Utforska och skapa tables i DBFS
Viktigt
Den här dokumentationen har dragits tillbaka och kanske inte uppdateras. De produkter, tjänster eller tekniker som nämns i det här innehållet stöds inte längre. Se Ladda upp filer till Azure Databricks, Skapa eller ändra en table med filuppladdningoch Vad är Catalog Explorer?.
Få åtkomst till det äldre DBFS-filuppladdnings- och table-skapargränssnittet via -lägg-till-datagränssnittet. Klicka på ![]() Ny > data > DBFS.
Ny > data > DBFS.
Du kan också komma åt användargränssnittet från notebook-filer genom att klicka på Arkiv > Lägg till data.
Databricks rekommenderar att du använder Catalog Explorer för en bättre upplevelse för att visa dataobjekt och hantera ACL:er och Skapa eller ändra table från filuppladdningssidan för att enkelt mata in små filer i Delta Lake.
Anteckning
Tillgängligheten för vissa element som beskrivs i den här artikeln varierar beroende på konfigurationer av arbetsytor. Kontakta arbetsytans administratör eller Azure Databricks-kontoteamet.
Om du har små datafiler på den lokala datorn som du vill analysera med Azure Databricks kan du importera dem till DBFS med hjälp av användargränssnittet.
Anteckning
Arbetsyteadministratörer kan inaktivera den här funktionen. Mer information finns i Hantera datauppladdning.
Du kan starta dbfs-användargränssnittet för att skapa table antingen genom att klicka på ![]() Ny i sidofältet eller knappen DBFS i lägga till datagränssnittet. Du kan fylla i en table från filer i DBFS eller ladda upp filer.
Ny i sidofältet eller knappen DBFS i lägga till datagränssnittet. Du kan fylla i en table från filer i DBFS eller ladda upp filer.
Med användargränssnittet kan du bara skapa externa tables.
Välj en datakälla och följ stegen i motsvarande avsnitt för att konfigurera table.
Om en Azure Databricks-arbetsyteadministratör har inaktiverat alternativet Ladda upp filhar du inte möjlighet att ladda upp filer. du kan skapa tables med någon av de andra datakällorna.
Instruktioner för att ladda upp fil
- Dra filer till dropzone-filen Filer eller klicka på dropzone för att bläddra och välja filer. Efter uppladdningen visas en sökväg för varje fil. Sökvägen kommer att likna
/FileStore/tables/<filename>-<integer>.<file-type>. Du kan använda den här sökvägen i en notebook-fil för att läsa data. - Klicka på Skapa Table med användargränssnittet.
- I listrutan Kluster väljer du ett kluster.
Instruktioner för DBFS
- Select en fil.
- Klicka på Skapa Table med användargränssnittet.
- I listrutan Kluster väljer du ett kluster.
- Dra filer till dropzone-filen Filer eller klicka på dropzone för att bläddra och välja filer. Efter uppladdningen visas en sökväg för varje fil. Sökvägen kommer att likna
Klicka på Förhandsversion Table för att visa table.
I fältet Table Namn kan du åsidosätta standardnamnet för table. Ett table-namn får bara innehålla små alfanumeriska tecken och understreck och måste börja med en liten bokstav eller understreck.
I fältet Skapa i databas kan du åsidosätta den valda
defaultdatabasen.I fältet Filtyp kan du åsidosätta den härledda filtypen.
Om filtypen är CSV:
- I fältet Column Avgränsareselect om den uppskjutna avgränsare ska åsidosättas.
- Ange om den första raden ska användas som column titel.
- Ange om du vill härleda schema.
Om filtypen är JSON anger du om filen är flera rader.
Klicka på Skapa Table.
Anteckning
Arbetsytor med Catalog Explorer aktiverat har inte åtkomst till det äldre beteende som beskrivs nedan.
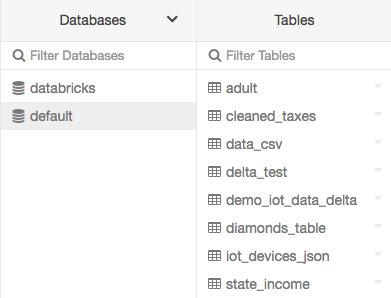
Klicka på ikonen ![]() Catalog i sidofältet. Azure Databricks väljer ett kluster som körs som du har åtkomst till. Mappen Databaser visar list av databaser med den
Catalog i sidofältet. Azure Databricks väljer ett kluster som körs som du har åtkomst till. Mappen Databaser visar list av databaser med den default databasen markerad. Mappen Tables visar list för tables i default-databasen.
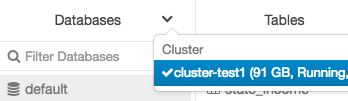
Du kan ändra klustret från menyn Databaser, skapa table användargränssnitteteller visa table användargränssnittet. Till exempel från menyn Databaser:
 Klicka på nedåtpilen överst i mappen Databaser.
Klicka på nedåtpilen överst i mappen Databaser.Select ett kluster.
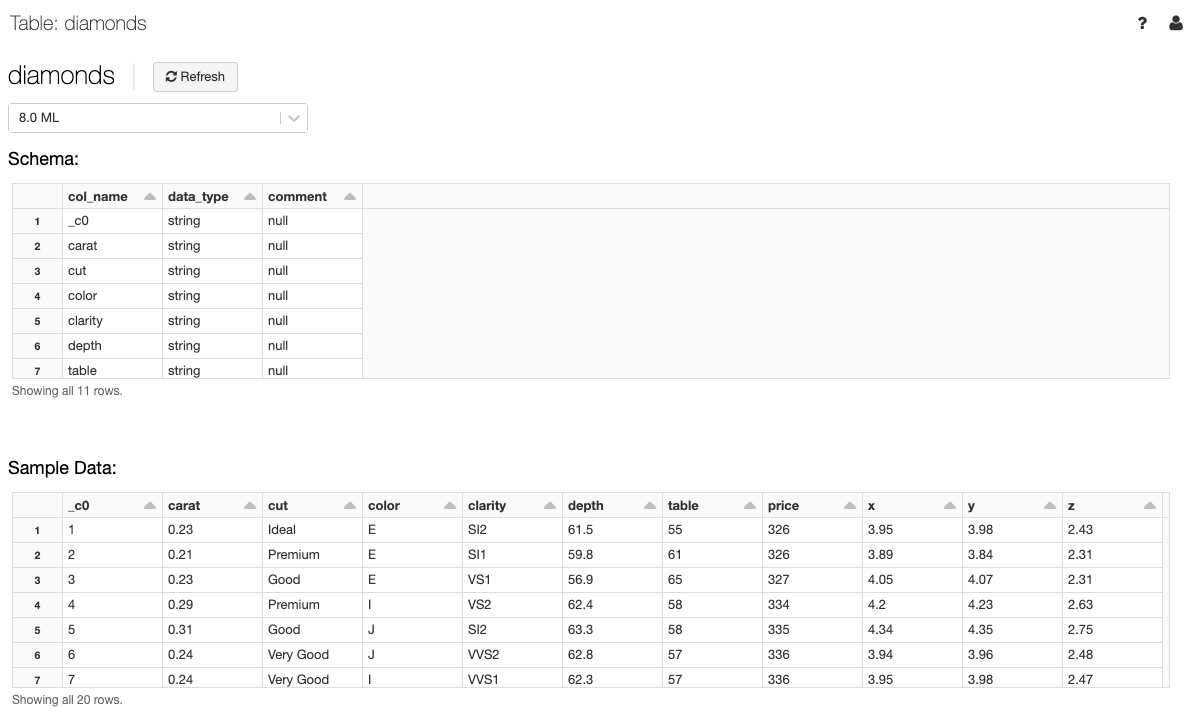
Detaljvyn table visar tableschema och exempeldata.
Klicka på ikonen
 Catalog i sidofältet.
Catalog i sidofältet.I mappen Databaser klickar du på en databas.
I mappen Tables klickar du på namnet på table.
I listrutan Kluster kan du (valfritt) select ett annat kluster för att visa table förhandsgranskningen.
Anteckning
För att visa förhandsversionen av
körs en Spark SQL-fråga på det kluster som valts i listrutan Kluster på . Om klustret redan har en arbetsbelastning som körs på det, kan det ta längre tid att ladda förhandsversionen table.
- Klicka på ikonen Catalog i sidofältet.
- Klicka på listrutan
 bredvid namnet på table och selectTa bort.
bredvid namnet på table och selectTa bort.