ORC-format i Azure Data Factory och Synapse Analytics
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Följ den här artikeln när du vill parsa ORC-filerna eller skriva data i ORC-format.
ORC-format stöds för följande anslutningsappar: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage och SFTP.
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av ORC-datauppsättningen.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till Orc. | Ja |
| plats | Platsinställningar för filen eller filerna. Varje filbaserad anslutningsapp har en egen platstyp och egenskaper som stöds under location. Mer information finns i artikeln om anslutningsappar –> avsnittet Egenskaper för datauppsättning. |
Ja |
| compressionCodec | Den komprimeringskodc som ska användas när du skriver till ORC-filer. När du läser från ORC-filer avgör datafabriker automatiskt komprimeringskodcen baserat på filmetadata. Typer som stöds är ingen, zlib, snappy (standard) och lzo. Observera att aktiviteten Kopiera för närvarande inte stöder LZO när du läser/skriver ORC-filer. |
Nej |
Nedan visas ett exempel på ORC-datauppsättning i Azure Blob Storage:
{
"name": "OrcDataset",
"properties": {
"type": "Orc",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
}
}
}
}
Observera följande:
- Komplexa datatyper (t.ex. MAP, LIST, STRUCT) stöds för närvarande endast i Dataflöde, inte i Kopieringsaktivitet. Om du vill använda komplexa typer i dataflöden ska du inte importera filschemat i datauppsättningen och lämna schemat tomt i datauppsättningen. Importera sedan projektionen i källtransformeringen.
- Tomt utrymme i kolumnnamnet stöds inte.
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av ORC-källan och mottagaren.
ORC som källa
Följande egenskaper stöds i avsnittet kopieringsaktivitet *källa* .
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till OrcSource. | Ja |
| store Inställningar | En grupp med egenskaper för hur du läser data från ett datalager. Varje filbaserad anslutningsapp har egna läsinställningar som stöds under storeSettings. Mer information finns i artikeln om anslutningsappar –> aktiviteten Kopiera egenskaper. |
Nej |
ORC som mottagare
Följande egenskaper stöds i avsnittet kopieringsaktivitet *mottagare* .
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetsmottagaren måste anges till OrcSink. | Ja |
| format Inställningar | En grupp med egenskaper. Se tabellen för ORC-skrivinställningar nedan. | Nej |
| store Inställningar | En grupp med egenskaper för hur du skriver data till ett datalager. Varje filbaserad anslutningsapp har egna skrivinställningar som stöds under storeSettings. Mer information finns i artikeln om anslutningsappar –> aktiviteten Kopiera egenskaper. |
Nej |
Orc-skrivinställningar som stöds under formatSettings:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typ av format Inställningar måste anges till OrcWrite Inställningar. | Ja |
| maxRowsPerFile | När du skriver data till en mapp kan du välja att skriva till flera filer och ange maximalt antal rader per fil. | Nej |
| fileNamePrefix | Tillämpligt när maxRowsPerFile har konfigurerats.Ange filnamnsprefixet när du skriver data till flera filer, vilket resulterade i det här mönstret: <fileNamePrefix>_00000.<fileExtension>. Om det inte anges genereras filnamnsprefixet automatiskt. Den här egenskapen gäller inte när källan är filbaserad lagring eller partitionsalternativaktiverat datalager. |
Nej |
Mappa dataflödesegenskaper
När du mappar dataflöden kan du läsa och skriva till ORC-format i följande datalager: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 och SFTP, och du kan läsa ORC-format i Amazon S3.
Du kan peka på ORC-filer antingen med orc-datauppsättningen eller med hjälp av en infogad datauppsättning.
Källegenskaper
Tabellen nedan visar de egenskaper som stöds av en ORC-källa. Du kan redigera dessa egenskaper på fliken Källalternativ .
När du använder infogad datauppsättning visas ytterligare filinställningar, som är samma som egenskaperna som beskrivs i avsnittet egenskaper för datamängd.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Format | Formatet måste vara orc |
ja | orc |
format |
| Sökvägar för jokertecken | Alla filer som matchar sökvägen för jokertecken bearbetas. Åsidosätter den mapp och filsökväg som angetts i datauppsättningen. | no | Sträng[] | wildcardPaths |
| Partitionsrotsökväg | För fildata som är partitionerade kan du ange en partitionsrotsökväg för att läsa partitionerade mappar som kolumner | no | String | partitionRootPath |
| Lista över filer | Om källan pekar på en textfil som visar filer som ska bearbetas | no | true eller false |
Filförteckning |
| Kolumn för att lagra filnamn | Skapa en ny kolumn med källfilens namn och sökväg | no | String | rowUrlColumn |
| Efter slutförande | Ta bort eller flytta filerna efter bearbetningen. Filsökvägen startar från containerroten | no | Ta bort: true eller false Flytta: [<from>, <to>] |
purgeFiles moveFiles |
| Filtrera efter senast ändrad | Välj att filtrera filer baserat på när de senast ändrades | no | Tidsstämpel | modifiedAfter modifiedBefore |
| Tillåt att inga filer hittas | Om sant utlöses inte ett fel om inga filer hittas | no | true eller false |
ignoreNoFilesFound |
Källexempel
Det associerade dataflödesskriptet för en ORC-källkonfiguration är:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'orc') ~> OrcSource
Egenskaper för mottagare
Tabellen nedan visar de egenskaper som stöds av en ORC-mottagare. Du kan redigera dessa egenskaper på fliken Inställningar.
När du använder infogad datauppsättning visas ytterligare filinställningar, som är samma som egenskaperna som beskrivs i avsnittet egenskaper för datamängd.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Format | Formatet måste vara orc |
ja | orc |
format |
| Rensa mappen | Om målmappen rensas före skrivning | no | true eller false |
trunkera |
| Filnamnsalternativ | Namngivningsformatet för de data som skrivits. Som standard är en fil per partition i format part-#####-tid-<guid> |
no | Mönster: Sträng Per partition: String[] Som data i kolumnen: Sträng Utdata till en enskild fil: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Exempel på mottagare
Det associerade dataflödesskriptet för en ORC-mottagarkonfiguration är:
OrcSource sink(
format: 'orc',
filePattern:'output[n].orc',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> OrcSink
Använda lokalt installerad integrationskörning
Viktigt!
För kopiering som möjliggörs av lokalt installerad integrationskörning, t.ex. mellan lokala datalager och molndatalager, måste du installera 64-bitars JRE 8 (Java Runtime Environment) eller OpenJDK och Microsoft Visual C++ 2010 Redistributable Package på din IR-dator om du inte kopierar ORC-filer som de är. Kontrollera följande stycke med mer information.
För kopiering som körs på lokalt installerad IR med ORC-filserialisering/deserialisering letar tjänsten upp Java-körningen genom att först kontrollera registret (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) för JRE, om det inte hittas, för det andra genom att kontrollera systemvariabeln JAVA_HOME för OpenJDK.
- För att kunna använda JRE: 64-bitars IR kräver 64-bitars JRE. Du hittar den härifrån.
- Så här använder du OpenJDK: Det stöds sedan IR version 3.13. Paketera jvm.dll med alla andra nödvändiga sammansättningar av OpenJDK till en lokalt installerad IR-dator och ange systemmiljövariabeln JAVA_HOME i enlighet med detta.
- Installera Visual C++ 2010 Redistributable Package: Visual C++ 2010 Redistributable Package är inte installerat med lokalt installerad IR-installation. Du hittar den härifrån.
Dricks
Om du kopierar data till/från ORC-format med hjälp av lokalt installerad integrationskörning och stöter på felet "Ett fel uppstod när java anropades, meddelande: java.lang.OutOfMemoryError:Java heap space", kan du lägga till en miljövariabel _JAVA_OPTIONS på datorn som är värd för lokalt installerad IR för att justera min/max-heapstorleken för JVM för att ge en sådan kopia och sedan köra pipelinen igen.
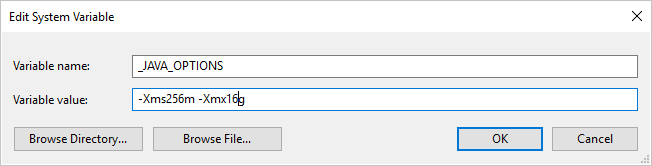
Exempel: ange variabel med _JAVA_OPTIONS värdet -Xms256m -Xmx16g. Flaggan Xms anger den första minnesallokeringspoolen för en virtuell Java-dator (JVM) och Xmx anger den maximala minnesallokeringspoolen. Det innebär att JVM startas med Xms mycket minne och kan använda maximalt Xmx mycket minne. Som standard använder tjänsten min 64 MB och max 1G.