Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln riktar sig till IT-proffs och IT-chefer. Du får lära dig mer om BI-lösningsarkitekturen i COE och de olika tekniker som används. Teknikerna omfattar Azure, Power BI och Excel. Tillsammans kan de användas för att leverera en skalbar och datadriven BI-plattform i molnet.
Att utforma en robust BI-plattform är ungefär som att bygga en bro. en brygga som ansluter transformerade och berikade källdata till datakonsumenter. Utformningen av en sådan komplex struktur kräver ett tekniskt tänkesätt, även om det kan vara en av de mest kreativa och givande IT-arkitekturer du kan utforma. I en stor organisation kan en BI-lösningsarkitektur bestå av:
- Datakällor
- Datainsamling
- Stordata / dataförberedelse
- Datavaruhus
- BI-semantiska modeller
- Rapporter
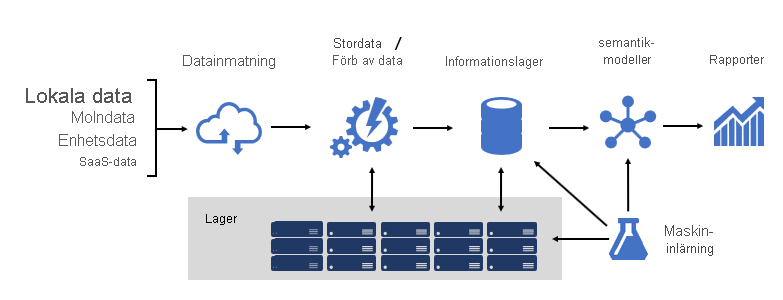
Plattformen måste stödja specifika krav. Mer specifikt måste den skala och prestera för att uppfylla förväntningarna hos affärstjänster och datakonsumenter. Samtidigt måste den vara säker från grunden. Och det måste vara tillräckligt motståndskraftigt för att anpassa sig till förändringar , eftersom det är säkert att nya data och ämnesområden måste tas online.
Ramverk
På Microsoft antog vi redan från början en systemliknande metod genom att investera i ramverksutveckling. Tekniska och affärsprocessramverk ökar återanvändningen av design och logik och ger ett konsekvent resultat. De erbjuder också flexibilitet i arkitektur som utnyttjar många tekniker, och de effektiviserar och minskar tekniska kostnader via repeterbara processer.
Vi har lärt oss att väl utformade ramverk ökar insynen i datahärledning, konsekvensanalys, underhåll av affärslogik, hantering av taxonomi samt effektiviserar styrning. Dessutom blev utvecklingen snabbare och samarbetet mellan stora team blev mer dynamiskt och effektivt.
Vi beskriver flera av våra ramverk i den här artikeln.
Datamodeller
Datamodeller ger dig kontroll över hur data struktureras och används. För affärstjänster och datakonsumenter är datamodeller deras gränssnitt med BI-plattformen.
En BI-plattform kan leverera tre olika typer av modeller:
- Företagsmodeller
- BI-semantiska modeller
- Maskininlärningsmodeller (ML)
Företagsmodeller
Företagsmodeller skapas och underhålls av IT-arkitekter. De kallas ibland för dimensionsmodeller eller data marts. Vanligtvis lagras data i relationsformat som dimensions- och faktatabeller. Dessa tabeller lagrar rensade och berikade data som konsoliderats från många system och de representerar en auktoritativ källa för rapportering och analys.
Företagsmodeller levererar en konsekvent och enskild datakälla för rapportering och BI. De skapas en gång och delas som en företagsstandard. Styrningsprinciper säkerställer att data är säkra, så åtkomsten till känsliga datamängder, till exempel kundinformation eller ekonomi, begränsas på behovsbasis. De antar namngivningskonventioner som säkerställer konsekvens, vilket ytterligare skapar trovärdighet för data och kvalitet.
På en BI-molnplattform kan företagsmodeller distribueras till en Synapse SQL-pool i Azure Synapse. Synapse SQL-poolen blir sedan den enda versionen av sanningen som organisationen kan räkna med för snabba och robusta insikter.
BI-semantiska modeller
BI-semantiska modeller representerar ett semantiskt lager över företagsmodeller. De skapas och underhålls av BI-utvecklare och företagsanvändare. BI-utvecklare skapar grundläggande BI-semantiska modeller som hämtar data från företagsmodeller. Företagsanvändare kan skapa mindre skalbara, oberoende modeller– eller utöka grundläggande BI-semantiska modeller med avdelnings- eller externa källor. BI-semantiska modeller fokuserar ofta på ett enskilt ämnesområde och delas ofta i stor utsträckning.
Affärsfunktioner aktiveras inte enbart av data, utan av BI-semantiska modeller som beskriver begrepp, relationer, regler och standarder. På så sätt representerar de intuitiva och lättbegripliga strukturer som definierar datarelationer och kapslar in affärsregler som beräkningar. De kan också framtvinga detaljerade databehörigheter, vilket säkerställer att rätt personer har åtkomst till rätt data. Det är viktigt att de påskyndar frågeprestandan och ger mycket dynamisk interaktiv analys – även över terabyte med data. Precis som företagsmodeller antar BI-semantiska modeller namngivningskonventioner som säkerställer konsekvens.
I en BI-molnplattform kan BI-utvecklare distribuera BI-semantiska modeller till Azure Analysis Services, Power BI Premium-kapaciteter för Microsoft Fabric-kapaciteter.
Viktigt!
Den här artikeln refererar till Power BI Premium eller dess kapacitetsprenumerationer (P SKU:er). För närvarande konsoliderar Microsoft köpalternativ och drar tillbaka SKU:erna för Power BI Premium per kapacitet. Nya och befintliga kunder bör överväga att köpa kapacitetsprenumerationer för Fabric (F SKUs) i stället.
Mer information finns i Viktig uppdatering som kommer till Power BI Premium-licensiering och Vanliga frågor och svar om Power BI Premium.
Vi rekommenderar att du distribuerar till Power BI när det används som ditt rapporterings- och analyslager. Dessa produkter stöder olika lagringslägen, vilket gör att datamodelltabeller kan cachelagrar sina data eller använda DirectQuery, vilket är en teknik som skickar frågor till den underliggande datakällan. DirectQuery är ett idealiskt lagringsläge när modelltabeller representerar stora datavolymer eller om det finns ett behov av att leverera resultat nästan i realtid. De två lagringslägena kan kombineras: Sammansatta modeller kombinerar tabeller som använder olika lagringslägen i en enda modell.
För kraftigt efterfrågade modeller kan Azure Load Balancer användas för att fördela frågebelastningen jämnt mellan modellrepliker. Du kan också skala dina program och skapa bi-semantiska modeller med hög tillgänglighet.
Maskininlärningsmodeller
Maskininlärningsmodeller (ML) skapas och underhålls av dataforskare. De flesta är utvecklade från rådatakällor i datasjön.
Tränade ML-modeller kan visa mönster i dina data. I många fall kan dessa mönster användas för att göra förutsägelser som kan användas för att berika data. Köpbeteende kan till exempel användas för att förutsäga kundbortfall eller segmentera kunder. Förutsägelseresultat kan läggas till i företagsmodeller för att tillåta analys efter kundsegment.
På en BI-molnplattform kan du använda Azure Machine Learning för att träna, distribuera, automatisera, hantera och spåra ML-modeller.
Datavaruhus
I hjärtat av en BI-plattform finns informationslagret som är värd för dina företagsmodeller. Det är en källa till sanktionerade data – som ett system för arkivhandling och som en hubb – som betjänar företagsmodeller för rapportering, BI och datavetenskap.
Många affärstjänster, inklusive verksamhetsspecifika program (LOB), kan förlita sig på informationslagret som en auktoritativ och styrd källa till företagskunskap.
På Microsoft finns vårt informationslager på Azure Data Lake Storage Gen2 (ADLS Gen2) och Azure Synapse Analytics.
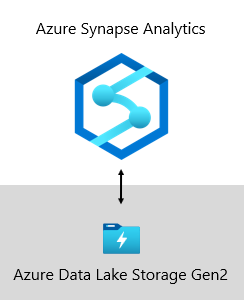
- ADLS Gen2 gör Azure Storage till grunden för att skapa företagsdatasjöar i Azure. Den är utformad för att betjäna flera petabyte med information samtidigt som hundratals gigabit dataflöde bibehålls. Och den erbjuder lagringskapacitet och transaktioner till låg kostnad. Dessutom har den stöd för Hadoop-kompatibel åtkomst, vilket gör att du kan hantera och komma åt data precis som med ett Hadoop Distributed File System (HDFS). Faktum är att Azure HDInsight, Azure Databricks och Azure Synapse Analytics kan komma åt alla data som lagras i ADLS Gen2. På en BI-plattform är det därför ett bra val att lagra rådata, halvbearbetade eller mellanlagrade data och produktionsklara data. Vi använder den för att lagra alla våra affärsdata.
- Azure Synapse Analytics är en analystjänst som samlar företagsdatalager och stordataanalys. Det ger dig friheten att fråga efter data på dina villkor, antingen med serverlösa resurser på begäran eller etablerade resurser – i stor skala. Synapse SQL, en komponent i Azure Synapse Analytics, stöder fullständig T-SQL-baserad analys, så det är idealiskt att vara värd för företagsmodeller som består av dina dimensions- och faktatabeller. Tabeller kan läsas in effektivt från ADLS Gen2 med hjälp av enkla Polybase T-SQL-frågor . Du har då kraften hos MPP för att köra högpresterande analys.
Business Rules Engine-ramverk
Vi har utvecklat ett BRE-ramverk (Business Rules Engine ) för att katalogisera all affärslogik som kan implementeras i informationslagrets lager. En BRE kan betyda många saker, men i samband med ett informationslager är det användbart för att skapa beräknade kolumner i relationstabeller. Dessa beräknade kolumner representeras vanligtvis som matematiska beräkningar eller uttryck med hjälp av villkorssatser.
Avsikten är att skilja affärslogiken från core BI-koden. Traditionellt är affärsregler hårdkodade i SQL-lagrade procedurer, så det resulterar ofta i mycket arbete med att underhålla dem när affärsbehoven ändras. I en BRE definieras affärsregler en gång och används flera gånger när de tillämpas på olika informationslagerentiteter. Om beräkningslogik behöver ändras behöver den bara uppdateras på ett ställe och inte i flera lagrade procedurer. Det finns också en sidoförmån: ett BRE-ramverk ger transparens och insyn i implementerad affärslogik, som kan exponeras via en uppsättning rapporter som skapar självuppdateringsdokumentation.
Datakällor
Ett informationslager kan konsolidera data från praktiskt taget vilken datakälla som helst. Det är främst byggt över LOB-datakällor, som ofta är relationsdatabaser som lagrar ämnesspecifika data för försäljning, marknadsföring, ekonomi osv. Dessa databaser kan vara molnbaserade eller finnas lokalt. Andra datakällor kan vara filbaserade, särskilt webbloggar eller IOT-data som kommer från enheter. Dessutom kan data hämtas från SaaS-leverantörer (Software-as-a-Service).
På Microsoft matar vissa av våra interna system ut driftdata direkt till ADLS Gen2 med hjälp av rådatafilformat. Förutom vår datasjö består andra källsystem av relationsbaserade LOB-program, Excel-arbetsböcker, andra filbaserade källor och MDM (Master Data Management) och anpassade datalagringsplatser. MED MDM-lagringsplatser kan vi hantera våra huvuddata för att säkerställa auktoritativa, standardiserade och verifierade versioner av data.
Datainsamling
Med jämna mellanrum, och enligt verksamhetens rytmer, matas data in från källsystem och läses in i informationslagret. Det kan vara en gång om dagen eller med mer frekventa intervall. Datainmatning handlar om att extrahera, transformera och läsa in data. Eller kanske tvärtom: extrahera, läsa in och sedan transformera data. Skillnaden beror på var omvandlingen sker. Transformeringar tillämpas för att rensa, anpassa, integrera och standardisera data. Mer information finns i Extrahera, transformera och läsa in (ETL).
I slutändan är målet att läsa in rätt data i din företagsmodell så snabbt och effektivt som möjligt.
På Microsoft använder vi Azure Data Factory (ADF). Tjänsterna används för att schemalägga och samordna datavalidering, transformeringar och massinläsningar från externa källsystem till vår datasjö. Den hanteras av anpassade ramverk för att bearbeta data parallellt och i stor skala. Dessutom utförs omfattande loggning för att stödja felsökning, prestandaövervakning och utlösa aviseringsmeddelanden när specifika villkor uppfylls.
Under tiden utför Azure Databricks – en Apache Spark-baserad analysplattform som är optimerad för Azure-molntjänstplattformen – transformeringar specifikt för datavetenskap. Den skapar och kör även ML-modeller med hjälp av Python-notebook-filer. Poäng från dessa ML-modeller läses in i informationslagret för att integrera förutsägelser med företagsprogram och rapporter. Eftersom Azure Databricks kommer åt data lake-filerna direkt eliminerar eller minimerar det behovet av att kopiera eller hämta data.
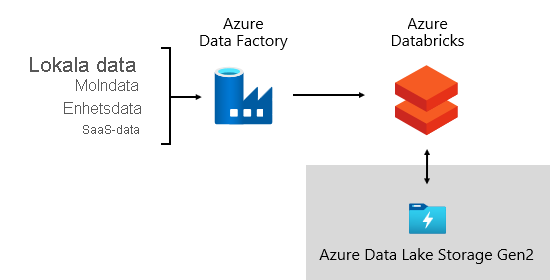
Inmatningsramverk
Vi utvecklade ett inmatningsramverk som en uppsättning konfigurationstabeller och procedurer. Den stöder en datadriven metod för att hämta stora mängder data med hög hastighet och med minimal kod. I korthet förenklar det här ramverket processen för datainsamling för att läsa in informationslagret.
Ramverket är beroende av konfigurationstabeller som lagrar information om datakällor och datamål, till exempel källtyp, server, databas, schema och tabellrelaterad information. Den här designmetoden innebär att vi inte behöver utveckla specifika ADF-pipelines eller SSIS-paket (SQL Server Integration Services). I stället skrivs procedurer på vårt valda språk för att skapa ADF-pipelines som dynamiskt genereras och körs under körning. Därför blir datainsamling en konfigurationsövning som enkelt kan operationaliseras. Traditionellt skulle det kräva omfattande utvecklingsresurser för att skapa hårdkodade ADF- eller SSIS-paket.
Inmatningsramverket har utformats för att förenkla processen för hantering av överordnade källschemaändringar. Det är enkelt att uppdatera konfigurationsdata – manuellt eller automatiskt när schemaändringar identifieras för att hämta nyligen tillagda attribut i källsystemet.
Orkestreringsramverk
Vi har utvecklat ett orkestreringsramverk för att operationalisera och samordna våra datapipelines. Orkestreringsramverket använder en datadriven design som är beroende av en uppsättning konfigurationstabeller. Dessa tabeller lagrar metadata som beskriver pipelineberoenden och hur du mappar källdata till måldatastrukturer. Investeringen i att utveckla detta anpassningsbara ramverk har sedan dess betalat sig själv. det finns inte längre något krav på att hårdkoda varje dataflytt.
Datalagring
En datasjö kan lagra stora mängder rådata för senare användning tillsammans med förberedelse av datatransformeringar.
På Microsoft använder vi ADLS Gen2 som vår enda sanningskälla. Den lagrar rådata tillsammans med mellanlagrade data och produktionsklara data. Det ger en mycket skalbar och kostnadseffektiv datasjölösning för stordataanalys. Genom att kombinera kraften i ett högpresterande filsystem med massiv skala är det optimerat för dataanalysarbetsbelastningar, vilket påskyndar tiden till insikt.
ADLS Gen2 ger det bästa av två världar: det är BLOB Storage och ett filsystemsnamnområde med höga prestanda, som vi konfigurerar med detaljerade åtkomstbehörigheter.
Förfinade data lagras sedan i en relationsdatabas för att leverera ett högpresterande, mycket skalbart datalager för företagsmodeller, med säkerhet, styrning och hanterbarhet. Ämnesspecifika data marts lagras i Azure Synapse Analytics, som läses in av Azure Databricks- eller Polybase T-SQL-frågor.
Dataförbrukning
På rapporteringslagret använder företagstjänster företagsdata som kommer från informationslagret. De kommer också åt data direkt i datasjön för ad hoc-analys eller datavetenskapsuppgifter.
Detaljerade behörigheter tillämpas på alla lager: i datasjön, företagsmodeller och BI-semantiska modeller. Behörigheterna säkerställer att datakonsumenter bara kan se de data de har behörighet att komma åt.
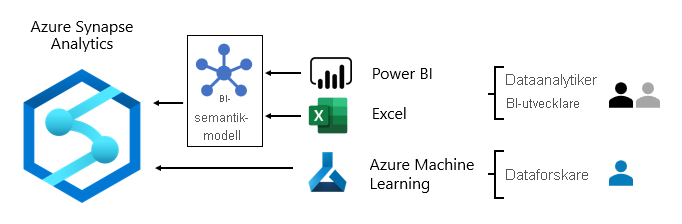
På Microsoft använder vi Power BI-rapporter och instrumentpaneler samt sidnumrerade Power BI-rapporter. Viss rapportering och ad hoc-analys görs i Excel , särskilt för finansiell rapportering.
Vi publicerar dataordlistor som innehåller referensinformation om våra datamodeller. De görs tillgängliga för våra användare så att de kan identifiera information om vår BI-plattform. Ordlistor dokumenterar modelldesign och ger beskrivningar om entiteter, format, struktur, dataursprung, relationer och beräkningar. Vi använder Azure Data Catalog för att göra våra datakällor lätta att identifiera och förstå.
Vanligtvis skiljer sig dataförbrukningsmönstren åt beroende på roll:
- Dataanalytiker ansluter direkt till centrala BI-semantiska modeller. När core BI-semantiska modeller innehåller alla data och all logik de behöver använder de live-anslutningar för att skapa Power BI-rapporter och instrumentpaneler. När de behöver utöka modellerna med avdelningsdata skapar de sammansatta Power BI-modeller. Om det finns behov av rapporter i kalkylbladsformat använder de Excel för att skapa rapporter baserade på grundläggande BI-semantiska modeller eller avdelnings-BI-semantiska modeller.
- BI-utvecklare och rapportförfattare ansluter direkt till företagsmodeller. De använder Power BI Desktop för att skapa analysrapporter för liveanslutning. De kan också skapa BI-rapporter av drifttyp som sidnumrerade Power BI-rapporter och skriva interna SQL-frågor för att komma åt data från Azure Synapse Analytics-företagsmodeller med hjälp av T-SQL eller Power BI-semantiska modeller med hjälp av DAX eller MDX.
- Dataforskare ansluter direkt till data i datasjön. De använder Azure Databricks- och Python-notebook-filer för att utveckla ML-modeller, som ofta är experimentella och kräver specialkunskaper för produktionsanvändning.
Relaterat innehåll
Mer information om den här artikeln finns i följande resurser:
- Översikt över infrastrukturimplementering: Center of Excellence
- Enterprise BI i Azure med Azure Synapse Analytics
- Frågor? Prova att fråga Fabric-gemenskapen
- Förslag? Bidra med idéer för att förbättra Fabric
Professionella tjänster
Certifierade Power BI-partner är tillgängliga för att hjälpa din organisation att lyckas när du konfigurerar en COE. De kan ge dig kostnadseffektiv utbildning eller en granskning av dina data. Om du vill hitta en Power BI-partner går du till Microsoft Power BI-partnerportalen.
Du kan också samarbeta med erfarna konsultpartners. De kan hjälpa dig att utvärdera, utvärdera eller implementera Power BI.