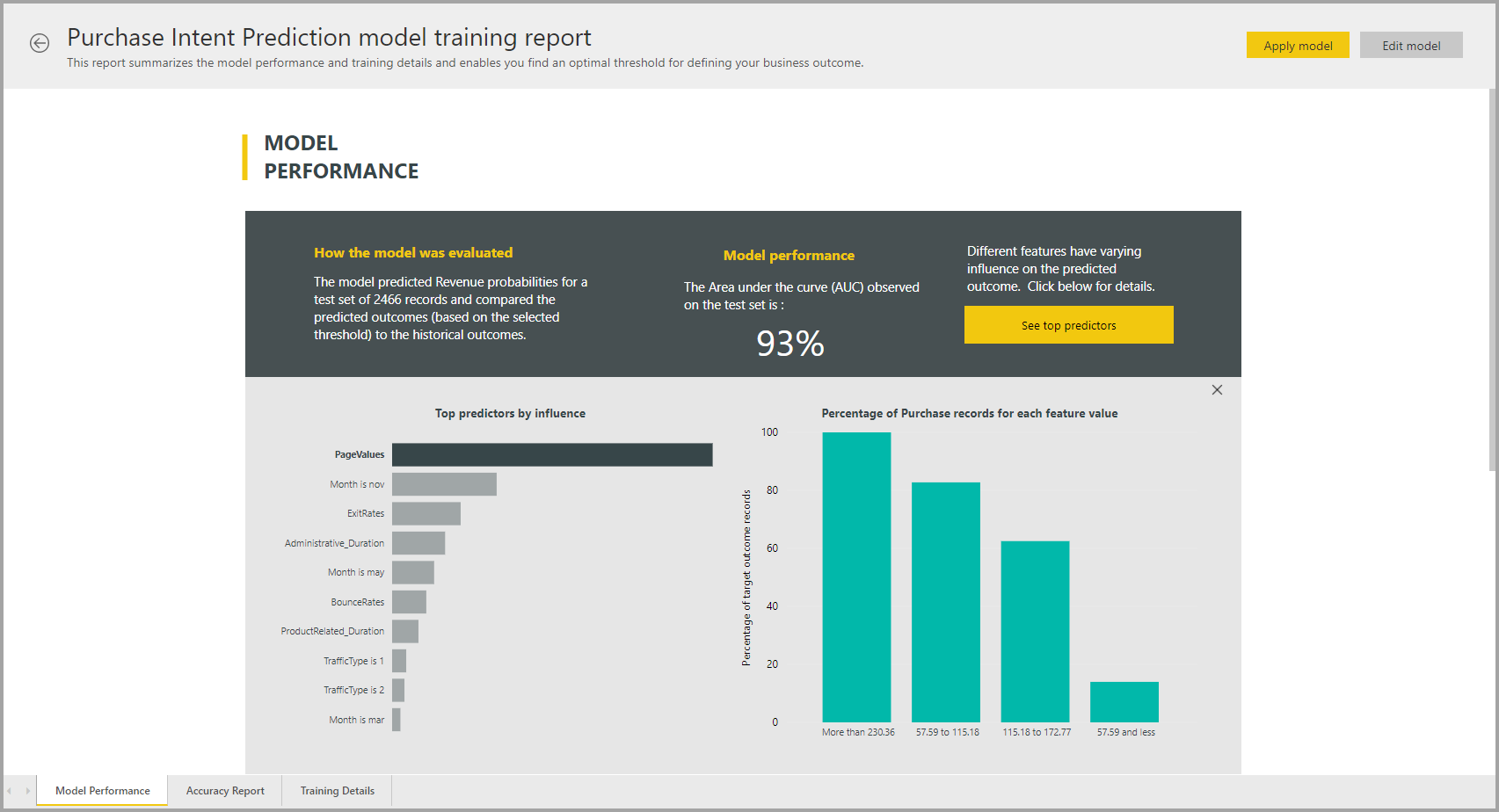
Raport modelu automatycznego uczenia maszynowego
Rozwiązanie AutoML generuje raport usługi Power BI, który podsumowuje wydajność modelu podczas walidacji wraz z globalnym znaczeniem funkcji. Dostęp do tego raportu można uzyskać na karcie Modele uczenia maszynowego po pomyślnym odświeżeniu przepływu danych. Raport zawiera podsumowanie wyników stosowania modelu uczenia maszynowego do danych testowych wstrzymania i porównywania przewidywań ze znanymi wartościami wyników.
Możesz przejrzeć raport modelu, aby zrozumieć jego wydajność. Możesz również sprawdzić, czy kluczowe elementy mające wpływ modelu są zgodne ze szczegółowymi informacjami biznesowymi dotyczącymi znanych wyników.
Wykresy i miary używane do opisywania wydajności modelu w raporcie zależą od typu modelu. Te wykresy wydajności i miary zostały opisane w poniższych sekcjach.
Inne strony w raporcie mogą opisywać miary statystyczne dotyczące modelu z perspektywy nauki o danych. Na przykład raport przewidywania binarnego zawiera wykres zysku i krzywą ROC dla modelu.
Raporty obejmują również stronę Szczegóły trenowania, która zawiera opis sposobu trenowania modelu oraz wykres opisujący wydajność modelu na każdym z uruchomionych iteracji.
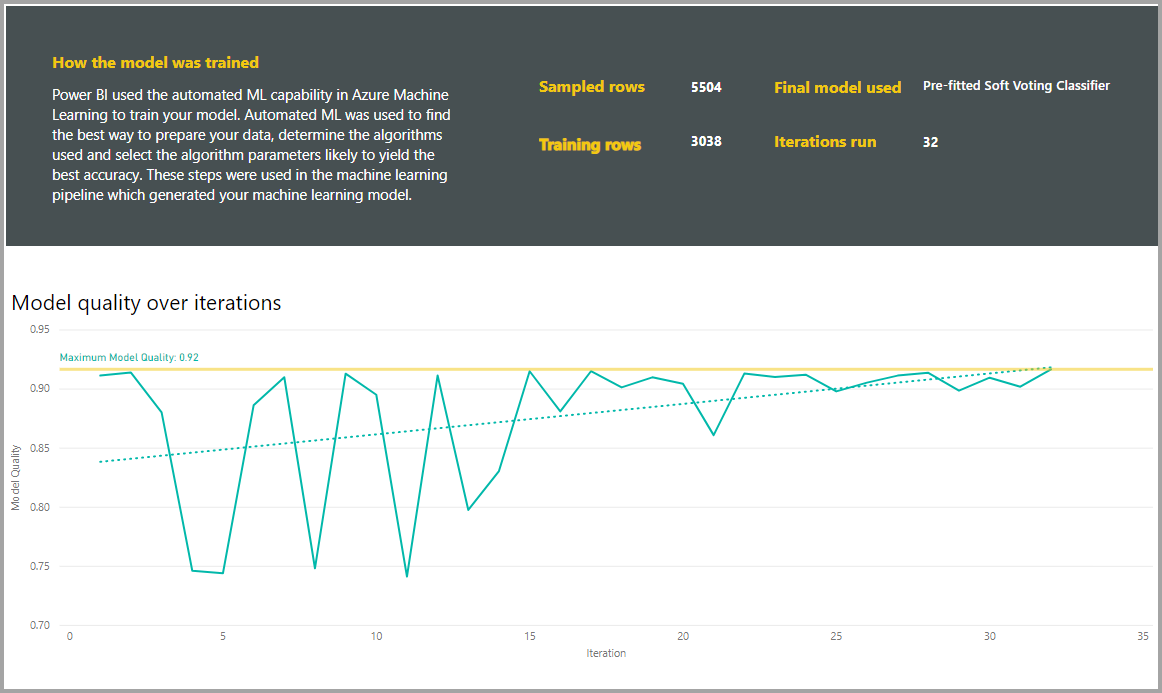
Inna sekcja na tej stronie zawiera opis wykrytego typu kolumny wejściowej i metody imputacji używanej do wypełniania brakujących wartości. Zawiera również parametry używane przez ostateczny model.
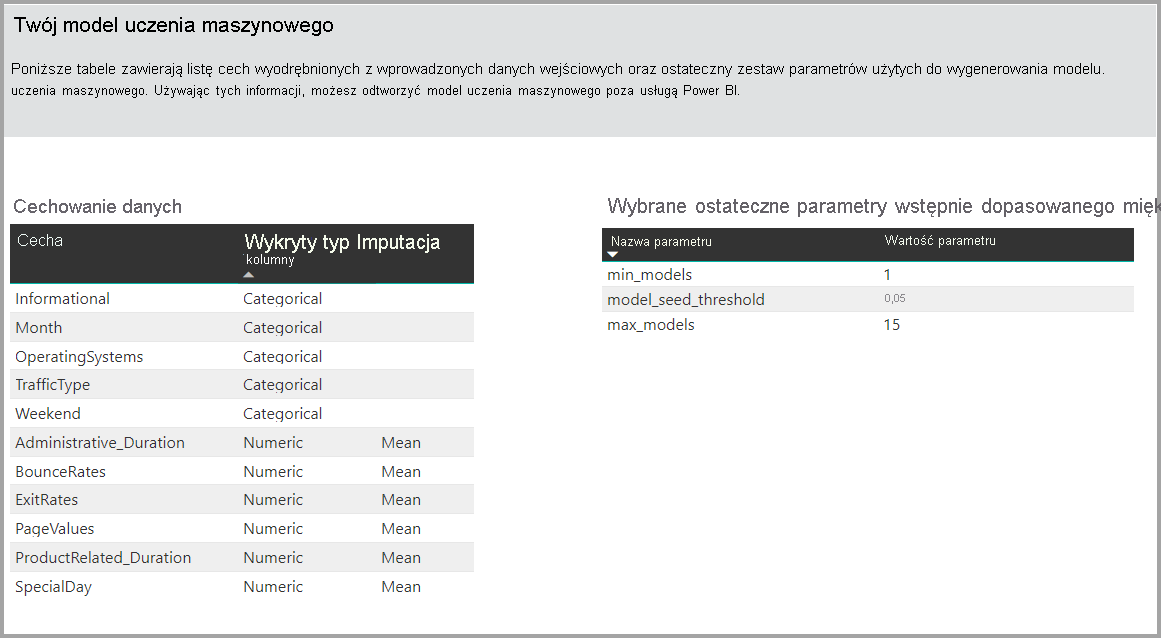
Jeśli utworzony model korzysta z uczenia zespołowego, na stronie Szczegóły trenowania znajduje się również wykres przedstawiający wagę każdego modelu składowego w zespole i jego parametry.

Stosowanie modelu automatycznego uczenia maszynowego
Jeśli wydajność utworzonego modelu uczenia maszynowego jest satysfakcjonująca, możesz zastosować go do nowych lub zaktualizowanych danych po odświeżeniu przepływu danych. W raporcie modelu wybierz przycisk Zastosuj w prawym górnym rogu lub przycisk Zastosuj model uczenia maszynowego w obszarze akcji na karcie Modele uczenia maszynowego.
Aby zastosować model uczenia maszynowego, należy określić nazwę tabeli, do której musi zostać zastosowana, oraz prefiks kolumn, które zostaną dodane do tej tabeli dla danych wyjściowych modelu. Domyślnym prefiksem nazw kolumn jest nazwa modelu. Funkcja Apply może zawierać więcej parametrów specyficznych dla typu modelu.
Zastosowanie modelu uczenia maszynowego tworzy dwie nowe tabele przepływu danych zawierające przewidywania i zdywidualizowane wyjaśnienia dla każdego wiersza, który ocenia w tabeli wyjściowej. Jeśli na przykład zastosujesz model PurchaseIntent do tabeli OnlineShoppers, dane wyjściowe wygeneruje tabele wykupów online wzbogaconych PurchaseIntent i OnlineShoppers wzbogaconych tabele PurchaseIntent. Dla każdego wiersza w wzbogaconej tabeli wyjaśnienia są podzielone na wiele wierszy w wzbogaconej tabeli wyjaśnień na podstawie funkcji wejściowej. Element ExplanationIndex pomaga mapować wiersze ze wzbogaconej tabeli wyjaśnień na wiersz w wzbogaconej tabeli.
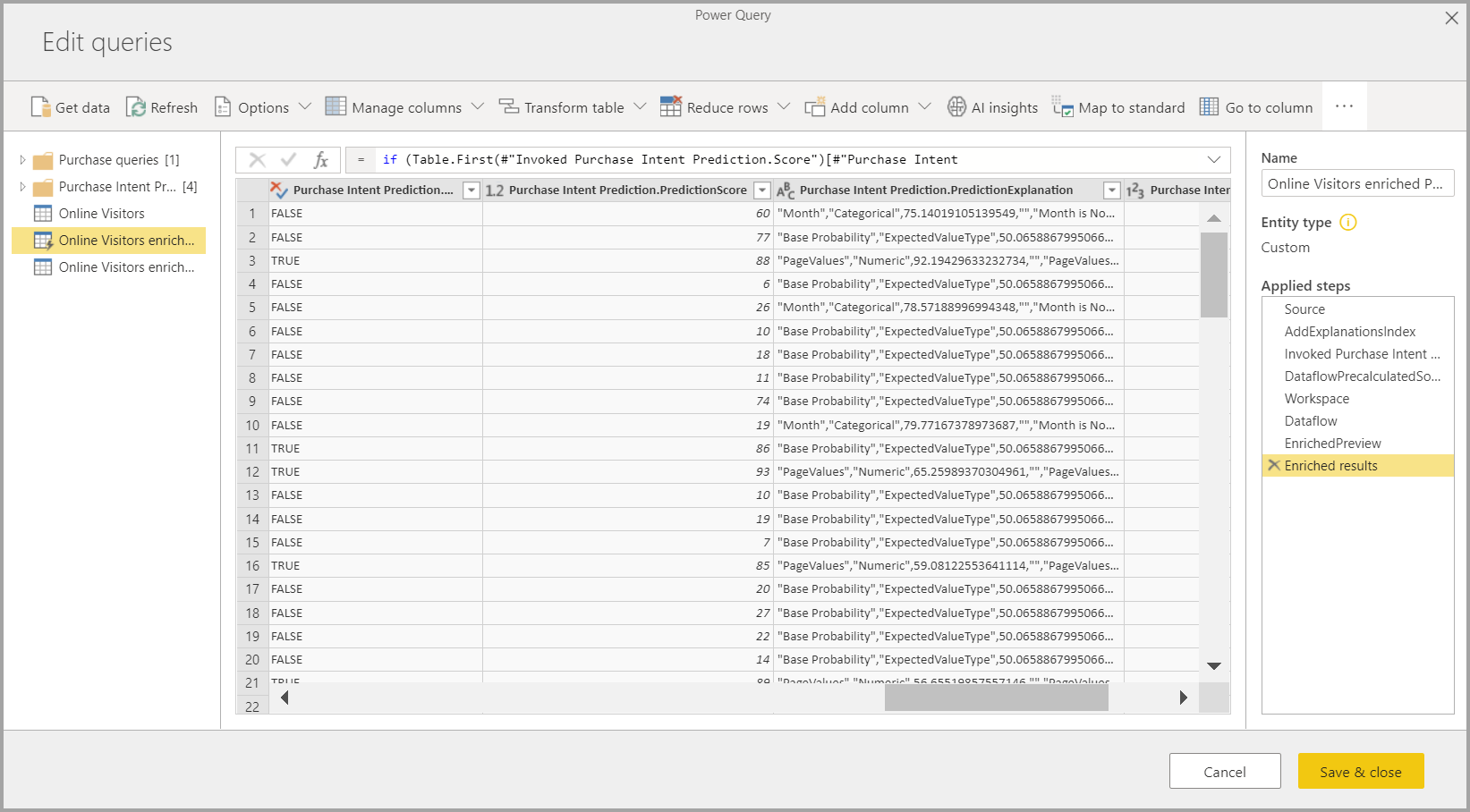
Możesz również zastosować dowolny model automatycznego uczenia maszynowego usługi Power BI do tabel w dowolnym przepływie danych w tym samym obszarze roboczym przy użyciu usługi AI Insights w przeglądarce funkcji PQO. W ten sposób można używać modeli utworzonych przez inne osoby w tym samym obszarze roboczym bez konieczności bycia właścicielem przepływu danych, który ma model. Dodatek Power Query odnajduje wszystkie modele usługi Power BI ML w obszarze roboczym i uwidacznia je jako dynamiczne funkcje dodatku Power Query. Możesz wywołać te funkcje, korzystając ze wstążki w Edytor Power Query lub bezpośrednio wywołując funkcję M. Ta funkcja jest obecnie obsługiwana tylko w przypadku przepływów danych usługi Power BI i usługi Power Query Online w usługa Power BI. Ten proces różni się od stosowania modeli uczenia maszynowego w przepływie danych przy użyciu kreatora automatycznego uczenia maszynowego. Nie ma żadnych wyjaśnień tabeli utworzonych przy użyciu tej metody. Jeśli nie jesteś właścicielem przepływu danych, nie możesz uzyskać dostępu do raportów trenowania modelu ani ponownego trenowania modelu. Ponadto jeśli model źródłowy zostanie edytowany przez dodanie lub usunięcie kolumn wejściowych albo usunięcie modelu lub źródłowego przepływu danych, ten zależny przepływ danych zostanie przerwany.
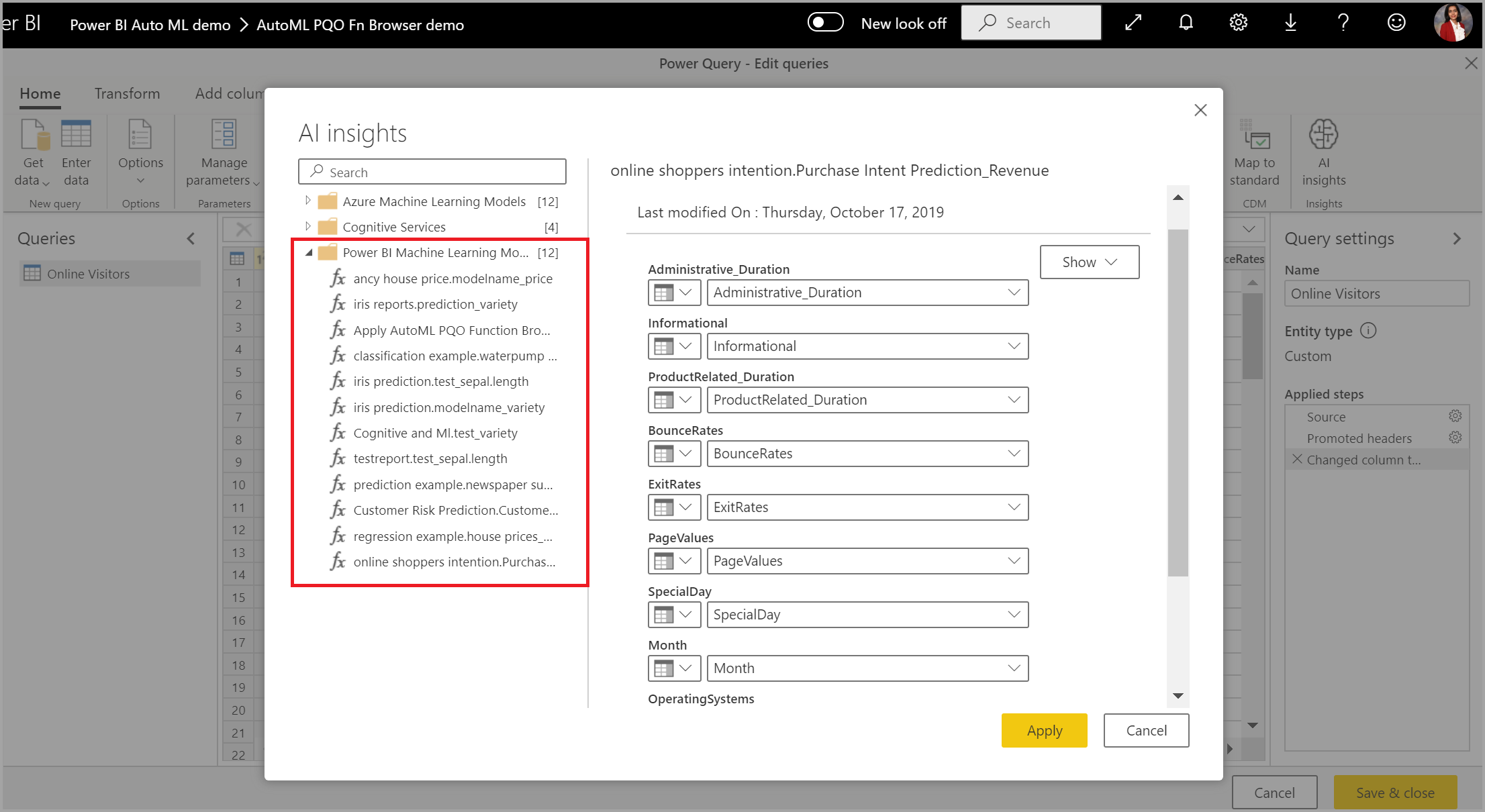
Po zastosowaniu modelu rozwiązanie AutoML zawsze zachowuje aktualność przewidywań za każdym razem, gdy przepływ danych zostanie odświeżony.
Aby użyć szczegółowych informacji i przewidywań z modelu uczenia maszynowego w raporcie usługi Power BI, możesz nawiązać połączenie z tabelą wyjściową z programu Power BI Desktop przy użyciu łącznika przepływów danych.
Modele przewidywania binarnego
Modele przewidywania binarnego, bardziej formalnie znane jako modele klasyfikacji binarnej, służą do klasyfikowania modelu semantycznego w dwie grupy. Są one używane do przewidywania zdarzeń, które mogą mieć wynik binarny. Na przykład czy szansa sprzedaży zostanie przekonwertowana, czy konto będzie ulegać zmianom, czy faktura zostanie zapłacona na czas, czy transakcja jest oszukańcza itd.
Dane wyjściowe modelu przewidywania binarnego to wynik prawdopodobieństwa, który identyfikuje prawdopodobieństwo osiągnięcia wyniku docelowego.
Trenowanie modelu przewidywania binarnego
Wymagania wstępne:
- Dla każdej klasy wyników wymagane jest co najmniej 20 wierszy danych historycznych
Proces tworzenia modelu przewidywania binarnego jest zgodny z tymi samymi krokami co inne modele automatycznego uczenia maszynowego opisane w poprzedniej sekcji Konfigurowanie danych wejściowych modelu uczenia maszynowego. Jedyną różnicą jest krok Wybierz model , w którym można wybrać docelową wartość wyniku, która cię najbardziej interesuje. Można również podać przyjazne etykiety wyników, które mają być używane w automatycznie generowanym raporcie, który podsumowuje wyniki weryfikacji modelu.
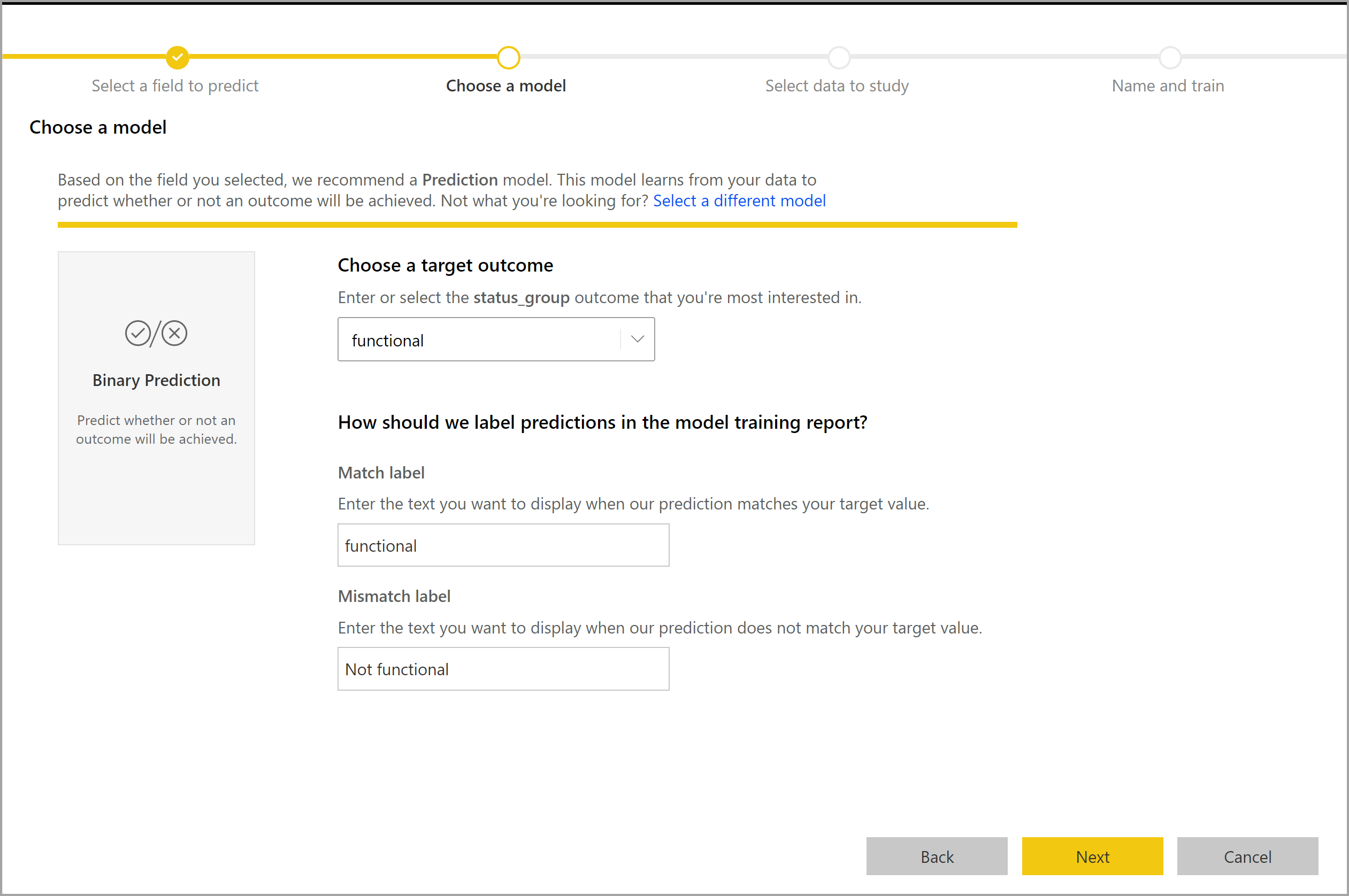
Raport modelu przewidywania binarnego
Model przewidywania binarnego generuje jako dane wyjściowe prawdopodobieństwo, że wiersz osiągnie wynik docelowy. Raport zawiera fragmentator progu prawdopodobieństwa, który wpływa na sposób interpretowania wyników większych i mniejszych niż próg prawdopodobieństwa.
Raport opisuje wydajność modelu pod względem wyników prawdziwie dodatnich, wyników fałszywie dodatnich, wyników prawdziwie ujemnych i wyników fałszywie ujemnych. Wyniki prawdziwie dodatnie i prawdziwie ujemne są prawidłowo przewidywane dla dwóch klas w danych wyniku. Wyniki fałszywie dodatnie to wiersze, które zostały przewidywane jako wynik docelowy, ale tak naprawdę nie. Z drugiej strony wartości fałszywie ujemne to wiersze, które miały wyniki docelowe, ale zostały przewidywane jako nie.
Miary, takie jak Precyzja i Kompletność, opisują wpływ progu prawdopodobieństwa na przewidywane wyniki. Możesz użyć fragmentatora progu prawdopodobieństwa, aby wybrać próg, który osiąga zrównoważony kompromis między precyzją a kompletnością.
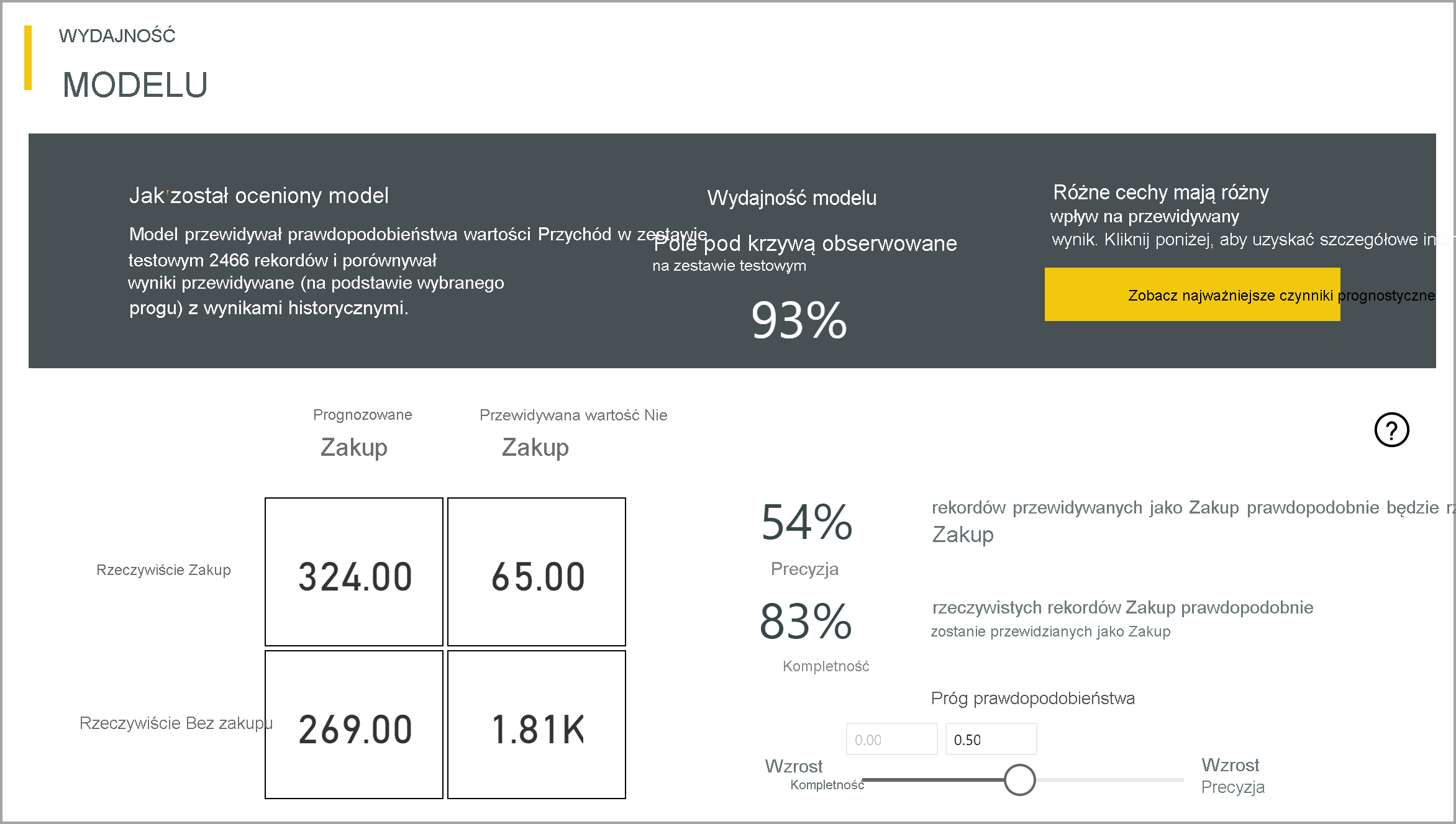
Raport zawiera również narzędzie do analizy kosztów i korzyści, które pomaga zidentyfikować podzbiór populacji, która powinna być przeznaczona do uzyskania najwyższego zysku. Biorąc pod uwagę szacowany koszt jednostkowy ukierunkowania i korzyści jednostkowe z osiągnięcia docelowego wyniku, analiza kosztów i korzyści próbuje zmaksymalizować zysk. Za pomocą tego narzędzia możesz wybrać próg prawdopodobieństwa na podstawie maksymalnego punktu na wykresie, aby zmaksymalizować zysk. Możesz również użyć wykresu, aby obliczyć zysk lub koszt dla wybranego progu prawdopodobieństwa.
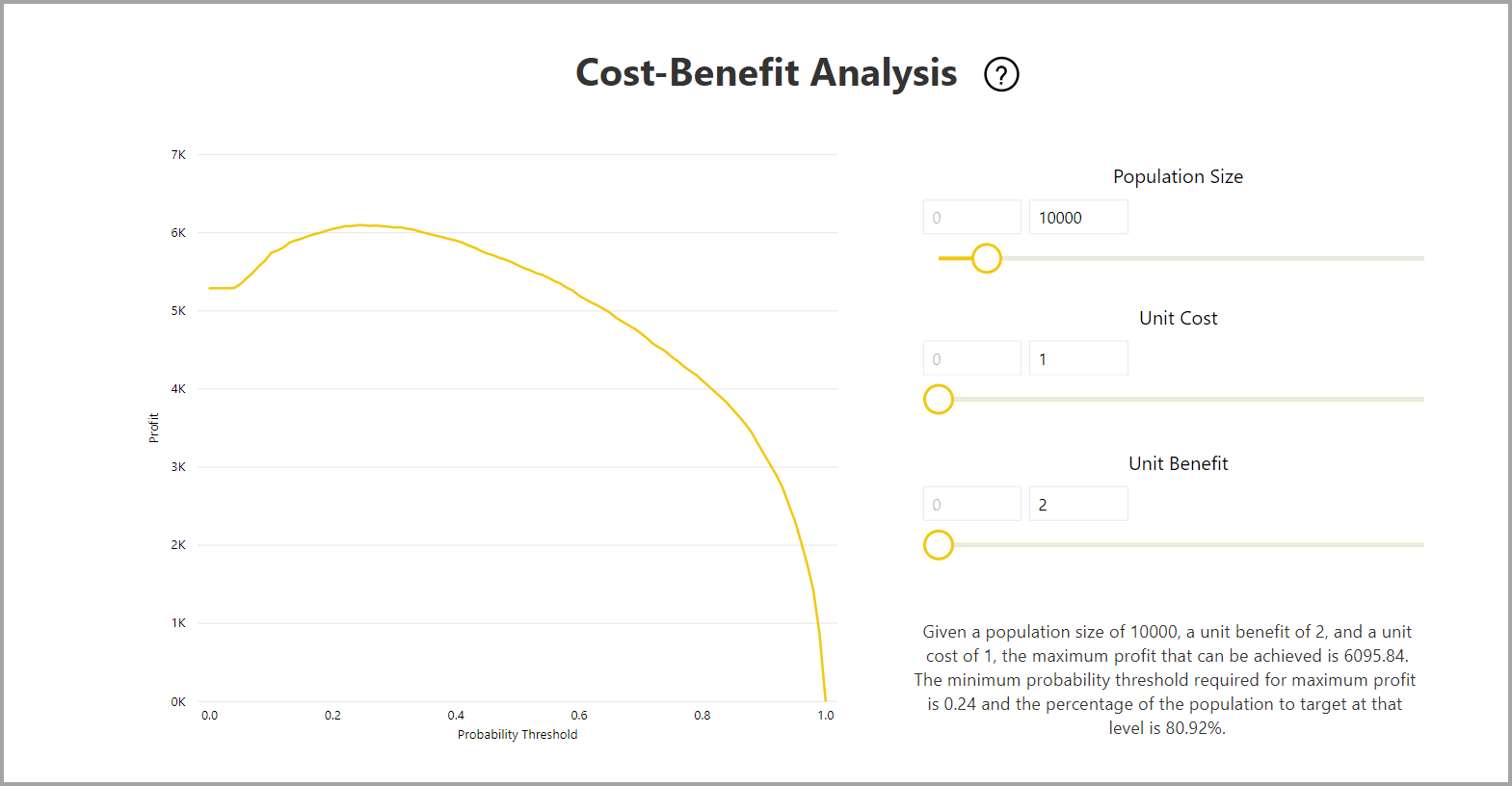
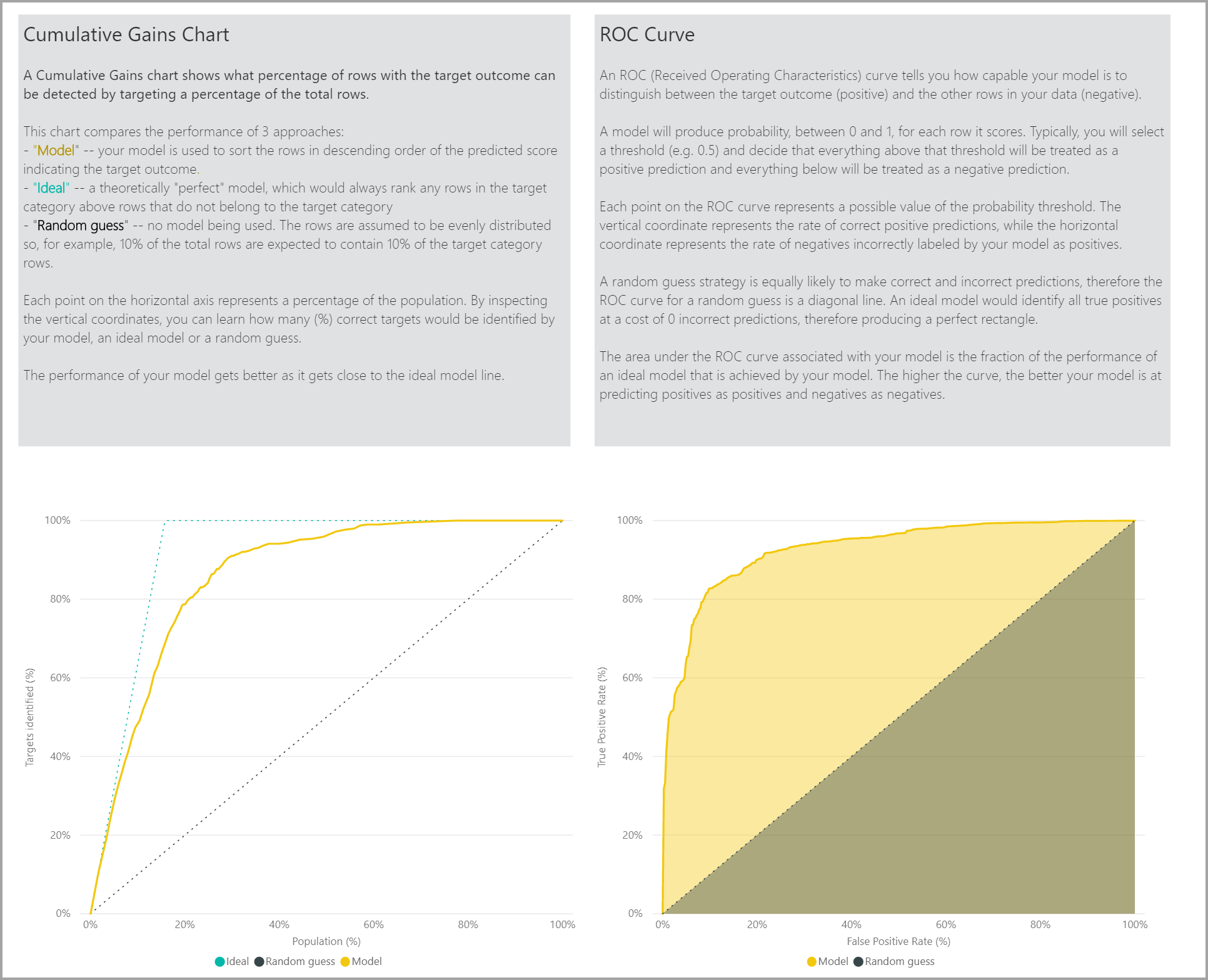
Strona Raport dokładności raportu modelu zawiera wykres Skumulowane zyski i krzywą ROC dla modelu. Te dane zapewniają statystyczne miary wydajności modelu. Raporty zawierają opisy pokazanych wykresów.
Stosowanie modelu przewidywania binarnego
Aby zastosować model przewidywania binarnego, należy określić tabelę z danymi, do których chcesz zastosować przewidywania z modelu uczenia maszynowego. Inne parametry obejmują prefiks nazwy kolumny wyjściowej i próg prawdopodobieństwa klasyfikowania przewidywanego wyniku.
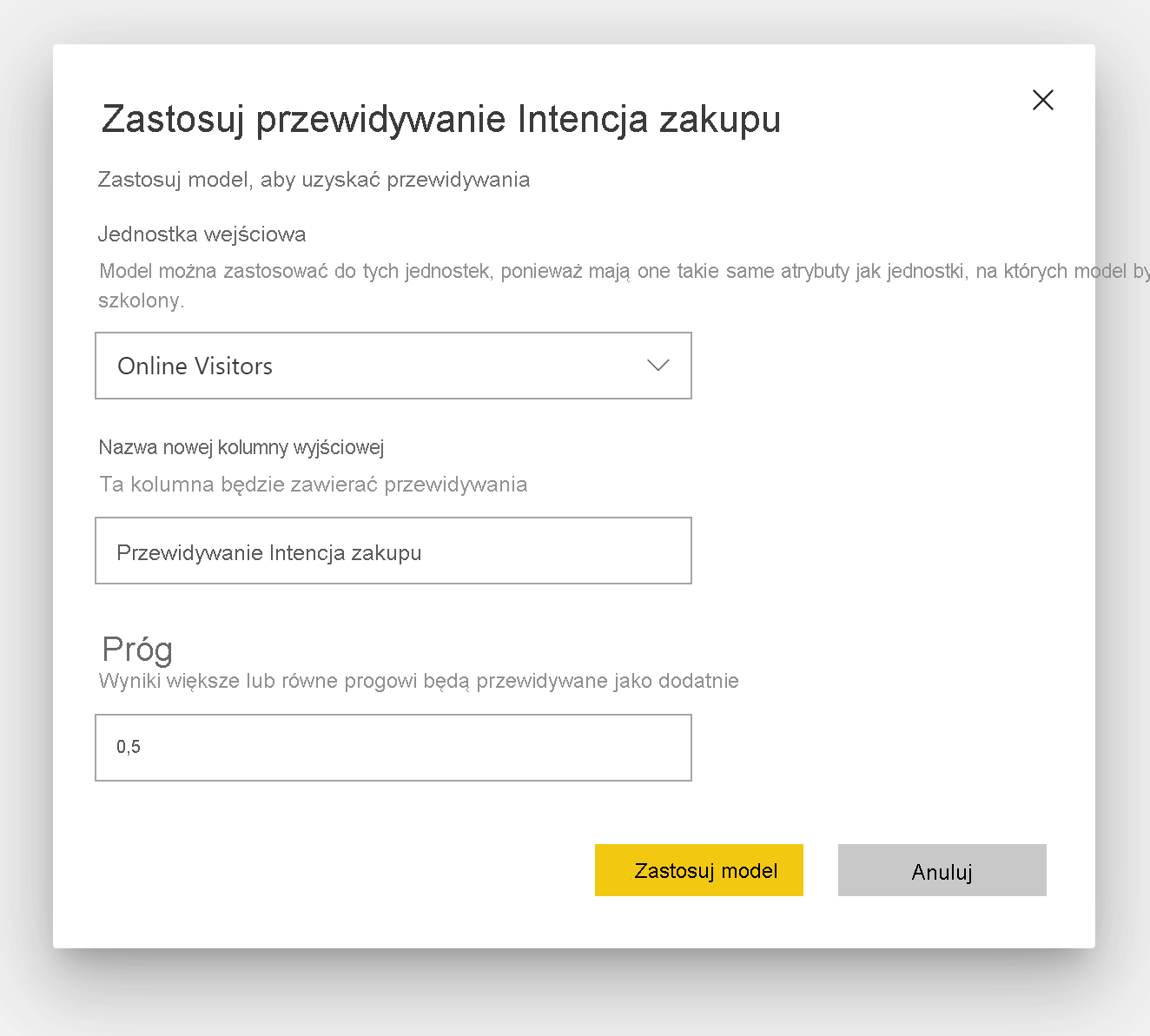
Po zastosowaniu modelu przewidywania binarnego dodaje cztery kolumny wyjściowe do wzbogaconej tabeli wyjściowej: Result, PredictionScore, PredictionExplanation i ExplanationIndex. Nazwy kolumn w tabeli mają prefiks określony podczas stosowania modelu.
PredictionScore to procentowe prawdopodobieństwo, które identyfikuje prawdopodobieństwo osiągnięcia wyniku docelowego.
Kolumna Result zawiera etykietę przewidywanego wyniku. Rekordy z prawdopodobieństwem przekraczającym próg są przewidywane jako prawdopodobne, aby osiągnąć wynik docelowy i są oznaczone jako True. Rekordy mniejsze niż próg są przewidywane jako mało prawdopodobne, aby osiągnąć wynik i są oznaczone jako False.
Kolumna PredictionExplanation zawiera wyjaśnienie specyficznego wpływu funkcji wejściowych na wartość PredictionScore.
Modele klasyfikacji
Modele klasyfikacji służą do klasyfikowania modelu semantycznego w wielu grupach lub klasach. Są one używane do przewidywania zdarzeń, które mogą mieć jeden z wielu możliwych wyników. Na przykład niezależnie od tego, czy klient może mieć wysoką, średnią lub niską wartość okresu istnienia. Mogą również przewidzieć, czy ryzyko domyślne jest wysokie, umiarkowane, niskie itd.
Dane wyjściowe modelu klasyfikacji to wynik prawdopodobieństwa, który identyfikuje prawdopodobieństwo, że wiersz osiągnie kryteria dla danej klasy.
Trenowanie modelu klasyfikacji
Tabela wejściowa zawierająca dane szkoleniowe dla modelu klasyfikacji musi zawierać kolumnę ciągu lub liczby całkowitej jako kolumnę wyniku, która identyfikuje wcześniejsze znane wyniki.
Wymagania wstępne:
- Dla każdej klasy wyników wymagane jest co najmniej 20 wierszy danych historycznych
Proces tworzenia modelu klasyfikacji jest zgodny z tymi samymi krokami co inne modele zautomatyzowanego uczenia maszynowego opisane w poprzedniej sekcji Konfigurowanie danych wejściowych modelu uczenia maszynowego.
Raport modelu klasyfikacji
Usługa Power BI tworzy raport modelu klasyfikacji, stosując model uczenia maszynowego do danych testowych wstrzymania. Następnie porównuje przewidywaną klasę dla wiersza z rzeczywistą znaną klasą.
Raport modelu zawiera wykres zawierający podział poprawnie i niepoprawnie sklasyfikowanych wierszy dla każdej znanej klasy.
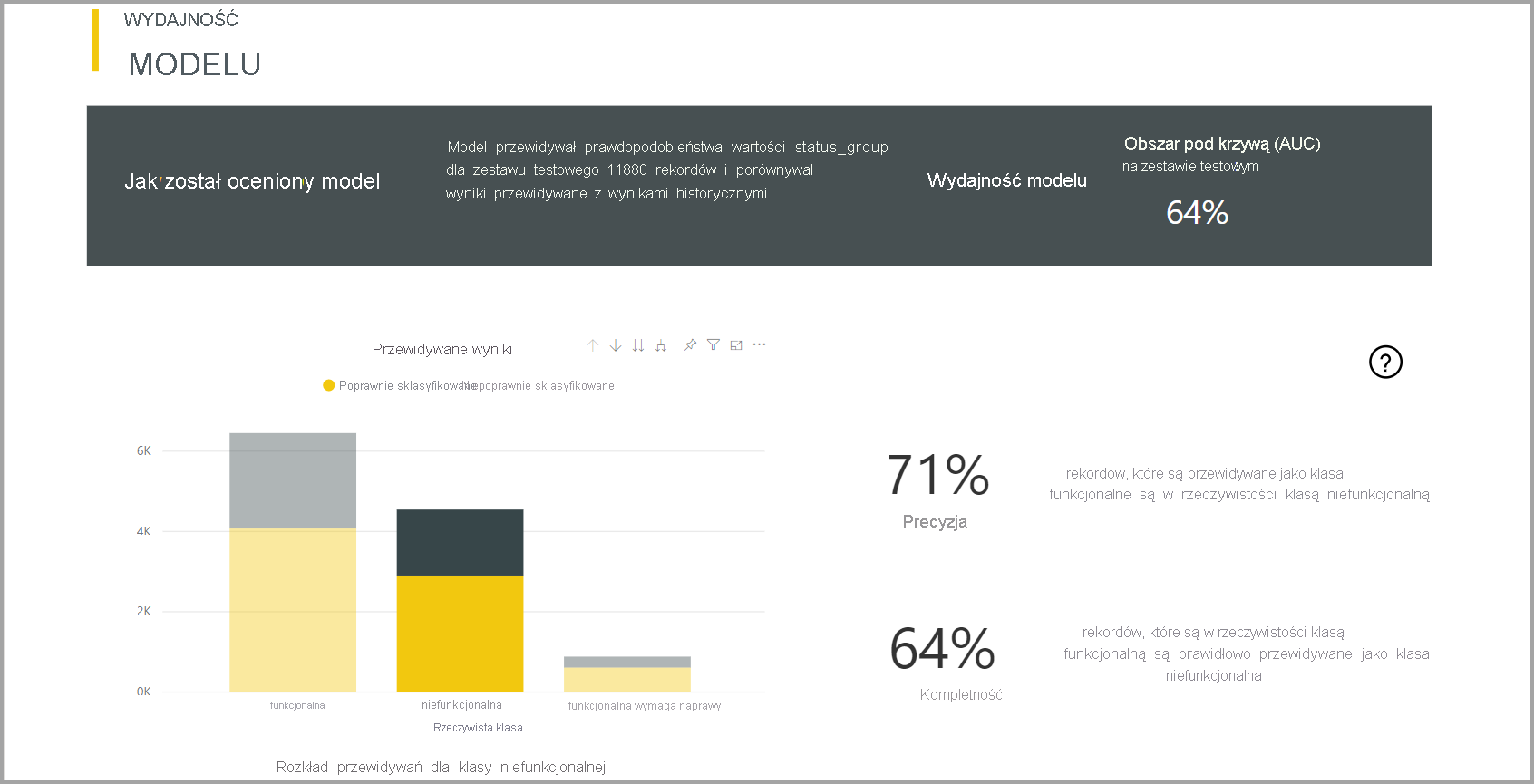
Kolejna akcja przechodzenia do szczegółów specyficzna dla klasy umożliwia analizę sposobu dystrybucji przewidywań dla znanej klasy. Ta analiza pokazuje inne klasy, w których wiersze tej znanej klasy mogą być błędnie sklasyfikowane.
Wyjaśnienie modelu w raporcie zawiera również najważniejsze czynniki prognostyczne dla każdej klasy.
Raport modelu klasyfikacji zawiera również stronę Szczegóły trenowania podobną do stron dla innych typów modeli, zgodnie z wcześniejszym opisem w raporcie modelu rozwiązania AutoML.
Stosowanie modelu klasyfikacji
Aby zastosować model uczenia maszynowego klasyfikacji, należy określić tabelę z danymi wejściowymi i prefiksem nazwy kolumny wyjściowej.
Po zastosowaniu modelu klasyfikacji dodaje pięć kolumn wyjściowych do wzbogaconej tabeli wyjściowej: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities i ExplanationIndex. Nazwy kolumn w tabeli mają prefiks określony podczas stosowania modelu.
Kolumna ClassProbabilities zawiera listę wyników prawdopodobieństwa dla wiersza dla każdej możliwej klasy.
KlasyfikacjaScore jest prawdopodobieństwem procentowym, które identyfikuje prawdopodobieństwo, że wiersz osiągnie kryteria dla danej klasy.
Kolumna ClassificationResult zawiera najbardziej prawdopodobną przewidywaną klasę dla wiersza.
Kolumna ClassificationExplanation zawiera wyjaśnienie o określonym wpływie funkcji wejściowych na wartość ClassificationScore.
Modele regresji
Modele regresji służą do przewidywania wartości liczbowej i mogą być używane w scenariuszach, takich jak określanie:
- Przychód prawdopodobnie zostanie zrealizowany z transakcji sprzedaży.
- Wartość okresu istnienia konta.
- Kwota faktury z tytułu należności, która prawdopodobnie zostanie zapłacona
- Data zapłaty faktury itd.
Dane wyjściowe modelu regresji to przewidywana wartość.
Trenowanie modelu regresji
Tabela wejściowa zawierająca dane treningowe dla modelu regresji musi zawierać kolumnę liczbową jako kolumnę wyniku, która identyfikuje znane wartości wyniku.
Wymagania wstępne:
- Do modelu regresji wymagany jest co najmniej 100 wierszy danych historycznych.
Proces tworzenia modelu regresji jest zgodny z tymi samymi krokami co inne modele automatycznego uczenia maszynowego opisane w poprzedniej sekcji Konfigurowanie danych wejściowych modelu uczenia maszynowego.
Raport modelu regresji
Podobnie jak w przypadku innych raportów modelu automatycznego uczenia maszynowego, raport regresji jest oparty na wynikach stosowania modelu do danych testowych wstrzymania.
Raport modelu zawiera wykres, który porównuje przewidywane wartości z rzeczywistymi wartościami. Na tym wykresie odległość od przekątnej wskazuje błąd w prognozie.
Wykres błędu reszt przedstawia rozkład wartości procentowej średniego błędu dla różnych wartości w modelu semantycznym testu wstrzymania. Oś pozioma reprezentuje średnią rzeczywistej wartości dla grupy. Rozmiar bąbelka pokazuje częstotliwość lub liczbę wartości w tym zakresie. Oś pionowa to średni błąd reszt.
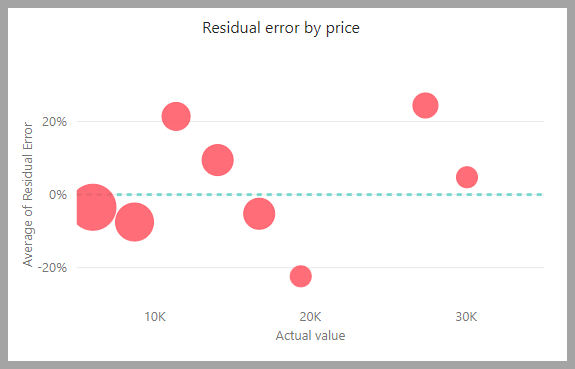
Raport modelu regresji zawiera również stronę Szczegóły trenowania, podobną do raportów dla innych typów modeli, zgodnie z opisem w poprzedniej sekcji, raport modelu automatycznego uczenia maszynowego.
Stosowanie modelu regresji
Aby zastosować model uczenia maszynowego regresji, należy określić tabelę z danymi wejściowymi i prefiksem nazwy kolumny wyjściowej.
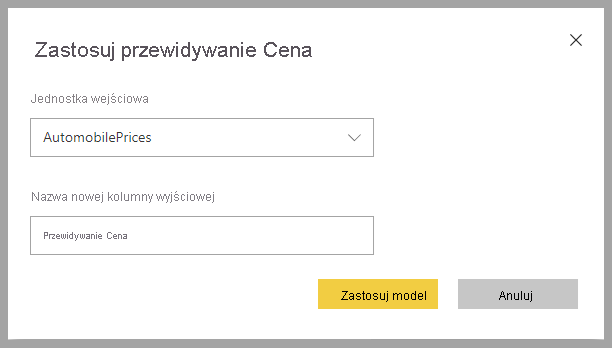
Po zastosowaniu modelu regresji dodaje trzy kolumny wyjściowe do wzbogaconej tabeli wyjściowej: RegressionResult, RegressionExplanation i ExplanationIndex. Nazwy kolumn w tabeli mają prefiks określony podczas stosowania modelu.
Kolumna RegressionResult zawiera przewidywaną wartość wiersza na podstawie kolumn wejściowych. Kolumna RegressionExplanation zawiera wyjaśnienie specyficznego wpływu funkcji wejściowych na wartość RegressionResult.
Integracja usługi Azure Machine Learning w usłudze Power BI
Wiele organizacji używa modeli uczenia maszynowego w celu uzyskania lepszych szczegółowych informacji i przewidywań dotyczących ich działalności. Możesz użyć uczenia maszynowego z raportami, pulpitami nawigacyjnymi i innymi analizami, aby uzyskać te szczegółowe informacje. Możliwość wizualizowania i wywoływania szczegółowych informacji z tych modeli może pomóc rozpowszechnić te szczegółowe informacje użytkownikom biznesowym, którzy ich najbardziej potrzebują. Usługa Power BI ułatwia teraz dołączanie szczegółowych informacji z modeli hostowanych w usłudze Azure Machine Learning przy użyciu prostych gestów typu punkt-kliknięcie.
Aby korzystać z tej możliwości, analityk danych może udzielić dostępu do modelu usługi Azure Machine Learning analitykowi analizy biznesowej przy użyciu witryny Azure Portal. Następnie na początku każdej sesji dodatek Power Query odnajduje wszystkie modele usługi Azure Machine Learning, do których użytkownik ma dostęp i uwidacznia je jako dynamiczne funkcje dodatku Power Query. Użytkownik może następnie wywołać te funkcje, korzystając ze wstążki w Edytor Power Query lub bezpośrednio wywołując funkcję M. Usługa Power BI automatycznie wsaduje żądania dostępu podczas wywoływania modelu usługi Azure Machine Learning dla zestawu wierszy w celu uzyskania lepszej wydajności.
Ta funkcja jest obecnie obsługiwana tylko w przypadku przepływów danych usługi Power BI i dodatku Power Query w trybie online w usługa Power BI.
Aby dowiedzieć się więcej o przepływach danych, zobacz Wprowadzenie do przepływów danych i przygotowywanie danych samoobsługi.
Aby dowiedzieć się więcej o usłudze Azure Machine Learning, zobacz:
- Omówienie: Co to jest usługa Azure Machine Learning?
- Przewodniki Szybki start i samouczki dotyczące usługi Azure Machine Learning: dokumentacja usługi Azure Machine Learning
Udzielanie dostępu do modelu usługi Azure Machine Learning użytkownikowi usługi Power BI
Aby uzyskać dostęp do modelu usługi Azure Machine Learning z poziomu usługi Power BI, użytkownik musi mieć dostęp do odczytu do subskrypcji platformy Azure i obszaru roboczego usługi Machine Learning.
W krokach opisanych w tym artykule opisano sposób udzielania użytkownikowi usługi Power BI dostępu do modelu hostowanego w usłudze Azure Machine Learning w celu uzyskania dostępu do tego modelu jako funkcji Dodatku Power Query. Aby uzyskać więcej informacji, zobacz przypisywanie ról Azure za pomocą portalu Azure.
Zaloguj się w witrynie Azure Portal.
Przejdź do strony Subskrypcje . Stronę Subskrypcje można znaleźć na liście Wszystkie usługi w menu okienka nawigacji witryny Azure Portal.
Wybierz subskrypcję.
Wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami), a następnie wybierz przycisk Dodaj.
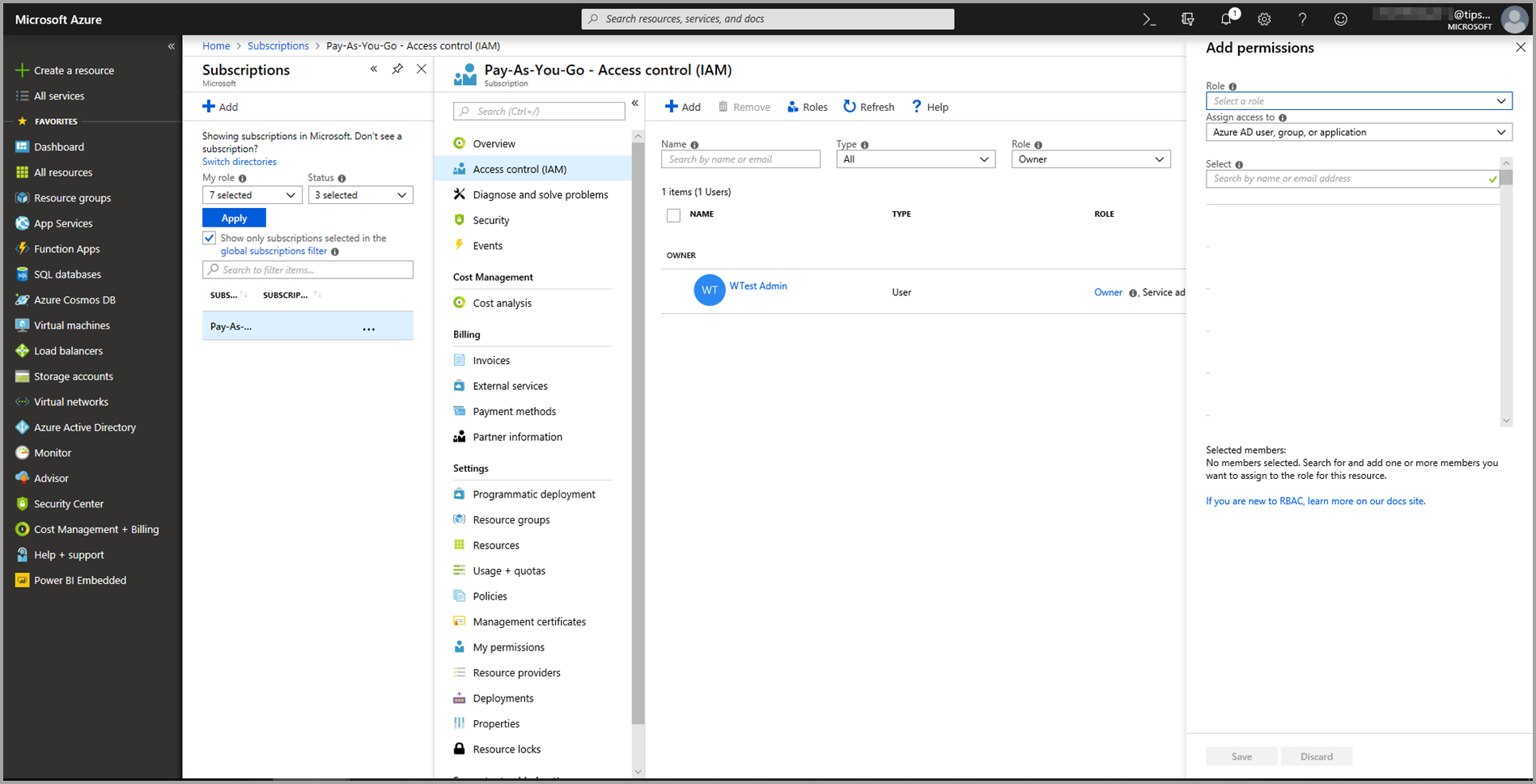
Wybierz pozycję Czytelnik jako rolę. Następnie wybierz użytkownika usługi Power BI, któremu chcesz udzielić dostępu do modelu usługi Azure Machine Learning.
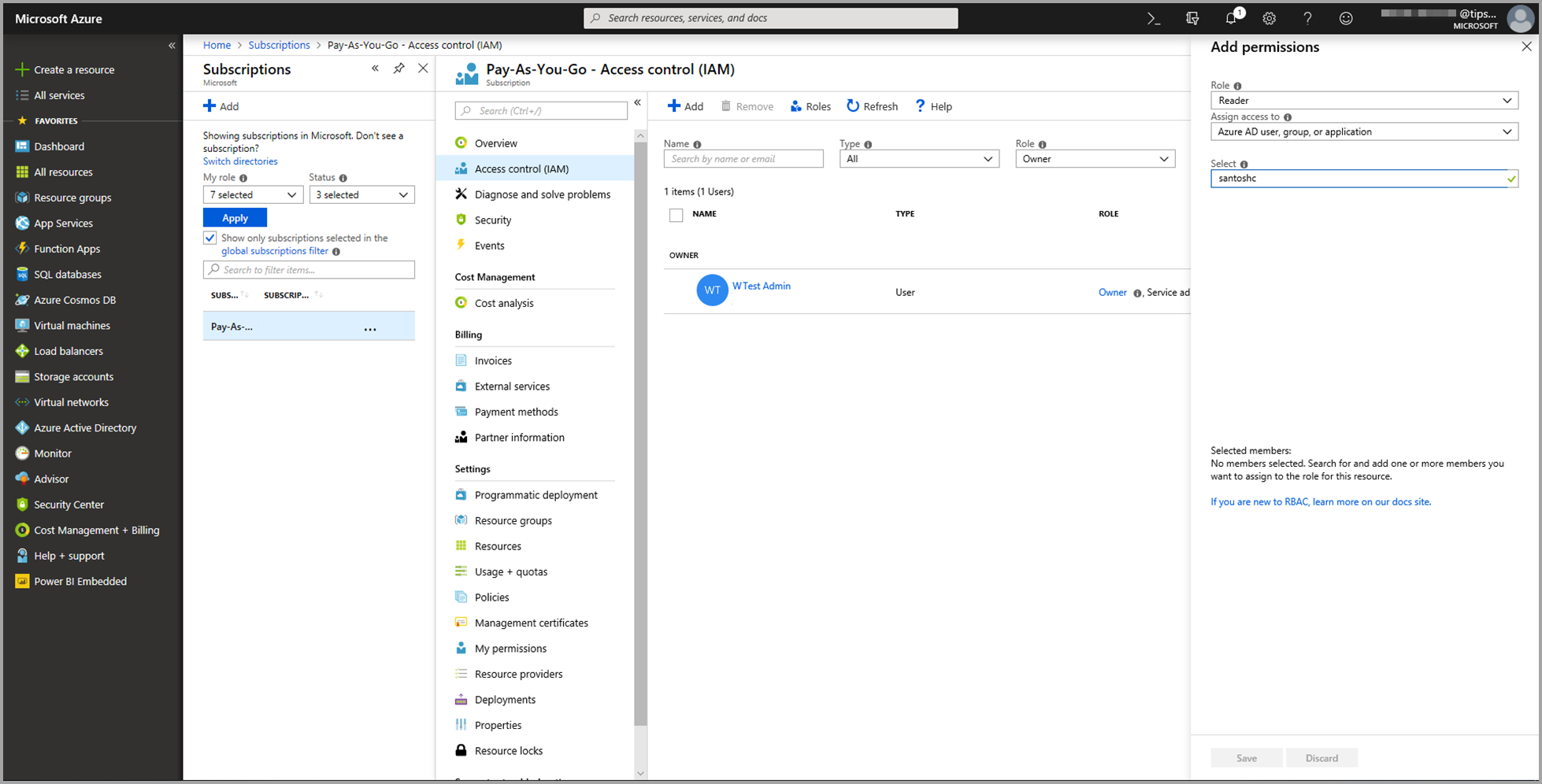
Wybierz pozycję Zapisz.
Powtórz kroki od trzech do sześciu, aby przyznać użytkownikowi dostęp czytelnika do określonego obszaru roboczego uczenia maszynowego obsługującego model.




Odnajdywanie schematu dla modeli uczenia maszynowego
Analitycy danych używają języka Python głównie do opracowywania, a nawet wdrażania modeli uczenia maszynowego na potrzeby uczenia maszynowego. Analityk danych musi jawnie wygenerować plik schematu przy użyciu języka Python.
Ten plik schematu musi być uwzględniony w wdrożonej usłudze internetowej dla modeli uczenia maszynowego. Aby automatycznie wygenerować schemat dla usługi internetowej, należy podać przykład danych wejściowych/wyjściowych w skry skrycie wejściowym dla wdrożonego modelu. Aby uzyskać więcej informacji, zobacz Wdrażanie i ocenianie modelu uczenia maszynowego przy użyciu punktu końcowego online. Link zawiera przykładowy skrypt wpisu z instrukcjami generowania schematu.
W szczególności funkcje @input_schema i @output_schema w skrycie wejściowym odwołują się do przykładowych formatów danych wejściowych i wyjściowych w zmiennych input_sample i output_sample . Funkcje używają tych przykładów do generowania specyfikacji interfejsu OpenAPI (Swagger) dla usługi internetowej podczas wdrażania.
Te instrukcje dotyczące generowania schematu przez zaktualizowanie skryptu wejścia muszą być również stosowane do modeli utworzonych przy użyciu eksperymentów zautomatyzowanego uczenia maszynowego z zestawem AZURE Machine Learning SDK.
Uwaga
Modele utworzone przy użyciu interfejsu wizualnego usługi Azure Machine Learning nie obsługują obecnie generowania schematu, ale będą dostępne w kolejnych wersjach.
Wywoływanie modelu usługi Azure Machine Learning w usłudze Power BI
Możesz wywołać dowolny model usługi Azure Machine Learning, do którego udzielono ci dostępu, bezpośrednio z Edytor Power Query w przepływie danych. Aby uzyskać dostęp do modeli usługi Azure Machine Learning, wybierz przycisk Edytuj tabelę dla tabeli, którą chcesz wzbogacić o szczegółowe informacje z modelu usługi Azure Machine Learning, jak pokazano na poniższej ilustracji.

Wybranie przycisku Edytuj tabelę powoduje otwarcie Edytor Power Query dla tabel w przepływie danych.

Wybierz przycisk AI Insights na wstążce, a następnie wybierz folder Modele usługi Azure Machine Learning z menu okienka nawigacji. Wszystkie modele usługi Azure Machine Learning, do których masz dostęp, są wymienione tutaj jako funkcje dodatku Power Query. Ponadto parametry wejściowe modelu usługi Azure Machine Learning są automatycznie mapowane jako parametry odpowiedniej funkcji Dodatku Power Query.
Aby wywołać model usługi Azure Machine Learning, możesz określić dowolną kolumnę wybranej tabeli jako dane wejściowe z listy rozwijanej. Możesz również określić stałą wartość, która ma być używana jako dane wejściowe, przełączając ikonę kolumny po lewej stronie okna dialogowego wprowadzania.

Wybierz pozycję Wywołaj , aby wyświetlić podgląd danych wyjściowych modelu usługi Azure Machine Learning jako nową kolumnę w tabeli. Wywołanie modelu jest wyświetlane jako zastosowany krok zapytania.

Jeśli model zwraca wiele parametrów wyjściowych, są grupowane razem jako wiersz w kolumnie wyjściowej. Możesz rozwinąć kolumnę, aby wygenerować poszczególne parametry wyjściowe w osobnych kolumnach.

Po zapisaniu przepływu danych model jest automatycznie wywoływany po odświeżeniu przepływu danych dla wszystkich nowych lub zaktualizowanych wierszy w tabeli.
Rozważania i ograniczenia
- Przepływy danych Gen2 nie są obecnie zintegrowane z automatycznym uczeniem maszynowym.
- Szczegółowe informacje o sztucznej inteligencji (usługi Cognitive Services i modele usługi Azure Machine Learning) nie są obsługiwane na maszynach z konfiguracją uwierzytelniania serwera proxy.
- Modele usługi Azure Machine Learning nie są obsługiwane dla użytkowników-gości.
- Istnieją znane problemy z używaniem bramy z usługami AutoML i Cognitive Services. Jeśli musisz użyć bramy, zalecamy utworzenie przepływu danych, który najpierw importuje niezbędne dane za pośrednictwem bramy. Następnie utwórz kolejny przepływ danych, który odwołuje się do pierwszego przepływu danych w celu utworzenia lub zastosowania tych modeli i funkcji sztucznej inteligencji.
- Jeśli praca sztucznej inteligencji z przepływami danych zakończy się niepowodzeniem, może być konieczne włączenie funkcji Szybkiego łączenia w przypadku korzystania ze sztucznej inteligencji z przepływami danych. Po zaimportowaniu tabeli i przed rozpoczęciem dodawania funkcji sztucznej inteligencji wybierz pozycję Opcje na wstążce Narzędzia główne, a następnie w wyświetlonym oknie zaznacz pole wyboru obok pozycji Zezwalaj na łączenie danych z wielu źródeł , aby włączyć tę funkcję, a następnie wybierz przycisk OK , aby zapisać wybór. Następnie możesz dodać funkcje sztucznej inteligencji do przepływu danych.
Powiązana zawartość
Ten artykuł zawiera omówienie zautomatyzowanego uczenia maszynowego dla przepływów danych w usługa Power BI. Poniższe artykuły mogą być również przydatne.
- Samouczek: tworzenie modelu uczenia maszynowego w usłudze Power BI
- Samouczek: korzystanie z usług Cognitive Services w usłudze Power BI
Następujące artykuły zawierają więcej informacji na temat przepływów danych i usługi Power BI:
- Wprowadzenie do przepływów danych i przygotowywania danych samoobsługi
- Tworzenie przepływu danych
- Konfigurowanie i używanie przepływu danych
- Konfigurowanie magazynu przepływu danych do korzystania z usługi Azure Data Lake Gen 2
- Funkcje premium przepływów danych
- Zagadnienia i ograniczenia dotyczące przepływów danych
- Najlepsze rozwiązania dotyczące przepływów danych