Adatok másolása és átalakítása az Azure SQL Database-ben az Azure Data Factory vagy az Azure Synapse Analytics használatával
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ez a cikk bemutatja, hogyan használható a másolási tevékenység az Azure Data Factoryben vagy az Azure Synapse-folyamatokban az adatok Azure SQL Database-ből és az Azure SQL Database-be való másolásához, valamint az Adatfolyam használatával az Adatok átalakítása az Azure SQL Database-ben. További információért olvassa el az Azure Data Factory vagy az Azure Synapse Analytics bevezető cikkét.
Támogatott képességek
Ez az Azure SQL Database-összekötő a következő képességeket támogatja:
| Támogatott képességek | IR | Felügyelt privát végpont |
|---|---|---|
| Copy tevékenység (forrás/fogadó) | (1) (2) | ✓ |
| Adatfolyam leképezése (forrás/fogadó) | (1) | ✓ |
| Keresési tevékenység | (1) (2) | ✓ |
| GetMetadata-tevékenység | (1) (2) | ✓ |
| Szkripttevékenység | (1) (2) | ✓ |
| Tárolt eljárástevékenység | (1) (2) | ✓ |
(1) Azure-integrációs modul (2) Saját üzemeltetésű integrációs modul
Az Copy tevékenység esetében ez az Azure SQL Database-összekötő a következő funkciókat támogatja:
- Adatok másolása SQL-hitelesítéssel és Microsoft Entra-alkalmazásjogkivonat-hitelesítéssel az Azure-erőforrások szolgáltatásnévvel vagy felügyelt identitásaival.
- Forrásként az adatok lekérése SQL-lekérdezéssel vagy tárolt eljárással. Az Azure SQL Database-forrásból történő párhuzamos másolást is választhatja, a részletekért tekintse meg az SQL Database párhuzamos példányát ismertető szakaszt.
- Fogadóként automatikusan hozzon létre céltáblát, ha nem létezik a forrásséma alapján; adatok hozzáfűzése egy táblához, vagy tárolt eljárás meghívása egyéni logikával a másolás során.
Ha kiszolgáló nélküli Azure SQL Database-szintet használ, vegye figyelembe, hogy a kiszolgáló szüneteltetésekor a tevékenységfuttatás meghiúsul ahelyett, hogy az automatikus folytatásra várna. Hozzáadhat tevékenység-újrapróbálkozást, vagy további tevékenységeket láncolva biztosíthatja, hogy a kiszolgáló a tényleges végrehajtás után is működőképes legyen.
Fontos
Ha az Azure integrációs modullal másol adatokat, konfiguráljon egy kiszolgálószintű tűzfalszabályt, hogy az Azure-szolgáltatások hozzáférhessenek a kiszolgálóhoz. Ha egy saját üzemeltetésű integrációs modullal másol adatokat, konfigurálja a tűzfalat a megfelelő IP-címtartomány engedélyezéséhez. Ez a tartomány tartalmazza az Azure SQL Database-hez való csatlakozáshoz használt gép IP-címét.
Első lépések
A Copy tevékenység folyamattal való végrehajtásához használja az alábbi eszközök vagy SDK-k egyikét:
- Az Adatok másolása eszköz
- Az Azure Portal
- A .NET SDK
- A Python SDK
- Azure PowerShell
- A REST API
- Az Azure Resource Manager-sablon
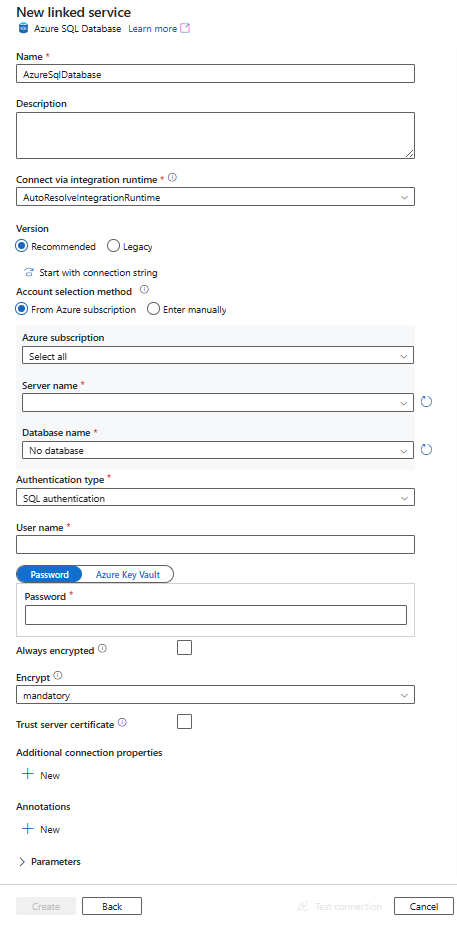
Azure SQL Database-hez társított szolgáltatás létrehozása felhasználói felületen
Az alábbi lépésekkel létrehozhat egy Azure SQL Database-hez társított szolgáltatást az Azure Portal felhasználói felületén.
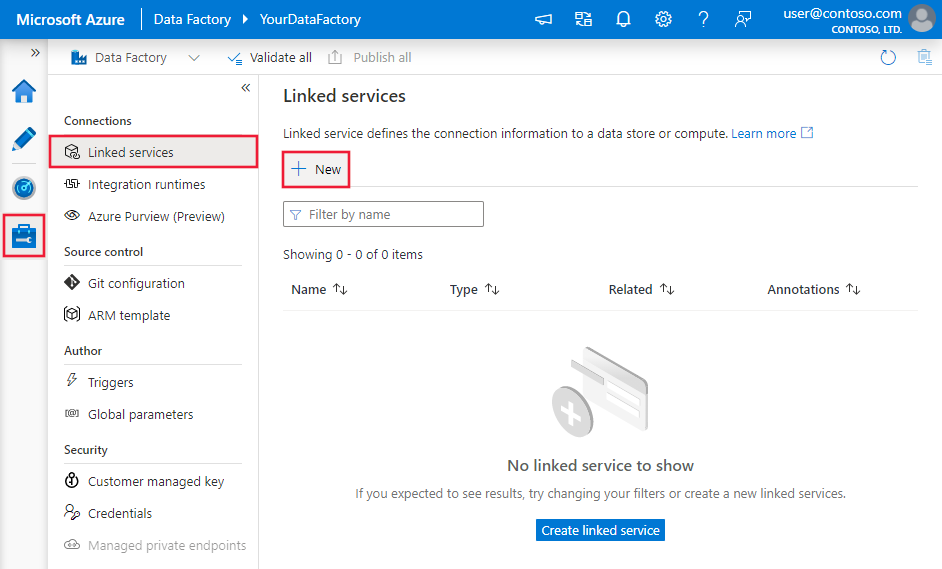
Keresse meg az Azure Data Factory vagy a Synapse-munkaterület Kezelés lapját, és válassza a Társított szolgáltatások lehetőséget, majd kattintson az Új gombra:
Keresse meg az SQL-t, és válassza ki az Azure SQL Database-összekötőt.

Konfigurálja a szolgáltatás részleteit, tesztelje a kapcsolatot, és hozza létre az új társított szolgáltatást.
Csatlakozás or konfigurációjának részletei
A következő szakaszok az Azure Data Factory vagy a Synapse-folyamat entitásainak az Azure SQL Database-összekötőkre vonatkozó meghatározásához használt tulajdonságokat ismertetik.
Társított szolgáltatás tulajdonságai
Ezek az általános tulajdonságok az Azure SQL Database-hez társított szolgáltatások esetében támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A típustulajdonságot az AzureSqlDatabase értékre kell állítani. | Igen |
| connectionString | Adja meg a connectionString tulajdonság Azure SQL Database-példányához való csatlakozáshoz szükséges információkat. Jelszót vagy szolgáltatásnévkulcsot is elhelyezhet az Azure Key Vaultban. Ha SQL-hitelesítésről van szó, húzza ki a konfigurációt password a kapcsolati sztring. További információ: JSON-példa a tábla és az Azure Key Vaultban tárolt hitelesítő adatok tárolására. |
Igen |
| azureCloudType | A szolgáltatásnév hitelesítéséhez adja meg annak az Azure-felhőkörnyezetnek a típusát, amelyre a Microsoft Entra-alkalmazás regisztrálva van. Az engedélyezett értékek az AzurePublic, az AzureChina, az AzureUsGovernment és az AzureGermany. Alapértelmezés szerint a rendszer az adat-előállítót vagy a Synapse-folyamat felhőkörnyezetét használja. |
Nem |
| alwaysEncrypted Gépház | Adja meg az Always Encrypted engedélyezéséhez szükséges Alwaysencryptedsettings-adatokat , amelyek felügyelt identitással vagy szolgáltatásnévvel védik az SQL Serveren tárolt bizalmas adatokat. További információ: A táblázatot és az Always Encrypted használata szakaszt követő JSON-példa. Ha nincs megadva, az alapértelmezett mindig titkosított beállítás le van tiltva. | Nem |
| connectVia | Ez az integrációs modul az adattárhoz való csatlakozásra szolgál. Használhatja az Azure integrációs modult vagy egy saját üzemeltetésű integrációs modult, ha az adattár magánhálózaton található. Ha nincs megadva, a rendszer az alapértelmezett Azure-integrációs modult használja. | Nem |
A különböző hitelesítési típusok esetében tekintse meg az egyes tulajdonságokra, előfeltételekre és JSON-mintákra vonatkozó alábbi szakaszokat:
- SQL-hitelesítés
- Egyszerű szolgáltatás hitelesítése
- Rendszer által hozzárendelt felügyelt identitás hitelesítése
- Felhasználó által hozzárendelt felügyelt identitás hitelesítése
Tipp.
Ha a "UserErrorFailedTo Csatlakozás ToSqlServer" hibakóddal és egy "Az adatbázis munkamenetkorlátja XXX, és elérte" hibaüzenetet kapott, adja hozzá Pooling=false a kapcsolati sztring, és próbálkozzon újra. Pooling=falseaz SHIR(saját üzemeltetésű integrációs modul) típusú társított szolgáltatásbeállításhoz is ajánlott. A készletezés és más kapcsolati paraméterek új paraméternévként és értékként is hozzáadhatók a társított szolgáltatás létrehozási űrlapJának További kapcsolattulajdonságok szakaszában.
SQL-hitelesítés
Az SQL-hitelesítés típusának használatához adja meg az előző szakaszban ismertetett általános tulajdonságokat.
Példa: SQL-hitelesítés használata
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=<databasename>;User ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Példa: jelszó az Azure Key Vaultban
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=<databasename>;User ID=<username>@<servername>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Példa: Always Encrypted használata
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=<databasename>;User ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egyszerű szolgáltatás hitelesítése
A szolgáltatásnév-hitelesítés használatához az előző szakaszban ismertetett általános tulajdonságok mellett adja meg a következő tulajdonságokat:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| servicePrincipalId | Adja meg az alkalmazás ügyfél-azonosítóját. | Igen |
| servicePrincipalKey | Adja meg az alkalmazás kulcsát. Jelölje meg ezt a mezőt SecureStringként, hogy biztonságosan tárolja, vagy hivatkozzon az Azure Key Vaultban tárolt titkos kódra. | Igen |
| bérlő | Adja meg a bérlő adatait, például azt a tartománynevet vagy bérlőazonosítót, amely alatt az alkalmazás található. Kérje le az egérmutatót az Azure Portal jobb felső sarkában. | Igen |
Az alábbi lépéseket is követnie kell:
Microsoft Entra-alkalmazás létrehozása az Azure Portalról. Jegyezze fel az alkalmazás nevét és a társított szolgáltatást meghatározó alábbi értékeket:
- Pályázat azonosítója
- Alkalmazáskulcs
- Bérlőazonosító
Ha még nem tette meg, kiépíthet egy Microsoft Entra-rendszergazdát a kiszolgálóhoz az Azure Portalon. A Microsoft Entra rendszergazdájának Microsoft Entra-felhasználónak vagy Microsoft Entra-csoportnak kell lennie, de nem lehet egyszerű szolgáltatásnév. Ez a lépés úgy történik, hogy a következő lépésben egy Microsoft Entra-identitással hozzon létre egy tartalmazott adatbázis-felhasználót a szolgáltatásnévhez.
Tartalmazott adatbázis-felhasználók létrehozása a szolgáltatásnévhez. Csatlakozás arra az adatbázisra, amelyből adatokat szeretne másolni olyan eszközökkel, mint az SQL Server Management Studio, olyan Microsoft Entra-identitással, amely legalább AZ U Standard kiadás R engedéllyel rendelkezik. Futtassa a következő T-SQL-t:
CREATE USER [your application name] FROM EXTERNAL PROVIDER;Adja meg a szolgáltatásnévnek a szükséges engedélyeket, ahogyan azt az SQL-felhasználók vagy mások esetében általában teszi. Futtassa a következő kódot. További lehetőségekért tekintse meg ezt a dokumentumot.
ALTER ROLE [role name] ADD MEMBER [your application name];Azure SQL Database-hez társított szolgáltatás konfigurálása Azure Data Factory- vagy Synapse-munkaterületen.
Szolgáltatásnév-hitelesítést használó társított szolgáltatás példája
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Rendszer által hozzárendelt felügyelt identitás hitelesítése
Egy adat-előállító vagy Synapse-munkaterület társítható egy rendszer által hozzárendelt felügyelt identitással az Azure-erőforrásokhoz , amelyek a szolgáltatást képviselik az Azure más erőforrásaihoz való hitelesítéskor. Ezt a felügyelt identitást használhatja az Azure SQL Database-hitelesítéshez. A kijelölt gyár vagy Synapse-munkaterület ezzel az identitással férhet hozzá és másolhat adatokat az adatbázisból vagy az adatbázisba.
A rendszer által hozzárendelt felügyelt identitáshitelesítés használatához adja meg az előző szakaszban ismertetett általános tulajdonságokat, és kövesse az alábbi lépéseket.
Ha még nem tette meg, kiépíthet egy Microsoft Entra-rendszergazdát a kiszolgálóhoz az Azure Portalon. A Microsoft Entra rendszergazdája lehet Microsoft Entra-felhasználó vagy Microsoft Entra-csoport. Ha rendszergazdai szerepkört ad a felügyelt identitással rendelkező csoportnak, hagyja ki a 3. és a 4. lépést. A rendszergazda teljes hozzáféréssel rendelkezik az adatbázishoz.
Tartalmazott adatbázis-felhasználók létrehozása a felügyelt identitáshoz. Csatlakozás arra az adatbázisra, amelyből adatokat szeretne másolni olyan eszközökkel, mint az SQL Server Management Studio, olyan Microsoft Entra-identitással, amely legalább AZ U Standard kiadás R engedéllyel rendelkezik. Futtassa a következő T-SQL-t:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Adja meg a felügyelt identitáshoz szükséges engedélyeket, ahogyan az SQL-felhasználók és mások esetében általában. Futtassa a következő kódot. További lehetőségekért tekintse meg ezt a dokumentumot.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Azure SQL Database társított szolgáltatás konfigurálása.
Példa
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=<databasename>;Connection Timeout=30"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Felhasználó által hozzárendelt felügyelt identitás hitelesítése
Egy adat-előállító vagy Synapse-munkaterület társítható felhasználó által hozzárendelt felügyelt identitásokkal, amelyek a szolgáltatást képviselik az Azure más erőforrásaihoz való hitelesítéskor. Ezt a felügyelt identitást használhatja az Azure SQL Database-hitelesítéshez. A kijelölt gyár vagy Synapse-munkaterület ezzel az identitással férhet hozzá és másolhat adatokat az adatbázisból vagy az adatbázisba.
A felhasználó által hozzárendelt felügyelt identitáshitelesítés használatához az előző szakaszban ismertetett általános tulajdonságok mellett adja meg a következő tulajdonságokat:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| hitelesítő adatok | Adja meg a felhasználó által hozzárendelt felügyelt identitást hitelesítő objektumként. | Igen |
Az alábbi lépéseket is követnie kell:
Ha még nem tette meg, kiépíthet egy Microsoft Entra-rendszergazdát a kiszolgálóhoz az Azure Portalon. A Microsoft Entra rendszergazdája lehet Microsoft Entra-felhasználó vagy Microsoft Entra-csoport. Ha rendszergazdai szerepkört ad a csoportnak a felhasználó által hozzárendelt felügyelt identitással, hagyja ki a 3. lépést. A rendszergazda teljes hozzáféréssel rendelkezik az adatbázishoz.
Tartalmazott adatbázis-felhasználók létrehozása a felhasználó által hozzárendelt felügyelt identitáshoz. Csatlakozás arra az adatbázisra, amelyből adatokat szeretne másolni olyan eszközökkel, mint az SQL Server Management Studio, olyan Microsoft Entra-identitással, amely legalább AZ U Standard kiadás R engedéllyel rendelkezik. Futtassa a következő T-SQL-t:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Hozzon létre egy vagy több felhasználó által hozzárendelt felügyelt identitást , és adja meg a felhasználó által hozzárendelt felügyelt identitásnak a szükséges engedélyeket, ahogyan azt az SQL-felhasználók és mások esetében általában teszi. Futtassa a következő kódot. További lehetőségekért tekintse meg ezt a dokumentumot.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Rendeljen hozzá egy vagy több felhasználó által hozzárendelt felügyelt identitást az adat-előállítóhoz, és hozzon létre hitelesítő adatokat minden felhasználó által hozzárendelt felügyelt identitáshoz.
Azure SQL Database társított szolgáltatás konfigurálása.
Példa:
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=<databasename>;Connection Timeout=30",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Adathalmaz tulajdonságai
Az adathalmazok definiálásához elérhető szakaszok és tulajdonságok teljes listáját az Adathalmazok című témakörben találja.
Az Azure SQL Database-adatkészlethez a következő tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | Az adathalmaz típustulajdonságának AzureSqlTable értékre kell állítania. | Igen |
| schema | A séma neve. | Nem a forráshoz, igen a fogadóhoz |
| table | A tábla/nézet neve. | Nem a forráshoz, igen a fogadóhoz |
| tableName | A táblázat/nézet neve sémával. Ez a tulajdonság támogatja a visszamenőleges kompatibilitást. Új számítási feladatokhoz használja schema és table. |
Nem a forráshoz, igen a fogadóhoz |
Példa adathalmaztulajdonságokra
{
"name": "AzureSQLDbDataset",
"properties":
{
"type": "AzureSqlTable",
"linkedServiceName": {
"referenceName": "<Azure SQL Database linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Másolási tevékenység tulajdonságai
A tevékenységek meghatározásához elérhető szakaszok és tulajdonságok teljes listáját a Folyamatok című témakörben találja. Ez a szakasz az Azure SQL Database-forrás és -fogadó által támogatott tulajdonságok listáját tartalmazza.
Forrásként az Azure SQL Database
Tipp.
Ha hatékonyan szeretne adatokat betölteni az Azure SQL Database-ből adatparticionálással, további információt az SQL Database párhuzamos másolásáról tudhat meg.
Az Adatok másolása az Azure SQL Database-ből a másolási tevékenység forrás szakaszában az alábbi tulajdonságokat támogatja:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység forrásának típustulajdonságát az AzureSqlSource-ra kell állítani. Az "SqlSource" típus továbbra is támogatott a visszamenőleges kompatibilitás érdekében. | Igen |
| sqlReaderQuery | Ez a tulajdonság az egyéni SQL-lekérdezést használja az adatok olvasásához. Például: select * from MyTable. |
Nem |
| sqlReaderStoredProcedureName | Annak a tárolt eljárásnak a neve, amely adatokat olvas be a forrástáblából. Az utolsó SQL-utasításnak egy Standard kiadás LECT utasításnak kell lennie a tárolt eljárásban. | Nem |
| storedProcedureParameters | A tárolt eljárás paraméterei. Az engedélyezett értékek név- vagy értékpárok. A paraméterek nevének és burkolatának meg kell egyeznie a tárolt eljárásparaméterek nevével és burkolatával. |
Nem |
| isolationLevel | Az SQL-forrás tranzakciózárolási viselkedését adja meg. Az engedélyezett értékek a következők: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Ha nincs megadva, a rendszer az adatbázis alapértelmezett elkülönítési szintjét használja. További részletekért tekintse meg ezt a dokumentumot. | Nem |
| partitionOptions | Az Azure SQL Database-ből való adatbetöltéshez használt adatparticionálási beállításokat adja meg. Az engedélyezett értékek a következők: Nincs (alapértelmezett), PhysicalPartitionsOfTable és DynamicRange. Ha egy partíciós beállítás engedélyezve van (vagyis nem None), a párhuzamosság mértékét, hogy egyidejűleg betöltse az adatokat egy Azure SQL Database-ből, a parallelCopies másolási tevékenység beállításai vezérlik. |
Nem |
| partíció Gépház | Adja meg az adatparticionálás beállításainak csoportját. Akkor alkalmazható, ha a partíciós beállítás nem None. |
Nem |
A következő alatt partitionSettings: |
||
| partitionColumnName | Adja meg annak a forrásoszlopnak a nevét egész számban vagy dátum/dátum/idő típusban (int, , smallint, bigint, datesmalldatetime, datetime, , datetime2) , datetimeoffsetamelyet a tartomány particionálása használ a párhuzamos másoláshoz. Ha nincs megadva, a rendszer automatikusan észleli a tábla indexét vagy elsődleges kulcsát, és partícióoszlopként használja.Akkor alkalmazható, ha a partíció beállítás. DynamicRange Ha lekérdezést használ a forrásadatok lekéréséhez, a WHERE záradékban kapcsoljon ?DfDynamicRangePartitionCondition be. Példaként tekintse meg az SQL Database párhuzamos másolatát. |
Nem |
| partitionUpperBound | A partíciótartományok felosztásához használt partícióoszlop maximális értéke. Ez az érték határozza meg a partíciós léptetést, nem pedig a tábla sorainak szűrésére. A tábla vagy lekérdezés eredményének összes sora particionálásra és másolásra kerül. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értéket. Akkor alkalmazható, ha a partíció beállítás. DynamicRange Példaként tekintse meg az SQL Database párhuzamos másolatát. |
Nem |
| partitionLowerBound | A partíciótartományok felosztásához használt partícióoszlop minimális értéke. Ez az érték határozza meg a partíciós léptetést, nem pedig a tábla sorainak szűrésére. A tábla vagy lekérdezés eredményének összes sora particionálásra és másolásra kerül. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értéket. Akkor alkalmazható, ha a partíció beállítás. DynamicRange Példaként tekintse meg az SQL Database párhuzamos másolatát. |
Nem |
Vegye figyelembe a következő szempontokat:
- Ha az sqlReaderQuery az AzureSqlSource-hoz van megadva, a másolási tevékenység ezt a lekérdezést az Azure SQL Database-forráson futtatja az adatok lekéréséhez. Tárolt eljárást is megadhat az sqlReaderStoredProcedureName és a storedProcedureParameters megadásával, ha a tárolt eljárás paramétereket vesz fel.
- Ha tárolt eljárást használ a forrásban az adatok lekéréséhez, vegye figyelembe, hogy a tárolt eljárás más sémát ad vissza, amikor különböző paraméterértéket ad át, akkor előfordulhat, hogy a séma felhasználói felületről történő importálásakor vagy az adatok sql-adatbázisba való automatikus létrehozásakor hiba vagy váratlan eredmény jelenik meg.
PÉLDA SQL-lekérdezésre
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Példa tárolt eljárásra
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Tárolt eljárás definíciója
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Az Azure SQL Database mint fogadó
Tipp.
További információ az Azure SQL Database-be való adatbetöltés ajánlott eljárásainak támogatott írási viselkedéseiről, konfigurációiról és ajánlott eljárásairól.
Ha adatokat szeretne az Azure SQL Database-be másolni, a másolási tevékenység fogadó szakaszában az alábbi tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A másolási tevékenység fogadójának típustulajdonságát Az AzureSqlSink értékre kell állítani. Az "SqlSink" típus továbbra is támogatott a visszamenőleges kompatibilitás érdekében. | Igen |
| preCopyScript | Adjon meg egy SQL-lekérdezést a másolási tevékenységhez, mielőtt adatokat írna az Azure SQL Database-be. Másolási futtatásonként csak egyszer lesz meghívva. Ezzel a tulajdonságkal törölheti az előre betöltött adatokat. | Nem |
| tableOption | Megadja, hogy automatikusan létre kívánja-e hozni a fogadótáblát , ha nem létezik a forrásséma alapján. Az automatikus táblalétrehozás nem támogatott, ha a fogadó a tárolt eljárást határozza meg. Az engedélyezett értékek a következők: none (alapértelmezett), autoCreate. |
Nem |
| sqlWriterStoredProcedureName | A tárolt eljárás neve, amely meghatározza a forrásadatok céltáblába való alkalmazását. Ezt a tárolt eljárást kötegenként hívja meg a rendszer. Olyan műveletek esetén, amelyek csak egyszer futnak, és nincs köze a forrásadatokhoz, például törléshez vagy csonkolási műveletekhez, használja a tulajdonságot preCopyScript .Tekintse meg az SQL-fogadó tárolt eljárásának meghívására vonatkozó példát. |
Nem |
| storedProcedureTableTypeParameterName | A tárolt eljárásban megadott táblatípus paraméterneve. | Nem |
| sqlWriterTableType | A tárolt eljárásban használandó táblatípus neve. A másolási tevékenység elérhetővé teszi az áthelyezett adatokat egy ilyen típusú ideiglenes táblában. A tárolt eljáráskód ezután egyesítheti a másolt adatokat a meglévő adatokkal. | Nem |
| storedProcedureParameters | A tárolt eljárás paraméterei. Az engedélyezett értékek név- és értékpárok. A paraméterek nevének és burkolatának meg kell egyeznie a tárolt eljárásparaméterek nevével és burkolatával. |
Nem |
| writeBatchSize | Az SQL-táblába kötegenként beszúrandó sorok száma. Az engedélyezett érték egész szám (sorok száma). Alapértelmezés szerint a szolgáltatás dinamikusan határozza meg a megfelelő kötegméretet a sorméret alapján. |
Nem |
| writeBatchTimeout | A beszúrási, upsert- és tárolt eljárásművelet befejezésének várakozási ideje, mielőtt túllépi az időkorlátot. Az engedélyezett értékek az időbélyeghez tartoznak. Ilyen például a "00:30:00" 30 percig. Ha nincs megadva érték, az időtúllépés alapértelmezés szerint "00:30:00". |
Nem |
| disableMetricsCollection | A szolgáltatás olyan metrikákat gyűjt, mint az Azure SQL Database DTU-k a másolási teljesítmény optimalizálásához és javaslatokhoz, amelyek további főadatbázis-hozzáférést vezetnek be. Ha ezzel a viselkedéssel foglalkozik, adja meg true , hogy kikapcsolja azt. |
Nem (alapértelmezett érték false) |
| maxConcurrent Csatlakozás ions | Az adattárhoz a tevékenység futtatása során létrehozott egyidejű kapcsolatok felső korlátja. Csak akkor adjon meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat. | Nem |
| WriteBehavior | Adja meg a másolási tevékenység írási viselkedését az adatok Azure SQL Database-be való betöltéséhez. Az engedélyezett érték a Beszúrás és az Upsert. Alapértelmezés szerint a szolgáltatás beszúrással tölti be az adatokat. |
Nem |
| upsert Gépház | Adja meg az írási viselkedés beállításainak csoportját. Alkalmazza, ha a WriteBehavior beállítás a következő Upsert: . |
Nem |
A következő alatt upsertSettings: |
||
| useTempDB | Adja meg, hogy a globális ideiglenes vagy fizikai táblát használja-e köztes táblaként az upserthez. Alapértelmezés szerint a szolgáltatás globális ideiglenes táblát használ köztes táblaként. értéke . true |
Nem |
| interimSchemaName | Adja meg a köztes sémát a köztes tábla létrehozásához fizikai tábla használata esetén. Megjegyzés: a felhasználónak rendelkeznie kell a tábla létrehozására és törlésére vonatkozó engedéllyel. Alapértelmezés szerint a köztes tábla ugyanazt a sémát fogja megosztani, mint a fogadó táblát. Akkor alkalmazható, ha a useTempDB beállítás a Falsekövetkező: . |
Nem |
| keys | Adja meg az egyedi sorazonosítás oszlopnevét. Egy vagy több kulcs használható. Ha nincs megadva, a rendszer az elsődleges kulcsot használja. | Nem |
1. példa: Adatok hozzáfűzése
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
2. példa: Tárolt eljárás meghívása másolás közben
További információ az SQL-fogadó tárolt eljárásának meghívásáról.
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
3. példa: Upsert data
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Párhuzamos másolás AZ SQL Database-ből
Az Azure SQL Database-összekötő másolási tevékenységben beépített adatparticionálást biztosít az adatok párhuzamos másolásához. Az adatparticionálási beállításokat a másolási tevékenység Forrás lapján találja.
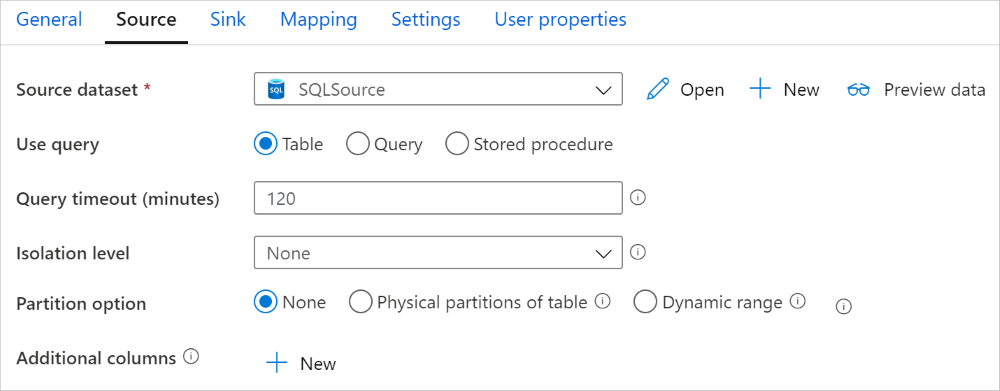
Ha engedélyezi a particionált másolást, a másolási tevékenység párhuzamos lekérdezéseket futtat az Azure SQL Database-forráson az adatok partíciók szerinti betöltéséhez. A párhuzamos fokot a másolási parallelCopies tevékenység beállításai vezérlik. Ha például négyre van állítva parallelCopies , a szolgáltatás egyszerre generál és futtat négy lekérdezést a megadott partícióbeállítás és beállítások alapján, és mindegyik lekérdezés lekéri az adatok egy részét az Azure SQL Database-ből.
Javasoljuk, hogy engedélyezze a párhuzamos másolást adatparticionálással, különösen akkor, ha nagy mennyiségű adatot tölt be az Azure SQL Database-ből. A következő javasolt konfigurációk különböző forgatókönyvekhez. Ha fájlalapú adattárba másol adatokat, ajánlott több fájlként írni egy mappába (csak a mappa nevét kell megadni), ebben az esetben a teljesítmény jobb, mint egyetlen fájlba írni.
| Eset | Javasolt beállítások |
|---|---|
| Teljes terhelés nagy táblából, fizikai partíciókkal. | Partíciós beállítás: A tábla fizikai partíciói. A végrehajtás során a szolgáltatás automatikusan észleli a fizikai partíciókat, és partíciók alapján másolja az adatokat. Ha ellenőrizni szeretné, hogy a tábla rendelkezik-e fizikai partícióval, tekintse meg ezt a lekérdezést. |
| Teljes terhelés nagy táblából fizikai partíciók nélkül, egész számmal vagy datetime oszlopmal az adatparticionáláshoz. | Partícióbeállítások: Dinamikus tartomány partíciója. Partícióoszlop (nem kötelező): Adja meg az adatok particionálásához használt oszlopot. Ha nincs megadva, a rendszer az indexet vagy az elsődleges kulcs oszlopot használja. A partíció felső határa és a partíció alsó határa (nem kötelező): Adja meg, hogy meg szeretné-e határozni a partíciós lépést. Ez nem a táblázat sorainak szűrésére, hanem a tábla összes sorának particionálása és másolása történik. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értékeket. Ha például az "ID" partícióoszlop értéke 1 és 100 között van, és az alsó kötést 20-ra, a felső kötést pedig 80-ra állítja be, a párhuzamos másolás 4-zel történik, a szolgáltatás 4 partícióval kéri le az adatokat – azonosítók az =20, [21, 50], [51, 80] és >=81 tartományban<. |
| Nagy mennyiségű adat betöltése egyéni lekérdezéssel fizikai partíciók nélkül, az adatparticionáláshoz pedig egész számmal vagy dátum/dátum/idő oszlopmal. | Partícióbeállítások: Dinamikus tartomány partíciója. Lekérdezés: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partícióoszlop: Adja meg az adatok particionálásához használt oszlopot. A partíció felső határa és a partíció alsó határa (nem kötelező): Adja meg, hogy meg szeretné-e határozni a partíciós lépést. Ez nem a tábla sorainak szűrésére használható, a lekérdezés eredményének összes sora particionálásra és másolásra kerül. Ha nincs megadva, a másolási tevékenység automatikusan észleli az értéket. Ha például az "ID" partícióoszlop értéke 1 és 100 között van, és az alsó kötést 20-ra, a felső kötést pedig 80-ra állítja be, a párhuzamos másolás 4-zel, akkor a szolgáltatás 4 partícióazonosítóval kéri le az adatokat az =20, [21, 50], [51, 80] és >=81 tartományban<. Az alábbiakban további minta lekérdezéseket talál a különböző forgatókönyvekhez: 1. A teljes tábla lekérdezése: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Lekérdezés oszlopkijelöléssel és további where-clause szűrőkkel rendelkező táblából: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Lekérdezés al lekérdezésekkel: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Lekérdezés a partícióval az alkérdezésben: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Ajánlott eljárások az adatok partíciós beállítással való betöltéséhez:
- Válassza a megkülönböztető oszlopot partícióoszlopként (például elsődleges kulcs vagy egyedi kulcs) az adateltérés elkerülése érdekében.
- Ha a tábla beépített partícióval rendelkezik, a jobb teljesítmény érdekében használja a "Tábla fizikai partíciói" partícióbeállítást.
- Ha az Azure Integration Runtime-t használja az adatok másolásához, nagyobb "adatintegráció egységeket (DIU)" (>4) állíthat be a nagyobb számítási erőforrások használatához. Ellenőrizze a vonatkozó forgatókönyveket.
- A "másolási párhuzamosság foka" szabályozza a partíciószámokat, a túl nagy szám beállítása néha rontja a teljesítményt, javasoljuk, hogy állítsa be ezt a számot (DIU vagy a saját üzemeltetésű INTEGRÁCIÓs csomópontok száma) * (2–4).
Példa: teljes terhelés nagy táblából fizikai partíciókkal
"source": {
"type": "AzureSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Példa: lekérdezés dinamikus tartománypartícióval
"source": {
"type": "AzureSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Minta lekérdezés a fizikai partíció ellenőrzéséhez
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Ha a tábla fizikai partícióval rendelkezik, a "HasPartition" az alábbihoz hasonlóan "igen" értékként jelenik meg.

Ajánlott eljárás adatok Azure SQL Database-be való betöltéséhez
Amikor adatokat másol az Azure SQL Database-be, eltérő írási viselkedésre lehet szükség:
- Hozzáfűzés: A forrásadatok csak új rekordokat tartalmaznak.
- Upsert: A forrásadatok beszúrásokkal és frissítésekkel is rendelkeznek.
- Felülírás: Minden alkalommal egy teljes dimenziótáblát szeretnék újra betölteni.
- Írás egyéni logikával: További feldolgozásra van szükségem a végső beszúrás előtt a céltáblába.
Tekintse meg a megfelelő szakaszokat a szolgáltatásban való konfigurálásról és az ajánlott eljárásokról.
Adatok hozzáfűzése
Az Adatok hozzáfűzése az Azure SQL Database fogadó összekötőjének alapértelmezett viselkedése. a szolgáltatás tömeges beszúrást végez a táblába való hatékony íráshoz. Ennek megfelelően konfigurálhatja a forrást és a fogadót a másolási tevékenységben.
Adatok beszúrása és frissítése (upsert)
Copy tevékenység mostantól támogatja az adatok natív betöltését egy adatbázis ideiglenes táblájába, majd frissíti a fogadó táblában lévő adatokat, ha van kulcs, és egyéb módon szúrjon be új adatokat. Ha többet szeretne megtudni a másolási tevékenységek upsert beállításairól, tekintse meg az Azure SQL Database-t fogadóként.
A teljes táblázat felülírása
A másolási tevékenység fogadójában konfigurálhatja a preCopyScript tulajdonságot. Ebben az esetben minden futtatott másolási tevékenységnél először a szolgáltatás futtatja a szkriptet. Ezután futtatja a másolatot az adatok beszúrásához. Ha például felül szeretné írni a teljes táblát a legújabb adatokkal, adjon meg egy szkriptet, amely először törli az összes rekordot, mielőtt tömegesen betöltené az új adatokat a forrásból.
Adatok írása egyéni logikával
Az adatok egyéni logikával történő írásának lépései hasonlóak az Upsert adatszakaszban leírtakhoz. Ha a forrásadatok végső beszúrása előtt további feldolgozást kell alkalmaznia a céltáblába, betölthet egy átmeneti táblába, majd meghívhatja a tárolt eljárástevékenységet, vagy meghívhat egy tárolt eljárást a másolási tevékenység fogadójában az adatok alkalmazásához, vagy használhatja a Leképezési Adatfolyam.
Tárolt eljárás meghívása SQL-fogadóból
Amikor adatokat másol az Azure SQL Database-be, konfigurálhat és meghívhat egy felhasználó által megadott tárolt eljárást is további paraméterekkel a forrástábla minden kötegén. A tárolt eljárás funkció kihasználja a táblaértékű paraméterek előnyeit.
Tárolt eljárást akkor használhat, ha a beépített másolási mechanizmusok nem szolgálják a célt. Ilyen például, ha a forrásadatok végső beszúrása előtt további feldolgozást szeretne alkalmazni a céltáblába. További feldolgozási példák az oszlopok egyesítése, további értékek keresése és több táblába való beszúrás.
Az alábbi minta bemutatja, hogyan használható tárolt eljárás egy upsert egy táblába az Azure SQL Database-ben. Tegyük fel, hogy a bemeneti adatok és a fogadó marketingtáblája három oszlopból áll: ProfileID, State és Category. Végezze el az upsertet a ProfileID oszlop alapján, és csak a "ProductA" nevű adott kategóriára alkalmazza.
Az adatbázisban adja meg az sqlWriterTableType nevével megegyező nevű táblatípust. A táblatípus sémája megegyezik a bemeneti adatok által visszaadott sémával.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Az adatbázisban adja meg a tárolt eljárást az sqlWriterStoredProcedureName névvel megegyező néven. Kezeli a megadott forrásból származó bemeneti adatokat, és egyesül a kimeneti táblában. A tárolt eljárásban a táblatípus paraméterneve megegyezik az adathalmazban definiált TableName paraméternévvel .
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDAz Azure Data Factoryben vagy a Synapse-folyamatban adja meg a másolási tevékenység SQL-fogadó szakaszát az alábbiak szerint:
"sink": { "type": "AzureSqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Amikor tárolt eljárással ír adatokat az Azure SQL Database-be, a fogadó a forrásadatokat mini kötegekre osztja, majd végrehajtja a beszúrást, így a tárolt eljárásban lévő extra lekérdezés többször is végrehajtható. Ha rendelkezik a másolási tevékenység futtatására vonatkozó lekérdezéssel, mielőtt adatokat írna az Azure SQL Database-be, akkor nem ajánlott hozzáadnia a tárolt eljáráshoz, hanem vegye fel a másolás előtti szkriptmezőbe .
Adatfolyam-tulajdonságok leképezése
A leképezési adatfolyam adatainak átalakításakor az Azure SQL Database-ből olvashat és írhat táblákba. További információkért tekintse meg a forrásátalakítást és a fogadóátalakítást a leképezési adatfolyamokban.
Forrásátalakítás
az Azure SQL Database-hez kapcsolódó Gépház a A forrásátalakítás Forrásbeállítások lapja.
Bemenet: Válassza ki, hogy a forrást egy táblára (egyenértékű) mutatja-e Select * from <table-name>, vagy egyéni SQL-lekérdezést ad meg.
Lekérdezés: Ha a bemeneti mezőben a Lekérdezés lehetőséget választja, adjon meg egy SQL-lekérdezést a forráshoz. Ez a beállítás felülírja az adathalmazban kiválasztott táblákat. Az Order By záradékok itt nem támogatottak, de beállíthat egy teljes Standard kiadás LECT FROM utasítást. Felhasználó által definiált táblafüggvényeket is használhat. select * from udfGetData() egy olyan UDF az SQL-ben, amely egy táblát ad vissza. Ez a lekérdezés létrehoz egy forrástáblát, amelyet használhat az adatfolyamban. A lekérdezések használatával is csökkenthetők a tesztelési és keresési sorok.
Tipp.
Az SQL-ben használt közös táblakifejezés (CTE) nem támogatott a leképezési adatfolyam lekérdezési módjában, mivel ennek a módnak az előfeltétele, hogy a lekérdezések használhatók legyenek az SQL-lekérdezés FROM záradékában, de a CTE-k ezt nem tehetik meg. A CTE-k használatához létre kell hoznia egy tárolt eljárást a következő lekérdezéssel:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Ezután használja a Tárolt eljárás módot a leképezési adatfolyam forrásátalakításában, és állítsa be a @query hasonló példát with CTE as (select 'test' as a) select * from CTE. Ezután használhatja a CT-eket a várt módon.
Tárolt eljárás: Akkor válassza ezt a lehetőséget, ha a forrásadatbázisból végrehajtott tárolt eljárásból szeretne előrejelzési és forrásadatokat létrehozni. Beírhatja a sémát, az eljárás nevét és a paramétereket, vagy a Frissítés gombra kattintva megkérheti a szolgáltatást, hogy felderítse a sémákat és az eljárásneveket. Ezután az Importálás gombra kattintva importálhatja az összes eljárásparamétert az űrlap @paraNamehasználatával.
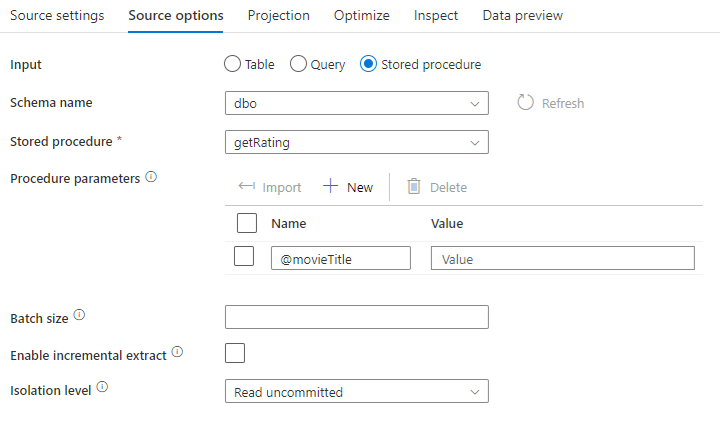
- SQL-példa:
Select * from MyTable where customerId > 1000 and customerId < 2000 - Paraméteres SQL-példa:
"select * from {$tablename} where orderyear > {$year}"
Kötegméret: Adjon meg egy kötegméretet, hogy nagy adatokat olvasson be.
Elkülönítési szint: A leképezési adatfolyamban az SQL-források alapértelmezett írásvédettként lesznek beolvasva. Az elkülönítési szintet itt az alábbi értékek egyikére módosíthatja:
- Lekötött olvasás
- Nem véglegesített olvasás
- Ismételhető olvasás
- Szerializálható
- Nincs (az elkülönítési szint figyelmen kívül hagyása)
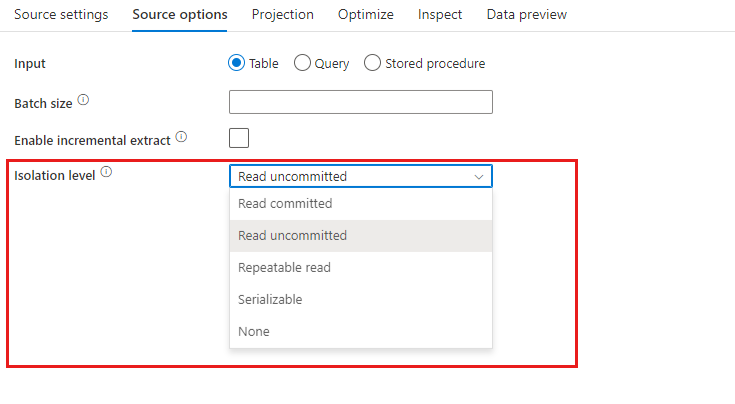
Növekményes kinyerés engedélyezése: Ezzel a beállítással tudathatja az ADF-sel, hogy csak azokat a sorokat dolgozza fel, amelyek a folyamat legutóbbi végrehajtása óta megváltoztak. Ha sémaeltolódással szeretné engedélyezni a növekményes kivonatot, a natív változásadat-rögzítéshez engedélyezett táblák helyett válassza a növekményes/vízjeles oszlopokon alapuló táblákat.
Növekményes oszlop: A növekményes kinyerési funkció használatakor ki kell választania a forrástáblában vízjelként használni kívánt dátum/idő vagy numerikus oszlopot.
Natív módosítási adatrögzítés engedélyezése (előzetes verzió): Ezzel a beállítással tudathatja az ADF-sel, hogy a folyamat legutóbbi végrehajtása óta csak az SQL-változási adatrögzítési technológia által rögzített változásadatokat dolgozza fel. Ezzel a beállítással a rendszer automatikusan betölti a deltaadatokat, beleértve a sor beszúrását, frissítését és törlését anélkül, hogy növekményes oszlopra lenne szükség. A beállítás ADF-ben való használata előtt engedélyeznie kell a változásadat-rögzítést az Azure SQL DB-ben. Az ADF-ben elérhető beállítással kapcsolatos további információkért lásd a natív változásadatok rögzítését.
Kezdje el az olvasást az elejétől: Ha ezt a beállítást növekményes kivonattal állítja be, az ADF arra utasítja az ADF-et, hogy olvassa be az összes sort egy folyamat első végrehajtásakor, és be van kapcsolva a növekményes kivonat.
Fogadó átalakítása
az Azure SQL Database-hez kapcsolódó Gépház a fogadóátalakítás Gépház lapján érhetők el.
Frissítési módszer: Meghatározza, hogy milyen műveletek engedélyezettek az adatbázis célhelyén. Az alapértelmezett beállítás csak a beszúrások engedélyezése. A sorok frissítéséhez, frissítéséhez vagy törléséhez váltakozósor-átalakításra van szükség az adott műveletek sorainak címkézéséhez. Frissítések, upserts és deletes esetén egy kulcsoszlopot vagy oszlopot kell beállítani annak meghatározásához, hogy melyik sort kell módosítani.
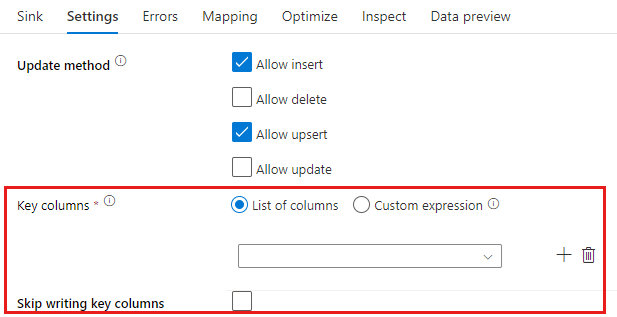
Az itt kulcsként megadott oszlopnevet a szolgáltatás a következő frissítés, a upsert és a törlés részeként fogja használni. Ezért ki kell választania egy olyan oszlopot, amely a fogadóleképezésben található. Ha nem szeretné ebbe a kulcsoszlopba írni az értéket, kattintson a "Kulcsoszlopok írásának kihagyása" elemre.
A cél Azure SQL Database-tábla frissítéséhez itt használt kulcsoszlop paraméterezhető. Ha több oszlopa van egy összetett kulcshoz, kattintson az "Egyéni kifejezés" elemre, és dinamikus tartalmat adhat hozzá az adatfolyam-kifejezés nyelvével, amely tartalmazhatja az összetett kulcs oszlopneveit tartalmazó sztringeket tartalmazó tömböt.
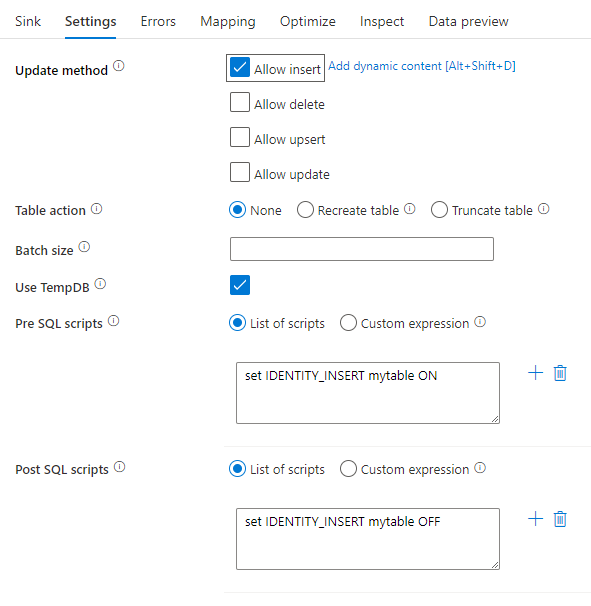
Táblaművelet: Meghatározza, hogy az írás előtt újra létre kell-e hozni vagy eltávolítani az összes sort a céltáblából.
- Nincs: A rendszer nem hajt végre műveletet a táblán.
- Újra: A tábla elvetve és újra létrehozva lesz. Új tábla dinamikus létrehozása esetén kötelező.
- Csonkolási: A céltábla összes sora el lesz távolítva.
Kötegméret: Azt szabályozza, hogy hány sor legyen megírva az egyes gyűjtőkben. A nagyobb kötegméretek javítják a tömörítést és a memóriaoptimalizálást, de az adatok gyorsítótárazásakor a memóriakivételek kiesnek.
TempDB használata: Alapértelmezés szerint a szolgáltatás egy globális ideiglenes táblával tárolja az adatokat a betöltési folyamat részeként. Másik lehetőségként törölheti a "TempDB használata" jelölőnégyzet jelölését, és ehelyett kérje meg a szolgáltatást, hogy tárolja az ideiglenes tárolótáblát a fogadóhoz használt adatbázisban található felhasználói adatbázisban.

SQL-szkriptek elő- és postálása: Adja meg azokat a többsoros SQL-szkripteket, amelyek az adatok feldolgozása előtt (előzetes feldolgozás) és (utófeldolgozás) után lesznek végrehajtva a Fogadó adatbázisba
Tipp.
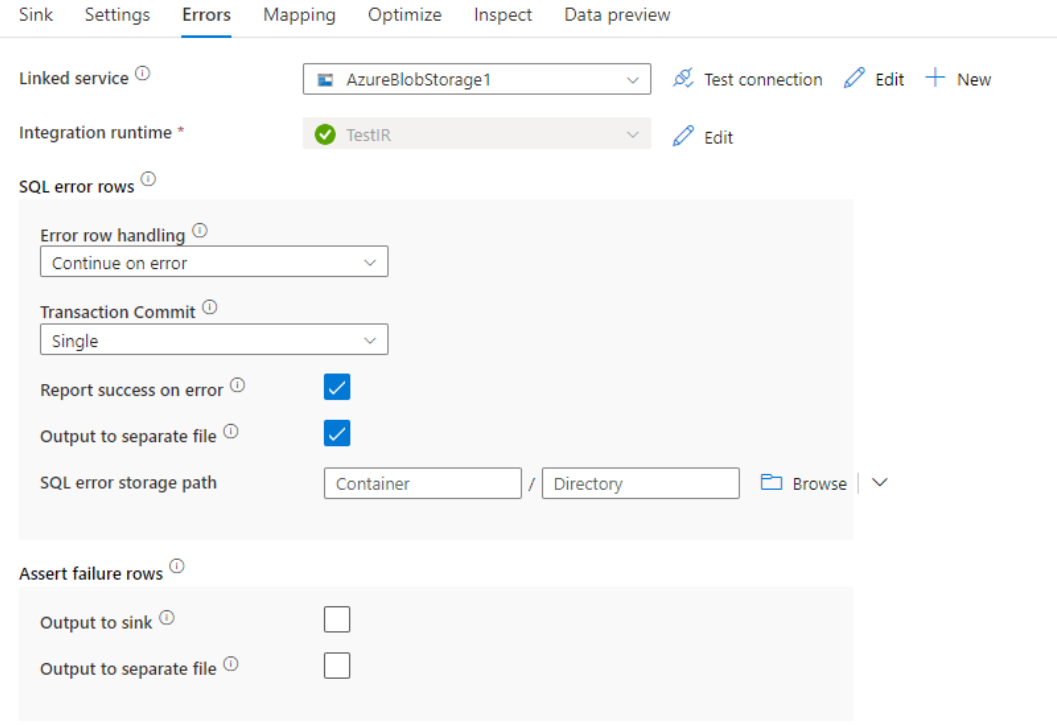
Hibát tartalmazó sorok kezelése
Az Azure SQL DB-be való íráskor bizonyos adatsorok meghiúsulhatnak a cél által beállított korlátozások miatt. Néhány gyakori hiba:
- A sztring- vagy bináris adatok csonkulnak a táblában
- A NULL értéket nem lehet beszúrni az oszlopba
- Az IN Standard kiadás RT utasítás ütközött a CHECK kényszerrel
Alapértelmezés szerint az adatfolyam-futtatás az első hibánál meghiúsul. Választhatja a Folytatás hibaüzenetet , amely lehetővé teszi az adatfolyam befejezését még akkor is, ha az egyes sorok hibásak. A szolgáltatás különböző lehetőségeket kínál a hibasorok kezelésére.
Tranzakció véglegesítése: Adja meg, hogy az adatok egyetlen tranzakcióban vagy kötegekben lesznek-e megírva. Az egyetlen tranzakció rosszabb teljesítményt nyújt, de a tranzakció befejezéséig nem jelennek meg mások számára megírt adatok.
Elutasított adatok kimenete: Ha engedélyezve van, a hibasorokat egy csv-fájlba is kiadhatja az Azure Blob Storage-ban vagy egy ön által választott Azure Data Lake Storage Gen2-fiókban. Ez megírja a hibasorokat három további oszlopmal: az SQL-művelettel( például IN Standard kiadás RT vagy UPDATE), az adatfolyam hibakódjával és a sor hibaüzenetével.
Hibajelentés sikerességéről: Ha engedélyezve van, az adatfolyam akkor is sikeresként lesz megjelölve, ha hibasorok találhatók.
Adattípus-leképezés az Azure SQL Database-hez
Amikor az adatokat az Azure SQL Database-ből vagy az Azure SQL Database-be másolja, a rendszer az alábbi leképezéseket használja az Azure SQL Database adattípusaiból az Azure Data Factory köztes adattípusaihoz. Ugyanazokat a leképezéseket használja a Synapse-folyamat funkció, amely közvetlenül implementálja az Azure Data Factoryt. Ha tudni szeretné, hogy a másolási tevékenység hogyan képezi le a forrássémát és az adattípust a fogadóhoz, tekintse meg a séma- és adattípus-leképezéseket.
| Az Azure SQL Database adattípusa | A Data Factory köztes adattípusa |
|---|---|
| bigint | Int64 |
| Bináris | Bájt[] |
| Kicsit | Logikai |
| Char | Sztring, Karakter[] |
| dátum: | Dátum/idő |
| Datetime | Dátum/idő |
| datetime2 | Dátum/idő |
| Datetimeoffset | DateTimeOffset |
| Decimális | Decimális |
| FILESTREAM attribútum (varbinary(max)) | Bájt[] |
| Lebegőpontos értékek | Dupla |
| rendszerkép | Bájt[] |
| egész | Int32 |
| Pénzt | Decimális |
| nchar | Sztring, Karakter[] |
| ntext | Sztring, Karakter[] |
| Numerikus | Decimális |
| nvarchar | Sztring, Karakter[] |
| valós szám | Egyszeres |
| rowversion | Bájt[] |
| smalldatetime | Dátum/idő |
| smallint | Int16 |
| smallmoney | Decimális |
| sql_variant | Objektum |
| text | Sztring, Karakter[] |
| time | időtartam |
| időbélyeg | Bájt[] |
| tinyint | Bájt |
| uniqueidentifier | GUID |
| varbinary | Bájt[] |
| varchar | Sztring, Karakter[] |
| xml | Sztring |
Feljegyzés
A decimális köztes típusra leképezhető adattípusok esetében jelenleg Copy tevékenység legfeljebb 28 pontosságot támogat. Ha 28-nál nagyobb pontosságú adatokkal rendelkezik, fontolja meg az SQL-lekérdezések sztringgé alakítását.
Keresési tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez tekintse meg a keresési tevékenységet.
GetMetadata tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez ellenőrizze a GetMetadata-tevékenységet
Always Encrypted használata
Amikor adatokat másol az Azure SQL Database-ből vagy az Azure SQL Database-be az Always Encrypted használatával, kövesse az alábbi lépéseket:
Tárolja az oszlop főkulcsát (CMK) egy Azure Key Vaultban. További információ az Always Encrypted Azure Key Vault használatával történő konfigurálásáról
Győződjön meg arról, hogy hozzáfér ahhoz a kulcstartóhoz, amelyben az oszlop főkulcsa (CMK) található. A szükséges engedélyekért tekintse meg ezt a cikket .
Hozzon létre társított szolgáltatást az SQL-adatbázishoz való csatlakozáshoz, és engedélyezze az "Always Encrypted" függvényt felügyelt identitás vagy szolgáltatásnév használatával.
Feljegyzés
Az Azure SQL Database Always Encrypted az alábbi forgatókönyveket támogatja:
- A forrás- vagy fogadóadattárak a felügyelt identitást vagy a szolgáltatásnevet használják kulcsszolgáltatói hitelesítési típusként.
- A forrás- és fogadóadattárak is a felügyelt identitást használják kulcsszolgáltatói hitelesítési típusként.
- A forrás- és fogadóadattárak ugyanazt a szolgáltatásnevet használják, mint a kulcsszolgáltatói hitelesítés típusát.
Feljegyzés
Az Azure SQL Database Always Encrypted jelenleg csak a forrásátalakítást támogatja a leképezési adatfolyamokban.
Natív változásadat-rögzítés
Az Azure Data Factory támogatja az SQL Server, az Azure SQL DB és az Azure SQL MI natív változásadat-rögzítési képességeit. Az ADF-leképezési adatfolyam automatikusan észlelheti és kinyerheti a módosított adatokat, beleértve a sor beszúrását, frissítését és törlését az SQL-tárolókban. Mivel nincs kódélmény az adatfolyam leképezésében, a felhasználók egyszerűen elérhetik az SQL-tárolókból származó adatreplikációs forgatókönyvet úgy, hogy céltárolóként hozzáfűznek egy adatbázist. Ráadásul a felhasználók bármilyen adatátalakítási logikát is megírhatnak az SQL-tárolók növekményes ETL-forgatókönyvének elérése érdekében.
Győződjön meg arról, hogy a folyamat és a tevékenység neve változatlan marad, hogy az ADF rögzíthesse az ellenőrzőpontot, hogy a legutóbbi futtatás során automatikusan megváltoztassa az adatokat. Ha módosítja a feldolgozási sor nevét vagy a tevékenység nevét, az ellenőrzőpont alaphelyzetbe lesz állítva, ami azt eredményezi, hogy Ön elölről kezdi vagy mostantól kapja a változásokat a következő futtatásban. Ha módosítani szeretné a folyamat nevét vagy tevékenységnevét, de továbbra is megtartja az ellenőrzőpontot, hogy az utolsó futtatásból származó módosított adatokat automatikusan megkapja, használja a saját Ellenőrzőpont-kulcsát az adatfolyam-tevékenységben ennek eléréséhez.
A folyamat hibakeresésekor ez a funkció ugyanúgy működik. Vegye figyelembe, hogy az ellenőrzőpont alaphelyzetbe áll, amikor frissíti a böngészőt a hibakeresési futtatás során. Miután elégedett a hibakeresési futtatás folyamatának eredményével, közzéteheti és aktiválhatja a folyamatot. Abban a pillanatban, amikor először aktiválja a közzétett folyamatot, az automatikusan újraindul az elejétől, vagy mostantól módosításokat kap.
A figyelési szakaszban mindig lehetősége van egy folyamat újrafuttatására. Ha így tesz, a módosított adatok mindig a kiválasztott folyamatfuttatás előző ellenőrzőpontjáról lesznek rögzítve.
1. példa:
Ha közvetlenül láncol egy SQL CDC-kompatibilis adatkészletre hivatkozott forrásátalakítást egy leképezési adatfolyam adatbázisára hivatkozva, a rendszer automatikusan alkalmazza a módosításokat az SQL-forráson a céladatbázisra, így könnyen lekérheti az adatbázisok közötti adatreplikációs forgatókönyvet. A fogadóátalakítás frissítési metódusával kiválaszthatja, hogy engedélyezi-e a beszúrást, engedélyezi a frissítést vagy engedélyezi a törlést a céladatbázison. A leképezési adatfolyam példaszkriptje az alábbi módon érhető el.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
2. példa:
Ha az sql CDC-n keresztüli adatreplikáció helyett az ETL-forgatókönyvet szeretné engedélyezni az adatbázis között, kifejezéseket használhat az adatfolyam leképezésében, beleértve az isInsert(1), az isUpdate(1) és az isDelete(1) függvényt a sorok különböző művelettípusokkal való megkülönböztetéséhez. Az alábbi példaszkriptek egyike az adatfolyamok leképezésére egy oszlopból származó érték alapján: 1 a beszúrt sorok jelzésére, 2 a frissített sorok jelzésére, 3 pedig a törölt sorok jelzésére az alsóbb rétegbeli átalakításokhoz a deltaadatok feldolgozásához.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Ismert korlátozás:
- Az ADF csak az SQL CDC nettó módosításait tölti be cdc.fn_cdc_get_net_changes_ keresztül.
Kapcsolódó tartalom
A másolási tevékenység által forrásként és fogadóként támogatott adattárak listáját lásd : Támogatott adattárak és formátumok.