Metodtips för livscykelhantering i Infrastrukturresurser
Den här artikeln innehåller vägledning för data- och analysskapare som hanterar sitt innehåll under hela livscykeln i Microsoft Fabric. Artikeln fokuserar på användningen av Git-integrering för källkontroll och distributionspipelines som ett versionsverktyg. För allmän vägledning om publicering av enterprise-innehåll, Publicering av enterprise-innehåll.
Artikeln är uppdelad i fyra avsnitt:
Förberedelse av innehåll – Förbered ditt innehåll för livscykelhantering.
Utveckling – Lär dig mer om de bästa sätten att skapa innehåll i utvecklingssteget för distributionspipelines.
Test – Förstå hur du använder ett teststeg för distributionspipelines för att testa din miljö.
Produktion – Använd en produktionsfas för distributionspipelines för att göra ditt innehåll tillgängligt för förbrukning.
Om du vill förbereda ditt innehåll för löpande hantering under hela livscykeln kan du läsa informationen i det här avsnittet innan du:
Släpp innehåll till produktion.
Börja använda en distributionspipeline för en specifik arbetsyta.
Olika team i organisationen har vanligtvis olika kunskaper, ägarskap och arbetsmetoder, även när de arbetar med samma projekt. Det är viktigt att sätta gränser samtidigt som varje team får sin självständighet att arbeta som de vill. Överväg att ha separata arbetsytor för olika team. Med separata arbetsytor kan varje team ha olika behörigheter, arbeta med olika lagringsplatser för källkontroll och skicka innehåll till produktion i olika takt. De flesta objekt kan ansluta och använda data mellan arbetsytor, så det blockerar inte samarbete på samma data och projekt.
Både Git-integrerings- och distributionspipelines kräver andra behörigheter än bara arbetsytebehörigheterna. Läs mer om behörighetskraven för Git-integrering och distributionspipelines.
Om du vill implementera ett säkert och enkelt arbetsflöde planerar du vem som får åtkomst till varje del av de miljöer som används, både Git-lagringsplatsen och utvecklings-/test-/prod-stegen i en pipeline. Några av de överväganden som bör beaktas är:
Vem ska ha åtkomst till källkoden på Git-lagringsplatsen?
Vilka åtgärder ska användare med pipelineåtkomst kunna utföra i varje steg?
Vem granskar innehåll i testfasen?
Ska teststegsgranskarna ha åtkomst till pipelinen?
Vem ska övervaka distributionen till produktionsfasen?
Vilken arbetsyta tilldelar du till en pipeline eller ansluter till git?
Vilken gren ansluter du arbetsytan till? Vilken princip har definierats för den grenen?
Delas arbetsytan av flera teammedlemmar? Ska de göra ändringar direkt på arbetsytan eller bara via Pull-begäranden?
Vilket steg tilldelar du arbetsytan till?
Behöver du göra ändringar i behörigheterna för den arbetsyta som du tilldelar?
En produktionsdatabas ska alltid vara stabil och tillgänglig. Det är bäst att inte överbelasta den med frågor som genereras av BI-skapare för deras utveckling eller testa semantiska modeller. Skapa separata databaser för utveckling och testning för att skydda produktionsdata och inte överbelasta utvecklingsdatabasen med hela produktionsdatavolymen.
När det är möjligt lägger du till parametrar i alla definitioner som kan ändras mellan utvecklings-/test-/prod-faser. Med hjälp av parametrar kan du enkelt ändra definitionerna när du flyttar ändringarna till produktion. Det finns fortfarande inget enhetligt sätt att hantera parametrar i Fabric, men vi rekommenderar att du använder det på objekt som stöder alla typer av parameteriseringar.
Parametrar har olika användningsområden, till exempel att definiera anslutningar till datakällor eller till interna objekt i Infrastrukturresurser. De kan också användas för att göra ändringar i frågor, filter och texten som visas för användarna.
I distributionspipelines kan du konfigurera parameterregler för att ange olika värden för varje distributionssteg.
Det här avsnittet innehåller vägledning för att arbeta med distributionspipelines och använda dem i utvecklingsfasen.
Med Git-integrering kan alla utvecklare säkerhetskopiera sitt arbete genom att engagera det i Git. Här följer några grundläggande regler för att säkerhetskopiera ditt arbete korrekt i Fabric:
Se till att du har en isolerad miljö att arbeta i, så att andra inte åsidosätter ditt arbete innan det checkas in. Det innebär att arbeta i ett skrivbordsverktyg (till exempel VS Code, Power BI Desktop eller andra) eller på en separat arbetsyta som andra användare inte kan komma åt.
Checka in till en gren som du har skapat och ingen annan utvecklare använder. Om du använder en arbetsyta som redigeringsmiljö kan du läsa om att arbeta med grenar.
Genomför ändringar som måste distribueras tillsammans. Det här rådet gäller för ett enskilt objekt eller flera objekt som är relaterade till samma ändring. Att genomföra alla relaterade ändringar tillsammans kan hjälpa dig senare när du distribuerar till andra steg, skapar pull-begäranden eller återställer ändringar tillbaka.
Stora incheckningar kan nå en maxgräns för incheckningsstorlek. Tänk på antalet objekt som du checkar in tillsammans eller den allmänna storleken på ett objekt. Rapporter kan till exempel bli stora när du lägger till stora bilder. Det är dålig praxis att lagra stora objekt i källkontrollsystem, även om det fungerar. Överväg olika sätt att minska storleken på dina objekt om de har många statiska resurser, till exempel bilder.
När du har säkerhetskopierar ditt arbete kan det finnas fall där du vill återgå till en tidigare version och återställa den på arbetsytan. Det finns några sätt att återgå till en tidigare version:
Knappen Ångra: Ångra-åtgärden är ett enkelt och snabbt sätt att återställa de omedelbara ändringar som du har gjort, så länge de inte har checkats in ännu. Du kan också ångra varje objekt separat. Läs mer om ångra-åtgärden .
Återgå till äldre incheckningar: Det finns inget direkt sätt att gå tillbaka till en tidigare incheckning i användargränssnittet. Det bästa alternativet är att höja upp en äldre incheckning för att vara HEAD med hjälp av git-återställning eller git-återställning. Detta visar att det finns en uppdatering i källkontrollfönstret, och du kan uppdatera arbetsytan med den nya incheckningen.
Eftersom data inte lagras i Git bör du tänka på att återställning av ett dataobjekt till en äldre version kan bryta befintliga data och eventuellt kräva att du släpper data eller att åtgärden misslyckas. Kontrollera detta i förväg innan du återställer ändringarna.
När du vill arbeta isolerat använder du en separat arbetsyta som en isolerad miljö. Läs mer om att isolera din arbetsmiljö när du arbetar med grenar. Tänk på följande för ett optimalt arbetsflöde för dig och teamet:
Konfigurera arbetsytan: Kontrollera att du kan skapa en ny arbetsyta (om du inte redan har en) innan du börjar, att du kan tilldela den till en Infrastrukturkapacitet och att du har åtkomst till data som ska fungera på din arbetsyta.
Skapa en ny gren: Skapa en ny gren från huvudgrenen, så att du har den senaste versionen av ditt innehåll. Se också till att du ansluter till rätt mapp i grenen, så att du kan hämta rätt innehåll till arbetsytan.
Små, frekventa ändringar: Det är en bra git-metod att göra små inkrementella ändringar som är enkla att sammanfoga och som är mindre benägna att hamna i konflikter. Om det inte är möjligt bör du uppdatera din gren från main så att du kan lösa konflikter på egen hand först.
Konfigurationsändringar: Om det behövs ändrar du konfigurationerna på arbetsytan så att du kan arbeta mer produktivt. Vissa ändringar kan omfatta anslutning mellan objekt, till olika datakällor eller ändringar av parametrar för ett visst objekt. Kom bara ihåg att allt du checkar in blir en del av incheckningen och av misstag kan sammanfogas till huvudgrenen.
För objekt och verktyg som stöder det kan det vara enklare att arbeta med klientverktyg för redigering, till exempel Power BI Desktop för semantiska modeller och rapporter, VS Code for Notebooks osv. Dessa verktyg kan vara din lokala utvecklingsmiljö. När du har slutfört ditt arbete skickar du ändringarna till fjärrplatsen och synkroniserar arbetsytan för att ladda upp ändringarna. Se bara till att du arbetar med strukturen som stöds för det objekt som du redigerar. Om du inte är säker klonar du först en lagringsplats med innehåll som redan har synkroniserats till en arbetsyta och börjar sedan redigera därifrån, där strukturen redan finns.
Eftersom en arbetsyta bara kan anslutas till en enda gren i taget rekommenderar vi att du behandlar detta som en 1:1-mappning. Tänk dock på följande alternativ för att minska mängden arbetsyta som det innebär:
Om en utvecklare konfigurerar en privat arbetsyta med alla nödvändiga konfigurationer kan de fortsätta att använda den arbetsytan för alla framtida grenar som de skapar. När en sprint är över sammanfogas dina ändringar och du startar en ny ny uppgift. Växla bara anslutningen till en ny gren på samma arbetsyta. Du kan också göra detta om du plötsligt behöver åtgärda en bugg mitt i en sprint. Se det som en arbetskatalog på webben.
Utvecklare som använder ett klientverktyg (till exempel VS Code, Power BI Desktop eller andra) behöver inte nödvändigtvis en arbetsyta. De kan skapa grenar och checka in ändringar i den grenen lokalt, push-överföra dem till fjärrplatsen och skapa en pull-begäran till huvudgrenen, allt utan en arbetsyta. En arbetsyta behövs bara som en testmiljö för att kontrollera att allt fungerar i ett verkligt scenario. Det är upp till dig att bestämma när det ska hända.
Så här duplicerar du ett objekt på en Git-lagringsplats:
- Kopiera hela objektkatalogen.
- Ändra logicalId till något unikt för den anslutna arbetsytan.
- Ändra visningsnamnet för att skilja det från det ursprungliga objektet och för att undvika duplicerat visningsnamnfel.
- Om det behövs uppdaterar du logicalId- och/eller visningsnamnen i beroenden.
Det här avsnittet innehåller vägledning för att arbeta med ett teststeg för distributionspipelines.
Det är viktigt att se hur den föreslagna ändringen kommer att påverka produktionsfasen. Med ett teststeg för distributionspipelines kan du simulera en verklig produktionsmiljö i testsyfte. Du kan också simulera detta genom att ansluta Git till en annan arbetsyta.
Se till att dessa tre faktorer åtgärdas i testmiljön:
Datavolym
Användningsvolym
En liknande kapacitet som i produktion
När du testar kan du använda samma kapacitet som produktionssteget. Att använda samma kapacitet kan dock göra produktionen instabil under belastningstestning. För att undvika instabil produktion testar du med en annan kapacitet som liknar resurserna i produktionskapaciteten. Undvik extra kostnader genom att använda en kapacitet där du bara kan betala för testtiden.
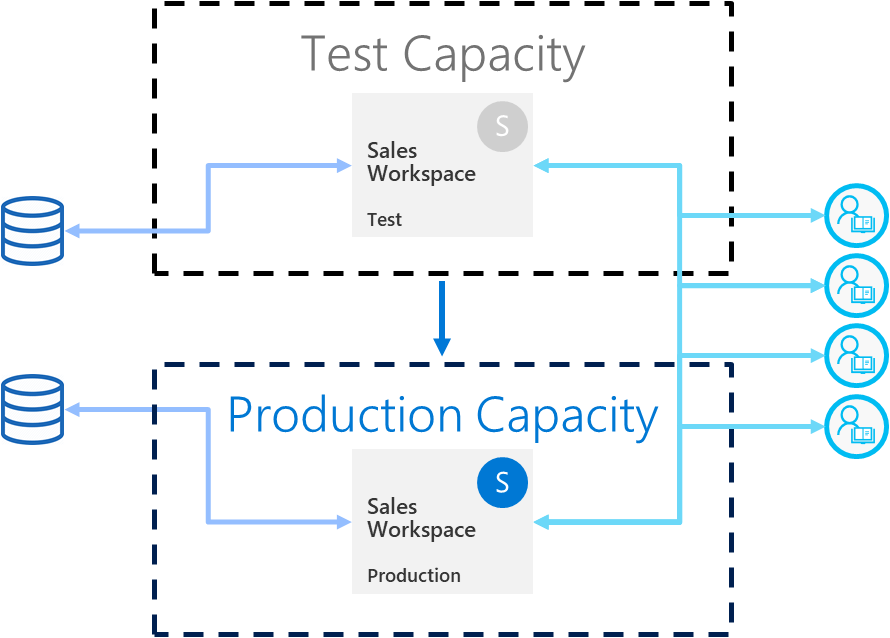
Om du använder teststeget för att simulera verklig dataanvändning är det bäst att separera utvecklings- och testdatakällorna. Utvecklingsdatabasen bör vara relativt liten och testdatabasen bör vara så lik produktionsdatabasen som möjligt. Använd datakällans regler för att växla datakällor i testfasen eller parametrisera anslutningen om den inte fungerar via distributionspipelines.
Ändringar som du gör kan också påverka de beroende objekten. Under testningen kontrollerar du att ändringarna inte påverkar eller bryter prestandan för befintliga objekt, som kan vara beroende av de uppdaterade objekten.
Du kan enkelt hitta relaterade objekt med hjälp av påverkansanalys.
Dataobjekt är objekt som lagrar data. Objektets definition i Git definierar hur data lagras. När vi uppdaterar ett objekt på arbetsytan importerar vi dess definition till arbetsytan och tillämpar den på befintliga data. Åtgärden att uppdatera dataobjekt är densamma för Git- och distributionspipelines.
Eftersom olika objekt har olika funktioner när det gäller att behålla data när ändringar i definitionen tillämpas bör du vara uppmärksam när du tillämpar ändringarna. Några metoder som kan hjälpa dig att tillämpa ändringarna på det säkraste sättet:
I förväg vet du vad ändringarna är och vilken inverkan de kan ha på befintliga data. Använd incheckningsmeddelanden för att beskriva de ändringar som gjorts.
Om du vill se hur objektet hanterar ändringen med testdata laddar du först upp ändringarna till en utvecklings- eller testmiljö.
Om allt går bra rekommenderar vi att du även kontrollerar det i en mellanlagringsmiljö med verkliga data (eller så nära det som möjligt) för att minimera oväntade beteenden i produktionen.
Överväg den bästa tidpunkten när du uppdaterar Prod-miljön för att minimera de skador som eventuella fel kan orsaka för företagsanvändare som använder data.
Efter distributionen testas efter distributionen i Prod för att verifiera att allt fungerar som förväntat.
Vissa ändringar betraktas alltid som icke-bakåtkompatibla ändringar. Förhoppningsvis hjälper de föregående stegen dig att spåra dem före produktion. Skapa en plan för hur du tillämpar ändringarna i Prod och återställer data för att återgå till normalt tillstånd och minimera stilleståndstiden för företagsanvändare.
Om du distribuerar innehåll till dina kunder via en app granskar du appens nya version innan den är i produktion. Eftersom varje distributionspipelinesteg har en egen arbetsyta kan du enkelt publicera och uppdatera appar för utvecklings- och testfaser. När du publicerar och uppdaterar appar kan du testa appen från slutanvändarens synvinkel.
Viktigt
Distributionsprocessen omfattar inte uppdatering av appens innehåll eller inställningar. Om du vill tillämpa ändringar på innehåll eller inställningar uppdaterar du appen manuellt i den pipelinefas som krävs.
Det här avsnittet innehåller vägledning om produktionssteget för distributionspipelines.
Eftersom distribution till produktion bör hanteras noggrant är det bra att bara låta specifika personer hantera den här känsliga åtgärden. Men du vill förmodligen att alla BI-skapare för en specifik arbetsyta ska ha åtkomst till pipelinen. Använd behörigheter för produktionsarbetsytan för att hantera åtkomstbehörigheter. Andra användare kan ha en visningsroll för produktionsarbetsytan för att se innehåll på arbetsytan men inte göra ändringar från Git eller distributionspipelines.
Dessutom begränsar du åtkomsten till lagringsplatsen eller pipelinen genom att endast aktivera behörigheter för användare som ingår i processen för att skapa innehåll.
Distributionsregler är ett kraftfullt sätt att säkerställa att data i produktionen alltid är anslutna och tillgängliga för användare. När distributionsregler tillämpas kan distributioner köras medan du har försäkrat dig om att kunderna kan se relevant information utan störningar.
Se till att du anger regler för produktionsdistribution för datakällor och parametrar som definierats i semantikmodellen.
Distribution i en pipeline via användargränssnittet uppdaterar innehållet på arbetsytan. Om du vill uppdatera den associerade appen använder du API:et för distributionspipelines. Det går inte att uppdatera appen via användargränssnittet. Om du använder en app för innehållsdistribution ska du inte glömma att uppdatera appen efter distributionen till produktion så att slutanvändarna omedelbart kan använda den senaste versionen.
Eftersom lagringsplatsen fungerar som "enkel sanningskälla" kanske vissa team vill distribuera uppdateringar i olika faser direkt från Git. Detta är möjligt med Git-integrering, med några saker att tänka på:
Vi rekommenderar att du använder versionsgrenar. Du måste kontinuerligt ändra anslutningen av arbetsytan till de nya versionsgrenarna före varje distribution.
Om din bygg- eller versionspipeline kräver att du ändrar källkoden eller kör skript i en byggmiljö innan du distribuerar till arbetsytan hjälper det inte att ansluta arbetsytan till Git.
När du har distribuerat till varje steg måste du ändra all konfiguration som är specifik för den fasen.
Ibland finns det problem i produktionen som kräver en snabbkorrigering. Det är inte bra att distribuera en korrigering utan att testa den först. Implementera därför alltid korrigeringen i utvecklingsfasen och push-överför den till resten av distributionspipelinestegen. När du distribuerar till utvecklingssteget kan du kontrollera att korrigeringen fungerar innan du distribuerar den till produktion. Det tar bara några minuter att distribuera över pipelinen.
Om du använder distribution från Git rekommenderar vi att du följer de metoder som beskrivs i Anta en Git-förgreningsstrategi.