Data Points
Efficient Coding With Strongly Typed DataSets
John Papa
Code download available at:DataPoints0412.exe(191 KB)
Contents
The Value of Being Typed
Casting Calls
Derived Classes
Typed DataSets in Enterprise Apps
Important Tidbits
Wrapping Up
Someone once said to me that the hallmark of a good developer is the desire to spend time efficiently. Developers are continually pursuing ways to make coding easier and faster, and to reduce the number of errors. Using strongly typed DataSet objects in ADO.NET can help you do just that.
This month I will discuss the pros and cons of developing a Microsoft® .NET Framework-based application using strongly typed DataSet objects. I will begin by discussing what a typed DataSet is and how it extends the DataSet, DataTable, and DataRow classes. Throughout this installment, I will refer to a sample application which includes the complete code to perform inserts, updates, and deletes on the Orders and Order Details tables of the SQL Server™ Northwind database using strongly typed DataSets. This sample multitier application (which you can downloaded from the link at the top of this article) uses a typed DataSet in several tiers including a class library used as the business logic layer, a Web service, and an ASP.NET Web application. I will wrap up by explaining some of the tips and tricks you can employ when using strongly typed DataSets.
The Value of Being Typed
Remember life before IntelliSense®? Okay, it is not as ground-breaking as the introduction of the Internet, but to a developer like me who is always looking for a faster way to code and an easier way to remember all of the property, method, and event names of an object, IntelliSense has been awesome. One area that hasn't benefited from IntelliSense is the traditional ADO Recordset. For example, in traditional ADO 2.x programming you had to use something like the following Visual Basic® 6.0 code to reference a column's value from a Recordset:
oRecordset.Fields("CompanyName").Value
Of course, to reduce code you could eliminate the Fields collection and the Value property since they are the default properties of their respective objects. However, if you misspell the name of the column, you will not be notified of the error at compile time. Also, if you forget the name of the column altogether, you will have to go back and look at your stored procedure, SQL statement, XML file, or other data source.
Another way to refer to a column in traditional ADO is by its ordinal position, using an index or a custom enumerator. An integer is easiest, but again, you can easily forget which ordinal position the column is in, or even that the columns begin at position 0, resulting in the index being off by one. Using the ordinal position makes readability an issue, too. When you take a look back at your code in a week, month, or year, there is a chance that you may not remember what column 2 represented.
Creating a custom enumerator can help with readability, and it's how I prefer to handle this problem in traditional ADO. However, your columns can still get out of sync if someone changes the order in which the columns are returned to ADO from a stored procedure. All of these are common issues that developers face in traditional ADO programming, and they can happen when using untyped DataSet objects in ADO.NET as well. These are just a few of the problems solved by strongly typed DataSets.
For example, typed DataSets contain additional methods and properties not available to untyped DataSets. Consider the following code snippet to refer to a column in ADO.NET using both typed and untyped DataSets:
//-- Untyped DataSet string sCoName = oDs.Tables["Customers"].Rows[0]["CompanyName"].ToString(); //-- Strongly typed DataSet string sCoName = oDs.Customers[0].CompanyName;
The typed DataSet code is shorter, requires neither the table name nor the column name to be accessed via a string or ordinal position, and it does not require the Rows property. You can use IntelliSense to get a list of the table names available to the typed DataSet as well as a list of the column names available to its tables, so the code is really easy to write. Notice that in the untyped DataSet code, the method ToString must be used to retrieve a string representation of the value contained within the column. In the typed DataSet, the columns are all defined as properties with their respective datatypes. As a case in point, the CompanyName property is defined as a string datatype, which makes the ToString method unnecessary. Typed DataSets make binding to controls easier since they contain the schema information within them. When binding a typed DataSet to an ASP.NET DataGrid, the properties menu reads the selected typed DataSet's schema and recognizes the DataTables and the DataColumns that the typed DataSet exposes. The Properties window fills the DataMember list with the names of the selected DataSet's DataTable objects. Likewise, the list of available fields is loaded into the DataKeyField property (as shown in Figure 1). This feature eliminates the need to write this code and reduces the chance of any misspellings or even the need to remember the names of the tables and columns in the schema (note that you can obtain this same functionality with untyped DataSets if you read the schema into the DataSet with the ReadXmlSchema method). (See the sidebar "Creating a Typed DataSet".)
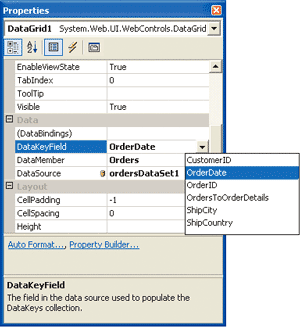
Figure 1** Data Binding Properties **
Casting Calls
Columns of strongly typed DataSet objects are defined as a particular datatype. For example, the OrderDate column in the Northwind database's Orders table is defined as a datetime. A strongly typed DataSet created from the Northwind Orders table would have a datatype of DateTime, respective to its counterpart in the database. This explicit typing of the columns eliminates the need for explicit casting to get values in and out of DataSets, as shown in the previous code example where I retrieved the CompanyName from the Customers DataTable. This feature reduces the amount of code you need to write to get a value out of or into a DataSet. Thus, strongly typed DataSets provide the developer with faster development and fewer runtime errors, since mistakes such as improperly spelled column and field names can easily be caught at compile time.
There are several ways to refer to a DataColumn's value using the various available overloaded methods. Some execute faster than others, while still others are more readable and easier to maintain. There are differences in maintenance and performance when referring to columns in an untyped DataSet. The strongly typed DataSet offers advantages over the untyped DataSet in terms of speed and easy maintainability. The speed in accessing a typed DataSet is comparable to the faster techniques in accessing an untyped DataSet (since a typed DataSet is just a layer over an untyped DataSet) and the readability of the typed DataSet is the best: oDs.Orders[0].OrderDate. The following untyped DataSet techniques have various combinations of convenience and performance. First, you can access the value of a column using a DataColumn instance:
oDs.Tables["Orders"].Rows[0][DataColumn]
This can be the least convenient since you need to get an instance of the DataColumn first. However, it's the fastest to execute. It's a good solution to use if you'll be retrieving the value from multiple rows, as you can get the DataColumn instance once and then use it over and over. You can also access a column using its ordinal position as shown in the following line of code:
oDs.Tables["Orders"].Rows[0][Ordinal]
This can make it difficult to determine what column you are referring to; however, its execution is quite fast. A third option is to use a string and refer to the column by name:
oDs.Tables["Orders"].Rows[0][StringName]
This is more readable and maintainable than ordinal position, but it's the slowest to execute since it has to search for the column by name rather than simply indexing into an array as can be done with the ordinal position option.
Derived Classes
It takes an XML Schema Definition (XSD) file as well as a class file to create a strongly typed DataSet. The XSD file stores the XML that defines the schema for the strongly typed DataSet. Figure 2 shows the diagram view of a typed DataSet that represents an Orders DataTable, an OrderDetails DataTable, and the relationship that links the two tables. The DataSet also depicts the primary keys of the two tables. The schema that defines the typed DataSet is stored in the XSD file. The view shown in Figure 2 is just a visual representation of the XML Schema that defines the strongly typed DataSet. There is also an XML Schema Extended (XSX) file that stores the designer's layout information, which is used to draw the visual representation of the DataSet, like the one shown in Figure 2. (This strongly typed DataSet is used within the sample application that you can download from the MSDN Magazine Web site.)
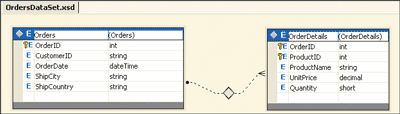
Figure 2** Orders DataSet **
A strongly typed DataSet is actually a class that inherits from the System.Data.DataSet class and adds a few extra features of its own. The class file is generated from the XSD file. You can regenerate the class file by right-clicking in the XSD's designer view and selecting Generate DataSet (alternatively, you can use the xsd.exe command-line utility). The class file actually contains a series of classes that inherit from and extend the DataSet, DataTable, DataRow, and EventArgs classes. Because of this inheritance, developers do not lose any functionality by using a strongly typed DataSet. For example, even though you can refer to a DataTable via a property with the same name as the table, you can still refer to the table through the Tables collection. The following two lines evaluate to the same DataTable object:
oDs.Tables["Orders"] oDs.Orders
The strongly typed DataSet class file contains one class that inherits from the base DataSet. It also contains one class for every DataTable contained within the DataSet. For example, if there are both Orders and OrderDetails DataTables in a strongly typed DataSet, there will be classes called OrdersDataTable and OrderDetailsDataTable that both inherit from the DataTable object. Likewise, there would be classes named OrdersRow and OrderDetailsRow that inherit from DataRow. Because of this inheritance, these classes also expose all of the standard functionality that the base classes expose.Creating a Typed DataSet
You can create strongly typed DataSet objects through drag and drop operations, command-line utilities, and through code. I will not go into much detail on this topic since there are several good references in MSDN that detail how to create a strongly typed DataSet. For example, see MSDN Knowledge Base articles 320714 ("Create and Use a Typed DataSet by Using Visual C# .NET") and 315678 ("Create and Use a Typed DataSet by Using Visual Basic .NET") for samples in both C# and Visual Basic .NET.
There are basically four techniques you can follow to create a strongly typed DataSet:
- Use the Visual Studio® .NET DataAdapter configuration wizard to create a DataAdapter and a Connection; then choose to generate a DataSet from them.
- Create an XML schema file, which can then be used by the XSD.exe command-line utility.
- Use Visual Studio .NET to drag a table, view, or stored procedure from the Server Explorer onto a DataSet designer (XSD file).
- Finally, you can even create one by hand, since it is just XML and .NET code. But obviously the other techniques listed here are much easier.
Strongly typed DataSets also offer a few additional methods to extend the DataSet base class. For example, a typed DataSet based on the Northwind database's Orders table would expose the method FindByOrderID which would accept an integer argument that would locate the DataRow with the corresponding OrderID value. The standard Find method could still be used since all of the base class's method and properties are available, but the extended properties and methods can make writing code a bit easier on developers. Assuming that an instance of the strongly typed DataSet shown in Figure 2 was created, the extended properties and methods would look like those shown in Figure 3.
Figure 3 Extended Properties and Methods
| Extended Method/Property | Description |
|---|---|
| oDs.Orders.AddOrdersRow | Adds an instance of an OrdersRow to the Orders DataTable. Also has an overloaded version that accepts a parameter for each of the columns in the Orders DataTable. |
| oDs.Orders.FindByOrderID | Accepts a value for the primary key field OrderID and then locates and returns an instance of the corresponding OrdersRow. |
| oDs.Orders.NewOrdersRow | Creates an instance of an OrdersRow. |
| oDs.Orders.RemoveOrdersRow | Accepts an instance of an OrdersRow and removes it from the Orders DataTable. |
| oDs.Orders[0].GetOrder- | Retrieves all of the Order- |
| DetailsRows | DetailsRow objects that are children of the 0 row of the Orders DataTable. |
| oDs.Orders[0].IsOrderDateNull | Returns a Boolean value indicating if the OrderDate column of the first OrdersRow of the Orders DataTable is null. |
| oDs.Orders[0].SetOrderDateNull | Sets the OrderDate column of OrdersRow 0 of the Orders DataTable to null. |
| oDs.OrderDetails[0].OrdersRow | Retrieves the OrdersRow that is the parent of OrderDetailsRow 0 of the OrderDetails DataTable. |
Typed DataSets in Enterprise Apps
When working with strongly typed DataSets in multitier applications, it is often necessary that the strongly typed DataSet be available in all (or at least most) of the tiers. Generally, it is a good idea to store the strongly typed DataSet object and its files in the lowest layer. That way, any projects and assemblies that reference that layer can also refer to the strongly typed DataSet. For example let's again refer to the sample application, in which a strongly typed DataSet exists in a class library project (the business logic layer). A Web service project has a reference to that class library project, therefore it also can refer to the strongly typed DataSet contained in the class library project.
I will point out places in the multitier solution where strongly typed DataSets are used and compare them to how they could have been written using untyped DataSets. First, take a look at Figure 4, which shows the code block that adds a new OrderDetailsRow to a strongly typed DataSet. This code block is a sample from the grdOrderDetail_OnItemCommand event from WebForm1.aspx found in the sample application. I highlighted the relevant code that uses the extended methods and properties of the strongly typed DataSet.
Figure 4 Adding an OrderDetailsRow
// Get the values for the new Order row from the footer row's controls int nOrderID_New = Convert.ToInt32(ViewState["nLastOrderID"]); DropDownList lstProductID_New = (DropDownList)e.Item.FindControl( "lstProductID_New"); int nProductID_New = Convert.ToInt32( lstProductID_New.SelectedItem.Value); string sProductName_New = lstProductID_New.SelectedItem.Text; TextBox txtUnitPrice_New = (TextBox)e.Item.FindControl( "txtUnitPrice_New"); Decimal mUnitPrice_New = Convert.ToDecimal(txtUnitPrice_New.Text); TextBox txtQuantity_New = (TextBox)e.Item.FindControl( "txtQuantity_New"); short nQuantity_New = Convert.ToInt16(txtQuantity_New.Text); // Create an Order table DataRow <span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">OrdersDataSet.OrderDetailsRow oRow</span> = oDs.OrderDetails.<span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">NewOrderDetailsRow</span>(); // Set the values for the new row <span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">oRow.OrderID</span> = nOrderID_New; <span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">oRow.ProductID</span> = nProductID_New; <span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">oRow.ProductName</span> = sProductName_New; <span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">oRow.UnitPrice</span> = mUnitPrice_New; <span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">oRow.Quantity</span> = nQuantity_New; // Add the new row to the Orders DataTable oDs.OrderDetails.<span class="clsRed" xmlns="https://www.w3.org/1999/xhtml">AddOrderDetailsRow</span>(oRow); // Store the DataSet Session["oDs"] = oDs; // Bind the DataSet to the Order Details DataGrid BindOrderDetails(nOrderID_New);
As another example, the following code locates an OrderDetailsRow in the typed DataSet. This code can be found in the grdOrderDetail_OnUpdateCommand event in the WebForm1.aspx file:
OrdersDataSet.OrderDetailsRow oRow; oRow = oDs.OrderDetails.FindByOrderIDProductID( nOrderID_OrderDetail, nProductID_Original);
This same code could have been written using an untyped DataSet, as you can see in the following:
DataRow oRow; oRow = oDs.Tables["OrderDetails"].Rows.Find( new object[]{nOrderID_OrderDetail, nProductID_Original});
To demonstrate other differences between the use of a strongly typed DataSet and an untyped DataSet, let's take a look at a few examples not found in the accompanying sample application. For example, if you wanted to check if a column contained a null value, and set it to null if it doesn't, you could use the following code with a strongly typed DataSet:
if(!oDs.Orders[0].IsOrderDateNull()) { oDs.Orders[0].SetOrderDateNull();}
The same task could be accomplished using an untyped DataSet, as shown in the following code:
if(!oDs.Tables["Orders"].Rows[0].IsNull("OrderDate")) { oDs.Tables["Orders"].Rows[0]["OrderDate"] = Convert.DBNull; }
Both of these code blocks will do the job, but the code using the strongly typed DataSet is a bit easier to write and read.
As another example of the differences between writing code with typed and untyped DataSets, I will show how to get all of the child rows of a row in a parent table. First, let's assume that there is a strongly typed DataSet like the one you saw earlier in Figure 2 that represents Orders and OrderDetails DataTable objects. Let's also assume that these are related to one another. If you want to loop through all of the orders and all of their related order details data, you could use the following code block:
foreach(OrdersDataSet.OrdersRow oOrderRow in oDs.Orders) { Debug.WriteLine("OrderID = " + oOrderRow.OrderID); foreach(OrdersDataSet.OrderDetailsRow oOrderDetailRow in oOrderRow.GetOrderDetailsRows()) { Debug.WriteLine(" — " + oOrderDetailRow.ProductName); } }
This code block loops through all of the orders and displays the OrdersRow's OrderID value, then loops through that order's OrderDetailsRow objects, and displays their ProductName values. The same code could be written using an untyped DataSet using the following code block:
foreach(DataRow oOrderRow in oDs.Tables["Orders"].Rows) { Debug.WriteLine("OrderID = " + oOrderRow["OrderID"].ToString()); foreach(DataRow oOrderDetailRow in oOrderRow.GetChildRows("Orders2OrderDetails")) { Debug.WriteLine(" — " + oOrderDetailRow["ProductName"]); } }
This code block exemplifies the fact that the code using the untyped DataSet is not as elegant as the code that was written using the strongly typed DataSet.
Important Tidbits
Keep in mind that when you use a typed DataSet, if the corresponding schema changes in the underlying database table, you will need to synchronize the schema in the typed DataSet. This is not a big deal because when you use an untyped DataSet you would still likely have to change some client code if the underlying schema changes. A huge benefit of a strongly typed DataSet in this scenario, however, is that the compiler will be able to flag most of the necessary changes in the user's code, whereas with an untyped DataSet errors might not be discovered until exceptions are thrown at runtime. In any event, it's worth noting that the typed DataSet needs to stay in sync with the schema.
I find that it is always a good idea to choose the name for your strongly typed DataSet when you create it. If you change the name after you create it, you may want to regenerate the strongly typed DataSet's class file as the classes and methods will not update their names to reflect the new names. And it is generally not a good idea to manually modify the generated class file for a typed DataSet. This code is automatically generated to reflect the schema defined in the XSD. Plus, if you regenerate the typed DataSet's class file, any manual modifications you might have made previously will be lost as the file is overwritten.
There is always an exception to the rule, and the one exception I make to changing the typed DataSet's class file or XSD's XML is when I need the typed DataSets to contain an attribute that I cannot set through the XSD designer. For example, two such properties that I set in the sample application are the AutoIncrementStep and AutoIncrementSeed. I wanted them to begin at -1 and increment by -1. There was no interface in the designer to set these properties, but I could view them. I altered the XSD's XML to include the properties in the second line in the following code:
<xs:element name="OrderID" msdata:ReadOnly="true" msdata:AutoIncrement="true" msdata:AutoIncrementSeed="-1" msdata:AutoIncrementStep="-1" type="xs:int" />
By adding this code to the XSD's XML and then regenerating the class file, my strongly typed DataSet was then able to respond with these auto-incrementing features.
There are also some important things to keep in mind if you are using strongly typed DataSets and Web services. For example, a Web service that uses a DataSet will not expose that DataSet in the autogenerated WSDL unless one of its WebMethod signatures references it in some way.
Wrapping Up
Strongly typed DataSet objects are practically self documenting since they are so easy to read. Because the names of the tables and columns that they represent are properties of the typed DataSet class, writing code with typed DataSets is more intuitive and easier to maintain. By making development time faster, easier, less prone to typing errors, and by making the code more maintainable, strongly typed DataSets are a great help to developers who want to write more effective code more efficiently.
Send your questions and comments for John to mmdata@microsoft.com.
John Papa is a baseball fanatic who spends most of his summer nights rooting for the Yankees with his two little girls, wife, and faithful dog, Kadi. He has authored several books on ADO, XML, and SQL Server and can often be found speaking at industry conferences such as VSLive.