Opsi big data pada platform Microsoft SQL Server
Berlaku untuk: ![]() SQL Server 2019 (15.x) dan versi yang lebih baru
SQL Server 2019 (15.x) dan versi yang lebih baru
Kluster Besar Microsoft SQL Server 2019 adalah add-on untuk Platform SQL Server yang memungkinkan Anda menyebarkan kluster kontainer SQL Server, Spark, dan HDFS yang dapat diskalakan yang berjalan di Kubernetes. Komponen-komponen ini berjalan berdampingan untuk memungkinkan Anda membaca, menulis, dan memproses big data menggunakan pustaka Transact-SQL atau Spark, memungkinkan Anda untuk dengan mudah menggabungkan dan menganalisis data relasional bernilai tinggi Anda dengan big data volume tinggi non-relasional. Kluster big data juga memungkinkan Anda untuk memvirtualisasi data dengan PolyBase, sehingga Anda dapat mengkueri data dari SQL Server eksternal, Oracle, Teradata, MongoDB, dan sumber data lainnya menggunakan tabel eksternal. Add-on Kluster Besar Microsoft SQL Server 2019 menyediakan ketersediaan tinggi untuk instans master SQL Server dan semua database dengan menggunakan teknologi grup ketersediaan AlwaysOn.
Add-on SQL Server 2019 Kluster Big Data berjalan secara lokal dan di cloud menggunakan platform Kubernetes, untuk setiap penyebaran standar Kubernetes. Selain itu, add-on SQL Server 2019 Kluster Big Data terintegrasi dengan Direktori Aktif dan mencakup kontrol akses berbasis peran untuk memenuhi kebutuhan keamanan dan kepatuhan perusahaan Anda.
Penghentian add-on Kluster Big Data SQL Server 2019
Pada 28 Februari 2025, kami akan menghentikan SQL Server 2019 Kluster Big Data. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman.
Perubahan pada dukungan PolyBase di SQL Server
Terkait dengan penghentian Kluster Big Data SQL Server 2019 adalah beberapa fitur yang terkait dengan kueri peluasan skala.
Fitur grup peluasan skala PolyBase microsoft SQL Server telah dihentikan. Fungsionalitas grup peluasan skala dihapus dari produk di SQL Server 2022 (16.x). Versi dalam pasar SQL Server 2019, SQL Server 2017, dan SQL Server 2016, terus mendukung fungsionalitas hingga akhir masa pakai produk tersebut. Virtualisasi data PolyBase terus didukung penuh sebagai fitur peningkatan skala di SQL Server.
Sumber data eksternal Cloudera (CDP) dan Hortonworks (HDP) Hadoop juga akan dihentikan untuk semua versi SQL Server di pasar dan tidak termasuk dalam SQL Server 2022. Dukungan untuk sumber data eksternal terbatas pada versi produk dalam dukungan mainstream oleh vendor masing-masing. Anda disarankan untuk menggunakan integrasi penyimpanan objek baru yang tersedia di SQL Server 2022 (16.x).
Di SQL Server 2022 (16.x) dan versi yang lebih baru, pengguna harus mengonfigurasi sumber data eksternal mereka untuk menggunakan konektor baru saat menyambungkan ke Azure Storage. Tabel berikut ini meringkas perubahan:
| Sumber Data Eksternal | Dari | Untuk |
|---|---|---|
| Azure Blob Storage | wasb[s] |
abs |
| ADLS Gen2 | abfs[s] |
adls |
Catatan
Azure Blob Storage (abs) akan memerlukan penggunaan Tanda Tangan Akses Bersama (SAS) untuk SECRET dalam kredensial lingkup database. Di SQL Server 2019 dan yang lebih lama, wasb[s] konektor menggunakan Kunci Akun Penyimpanan dengan kredensial cakupan database saat mengautentikasi ke akun Azure Storage.
Memahami arsitektur Kluster Big Data untuk opsi penggantian dan migrasi
Untuk membuat solusi penggantian untuk sistem penyimpanan dan pemrosesan Big Data, penting untuk memahami apa yang Kluster Big Data SQL Server 2019 berikan, dan arsitekturnya dapat membantu menginformasikan pilihan Anda. Arsitektur kluster big data adalah sebagai berikut:

Arsitektur ini menyediakan pemetaan fungsionalitas berikut:
| Komponen | Keuntungan |
|---|---|
| Kubernetes | Orkestrator sumber terbuka untuk menyebarkan dan mengelola aplikasi berbasis kontainer dalam skala besar. Menyediakan metode deklaratif untuk membuat dan mengontrol ketahanan, redundansi, dan portabilitas untuk seluruh lingkungan dengan skala elastis. |
| Pengontrol Kluster Big Data | Menyediakan manajemen dan keamanan untuk kluster. Ini berisi layanan kontrol, penyimpanan konfigurasi, dan layanan tingkat kluster lainnya seperti Kibana, Grafana, dan Elastic Search. |
| Kumpulan Komputasi | Menyediakan sumber daya komputasi ke kluster. Ini berisi simpul yang menjalankan SQL Server pada pod Linux. Pod dalam kumpulan komputasi dibagi menjadi instans SQL Compute untuk tugas pemrosesan tertentu. Komponen ini juga menyediakan Virtualisasi Data menggunakan PolyBase untuk mengkueri sumber data eksternal tanpa memindahkan atau menyalin data. |
| Kumpulan Data | Menyediakan persistensi data untuk kluster. Kumpulan data terdiri dari satu atau beberapa pod yang menjalankan SQL Server di Linux. Ini digunakan untuk menyerap data dari kueri SQL atau pekerjaan Spark. |
| Kumpulan Penyimpanan | Kumpulan penyimpanan terdiri dari pod kumpulan penyimpanan yang terdiri dari SQL Server di Linux, Spark, dan HDFS. Semua simpul penyimpanan dalam kluster big data adalah anggota kluster HDFS. |
| Kumpulan Aplikasi | Memungkinkan penyebaran aplikasi pada kluster big data dengan menyediakan antarmuka untuk membuat, mengelola, dan menjalankan aplikasi. |
Untuk informasi selengkapnya tentang fungsi-fungsi ini, lihat Memperkenalkan Kluster Big Data SQL Server.
Opsi penggantian fungsionalitas untuk Big Data dan SQL Server
Fungsi data operasional yang difasilitasi oleh SQL Server di dalam Kluster Big Data dapat digantikan oleh SQL Server lokal dalam konfigurasi hibrid atau menggunakan platform Microsoft Azure. Microsoft Azure menawarkan pilihan database relasional, NoSQL, dan dalam memori yang dikelola sepenuhnya, yang mencakup mesin milik dan sumber terbuka, agar sesuai dengan kebutuhan pengembang aplikasi modern. Manajemen infrastruktur—termasuk skalabilitas, ketersediaan, dan keamanan—otomatis, menghemat waktu dan uang Anda, dan memungkinkan Anda untuk fokus membangun aplikasi sementara database yang dikelola Azure membuat pekerjaan Anda lebih sederhana dengan memunculkan wawasan performa melalui kecerdasan tersemat, penskalaan tanpa batas, dan mengelola ancaman keamanan. Untuk informasi selengkapnya, lihat Database Azure.
Titik keputusan berikutnya adalah lokasi komputasi dan penyimpanan data untuk analitik. Dua pilihan arsitektur adalah penyebaran dalam cloud dan hibrid. Sebagian besar beban kerja analitik dapat dimigrasikan ke platform Microsoft Azure. Data "lahir di cloud" (berasal dari aplikasi berbasis Cloud) adalah kandidat utama untuk teknologi ini, dan layanan pergerakan data dapat memigrasikan data lokal skala besar dengan aman dan cepat. Untuk informasi selengkapnya tentang opsi pergerakan data, lihat Solusi transfer data.
Microsoft Azure memiliki sistem dan sertifikasi yang memungkinkan pemrosesan data dan data yang aman di berbagai alat. Untuk informasi selengkapnya tentang sertifikasi ini, lihat Pusat Kepercayaan.
Catatan
Platform Microsoft Azure menyediakan tingkat keamanan yang sangat tinggi, beberapa sertifikasi untuk berbagai industri, dan menghormati kedaulatan data untuk persyaratan pemerintah. Microsoft Azure juga memiliki platform cloud khusus untuk beban kerja pemerintah. Keamanan saja tidak boleh menjadi titik keputusan utama untuk sistem lokal. Anda harus mengevaluasi tingkat keamanan yang disediakan oleh Microsoft Azure dengan cermat sebelum memutuskan untuk mempertahankan solusi big data Anda secara lokal.
Dalam opsi arsitektur dalam cloud, semua komponen berada di Microsoft Azure. Tanggung jawab Anda terletak pada data dan kode yang Anda buat untuk penyimpanan dan pemrosesan beban kerja Anda. Opsi tersebut dibahas secara lebih rinci dalam artikel ini.
- Opsi ini berfungsi paling baik untuk berbagai komponen untuk penyimpanan dan pemrosesan data, dan ketika Anda ingin fokus pada konstruksi data dan pemrosesan daripada infrastruktur.
Dalam opsi arsitektur hibrid, beberapa komponen dipertahankan secara lokal dan komponen lainnya ditempatkan di Penyedia Cloud. Konektivitas antara keduanya dirancang untuk penempatan data yang berlebihan pemrosesan terbaik.
- Opsi ini berfungsi paling baik ketika Anda memiliki investasi yang cukup besar dalam teknologi dan arsitektur lokal, tetapi Anda ingin menggunakan penawaran Microsoft Azure, atau ketika Anda memiliki target pemrosesan dan aplikasi yang berada di tempat atau untuk audiens di seluruh dunia.
Untuk informasi selengkapnya tentang membangun arsitektur yang dapat diskalakan, lihat Membangun sistem yang dapat diskalakan untuk data besar-besaran.
Di cloud
Azure SQL dengan Synapse
Anda dapat mengganti fungsionalitas SQL Server Kluster Big Data dengan menggunakan satu atau beberapa opsi database Azure SQL untuk data operasional, dan Microsoft Azure Synapse untuk beban kerja analitik Anda.
Microsoft Azure Synapse adalah layanan analitik perusahaan yang mempercepat waktu untuk wawasan di seluruh gudang data dan sistem big data, menggunakan pemrosesan terdistribusi dan konstruksi data. Azure Synapse menyatukan teknologi SQL yang digunakan dalam pergudangan data perusahaan, teknologi Spark yang digunakan untuk big data, Alur untuk integrasi data dan ETL/ELT, dan integrasi mendalam dengan layanan Azure lainnya seperti Power BI, Cosmos DB, dan Azure Pembelajaran Mesin.
Gunakan Microsoft Azure Synapse sebagai pengganti SQL Server 2019 Kluster Big Data saat Anda perlu:
- Gunakan model sumber daya tanpa server dan khusus. Untuk performa dan biaya yang dapat diprediksi, buat kumpulan SQL khusus guna mencadangkan kekuatan pemrosesan untuk data yang disimpan dalam tabel SQL.
- Proses beban kerja yang tidak dienkripsi atau "meledak", akses titik akhir SQL tanpa server yang selalu tersedia.
- Gunakan kemampuan streaming bawaan untuk memasukkan data dari sumber data awan ke dalam tabel SQL.
- Integrasikan AI dengan SQL menggunakan model pembelajaran mesin untuk menilai data menggunakan fungsi T-SQL PREDICT.
- Gunakan model ML dengan algoritma SparkML dan integrasi Azure Pembelajaran Mesin untuk Apache Spark 2.4 yang didukung untuk Linux Foundation Delta Lake.
- Gunakan model sumber daya yang disederhanakan yang membebaskan Anda dari kekhawatirkan mengelola kluster.
- Memproses data yang memerlukan start-up Spark yang cepat dan penskalakan otomatis yang agresif.
- Memproses data using.NET untuk Spark memungkinkan Anda menggunakan kembali keahlian C# dan kode .NET yang ada dalam aplikasi Spark.
- Bekerja dengan tabel yang ditentukan pada file di data lake, yang dikonsumsi dengan mulus oleh Spark atau Apache Hive.
- Gunakan SQL dengan Spark untuk langsung menjelajahi dan menganalisis file Parquet, CSV, TSV, dan JSON yang disimpan di data lake.
- Aktifkan pemuatan data yang cepat dan dapat diskalakan antara database SQL dan Spark.
- Menyerap data dari 90+ sumber data.
- Aktifkan ETL "Bebas Kode" dengan aktivitas Aliran data.
- Mengatur notebook, pekerjaan Spark, prosedur tersimpan, skrip SQL, dan banyak lagi.
- Pantau sumber daya, penggunaan, dan pengguna di seluruh SQL dan Spark.
- Gunakan kontrol akses berbasis peran untuk menyederhanakan akses ke sumber daya analitik.
- Tulis kode SQL atau Spark dan integrasikan dengan proses CI/CD perusahaan.
Arsitektur Microsoft Azure Synapse adalah sebagai berikut:

Untuk informasi selengkapnya tentang Microsoft Azure Synapse, lihat Apa itu Azure Synapse Analytics?
Azure SQL plus Azure Pembelajaran Mesin
Anda dapat mengganti fungsionalitas SQL Server Kluster Big Data dengan menggunakan satu atau beberapa opsi database Azure SQL untuk data operasional, dan Pembelajaran Mesin Microsoft Azure untuk beban kerja prediktif Anda.
Azure Pembelajaran Mesin adalah layanan berbasis cloud yang dapat digunakan untuk semua jenis pembelajaran mesin, dari ML klasik hingga pembelajaran mendalam, diawasi, dan pembelajaran tanpa pengawasan. Apakah Anda lebih suka menulis kode Python atau R dengan SDK atau bekerja dengan opsi tanpa kode/kode rendah di studio,Anda dapat membangun, melatih, dan melacak pembelajaran mesin dan model pembelajaran mendalam di Ruang Azure Machine Learning. Dengan Azure Pembelajaran Mesin, Anda dapat memulai pelatihan di komputer lokal Anda lalu meluaskan skala ke cloud. Layanan ini juga beroperasi dengan alat sumber terbuka deep learning dan reinforcement populer seperti PyTorch, TensorFlow, scikit-learn, dan Ray RLlib.
Gunakan Pembelajaran Mesin Microsoft Azure sebagai pengganti Kluster Big Data SQL Server 2019 saat Anda membutuhkan:
- Lingkungan web berbasis desainer untuk Pembelajaran Mesin: modul drag-n-drop untuk membangun eksperimen Anda lalu menyebarkan alur di lingkungan kode rendah.
- Jupyter notebooks: gunakan contoh notebook kami atau buat notebook Anda sendiri untuk menggunakan SDK kami untuk sampel Python untuk pembelajaran mesin Anda.
- Skrip R atau buku catatan tempat Anda menggunakan SDK untuk R untuk menulis kode Anda sendiri atau menggunakan modul R di perancang.
- Akselerator Solusi Banyak Model dibangun di Azure Pembelajaran Mesin dan memungkinkan Anda melatih, mengoperasikan, dan mengelola ratusan atau bahkan ribuan model pembelajaran mesin.
- Ekstensi pembelajaran mesin untuk Visual Studio Code (pratinjau) memberi Anda lingkungan pengembangan berfungsi lengkap untuk membangun dan mengelola proyek pembelajaran mesin Anda.
- Antarmuka Baris Perintah (CLI) pembelajaran mesin, Azure Pembelajaran Mesin menyertakan ekstensi Azure CLI yang menyediakan perintah untuk mengelola dengan sumber daya Azure Pembelajaran Mesin dari baris perintah.
- Integrasi dengan kerangka kerja open-source seperti PyTorch, TensorFlow, dan scikit-learn dan banyak lagi untuk pelatihan, penyebaran, dan pengelolaan proses pembelajaran mesin end-to-end.
- Pembelajaran penguatan dengan Ray RLlib.
- MLflow untuk melacak metrik dan menyebarkan model atau Kubeflow untuk membangun alur kerja end-to-end.
Arsitektur penyebaran Pembelajaran Mesin Microsoft Azure adalah sebagai berikut:

Untuk informasi selengkapnya tentang Pembelajaran Mesin Microsoft Azure, lihat Cara kerja Azure Pembelajaran Mesin.
Azure SQL dari Databricks
Anda dapat mengganti fungsionalitas SQL Server Kluster Big Data dengan menggunakan satu atau beberapa opsi database Azure SQL untuk data operasional, dan Microsoft Azure Databricks untuk beban kerja analitik Anda.
Azure Databricks adalah platform analitik data yang dioptimalkan untuk platform layanan cloud Microsoft Azure. Azure Databricks menawarkan dua lingkungan untuk mengembangkan aplikasi intensif data: Azure Databricks SQL Analytics dan Azure Databricks Workspace.
Azure Databricks SQL Analytics menyediakan platform yang mudah digunakan untuk analis yang ingin menjalankan kueri SQL di data lake mereka, membuat beberapa jenis visualisasi untuk menjelajahi hasil kueri dari perspektif yang berbeda, dan membangun dan berbagi dasbor.
Ruang Kerja Azure Databricks menyediakan ruang kerja interaktif yang memungkinkan kolaborasi antara teknisi data, ilmuwan data, dan insinyur pembelajaran mesin. Untuk alur big data, data (mentah atau terstruktur) diserap ke Azure melalui Azure Data Factory dalam batch, atau dialirkan mendekati real-time menggunakan Apache Kafka, Event Hubs, atau IoT Hub. Data ini disimpan di data lake untuk penyimpanan jangka panjang, di Azure Blob Storage, atau di Azure Data Lake Storage. Sebagai bagian dari alur kerja analitik Anda, gunakan Azure Databricks untuk membaca data dari beberapa sumber data dan mengubahnya menjadi insight terobosan menggunakan Spark.
Gunakan Microsoft Azure Databricks sebagai pengganti SQL Server 2019 Kluster Big Data saat Anda membutuhkan:
- Kluster Spark yang dikelola sepenuhnya dengan Spark SQL dan DataFrames.
- Streaming untuk pemrosesan dan analisis data real time untuk aplikasi analitik dan interaktif, Mengintegrasikan dengan HDFS, Flume, dan Kafka.
- Akses ke pustaka MLlib, yang terdiri dari algoritma dan utilitas pembelajaran umum, termasuk klasifikasi, regresi, pengklusteran, pemfilteran kolaboratif, pengurangan dimensi, dan primitif pengoptimalan yang mendasar.
- Dokumentasi kemajuan Anda di notebook di R, Python, Scala, atau SQL.
- Visualisasi data dalam beberapa langkah, menggunakan alat yang sudah dikenal seperti Matplotlib, ggplot, atau d3.
- Dasbor interaktif untuk membuat laporan dinamis.
- GraphX, untuk Grafik dan komputasi grafik untuk cakupan kasus penggunaan yang luas dari analitik kognitif hingga eksplorasi data.
- Pembuatan kluster dalam hitungan detik, dengan kluster penskalaan otomatis dinamis, membagikannya di seluruh tim.
- Akses kluster terprogram menggunakan REST API.
- Akses instan ke fitur Apache Spark terbaru dengan setiap rilis.
- API Spark Core: Mencakup dukungan untuk R, SQL, Python, Scala, dan Java.
- Ruang kerja interaktif untuk eksplorasi dan visualisasi.
- Titik akhir SQL yang dikelola sepenuhnya di cloud.
- Kueri SQL yang berjalan pada titik akhir SQL yang dikelola sepenuhnya berukuran sesuai dengan latensi kueri dan jumlah pengguna bersamaan.
- Integrasi dengan MICROSOFT Entra ID (sebelumnya Azure Active Directory).
- Akses berbasis peran untuk izin pengguna yang menenangkan untuk notebook, kluster, pekerjaan, dan data.
- SLA kelas perusahaan.
- Dasbor untuk berbagi wawasan, menggabungkan visualisasi dan teks untuk berbagi wawasan yang diambil dari kueri Anda.
- Pemberitahuan membantu Anda memantau dan mengintegrasikan, dan pemberitahuan saat bidang yang dikembalikan oleh kueri memenuhi ambang batas. Gunakan peringatan untuk memantau bisnis Anda atau mengintegrasikannya dengan alat untuk memulai alur kerja seperti onboarding pengguna atau tiket dukungan.
- Keamanan perusahaan, termasuk integrasi ID Microsoft Entra, kontrol berbasis peran, dan SLA yang melindungi data dan bisnis Anda.
- Integrasi dengan layanan Azure dan database dan penyimpanan Azure termasuk penyimpanan Synapse Analytics, Cosmos DB, Data Lake Store, dan Blob.
- Integrasi dengan Power BI dan alat BI lainnya, seperti Tableau Software.
Arsitektur penyebaran Microsoft Azure Databricks adalah sebagai berikut:
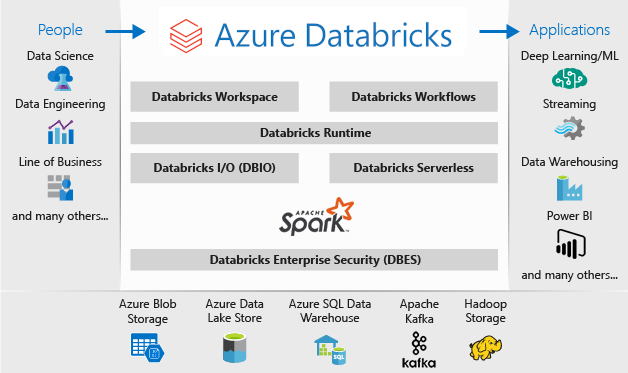
Untuk informasi selengkapnya tentang Microsoft Azure Databricks, lihat Apa itu Databricks Ilmu Data & Engineering?
Hibrid
Fabric Mirrored Database
Sebagai pengalaman replikasi data, Pencerminan Database di Fabric adalah solusi bernilai rendah dan latensi rendah untuk menyatukan data dari berbagai sistem ke dalam satu platform analitik. Anda dapat terus mereplikasi data estate yang ada langsung ke OneLake Fabric, termasuk data dari Azure SQL Database, Snowflake, dan Cosmos DB.
Dengan data terbaru dalam format yang dapat dikueri di OneLake, Anda sekarang dapat menggunakan semua layanan berbeda di Fabric, seperti menjalankan analitik dengan Spark, menjalankan notebook, rekayasa data, memvisualisasikan melalui Laporan Power BI, dan banyak lagi.
Mirroring in Fabric memberikan pengalaman mudah untuk mempercepat waktu ke nilai untuk wawasan dan keputusan, dan untuk memecah silo data antara solusi teknologi, tanpa mengembangkan proses Ekstraksi, Transformasi, dan Muat (ETL) yang mahal untuk memindahkan data.
Dengan Mirroring in Fabric, Anda tidak perlu mengumpulkan layanan yang berbeda dari beberapa vendor. Sebagai gantinya, Anda dapat menikmati produk yang sangat terintegrasi, end-to-end, dan mudah digunakan yang dirancang untuk menyederhanakan kebutuhan analitik Anda, dan dibangun untuk keterbukaan dan kolaborasi antara solusi teknologi yang dapat membaca format tabel Delta Lake sumber terbuka.
Untuk informasi selengkapnya, lihat:
- Database cermin Microsoft Fabric
- Pemantauan database cermin Microsoft Fabric
- Menjelajahi data di database Cermin Anda menggunakan Microsoft Fabric
- Apa itu Microsoft Fabric?
- Data model dalam model semantik Power BI default di Microsoft Fabric
- Apa itu titik akhir analitik SQL untuk Lakehouse?
- Danau Langsung
Menggunakan SQL Server 2022 dengan Azure Synapse Link untuk SQL
SQL Server 2022 (16.x) berisi fitur baru yang memungkinkan konektivitas antara tabel SQL Server dan platform Microsoft Azure Synapse, Azure Synapse Link untuk SQL. Azure Synapse Link untuk SQL Server 2022 (16.x) menyediakan umpan perubahan otomatis yang menangkap perubahan dalam SQL Server dan memuatnya ke Azure Synapse Analytics. Ini memberikan analisis mendekati real-time dan pemrosesan transaksional dan analitik hibrid dengan dampak minimal pada sistem operasional. Setelah data berada di Synapse, Anda dapat menggabungkannya dengan banyak sumber data yang berbeda terlepas dari ukuran, skala, atau formatnya dan menjalankan analitik yang kuat di atasnya menggunakan pilihan Azure Pembelajaran Mesin, Spark, atau Power BI. Karena umpan perubahan otomatis hanya mendorong apa yang baru atau berbeda, transfer data terjadi jauh lebih cepat dan sekarang memungkinkan wawasan hampir real-time, dengan dampak minimal pada performa database sumber di SQL Server 2022 (16.x).
Untuk beban kerja analitik Anda secara operasional dan bahkan banyak, SQL Server dapat menangani ukuran database besar-besaran - untuk informasi selengkapnya tentang spesifikasi kapasitas maksimum untuk SQL Server, lihat Batas kapasitas komputasi berdasarkan edisi SQL Server. Menggunakan beberapa Instans SQL Server pada komputer terpisah dengan permintaan T-SQL yang dipartisi memungkinkan lingkungan peluasan skala untuk aplikasi.
Menggunakan PolyBase memungkinkan instans SQL Server Anda untuk mengkueri data dengan T-SQL langsung dari SQL Server, Oracle, Teradata, MongoDB, dan Cosmos DB tanpa menginstal perangkat lunak koneksi klien secara terpisah. Anda juga dapat menggunakan konektor ODBC generik pada instans berbasis Microsoft Windows untuk terhubung ke penyedia tambahan menggunakan driver ODBC pihak ketiga. PolyBase memungkinkan kueri T-SQL menggabungkan data dari sumber eksternal ke tabel relasional dalam instans SQL Server. Ini memungkinkan data untuk tetap berada di lokasi dan format aslinya. Anda dapat memvirtualisasi data eksternal melalui instans SQL Server, sehingga dapat dikueri di tempat seperti tabel lain di SQL Server. SQL Server 2022 (16.x) juga memungkinkan kueri ad hoc dan pencadangan/pemulihan melalui Object-Store (menggunakan opsi penyimpanan perangkat keras atau perangkat lunak S3-API).
Dua arsitektur referensi umum adalah menggunakan SQL Server pada server yang berdiri sendiri untuk kueri data terstruktur dan instalasi terpisah dari sistem non-relasional peluasan skala (seperti Apache Hadoop atau Apache Spark) untuk Tautan lokal ke Synapse, dan opsi lainnya adalah menggunakan sekumpulan kontainer dalam kluster Kubernetes dengan semua komponen untuk solusi Anda.
Microsoft SQL Server di Windows, Apache Spark, dan penyimpanan objek lokal
Anda dapat menginstal SQL Server di Windows atau Linux, dan meningkatkan arsitektur perangkat keras, menggunakan kemampuan kueri penyimpanan objek SQL Server 2022 (16.x) dan fitur PolyBase untuk mengaktifkan kueri di semua data dalam sistem Anda.
Menginstal dan mengonfigurasi platform peluasan skala seperti Apache Hadoop atau Apache Spark memungkinkan kueri data non-relasional dalam skala besar. Menggunakan sekumpulan sistem Object-Storage terpusat yang mendukung S3-API memungkinkan SQL Server 2022 (16.x) dan Spark untuk mengakses kumpulan data yang sama di semua sistem.
Konektor Microsoft Apache Spark untuk SQL Server dan Azure SQL juga memiliki yang memungkinkan Anda untuk mengkueri data langsung dari SQL Server menggunakan Pekerjaan Spark. Untuk informasi selengkapnya tentang konektor Apache Spark untuk SQL Server dan Azure SQL, lihat Konektor Apache Spark: SQL Server & Azure SQL.
Anda juga dapat menggunakan sistem orkestrasi kontainer Kubernetes untuk penyebaran Anda. Ini memungkinkan arsitektur deklaratif yang dapat berjalan secara lokal atau di Cloud apa pun yang mendukung Kubernetes atau platform Red Hat OpenShift. Untuk mempelajari selengkapnya tentang menyebarkan SQL Server ke lingkungan Kubernetes, lihat Menyebarkan kluster kontainer SQL Server di Azure atau menonton Menyebarkan SQL Server 2019 di Kubernetes.
Gunakan SQL Server dan Hadoop/Spark lokal sebagai pengganti SQL Server 2019 Kluster Big Data saat Anda perlu:
- Pertahankan seluruh solusi lokal
- Gunakan perangkat keras khusus untuk semua bagian solusi
- Akses data relasional dan non-relasional dari arsitektur yang sama, di kedua arah
- Berbagi satu set data non-relasional antara SQL Server dan sistem non-relasional peluasan skala
Lakukan migrasi
Setelah Memilih lokasi (In-Cloud atau Hybrid) untuk migrasi, Anda harus menimbang waktu henti dan vektor biaya untuk menentukan apakah Anda menjalankan sistem baru dan memindahkan data dari sistem sebelumnya ke yang baru secara real time (migrasi berdampingan) atau pencadangan dan pemulihan, atau awal baru sistem dari sumber data yang ada (migrasi di tempat).
Keputusan Anda selanjutnya adalah menulis ulang fungsionalitas saat ini dalam sistem Anda menggunakan pilihan arsitektur baru atau memindahkan sebanyak mungkin kode ke sistem baru. Meskipun pilihan sebelumnya dapat memakan waktu lebih lama, ini memungkinkan Anda untuk menggunakan metode, konsep, dan keuntungan baru yang disediakan arsitektur baru. Dalam hal ini, akses data dan peta fungsionalitas adalah upaya perencanaan utama yang harus Anda fokuskan.
Jika Anda berencana untuk memigrasikan sistem saat ini dengan sedikit perubahan kode mungkin, kompatibilitas bahasa adalah fokus utama Anda untuk perencanaan.
Migrasi kode
Langkah Anda selanjutnya adalah mengaudit kode yang digunakan sistem saat ini dan perubahan apa yang perlu dijalankan terhadap lingkungan baru.
Ada dua vektor utama untuk migrasi kode yang perlu dipertimbangkan:
- Sumber dan sink
- Migrasi fungsionalitas
Sumber dan sink
Tugas pertama dalam migrasi kode adalah mengidentifikasi metode koneksi sumber data, string, atau API yang digunakan kode untuk mengakses data yang diimpor, jalurnya, dan tujuan akhirnya. Dokumentasikan sumber tersebut dan buat peta ke lokasi arsitektur baru.
- Jika solusi saat ini menggunakan sistem alur untuk memindahkan data melalui sistem, petakan sumber arsitektur, langkah, dan sink baru ke komponen alur.
- Jika solusi baru juga mengganti arsitektur alur , perlakukan sistem sebagai penginstalan baru untuk tujuan perencanaan, bahkan jika Anda menggunakan kembali perangkat keras atau platform cloud sebagai penggantinya.
Migrasi fungsionalitas
Pekerjaan paling kompleks yang diperlukan dalam migrasi adalah mereferensikan, memperbarui, atau membuat dokumentasi fungsionalitas sistem saat ini. Jika Anda merencanakan peningkatan di tempat dan mencoba mengurangi jumlah penulisan ulang kode sebanyak mungkin, langkah ini membutuhkan waktu paling lama.
Namun, migrasi dari teknologi sebelumnya sering kali merupakan waktu yang optimal untuk memperbarui diri Anda pada kemajuan terbaru dalam teknologi dan memanfaatkan konstruksi yang disediakannya. Seringkali Anda dapat memperoleh lebih banyak keamanan, performa, pilihan fitur, dan bahkan pengoptimalan biaya dengan penulisan ulang sistem Anda saat ini.
Dalam kedua kasus, Anda memiliki dua faktor utama yang terlibat dalam migrasi: kode dan bahasa yang didukung sistem baru, dan pilihan sekeliling pergerakan data. Biasanya, Anda harus dapat mengubah string koneksi dari kluster big data saat ini ke instans SQL Server dan lingkungan Spark. Setiap informasi koneksi data dan cutover kode harus minimal.
Jika Anda membayangkan penulisan ulang fungsionalitas Anda saat ini, petakan pustaka, paket, dan DLL baru ke arsitektur yang Anda pilih untuk migrasi Anda. Anda akan menemukan daftar setiap pustaka, bahasa, dan fungsi yang ditawarkan setiap solusi dalam referensi dokumentasi yang ditampilkan di bagian sebelumnya. Petakan tersangka atau bahasa yang tidak didukung dan rencanakan penggantian dengan arsitektur yang dipilih.
Opsi migrasi data
Ada dua pendekatan umum untuk pergerakan data dalam sistem analitik skala besar. Yang pertama adalah membuat proses "cutover" di mana sistem asli terus memproses data, dan data tersebut digulung menjadi sekumpulan sumber data laporan agregat yang lebih kecil. Sistem baru kemudian dimulai dengan data baru dan digunakan sejak tanggal migrasi dan seterusnya.
Dalam beberapa kasus, semua data perlu berpindah dari sistem warisan ke sistem baru. Dalam hal ini, Anda dapat memasang penyimpanan file asli dari SQL Server Kluster Big Data jika sistem baru mendukungnya dan kemudian menyalin data sepotong-sepotong ke sistem baru, atau Anda dapat membuat pemindahan fisik.
Memigrasikan data Anda saat ini dari SQL Server 2019 Kluster Big Data ke sistem lain sangat bergantung pada dua faktor: lokasi data Anda saat ini, dan tujuannya adalah lokal atau ke cloud.
Migrasi data lokal
Untuk migrasi lokal ke lokal, Anda dapat memigrasikan data SQL Server dengan strategi pencadangan dan pemulihan, atau Anda dapat menyiapkan replikasi untuk memindahkan beberapa atau semua data relasional Anda. SQL Server Integration Services juga dapat digunakan untuk menyalin data dari SQL Server ke lokasi lain. Untuk informasi selengkapnya tentang memindahkan data dengan SSIS, lihat SQL Server Integration Services.
Untuk data HDFS di lingkungan Kluster Big Data SQL Server Anda saat ini, pendekatan standarnya adalah memasang data ke Kluster Spark yang berdiri sendiri, dan menggunakan proses Object Storage untuk memindahkan data sehingga instans SQL Server 2022 (16.x) dapat mengaksesnya atau membiarkannya apa adanya dan terus memprosesnya dengan Pekerjaan Spark.
Migrasi data dalam cloud
Untuk data yang terletak di penyimpanan cloud atau lokal, Anda dapat menggunakan Azure Data Factory, yang memiliki lebih dari 90 konektor untuk alur transfer lengkap, dengan penjadwalan, pemantauan, pemberitahuan, dan layanan lainnya. Untuk informasi selengkapnya tentang Azure Data Factory, lihat Apa itu Azure Data Factory?
Jika Anda ingin memindahkan data dalam jumlah besar dengan aman dan cepat dari data estate lokal Anda ke Microsoft Azure, Anda dapat menggunakan Layanan Impor/Ekspor Azure. Layanan Impor/Ekspor Azure digunakan untuk mengimpor data dalam jumlah besar dengan aman ke penyimpanan Azure Blob dan Azure Files dengan mengirim drive disk ke pusat data Azure. Layanan ini juga dapat digunakan untuk mentransfer data dari penyimpanan Azure Blob ke drive disk dan dikirim ke situs lokal Anda. Data dari satu atau beberapa drive disk dapat diimpor ke penyimpanan Azure Blob atau Azure Files. Untuk data dalam jumlah yang sangat besar, menggunakan layanan ini bisa menjadi jalur tercepat.
Jika Anda ingin mentransfer data menggunakan disk drive yang disediakan oleh Microsoft, Anda dapat menggunakan Azure Data Box Disk untuk mengimpor data ke Azure. Untuk informasi selengkapnya, lihat Apa itu layanan Impor/Ekspor Azure?
Untuk informasi selengkapnya tentang pilihan ini dan keputusan yang menyertainya, lihat Menggunakan Azure Data Lake Storage Gen1 untuk persyaratan big data.