Události
Připojte se k nám ve společnosti FabCon Vegas
31. 3. 23 - 2. 4. 23
Ultimate Microsoft Fabric, Power BI, SQL a AI community-led event. 31. března až 2. dubna 2025.
Zaregistrovat se ještě dnesTento prohlížeč se už nepodporuje.
Upgradujte na Microsoft Edge, abyste mohli využívat nejnovější funkce, aktualizace zabezpečení a technickou podporu.
Tento článek se zaměřuje na modelátora dat, který pracuje s Power BI Desktopem. Popisuje osvědčené postupy návrhu pro vynucování zabezpečení na úrovni řádků (RLS) v datových modelech.
Je důležité pochopit, že zabezpečení na úrovni řádků v tabulce filtruje. Není možné je nakonfigurovat tak, aby omezovaly přístup k objektům modelu, včetně tabulek, sloupců nebo měr.
Poznámka
Tento článek nepopisuje zabezpečení na úrovni řádků ani jeho nastavení. Další informace najdete v tématu Omezení přístupu k datům pomocí zabezpečení na úrovni řádků (RLS) pro Power BI Desktop.
Nevztahuje se také na vynucování zabezpečení na úrovni řádků v živých připojeních k externím hostovaným modelům se službou Azure Analysis Services nebo Služba Analysis Services serveru SQL. V těchto případech služba Analysis Services vynucuje zabezpečení na úrovni řádků. Když se Power BI připojí pomocí jednotného přihlašování (SSO), služba Analysis Services vynutí zabezpečení na úrovni řádků (pokud účet nemá oprávnění správce).
Je možné vytvořit více rolí. Při zvažování potřeb oprávnění pro jednoho uživatele sestavy se snažte vytvořit jednu roli, která uděluje všechna tato oprávnění, místo návrhu, kde bude uživatel sestavy členem více rolí. Je to proto, že uživatel sestavy může namapovat na více rolí, a to buď přímo pomocí svého uživatelského účtu, nebo nepřímo prostřednictvím členství ve skupině zabezpečení. Více mapování rolí může vést k neočekávaným výsledkům.
Když je uživatel sestavy přiřazený k více rolím, filtry zabezpečení na úrovni řádků se stanou doplňkovými. To znamená, že uživatelé sestavy uvidí řádky tabulky, které představují sjednocení těchto filtrů. V některých scénářích navíc není možné zaručit, že uživatel sestavy neuvidí řádky v tabulce. Na rozdíl od oprávnění použitých u databázových objektů SQL Serveru (a jiných modelů oprávnění) se princip "jakmile odepře vždy odepřen" nepoužije.
Představte si model se dvěma rolemi: První role s názvem Pracovní procesy omezuje přístup ke všem řádkům tabulky Mzdy pomocí následujícího výrazu pravidla:
FALSE()
Poznámka
Pravidlo nevrátí žádné řádky tabulky, když se jeho výraz vyhodnotí jako FALSE.
Druhá role s názvem Manažeři ale umožňuje přístup ke všem řádkům tabulky Mzdy pomocí následujícího výrazu pravidla:
TRUE()
Dbejte na to: Pokud se uživatel sestavy mapuje na obě role, uvidí všechny řádky tabulky Mzdy .
Zabezpečení na úrovni řádků funguje tak, že automaticky použije filtry na každý dotaz DAX a tyto filtry můžou mít negativní dopad na výkon dotazů. Efektivní zabezpečení na úrovni řádků se tedy týká dobrého návrhu modelu. Je důležité postupovat podle pokynů k návrhu modelu, jak je popsáno v následujících článcích:
Obecně platí, že je efektivnější vynucovat filtry zabezpečení na úrovni řádků u tabulek dimenzí, nikoli tabulek faktů. A spoléháte na dobře navržené relace, abyste zajistili, že se filtry zabezpečení na úrovni řádků rozšíří do jiných tabulek modelu. Filtry zabezpečení na úrovni řádků se šíří pouze prostřednictvím aktivních relací. Proto nepoužívejte funkci DAX LOOKUPVALUE , pokud by relace modelu mohly dosáhnout stejného výsledku.
Vždy, když se filtry zabezpečení na úrovni řádků vynucují u tabulek DirectQuery a existují relace s jinými tabulkami DirectQuery, nezapomeňte zdrojová databáze optimalizovat. Může zahrnovat návrh vhodných indexů nebo použití trvalých počítaných sloupců. Další informace najdete v pokynech k modelu DirectQuery v Power BI Desktopu.
Pomocí Analyzátor výkonu je možné měřit dopad filtrů RLS na výkon v Power BI Desktopu. Nejprve určete dobu trvání dotazu vizuálu sestavy, pokud není vynuceno zabezpečení na úrovni řádků. Potom pomocí příkazu Zobrazit jako na kartě Modelování na pásu karet vynucujte zabezpečení na úrovni řádků a určete a porovnejte doby trvání dotazu.
Po publikování do Power BI je nutné namapovat členy na sémantické role modelu. Do rolí můžou přidávat členy pouze sémantické vlastníky modelu nebo správci pracovního prostoru. Další informace najdete v tématu Zabezpečení na úrovni řádků (RLS) pomocí Power BI (Správa zabezpečení v modelu).
Členy můžou být uživatelské účty, skupiny zabezpečení, distribuční skupiny nebo skupiny s podporou pošty. Kdykoli je to možné, doporučujeme namapovat skupiny zabezpečení na sémantické role modelu. Zahrnuje správu členství ve skupinách zabezpečení v Microsoft Entra ID. Pravděpodobně tento úkol deleguje na správce sítě.
Otestujte každou roli, abyste měli jistotu, že model správně filtruje. Snadno to uděláte pomocí příkazu Zobrazit jako na kartě Modelování na pásu karet.
Pokud má model dynamická pravidla pomocí funkce USERNAME DAX, nezapomeňte otestovat očekávané a neočekávané hodnoty. Při vkládání obsahu Power BI – konkrétně pomocí vložení pro váš scénář zákazníků – může logika aplikace předat libovolnou hodnotu jako efektivní uživatelské jméno identity. Pokud je to možné, zajistěte, aby náhodné nebo škodlivé hodnoty byly výsledkem filtrů, které nevracely žádné řádky.
Představte si příklad použití Power BI Embedded, kde aplikace předá roli úlohy uživatele jako efektivní uživatelské jméno: Jedná se o manažera nebo pracovního procesu. Správci můžou zobrazit všechny řádky, ale pracovníci uvidí jenom řádky, ve kterých je hodnota sloupce Typ interní.
Definuje se následující výraz pravidla:
IF(
USERNAME() = "Worker",
[Type] = "Internal",
TRUE()
)
Problém s tímto výrazem pravidla spočívá v tom, že všechny hodnoty s výjimkou "Worker" vrátí všechny řádky tabulky. Náhodná hodnota, například "Wrker", tedy neúmyslně vrátí všechny řádky tabulky. Proto je bezpečnější napsat výraz, který testuje každou očekávanou hodnotu. V následujícím vylepšeném výrazu pravidla má neočekávaná hodnota za následek, že tabulka nevrací žádné řádky.
IF(
USERNAME() = "Worker",
[Type] = "Internal",
IF(
USERNAME() = "Manager",
TRUE(),
FALSE()
)
)
Výpočty někdy potřebují hodnoty, které nejsou omezené filtry zabezpečení na úrovni řádků. Sestava může například potřebovat zobrazit poměr výnosů získaných pro prodejní oblast uživatele sestavy nad všemi získanými výnosy.
I když není možné, aby výraz DAX přepsal zabezpečení na úrovni řádků – ve skutečnosti ani nedokáže určit, že se zabezpečení na úrovni řádků vynucuje – můžete použít tabulku souhrnného modelu. Tabulka souhrnného modelu se dotazuje na načtení výnosů pro všechny oblasti a není omezena filtry zabezpečení na úrovni řádků.
Pojďme se podívat, jak byste mohli tento požadavek na návrh implementovat. Nejprve zvažte následující návrh modelu:
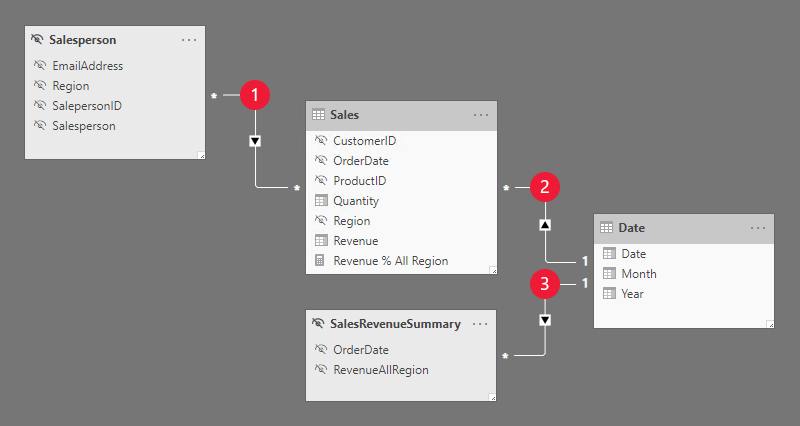
Model se skládá ze čtyř tabulek:
Následující výraz definuje počítanou tabulku SalesRevenueSummary :
SalesRevenueSummary =
SUMMARIZECOLUMNS(
Sales[OrderDate],
"RevenueAllRegion", SUM(Sales[Revenue])
)
Pro tabulku Salesperson se použije následující pravidlo zabezpečení na úrovni řádků:
[EmailAddress] = USERNAME()
Každá ze tří relací modelu je popsaná v následující tabulce:
| Vztah | Popis |
|---|---|
 |
Mezi tabulkami Salesperson a Sales existuje relace M:N. Pravidlo RLS filtruje sloupec EmailAddress skryté tabulky Salesperson pomocí funkce USERNAME DAX. Hodnota sloupce Region (pro uživatele sestavy) se rozšíří do tabulky Sales (Sales ). |
 |
Mezi tabulkami Date a Sales existuje relace 1:N. |
 |
Mezi tabulkami Date a SalesRevenueSummary existuje relace 1:N. |
Následující výraz definuje míru Revenue % All Region :
Revenue % All Region =
DIVIDE(
SUM(Sales[Revenue]),
SUM(SalesRevenueSummary[RevenueAllRegion])
)
Poznámka
Dbejte na to, abyste se vyhnuli zveřejnění citlivých faktů. Pokud v tomto příkladu existují jenom dvě oblasti, může uživatel sestavy vypočítat výnosy pro jinou oblast.
Někdy je vhodné se vyhnout použití zabezpečení na úrovni řádků. Pokud máte jenom několik jednoduchých pravidel zabezpečení na úrovni řádků, která používají statické filtry, zvažte místo toho publikování více sémantických modelů. Žádný z sémantických modelů nedefinuje role, protože každý sémantický model obsahuje data pro konkrétní cílovou skupinu uživatelů sestavy, která má stejná oprávnění k datům. Pak vytvořte jeden pracovní prostor pro cílovou skupinu a přiřaďte přístupová oprávnění k pracovnímu prostoru nebo aplikaci.
Například společnost, která má jen dvě prodejní oblasti, se rozhodne publikovat sémantický model pro každou prodejní oblast do různých pracovních prostorů. Sémantické modely nevynucuje zabezpečení na úrovni řádků. K filtrování zdrojových dat však používají parametry dotazu. Tímto způsobem se stejný model publikuje do každého pracovního prostoru – mají jenom jiné sémantické hodnoty parametrů modelu. Prodejci mají přiřazený přístup jenom k jednomu z pracovních prostorů (nebo publikovaným aplikacím).
Existuje několik výhod spojených s vyloučením zabezpečení na úrovni řádků:
Existují však nevýhody spojené s vyloučením zabezpečení na úrovni řádků:
Pokud zabezpečení na úrovni řádků generuje neočekávané výsledky, zkontrolujte následující problémy:
Pokud konkrétní uživatel nevidí žádná data, může to být proto, že jeho hlavní jméno uživatele (UPN) není uložené nebo je zadané nesprávně. Může k tomu dojít náhle, protože se jeho uživatelský účet změnil v důsledku změny jména.
Tip
Pro účely testování přidejte míru, která vrátí funkci USERNAME DAX. Můžeš to pojmenovat třeba "Kdo jsem já". Pak přidejte míru do vizuálu karty v sestavě a publikujte ji do Power BI.
Tvůrci a příjemci s oprávněním jen ke čtení v sémantickém modelu budou moct zobrazit jenom data, která mají povoleno zobrazit (na základě mapování role RLS).
Když uživatel zobrazí sestavu v pracovním prostoru nebo v aplikaci, může se zabezpečení na úrovni řádků v závislosti na jejich sémantických oprávněních modelu vynucovat. Z tohoto důvodu je důležité, aby uživatelé a tvůrci obsahu měli oprávnění ke čtení pouze pro základní sémantický model, když je nutné vynutit zabezpečení na úrovni řádků. Podrobnosti o pravidlechoprávněních
Další informace týkající se tohoto článku najdete v následujících zdrojích informací:
Události
Připojte se k nám ve společnosti FabCon Vegas
31. 3. 23 - 2. 4. 23
Ultimate Microsoft Fabric, Power BI, SQL a AI community-led event. 31. března až 2. dubna 2025.
Zaregistrovat se ještě dnes