Gunakan Azure Toolkit untuk IntelliJ untuk men-debug aplikasi Apache Spark dari jarak jauh di HDInsight melalui VPN
Kami merekomendasikan penelusuran kesalahan aplikasi Apache Spark dari jarak jauh melalui SSH. Untuk mengetahui petunjuknya, lihat Men-debug aplikasi Apache Spark dari jarak jauh pada kluster Microsoft Azure HDInsight dengan Azure Toolkit untuk IntelliJ melalui SSH.
Artikel ini menyediakan panduan langkah demi langkah tentang cara menggunakan Alat Microsoft Azure HDInsight di Azure Toolkit untuk IntelliJ untuk mengirimkan pekerjaan Spark pada kluster Microsoft Azure HDInsight Spark, lalu men-debugnya dari jarak jauh dari komputer desktop Anda. Untuk menyelesaikan tugas ini, Anda harus melakukan langkah-langkah tingkat tinggi berikut:
- Buat jaringan virtual Azure situs-ke-situs atau titik-ke-situs. Langkah-langkah dalam dokumen ini mengasumsikan bahwa Anda menggunakan jaringan situs-ke-situs.
- Buat kluster Spark di Microsoft Azure HDInsight yang merupakan bagian dari jaringan virtual situs-ke-situs.
- Verifikasi konektivitas antara simpul kepala kluster dan desktop Anda.
- Buat aplikasi Scala di IntelliJ IDEA, lalu konfigurasikan untuk penelusuran kesalahan jarak jauh.
- Jalankan dan debug aplikasi.
Prasyarat
- Langganan Azure. Untuk informasi selengkapnya, lihat Dapatkan uji coba gratis Azure.
- Kluster Apache Spark di Microsoft Azure HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight.
- Kit pengembangan Oracle Java. Anda dapat memasangnya dari situs web Oracle.
- IDEA IntelliJ. Artikel ini menggunakan versi 2017.1. Anda dapat memasangnya dari situs web JetBrains.
- Alat Microsoft Azure HDInsight di Azure Toolkit untuk IntelliJ. Alat Microsoft Azure HDInsight untuk IntelliJ tersedia sebagai bagian dari Azure Toolkit untuk IntelliJ. Untuk petunjuk tentang cara memasang Azure Toolkit, lihat Pasang Azure Toolkit untuk IntelliJ.
- Masuk ke langganan Azure Anda dari IntelliJ IDEA. Ikuti instruksi dalam Menggunakan Azure Toolkit untuk IntelliJ untuk membuat aplikasi Apache Spark untuk kluster Microsoft Azure HDInsight.
- Solusi sementara pengecualian. Saat menjalankan aplikasi Spark Scala untuk penelusuran kesalahan jarak jauh pada komputer Windows, Anda mungkin mendapatkan pengecualian. Pengecualian ini dijelaskan dalam SPARK-2356 dan terjadi karena file WinUtils.exe hilang di Windows. Untuk mengatasi kesalahan ini, Anda harus mengunduh Winutils.exe ke lokasi seperti C:\WinUtils\bin. Tambahkan variabel lingkungan HADOOP_HOME, lalu set nilai variabel ke C\WinUtils.
Langkah 1: Buat jaringan virtual Azure
Ikuti instruksi dari tautan berikut untuk membuat jaringan virtual Azure, lalu verifikasi konektivitas antara komputer desktop Anda dan jaringan virtual:
- Buat VNet dengan koneksi VPN situs-ke-situs menggunakan portal Microsoft Azure
- Buat VNet dengan koneksi VPN situs-ke-situs menggunakan PowerShell
- Konfigurasikan koneksi titik-ke-situs ke jaringan virtual menggunakan PowerShell
Langkah 2: Buat kluster Microsoft Azure HDInsight Spark
Kami menyarankan agar Anda juga membuat kluster Apache Spark di Microsoft Azure HDInsight yang merupakan bagian dari jaringan virtual Azure yang Anda buat. Gunakan informasi yang tersedia di Buat kluster berbasis Linux di Microsoft Azure HDInsight. Sebagai bagian dari konfigurasi opsional, pilih jaringan virtual Azure yang Anda buat di langkah sebelumnya.
Langkah 3: Verifikasi konektivitas antara simpul kepala kluster dan desktop Anda
Dapatkan alamat IP simpul kepala. Buka antarmuka pengguna Ambari untuk kluster. Dari bilah kluster, pilih Dasbor.
Dari antarmuka pengguna Ambari, pilih Host.

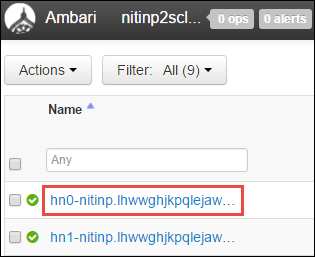
Anda melihat daftar simpul kepala, simpul pekerja, dan simpul zookeeper. Simpul kepala memiliki awalan hn*. Pilih simpul kepala pertama.
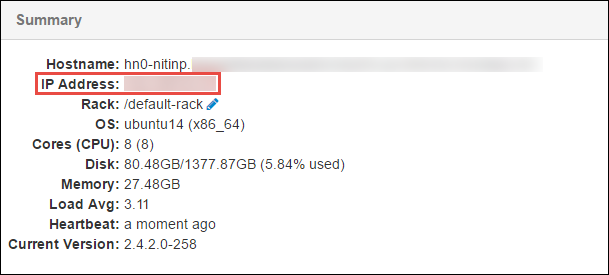
Dari panel Ringkasan di bagian bawah halaman yang terbuka, salin Alamat IP simpul kepala dan Nama Host.
Tambahkan alamat IP dan nama host simpul kepala ke file host di komputer tempat Anda ingin menjalankan dan men-debug pekerjaan Spark dari jarak jauh. Ini memungkinkan Anda untuk berkomunikasi dengan simpul kepala dengan menggunakan alamat IP, serta nama host.
a. Buka file Notepad dengan izin akses yang ditinggikan. Dari menu File, pilih Buka, lalu temukan lokasi file host. Pada komputer Windows, lokasinya adalah C:\Windows\System32\Drivers\etc\hosts.
b. Tambahkan informasi berikut ke file host:
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netDari komputer yang Anda sambungkan ke jaringan virtual Azure yang digunakan oleh kluster Microsoft Azure HDInsight, verifikasi bahwa Anda dapat melakukan ping simpul kepala dengan menggunakan alamat IP, serta nama host.
Gunakan SSH untuk menyambungkan ke simpul kepala kluster dengan mengikuti instruksi di sambungkan ke kluster Microsoft Azure HDInsight menggunakan SSH. Dari simpul kepala kluster, ping alamat IP komputer desktop. Uji konektivitas ke kedua alamat IP yang ditetapkan ke komputer:
- Satu untuk koneksi jaringan
- Satu untuk jaringan virtual Azure
Ulangi langkah-langkah untuk simpul kepala lainnya.
Langkah 4: Buat aplikasi Apache Spark Scala dengan menggunakan Alat Microsoft Azure HDInsight di Azure Toolkit untuk IntelliJ dan konfigurasikan untuk penelusuran kesalahan jarak jauh
Buka IntelliJ IDEA dan buat proyek baru. Dalam kotak dialog Proyek Baru, lakukan hal berikut:
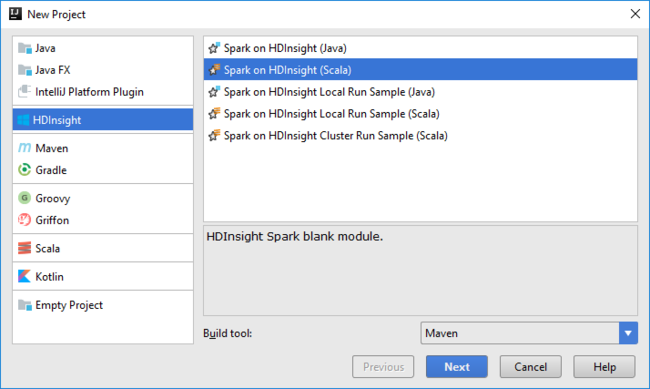
a. Pilih Microsoft Azure HDInsight>Spark di Microsoft Azure HDInsight (Scala).
b. Pilih Selanjutnya.
Dalam kotak dialog Proyek Baru berikutnya, lakukan hal berikut ini, lalu pilih Selesai:
Masukkan nama dan lokasi proyek.
Di daftar tarik-turun Project SDK, pilih Java 1.8 untuk kluster Spark 2.x, atau pilih Java 1.7 untuk kluster Spark 1.x.
Dalam daftar tarik-turun versi Spark, panduan pembuatan proyek Scala mengintegrasikan versi yang tepat untuk Spark SDK dan Scala SDK. Jika versi kluster Spark lebih lama dari 2.0, pilih Spark 1.x. Jika tidak, pilih Spark2.x. Contoh ini menggunakan Spark 2.0.2 (Scala 2.11.8).
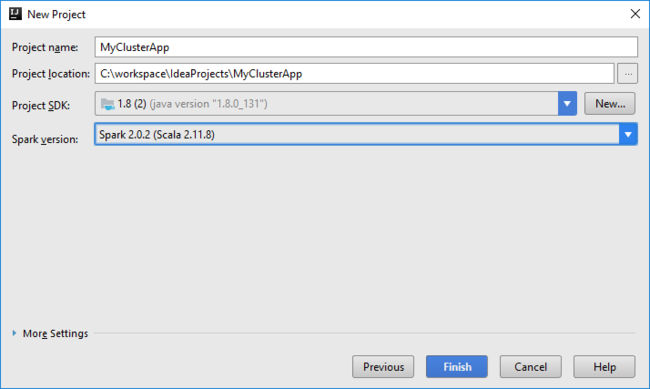
Proyek Spark secara otomatis membuat artefak untuk Anda. Untuk menampilkan artefak, lakukan hal berikut:
a. Dari menu File, pilih Struktur Proyek.
b. Dalam kotak Struktur Proyek, pilih Artefak untuk menampilkan artefak default yang dibuat. Anda juga dapat membuat artefak Anda sendiri dengan memilih tanda plus (+).
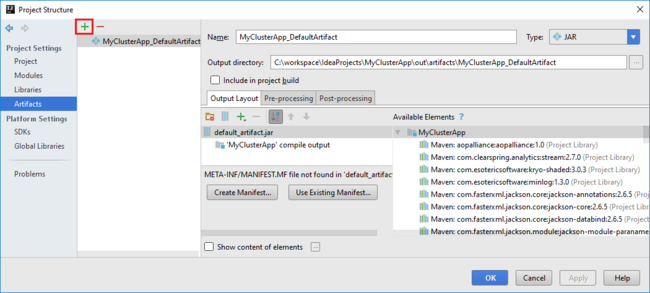
Tambahkan pustaka ke proyek Anda. Untuk menambahkan pustaka, lakukan hal berikut ini:
a. Klik kanan nama proyek di pohon proyek, dan lalu pilih Buka Pengaturan Modul.
b. Dalam kotak dialog Struktur Proyek, pilih Pustaka, pilih simbol (+), lalu pilih Dari Maven.
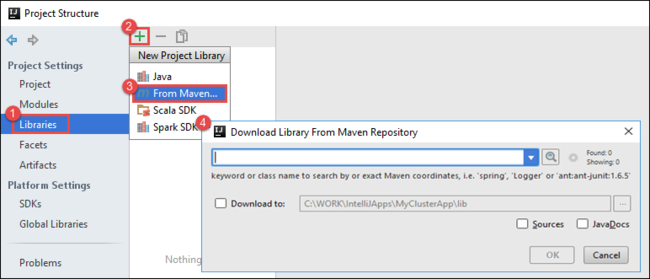
c. Di Pustaka Pengunduhan dari Repositori Maven, cari dan tambahkan pustaka berikut ini:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Salin
yarn-site.xmldancore-site.xmldari simpul kepala kluster dan tambahkan ke proyek. Gunakan perintah berikut untuk menyalin file. Anda dapat menggunakan Cygwin untuk menjalankan perintah berikutscpuntuk menyalin file dari simpul kepala kluster:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Karena kami sudah menambahkan alamat IP simpul kepala kluster dan nama host untuk file host di desktop, kita dapat
scpmenggunakan perintah dengan cara berikut:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Untuk menambahkan file-file ini ke proyek Anda, salin ke dalam folder /src di pohon proyek Anda, misalnya
<your project directory>\src.Perbarui file
core-site.xmluntuk membuat perubahan berikut:a. Ganti kunci terenkripsi. File
core-site.xmlmencakup kunci terenkripsi ke akun penyimpanan yang terkait dengan kluster. Padacore-site.xmlfile yang Anda tambahkan ke proyek, ganti kunci terenkripsi dengan kunci penyimpanan aktual yang terkait dengan akun penyimpanan default. Untuk informasi selengkapnya, lihat Mengelola kunci akses akun penyimpanan.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Hapus entri berikut dari
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Simpan file.
Tambahkan kelas utama untuk aplikasi Anda. Dari Explorer Proyek, klik kanan src, arahkan ke Baru, lalu pilih kelas Scala.
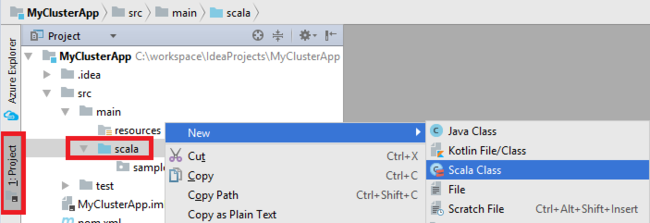
Pada kotak dialog Buat Kelas Scala Baru, berikan nama, pilih Objek dalam kotak Jenis, lalu pilih OK.
Pada
MyClusterAppMain.scalafile, tempelkan kode berikut. Kode ini membuat konteks Spark dan membukaexecuteJobmetode dariSparkSampleobjek.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Ulangi langkah 8 dan 9 untuk menambahkan objek Scala baru yang disebut
*SparkSample. Tambahkan kode berikut ke kelas. Kode ini membaca data dari HVAC.csv (tersedia di semua kluster Spark Microsoft Azure HDInsight). Ini mengambil baris yang hanya memiliki satu digit di kolom ketujuh dalam file CSV, dan kemudian menulis output ke /HVACOut pada bawah kontainer penyimpanan default untuk kluster.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Ulangi langkah 8 dan 9 untuk menambahkan kelas baru yang disebut
RemoteClusterDebugging. Kelas ini mengimplementasikan kerangka kerja uji Spark yang digunakan untuk men-debug aplikasi. Tambahkan kode berikut ke kelasRemoteClusterDebugging:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Ada beberapa hal penting yang perlu diperhatikan:
- Untuk
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar"), pastikan JAR rakitan Spark tersedia pada penyimpanan kluster pada jalur yang ditentukan. - Untuk
setJars, tentukan lokasi tempat JAR artefak dibuat. Biasanya, itu<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- Untuk
Di
*RemoteClusterDebuggingkelas, klik kanantestkata kunci, lalu pilih Buat Konfigurasi RemoteClusterDebugging.
Dalam kotak dialog Buat Konfigurasi RemoteClusterDebugging, berikan nama untuk konfigurasi tersebut, lalu pilih Jenis pengujian sebagai nama Uji. Biarkan semua nilai lainnya sebagai pengaturan default. Pilih Terapkan, lalu pilih OK.
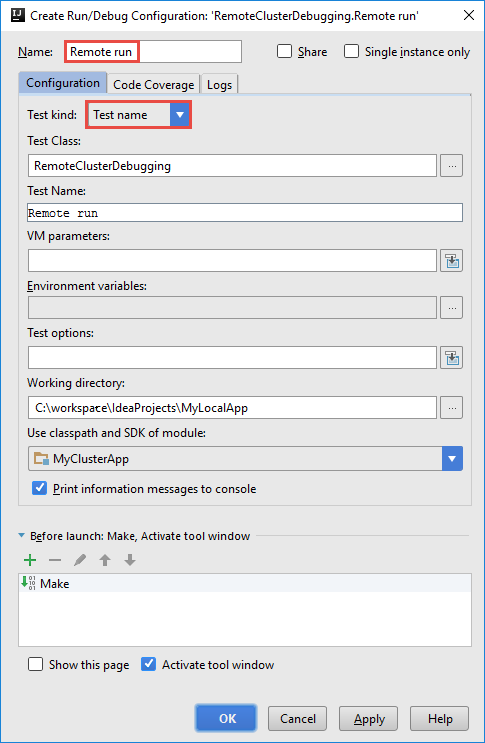
Sekarang Anda akan melihat daftar turun bawah Konfigurasi eksekusi jarak jauh di bilah menu.

Langkah 5: Jalankan aplikasi dalam mode debug
Dalam proyek IntelliJ IDEA Anda,
SparkSample.scalabuka dan buat titik henti di sebelahnyaval rdd1. Di menu pop-up Buat Titik Henti, pilih garis dalam fungsi executeJob.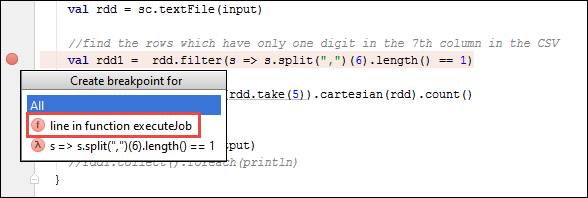
Untuk menjalankan aplikasi, pilih tombol Debug Run di samping daftar turun bawah konfigurasi Eksekusi Jarak jauh.

Saat eksekusi program mencapai titik henti, Anda akan melihat tab Debugger di panel bawah.
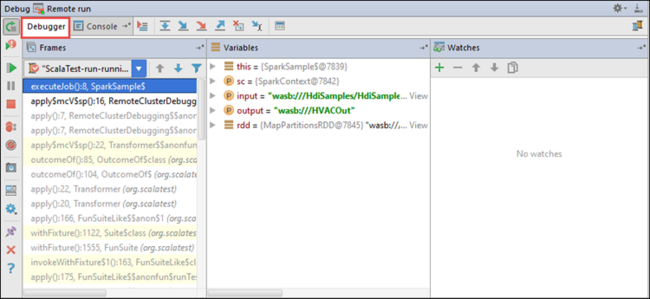
Untuk menambahkan sebuah jam, pilih ikon (+).
Dalam contoh ini, aplikasi rusak sebelum variabel
rdd1dibuat. Dengan menggunakan jam ini, kita dapat melihat lima baris pertama dalamrddvariabel. Pilih Masukkan.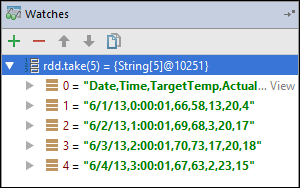
Apa yang Anda lihat di gambar sebelumnya adalah bahwa pada waktu proses, Anda mungkin meminta data lebih dari satu terabyte dan debug bagaimana aplikasi Anda berkembang. Misalnya, dalam output yang ditampilkan di gambar sebelumnya, Anda dapat melihat bahwa baris pertama output adalah sebuah header. Berdasarkan output ini, Anda dapat mengubah kode aplikasi untuk melompati baris header, jika perlu.
Sekarang Anda dapat memilih ikon Lanjutkan Program untuk melanjutkan dengan menjalankan aplikasi Anda.
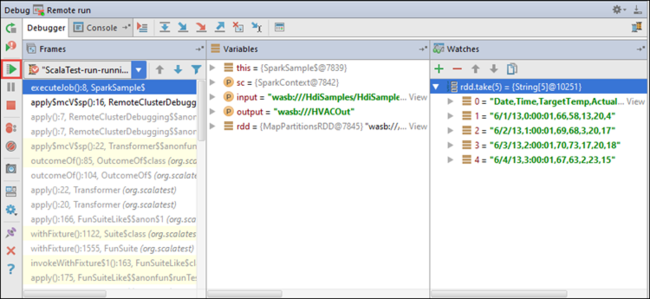
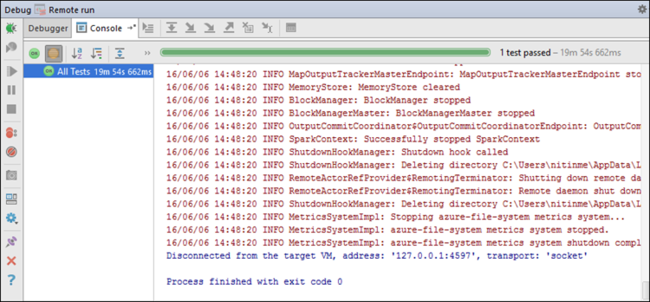
Jika sebuah aplikasi berhasil diselesaikan, Anda akan melihat output seperti berikut:
Langkah berikutnya
Skenario
- Apache Spark dengan BI: Melakukan analisis data interaktif dengan menggunakan Spark di Microsoft Azure HDInsight dengan alat BI
- Apache Spark dengan Azure Machine Learning: Gunakan Apache Spark di Microsoft Azure HDInsight untuk menganalisis suhu bangunan menggunakan data HVAC
- Apache Spark dengan Pembelajaran Mesin: Menggunakan Spark di Microsoft Azure HDInsight untuk memprediksi hasil pemeriksaan makanan
- Analisis log situs web menggunakan Apache Spark di HDInsight
Membuat dan menjalankan aplikasi
- Membuat aplikasi mandiri menggunakan Scala
- Jalankan pekerjaan dari jarak jauh pada kluster Apache Spark menggunakan Apache Livy
Alat dan ekstensi
- Gunakan Alat Azure for IntelliJ untuk membuat aplikasi Apache Spark untuk kluster Microsoft Azure HDInsight
- Menggunakan Azure Toolkit untuk IntelliJ untuk men-debug aplikasi Apache Spark dari jarak jauh melalui SSH
- Gunakan Alat Azure for Eclipse untuk membuat aplikasi Apache Spark untuk kluster Microsoft Azure HDInsight
- Gunakan notebook Apache Zeppelin dengan Apache Spark pada Microsoft Azure HDInsight
- Kernel tersedia untuk Jupyter Notebook di kluster Apache Spark untuk Microsoft Azure HDInsight
- Menggunakan paket eksternal dengan Jupyter Notebooks
- Pasang Jupyter di komputer Anda dan sambungkan ke kluster Microsoft Azure HDInsight Spark
Mengelola sumber daya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk