Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tips
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Aliran data tersedia di alur Azure Data Factory dan alur Azure Synapse Analytics. Artikel ini berlaku untuk memetakan aliran data. Jika Anda baru mengenal transformasi, lihat artikel pengantar Mengubah data menggunakan aliran data pemetaan.
Tips
Untuk transformasi yang setara (Dapatkan Data) di Dataflow Gen2, lihat Panduan untuk Dataflow Gen2 untuk memetakan pengguna aliran data.
Transformasi sumber mengonfigurasi sumber data Anda untuk aliran data. Saat Anda mendesain aliran data, langkah pertamanya selalu mengonfigurasi transformasi sumber. Untuk menambahkan sumber, pilih kotak Tambahkan Sumber di kanvas aliran data.
Setiap aliran data memerlukan setidaknya satu transformasi sumber, tetapi Anda dapat menambahkan sumber sebanyak yang diperlukan untuk menyelesaikan transformasi data Anda. Anda dapat menggabungkan sumber-sumber tersebut dengan transformasi join, lookup, atau union.
Setiap transformasi sumber dikaitkan dengan satu himpunan data atau layanan tertaut. Himpunan data menentukan bentuk dan lokasi data yang ingin Anda tulis atau baca. Jika Anda menggunakan himpunan data berbasis file, Anda dapat menggunakan wildcard dan daftar file di sumber Anda untuk bekerja dengan lebih dari satu file sekaligus.
Himpunan data sebaris
Keputusan pertama saat membuat transformasi sumber adalah apakah informasi sumber Anda ditentukan dalam objek himpunan data atau dalam transformasi sumber. Sebagian besar format hanya tersedia dalam satu atau lainnya. Untuk mempelajari cara menggunakan konektor tertentu, lihat dokumen konektor yang sesuai.
Ketika format didukung baik secara sebaris maupun dalam objek kumpulan data, keduanya memiliki keuntungan. Objek data adalah entitas yang dapat digunakan kembali dalam aliran data dan aktivitas lain seperti penyalinan. Entitas yang dapat digunakan kembali ini sangat berguna ketika Anda menggunakan skema yang diperkuat. Himpunan data tidak berbasis di Spark. Terkadang, Anda mungkin perlu mengambil alih pengaturan atau proyeksi skema tertentu dalam transformasi sumber.
Set data internal disarankan saat Anda menggunakan skema fleksibel, instans sumber sekali pakai, atau sumber parameter. Jika sumber Anda memiliki banyak parameterisasi, himpunan data sebaris memungkinkan Anda untuk tidak membuat objek "tiruan". Himpunan data sebaris berbasis di Spark sedangkan propertinya berasal dari aliran data.
Untuk menggunakan himpunan data sebaris, pilih format yang Anda inginkan di pemilih Jenis sumber. Alih-alih memilih himpunan data sumber, pilihlah layanan tertaut yang ingin Anda sambungkan.
Opsi skema
Karena himpunan data sebaris ditentukan di dalam aliran data, tidak ada skema yang ditentukan yang terkait dengan himpunan data sebaris. Pada tab Proyeksi, Anda dapat mengimpor skema data sumber dan menyimpan skema tersebut sebagai proyeksi sumber Anda. Pada tab ini, Anda menemukan tombol "Opsi skema" yang memungkinkan Anda menentukan perilaku layanan penemuan skema ADF.
- Gunakan skema yang diproyeksikan: Opsi ini berguna saat Anda memiliki sejumlah besar file sumber yang dipindai ADF sebagai sumber Anda. Perilaku default ADF adalah menemukan skema setiap file sumber. Tetapi jika Anda memiliki proyeksi yang telah ditentukan sebelumnya yang sudah disimpan dalam transformasi sumber Anda, Anda dapat mengaturnya menjadi 'true' dan ADF melewatkan penemuan otomatis untuk setiap skema. Dengan opsi ini diaktifkan, transformasi sumber dapat membaca semua file dengan cara yang jauh lebih cepat, menerapkan skema yang telah ditentukan sebelumnya ke setiap file.
- Izinkan penyimpangan skema: Aktifkan penyimpangan skema sehingga aliran data Anda memungkinkan kolom baru yang belum ditentukan dalam skema sumber.
- Validasi skema: Mengatur opsi ini menyebabkan aliran data gagal jika ada kolom dan jenis yang ditentukan dalam proyeksi tidak cocok dengan skema data sumber yang ditemukan.
- Menyimpulkan jenis kolom yang menyimpang: Saat kolom baru yang menyimpang diidentifikasi oleh ADF, kolom baru tersebut diubah ke jenis data yang sesuai menggunakan inferensi jenis otomatis ADF.
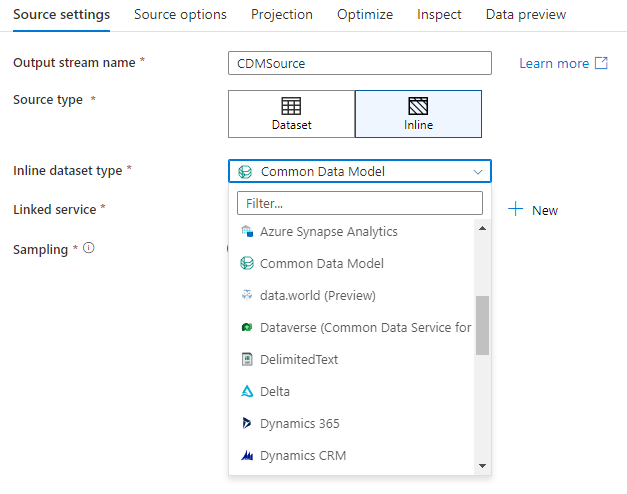
Workspace DB (hanya untuk ruang kerja Synapse)
Di ruang kerja Azure Synapse, opsi tambahan ada dalam transformasi sumber aliran data yang disebut Workspace DB. Ini memungkinkan Anda untuk langsung memilih database ruang kerja dari jenis apa pun yang tersedia sebagai data sumber Anda tanpa memerlukan layanan atau himpunan data tertaut tambahan. Database yang dibuat melalui templat database Azure Synapse juga dapat diakses saat Anda memilih Workspace DB.
Jenis sumber yang didukung
Pemetaan aliran data mengikuti pendekatan ekstrak, memuat, dan mentransformasi (ELT) dan berfungsi dengan himpunan data staging yang disimpan di Azure. Saat ini, himpunan data berikut dapat digunakan dalam transformasi sumber.
Pengaturan khusus untuk konektor ini terletak pada tab Opsi sumber. Contoh skrip informasi dan aliran data pada pengaturan ini terletak di dokumentasi konektor.
alur Azure Data Factory dan Synapse memiliki akses ke lebih dari 90 konektor asli. Untuk menyertakan data dari sumber lain di aliran data Anda, gunakan Aktivitas Salin untuk memuat data tersebut ke salah satu area sementara yang didukung.
Pengaturan sumber
Setelah Anda menambahkan sumber, konfigurasikan melalui tab Pengaturan sumber. Di sini Anda dapat memilih atau membuat himpunan data yang menjadi tujuan sumber Anda. Anda juga dapat memilih opsi skema dan pengambilan sampel untuk data Anda.
Nilai pengembangan untuk parameter himpunan data dapat dikonfigurasi dalam pengaturan debug. (Mode debug harus dinyalakan.)
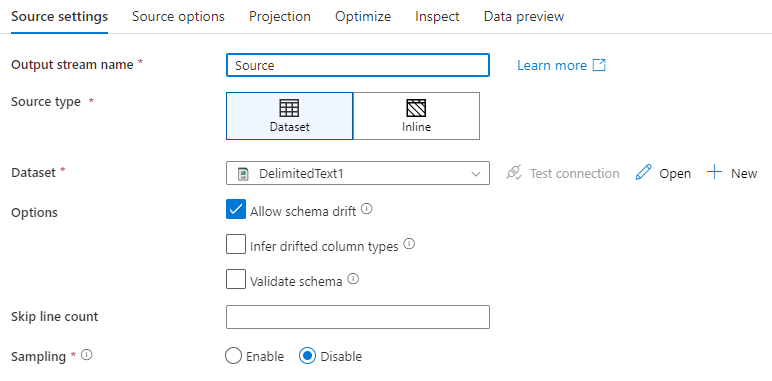
Nama aliran output: Nama transformasi sumber.
Jenis sumber: Pilih apakah Anda ingin menggunakan himpunan data sebaris atau objek himpunan data yang sudah ada.
Koneksi pengujian: Uji apakah layanan Spark aliran data berhasil terhubung ke layanan tertaut yang digunakan dalam himpunan data sumber Anda atau tidak. Mode debug harus menyala agar fitur ini diaktifkan.
Drift skema: Drift skema adalah kemampuan layanan untuk menangani skema fleksibel secara langsung dalam aliran data Anda tanpa perlu mendefinisikan perubahan kolom secara eksplisit.
Pilih kotak centang Izinkan penyimpangan skema jika kolom sumber sering berubah. Setelan ini memungkinkan semua bidang sumber masuk mengalir melalui transformasi ke sink.
Memilih Tentukan tipe kolom yang berubah menginstruksikan layanan untuk mendeteksi dan menentukan tipe data untuk setiap kolom baru yang ditemukan. Jika fitur ini dimatikan, semua kolom yang bergeser berjenis string.
Validasi skema: Jika skema Validasi dipilih, aliran data gagal dijalankan jika data sumber masuk tidak cocok dengan skema himpunan data yang ditentukan.
Lompati jumlah baris: Bidang Lompati Jumlah baris menentukan jumlah baris yang diabaikan di awal himpunan data.
Pengambilan Sampel: Aktifkan Pengambilan Sampel untuk membatasi jumlah baris dari sumber Anda. Gunakan pengaturan ini saat Anda menguji atau mengambil sampel data dari sumber Anda untuk tujuan penelusuran kesalahan. Hal ini sangat berguna ketika mengeksekusi aliran data dalam mode debug dari pipeline.
Untuk memvalidasi bahwa sumber Anda dikonfigurasi dengan benar, aktifkan mode debug dan ambil pratinjau data. Untuk informasi selengkapnya, lihat Mode debug.
Catatan
Saat mode debug diaktifkan, konfigurasi batas baris di pengaturan debug menimpa pengaturan pengambilan sampel di sumber selama pratinjau data.
Opsi sumber
Tab Opsi sumber berisi pengaturan khusus untuk konektor dan format yang dipilih. Untuk informasi dan contoh selengkapnya, lihat dokumentasi konektor yang relevan. Ini termasuk detail seperti tingkat isolasi untuk sumber data yang mendukungnya (seperti SQL Server lokal, Database Azure SQL, dan instans terkelola Azure SQL), dan pengaturan spesifik sumber data lainnya juga.
Proyeksi
Seperti skema dalam himpunan data, proyeksi dalam sumber menentukan kolom data, jenis, dan format dari data sumber. Untuk sebagian besar jenis himpunan data, seperti SQL dan Parquet, proyeksi dalam sumber diperbaiki untuk mencerminkan skema yang ditentukan dalam himpunan data, yang akan bervariasi berdasarkan sumbernya. Saat file sumber Anda tidak diketik dengan kuat (misalnya, file .csv datar, bukan file Parquet), Anda dapat menentukan jenis data untuk setiap bidang dalam transformasi sumber. Gambar berikut menunjukkan contoh proyeksi:
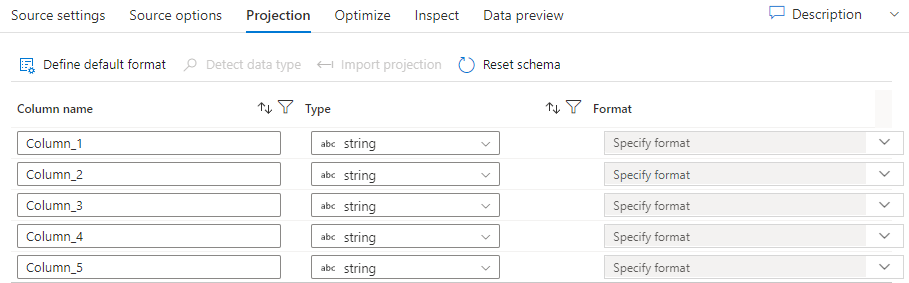
Jika file teks Anda tidak memiliki skema yang ditentukan, pilih Deteksi jenis data sehingga layanan mengambil sampel dan menyimpulkan jenis data. Pilih Tetapkan format default untuk mendeteksi secara otomatis format data default.
Atur ulang skema menyetel ulang proyeksi ke apa yang telah ditentukan dalam himpunan data yang direferensikan.
Timpa skema memungkinkan Anda mengubah jenis data yang diproyeksikan di bagian sumber, dengan menimpa jenis data yang ditentukan oleh skema. Sebagai alternatif, Anda dapat memodifikasi tipe data kolom dalam transformasi kolom turunan hilir. Gunakan transformasi pilihan untuk mengubah nama kolom.
Mengimpor skema
Pilih tombol Impor skema pada tab Proyeksi untuk menggunakan kluster debug aktif untuk membuat proyeksi skema. Tersedia di setiap jenis sumber. Mengimpor skema di sini mengambil alih proyeksi yang ditentukan dalam himpunan data. Objek himpunan data tidak akan diubah.
Mengimpor skema berguna dalam himpunan data seperti Avro dan Azure Cosmos DB yang mendukung struktur data kompleks yang tidak memerlukan definisi skema untuk ada di himpunan data. Untuk himpunan data sebaris, mengimpor skema adalah satu-satunya cara untuk mereferensikan metadata kolom tanpa drift skema.
Mengoptimalkan transformasi sumber
Tab Optimalkan memungkinkan pengeditan informasi partisi di setiap langkah transformasi. Dalam kebanyakan kasus, Gunakan partisi saat ini untuk mengoptimalkan struktur partisi yang ideal untuk sumber.
Jika Anda membaca dari sumber Azure SQL Database, pembagian Source kustom kemungkinan paling cepat membaca data. Layanan membaca kueri besar dengan membuat koneksi ke database Anda secara paralel. Partisi sumber ini dapat dilakukan pada kolom atau dengan menggunakan kueri.
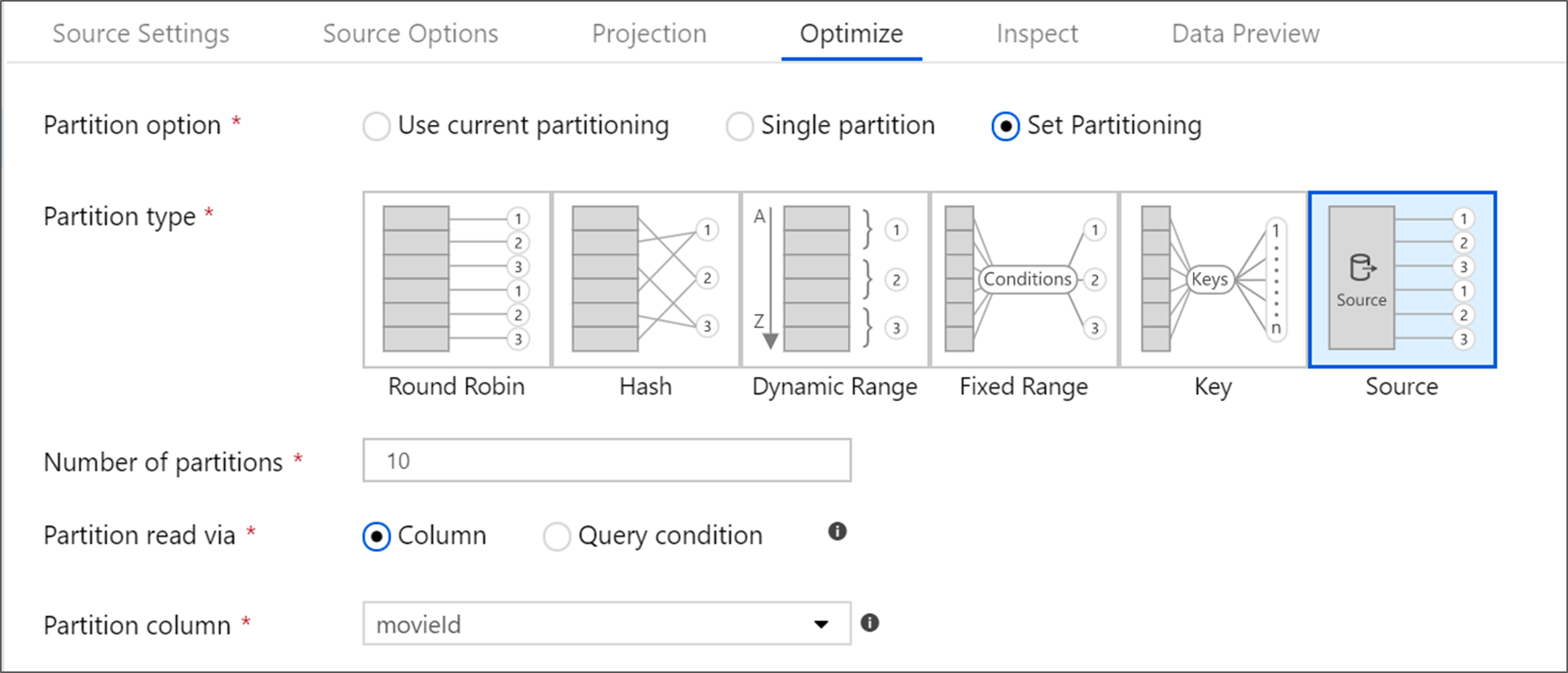
Untuk informasi selengkapnya tentang pengoptimalan dalam alur data pemetaan, lihat tab Optimalkan.
Konten terkait
Mulai membangun aliran data Anda dengan transformasi kolom turunan dan transformasi pilihan.