Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita.
Questo articolo illustra come usare l'attività Copy nelle pipeline di Azure Data Factory o Synapse Analytics per copiare i dati da e in Database di Azure per MySQL, e usare Flusso di dati per trasformare i dati in Database di Azure per MySQL. Per altre informazioni, vedere gli articoli introduttivi per Azure Data Factory e Synapse Analytics.
Questo connettore è specializzato per
Per copiare i dati da un database MySQL generico in locale o nel cloud, usare il Connettore MySQL.
Prerequisiti
Questo avvio rapido richiede le risorse e la configurazione indicate di seguito come punto di partenza:
- Un server singolo di Database di Azure per MySQL esistente o un server flessibile MySQL con accesso pubblico o endpoint privato.
- Abilitare Consentire l'accesso pubblico da qualsiasi servizio Azure all'interno di Azure a questo server nella pagina di rete del server MySQL . Ciò consentirà di usare Studio di Data Factory.
Funzionalità supportate
Questo connettore di Database di Azure per MySQL è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività Copy (origine/sink) | ① ② | ✓ |
| Flusso di dati di mapping (origine/sink) | ① | ✓ |
| Attività Lookup | (1) (2) | ✓ |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento di copia dati
- Portale di Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Modello di Azure Resource Manager
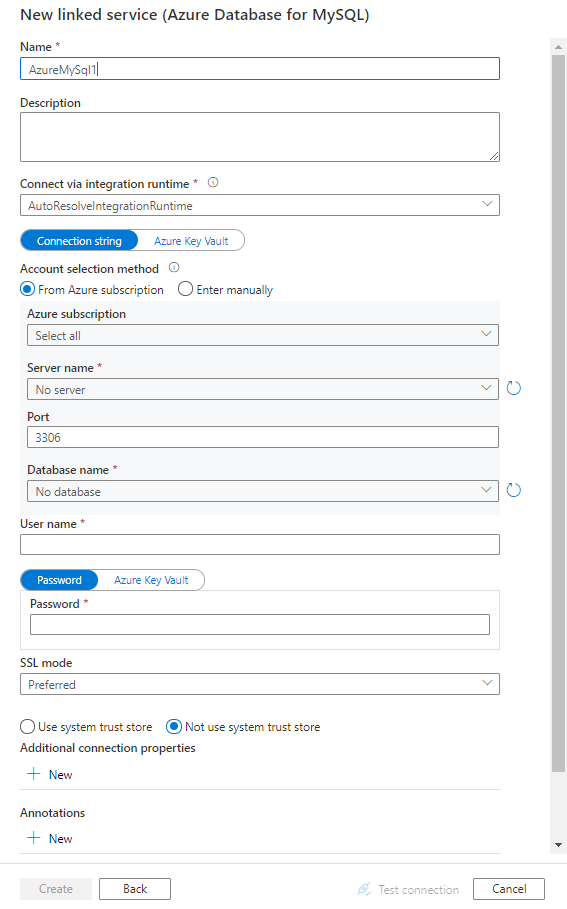
Creare un servizio collegato a Database di Azure per MySQL usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Database di Azure per MySQL nell'interfaccia utente del portale di Azure.
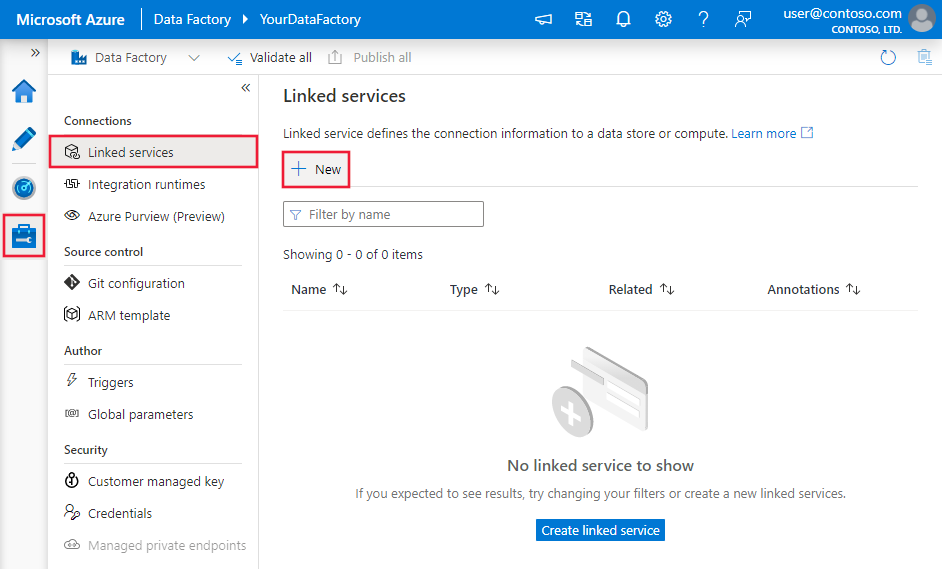
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare MySQL e selezionare il connettore Database di Azure per MySQL.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà usate per definire entità di data factory specifiche in un connettore del database Azure per MySQL.
Proprietà del servizio collegato
Per il servizio collegato del database di Azure per MySQL sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| type | La proprietà type deve essere impostata su: AzureMySql | Sì |
| connectionString | Specifica le informazioni necessarie per connettersi all'istanza del database di Azure per MySQL. È anche possibile inserire la password in Azure Key Vault ed eseguire lo spostamento forzato dei dati della configurazione password all'esterno della stringa di connessione. Vedere gli esempi seguenti e l'articolo Archiviare le credenziali in Azure Key Vault per altri dettagli. |
Sì |
| connectVia | Il runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare il runtime di integrazione di Azure o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Una stringa di connessione tipica è Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>. Altre proprietà che è possibile impostare per il case:
| Proprietà | Descrizione | Opzioni | Obbligatoria |
|---|---|---|---|
| SSLMode | Questa opzione specifica se il driver usa la crittografia TLS e verifica la connessione a MySQL. Ad esempio SSLMode=<0/1/2/3/4>. |
DISABLED (0) / PREFERRED (1) (impostazione predefinita) / REQUIRED (2) / VERIFY_CA (3) / VERIFY_IDENTITY (4) | No |
| UseSystemTrustStore | Questa opzione specifica se usare o meno un certificato CA dall'archivio di attendibilità di sistema o da un file PEM specificato. Ad esempio UseSystemTrustStore=<0/1>;. |
Abilitato (1) / Disabilitato (0) (impostazione predefinita) | No |
Esempio:
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: archiviare la password in Azure Key Vault
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati del database di Azure per MySQL.
Per copiare dati dal database di Azure per MySQL, impostare la proprietà type del set di dati su AzureMySqlTable. Sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su AzureMySqlTable | Sì |
| tableName | Nome della tabella nel database MySQL. | No (se nell'origine dell'attività è specificato "query") |
Esempio
{
"name": "AzureMySQLDataset",
"properties": {
"type": "AzureMySqlTable",
"linkedServiceName": {
"referenceName": "<Azure MySQL linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione offre un elenco delle proprietà supportate da origine e sink di Database di Azure per MySQL.
Database di Azure per MySQL come origine
Per copiare i dati da Database di Azure per MySQL, sono supportate le proprietà seguenti nella sezione source dell'attività Copy:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su: AzureMySqlSource | Sì |
| query | Usare la query SQL personalizzata per leggere i dati. Ad esempio "SELECT * FROM MyTable". |
No (se nel set di dati è specificato "tableName") |
| queryCommandTimeout | Tempo di attesa prima del timeout della richiesta di query. Il valore predefinito è 120 minuti (02:00:00) | No |
Esempio:
"activities":[
{
"name": "CopyFromAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure MySQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureMySqlSource",
"query": "<custom query e.g. SELECT * FROM MyTable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Database di Azure per MySQL come sink
Per copiare i dati in Database di Azure per MySQL, nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| type | La proprietà type del sink dell'attività Copy deve essere impostata su AzureMySqlSink | Sì |
| preCopyScript | Specificare una query SQL per l'attività Copy da eseguire prima di scrivere i dati nel Database di Azure per MySQL in ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati. | No |
| writeBatchSize | Inserisce i dati nella tabella Database di Azure per MySQL quando la dimensione del buffer raggiunge writeBatchSize. Il valore consentito è un integer che rappresenta il numero di righe. |
No (il valore predefinito è 10.000) |
| writeBatchTimeout | Tempo di attesa per l'operazione di inserimento batch da completare prima del timeout. I valori consentiti sono un intervallo di tempo. Ad esempio "00:30:00" (30 minuti). |
No, il valore predefinito è 00:00:30 |
Esempio:
"activities":[
{
"name": "CopyToAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure MySQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureMySqlSink",
"preCopyScript": "<custom SQL script>",
"writeBatchSize": 100000
}
}
}
]
Proprietà del flusso di dati per mapping
Durante la trasformazione dei dati in un flusso di dati per mapping è possibile leggere e scrivere in tabelle di Database di Azure per MySQL. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping. È possibile scegliere di usare un set di Database di Azure per MySQL o un set di dati inline come tipo di origine e sink.
Trasformazione origine
La tabella seguente elenca le proprietà supportate dall'origine di Database di Azure per MySQL. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Obbligatoria | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Tabella | Se si seleziona Tabella come input, il flusso di dati recupera tutti i dati dalla tabella specificata nel set di dati. | No | - |
(solo per set di dati inline) tableName |
| Query | Se si seleziona Query come input, specificare una query SQL per recuperare i dati dall'origine, il che esegue l'override di ogni tabella specificata nel set di dati. L'uso delle query è un ottimo metodo per ridurre il numero di righe per test o ricerche. La clausola Order By non è supportata, ma è possibile impostare un'istruzione SELECT FROM completa. È possibile usare anche funzioni di tabella definite dall'utente. select * from udfGetData() è una funzione definita dall'utente in SQL che restituisce una tabella che è possibile usare nel flusso di dati. Esempio di query: select * from mytable where customerId > 1000 and customerId < 2000 o select * from "MyTable". |
No | String | query |
| Procedura memorizzata | Se si seleziona Stored procedure come input, specificare un nome della stored procedure per leggere i dati dalla tabella di origine, oppure selezionare Aggiorna per chiedere al servizio di individuare i nomi delle procedure. | Sì, se si seleziona Stored procedure come input | String | procedureName |
| Parametri della procedura | Se si seleziona Stored procedure come input, specificare i parametri di input per la stored procedure nell'ordine impostato nella procedura, oppure selezionare Importa per importare tutti i parametri della procedura usando il modulo @paraName. |
No | Array | inputs |
| Dimensioni dei batch | Specificare una dimensione del batch per suddividere i dati di grandi dimensioni in batch. | No | Integer | batchSize |
| Livello di isolamento | Scegliere uno dei livelli di isolamento seguenti: - Read Committed - Read Uncommitted (impostazione predefinita) - Lettura ripetibile -Serializzabile - None (livello di isolamento ignorato) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Esempio di script di origine di Database di Azure per MySQL
Quando si usa Database di Azure per MySQL come tipo di origine, lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzureMySQLSource
Trasformazione sink
La tabella seguente elenca le proprietà supportate dal sink di Database di Azure per MySQL. È possibile modificare queste proprietà nella scheda Opzioni sink.
| Nome | Descrizione | Obbligatoria | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Metodo di aggiornamento | Specificare le operazioni consentite nella destinazione del database. Per impostazione predefinita, sono consentiti solo gli inserimenti. Per operazioni di aggiornamento, upsert o eliminazione di righe, è necessaria una trasformazione Altera riga perché i tag siano applicati alle righe per queste azioni. |
Sì |
true o false |
deletable insertable aggiornabile upsertable |
| Colonne chiave | Per operazioni di aggiornamento, upsert ed eliminazione, è necessario impostare una o più colonne chiave per determinare quale riga modificare. Il nome della colonna selezionato come chiave verrà usato come parte dell'operazione di aggiornamento, upsert ed eliminazione successiva. Pertanto, è necessario selezionare una colonna esistente nel mapping sink. |
No | Array | chiavi |
| Ignora scrittura colonne chiave | Se si desidera non scrivere il valore nella colonna chiave, selezionare "Ignora la scrittura di colonne chiave". | No |
true o false |
skipKeyWrites |
| azione Tabella | determina se ricreare o rimuovere tutte le righe dalla tabella di destinazione prima della scrittura. - Nessuno: Non verrà effettuata alcuna azione sulla tabella. - Ricrea: la tabella verrà eliminata e ricreata. Questa opzione è obbligatoria se si crea una nuova tabella in modo dinamico. - Tronca: verranno rimosse tutte le righe della tabella di destinazione. |
No |
true o false |
recreate truncate |
| Dimensioni dei batch | Specificare il numero di righe scritte in ogni batch. Dimensioni batch più grandi migliorano l'ottimizzazione della compressione e della memoria, ma rischiano di causare eccezioni di memoria insufficiente durante la memorizzazione nella cache dei dati. | No | Integer | batchSize |
| Pre e post-script SQL | Specificare script SQL a più righe che verranno eseguiti prima (pre-elaborazione) e dopo (post-elaborazione) la scrittura dei dati nel database sink. | No | String | preSQLs postSQLs |
Suggerimento
- È consigliabile suddividere singoli script batch con più comandi in più batch.
- Possono essere eseguite come parte di un batch solo le istruzioni DDL (Data Definition Language) e DML (Data Manipulation Language) che restituiscono un semplice conteggio di aggiornamento. Per altre informazioni, vedere Esecuzione di operazioni batch
Abilita l'estrazione incrementale: usare questa opzione per indicare ad Azure Data Factory di elaborare solo le righe modificate dall'ultima esecuzione della pipeline.
Colonna incrementale: quando si usa la funzionalità di estrazione incrementale, è necessario scegliere la colonna data/ora o numerica da usare come filigrana nella tabella di origine.
Inizia a leggere dall'inizio: l'impostazione di questa opzione con l'estrazione incrementale indicherà ad ADF di leggere tutte le righe alla prima esecuzione di una pipeline con l'estrazione incrementale attivata.
Esempio di script di sink di Database di Azure per MySQL
Quando si usa Database di Azure per MySQL come tipo di sink, lo script del flusso di dati associato è:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureMySQLSink
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Mapping dei tipi di dati per il database di Azure per MySQL
Quando si copiano i dati dal Database di Azure per MySQL, vengono usati i mapping seguenti tra i tipi di dati MySQL e i tipi di dati provvisori usati internamente dal servizio. Vedere Mapping dello schema e del tipo di dati per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink.
| Tipo di dati del database di Azure per MySQL | Tipo di dati del servizio provvisorio |
|---|---|
bigint |
Int64 |
bigint unsigned |
Decimal |
bit |
Boolean |
bit(M), M>1 |
Byte[] |
blob |
Byte[] |
bool |
Int16 |
char |
String |
date |
Datetime |
datetime |
Datetime |
decimal |
Decimal, String |
double |
Double |
double precision |
Double |
enum |
String |
float |
Single |
int |
Int32 |
int unsigned |
Int64 |
integer |
Int32 |
integer unsigned |
Int64 |
long varbinary |
Byte[] |
long varchar |
String |
longblob |
Byte[] |
longtext |
String |
mediumblob |
Byte[] |
mediumint |
Int32 |
mediumint unsigned |
Int64 |
mediumtext |
String |
numeric |
Decimal |
real |
Double |
set |
String |
smallint |
Int16 |
smallint unsigned |
Int32 |
text |
String |
time |
TimeSpan |
timestamp |
Datetime |
tinyblob |
Byte[] |
tinyint |
Int16 |
tinyint unsigned |
Int16 |
tinytext |
String |
varchar |
String |
year |
Int32 |
Contenuti correlati
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, vedere Archivi dati supportati.