Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This post is based on a talk Nathan Henderson (@nathos) and I (@wbuchw) gave a few weeks ago. Nathan is Services Principal Engineer at GitHub.
The current state of things (spoiler: git-flow)
In the last few years, a lot of us have chosen Git to handle our version control for a lot of good reasons.
One of them is easy branching: branching in Git is instantaneous, since it is just a diff and not a whole copy, giving us an easy way to isolate our work in progress and to switch between tasks.
But with power, comes responsibility: how to keep this flexibility without creating a total mess? As a team, we need to agree on a common place to store finished work at the very least. This agreement is often called a branching model, or a workflow. Different team will use different branching models, but some are more common than others.
One particular branching model gained a lot of popularity over the years, to the point that it is almost considered a standard. It is commonly referred as git-flow.
Search for "git workflow" and you will most likely end up on this article: "A successful Git branching model".
You might notice something though, this post was written in 2010 and a lot of things happened since then.
Since then, the DevOps culture has gained a lot of adoption and continuous delivery is the new grail.
Companies such as Flickr and ThoughtWorks showed us how integrating and releasing way more often will reduce the pain of... integrating and releasing.
New tools appeared in those 5 years, helping us release software easily. We are now able to do it in a matter of minutes!
Git-flow is actually not well suited to accommodate continuous delivery.
It makes the assumption that every feature branch will be long lived, hence contains a lot of changes. In turn, this means it will take a lot of time integrating a feature branch back into the trunk, so we have a "dev" branch which is used to integrate and make a preliminary QA check.
Since there might be many people merging back their (huge) changes for a single release, creating a release branch is needed before merging back to master where we do another QA round and fix the (hopefully) last bugs.
On top of that, we have hotfix branches, release tags, etc., adding yet another layer of complexity.
[caption id="attachment_1375" align="aligncenter" width="668"]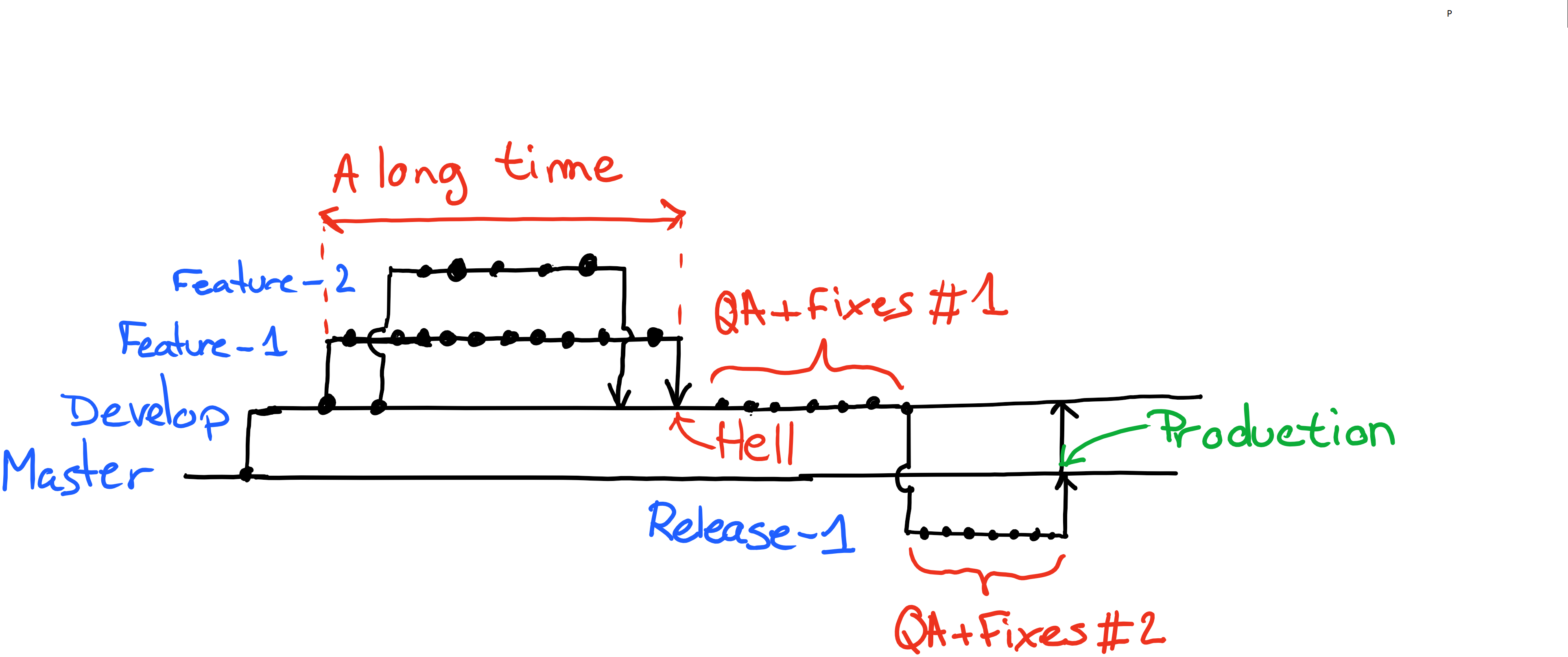 Simplified git-flow representation[/caption]
Simplified git-flow representation[/caption]
Isn't there a better, simpler alternative?
There is and it's actually being used today by companies like GitHub, Microsoft, ThoughtWorks and many others doing CD.
This workflow has different names, but it is mostly known as either GitHub-flow or Trunk Based Development (I'll use GitHub-flow from here). So what is this flow about?
Enter GitHub Flow
GitHub Flow is all about short feedback loops (everything in DevOps mostly is, actually). This means work branches (‘work’ could mean a new feature or a bug fix - there is no distinction) starts from the production code (master) and are short lived - the shorter the better. Merging back becomes a breeze and we are truly continuously integrating. Indeed, if two developers are working in two separate branches for 3 months, they are by definition not continuously integrating their code and will have a lot of fun when it’s merging time :).
That’s pretty much all there is to know about the actual workflow, really.
[caption id="attachment_1335" align="aligncenter" width="580"]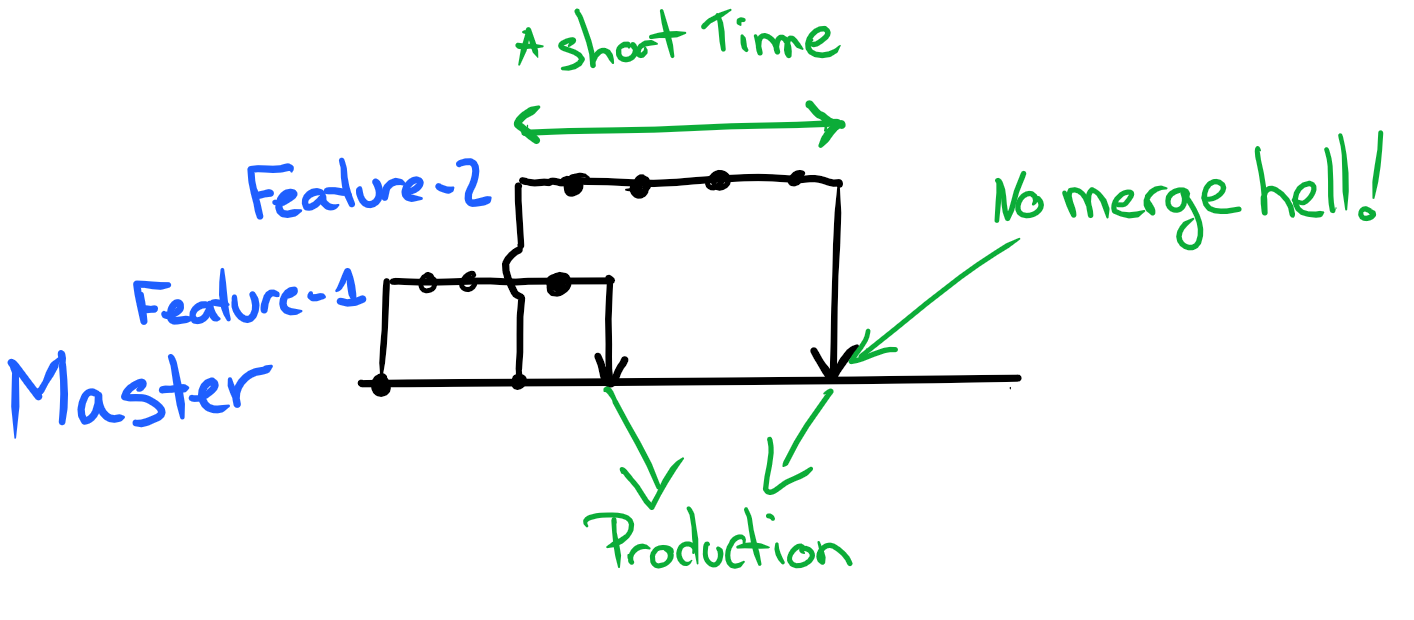 Simplified GitHub Flow[/caption]
Simplified GitHub Flow[/caption]
Collaboration is the other cornerstone of the GitHub Flow. Everyone agrees that code reviews are a good thing, but few will actually do it seriously. In many cases this is simply because it takes too much time: most developers will wait until they think they are done to open a pull request (or Merge Request if you use GitLab). How can we review 3 weeks of changes in a reasonable amount of time? We cannot, so we just skim over the surface and approve 👍 .
A better approach is to open a pull request as early as possible and code in the open, discuss implementation details and architecture choices as you go, tag people that can help you while you’re coding.
This has the side effect of creating a living documentation for you: wondering why someone made a particular decision? Check the discussion in the related pull request.
Of course, you could do that with any flow, it is not something specific to GitHub Flow, but it happens to be a best practice among teams implementing this flow and a smaller change set is always easier to review.
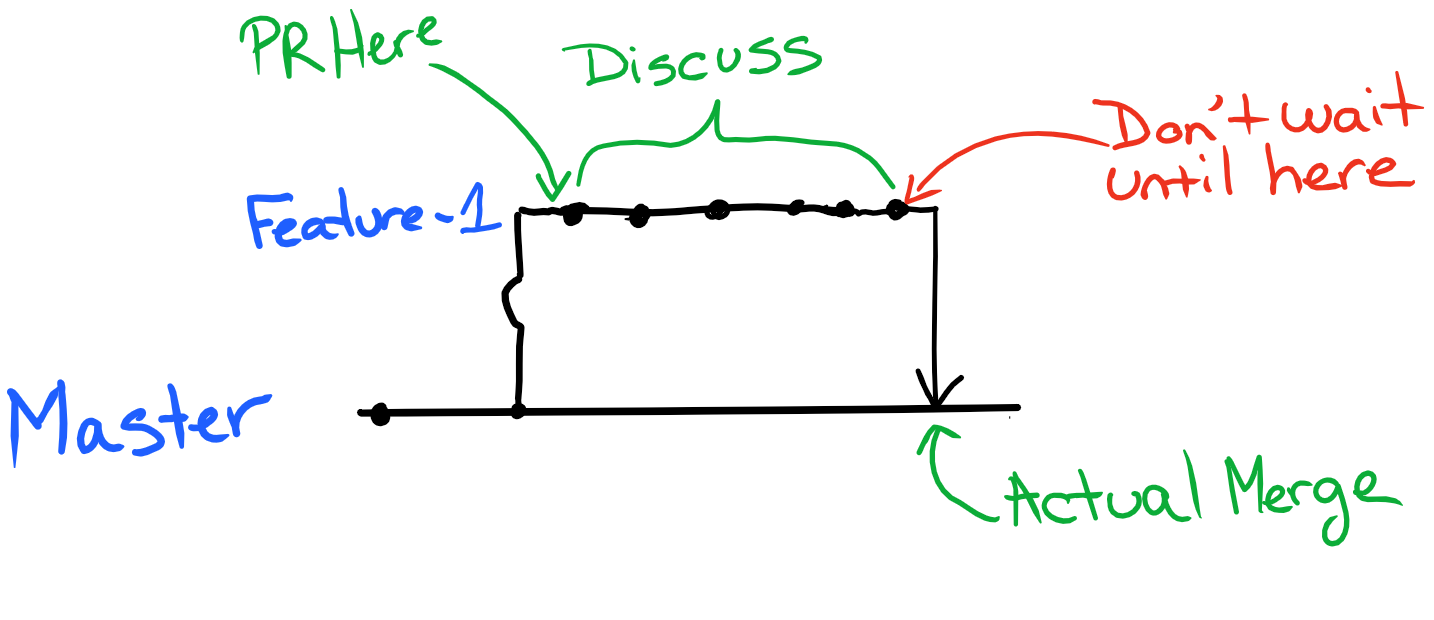
When you're done and the pull request is accepted, your code should be deployed to a production-like environment as soon as possible (production is a good production-like environment ;) ). If anything breaks, it's easier to narrow down an issue in a release where only one or two developers made changes, than in a 100+ commits mess.
Making large-scale changes
Short lived branches and merging into master frequently seems like a good idea, but how can we make major changes to the code base in this context?
- Feature flags: Split your work in smaller self contained changes and release them behind a feature flag. You can still get true CI and fast feedback from a staging environment for example, without exposing your work in progress in production.
- Branch by abstraction: We branch so our modifications are isolated and don't impact others and vice-versa. Developers already have another tool do the job: abstraction. Hide the component you want to refactor behind an interface and incrementally swap the old implementation with the new. You should still be able to release in production at anytime without breaking anything. Here is a nice read on the subject by Martin Fowler.
- Split your work (microservices): This won't apply to most cases, but when creating a new component, ask yourself if you could make it stand alone. A series of smaller and independent components are much easier to change safely.
Short lived branches are something to strive for. They remove a lot of pain from integrating and merging while giving you feedback quickly.
When dealing with messy and highly coupled code though, the cost of doing branching by abstraction may be bigger than the benefits of short lived branches. Like many things, it's a tradeoff. There are some legitimate cases for a long lived branch, but it should remain an exception.
Going One step further
- Deploying before merging: GitHub deploys in production directly from the feature branch and if everything looks good, it is then merged into master. This means that master becomes a record of known good production code.
- Scheduled release: GitHub.com is deployed continuously, but GitHub Enterprise's updates are shipped every few weeks. To achieve that, GitHub creates release branches from master (say release-2.6) and cherry-pick the features they want to ship in that version. No development happens on this release branch.
When GitHub Flow doesn't make sense
GitHub Flow is awesome, but it is not a silver bullet. Trying to implement it before having a reliable test suite and continuous integration in place (at least) will lead to serious quality issues in production.
Let me stress this point: Git-flow is not a bad workflow, but it is not well suited for continuous delivery.
If you still need manual verifications to ensure the quality of your product, then by all means, stay with Git-flow.
Resources
- The excellent "Understanding the GitHub-flow" by GitHub themselves.
- "Enabling Trunk Based Development with Deployment Pipelines" by Vishal Naik from ThoughtWorks
Comments
- Anonymous
September 08, 2016
Many devops Engineer use CloudMunch, It can also plugin various devops templates such as:Mesos Marathon Template Continuous ALM Insights Multiple Containers using Jenkins You can also use built in CloudMunch DevOps TemplatesThere are many Available Free Templates.Even Adobe uses CloudMunch, You can find more about it here http://bit.ly/2buNC7p - Anonymous
November 16, 2016
Thank you for this great article! It really helped us decide, if we should use GitFlow og the GitHub Workflow..(we are now using the latter):-) - Anonymous
June 29, 2017
What if you want to do an hotfix and do not want to deploy the work that was done since the last production deployment?This can happen when you have a release that include multiple features and you want to deploy all or nothing on that release.In the git-flow the code in master is always ready to go to production environment. With Github Workflow you need to pray that none of your colleagues have merged their features to the master branches. - Anonymous
April 23, 2019
I agree that gitflow isn't well suited for continuous delivery, but for different reasons.There are a few things you're misrepresenting about the branching model behind gitflow:"It makes the assumption that every feature branch will be long lived, hence contains a lot of changes."No, it doesn't make any assumptions. Shortlived branches are always good, and this is true in gitflow land as well."In turn, this means it will take a lot of time integrating a feature branch back into the trunk, so we have a “dev” branch which is used to integrate and make a preliminary QA check."Not really. In gitflow, the develop branch is the trunk/mainline. The master branch is only there to represent what is currently in production. The benefit of this is that when you discover a bug in production, you can bypass everything in your trunk and make a small deploy that only fixes the bug.I do agree however that this setup isn't that valuable in a CD world. For example, say that everything in your develop branch gets automatically deployed to a staging environment. From there, when you decide to promote that to production, you just want to push a button (regardless if this is a slot swap à la Azure or any other deploy mechanism). You don't wanna mess about with git and create a release branch and stuff. You do however wanna tag the master branch with the release version generated by your CD system, but that's a technical concern.I'm still looking for a good way to get the benefits of separation between develop and master, but at the same time integrating that into a workflow where the task of deciding "this is now production ready" is not a git-centric action.