HPC Server 2008 - was ist das eigentlich?
Nach den drei Artikeln zu meinen konkreten Projekterfahrungen wird es nun langsam Zeit, dass ich ein wenig über HPC Server 2008 schreibe.
Wie ich das schon hier beschrieben habe geht es bei HPC um Clustering für Performance, nicht um Clustering für Verfügbarkeit. Es werden also Computer für schnellere Berechnungen zusammengeschaltet.
Allgemeine Produktinformationen finden sich auf der Produktseite und auf windowshpc.net Die deutsche User Group Seite wird von der RWTH Aachen gehostet.
Was sind für mich nun die Highlights von Windows HPC Server 2008 gegenüber Compute Cluster Server 2003? Hier meine Top 10:
1. Die Möglichkeit, den Head Node (der die Jobverteilung macht) redundant auszulegen
2. Die viel einfachere Konfiguration. Nach der Installation kommt man auf eine ToDo Seite, in der alle Schritte zum Aufbau eines Rechenclusters aufgeführt sind.
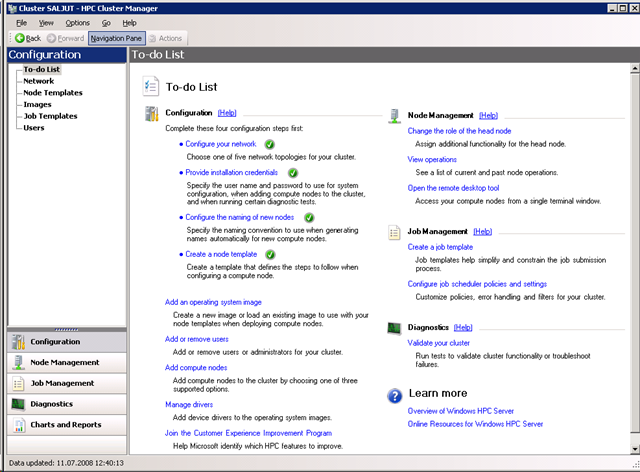
Hier kann man zum Beispiel die komplette Netzwerkkonfiguration für den Cluster einstellen. Dabei werden Firewallregeln, DHCP-Scopes, IP-Adressen und ähnliches an einer einzigen Stelle konfiguriert:
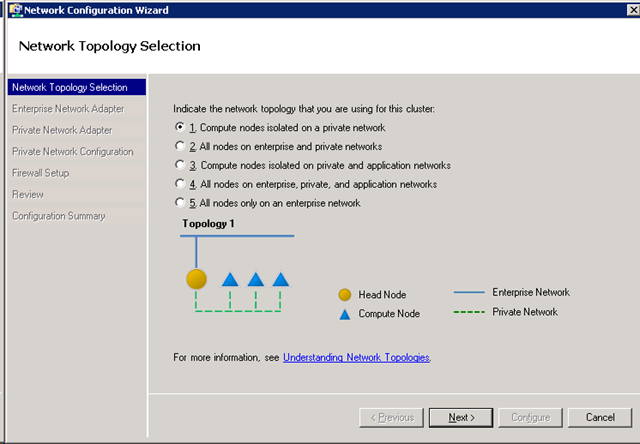
3. Die einfachere Installation von Rechenknoten. In einem Assistenten muss man nur das zu installierende Betriebssystem, die Knotenkonfiguration und ggf. zusätzlich zu installierende Treiber angeben und es wird die gesamte, WDS-basierte automatische Installation der Knoten vorbereitet

Danach braucht man die neuen Knoten nur noch vom Netzwerk (mit PXE) booten, in der Node Management Oberfläche auswählen und nach ca. 1 Stunde hat man einen (oder viele) neue Rechenknoten im Cluster.
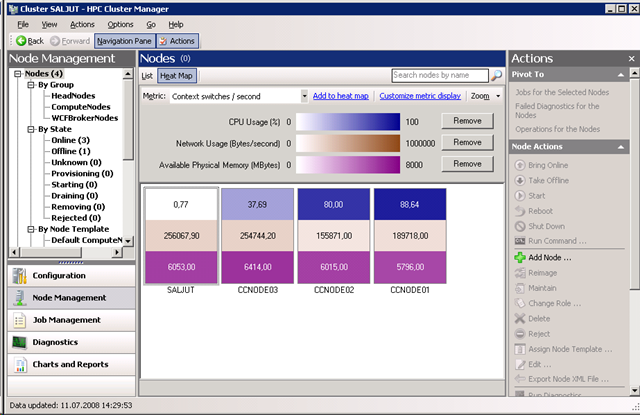
4. Die neue Heat Map zur Überwachung des Clusters. Hier sieht man auf Anhieb, wie beschäftigt der Cluster ist und welche Ressourcen (CPU, Memory, Netzwerk) besonders belastet sind:
5. Die neuen Diagnostic Tests. Mit dieser Diagnose kann man sehr leicht das korrekte Funktionieren des Clusters validieren
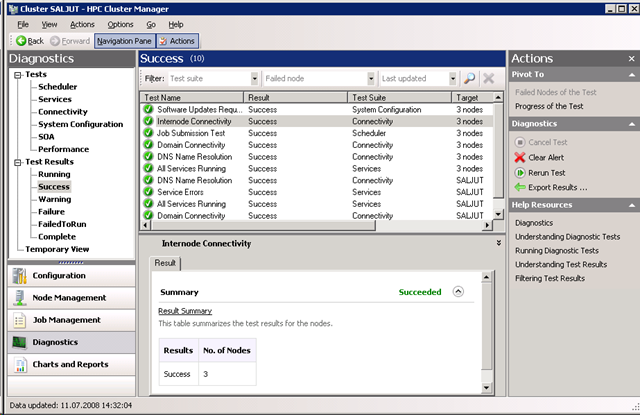
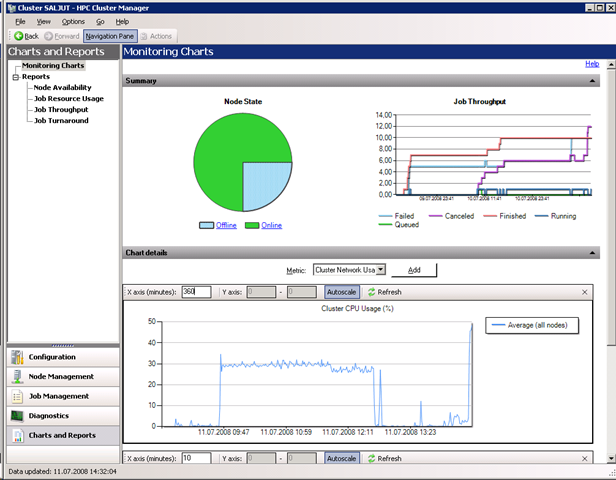
6. Das eingebaute Reporting über die Clusterauslastung und Probleme:
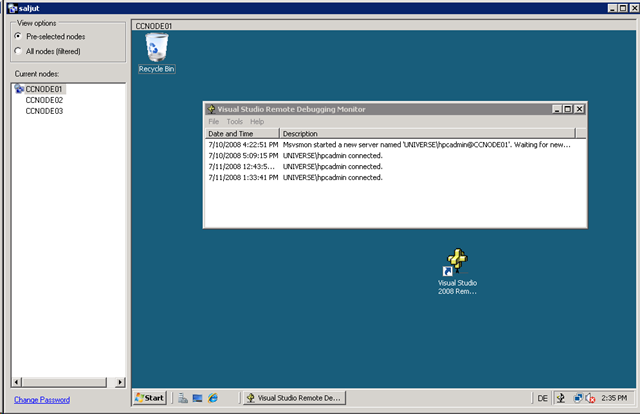
7. Die Möglichkeit, auf mehrere Nodes gleichzeitig Dinge wie Kommandoausführung oder Remote Desktop zu starten:
8. Die neuen High Performance MPI Interfaces. Mit NetworkDirect wird extrem geringe Latenz zwischen den einzelnen Rechenknoten erzielt. Leider gibt es dafür noch keine Treiber für die Broadcom-Netzwerkkarten in den bei hhpberlin verwendeten Servern
9. Die Powershell-Integration
10. Die Integration mit dem Visual Studio MPI Clusterdebugger
Gruß,
Steffen