Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Los flujos de datos están disponibles tanto en canalizaciones de Azure Data Factory como en canalizaciones de Azure Synapse Analytics. Este artículo se aplica a los flujos de datos de mapeo. Si no está familiarizado con las transformaciones, consulte el artículo introductorio Transformación de datos mediante flujos de datos de asignación.
Sugerencia
La transformación Assert no se admite actualmente en Dataflow Gen2. Para obtener una lista de las transformaciones admitidas y sus equivalentes, consulte Una guía de Dataflow Gen2 para asignar usuarios de flujo de datos.
La transformación Assert permite crear reglas personalizadas dentro de los flujos de datos de mapeo para evaluar la calidad de los datos y validarlos. Puede crear reglas que determinen si los valores cumplen un dominio de valor esperado. Además, puede crear reglas que comprueben la unidad de fila. La transformación de aserción le ayudará a determinar si cada fila de los datos cumple un conjunto de criterios. La transformación de aserción también permite establecer mensajes de error personalizados cuando no se cumplen las reglas de validación de datos.
Configuración
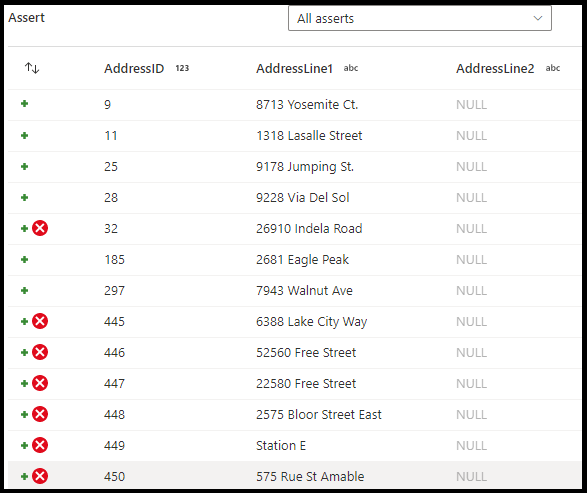
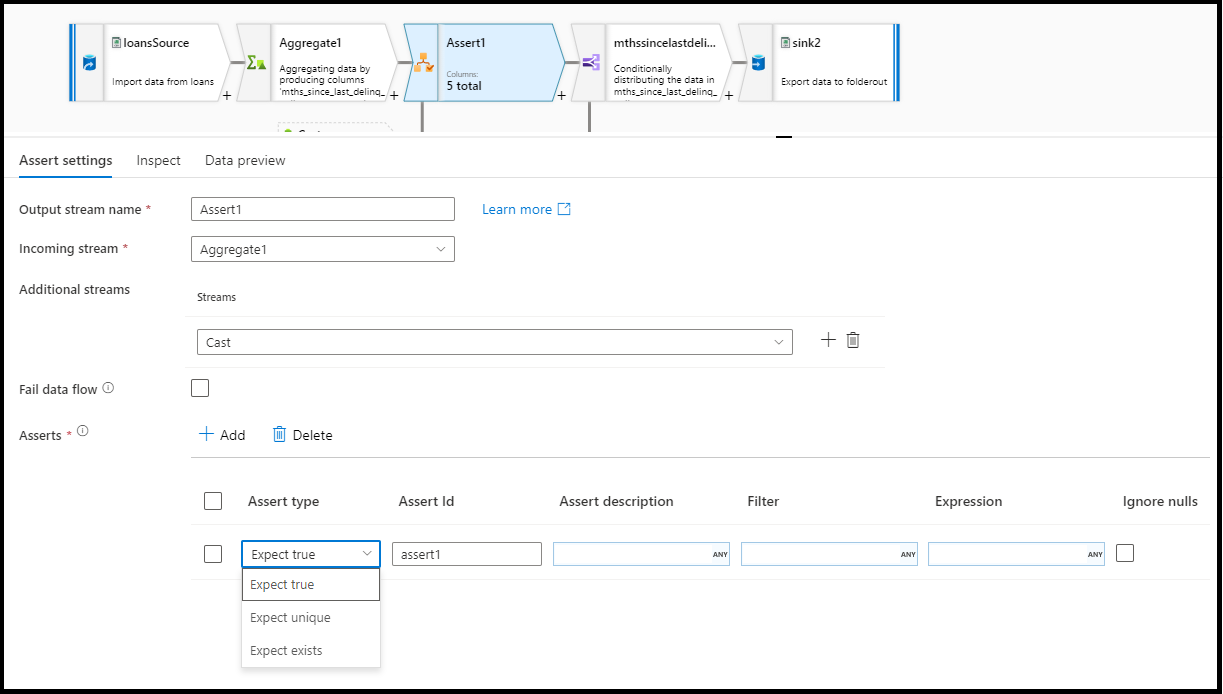
En el panel de configuración de la transformación de aserciones, va a elegir el tipo de aserción, proporcionará un nombre único para la aserción y una descripción opcional y definirá la expresión y el filtro opcional. El panel de vista previa de datos indica en qué filas las aserciones han dado error. Además, puede probar cada etiqueta de fila de bajada mediante isError() y hasError() para las filas en las que las aserciones dieron error.
Tipo de afirmación
- Expect true (Esperar true): el resultado de la expresión debe evaluarse como un resultado booleano true. Use este ajuste para validar los intervalos de valores de dominio en los datos.
- Expect unique (Esperar unique): establezca una columna o una expresión como una regla de unicidad en los datos. Use este ajuste para etiquetar filas duplicadas.
- Expect exists (Esperar exists): esta opción solo está disponible cuando se ha seleccionado una segunda secuencia entrante. Exists examinará ambas secuencias y determinará si las filas existen en ambas en función de las columnas o las expresiones que haya especificado. Para agregar la segunda secuencia para "exists", seleccione
Additional streams.
Error en el flujo de datos
Seleccione fail data flow si quiere que la actividad de flujo de datos produzca error tan pronto como lo haga la regla de aserción.
Assert ID
Assert ID es una propiedad donde se escribe un nombre (cadena) para la aserción. Podrá usar el identificador más adelante en el flujo de datos mediante hasError() o para generar el código de error de aserción. Los ID de afirmación deben ser únicos dentro de cada flujo de datos.
Descripción de la aserción
Introduzca aquí una descripción de la cadena para su afirmación. También puede usar aquí expresiones y valores de columna de contexto de fila.
Filtro
Filter es una propiedad opcional en la que puede filtrar la aserción solo por un subconjunto de filas en función del valor de la expresión.
Expresión
Escriba una expresión para la evaluación de cada una de las aserciones. Puede tener varias aserciones para cada transformación de aserción. Cada tipo de aserción requiere una expresión que ADF necesita evaluar para verificar si se ha cumplido la aserción.
Omisión de valores NULL
De forma predeterminada, la transformación de aserción incluirá valores NULL en la evaluación de aserciones de fila. Con esta propiedad, puede optar por omitir los valores NULL.
Errores de fila de aserción directa
Cuando se produce un error en una aserción, opcionalmente puede dirigir esas filas de error a un archivo en Azure mediante la pestaña "Errores" de la transformación del receptor. También tiene una opción en la transformación del receptor para no generar ninguna fila con errores de aserción omitiendo las filas de error.
Ejemplos
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Script de flujo de datos
Ejemplos
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Contenido relacionado
- Use la transformación de selección para seleccionar y validar columnas.
- Use la transformación de columna derivada para transformar los valores de columna.