Bei Azure Virtual Desktop handelt es sich um einen umfassenden in Microsoft Azure ausgeführten Dienst zur Desktop- und App-Virtualisierung. Virtual Desktop unterstützt die Aktivierung einer sicheren Remotedesktopumgebung, die Organisationen bei der Stärkung der Geschäftssicherheit unterstützt. Es bietet eine vereinfachte Verwaltung, Windows 10 und 11 Enterprise Multisession und Optimierungen für Microsoft 365 Apps für Unternehmen. Mit Virtual Desktop können Sie Ihre Windows-Desktops und Apps in Azure in Minuten bereitstellen und skalieren, indem Sie integrierte Sicherheits- und Compliancefeatures bereitstellen, um Ihre Apps und Daten sicher zu halten.
Wenn Sie weiterhin Remotearbeit für Ihre Organisation mit Virtual Desktop aktivieren, ist es wichtig, die Notfallwiederherstellungsfunktionen und bewährte Methoden zu verstehen. Diese Methoden stärken die Zuverlässigkeit in allen Regionen, um Daten sicher und Mitarbeiter produktiv zu halten. In diesem Artikel finden Sie Überlegungen zur Geschäftskontinuität und Notfallwiederherstellung (Business Continuity & Disaster Recovery, BCDR) zu Voraussetzungen, Bereitstellungsschritten und bewährten Methoden. Sie erfahren mehr über Optionen, Strategien und Architekturleitlinien. Mit dem Inhalt in diesem Dokument können Sie einen erfolgreichen BCDR-Plan vorbereiten und Ihnen dabei helfen, während geplanter und ungeplanter Ausfallzeiten mehr Resilienz in Ihr Unternehmen zu bringen.
Es gibt mehrere Arten von Katastrophen und Ausfällen, und jede kann eine andere Auswirkung haben. Resilienz und Wiederherstellung werden ausführlich für lokale und regionweite Ereignisse erläutert, einschließlich der Wiederherstellung des Dienstes in einer anderen Remote-Azure-Region. Diese Art der Wiederherstellung wird als georedundante Notfallwiederherstellung bezeichnet. Es ist wichtig, Ihre Virtual Desktop-Architektur für Resilienz und Verfügbarkeit zu erstellen. Sie sollten maximale lokale Resilienz bereitstellen, um die Auswirkungen von Fehlerereignissen zu verringern. Diese Resilienz reduziert auch die Anforderungen für die Ausführung von Wiederherstellungsprozeduren. Dieser Artikel enthält zudem Informationen zu Hochverfügbarkeit und bewährten Methoden.
Ziele und Umfang
Für diese Anleitung gelten die folgenden Zielsetzungen:
- Sicherstellen der maximalen Verfügbarkeit, Ausfallsicherheit und georedundanten Notfallwiederherstellung, während der Datenverlust für wichtige ausgewählte Benutzerdaten minimiert wird.
- Minimieren der Wiederherstellungszeit.
Diese Ziele werden auch als Recovery Point Objective (RPO) und Recovery Time Objective (RTO) bezeichnet.
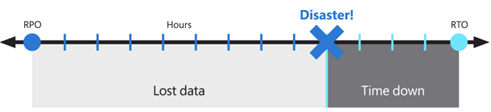
Die vorgeschlagene Lösung bietet lokale Hochverfügbarkeit, Schutz vor dem Ausfall einer einzelnen Verfügbarkeitszone sowie Schutz gegen den Ausfall einer gesamten Azure-Region. Sie basiert auf einer redundanten Bereitstellung in einer anderen oder sekundären Azure-Region, um den Dienst wiederherzustellen. Während es weiterhin eine bewährte Methode ist, benötigen Virtual Desktop und die Technologie, die zum Erstellen von BCDR verwendet wird, keine Azure-Regionen, die gekoppelt werden sollen. Primäre und sekundäre Speicherorte können eine beliebige Azure-Region-Kombination sein, wenn die Netzwerklatenz es zulässt. Der Betrieb von AVD-Hostpools in mehreren geographischen Regionen kann weitere Vorteile bieten, die nicht auf BCDR beschränkt sind.
Um die Auswirkungen eines einzelnen Verfügbarkeitszonenfehlers zu verringern, verwenden Sie Resilienz, um die Hochverfügbarkeit zu verbessern:
- Verteilen Sie auf der Berechnungsebene die Virtual Desktop-Sitzungshosts auf verschiedene Verfügbarkeitszonen.
- Verwenden Sie auf der Speicherebene die Zonenresilienz, wann immer möglich.
- Stellen Sie auf der Netzwerkebene zonenresiliente Azure ExpressRoute- und virtuelle private Netzwerkgateways (VPN) bereit.
- Überprüfen Sie für jede Abhängigkeit die Auswirkungen eines einzelnen Zonenausfalls und planen Sie Risikominderungen. Stellen Sie beispielsweise Active Directory-Domänencontroller und andere externe Ressourcen bereit, auf die von Virtual Desktop-Benutzern über mehrere Verfügbarkeitszonen hinweg zugegriffen wird.
Je nach der Anzahl der von Ihnen verwendeten Verfügbarkeitszonen sollten Sie die Anzahl der Sitzungshosts erhöhen, um den Verlust einer Zone auszugleichen. Beispielsweise können Sie auch mit verfügbaren (n-1)-Zonen die Benutzerfreundlichkeit und Leistung gewährleisten.
Hinweis
Azure-Verfügbarkeitszonen sind ein Feature mit hoher Verfügbarkeit, das die Resilienz verbessern kann. Betrachten Sie sie jedoch nicht als Notfallwiederherstellungslösung, um sich vor regionsweiten Katastrophen zu schützen.

Aufgrund der möglichen Kombinationen von Typen, Replikationsoptionen, Dienstfunktionen und Verfügbarkeitseinschränkungen in einigen Regionen wird die Cloud Cache-Komponente von FSLogix anstelle spezifischer Mechanismen zur Speicherreplikation empfohlen.
OneDrive wird In diesem Artikel nicht behandelt. Weitere Informationen zu Redundanz und Hochverfügbarkeit finden Sie unter SharePoint- und OneDrive-Datenresilienz in Microsoft 365.
Im weiteren Verlauf dieses Artikels lernen Sie Lösungen für die beiden verschiedenen Virtual Desktop-Hostpool-Typen kennen. Es gibt auch Beobachtungen, damit Sie diese Architektur mit anderen Lösungen vergleichen können:
- Persönlich: In diesem Typ des Hostpools verfügt ein Benutzer über einen dauerhaft zugewiesenen Sitzungshost, der sich niemals ändern sollte. Da es persönlich ist, kann diese VM Benutzerdaten speichern. Die Annahme besteht darin, Replikations- und Sicherungstechniken zu verwenden, um den Zustand zu erhalten und zu schützen.
- Gepoolt: Benutzer werden vorübergehend einem der verfügbaren Sitzungshost-VMs aus dem Pool zugewiesen, entweder direkt über eine Desktop-Anwendungsgruppe oder mithilfe von Remote-Apps. VMs sind zustandslos und Benutzerdaten und Profile werden im externen Speicher oder in OneDrive gespeichert.
Kostenauswirkungen werden diskutiert, aber das primäre Ziel ist die Bereitstellung einer effektiven georedundanten Notfallwiederherstellung mit minimalem Datenverlust. Weitere Informationen zu BCDR finden Sie in den folgenden Ressourcen:
Voraussetzungen
Stellen Sie die Kerninfrastruktur bereit und stellen Sie sicher, dass sie in der primären und sekundären Azure-Region verfügbar ist. Für Anleitungen zu Ihrer Netzwerktopologie können Sie die Azure Cloud Adoption Framework-Modelle Netzwerktopologie und Konnektivität verwenden:
Stellen Sie in beiden Modellen den primären Virtual Desktop-Hostpool und die sekundäre Notfallwiederherstellungsumgebung in unterschiedlichen virtuellen Netzwerken bereit und verbinden Sie sie mit jedem Hub in derselben Region. Platzieren Sie einen Hub an der primären Position, einen Hub an der sekundären Position, und richten Sie dann die Konnektivität zwischen den beiden ein.
Der Hub bietet schließlich hybride Konnektivität zu lokalen Ressourcen, Firewalldiensten, Identitätsressourcen wie Active Directory-Domänencontrollern und Verwaltungsressourcen wie Log Analytics.
Sie sollten alle Geschäftsanwendungen und abhängige Ressourcenverfügbarkeit berücksichtigen, wenn das Failover zum sekundären Speicherort ausgeführt werden soll.
Geschäftliche Kontinuität des Steuerbereichs und Notfallwiederherstellung
Virtual Desktop bietet Geschäftskontinuität und Notfallwiederherstellung für seinen Steuerbereich, damit Kundenmetadaten bei Ausfällen erhalten bleiben. Die Azure-Plattform verwaltet diese Daten und Prozesse, und Benutzer müssen nichts konfigurieren oder ausführen.

Virtual Desktop ist so konzipiert, dass es gegenüber Ausfällen einzelner Komponenten widerstandsfähig ist und eine schnelle Wiederherstellung nach Ausfällen ermöglicht. Wenn in einer Region ein Ausfall auftritt, führen die Komponenten der Dienstinfrastruktur einen Failover auf den zweiten Standort aus und setzen ihre Funktion wie gewohnt fort. Sie können weiterhin auf die Metadaten für den Dienst zugreifen, und die Benutzer können weiterhin Verbindungen mit den verfügbaren Hosts herstellen. Die Verbindungen von Endbenutzern bleiben online, sofern auf die Mandantenumgebung oder die Hosts zugegriffen werden kann. Datenspeicherorte für Virtual Desktop unterscheiden sich vom Speicherort des Hostpools, in dem die virtuellen Computer (VMs) bereitgestellt werden. Es ist möglich, Virtual Desktop-Metadaten in einer der unterstützten Regionen zu finden und dann VMs an einem anderen Speicherort bereitzustellen. Weitere Informationen finden Sie im Artikel zum Thema Virtual Desktop-Dienstarchitektur und -Resilienz.
Aktiv-Aktiv vs. Aktive-Passiv
Wenn verschiedene Gruppen von Benutzern unterschiedliche BCDR-Anforderungen haben, empfiehlt Microsoft, mehrere Hostpools mit verschiedenen Konfigurationen zu verwenden. Beispielsweise können Benutzer mit einer geschäftskritischen Anwendung einen vollständig redundanten Hostpool mit Funktionen für die georedundante Notfallwiederherstellung zuweisen. Entwicklungs- und Testbenutzer können jedoch einen separaten Hostpool ohne Notfallwiederherstellung verwenden.
Für jeden einzelnen Virtual Desktop-Hostpool können Sie Ihre BCDR-Strategie auf einem Aktiv-Aktiv- oder Aktiv-Passiv-Modell basieren. Bei diesem Szenario wird davon ausgegangen, dass dieselbe Gruppe von Benutzern an einem geographischen Standort von einem bestimmten Hostpool bereitgestellt wird.
- Aktiv/Aktiv
Für jeden Hostpool in der primären Region stellen Sie einen zweiten Hostpool in der sekundären Region bereit.
Diese Konfiguration bietet fast kein RTO, und RPO ist mit zusätzlichen Kosten verbunden.
Sie benötigen keinen Administrator, um zu eingreifen oder einen Failover auszuführen. Während normaler Vorgänge bietet der sekundäre Hostpool dem Benutzer virtuelle Desktopressourcen.
Jeder Hostpool verfügt über eigene Speicherkonten (mindestens eines) für persistente Benutzerprofile.
Sie sollten die Latenz auf der Grundlage des physischen Standorts des Benutzers und der verfügbaren Konnektivität bewerten. Für einige Azure-Regionen, z. B. Westeuropa und Nordeuropa, kann der Unterschied beim Zugriff auf die primären oder sekundären Regionen vernachlässigbar sein. Sie können dieses Szenario mithilfe des Tools Azure Virtual Desktop Estimator überprüfen.
Benutzer werden sowohl im primären als auch im sekundären Hostpool verschiedenen Anwendungsgruppen zugewiesen, z. B der Desktopanwendungsgruppe (DAG) und der RemoteApp-Anwendungsgruppe (RAG). In diesem Fall werden doppelte Einträge in ihrem Virtual Desktop-Clientfeed angezeigt. Um Verwirrung zu vermeiden, verwenden Sie separate Virtuelle Desktop-Arbeitsbereiche mit klaren Namen und Bezeichnungen, die den Zweck jeder Ressource widerspiegeln. Informieren Sie Ihre Benutzer über die Verwendung dieser Ressourcen.
Wenn Sie Speicher zum separaten Verwalten von FSLogix-Profil- und ODFC-Containern benötigen, verwenden Sie Cloud Cache, um einen RPO-Wert von fast Null sicherzustellen.
- Um Profilkonflikte zu vermeiden, können Benutzer nicht gleichzeitig auf beide Hostpools zugreifen.
- Aufgrund der aktiven Natur dieses Szenarios sollten Sie Ihre Benutzer darüber informieren, wie Sie diese Ressourcen ordnungsgemäß verwenden.
Hinweis
Die Verwendung separater ODFC-Container ist ein erweitertes Szenario mit höherer Komplexität. Die Bereitstellung auf diese Weise wird nur in bestimmten Szenarien empfohlen.
- Aktiv-Passiv
- Wie bei Aktiv-Aktiv stellen Sie für jeden Hostpool in der primären Region einen zweiten Hostpool in der sekundären Region bereit.
- Die Anzahl der in der sekundären Region aktiven Berechnungsressourcen wird je nach verfügbarem Budget im Vergleich zu der primären Region reduziert. Sie können die automatische Skalierung verwenden, um mehr Rechenkapazität bereitzustellen, aber es erfordert mehr Zeit, und Azure-Kapazität ist nicht garantiert.
- Diese Konfiguration bietet höhere RTO im Vergleich zum Aktiv-Aktiv-Ansatz, ist aber weniger teuer.
- Bei einem Azure-Ausfall muss ein Administrator eingreifen, um eine Failoverprozedur durchzuführen. Der sekundäre Hostpool bietet Benutzern normalerweise keinen Zugriff auf Virtual Desktop-Ressourcen.
- Jeder Hostpool verfügt über eigene Speicherkonten für beständige Benutzerprofile.
- Benutzer, die Virtual Desktop-Dienste mit optimaler Latenz und Leistung nutzen, sind nur betroffen, wenn es einen Azure-Ausfall gibt. Sie sollten dieses Szenario mithilfe des Tools Azure Virtual Desktop Experience Estimator überprüfen. Die Leistung sollte für die sekundäre Notfallwiederherstellungsumgebung akzeptabel sein.
- Benutzer werden nur einer einzelnen Gruppe von Anwendungsgruppen zugewiesen, z. B. Desktop- und Remote-Apps. Während normaler Vorgänge befinden sich diese Apps im primären Hostpool. Während eines Ausfalls und nach einem Failover werden Benutzern Anwendungsgruppen im sekundären Hostpool zugewiesen. Es werden keine doppelten Einträge im Virtual Desktop-Client-Feed des Benutzers angezeigt, sie können denselben Arbeitsbereich verwenden, und alles ist transparent für sie.
- Wenn Sie Speicher zum Verwalten von FSLogix-Profil- und Office-Containern benötigen, verwenden Sie Cloud Cache, um fast null RPO sicherzustellen.
- Um Profilkonflikte zu vermeiden, können Benutzer nicht gleichzeitig auf beide Hostpools zugreifen. Da dieses Szenario Aktiv-Passiv ist, können Administratoren dieses Verhalten auf Anwendungsgruppenebene erzwingen. Erst nach einer Failoverprozedur kann der Benutzer auf jede Anwendungsgruppe im sekundären Hostpool zugreifen. Der Zugriff wird in der primären Hostpoolan-Awendungsgruppe widerrufen und einer Anwendungsgruppe im sekundären Hostpool neu zugewiesen.
- Führen Sie ein Failover für alle Anwendungsgruppen aus, andernfalls können Benutzer, die unterschiedliche Anwendungsgruppen in verschiedenen Hostpools verwenden, Profilkonflikte verursachen, wenn sie nicht effektiv verwaltet werden.
- Es ist möglich, einer bestimmten Teilmenge von Benutzern den selektiven Failover auf den sekundären Hostpool zu gestatten und ein begrenztes Aktiv-Aktiv-Verhalten sowie eine Test-Failover-Funktionalität zu bieten. Es ist auch möglich, bestimmte Anwendungsgruppen ausfallen zu lassen, aber Sie sollten Ihre Benutzer darauf hinweisen, dass sie nicht gleichzeitig Ressourcen aus verschiedenen Hostpools verwenden sollten.
Unter bestimmten Umständen können Sie einen einzelnen Hostpool mit einer Mischung aus Sitzungshosts erstellen, die sich in verschiedenen Regionen befinden. Der Vorteil dieser Lösung besteht darin, dass, wenn Sie über einen einzelnen Hostpool verfügen, keine doppelten Definitionen und Zuordnungen für Desktop- und Remote-Apps erforderlich sind. Leider hat die Notfallwiederherstellung für freigegebene Hostpools verschiedene Nachteile:
- Für gepoolte Hostpools ist es nicht möglich, einen Benutzer in derselben Region zu einem Sitzungshost zu erzwingen.
- Ein Benutzer kann beim Herstellen einer Verbindung mit einem Sitzungshost in einer Remoteregion eine höhere Latenz und eine suboptimale Leistung erzielen.
- Wenn Sie Speicher für Benutzerprofile benötigen, benötigen Sie eine komplexe Konfiguration zum Verwalten von Zuordnungen für Sitzungshosts in den primären und sekundären Regionen.
- Sie können den Ausgleichsmodus verwenden, um den Zugriff auf Sitzungshosts, die sich in der sekundären Region befinden, vorübergehend zu deaktivieren. Diese Methode führt jedoch zu mehr Komplexität, Verwaltungsaufwand und ineffizienter Nutzung von Ressourcen.
- Sie können Sitzungshosts in den sekundären Regionen in einem Offlinezustand halten, was jedoch zu mehr Komplexität und Verwaltungsaufwand führt.
Überlegungen und Empfehlungen
Allgemein
Um entweder eine Aktiv-Aktiv- oder Aktiv-Passiv-Konfiguration mit mehreren Hostpools und einem FSLogix-Cloudcachemechanismus bereitzustellen, können Sie den Hostpool je nach Modell innerhalb desselben Arbeitsbereichs oder eines anderen Erstellens erstellen. Dieser Ansatz erfordert, dass Sie die Ausrichtung und Updates beibehalten und sowohl Hostpools synchronisiert als auch auf derselben Konfigurationsebene halten. Zusätzlich zu einem neuen Hostpool für die sekundäre Notfallwiederherstellungsregion müssen Sie:
- Neue unterschiedliche Anwendungsgruppen und verwandte Anwendungen für den neuen Hostpool erstellen.
- Benutzerzuweisungen an den primären Hostpool widerrufen, und sie dann während des Failovers manuell dem neuen Hostpool zuweisen.
Sehen Sie sich Optionen für Geschäftskontinuität und Notfallwiederherstellung für FSLogix an.
- In diesem Dokument wird keine Profilwiederherstellung behandelt.
- Der Cloudcache (aktiv/passiv) ist in diesem Dokument enthalten, wird aber mithilfe desselben Hostpools implementiert.
- Der Cloudcache (aktiv/aktiv) wird im restlichen Teil dieses Dokuments behandelt.
Es gibt Einschränkungen für Virtual Desktop-Ressourcen, die beim Entwurf einer Virtual Desktop-Architektur berücksichtigt werden müssen. Überprüfen Sie Ihren Entwurf basierend auf den Einschränkungen des Virtual Desktop Services.
Für Diagnose und Überwachung ist es sinnvoll, denselben Log Analytics-Arbeitsbereich sowohl für den primären als auch für den sekundären Hostpool zu verwenden. Mit dieser Konfiguration bietet Azure Virtual Desktop Insights eine einheitliche Ansicht der Bereitstellung in beiden Regionen.
Die Verwendung eines einzelnen Protokollziels kann jedoch Probleme verursachen, wenn die gesamte primäre Region nicht verfügbar ist. Die sekundäre Region kann den Log Analytics-Arbeitsbereich in der nicht verfügbaren Region nicht verwenden. Wenn diese Situation inakzeptabel ist, könnten die folgenden Lösungen durchgeführt werden:
- Verwenden Sie einen separaten Log Analytics-Arbeitsbereich für jede Region, und verweisen Sie dann auf die Virtual Desktop-Komponenten, um sich beim lokalen Arbeitsbereich anzumelden.
- Testen und überprüfen Sie die Replikations- und Failoverfunktionen des Logs Analytics-Arbeitsbereichs.
Compute
Für die Bereitstellung beider Hostpools in den primären und sekundären Notfallwiederherstellungsregionen sollten Sie Ihre Sitzungshost-VM-Flotte über mehrere Verfügbarkeitszonen verteilen. Wenn in der lokalen Region keine Verfügbarkeitszonen verfügbar sind, können Sie eine Verfügbarkeitsgruppe verwenden, um Ihre Lösung stabiler zu machen als bei einer Standardbereitstellung.
Das goldene Image, das Sie für die Bereitstellung von Hostpools in der sekundären Notfallwiederherstellungsregion verwenden, sollte dasselbe sein, das Sie für die primäre Bereitstellung verwenden. Sie sollten Images in der Azure Compute Gallery speichern und mehrere Imagereplikate sowohl an den primären als auch an den sekundären Speicherorten konfigurieren. Jedes Imagereplikat kann eine parallele Bereitstellung einer maximalen Anzahl von VMs unterstützen, und je nach gewünschter Größe des Bereitstellungsbatches benötigen Sie möglicherweise mehr als eines. Weitere Informationen zu Compute Gallery finden Sie unter Speichern und Freigeben von Images in einer Azure Compute Gallery.
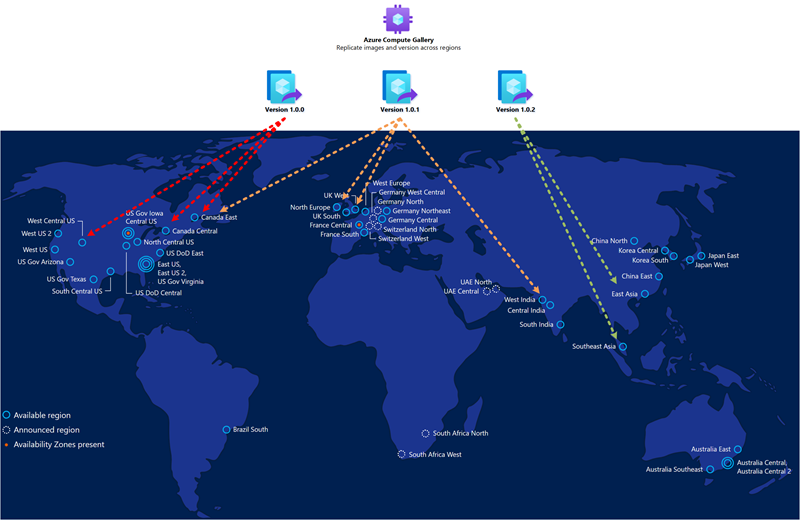
Die Azure Compute Gallery ist keine globale Ressource. Es wird empfohlen, mindestens einen sekundären Katalog in der sekundären Region zu verwenden. Erstellen Sie in Ihrer primären Region einen Katalog, eine VM-Imagedefinition und eine VM-Imageversion. Erstellen Sie dann dieselben Objekte auch in der sekundären Region. Beim Erstellen der VM-Imageversion besteht die Möglichkeit, die in der primären Region erstellte VM-Imageversion zu kopieren, indem Sie den Katalog, die VM-Imagedefinition und die VM-Imageversion angeben, die in der primären Region verwendet wird. Azure kopiert das Image und erstellt eine lokale VM-Imageversion. Es ist möglich, diesen Vorgang über das Azure-Portal oder mithilfe des Azure-CLI-Befehls wie unten beschrieben auszuführen:
Nicht alle Sitzungshost-VMs in den sekundären Notfallwiederherstellungsspeicherorten müssen aktiv sein und ständig ausgeführt werden. Sie müssen zunächst eine ausreichende Anzahl von VMs erstellen und danach einen Autoskalierungsmechanismus wie Skalierungspläne verwenden. Mit diesen Mechanismen ist es möglich, die meisten Computeressourcen in einem Offline- oder freigegebenen Zustand beizubehalten, um Kosten zu reduzieren.
Es ist auch möglich, die Automatisierung zum Erstellen von Sitzungshosts in der sekundären Region nur bei Bedarf zu verwenden. Diese Methode optimiert die Kosten, aber je nach verwendeten Mechanismus ist möglicherweise ein längeres RTO erforderlich. Dieses Konzept ermöglicht keine Failovertests ohne eine neue Bereitstellung und kein selektives Failover für bestimmte Benutzergruppen.

Hinweis
Sie müssen jede VM des Sitzungshosts mindestens einmal alle 90 Tage aktivieren, um das Authentifizierungstoken zu aktualisieren, das zum Herstellen einer Verbindung mit dem Virtual Desktop-Steuerbereich erforderlich ist. Sie sollten auch routinemäßig Sicherheitspatches und Anwendungsupdates anwenden.
- Wenn Sitzungshosts in einer Offline- oder im freigegebenen Zustand in der sekundären Region vorhanden sind, ist nicht garantiert, dass die Kapazität verfügbar ist, wenn es einen Notfall in der primären Region gibt. Dies gilt auch, wenn neue Sitzungshosts bei Bedarf und bei der Verwendung von Site Recovery bereitgestellt werden. Die Computekapazität kann nur gewährleistet werden, wenn die zugehörigen Ressourcen bereits zugewiesen und aktiv sind.
Wichtig
Azure Reservations bietet keine garantierte Kapazität in der Region.
Für Cloud Cache-Nutzungsszenarien empfehlen wir die Verwendung der Premium-Ebene für verwaltete Datenträger.
Storage
In diesem Leitfaden verwenden Sie mindestens zwei separate Speicherkonten für jeden Virtual Desktop-Hostpool. Einer ist für den FSLogix-Profilcontainer und einer für die Office-Containerdaten. Sie benötigen zudem ein weiteres Speicherkonto für MSIX-Pakete. Es gelten die folgenden Bedingungen:
- Sie können die Azure Files-Freigabe und Azure NetApp Files als Speicheralternativen verwenden. Informationen zum Vergleichen der Optionen finden Sie unter den FSLogix-Container-Speicheroptionen.
- Die Azure Files-Freigabe kann Zonenresilienz bieten, indem sie die Resilienzoption für zonenredundanten Speicher (ZRS) verwendet, wenn sie in der Region verfügbar ist.
- Sie können die Funktion für den georedundanten Speicher in den folgenden Situationen nicht verwenden:
- Sie benötigen eine Region, die nicht über ein Paar verfügt. Die Regionspaare für den georedundanten Speicher sind fest und können nicht geändert werden.
- Sie verwenden die Premium-Ebene.
- RPO und RTO sind im Vergleich zum FSLogix Cloud Cache-Mechanismus höher.
- Es ist nicht einfach, Failover und Failback in einer Produktionsumgebung zu testen.
- Für Azure NetApp Files sind weitere Überlegungen erforderlich:
- Zonenredundanz ist noch nicht verfügbar. Wenn die Resilienzanforderung wichtiger als die Leistung ist, verwenden Sie die Azure Files- Freigabe.
- Azure NetApp Files kann zonal sein. Kunden können also entscheiden, welche (einzelne) Azure-Verfügbarkeitszone für Zuordnungen verwendet werden soll.
- Zonenübergreifende Replikation kann auf Volume-Ebene eingerichtet werden, um Zonenresilienz bereitzustellen, die Replikation erfolgt jedoch asynchron und erfordert ein manuelles Failover. Für diesen Prozess ist ein Wiederherstellungspunktziel (RPO) und ein Wiederherstellungszeitziel (RTO) erforderlich, die größer als 0 sind. Bevor Sie dieses Feature verwenden, sollten Sie die Anforderungen und Überlegungen für die zonenübergreifende Replikation lesen.
- Azure NetApp Files kann jetzt mit zonenredundanten VPN- und ExpressRoute-Gateways verwendet werden, wenn das Feature Standard Networking verwendet wird (beispielsweise für Netzwerkresilienz). Weitere Informationen finden Sie unter Unterstützte Netzwerktopologien.
- Azure Virtual WAN wird unterstützt, wenn es zusammen mit Azure NetApp Files Standard Networking verwendet wird. Weitere Informationen finden Sie unter Unterstützte Netzwerktopologien.
- Azure NetApp Files verfügt über einen regionsübergreifenden Replikationsmechanismus. Es gelten die folgenden Bedingungen:
- Es ist nicht in allen Regionen verfügbar.
- Regionspaare der regionsübergreifenden Replikation von Azure NetApp Files-Volumes können sich von Azure Storage-Regionspaaren unterscheiden.
- Sie kann nicht gleichzeitig mit der zonenübergreifenden Replikation verwendet werden.
- Das Failover ist nicht transparent, und das Failback erfordert eine Neukonfiguration des Speichers.
- Einschränkungen
- Es gibt Grenzwerte für die Größe, Eingabe-/Ausgabevorgänge pro Sekunde (IOPS), Bandbreite MB/s für Speicherkonten und Volumes für Azure Files-Freigaben und Azure NetApp Files. Bei Bedarf ist es möglich, mehr als einen für denselben Hostpool in Virtual Desktop zu verwenden, indem die Gruppeneinstellungen in FSLogix verwendet werden. Diese Konfiguration erfordert jedoch mehr Planung und Konfiguration.
Das Speicherkonto, das Sie für MSIX-Anwendungspakete verwenden, sollte sich von den anderen Konten für Profil- und Office-Container unterscheiden. Die folgenden Optionen für die georedundante Notfallwiederherstellung sind verfügbar:
- Ein Speicherkonto mit aktiviertem georedundanten Speicher in der primären Region
- Der sekundäre Bereich ist fest. Diese Option eignet sich nicht für den lokalen Zugriff, wenn ein Failover des Speicherkontos vorliegt.
- Zwei separate Speicherkonten, eines in der primären Region und eines in der sekundären Region (empfohlen)
- Verwenden Sie den zonenredundanten Speicher für mindestens die primäre Region.
- Jeder Hostpool in jeder Region verfügt über lokalen Speicherzugriff auf MSIX-Pakete mit geringer Latenz.
- Kopieren Sie MSIX-Pakete zweimal an beiden Speicherorten, und registrieren Sie die Pakete zweimal in beiden Hostpools. Weisen Sie der Anwendungsgruppe zweimal Benutzer zu.
FSLogix
Microsoft empfiehlt, die folgende FSLogix-Konfiguration und -Funktionen zu verwenden:
Wenn der Profilcontainerinhalt über eine separate BCDR-Verwaltung verfügen muss und unterschiedliche Anforderungen im Vergleich zum Office-Container aufweist, sollten Sie sie teilen.
- Der Office-Container hat nur zwischengespeicherte Inhalte, die von der Quelle neu erstellt oder neu aufgefüllt werden können, wenn es einen Notfall gibt. Bei Office-Container müssen Sie möglicherweise keine Sicherungen beibehalten, wodurch Kosten reduziert werden können.
- Wenn Sie verschiedene Speicherkonten verwenden, können Sie nur Sicherungen im Profilcontainer aktivieren. Oder Sie müssen verschiedene Einstellungen wie Aufbewahrungszeitraum, verwendeter Speicher, Häufigkeit und RTO/RPO haben.
Cloud Cache ist eine FSLogix-Komponente, in der Sie mehrere Profilspeicherorte angeben und Profildaten asynchron replizieren können, ohne sich auf zugrunde liegende Mechanismen zur Speicherreplikation zu verlassen. Wenn der erste Speicherort fehlschlägt oder nicht erreichbar ist, verwendet Cloud Cache automatisch per Failover den zweiten und fügt effektiv eine Resilienzebene hinzu. Verwenden Sie Cloud Cache, um sowohl Profil- als auch Office-Container zwischen verschiedenen Speicherkonten in den primären und sekundären Regionen zu replizieren.
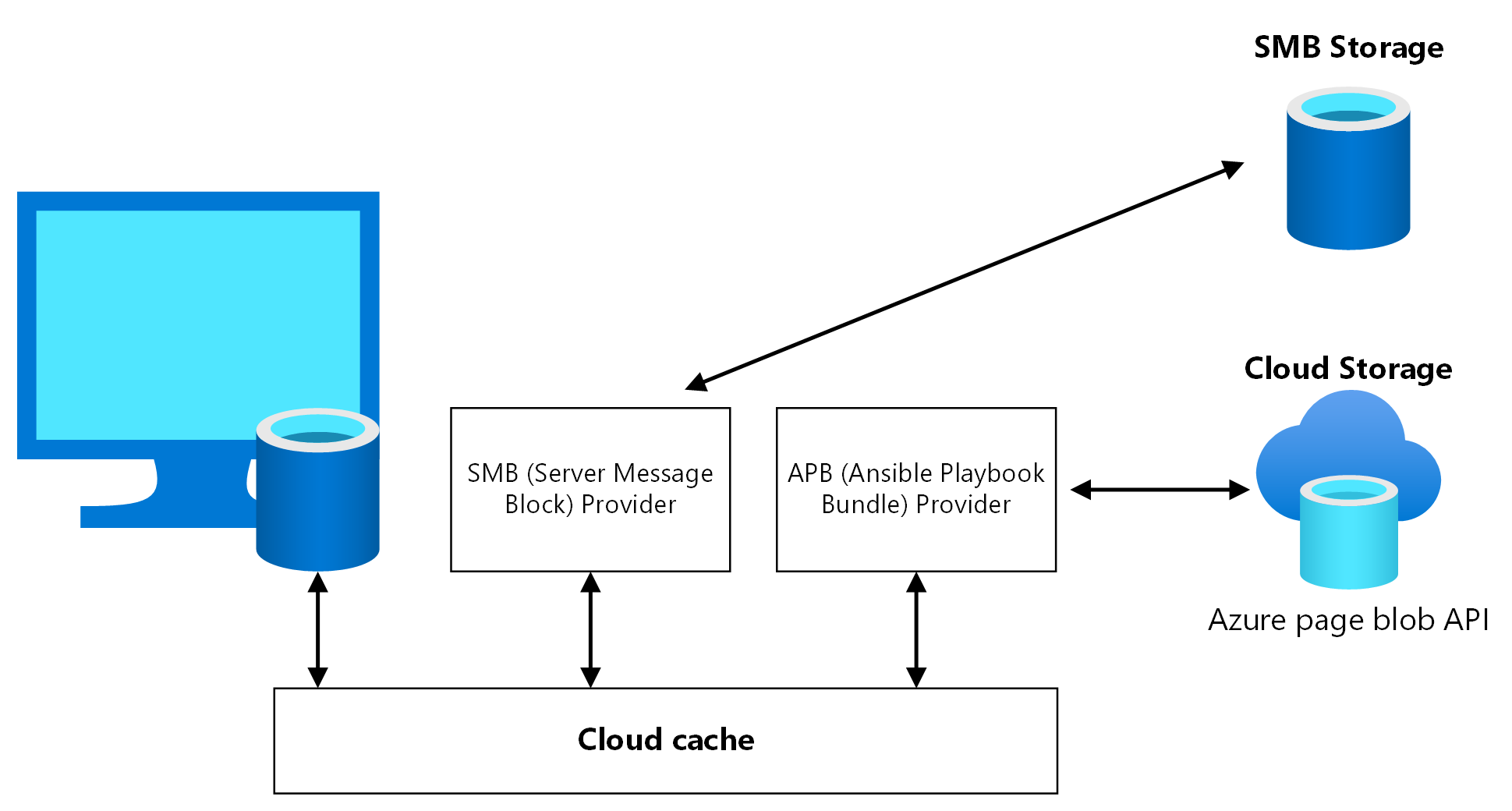
Sie müssen Cloud Cache zweimal in der Sitzungshost-VM-Registrierung aktivieren, einmal für den Profil-Container und einmal für den Office-Container. Es ist möglich, Cloud Cache für den Office-Container nicht zu aktivieren, aber es nicht zu aktivieren, kann eine Datenverlagerung zwischen der primären und der sekundären Notfallwiederherstellungsregion verursachen, wenn ein Failover und ein Failback stattfindet. Testen Sie dieses Szenario sorgfältig, bevor Sie es in der Produktion verwenden.
Cloud Cache ist sowohl mit geteilten Profilen als auch mit Einstellungen pro Gruppe kompatibel. Pro Gruppe erfordert sorgfältiges Entwerfen und Planen von Active Directory-Gruppen und -Mitgliedschaften. Sie müssen sicherstellen, dass jeder Benutzer Teil genau einer Gruppe ist und diese Gruppe verwendet wird, um Zugriff auf Hostpools zu gewähren.
Der Parameter CCDLocations, der in der Registrierung für den Hostpool in der sekundären Notfallwiederherstellungsregion angegeben ist, wird im Vergleich zu den Einstellungen in der primären Region in umgekehrter Reihenfolge wiederhergestellt. Weitere Informationen finden Sie unter Tutorial: Konfigurieren von Cloudcache zum Umleiten von Profil- oder Office-Containern zu mehreren Anbietern.
Tipp
Dieser Artikel konzentriert sich auf ein bestimmtes Szenario. Weitere Szenarien werden in den Optionen für hohe Verfügbarkeit für FSLogix und Geschäftskontinuität und Notfallwiederherstellung für FSLogix beschrieben.

Das folgende Beispiel zeigt eine Cloud Cache-Konfiguration und verwandte Registrierungsschlüssel:
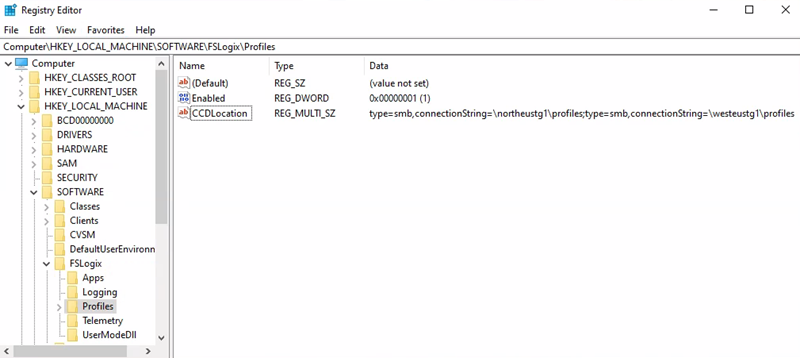
Primärregion = Nordeuropa
Profilcontainerspeicherkonto URI = \northeustg1\profile
- Registrierungsschlüsselpfad = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix-Profile >
- CCDLocations-Wert = type=smb,connectionString=\northeustg1\profiles;type=smb,connectionString=\westeustg1\profile
Hinweis
Wenn Sie zuvor die FSLogix-Vorlagen heruntergeladen haben, können Sie die gleichen Konfigurationen über die Active Directory-Gruppenrichtlinie Verwaltungskonsole ausführen. Weitere Informationen zum Einrichten des Gruppenrichtlinie-Objekts für FSLogix finden Sie in der Anleitung Verwenden von FSLogix Gruppenrichtlinie Vorlagendateien.
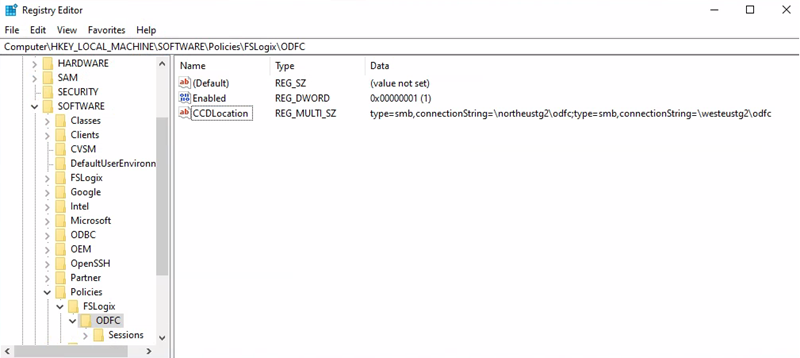
Office-Container-Speicherkonto-URI = \northeustg2\odcf
Registrierungsschlüsselpfad = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
CCDLocations-Wert = type=smb,connectionString=\northeustg2\odfc;type=smb,connectionString=\westeustg2\odfc


Hinweis
In den obigen Screenshots sind der Kürze und Einfachheit halber nicht alle empfohlenen Registrierungsschlüssel für FSLogix und Cloud Cache aufgeführt. Weitere Informationen finden Sie in den FSLogix-Konfigurationsbeispielen.
Sekundäre Region = Westeuropa
- Profilcontainer-Speicherkonto-URI = \westeustg1\profiles
- Registrierungsschlüsselpfad = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- CCDLocations-Wert = type=smb,connectionString=\westeustg1\profiles;type=smb,connectionString=\northeustg1\profiles
- Office-Container-Speicherkonto-URI = \westeustg2\odcf
- Registrierungsschlüsselpfad = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- CCDLocations-Wert = type=smb,connectionString=\westeustg2\odfc;type=smb,connectionString=\northeustg2\odfc
Cloud Cache-Replikation
Die Mechanismen für die Cloud Cache-Konfiguration und -Replikation garantieren die Profildatenreplikation zwischen verschiedenen Regionen mit minimalem Datenverlust. Da die gleiche Benutzerprofildatei im ReadWrite-Modus nur durch einen Prozess geöffnet werden kann, sollte der gleichzeitige Zugriff vermieden werden, daher sollten Benutzer keine Verbindung mit beiden Hostpools gleichzeitig öffnen.

Laden Sie eine Visio-Datei dieser Architektur herunter.
Datenfluss
Ein Virtual Desktop-Benutzer startet den Virtual Desktop-Client und öffnet dann eine veröffentlichte Desktop- oder Remote-App-Anwendung, die dem Hostpool der primären Region zugewiesen ist.
FSLogix ruft das Benutzerprofil und Office-Container ab und stellt dann den zugrunde liegenden Speicher-VHD/X aus dem Speicherkonto in der primären Region her.
Gleichzeitig initialisiert die Cloud Cache-Komponente die Replikation zwischen den Dateien in der primären Region und den Dateien in der sekundären Region. Für diesen Prozess erhält Cloud Cache in der primären Region eine exklusive Lese- und Schreibsperre für diese Dateien.
Derselbe Virtual Desktop-Benutzer möchte jetzt eine andere veröffentlichte Anwendung starten, die dem sekundären Hostpool zugewiesen ist.
Die FSLogix-Komponente, die auf dem Virtual Desktop-Sitzungshost in der sekundären Region ausgeführt wird, versucht, die Benutzerprofil-VHD/X-Dateien aus dem lokalen Speicherkonto einzubinden. Das Einbinden schlägt jedoch fehl, da diese Dateien von der Cloud Cache-Komponente gesperrt werden, die auf dem Virtual Desktop-Sitzungshost in der primären Region ausgeführt wird.
In der Standardkonfiguration von FSLogix und Cloud Cache kann sich der Benutzer nicht anmelden, und in den FSLogix-Diagnoseprotokollen wird der Fehler ERROR_LOCK_VIOLATION 33 (0x21) angezeigt.


Identität
Eine der wichtigsten Abhängigkeiten für Virtual Desktop ist die Verfügbarkeit der Benutzeridentität. Um von Ihren Sitzungshosts aus auf vollständig-remote virtuelle Desktops und Remote-Apps zugreifen zu können, müssen sich Ihre Benutzer authentifizieren können. Microsoft Entra ID ist der zentralisierte Cloudidentitätsdienst von Microsoft, der diese Funktion ermöglicht. Microsoft Entra ID wird immer verwendet, um Benutzer für Virtual Desktop zu authentifizieren. Sitzungshosts können mit dem gleichen Microsoft Entra-Mandanten oder unter Verwendung von Active Directory Domain Services (AD DS) oder Microsoft Entra Domain Services mit einer Active Directory-Domäne verbunden werden, was Ihnen eine Auswahl flexibler Konfigurationsoptionen bietet.
Microsoft Entra ID
- Dies ist ein globaler, multiregionaler und resilienter Dienst mit hoher Verfügbarkeit. In diesem Kontext ist keine andere Aktion im Rahmen eines Virtual Desktop BCDR-Plans erforderlich.
Active Directory Domain Services
- Damit Active Directory Domain Services auch im Falle eines regionsweiten Notfalls belastbar und hochverfügbar sind, sollten Sie mindestens zwei Domänencontroller (DC) in der primären Azure-Region bereitstellen. Diese Domänencontroller sollten sich in verschiedenen Verfügbarkeitszonen befinden, sofern möglich, und Sie sollten die ordnungsgemäße Replikation mit der Infrastruktur in der sekundären Region und schließlich lokal sicherstellen. Sie sollten mindestens einen weiteren Domänencontroller in der sekundären Region mit globalen Katalog- und DNS-Rollen erstellen. Weitere Informationen finden Sie unter Bereitstellen von AD DS in einem virtuellen Azure-Netzwerk.
Microsoft Entra Connect
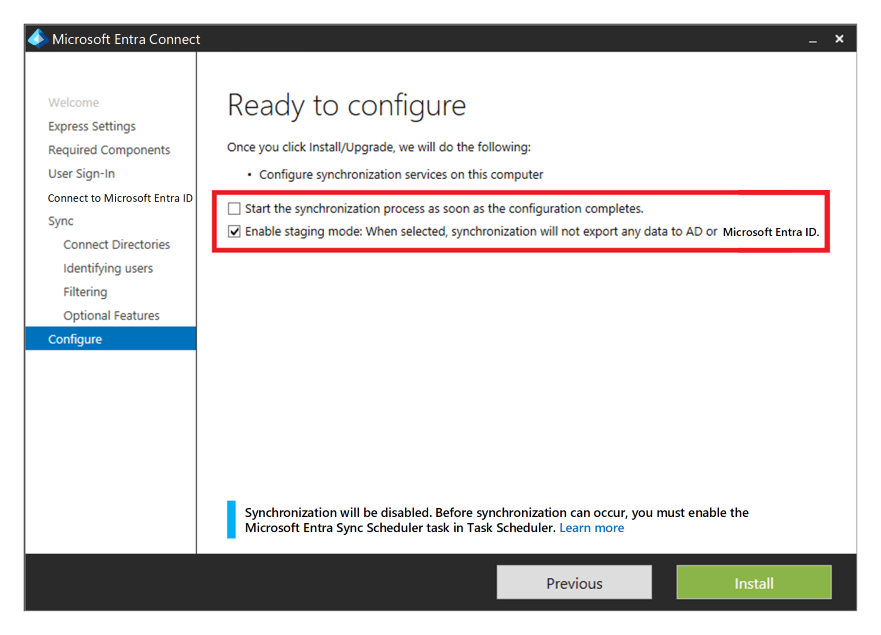
Wenn Sie Microsoft Entra ID mit Active Directory Domain Services und dannMicrosoft Entra Connect verwenden, um Benutzeridentitätsdaten zwischen Active Directory Domain Services und Microsoft Entra ID zu synchronisieren, sollten Sie die Resilienz und Wiederherstellung dieses Diensts zum Schutz vor einem dauerhaften Notfall berücksichtigen.
Sie können Hochverfügbarkeit und Notfallwiederherstellung bereitstellen, indem Sie eine zweite Instanz des Dienstes in der sekundären Region installieren und den Stagingmodus aktivieren.
Im Falle einer Wiederherstellung muss der Administrator die sekundäre Instanz hochstufen, indem er sie aus dem Stagingmodus nimmt. Sie müssen derselben Prozedur folgen wie beim Versetzen eines Servers in den Stagingmodus. Microsoft Entra-Anmeldeinformationen als „Globaler Administrator“ sind erforderlich, um diese Konfiguration auszuführen.
Microsoft Entra Domain Services
- Sie können Microsoft Entra Domain Services in einigen Szenarien als Alternative zu Active Directory Domain Services verwenden.
- Es bietet Hochverfügbarkeit.
- Wenn die georedundante Notfallwiederherstellung im Umfang Ihres Szenarios liegt, sollten Sie ein anderes Replikat in der sekundären Azure-Region mithilfe einer Replikatgruppe bereitstellen. Sie können diese Funktion auch verwenden, um die Hochverfügbarkeit in der primären Region zu erhöhen.
Architekturdiagramme
Persönlicher Hostpool

Laden Sie eine Visio-Datei dieser Architektur herunter.
Gepoolter Hostpool

Laden Sie eine Visio-Datei dieser Architektur herunter.
Failover und Failback
Szenario des persönlichen Hostpools
Hinweis
Nur das Aktiv-Passiv-Modell wird in diesem Abschnitt behandelt – ein Aktiv-Aktive-Modell erfordert kein Failover oder ein Eingreifen des Administrators.
Failover und Failback für einen persönlichen Hostpool unterscheidet sich, da kein Cloud Cache und externer Speicher für Profil- und Office-Container verwendet werden. Sie können die FSLogix-Technologie weiterhin verwenden, um die Daten in einem Container aus dem Sitzungshost zu speichern. Es gibt keinen sekundären Hostpool in der Notfallwiederherstellungsregion, sodass keine weiteren Arbeitsbereiche und Virtual Desktop-Ressourcen erstellt werden müssen, um sie zu replizieren und auszurichten. Sie können Site Recovery verwenden, um Sitzungshost-VMs zu replizieren.
Sie können Site Recovery in mehreren unterschiedlichen Szenarien verwenden. Verwenden Sie für Virtual Desktop die Architektur der Notfallwiederherstellung von Azure zu Azure in Azure Site Recovery.
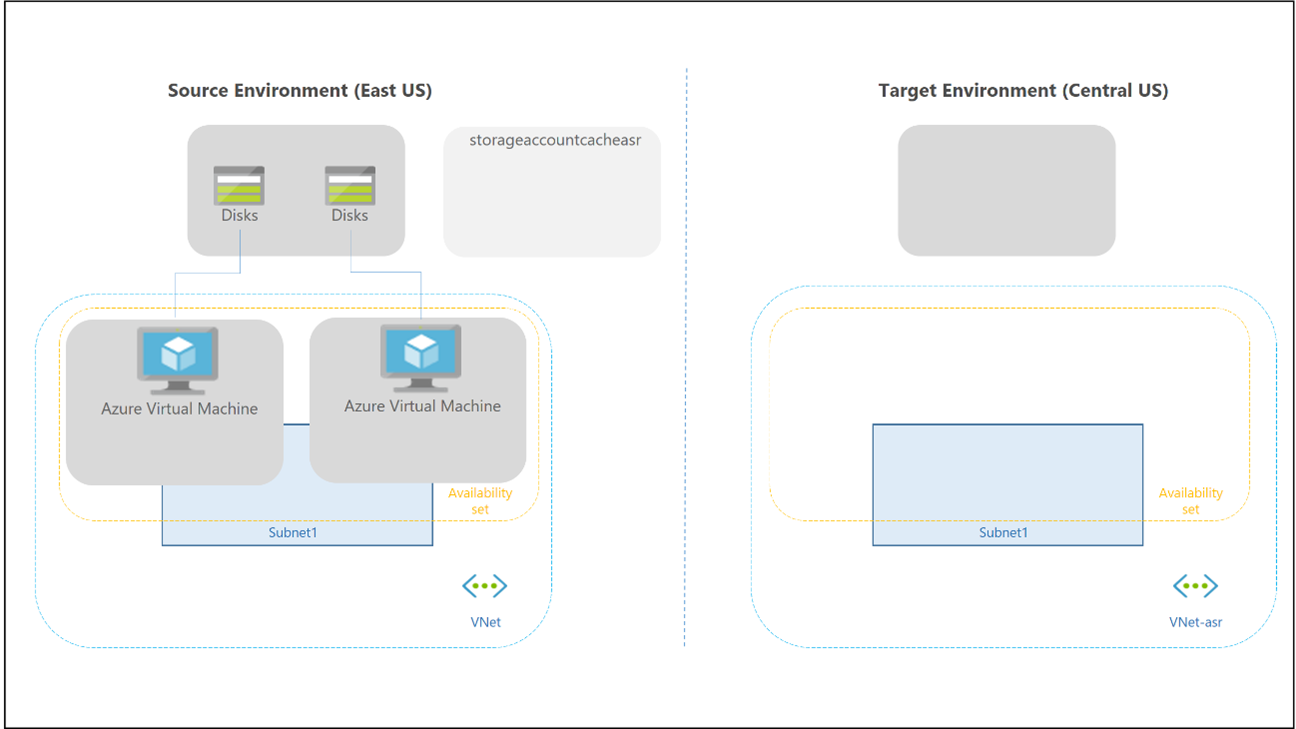
Es gelten die folgenden Überlegungen und Empfehlungen:
- Das Site Recovery-Failover ist nicht automatisch – ein Administrator muss es mithilfe des Azure-Portals oder Powershell/API auslösen.
- Sie können die gesamte Site Recovery-Konfiguration und -Vorgänge mithilfe von PowerShell skripten und automatisieren.
- Site Recovery verfügt über ein deklariertes RTO in seiner Vereinbarung zum Servicelevel (Service Level Agreement, SLA). In den meisten Fällen erfolgt ein Failover der VMs durch Site Recovery innerhalb weniger Minuten.
- Sie können Site Recovery mit Azure Backup verwenden. Weitere Informationen finden Sie unter Unterstützung für die Verwendung von Site Recovery mit Azure Backup.
- Sie müssen Site Recovery auf VM-Ebene aktivieren, da keine direkte Integration in die Virtual Desktop-Portalumgebung vorhanden ist. Sie müssen auch Failover und Failback auf einzelner VM-Ebene auslösen.
- Site Recovery stellt Test-Failover-Funktionen in einem separaten Subnetz für allgemeine Azure-VMs bereit. Verwenden Sie dieses Funktion nicht für Virtual Desktop-VMs, da Sie zwei identische Virtual Desktop-Sitzungshosts haben, die gleichzeitig den Dienststeuerbereich aufrufen.
- Site Recovery verwaltet während der Replikation keine Erweiterungen von virtuellen Computern. Wenn Sie benutzerdefinierte Erweiterungen für Virtual Desktop-Sitzungshost-VMs aktivieren, müssen Sie die Erweiterungen nach einem Failover oder Failback erneut aktivieren. Die integrierten Virtual Desktop-Erweiterungen joindomain und Microsoft.PowerShell.DSC werden nur verwendet, wenn ein Sitzungshost-VM erstellt wird. Erst nach einem ersten Failover können sie getrost verloren gehen.
- Überprüfen Sie unbedingt die Supportmatrix für die Azure-VM-Notfallwiederherstellung zwischen Azure-Regionen und überprüfen Sie Anforderungen, Einschränkungen und die Kompatibilitätsmatrix für das Szenario „Site Recovery Azure-zu-Azure-Notfallwiederherstellung“, insbesondere die unterstützten Betriebssystemversionen.
- Wenn Sie ein Failover für VMs von einer Region in eine andere ausführen, werden die VMs in der Zielregion für die Notfallwiederherstellung in einem ungeschützten Zustand gestartet. Das Failback ist möglich, aber der Benutzer muss VMs in der sekundären Region erneut schützen und dann die Replikation wieder in der primären Region aktivieren.
- Führen Sie regelmäßige Tests von Failover- und Failbackprozeduren aus. Dokumentieren Sie dann eine genaue Liste der Schritte und Wiederherstellungsaktionen basierend auf Ihrer spezifischen Virtual Desktop-Umgebung.
Szenario für gepoolte Hostpools
Eines der gewünschten Merkmale eines Aktiv-Aktiv-Notfallwiederherstellungsmodells besteht darin, dass kein Eingreifen des Administrators erforderlich ist, um den Dienst wiederherzustellen, wenn ein Ausfall vorliegt. Failoverprozeduren sollten nur in einer Aktiv-Passiv-Architektur erforderlich sein.
In einem Aktiv-Passiv-Modell sollte die sekundäre Notfallwiederherstellungsregion leer sein, wobei minimale Ressourcen konfiguriert und aktiv sind. Die Konfiguration sollte an der primären Region ausgerichtet bleiben. Wenn ein Failover stattfindet, werden alle Benutzer allen Desktop- und Anwendungsgruppen für Remote-Apps im sekundären Notfallwiederherstellungs-Hostpool gleichzeitig neu zugewiesen.
Es ist möglich, über ein Aktiv-Aktiv-Modell und ein partielles Failover zu verfügen. Wenn der Hostpool nur zum Bereitstellen von Desktop- und Anwendungsgruppen verwendet wird, können Sie die Benutzer in mehreren nicht überlappende Active Directory-Gruppen partitionieren und die Gruppe in den primären oder sekundären Notfallwiederherstellungs-Hostpools neu zuweisen. Ein Benutzer sollte nicht gleichzeitig auf beide Hostpools zugreifen können. Wenn mehrere Anwendungsgruppen und Anwendungen vorhanden sind, können sich die Benutzergruppen, die Sie zum Zuweisen von Benutzern verwenden, überlappen. In diesem Fall ist es schwierig, eine Aktiv-Aktiv-Strategie zu implementieren. Wenn ein Benutzer eine Remote-App im primären Hostpool startet, wird das Benutzerprofil von FSLogix auf einem Sitzungshost-VM geladen. Der Versuch, denselben Vorgang im sekundären Hostpool auszuführen, kann zu einem Konflikt auf dem zugrunde liegenden Profildatenträger führen.
Warnung
Standardmäßig verbieten FSLogix-Registrierungseinstellungen den gleichzeitigen Zugriff auf dasselbe Benutzerprofil aus mehreren Sitzungen. In diesem BCDR-Szenario sollten Sie dieses Verhalten nicht ändern und einen Wert von 0 für den Registrierungsschlüssel ProfileType hinterlassen.
Hier sind die Ausgangssituation und die Konfigurationsannahmen:
- Die Hostpools in der primären Region und sekundären Notfallwiederherstellungsregionen werden während der Konfiguration ausgerichtet, einschließlich Cloud Cache.
- In den Hostpools werden Benutzern sowohl DAG1-Desktop- als auch APPG2- und APPG3-App-Anwendungsgruppen angeboten.
- Im Hostpool in der primären Region werden die Active Directory-Benutzergruppen GRP1, GRP2 und GRP3 verwendet, um Benutzern DAG1, APPG2 und APPG3 zuzuweisen. Diese Gruppen haben möglicherweise überlappende Benutzermitgliedschaften, aber da das Modell hier Aktiv-Passiv mit vollständigem Failover verwendet, ist es kein Problem.
In den folgenden Schritten wird beschrieben, wann nach einer geplanten oder nicht geplanten Notfallwiederherstellung ein Failover erfolgt.
- Entfernen Sie im primären Hostpool die Benutzerzuweisungen von den Gruppen GRP1, GRP2 und GRP3 für die Anwendungsgruppen DAG1, APPG2 und APPG3.
- Es gibt eine erzwungene Trennung für alle verbundenen Benutzer vom primären Hostpool.
- Im sekundären Hostpool, in dem dieselben Anwendungsgruppen konfiguriert sind, müssen Sie Benutzern Zugriff auf DAG1, APPG2 und APPG3 mithilfe der Gruppen GRP1, GRP2 und GRP3 gewähren.
- Überprüfen Sie die Kapazität des Hostpools in der sekundären Region und passen Sie sie an. Hier sollten Sie sich möglicherweise auf einen Plan für die Autoskalierung stützen, um Sitzungshosts automatisch zu aktivieren. Sie können die erforderlichen Ressourcen auch manuell starten.
Die Failback-Schritte und der Ablauf sind ähnlich, und Sie können den gesamten Prozess mehrmals ausführen. Cloud Cache und das Konfigurieren der Speicherkonten stellen sicher, dass Profil- und Office-Container-Daten repliziert werden. Stellen Sie vor dem Failback sicher, dass die Hostpoolkonfiguration und die Computeressourcen wiederhergestellt werden. Bei einem Datenverlust des Speicherteils in der primären Region repliziert Cloud Cache die Profil- und Office-Containerdaten aus dem Speicher der sekundären Region.
Es ist auch möglich, einen Test-Failoverplan mit einigen Konfigurationsänderungen zu implementieren, ohne die Produktionsumgebung zu beeinträchtigen.
- Erstellen Sie einige neue Benutzerkonten in Active Directory für die Produktion.
- Erstellen Sie eine neue Active Directory-Gruppe namens GRP-TEST und weisen Sie Benutzer zu.
- Weisen Sie mithilfe der GRP-TEST-Gruppe Zugriff auf DAG1, APPG2 und APPG3 zu.
- Geben Sie Benutzern in der GRP-TEST-Gruppe Anweisungen zum Testen von Anwendungen.
- Testen Sie die Failoverprozedur mithilfe der GRP-TEST-Gruppe, um den Zugriff vom primären Hostpool zu entfernen und den Zugriff auf den sekundären Notfallwiederherstellungspool zu gewähren.
Wichtige Empfehlungen
- Automatisieren Sie den Failoverprozess mithilfe von PowerShell, mithilfe der Azure CLI oder mithilfe einer anderen verfügbaren API oder einem anderen verfügbaren Tool.
- Testen Sie die gesamte Failover- und Failbackprozedur regelmäßig.
- Führen Sie eine regelmäßige Überprüfung der Konfigurationsausrichtung aus, um sicherzustellen, dass Hostpools in der primären und sekundären Notfallregion synchronisiert sind.
Backup
Eine Annahme in diesem Leitfaden besteht darin, dass Profilteilung und Datentrennung zwischen Profil-Containern und Office-Containern vorhanden ist. FSLogix ermöglicht diese Konfiguration und die Verwendung separater Speicherkonten. Sobald sie in separaten Speicherkonten sind, können Sie verschiedene Sicherungsrichtlinien verwenden.
Wenn der Inhalt für ODFC-Container nur zwischengespeicherte Daten darstellt, die aus einem Onlinedatenspeicher wie Microsoft 365 neu erstellt werden können, ist es nicht erforderlich, Daten zu sichern.
Wenn es erforderlich ist, Office-Containerdaten zu sichern, können Sie einen preiswerteren Speicher oder eine andere Sicherungshäufigkeit und Aufbewahrungsfrist verwenden.
Für einen persönlichen Hostpooltyp sollten Sie die Sicherung auf der VM-Ebene des Sitzungshosts ausführen. Diese Methode gilt nur, wenn die Daten lokal gespeichert werden.
Wenn Sie OneDrive und eine bekannte Ordnerumleitung verwenden, wird die Anforderung zum Speichern von Daten im Container möglicherweise ausgeblendet.
Hinweis
Die OneDrive-Sicherung wird in diesem Artikel und Szenario nicht berücksichtigt.
Wenn es keine weiteren Anforderungen gibt, sollte die Sicherung des Speichers in der primären Region ausreichen. Die Sicherung der Notfallwiederherstellungsumgebung wird normalerweise nicht verwendet.
Verwenden Sie für die Azure Files-Freigabe Azure Backup.
- Verwenden Sie für den Resilienztyp den zonenredundanten Speicher, wenn der Sicherungsspeicher für die Sicherung vor Ort oder Region nicht erforderlich ist. Wenn diese Sicherungen erforderlich sind, verwenden Sie den georedundanten Speicher.
Azure NetApp Files bietet eine eigene integrierte Sicherungslösung.
- Stellen Sie sicher, dass Sie die Verfügbarkeit der Regionsfunktionen sowie Anforderungen und Einschränkungen überprüfen.
Die für MSIX verwendeten separaten Speicherkonten sollten ebenfalls durch eine Sicherung abgedeckt werden, wenn die Repositorys der Anwendungspakete nicht einfach wiederhergestellt werden können.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Ben Martin Baur | Cloud Solution Architect
- Igor Pagliai | FastTrack für Azure (FTA) Principal Engineer
Andere Mitwirkende:
- Nelson Del Villar | Cloud Solution Architect, Azure Core Infrastructure
- Jason Martinez | Technical Writer
Nächste Schritte
- Notfallwiederherstellungsplan für Virtual Desktop
- BCDR für Azure Virtual Desktop – Cloud Adoption Framework
- Gewährleisten der Resilienz und Verfügbarkeit mit Cloudcache