Kopiera data från HDFS-servern med Hjälp av Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du kopierar data från HDFS-servern (Hadoop Distributed File System). Mer information finns i introduktionsartiklarna för Azure Data Factory och Synapse Analytics.
Funktioner som stöds
Den här HDFS-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/-) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
| Ta bort aktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
Mer specifikt stöder HDFS-anslutningsappen:
- Kopiera filer med hjälp av Windows -autentisering (Kerberos) eller anonym autentisering.
- Kopiera filer med hjälp av webhdfs-protokollet eller inbyggt DistCp-stöd .
- Kopiera filer som de är eller genom att parsa eller generera filer med de filformat och komprimeringskodex som stöds.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Kommentar
Kontrollera att integreringskörningen kan komma åt alla [namnnodserver]:[namnnodport] och [datanodservrar]:[datanodport] i Hadoop-klustret. Standardporten [namnnod] är 50070 och standardporten [datanod] är 50075.
Kom igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till HDFS med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till HDFS i Azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter HDFS och välj HDFS-anslutningsappen.
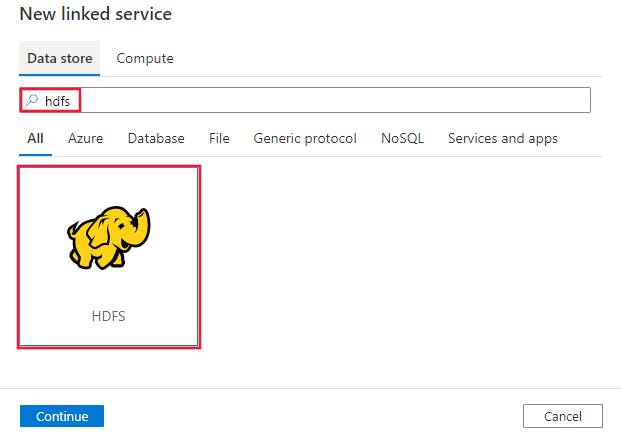
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
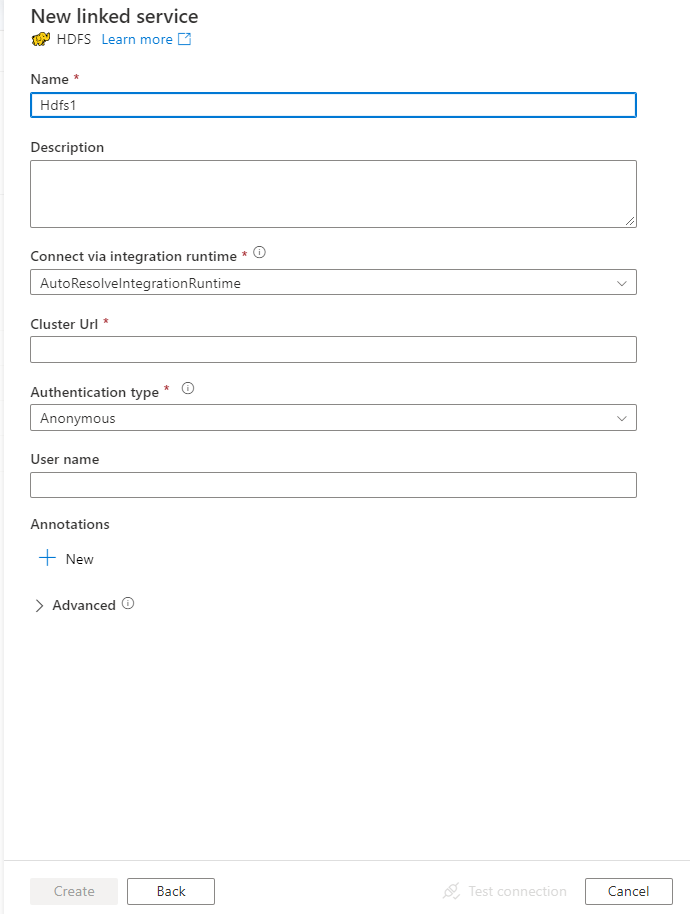
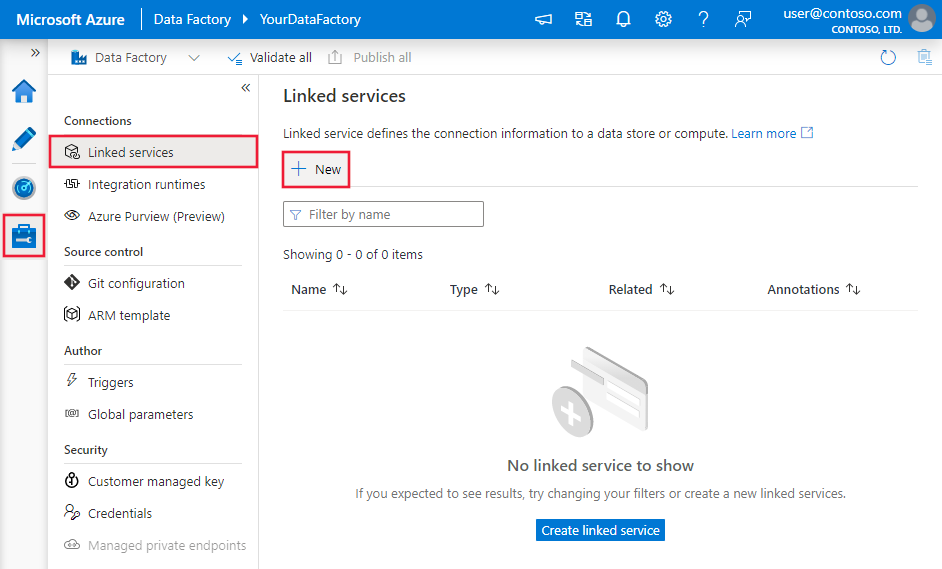
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för HDFS.
Länkade tjänstegenskaper
Följande egenskaper stöds för den länkade HDFS-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på HDFS. | Ja |
| URL | URL:en till HDFS | Ja |
| authenticationType | De tillåtna värdena är Anonyma eller Windows. Information om hur du konfigurerar din lokala miljö finns i avsnittet Använda Kerberos-autentisering för HDFS-anslutningsappen . |
Ja |
| userName | Användarnamnet för Windows-autentisering. För Kerberos-autentisering anger du <username>@<domain>.com. | Ja (för Windows-autentisering) |
| password | Lösenordet för Windows-autentisering. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i ett Azure-nyckelvalv. | Ja (för Windows-autentisering) |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Mer information finns i avsnittet Krav . Om integreringskörningen inte har angetts använder tjänsten standardkörningen för Azure Integration Runtime. | Nej |
Exempel: använda anonym autentisering
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exempel: använda Windows-autentisering
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i Datauppsättningar.
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Följande egenskaper stöds för HDFS under location inställningar i den formatbaserade datauppsättningen:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under location i datauppsättningen måste vara inställd på HdfsLocation. |
Ja |
| folderPath | Sökvägen till mappen. Om du vill använda ett jokertecken för att filtrera mappen hoppar du över den här inställningen och anger sökvägen i inställningarna för aktivitetskällan. | Nej |
| fileName | Filnamnet under den angivna folderPath. Om du vill använda ett jokertecken för att filtrera filer hoppar du över den här inställningen och anger filnamnet i inställningarna för aktivitetskällan. | Nej |
Exempel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i Pipelines och aktiviteter. Det här avsnittet innehåller en lista över egenskaper som stöds av HDFS-källan.
HDFS som källa
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Följande egenskaper stöds för HDFS under storeSettings inställningar i den formatbaserade kopieringskällan:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under storeSettings måste anges till HdfsReadSettings. |
Ja |
| Leta upp filerna som ska kopieras | ||
| ALTERNATIV 1: statisk sökväg |
Kopiera från mappen eller filsökvägen som anges i datauppsättningen. Om du vill kopiera alla filer från en mapp anger du wildcardFileName dessutom som *. |
|
| ALTERNATIV 2: jokertecken - jokerteckenFolderPath |
Mappsökvägen med jokertecken för att filtrera källmappar. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken). Använd ^ för att fly om ditt faktiska mappnamn har ett jokertecken eller det här escape-tecknet inuti. Fler exempel finns i Exempel på mapp- och filfilter. |
Nej |
| ALTERNATIV 2: jokertecken - jokerteckenFileName |
Filnamnet med jokertecken under den angivna mappenPath/wildcardFolderPath för att filtrera källfiler. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller ett enda tecken); använd ^ för att fly om ditt faktiska filnamn har ett jokertecken eller det här escape-tecknet inuti. Fler exempel finns i Exempel på mapp- och filfilter. |
Ja |
| ALTERNATIV 3: en lista över filer – fileListPath |
Anger att en angiven filuppsättning ska kopieras. Peka på en textfil som innehåller en lista över filer som du vill kopiera (en fil per rad, med den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen). När du använder det här alternativet ska du inte ange filnamnet i datauppsättningen. Fler exempel finns i Exempel på fillista. |
Nej |
| Ytterligare inställningar | ||
| rekursiv | Anger om data läse rekursivt från undermapparna eller endast från den angivna mappen. När recursive är inställt på sant och mottagaren är ett filbaserat arkiv kopieras inte en tom mapp eller undermapp i mottagaren. Tillåtna värden är sanna (standard) och falska. Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| deleteFilesAfterCompletion | Anger om de binära filerna kommer att tas bort från källarkivet när de har flyttats till målarkivet. Filborttagningen är per fil, så när kopieringsaktiviteten misslyckas ser du att vissa filer redan har kopierats till målet och tagits bort från källan, medan andra fortfarande finns kvar i källarkivet. Den här egenskapen är endast giltig i scenariot med kopiering av binära filer. Standardvärdet: false. |
Nej |
| modifiedDatetimeStart | Filer filtreras baserat på attributet Senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet 2018-12-01T05:00:00Z. Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL innebär det att de filer vars senast ändrade attribut är större än eller lika med datetime-värdet är markerade. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL innebär det att de filer vars senast ändrade attribut är mindre än datetime-värdet har valts.Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| modifiedDatetimeEnd | Samma som ovan. | |
| enablePartitionDiscovery | För filer som är partitionerade anger du om partitionerna ska parsas från filsökvägen och lägga till dem som ytterligare källkolumner. Tillåtna värden är false (standard) och true. |
Nej |
| partitionRootPath | När partitionsidentifiering är aktiverat anger du den absoluta rotsökvägen för att läsa partitionerade mappar som datakolumner. Om det inte anges, som standard, – När du använder filsökvägen i datauppsättningen eller listan över filer på källan är partitionsrotsökvägen den sökväg som konfigurerats i datauppsättningen. – När du använder mappfilter för jokertecken är partitionsrotsökvägen undersökvägen före det första jokertecknet. Anta till exempel att du konfigurerar sökvägen i datauppsättningen som "root/folder/year=2020/month=08/day=27": – Om du anger partitionsrotsökväg som "root/folder/year=2020" genererar kopieringsaktiviteten ytterligare två kolumner month och day med värdet "08" respektive "27", utöver kolumnerna i filerna.– Om partitionsrotsökvägen inte har angetts genereras ingen extra kolumn. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
| DistCp-inställningar | ||
| distcpSettings | Egenskapsgruppen som ska användas när du använder HDFS DistCp. | Nej |
| resourceManagerEndpoint | YARN-slutpunkten (ännu en resursförhandlare) | Ja, om du använder DistCp |
| tempScriptPath | En mappsökväg som används för att lagra distCp-kommandoskriptet temp. Skriptfilen genereras och tas bort när kopieringsjobbet är klart. | Ja, om du använder DistCp |
| distcpOptions | Ytterligare alternativ för DistCp-kommandot. | Nej |
Exempel:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exempel på mapp- och filfilter
I det här avsnittet beskrivs det resulterande beteendet om du använder ett jokerteckenfilter med mappsökvägen och filnamnet.
| folderPath | fileName | rekursiv | Källmappens struktur och filterresultat (filer i fetstil hämtas) |
|---|---|---|---|
Folder* |
(tom, använd standard) | falskt | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(tom, använd standard) | true | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
falskt | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Exempel på fillista
I det här avsnittet beskrivs hur du använder en fillistesökväg i kopieringsaktivitetskällan. Det förutsätter att du har följande källmappstruktur och vill kopiera filerna som är av fetstil:
| Exempel på källstruktur | Innehåll i FileListToCopy.txt | Konfiguration |
|---|---|---|
| rot MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Undermapp1/File3.csv Undermapp1/File5.csv |
I datauppsättningen: – Mappsökväg: root/FolderAI kopieringsaktivitetskällan: – Sökväg till fillista: root/Metadata/FileListToCopy.txt Sökvägen till fillistan pekar på en textfil i samma datalager som innehåller en lista över filer som du vill kopiera (en fil per rad, med den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen). |
Använda DistCp för att kopiera data från HDFS
DistCp är ett hadoop-internt kommandoradsverktyg för att utföra en distribuerad kopia i ett Hadoop-kluster. När du kör ett kommando i DistCp visas först alla filer som ska kopieras och skapar sedan flera mappningsjobb i Hadoop-klustret. Varje map-jobb gör en binär kopia från källan till mottagaren.
Kopieringsaktiviteten stöder användning av DistCp för att kopiera filer till Azure Blob Storage (inklusive mellanlagrad kopia) eller ett Azure Data Lake-lager. I det här fallet kan DistCp dra nytta av klustrets kraft i stället för att köra på den lokala integrationskörningen. Att använda DistCp ger bättre dataflöde för kopiering, särskilt om klustret är mycket kraftfullt. Baserat på konfigurationen skapar kopieringsaktiviteten automatiskt ett DistCp-kommando, skickar det till Hadoop-klustret och övervakar kopieringsstatusen.
Förutsättningar
Om du vill använda DistCp för att kopiera filer från HDFS till Azure Blob Storage (inklusive mellanlagrad kopia) eller Azure Data Lake Store kontrollerar du att Hadoop-klustret uppfyller följande krav:
MapReduce- och YARN-tjänsterna är aktiverade.
YARN-versionen är 2.5 eller senare.
HDFS-servern är integrerad med ditt måldatalager: Azure Blob Storage eller Azure Data Lake Store (ADLS Gen1):
- Azure Blob FileSystem stöds internt sedan Hadoop 2.7. Du behöver bara ange JAR-sökvägen i Hadoop-miljökonfigurationen.
- Azure Data Lake Store FileSystem paketeras från Hadoop 3.0.0-alpha1. Om hadoop-klusterversionen är tidigare än den versionen måste du manuellt importera Azure Data Lake Store-relaterade JAR-paket (azure-datalake-store.jar) till klustret härifrån och ange JAR-filsökvägen i Hadoop-miljökonfigurationen.
Förbered en temp-mapp i HDFS. Den här temporära mappen används för att lagra ett DistCp-gränssnittsskript, så den upptar utrymme på KB-nivå.
Kontrollera att det användarkonto som tillhandahålls i den länkade HDFS-tjänsten har behörighet att:
- Skicka ett program i YARN.
- Skapa en undermapp och läsa/skriva filer under temp-mappen.
-konfigurationer
För DistCp-relaterade konfigurationer och exempel går du till avsnittet HDFS som källa .
Använda Kerberos-autentisering för HDFS-anslutningsappen
Det finns två alternativ för att konfigurera den lokala miljön för att använda Kerberos-autentisering för HDFS-anslutningsappen. Du kan välja den som passar din situation bättre.
- Alternativ 1: Ansluta till en lokalt installerad integrationskörningsdator i Kerberos-sfären
- Alternativ 2: Aktivera ömsesidigt förtroende mellan Windows-domänen och Kerberos-sfären
För båda alternativen kontrollerar du att du aktiverar webhdfs för Hadoop-kluster:
Skapa HTTP-huvudnamnet och nyckelfliken för webhdfs.
Viktigt!
HTTP Kerberos-huvudkontot måste börja med "HTTP/" enligt Kerberos HTTP SPNEGO-specifikation. Läs mer här.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS-konfigurationsalternativ: Lägg till följande tre egenskaper i
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Alternativ 1: Ansluta till en lokalt installerad integrationskörningsdator i Kerberos-sfären
Krav
- Den lokalt installerade integrationskörningsdatorn måste ansluta till Kerberos-sfären och kan inte ansluta till någon Windows-domän.
Konfigurera
På KDC-servern:
Skapa ett huvudnamn och ange lösenordet.
Viktigt!
Användarnamnet får inte innehålla värdnamnet.
Kadmin> addprinc <username>@<REALM.COM>
På den lokalt installerade integrationskörningsdatorn:
Kör Ksetup-verktyget för att konfigurera Kerberos Key Distribution Center (KDC) server och sfär.
Datorn måste konfigureras som medlem i en arbetsgrupp eftersom en Kerberos-sfär skiljer sig från en Windows-domän. Du kan uppnå den här konfigurationen genom att ange Kerberos-sfären och lägga till en KDC-server genom att köra följande kommandon. Ersätt REALM.COM med ditt eget sfärnamn.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>Starta om datorn när du har kört dessa kommandon.
Kontrollera konfigurationen med
Ksetupkommandot . Utdata bör se ut så här:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
I din datafabrik eller Synapse-arbetsyta:
- Konfigurera HDFS-anslutningsappen med hjälp av Windows-autentisering tillsammans med ditt Kerberos-huvudnamn och lösenord för att ansluta till HDFS-datakällan. Information om konfigurationen finns i avsnittet för länkade HDFS-tjänstegenskaper .
Alternativ 2: Aktivera ömsesidigt förtroende mellan Windows-domänen och Kerberos-sfären
Krav
- Den lokalt installerade integrationskörningsdatorn måste ansluta till en Windows-domän.
- Du behöver behörighet att uppdatera domänkontrollantens inställningar.
Konfigurera
Kommentar
Ersätt REALM.COM och AD.COM i följande självstudiekurs med ditt eget sfärnamn och domänkontrollant.
På KDC-servern:
Redigera KDC-konfigurationen i filen krb5.conf så att KDC kan lita på Windows-domänen genom att referera till följande konfigurationsmall. Som standard finns konfigurationen på /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }När du har konfigurerat filen startar du om KDC-tjänsten.
Förbered ett huvudnamn med namnet krbtgt/REALM.COM@AD.COM på KDC-servern med följande kommando:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMI konfigurationsfilen för hadoop.security.auth_to_local HDFS-tjänsten lägger du till
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
På domänkontrollanten:
Kör följande
Ksetupkommandon för att lägga till en sfärpost:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMUpprätta förtroende från Windows-domänen till Kerberos-sfären. [lösenord] är lösenordet för huvudkontot krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Välj krypteringsalgoritmen som används i Kerberos.
a. Välj Serverhanteraren>Grupprinciphantering>Domängruppprincipobjekt>>Standard eller Aktiv domänprincip och välj sedan Redigera.
b. I fönstret Redigerare för grupprinciphantering väljer du Datorkonfigurationsprinciper>>Windows-inställningar>Säkerhetsinställningar>Säkerhetsalternativ för lokala principer>och konfigurerar sedan Nätverkssäkerhet: Konfigurera krypteringstyper som tillåts för Kerberos.
c. Välj den krypteringsalgoritm som du vill använda när du ansluter till KDC-servern. Du kan välja alla alternativ.
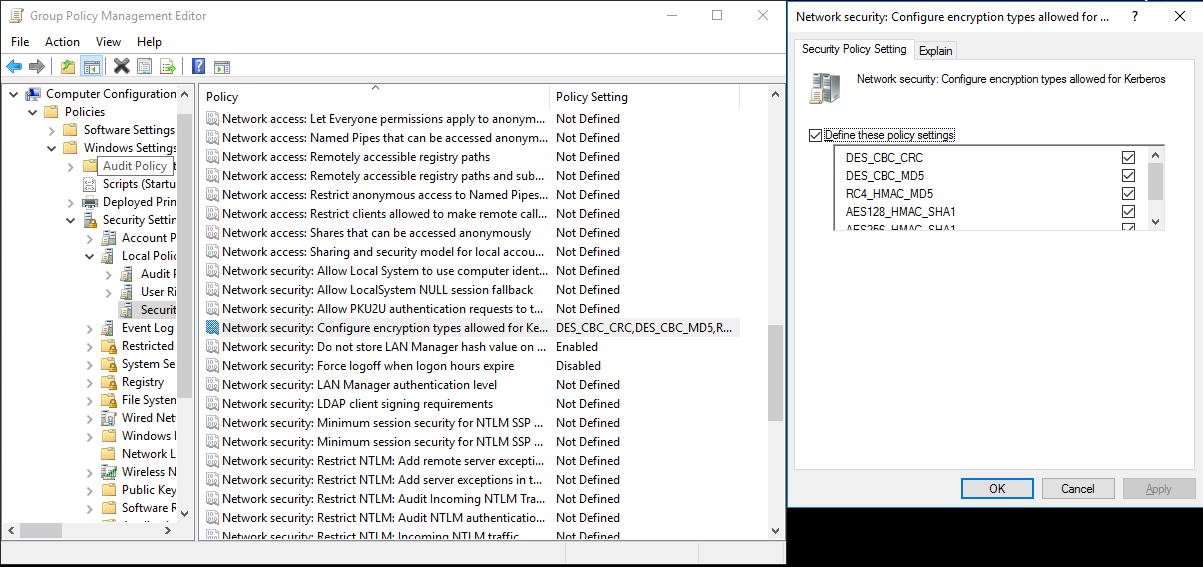
d.
KsetupAnvänd kommandot för att ange krypteringsalgoritmen som ska användas på den angivna sfären.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Skapa mappningen mellan domänkontot och Kerberos-huvudnamnet så att du kan använda Kerberos-huvudnamnet i Windows-domänen.
a. Välj Administrationsverktyg>Active Directory -användare och datorer.
b. Konfigurera avancerade funktioner genom att välja Visa>avancerade funktioner.
c. Högerklicka på det konto som du vill skapa mappningar till i fönstret Avancerade funktioner och välj fliken Kerberos-namn i fönstret Namnmappningar.
d. Lägg till ett huvudnamn från sfären.
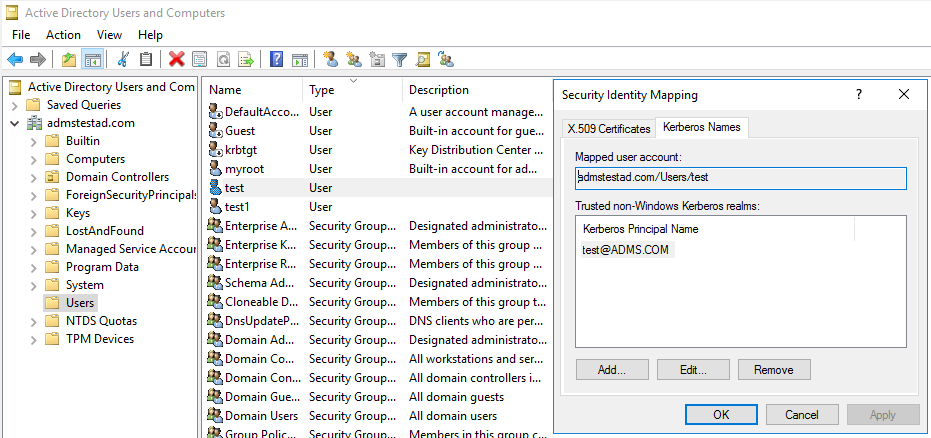
På den lokalt installerade integrationskörningsdatorn:
Kör följande
Ksetupkommandon för att lägga till en sfärpost.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
I din datafabrik eller Synapse-arbetsyta:
- Konfigurera HDFS-anslutningsappen med hjälp av Windows-autentisering tillsammans med antingen ditt domänkonto eller Kerberos-huvudnamn för att ansluta till HDFS-datakällan. Mer information om konfiguration finns i avsnittet för länkade HDFS-tjänstegenskaper .
Egenskaper för uppslagsaktivitet
Information om egenskaper för uppslagsaktivitet finns i Sökningsaktivitet.
Ta bort aktivitetsegenskaper
Information om egenskaper för ta bort aktivitet finns i Ta bort aktivitet.
Äldre modeller
Kommentar
Följande modeller stöds fortfarande, precis som för bakåtkompatibilitet. Vi rekommenderar att du använder den tidigare diskuterade nya modellen eftersom redigeringsgränssnittet har växlat till att generera den nya modellen.
Äldre datauppsättningsmodell
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till FileShare | Ja |
| folderPath | Sökvägen till mappen. Ett jokerteckenfilter stöds. Tillåtna jokertecken är * (matchar noll eller fler tecken) och ? (matchar noll eller ett enda tecken); använd ^ för att fly om ditt faktiska filnamn har ett jokertecken eller det här escape-tecknet inuti. Exempel: rootfolder/subfolder/, se fler exempel i mapp- och filfilterexempel. |
Ja |
| fileName | Namn- eller jokerteckenfiltret för filerna under den angivna "folderPath". Om du inte anger något värde för den här egenskapen pekar datauppsättningen på alla filer i mappen. För filter är * tillåtna jokertecken (matchar noll eller fler tecken) och ? (matchar noll eller ett enda tecken).- Exempel 1: "fileName": "*.csv"- Exempel 2: "fileName": "???20180427.txt"Använd ^ för att fly om ditt faktiska mappnamn har ett jokertecken eller det här escape-tecknet inuti. |
Nej |
| modifiedDatetimeStart | Filer filtreras baserat på attributet Senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet 2018-12-01T05:00:00Z. Tänk på att den övergripande prestandan för dataflytt påverkas genom att aktivera den här inställningen när du vill använda ett filfilter på ett stort antal filer. Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL innebär det att de filer vars senast ändrade attribut är större än eller lika med datetime-värdet är markerade. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL innebär det att de filer vars senast ändrade attribut är mindre än datetime-värdet har valts. |
Nej |
| modifiedDatetimeEnd | Filer filtreras baserat på attributet Senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet 2018-12-01T05:00:00Z. Tänk på att den övergripande prestandan för dataflytt påverkas genom att aktivera den här inställningen när du vill använda ett filfilter på ett stort antal filer. Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL innebär det att de filer vars senast ändrade attribut är större än eller lika med datetime-värdet är markerade. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL innebär det att de filer vars senast ändrade attribut är mindre än datetime-värdet har valts. |
Nej |
| format | Om du vill kopiera filer som de är mellan filbaserade lager (binär kopia) hoppar du över formatavsnittet i både indata- och utdatauppsättningsdefinitionerna. Om du vill parsa filer med ett visst format stöds följande filformattyper: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Ange typegenskapen under format till ett av dessa värden. Mer information finns i avsnitten Textformat, JSON-format, Avro-format, ORC-format och Parquet-format . |
Nej (endast för scenario med binär kopiering) |
| komprimering | Ange typ och komprimeringsnivå för data. Mer information finns i Filformat som stöds och komprimeringskodex. Typer som stöds är: Gzip, Deflate, Bzip2 och ZipDeflate. Nivåerna som stöds är: Optimala och snabbaste. |
Nej |
Dricks
Om du vill kopiera alla filer under en mapp anger du endast folderPath .
Om du vill kopiera en enskild fil med ett angivet namn anger du folderPath med mappdel och fileName med filnamn.
Om du vill kopiera en delmängd av filer under en mapp anger du folderPath med mappdel och fileName med jokerteckenfilter.
Exempel:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Källmodell för äldre kopieringsaktivitet
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till HdfsSource. | Ja |
| rekursiv | Anger om data läse rekursivt från undermapparna eller endast från den angivna mappen. När rekursivt är inställt på true och mottagaren är ett filbaserat arkiv kopieras eller skapas inte en tom mapp eller undermapp i mottagaren. Tillåtna värden är sanna (standard) och falska. |
Nej |
| distcpSettings | Egenskapsgruppen när du använder HDFS DistCp. | Nej |
| resourceManagerEndpoint | YARN Resource Manager-slutpunkten | Ja, om du använder DistCp |
| tempScriptPath | En mappsökväg som används för att lagra distCp-kommandoskriptet temp. Skriptfilen genereras och tas bort när kopieringsjobbet är klart. | Ja, om du använder DistCp |
| distcpOptions | Ytterligare alternativ finns i Kommandot DistCp. | Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Exempel: HDFS-källa i kopieringsaktivitet med DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.