Menggunakan paket eksternal dengan notebook Jupyter di kluster Apache Spark pada Microsoft Azure HDInsight
Pelajari cara mengonfigurasi Jupyter Notebook di kluster Apache Spark di Microsoft Azure HDInsight untuk menggunakan paket maven Apache eksternal yang disumbangkan komunitas yang tidak disertakan di luar kotak dalam kluster.
Anda dapat mencari repositori Maven untuk daftar lengkap paket yang tersedia. Anda juga bisa mendapatkan daftar paket yang tersedia dari sumber lain. Misalnya, daftar lengkap paket yang berkontribusi komunitas tersedia di Paket Spark.
Dalam artikel ini, Anda akan mempelajari cara menggunakan paket spark-csv dengan Jupyter Notebook.
Prasyarat
Klaster Apache Spark pada HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight.
Terbiasa menggunakan Jupyter Notebook dengan Spark di Microsoft Azure HDInsight. Untuk informasi selengkapnya, lihat Muat data dan menjalankan kueri dengan Apache Spark di Microsoft Azure HDInsight.
Skema URI untuk penyimpanan utama kluster Anda. Skema yang digunakan adalah
wasb://untuk Azure Storage,abfs://untuk Azure Data Lake Storage Gen2 atauadl://untuk Azure Data Lake Storage Gen1. Jika transfer aman diaktifkan untuk Azure Storage atau Data Lake Storage Gen2, URI masing-masing akan menjadiwasbs://atauabfss://. Lihat juga, transfer keamanan.
Menggunakan paket eksternal dengan Jupyter Notebooks
Menavigasi ke
https://CLUSTERNAME.azurehdinsight.net/jupytertempatCLUSTERNAMEnama klaster Spark Anda.Buat notebook baru. Pilih Baru, lalu pilih Spark.
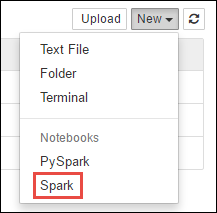
Notebook baru dibuat dan dibuka dengan nama Untitled.pynb. Pilih nama notebook di bagian atas, dan masukkan nama yang bersahabat.
Anda akan menggunakan
%%configuremagic untuk mengonfigurasi buku catatan untuk menggunakan paket eksternal. Di buku catatan yang menggunakan paket eksternal, pastikan Anda memanggil%%configuremagic di sel kode pertama. Ini memastikan bahwa kernel dikonfigurasi untuk menggunakan paket sebelum sesi dimulai.Penting
Jika Anda lupa mengonfigurasi kernel di sel pertama, Anda dapat menggunakan
%%configuredengan parameter-f, tetapi itu akan memulai ulang sesi dan semua kemajuan akan hilang.Versi Azure HDInsight Perintah Untuk Microsoft Azure HDInsight 3.5 dan Microsoft Azure HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Untuk Microsoft Azure HDInsight 3.3 dan Microsoft Azure HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Cuplikan di atas mengharapkan koordinat maven untuk paket eksternal di Repositori Pusat Maven. Dalam cuplikan ini,
com.databricks:spark-csv_2.11:1.5.0adalah koordinat maven untuk paket spark-csv. Begini caramu membuat koordinat untuk sebuah paket.a. Cari paket di Repositori Maven. Untuk artikel ini, kami menggunakan spark-csv.
b. Dari repositori, kumpulkan nilai untuk GroupId, ArtifactId, dan Versi. Pastikan nilai yang Anda kumpulkan cocok dengan kluster Anda. Dalam hal ini, kami menggunakan paket Scala 2.11 dan Spark 1.5.0, tetapi Anda mungkin perlu memilih versi yang berbeda untuk versi Scala atau Spark yang sesuai di kluster Anda. Anda dapat mengetahui versi Scala pada kluster Anda dengan berjalan
scala.util.Properties.versionStringpada kernel Spark Jupyter atau di Apache Spark submit. Anda dapat mengetahui versi Spark di kluster Anda dengan berjalansc.versiondi Jupyter Notebooks.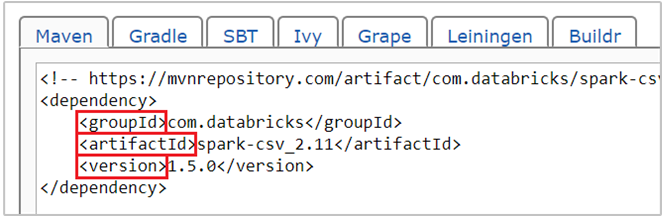
c. Gabungkan tiga nilai, yang dipisahkan oleh titik dua (:).
com.databricks:spark-csv_2.11:1.5.0Menjalankan sel kode dengan
%%configuresihir. Hal ini akan mengonfigurasi sesi Apache Livy yang mendasarinya untuk menggunakan paket yang Anda berikan. Di sel berikutnya di buku catatan, Sekarang Anda bisa menggunakan paket tersebut, seperti yang diperlihatkan di bawah ini.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Untuk Microsoft Azure HDInsight 3.4 ke bawah, Anda harus menggunakan cuplikan berikut.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Anda kemudian dapat menjalankan cuplikan, seperti yang diperlihatkan di bawah ini, untuk menampilkan data dari dataframe yang Anda buat di langkah sebelumnya.
df.show() df.select("Time").count()
Lihat juga
Skenario
- Apache Spark dengan BI: Melakukan analisis data interaktif menggunakan Spark di HDInsight dengan alat BI
- Apache Spark dengan Pembelajaran Mesin: Menggunakan Apache Spark di HDInsight untuk menganalisis suhu bangunan menggunakan data HVAC
- Apache Spark dengan Pembelajaran Mesin: Menggunakan Spark di Microsoft Azure HDInsight untuk memprediksi hasil pemeriksaan makanan
- Analisis log situs web menggunakan Apache Spark di HDInsight
Membuat dan menjalankan aplikasi
- Membuat aplikasi mandiri menggunakan Scala
- Jalankan pekerjaan dari jarak jauh pada kluster Apache Spark menggunakan Apache Livy
Alat dan ekstensi
- Menggunakan paket Python eksternal dengan Jupyter Notebooks di kluster Apache Spark di HDInsight Linux
- Menggunakan HDInsight Tools Plugin untuk IntelliJ IDEA untuk membuat dan mengirimkan aplikasi Spark Scala
- Menggunakan Plugin Alat Microsoft Azure HDInsight untuk IntelliJ IDEA untuk men-debug aplikasi Apache Spark dari jarak jauh
- Menggunakan notebook Apache Zeppelin dengan Apache Spark pada Microsoft Azure HDInsight
- Kernel tersedia untuk Jupyter Notebook di kluster Apache Spark untuk Microsoft Azure HDInsight
- Pasang Jupyter di komputer Anda dan sambungkan ke kluster Microsoft Azure HDInsight Spark
Mengelola sumber daya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk