Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du uppdaterar ett befintligt index i Azure AI Search med schemaändringar eller innehållsändringar genom inkrementell indexering. Den förklarar de omständigheter under vilka återskapanden krävs och ger rekommendationer för att minimera effekterna av återskapanden på pågående frågebegäranden.
Under aktiv utveckling är det vanligt att släppa och återskapa index när du itererar över indexdesignen. De flesta utvecklare arbetar med ett litet representativt urval av sina data så att omindexeringen går snabbare.
För schemaändringar för program som redan är i produktion rekommenderar vi att du skapar och testar ett nytt index som körs sida vid sida med ett befintligt index. Använd ett indexalias för att växla i det nya indexet så att du kan undvika ändringar i programkoden.
Uppdatera innehåll
Inkrementell indexering och synkronisering av ett index mot ändringar i källdata är grundläggande för de flesta sökprogram. I det här avsnittet beskrivs arbetsflödet för att lägga till, ta bort eller skriva över innehållet i ett sökindex via REST-API:et, men Azure SDK:erna ger motsvarande funktioner.
Kroppen i begäran innehåller ett eller flera dokument som ska indexeras. I begäran är varje dokument i indexet:
- Identifieras med en unik skiftlägeskänslig nyckel.
- Associerad med en åtgärd: "upload", "delete", "merge" eller "mergeOrUpload".
- Fylls med en uppsättning namn/värde-par för varje fält som du lägger till eller uppdaterar.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (name/value pairs matching index schema)
...
},
...
]
}
Använd först API:erna för att läsa in dokument, till exempel Dokument – Index (REST) eller ett motsvarande API i Azure SDK:er. Mer information om indexeringstekniker finns i Läsa in dokument.
För en stor uppdatering rekommenderas batchbearbetning (upp till 1 000 dokument per batch eller cirka 16 MB per batch, beroende på vilken gräns som kommer först) och förbättrar indexeringsprestanda avsevärt.
Ange parametern
@search.actionför API:et för att fastställa effekten på befintliga dokument.Åtgärd Effekt ta bort Tar bort hela dokumentet från indexet. Om du vill ta bort ett enskilt fält använder du sammanfoga i stället och anger fältet i fråga till null. Borttagna dokument och fält frigör inte omedelbart utrymme i indexet. Med några minuters mellanrum utför en bakgrundsprocess den fysiska borttagningen. Oavsett om du använder Azure Portal eller ett API för att returnera indexstatistik kan du förvänta dig en liten fördröjning innan borttagningen återspeglas i Azure Portal och via API:er. sammanslå Uppdaterar ett dokument som redan finns och misslyckas med ett dokument som inte kan hittas. Sammanslagning ersätter befintliga värden. Därför bör du söka efter samlingsfält som innehåller flera värden, till exempel fält av typen Collection(Edm.String). Om etttagsfält till exempel börjar med värdet["budget"]och du kör en sammanslagning med["economy", "pool"]ärtagsdet slutliga värdet för fältet["economy", "pool"]. Det blir det inte["budget", "economy", "pool"].
Samma beteende gäller för komplexa samlingar. Om dokumentet innehåller ett komplext samlingsfält med namnet Rum med värdet[{ "Type": "Budget Room", "BaseRate": 75.0 }], och du kör en sammanslagning med värdet[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }], blir[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]det slutliga värdet för fältet Rum . Den lägger inte till eller sammanfogar nya och befintliga värden.slå ihop eller ladda upp Fungerar som sammanslagning om dokumentet finns och ladda upp om dokumentet är nytt. Det här är den vanligaste åtgärden för inkrementella uppdateringar. ladda upp Liknar en "upsert", där dokumentet infogas om det är nytt, och uppdateras eller ersätts om det redan finns. Om dokumentet saknar värden som krävs för indexet är dokumentfältets värde inställt på null.
Sökfrågor fortsätter att köras under indexeringen, men om du uppdaterar eller tar bort befintliga fält kan du förvänta dig blandade resultat och en högre förekomst av strypning.
Kommentar
Det finns inga garantier för i vilken ordning åtgärderna i begärandetexten körs. Det rekommenderas inte att ha flera "sammanslagningsåtgärder" associerade med samma dokument i en och samma begärandetext. Om det krävs flera "sammanslagningsåtgärder" för samma dokument utför du den sammanfogande klientsidan innan du uppdaterar dokumentet i sökindexet.
Svar
Statuskod 200 returneras för ett lyckat svar, vilket innebär att alla objekt har blivit lagrade varaktigt och börjar indexeras. Indexering körs i bakgrunden och gör nya dokument tillgängliga (dvs. frågebara och sökbara) några sekunder efter att indexeringsåtgärden har slutförts. Den specifika fördröjningen beror på belastningen på tjänsten.
Lyckad indexering indikeras av att statusegenskapen har angetts till true för alla objekt, samt egenskapen statusCode som anges till antingen 201 (för nyligen uppladdade dokument) eller 200 (för sammanfogade eller borttagna dokument):
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
Statuskod 207 returneras när minst ett objekt inte har indexerats. Objekt som inte har indexerats har statusfältet inställt på false. Egenskaperna errorMessage och statusCode anger orsaken till indexeringsfelet:
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
Egenskapen errorMessage anger orsaken till indexeringsfelet om möjligt.
I följande tabell förklaras de olika statuskoder per dokument som kan returneras i svaret. Vissa statuskoder anger problem med själva begäran, medan andra anger tillfälliga felvillkor. Det senare bör du försöka igen efter en fördröjning.
| Statuskod | Innebörd | Återförsökbar | Anteckningar |
|---|---|---|---|
| 200 | Dokumentet har ändrats eller tagits bort. | saknas | Borttagningsåtgärder är idempotenta. Det innebär att även om det inte finns någon dokumentnyckel i indexet resulterar ett försök att ta bort en borttagningsåtgärd med den nyckeln i en statuskod på 200. |
| 201 | Dokumentet har skapats. | saknas | |
| 400 | Det uppstod ett fel i dokumentet som förhindrade att det indexerades. | Nej | Felmeddelandet i svaret anger vad som är fel med dokumentet. |
| 404 | Det gick inte att sammanfoga dokumentet eftersom den angivna nyckeln inte finns i indexet. | Nej | Det här felet uppstår inte för uppladdningar eftersom de skapar nya dokument och det uppstår inte för borttagningar eftersom de är idempotenter. |
| 409 | En versionskonflikt upptäcktes när ett dokument skulle indexeras. | Ja | Detta kan inträffa när du försöker indexera samma dokument mer än en gång samtidigt. |
| 422 | Indexet är tillfälligt otillgängligt eftersom det uppdaterades med flaggan ”allowIndexDowntime” inställd på ”true”. | Ja | |
| 429 | För många begäranden | Ja | Om du får den här felkoden under indexeringen innebär det vanligtvis att du har ont om lagringsutrymme. När du närmar dig lagringsgränser kan tjänsten ange ett tillstånd där du inte kan lägga till eller uppdatera förrän du tar bort vissa dokument. Mer information finns i Planera och hantera kapacitet om du vill ha mer lagringsutrymme eller frigöra utrymme genom att ta bort dokument. |
| 503 | Din söktjänst är tillfälligt otillgänglig, möjligen på grund av hög belastning. | Ja | I detta fall bör koden vänta innan ett nytt försök görs så att tjänsten inte är otillgänglig längre än nödvändigt. |
Om klientkoden ofta stöter på ett 207-svar är en möjlig orsak att systemet är under belastning. Du kan bekräfta detta genom att kontrollera egenskapen statusCode för 503. Om statusCode är 503 rekommenderar vi att du begränsar indexeringsbegäranden. Annars kan systemet börja avvisa alla begäranden med 503-fel om indexeringstrafiken inte avtar.
Statuskod 429 anger att du har överskridit din kvot för antalet dokument per index. Du måste antingen uppgradera för högre kapacitetsgränser eller skapa ett nytt index.
Kommentar
När du laddar upp DateTimeOffset värden med tidszonsinformation till ditt index normaliserar Azure AI Search dessa värden till UTC. Till exempel lagras 2024-01-13T14:03:00-08:00 som 2024-01-13T22:03:00Z. Om du behöver lagra information om tidszonen lägger du till en extra kolumn i ditt index för den här datapunkten.
Tips för inkrementell indexering
Indexomvandlare automatiserar successiv indexering. Om du kan använda en indexerare, och om datakällan stöder ändringsspårning, kan du köra indexeraren enligt ett återkommande schema för att lägga till, uppdatera eller skriva över sökbart innehåll så att det synkroniseras med dina externa data.
Om du gör indexanrop direkt via push-API:et använder
mergeOrUploaddu som sökåtgärd.Nyttolasten måste innehålla nycklar eller identifierare för varje dokument som du vill lägga till, uppdatera eller ta bort.
Om ditt index innehåller vektorfält och du anger
storedegenskapen till false kontrollerar du att du anger vektorn i den partiella dokumentuppdateringen, även om värdet är oförändrat. En bieffekt av inställningenstoredtill false är att vektorer släpps vid en omindexeringsåtgärd. Genom att tillhandahålla vektorn i dokumentnyttolasten förhindras detta.Om du vill uppdatera innehållet i enkla fält och underfält i komplexa typer listar du bara de fält som du vill ändra. Om du till exempel bara behöver uppdatera ett beskrivningsfält ska nyttolasten bestå av dokumentnyckeln och den ändrade beskrivningen. Om du utelämnar andra fält bevaras deras befintliga värden.
Om du vill sammanfoga infogade ändringar i strängsamlingen anger du hela värdet. Kom ihåg fältexemplet
tagsfrån föregående avsnitt. Nya värden skriver över de gamla värdena för ett helt fält och det finns ingen sammanslagning i innehållet i ett fält.
Här är ett REST API-exempel som visar följande tips:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Uppdatera ett indexschema
Indexschemat definierar de fysiska datastrukturer som skapats i söktjänsten, så det finns inte många schemaändringar som du kan göra utan att behöva återskapa dem fullständigt.
Uppdateringar utan ombyggnad
I följande lista räknas de schemaändringar som kan införas sömlöst i ett befintligt index. I allmänhet innehåller listan nya fält och funktioner som används vid exekvering av frågor.
- Lägg till en indexbeskrivning (förhandsversion)
- Lägg till ett nytt fält
- Ange attributet för
retrievableett befintligt fält - Uppdatera
searchAnalyzeri ett fält med en befintligindexAnalyzer - Lägg till en ny analysdefinition i ett index (som kan tillämpas på nya fält)
- Lägga till, uppdatera eller ta bort bedömningsprofiler
- Lägga till, uppdatera eller ta bort synonymmappar
- Lägga till, uppdatera eller ta bort semantiska konfigurationer
- Lägga till, uppdatera eller ta bort CORS-inställningar
Åtgärdsordningen är:
Hämta indexdefinitionen.
Ändra schemat med uppdateringar från föregående lista.
Uppdatera indexschemat för söktjänsten.
Uppdatera indexinnehållet så att det matchar ditt ändrade schema om du har lagt till ett nytt fält. För alla andra ändringar används det befintliga indexerade innehållet som det är.
När du uppdaterar ett indexschema så att det innehåller ett nytt fält får befintliga dokument i indexet ett null-värde för det fältet. I nästa indexeringsjobb ersätter värden från externa källdata de null-värden som lagts till av Azure AI Search.
Det bör inte finnas några frågestörningar under uppdateringarna, men frågeresultaten varierar när uppdateringarna börjar gälla.
Uppdateringar som kräver återskapande
Vissa ändringar kräver att index släpps och återskapas, vilket ersätter ett aktuellt index med ett nytt.
| Åtgärd | beskrivning |
|---|---|
| Ta bort ett fält | Om du vill ta bort alla spår av ett fält fysiskt måste du återskapa indexet. När en omedelbar återskapande inte är praktisk kan du ändra programkod för att omdirigera åtkomst bort från ett föråldrat fält eller använda sökfälten och välja frågeparametrar för att välja vilka fält som söks och returneras. Fysiskt finns fältdefinitionen och innehållet kvar i indexet till nästa återskapande, när du tillämpar ett schema som utelämnar fältet i fråga. |
| Ändra en fältdefinition | Omarbetningar av ett fältnamn, datatyp eller specifika indexattribut (sökbara, filterbara, sorterbara, fasettbara) kräver en fullständig återskapande. |
| Tilldela en analysator till ett fält | Analysverktyg definieras i ett index, tilldelas till fält och anropas sedan under indexeringen för att informera om hur token skapas. Du kan lägga till en ny analysdefinition till ett index när som helst, men du kan bara tilldela en analysator när fältet skapas. Detta gäller både för egenskaperna analyzer och indexAnalyzer . Egenskapen searchAnalyzer är ett undantag (du kan tilldela den här egenskapen till ett befintligt fält). |
| Uppdatera eller ta bort en analysdefinition i ett index | Du kan inte ta bort eller ändra en befintlig analyskonfiguration (analysverktyg, tokeniserare, tokenfilter eller teckenfilter) i indexet om du inte återskapar hela indexet. |
| ** Lägg till ett fält i en förslagsfunktion | Om det redan finns ett fält och du vill lägga till det i en Suggesters-konstruktion återskapar du indexet. |
| Uppgradera din tjänst eller nivå | Om du behöver mer kapacitet kontrollerar du om du kan uppgradera tjänsten eller byta till en högre prisnivå. Annars måste du skapa en ny tjänst och återskapa dina index från grunden. För att automatisera den här processen kan du använda ett kodexempel som säkerhetskopierar ditt index till en serie JSON-filer. Du kan sedan återskapa indexet i en söktjänst som du anger. |
Åtgärdsordningen är:
Hämta en indexdefinition om du behöver den för framtida referens eller för att använda den som grund för en ny version.
Överväg att använda en säkerhetskopierings- och återställningslösning för att bevara en kopia av indexinnehållet. Det finns lösningar i C#och Python. Vi rekommenderar Python-versionen eftersom den är mer uppdaterad.
Om du har kapacitet för söktjänsten behåller du det befintliga indexet medan du skapar och testar det nya.
Släpp det befintliga indexet. Frågor som riktar sig till indexet tas bort omedelbart. Kom ihåg att det inte går att ångra borttagningen av ett index, vilket förstör fysisk lagring för fältsamlingen och andra konstruktioner.
Publicera ett reviderat index, där brödtexten i begäran innehåller ändrade eller ändrade fältdefinitioner och konfigurationer.
Läs in indexet med dokument från en extern källa. Dokument indexeras med hjälp av fältdefinitioner och konfigurationer för det nya schemat.
När du skapar indexet allokeras fysisk lagring för varje fält i indexschemat, med ett inverterat index som skapats för varje sökbart fält och ett vektorindex som skapats för varje vektorfält. Fält som inte kan sökas kan användas i filter eller uttryck, men som inte har inverterade index och inte är fulltext- eller fuzzy-sökbara. När indexet återskapas tas dessa inverterade index och vektorindex bort och återskapas baserat på det indexschema som du anger.
Om du vill minimera avbrott i programkoden bör du överväga att skapa ett indexalias. Programkoden refererar till aliaset, men du kan uppdatera namnet på det index som aliaset pekar på.
Lägg till en indexbeskrivning (förhandsversion)
Från och med REST API version 2025-05-01-preview stöds en ddescription nu. Den här text som kan läsas av människor är ovärderlig när ett system måste komma åt flera index och fatta ett beslut baserat på beskrivningen. Överväg en MCP-server (Model Context Protocol) som måste välja rätt index under körtid. Beslutet kan baseras på beskrivningen i stället för enbart indexnamnet.
En indexbeskrivning är en schemauppdatering och du kan lägga till den utan att behöva återskapa hela indexet.
- Stränglängden är högst 4 000 tecken.
- Innehållet måste vara läsbart för människor i Unicode. Ditt användningsfall bör avgöra vilket språk som ska användas.
Stöd för en indexbeskrivning finns i förhandsversionen av REST-API:et, Azure-portalen eller i ett Azure SDK-paket i förväg som tillhandahåller funktionen.
Azure-portalen stöder det senaste förhandsversions-API:et.
Logga in på Azure-portalen och leta reda på söktjänsten.
Under Sökhanteringsindex> väljer du ett index.
Välj Redigera JSON.
Infoga
"description", följt av beskrivningen. Värdet måste vara mindre än 4 000 tecken och i Unicode.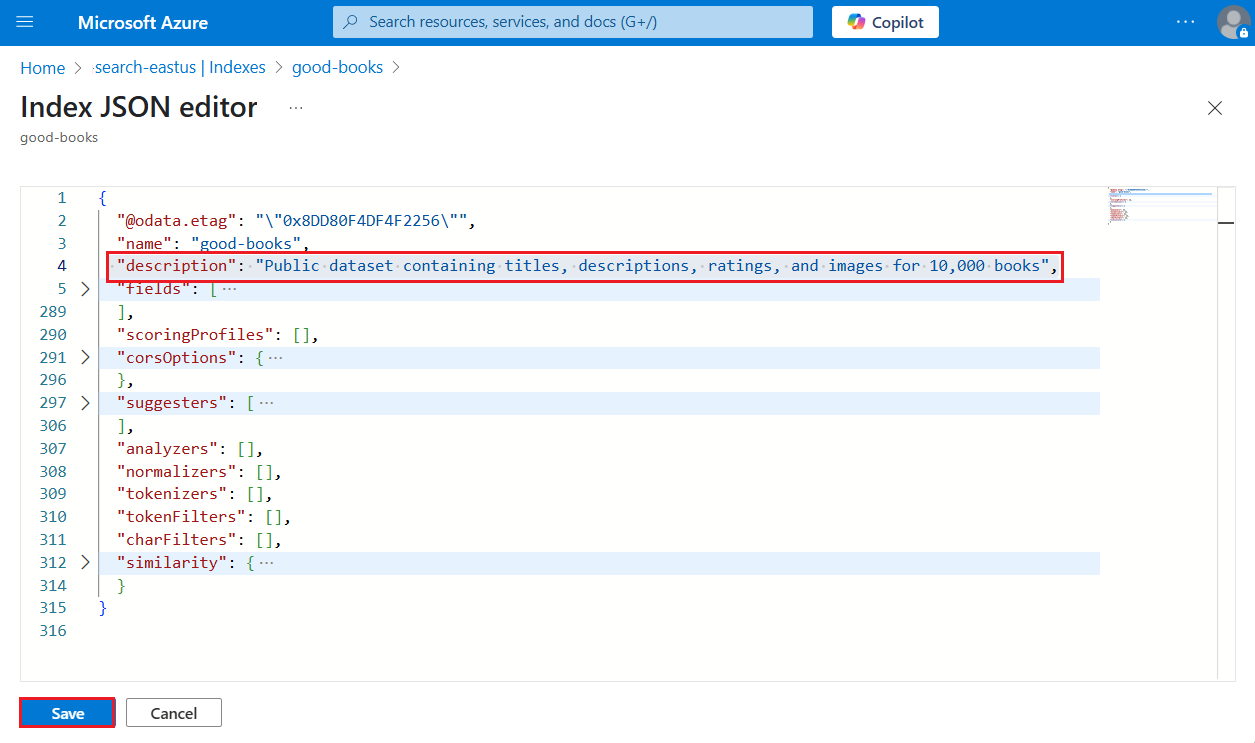
Spara indexet.
Balansera arbetsbelastningar
Indexering körs inte i bakgrunden, men söktjänsten balanserar alla indexeringsjobb mot pågående frågor. Under indexeringen kan du övervaka frågebegäranden i Azure-portalen för att säkerställa att frågorna slutförs i tid.
Om indexering av arbetsbelastningar introducerar oacceptabla nivåer av frågesvarstid utför du prestandaanalys och granskar dessa prestandatips för potentiell åtgärd.
Sök efter uppdateringar
Du kan börja köra frågor mot ett index så snart det första dokumentet har lästs in. Om du känner till ett dokuments ID returnerar REST-API:et för uppslagsdokument det specifika dokumentet. För bredare testning bör du vänta tills indexet är helt inläst och sedan använda frågor för att verifiera den kontext som du förväntar dig att se.
Du kan använda Sökutforskaren eller en REST-klient för att söka efter uppdaterat innehåll.
Om du har lagt till eller bytt namn på ett fält, välj select för att returnera det fältet:
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
Azure Portal ger indexstorlek och vektorindexstorlek. Du kan kontrollera dessa värden när du har uppdaterat ett index, men kom ihåg att förvänta dig en liten fördröjning när tjänsten bearbetar ändringen och tar hänsyn till uppdateringsfrekvensen för portalen, vilket kan ta några minuter.
Ta bort överblivna dokument
Azure AI Search stöder åtgärder på dokumentnivå så att du kan söka efter, uppdatera och ta bort ett specifikt dokument isolerat. I följande exempel visas hur du tar bort ett dokument.
Om du tar bort ett dokument frigörs inte omedelbart utrymme i indexet. Med några minuters mellanrum utför en bakgrundsprocess den fysiska borttagningen. Oavsett om du använder Azure Portal eller ett API för att returnera indexstatistik kan du förvänta dig en liten fördröjning innan borttagningen återspeglas i måtten Azure Portal och API.
Identifiera vilket fält som är dokumentnyckeln. I Azure Portal kan du visa fälten för varje index. Dokumentnycklar är strängfält och betecknas med en nyckelikon för att göra dem enklare att upptäcka.
Kontrollera värdena för dokumentnyckelfältet:
search=*&$select=HotelId. En enkel sträng är enkel, men om indexet använder ett base-64-kodat fält, eller om sökdokument har genererats från enparsingModeinställning, kanske du arbetar med värden som du inte är bekant med.Leta upp dokumentet för att verifiera värdet för dokument-ID:t och granska dess innehåll innan du tar bort det. Ange nyckel- eller dokument-ID:t i begäran. I följande exempel illustreras en enkel sträng för Hotels-provindexet och en base-64-kodad sträng för nyckeln metadata_storage_path för cog-search-demo-indexet.
GET https://[service name].search.windows.net/indexes/hotel-sample-index/docs/1111?api-version=2024-07-01GET https://[service name].search.windows.net/indexes/cog-search-demo/docs/aHR0cHM6Ly9oZWlkaWJsb2JzdG9yYWdlMi5ibG9iLmNvcmUud2luZG93cy5uZXQvY29nLXNlYXJjaC1kZW1vL2d1dGhyaWUuanBn0?api-version=2024-07-01Ta bort dokumentet genom att använda en borttagning
@search.actionför att radera det från sökindexet.POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/index?api-version=2024-07-01 Content-Type: application/json api-key: [admin key] { "value": [ { "@search.action": "delete", "id": "1111" } ] }