Content Pipeline その3 そのカスタマイズ
2009/06/15 追記:XNA 3.1用に書き換えたサンプルを追加しました。
2008/02/22 追記:XNA 2.0のサンプルをここに追加しました。
え~、今回の記事は非常に長く、単に読むだけでも10分程、内容を理解しながらだと30分以上掛かることもあるかもしれないので、暇な時間を見つけて読んでやってください。本当は、数回に分けて書こうと思っていたのですが、一気に読んだ方が理解が深まると思い、一つの長い記事にまとめました。
GSE 1.0 Refreshで追加された新機能として文字列描画がありますが、使用する文字コードをspritefontファイルのCharacterResionsに追加しないといけません。ここにユニコードの文字コード表があり、カタカナやひらがなは簡単に追加できたとしても、漢字にいたってはUnified CJK ideographsという中国、日本、そして韓国で使用されている漢字を合わせた約2万文字もの漢字があります。日本の常用漢字が2千文字程なので10倍もの漢字すべてを追加するのはあまりにも不効率です。
XNAのドキュメントに「How to: Extend the Font Description Processor to Support Additional Characters」というのがあり、ここではmessage.txtというファイル内で使われている文字のフォントを作るカスタムプロセッサが紹介されています。
確かに、このプロセッサを使って任意の文字を表示することはできるのですが、このままゲームで使うのには以下の問題があります。
- テキストファイル名が固定なので、複数のフォントで違ったメッセージを処理させることができない
- テキストデータ自体はコンテントとして処理されないので、実際に表示されるメッセージを用意しないといけない
- 別のメッセージデータを用意した場合、プロセッサ用のテキストファイルと、メッセージデータを同一にしないといけない
- メッセージデータとフォントデータがずれた場合、ミスを自動的に検知する仕組みがない
とくに最後の問題が実際のゲーム製作では厄介で、ミスを起こしやすく、そのミスを発見するのが難しいというのは是非とも避けたい問題です。
そこで、今回は以上の問題を解決して、英数字以外の文字も手軽に表示できるようにするカスタムインポーターとカスタムプロセッサを、コンテント・パイプラインの実際のコーディングの説明を交えて紹介します。
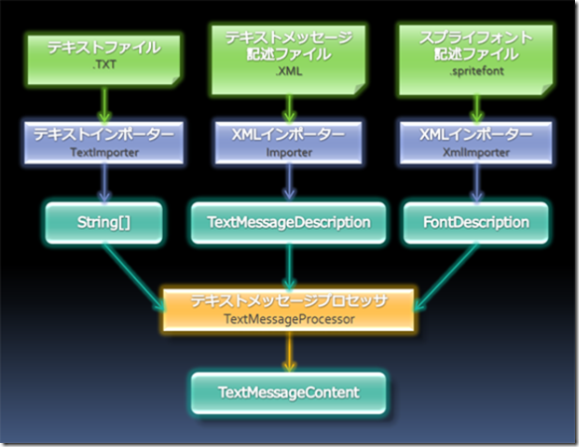
上の図は、今回作るテキストメッセージプロセッサへのコンテントの流れを表しています。要となるのはメッセージテキスト(.txt)と、スプライトフォント記述ファイル(.spritefont)の2つのファイルの関連情報を持つTextMessageDescriptionクラスです。ここに書いてある情報を元に、TextMessageProcessorはメッセージテキスト自体と、そのメッセージで使われているフォントデータを持つSpriteFontContentを生成し、最終結果をTextMessageContentに格納します。
今回は単純にテキストファイルから文字列を読み込む為にテキストインポーターを作りますが、このインポーターを自分のゲームに合ったファイルフォーマットから文字列に変換するインポーターを作るだけで、プロセッサや他のデータ構造を使い回しすることができます。
今回の記事の流れは
- テキストインポーターのコーディング
- XMLインポーターの使い方
- カスタムプロセッサのコーディング
- コンテントタイプライターのコーディング
- タイプリーダーのコーディング
- 作ったカスタムインポーターや、カスタムプロセッサの使い方
- まとめ
と、なっています。
今回の記事の為に書いたサンプルは、記事の一番下にあるTextMessageSample.zipダウンロードできます。WindowsとXbox用の2つのソリューションファイルがあり、実行するにはGSE 1.0 Refreshが必要になります。このサンプルのコードを見ながら、記事を読むとより理解しやすいと思います。サンプルで使っているspritefontは、元の英文を訳してあるので参考になれば幸いです。
まずは、UTF-8形式のテキストファイルから、メッセージテキストをstring[] 形式に読み込むTextImporterを作ります。
カスタムインポーターはContent.Pipeline.ContentImporter<T> ジェネリッククラスから派生させたさせたクラスを宣言し、Content.Pipeline.ContentImpoerterアトリビュートを指定します。ContentImporter<T>には好きな型を指定することができ、ここではstring[] を指定しています。アトリビュートの方にはインポートするファイルの拡張子や、プロパティ編集画面で表示させる文字列を指定することができます。
// インポータークラスには、ContentImporterAttributeを指定する
[ContentImporter(".txt", DisplayName="UTF-8 テキストファイルインポーター")]
public class TextImporter : ContentImporter<string[]>
{
/// <summary>
/// データをファイルから既定のタイプにインポートする。
/// </summary>
/// <param name="filename">インポートするファイル名</param>
/// <param name="context">コンテントインポーターのコンテキスト、ログやファイルの依存関係を指定できる。</param>
/// <returns></returns>
public override string[] Import(string filename, ContentImporterContext context)
実装はImportメソッドをオーバーライドして行います。このメソッドにはインポートするファイル名と、ビルド情報のログ保存の為のLoggerや、AddDependecyメソッドがあるContentImporterContextが渡されます。
Loggerを介して、ビルドログメッセージをビルドウィンドウに表示することができます。通常はLogWarningやLogImportantMessageメソッドを使います。LogMessageを使ったメッセージは、GSEのMSBuildのビルド出力レベルを通常以上に設定しないと表示されません。この出力詳細変更はGSEのツール/オプションメニューを選択してオプションダイアログを表示し、プロジェクトおよびソリューション/ビルド/実行タブ内のMSBuildプロジェクト ビルドの出力の詳細のコンボボックスからできます。
インポートするファイルは、他のファイルを参照している場合がありますが、その時にはContentImporterContext.AddDependencyメソッドを使います。これはインポートするファイルAがBファイルを参照していて、Bファイルを変更した時にAをインポートし直す必要がある場合、このファイル間の依存関係をコンテント・パイプラインに伝える役目をするのがAddDependencyメソッドです。
インポーター内の実装は、単にテキストファイルからの読み込みをしているだけなので、ここでの説明は割愛します。
次に、テキストファイルとスプライトフォントファイルを関連づけるためのTextMessageDescriptionクラスを書きます。
/// <summary>
/// テキストメッセージ記述クラス。使うフォントとメッセージファイルを指定する。
/// </summary>
public class TextMessageDescription
{
/// <summary>
/// SpriteFontファイルへの外部参照
/// </summary>
public ExternalReference<FontDescription> FontDescription;
/// <summary>
/// テキストファイルの外部参照
/// </summary>
public ExternalReference<string[]> Message;
/// <summary>
/// メッセージをTextMessageContentに格納するかの指定フラグ。
/// これはテキストファイルがソースコード自体や、リソースファイル
/// だった時などにメッセージデータが重複するのを防ぐため。
/// </summary>
public bool DiscardMessage;
}
ここでは、テキストファイルとスプライトフォントファイルを外部参照するために、ExternalReference<T> クラスを使っています。単純にファイル名を指定するという手もあるのですが、その場合はプロセッサ内でAddDependencyを使ってファイルの依存関係を手作業で指定する必要があり、前述のミスしやすく、原因特定に時間が掛かってしまうという問題が起きる可能性があるのでExternalReference<T> を使っています。
こういったシンプルなデータを扱う場合、コンテント・パイプラインで用意されているXMLインポーターがあるので、XMLファイル形式にした方が便利です。
ただ、このデータ構造を表すXMLファイルを何も無いところから書くのは大変なので、雛形となるXMLファイルを生成するTestWriteというメソッドを追加してあります。
public static void TestWrite( string filename )
{
// 仮データの生成
TextMessageDescription obj = new TextMessageDescription();
obj.FontDescription = new ExternalReference<FontDescription>("MyFont.spritefont");
obj.Message = new ExternalReference<string[]>("Message.txt");
obj.DiscardMessage = false;
// シリアライズする
using ( XmlWriter writer = XmlWriter.Create( filename ) )
{
IntermediateSerializer.Serialize<TextMessageDescription>(writer, obj, ".");
}
}
XMLインポーターの実装はContent.Pipeline.Serialization.Intermediate.IntermediateSerializeクラスのDeserialize<T> メソッドを使ってXMLファイルからのデータ読み込みをしています。ですから、ここではSerialize<T> メソッドを使って雛形のXMLファイルを作っています。IntermediateSerializeクラスの詳細説明は次の機会にしますので、ここでは使い方だけを述べるに留めます。この雛形XMLファイルを編集するわけですが、場合によっては出力したXMLファイルがとてつもなく長い一行のファイルになることがあります。この場合、メニューから、編集/詳細/ドキュメントのフォーマットを選択することで、読みやすくなります。
殆どのパラメーターの場合、
<パラメーター名>false</パラメーター名>
のように、直感的に判りやすいのですが、ExternalReferenceの場合はAssetエレメントの中で
<パラメーター名>
<Reference>#External1</Reference>
</パラメーター名>
のように、#External1, #External2, .... #Extenrnal nというXMLファイル内でのローカル名を指していて、ファイル後部のExternalReferencesエレメント内に実際の外部参照情報が以下のように記述されるようになっています。
<ExternalReferences>
<ExternalReference ID="#External1" TargetType="Microsoft.Xna.Framework.Content.Pipeline.Graphics.FontDescription">MyFont.spritefont</ExternalReference>
<ExternalReference ID="#External2" TargetType="string[]">Message.txt</ExternalReference>
</ExternalReferences>
このようなデータフォーマットになっている理由として、3Dモデルのデータファイルなどで、テクスチャファイルを外部参照とする時に同じテクスチャを複数回参照することが多く、参照の度に型情報や、ファイル名を指定する冗長さを軽減するという目的があります。また、ユニークな外部参照リストをまとめておくことで、複雑なデータ構造内を巡回することなく、すぐにファイルの依存関係を調べることができるのでビルド時間の短縮にもなります。
次にTextMessageDescriptionからTextMessageContentに変換するTextMessageProcessorを作ります。
/// <summary>
/// TextMessageDescriptionからTextMessageContentに変換するプロセッサ
/// </summary>
// プロセッサクラスには、ContentProcessorAttributeを指定する
[ContentProcessor(DisplayName = "テキストメッセージプロセッサ")]
class TextMessageProcessor : ContentProcessor<TextMessageDescription, TextMessageContent>
{
public override TextMessageContent Process(TextMessageDescription input, ContentProcessorContext context)
}
カスタムプロセッサはContentProcessor<TInput,TOutput> ジェネリッククラスから派生させ、ContentProcessorアトリビュートを記述し、Processメソッドをオーバーライドします。TInput型からTOutput型に変換するのがプロセッサの役割です。
ExternalReference自体には、インポーターやプロセッサといったコンテントを処理するために必要な情報を持っておらず、コンテント・パイプラインはビルド時に、ExternalReferenceのファイル拡張子と、変換する型情報から、インポーターとプロセッサの組み合わせを推測して処理します。ですから、3Dモデルデータや、テクスチャデータといったコンテントを外部参照している場合は、何もしなくてもコンテントは正しくビルドされます。
それ以外のコンテントを扱う場合には、Processメソッドに渡されるContentProcessorContextにあるBuildAsset<TInput,TOutput> メソッドにインポーターとプロセッサを直接指定することができます。また、インポート後のデータや、プロセッサを通した後のデータを使いたい場合にはBuildAndLoadAsset<TInput,TOutput> メソッドを使います。
FontDescription fontDescription = context.BuildAndLoadAsset<FontDescription, FontDescription>(input.FontDescription, null);
string[] messageSource = context.BuildAndLoadAsset<string[], string[]>(input.Message, null);
ここでは、フォントとテキストメッセージのインポート後のデータが欲しいので、BuildAndLoadAssetメソッドのprocessorName引数にnullを指定することで、プロセッサを通す前のデータを取得します。
FontDescriptionには、変換する文字コードを保持するFontDescription.Charactersプロパティがあります。ここに変換したい文字コードを追加します。ここではmessageSourceに読み込んだ文字列に使っている文字コード(Unicode)をFontDescription.Charactersに追加します。
FontDescription.CharactersはIList<char> 型ですが、重複した文字コードがリスト内に存在しないように実装されています。例えば "あ" という文字コードをAddメソッドを使って複数回追加しても、リストの中身には "あ" の文字コードはひとつだけしか存在しません。ですから、文字コードを追加するコードは以下のようにシンプルなものになっています。
foreach (string line in messageSource)
{
foreach (char c in line)
{
fontDescription.Characters.Add(c);
}
}
次に、このプロセッサの出力型であるTextMessageContentへ必要な情報を格納します。TextMessageContentは以下のようになっています。
public class TextMessageContent
{
/// <summary>
/// スプライトフォントコンテント
/// </summary>
public SpriteFontContent Font;
/// <summary>
/// メッセージ配列
/// </summary>
public string[] Message;
}
まずはFontDescriptionから、SpriteFontContentへ変換するのにContent.Pipeline.Processors.FontDescriptionProcessorを使います。 FontDescriptionProcessorは他のクラスへの依存性が無いので、以下のコードのようにデフォルトコンストラクタを使ってインスタンスを作り、Processメソッドを呼ぶだけでコンテントのデータ変換をすることができます。
TextMessageContent outContent = new TextMessageContent();
FontDescriptionProcessor processor = new FontDescriptionProcessor();
outContent.Font = processor.Process(fontDescription, context);
XNAで最初から使えるプロセッサは全てContent.Piepline.Processors名前空間の中にあり、EffectProcessor、FontTextureProcessor、MaterialProcessor、ModelProcessor、ModelTextureProcessor、SprteTextureProcessor、そしてTextureProcessorがあります。これらのプロセッサはFontDescriptionProcessorと同じように、自分で作ったプロセッサ内から自由に使うことができます。
そして最後に、メッセージテキスト自体は以下のコードのように変換します。
if (!input.DiscardMessage)
outContent.Message = ProcessMessage(messageSource);
ProcessMessageメソッド内では、テキストインポーターで読み込んだテキストを、空白行を区切りとした複数行のメッセージに変換しています。ゲームによって、テキストメッセージの扱いは色々とあるので、この部分を自分のゲームにあった処理方法に変えるといいでしょう。
コンテントビルドの最終プロセスとして、プロセッサから出力されたデータをXNBファイルに書き出す必要があります。この役割を果たすのが、コンテント・タイプライター(ContentTypeWriter)で、この記事では以後、単にタイプライターと呼ぶことにします。XNAには、あらかじめ以下の型のタイプライターが用意されています。
| コンテント・パイプラインで 使われるもの | XNAの基本型 | .Net 基本型 | ジェネリック型 |
BasicMaterialContent EffectMaterialContent CompiledEffect ExternalReference IndexCollection ModelContent SpriteFontContent Texture2DContent Texture3DContent TextureCubeContent VertexBufferContent VertexElement[] |
BoundingBox BoundingFrustum BoundingSphere Curve Color Vector2 Vector3 Vector4 Matrix Plane Point Quaternion Ray Rectangle |
bool char string sbyte byte short ushort int uint long ulong float double DateTime TimeSpan Decimal Enum型 |
T[] List<T> Dictionary<Key,Value> Nullable<T> |
ジェネリック型のタイプライターがあるので、例えばstring[] や、Dicrionary<int,string> 、List<float> のようなものは、独自のタイプライター書かなくても済みます。データを書き出すのに必要なタイプライターが無かった場合は「Unsupported type. Cannot find a ContentTypeWriter implementation for 書き出そうとした型.」というエラーメッセージがビルド時に表示されます。
今回のサンプルではTextMessageContentという型を作ったので、このデータを書き出すタイプライターを実装する必要があります。
[ContentTypeWriter]
public class TextMessageContentWriter : ContentTypeWriter<TextMessageContent>
{
protected override void Write(ContentWriter output, TextMessageContent value)
{
output.WriteObject<SpriteFontContent>(value.Font);
output.WriteObject<string[]>(value.Message);
}
}
カスタムタイプライターを作るにはContentTypeWriter<T> ジェネリッククラスから派生させ、ContentTypeWriterアトリビュートを記述し、WriteとGetRuntimeReaderメソッドをオーバーライドします。
WriteメソッドにはContentWriterと、書き込むデータが渡されます。ContentWriterにはデータを書き込む為に以下のメソッドが用意されています。
| メソッド名 | 役割 |
Write |
.NetとXNAの基本タイプを書き出す |
WriteObject<T> |
カスタムタイプライターが必要なオブジェクトはこのメソッドを使う。 |
WriteSharedObject<T> |
XNBファイル内で共有されたデータの書き出し |
WriteExternalReference<T> |
外部参照の書き出し |
WriteRawObject<T> |
指定したTypeWriterを使ってデータを書き出す |
WriteObject<T>を使う場合、XNBファイルには書き込む型情報も保存されるので、floatやint型のような単純なデータを書き込むにはWriteを使った方がXNBファイルサイズを小さくする事ができます。
GetRuntimeReaderメソッドでは、ランタイム時にデータを読み込む為に使うタイプリーダー(TypeReader)の型を文字列で返します。ここでの型情報は、通常、 "フルネームスペース,アセンブリ名" といった形式の文字列を返します。
public override string GetRuntimeReader(Microsoft.Xna.Framework.TargetPlatform targetPlatform)
{
return "Sample.Runtime.TextMessageReader,Sample.Runtime";
}
実は、これがゲーム本体とコンテント・パイプライン用以外にランタイム用のプロジェクトを持つ最大の理由になります。タイプリーダーはゲーム本体のプロジェクトで定義できるのですが、その場合はGetRuntimeReaderメソッドはゲーム本体のアセンブリ名を書くことになります。これでは、ゲーム毎にこのコードを変更しないといけないので、非常に不便になってしまいます。ですから、今回のサンプルのようにコンテント・パイプライン用、ランタイムライブラリ用、そしてゲーム本体の3つのプロジェクトを作った方が、コードを変更することなく、他のゲームでも簡単に使えるようになるわけです。
ここまででオフラインプロセス部分が終わりました。最後にランタイム側のコーディングですが、ここではTextMessageContentWriterで書き込んだデータを読み込むTextMessageReaderを実装するだけです。ここで読み込むデータはTextMessageクラスとして宣言します。
public class TextMessage
{
public SpriteFont Font;
public string[] Message;
}
メッセージはstring[]のままですが、タイプライターで書き出したデータは、ランタイム時にはSpriteFontとなります。タイプリーダーの実装は、ContentTypeReader<T> クラスから派生させたクラスを書き、Readメソッドをオーバーライドするだけです。インポーターや、プロセッサ、タイプライターと違って、ここではアトリビュートを指定する必要がありません。なぜなら、GetRuntimeReaderメソッドで返したタイプリーダーの型情報がXNBファイルに書き込まれているからです。
public class TextMessageReader : ContentTypeReader<TextMessage>
{
protected override TextMessage Read(ContentReader input, TextMessage existingInstance)
{
TextMessage textMessage = new TextMessage();
textMessage.Font = input.ReadObject<SpriteFont>();
textMessage.Message = input.ReadObject<string[]>();
return textMessage;
}
}
Readメソッドに渡されるContentReaderクラスにはXNBファイルからデータを読み込む為のメソッドがあります。このメソッドはContentTypeWriterにあるメソッドと対になっているものが殆どですが、Writeメソッドで書き込んだデータを読み込むには、ReadSingleやReadVector3といった "Read+書き込んだデータ型" のメソッドを使う必要があります。
さて、これで日本語のテキストメッセージをゲーム上で表示する準備ができました。次に実際に使うわけですが、まずは作ったアセットを使いたいプロジェクト、ここではSmpaleWinまたはSampleXboxプロジェクトのプロパティ画面、Content Pipelineタブ画面で "Add" ボタンを押し、作ったパイプライン用のアセンブリを追加します。追加した直後から、プロジェクト内のファイルのプロパティ画面でContent Importer、Content Processorの項目に追加したプロセッサやインポータが表示されるので、使いたいものを選択します。このサンプルでは "テキストメッセージプロセッサ" と、 "UTF-8 テキストファイルインポーター" の二つが表示されるようになります。
サンプルプロジェクト内には、Contentフォルダがあり、その下にMessageFont.spritefont、MessageText.txt、SampleMessage.xmlが表示されています。ですが実際にXNAコンテントとして追加されている(XNA Framework Contentがtrueになっている)のはSampleMessage.xmlだけです。これは、プロセッサ内でメッセージテキストや、フォントデータをTextMessageContentに直接格納しているからです。
SampleMessage.xml以外はXNAコンテントになっていませんが、ExternalReferenceを使ってのファイル依存関係にあるので、MessageText.txtファイルを編集した後に実行すると、自動的にビルドします。UTF-8形式なので、日本語と他言語を自由に混ぜて使うことができ、どの文字コードがサポートされているのか?というのを意識せずにメッセージテキストを書くことができます。

UTF-8でエンコーディングする場合、メモ帳の場合は保存のときに文字コードをUTF-8形式にできます。また、GSE上では保存ダイアログの保存オプション(保存ボタンの右脇についている下向きの三角形部分を押す)から変更することができます。
今回のサンプルではテキストファイルを使いましたが、UTF-8形式のテキストファイルということで、日本語メッセージが書いてあるソースコード自体や、リソースファイルを、そのまま使うということもできます。ここでのポイントは、実際にゲームで使う文字列と、生成されるフォントデータが常に自動的に一致するようにすることで、メッセージデータを変更したけど、フォントデータを作るのを忘れてしまったという、ミスを未然に防ぐことができるということです。
実際に、カスタムインポーターや、カスタムプロセッサの実装コードを見てきて、オフラインプロセスとオンラインプロセス用に書くコード量が極端に違うということに気づいた方もいると思われます。これは、できる限りの処理をオフラインで済ませてしまうことで、ゲーム実行時のアセット読み込みに掛かる処理を軽減することができ、結果的にゲームで遊んでくれる人達が長いローディング画面でやる気がなくなってしまうなんてことが少なくなります。
カスタムインポーターやカスタムプロセッサを作るのは、オフライン用のコードと、オンライン用のコードの間を行ったり来たりして、慣れないうちは大変だと思いますが、以下のポイントを参考にして、いろんなプロセッサや、インポーターを作ってみてはどうでしょうか?
コンテントに対して何らかのデータの処理(変更、追加、削除)をしたい場合はカスタムプロセッサを作る
カスタムプロセッサ内では自由にコンテントを読み込むのはもちろん、コンテントをビルド時に生成したり、他のプロセッサを使うことができる
インポーターは単にファイルからデータを読み込み仕組み
カスタムインポーターを書きたいときは、それがXMLインポーターで実現できるか考慮してみる
新しいデータ型を追加したときには、タイプライターとタイプリーダーを書く
プロジェクトはパイプライン用にひとつ、ランタイム時の型とタイプリーダー用にひとつ、そしてゲーム本体の3つのプロジェクトを作っておく
ランタイムでFooと名づけたデータを扱いたい場合、以下のような名前に統一しておくと判りやすい
- インポーターはFooImporter
- インポートするデータはFooDescription
- プロセッサはFooProcessor
- プロセス後のデータはFooContent
- タイプライターはFooContentWriter
- タイプリーダーはFooReader
ランタイムで、読み込み直後に何らかの処理をしていたら、その処理をコンテントパイプラインに移行できないか考慮する
Anonymous
August 02, 2007
research 研究タイトル 班別ミーティング 画像集 課題 今後の予定 備考 コメント 研究タイトル † 地下鉄の路線情報の可視化に関する研究 ↑班別ミーティング † 主な内容 進捗状況 夏休みの研究計画(やろうと思うこと) アニメ班...Anonymous
February 22, 2008
以前紹介した 英数字以外の文字列表示方法 はコンテントパイプラインの全体の流れを説明するという目的もあったので複雑なつくりになっていました。RPGやテキストベースのアドベンチャーゲームなどの大量のテキストデータを扱う場合は、こういったものは必須になってきますが、今回はXNAAnonymous
February 22, 2008
以前紹介した 英数字以外の文字列表示方法 はコンテントパイプラインの全体の流れを説明するという目的もあったので複雑なつくりになっていました。RPGやテキストベースのアドベンチャーゲームなどの大量のテキストデータを扱う場合はAnonymous
June 15, 2009
コンテントタイプライター/リーダーを書くのは面倒 XNA Game Studioのコンテント・パイプラインでのデータの流れは下図のようになっています。オフラインプロセスは開発しているVisual Studio上でビルドしたときにWindows上で処理されるプロセスで、オフラインプロセスはWindows、Xbox