Richtlijnen voor Power BI-modellering voor Power Platform
Microsoft Dataverse is het standaardgegevensplatform voor veel Microsoft-producten voor zakelijke toepassingen, waaronder Dynamics 365 Customer Engagement - en Power Apps-canvas-apps, en ook Dynamics 365 Customer Voice (voorheen Microsoft Forms Pro), Power Automate-goedkeuringen, Power Apps-portals en andere.
Dit artikel bevat richtlijnen voor het maken van een Power BI-gegevensmodel dat verbinding maakt met Dataverse. Hierin worden verschillen beschreven tussen een Dataverse-schema en een geoptimaliseerd Power BI-schema. Het biedt richtlijnen voor het uitbreiden van de zichtbaarheid van uw zakelijke toepassingsgegevens in Power BI.
Vanwege het gemak van de installatie, snelle implementatie en wijdverspreide acceptatie slaat Dataverse een toenemend aantal gegevens op in omgevingen binnen organisaties en beheert deze. Dat betekent dat er nog meer behoefte is aan het integreren van analyses met deze processen. Verkoopkansen zijn onder andere:
- Rapporteer over alle Dataverse-gegevens die verder gaan dan de beperkingen van de ingebouwde grafieken.
- Bieden eenvoudige toegang tot relevante, contextgefilterde rapporten binnen een specifieke record.
- Verbeter de waarde van Dataverse-gegevens door deze te integreren met externe gegevens.
- Profiteer van de ingebouwde kunstmatige intelligentie (AI) van Power BI zonder dat u complexe code hoeft te schrijven.
- Verhoog de acceptatie van Power Platform-oplossingen door hun nut en waarde te vergroten.
- Lever de waarde van de gegevens in uw app aan besluitvormers van het bedrijf.
Power BI Verbinding maken naar Dataverse
Verbinding maken Power BI naar Dataverse bestaat uit het maken van een Power BI-gegevensmodel. U kunt kiezen uit drie methoden om een Power BI-model te maken.
- Gegevens importeren met behulp van de Dataverse-connector: met deze methode worden gegevens in een Power BI-model in de cache opgeslagen (opgeslagen). Het biedt snelle prestaties dankzij query's in het geheugen. Het biedt ook ontwerpflexybiliteit voor modelleerders, zodat ze gegevens uit andere bronnen kunnen integreren. Vanwege deze sterke punten is het importeren van gegevens de standaardmodus bij het maken van een model in Power BI Desktop.
- Gegevens in Dataverse importeren met behulp van Azure Synapse Link: deze methode is een variatie op de importmethode, omdat er ook gegevens in het Power BI-model worden opgeslagen, maar dit doet door verbinding te maken met Azure Synapse Analytics. Met behulp van Azure Synapse Link voor Dataverse worden Dataverse-tabellen continu gerepliceerd naar Azure Synapse of Azure Data Lake Storage (ADLS) Gen2. Deze benadering wordt gebruikt om te rapporteren over honderdduizenden of zelfs miljoenen records in Dataverse-omgevingen.
- Een DirectQuery-verbinding maken met behulp van de Dataverse-connector: deze methode is een alternatief voor het importeren van gegevens. Een DirectQuery-model bestaat alleen uit metagegevens die de modelstructuur definiëren. Wanneer een gebruiker een rapport opent, verzendt Power BI systeemeigen query's naar Dataverse om gegevens op te halen. Overweeg om een DirectQuery-model te maken wanneer rapporten bijna realtime Dataverse-gegevens moeten weergeven of wanneer Dataverse beveiliging op basis van rollen moet afdwingen, zodat gebruikers alleen de gegevens kunnen zien waartoe ze bevoegdheden hebben.
Belangrijk
Hoewel een DirectQuery-model een goed alternatief kan zijn wanneer u bijna realtime rapportage of afdwinging van Dataverse-beveiliging in een rapport nodig hebt, kan dit leiden tot trage prestaties voor dat rapport.
Verderop in dit artikel vindt u meer informatie over overwegingen voor DirectQuery .
Als u de juiste methode voor uw Power BI-model wilt bepalen, moet u het volgende overwegen:
- Queryprestaties
- Gegevensvolume
- Gegevenslatentie
- Op rollen gebaseerde beveiliging
- Complexiteit van installatie
Tip
Zie Een Power BI-modelframework kiezen voor een gedetailleerde bespreking van modelframeworks (importeren, DirectQuery of samengesteld), de voordelen en beperkingen en functies om Power BI-gegevensmodellen te optimaliseren.
Queryprestaties
Query's die naar importmodellen worden verzonden, zijn sneller dan systeemeigen query's die naar DirectQuery-gegevensbronnen worden verzonden. Dat komt doordat geïmporteerde gegevens in de cache worden opgeslagen in het geheugen en geoptimaliseerd zijn voor analysequery's (filter-, groeps- en samenvattende bewerkingen ).
Omgekeerd halen DirectQuery-modellen alleen gegevens op uit de bron nadat de gebruiker een rapport heeft geopend, wat resulteert in seconden vertraging wanneer het rapport wordt weergegeven. Daarnaast vereisen gebruikersinteracties in het rapport dat Power BI de bron opnieuw moet opquery's uitvoeren, waardoor de reactiesnelheid verder wordt verminderd.
Gegevensvolume
Bij het ontwikkelen van een importmodel moet u ernaar streven om de gegevens te minimaliseren die in het model worden geladen. Dit geldt met name voor grote modellen of modellen die u verwacht te groeien in de loop van de tijd. Zie Technieken voor gegevensreductie voor het importeren van modellering voor meer informatie.
Een DirectQuery-verbinding met Dataverse is een goede keuze wanneer het queryresultaat van het rapport niet groot is. Een groot queryresultaat bevat meer dan 20.000 rijen in de brontabellen van het rapport of het resultaat dat wordt geretourneerd naar het rapport nadat filters zijn toegepast meer dan 20.000 rijen. In dit geval kunt u een Power BI-rapport maken met behulp van de Dataverse-connector.
Notitie
De grootte van 20.000 rijen is geen vaste limiet. Elke gegevensbronquery moet echter binnen tien minuten een resultaat retourneren. Verderop in dit artikel leert u hoe u binnen deze beperkingen en andere ontwerpoverwegingen voor DirectQuery van Dataverse kunt werken.
U kunt de prestaties van grotere semantische modellen (voorheen gegevenssets genoemd) verbeteren met behulp van de Dataverse-connector om de gegevens in het gegevensmodel te importeren.
Zelfs grotere semantische modellen, met enkele honderden of zelfs miljoenen rijen, kunnen profiteren van het gebruik van Azure Synapse Link voor Dataverse. Met deze aanpak wordt een doorlopende beheerde pijplijn ingesteld waarmee Dataverse-gegevens worden gekopieerd naar ADLS Gen2 als CSV- of Parquet-bestanden. Power BI kan vervolgens een query uitvoeren op een serverloze SQL-pool van Azure Synapse om een importmodel te laden.
Gegevenslatentie
Wanneer de Dataverse-gegevens snel worden gewijzigd en rapportgebruikers up-to-date gegevens moeten zien, kan een DirectQuery-model bijna realtime queryresultaten leveren.
Tip
U kunt een Power BI-rapport maken dat gebruikmaakt van automatisch vernieuwen van pagina's om realtime-updates weer te geven, maar alleen wanneer het rapport verbinding maakt met een DirectQuery-model.
Gegevensmodellen importeren moet een gegevensvernieuwing voltooien om rapportage over recente gegevenswijzigingen mogelijk te maken. Houd er rekening mee dat er beperkingen gelden voor het aantal dagelijkse geplande gegevensvernieuwingsbewerkingen. U kunt maximaal acht vernieuwingen per dag plannen voor een gedeelde capaciteit. Op een Premium-capaciteit of Microsoft Fabric-capaciteit kunt u maximaal 48 vernieuwingen per dag plannen, wat een vernieuwingsfrequentie van 15 minuten kan bereiken.
Belangrijk
Soms verwijst dit artikel naar Power BI Premium of de capaciteitsabonnementen (P-SKU's). Houd er rekening mee dat Microsoft momenteel aankoopopties consolideert en de Power BI Premium-SKU's per capaciteit buiten gebruik stelt. Nieuwe en bestaande klanten moeten overwegen om in plaats daarvan F-SKU's (Fabric-capaciteitsabonnementen) aan te schaffen.
Zie Belangrijke update voor Power BI Premium-licenties en veelgestelde vragen over Power BI Premium voor meer informatie.
U kunt ook overwegen incrementeel vernieuwen te gebruiken om snellere vernieuwingen en bijna realtime prestaties te bereiken (alleen beschikbaar met Premium of Fabric).
Op rollen gebaseerde beveiliging
Wanneer er behoefte is aan het afdwingen van beveiliging op basis van rollen, kan dit rechtstreeks van invloed zijn op de keuze van het Power BI-modelframework.
Dataverse kan complexe beveiliging op basis van rollen afdwingen om de toegang van specifieke records tot specifieke gebruikers te beheren. Een verkoper kan bijvoorbeeld alleen zijn verkoopkansen zien, terwijl de verkoopmanager alle verkoopkansen voor alle verkopers kan zien. U kunt het complexiteitsniveau aanpassen op basis van de behoeften van uw organisatie.
Een DirectQuery-model op basis van Dataverse kan verbinding maken met behulp van de beveiligingscontext van de rapportgebruiker. Op die manier ziet de rapportgebruiker alleen de gegevens waartoe ze toegang hebben. Deze aanpak kan het ontwerp van het rapport vereenvoudigen, waardoor de prestaties acceptabel zijn.
Voor verbeterde prestaties kunt u in plaats daarvan een importmodel maken dat verbinding maakt met Dataverse. In dit geval kunt u beveiliging op rijniveau (RLS) toevoegen aan het model, indien nodig.
Notitie
Het kan lastig zijn om bepaalde beveiliging op basis van rollen in Dataverse te repliceren als Power BI RLS, met name wanneer Dataverse complexe machtigingen afdwingt. Daarnaast is het mogelijk dat doorlopend beheer nodig is om Power BI-machtigingen synchroon te houden met Dataverse-machtigingen.
Zie de richtlijnen voor beveiliging op rijniveau (RLS) in Power BI Desktop voor meer informatie over Power BI RLS.
Complexiteit van installatie
Het gebruik van de Dataverse-connector in Power BI, ongeacht of het gaat om import- of DirectQuery-modellen, is eenvoudig en vereist geen speciale software- of verhoogde Dataverse-machtigingen. Dat is een voordeel voor organisaties of afdelingen die aan de slag gaan.
De optie Azure Synapse Link vereist systeembeheerderstoegang tot Dataverse en bepaalde Azure-machtigingen. Deze Azure-machtigingen zijn vereist voor het instellen van het opslagaccount en een Synapse-werkruimte.
Aanbevolen praktijken
In deze sectie worden ontwerppatronen (en antipatronen) beschreven die u moet overwegen bij het maken van een Power BI-model dat verbinding maakt met Dataverse. Slechts een paar van deze patronen zijn uniek voor Dataverse, maar ze zijn meestal veelvoorkomende uitdagingen voor Dataverse-makers wanneer ze Power BI-rapporten gaan bouwen.
Focus op een specifieke use case
In plaats van alles op te lossen, richt u zich op de specifieke use case.
Deze aanbeveling is waarschijnlijk het meest voorkomende en gemakkelijk meest uitdagende antipatroon om te voorkomen. Het is lastig om één model te bouwen dat alle selfservicerapportagebehoeften bereikt. De realiteit is dat succesvolle modellen zijn gebouwd om vragen te beantwoorden over een centrale set feiten over één kernonderwerp. Hoewel dat in eerste instantie lijkt te beperken, is het in feite mogelijk omdat u het model kunt afstemmen en optimaliseren voor het beantwoorden van vragen in dat onderwerp.
Stel uzelf de volgende vragen om ervoor te zorgen dat u een duidelijk inzicht hebt in het doel van het model.
- Welk onderwerpgebied ondersteunt dit model?
- Wie is het publiek van de rapporten?
- Welke vragen proberen de rapporten te beantwoorden?
- Wat is het minimaal levensvatbare semantische model?
Verzet zich tegen het combineren van meerdere onderwerpgebieden in één model, alleen omdat de rapportgebruiker vragen heeft over meerdere onderwerpgebieden die ze willen aanpakken door één rapport. Door dat rapport uit te breken in meerdere rapporten, elk met een focus op een ander onderwerp (of feitentabel), kunt u veel efficiëntere, schaalbare en beheerbare modellen produceren.
Een stervormig schema ontwerpen
Dataverse-ontwikkelaars en -beheerders die vertrouwd zijn met het Dataverse-schema, kunnen verleidelijk zijn om hetzelfde schema in Power BI te reproduceren. Deze benadering is een antipatroon en het is waarschijnlijk de moeilijkste om te overwinnen, omdat het gewoon goed voelt om consistentie te behouden.
Dataverse, als relationeel model, is geschikt voor het doel ervan. Het is echter niet ontworpen als een analytisch model dat is geoptimaliseerd voor analytische rapporten. Het meest voorkomende patroon voor het modelleren van analysegegevens is een stervormig schemaontwerp . Stervormig schema is een volwassen modelleringsbenadering die veel wordt gebruikt door relationele datawarehouses. Hiervoor moeten modelleerders hun modeltabellen classificeren als dimensie of feit. Rapporten kunnen filteren of groeperen met behulp van dimensietabelkolommen en feitentabelkolommen samenvatten.
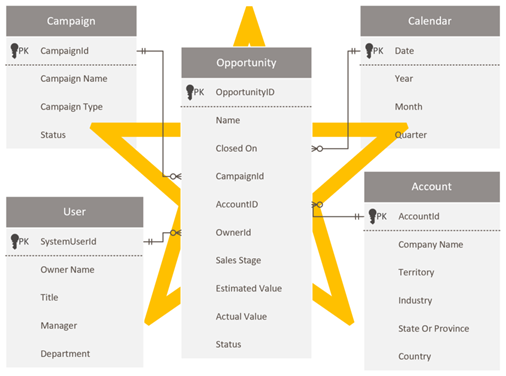
Zie Meer informatie over stervormige schema's en het belang van Power BI.
Power Query-query's optimaliseren
De Mashup-engine van Power Query streeft ernaar om waar mogelijk query's te vouwen om redenen van efficiëntie. Een query waarmee het vouwen van queryverwerking naar het bronsysteem wordt uitgevoerd.
In dit geval hoeft Dataverse alleen gefilterde of samengevatte resultaten te leveren aan Power BI. Een gevouwen query is vaak aanzienlijk sneller en efficiënter dan een query die niet wordt gevouwen.
Zie Power Query-query folding voor meer informatie over hoe u query's kunt vouwen.
Notitie
Het optimaliseren van Power Query is een breed onderwerp. Zie Querydiagnose voor een beter inzicht in wat Power Query doet bij het ontwerpen en vernieuwen van modellen in Power BI Desktop.
Het aantal querykolommen minimaliseren
Wanneer u Power Query gebruikt om een Dataverse-tabel te laden, worden standaard alle rijen en alle kolommen opgehaald. Wanneer u bijvoorbeeld een query uitvoert op een systeemgebruikertabel, kan deze meer dan 1000 kolommen bevatten. De kolommen in de metagegevens bevatten relaties met andere entiteiten en zoekacties naar optielabels, zodat het totale aantal kolommen toeneemt met de complexiteit van de Dataverse-tabel.
Het ophalen van gegevens uit alle kolommen is een antipatroon. Het resulteert vaak in uitgebreide bewerkingen voor het vernieuwen van gegevens. De query mislukt wanneer de benodigde tijd voor het retourneren van de gegevens langer is dan 10 minuten.
U wordt aangeraden alleen kolommen op te halen die vereist zijn voor rapporten. Het is vaak een goed idee om query's opnieuw te evalueeren en te herstructureren wanneer het ontwikkelen van rapporten is voltooid, zodat u ongebruikte kolommen kunt identificeren en verwijderen. Zie Technieken voor gegevensreductie voor het importeren van modellen (Overbodige kolommen verwijderen) voor meer informatie.
Zorg er bovendien voor dat u de stap Kolommen verwijderen van Power Query vroeg introduceert, zodat deze terugvouwt naar de bron. Op die manier kan Power Query het onnodige werk van het extraheren van brongegevens voorkomen om deze later te verwijderen (in een uitgevouwen stap).
Wanneer u een tabel hebt die veel kolommen bevat, is het mogelijk niet praktisch om de interactieve opbouwfunctie voor query's van Power Query te gebruiken. In dit geval kunt u beginnen met het maken van een lege query. Vervolgens kunt u de Geavanceerde editor gebruiken om een minimale query te plakken waarmee een beginpunt wordt gemaakt.
Bekijk de volgende query waarmee gegevens worden opgehaald uit slechts twee kolommen van de accounttabel .
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Systeemeigen query's schrijven
Wanneer u specifieke transformatievereisten hebt, kunt u betere prestaties bereiken met behulp van een systeemeigen query die is geschreven in Dataverse SQL. Dit is een subset van Transact-SQL. U kunt een systeemeigen query schrijven naar:
- Verminder het aantal rijen (met behulp van een
WHEREcomponent). - Gegevens aggregeren (met behulp van de
GROUP BYenHAVINGcomponenten). - Tabellen op een specifieke manier samenvoegen (met behulp van de
JOINofAPPLYsyntaxis). - Gebruik ondersteunde SQL-functies.
Zie voor meer informatie:
Systeemeigen query's uitvoeren met de optie EnableFolding
Power Query voert een systeemeigen query uit met behulp van de Value.NativeQuery functie.
Wanneer u deze functie gebruikt, is het belangrijk om de EnableFolding=true optie toe te voegen om ervoor te zorgen dat query's worden teruggevouwen naar de Dataverse-service. Een systeemeigen query wordt niet gevouwen, tenzij deze optie wordt toegevoegd. Het inschakelen van deze optie kan leiden tot aanzienlijke prestatieverbeteringen, tot wel 97 procent sneller in sommige gevallen.
Houd rekening met de volgende query die gebruikmaakt van een systeemeigen query om geselecteerde kolommen uit de accounttabel te broneren. De systeemeigen query wordt gevouwen omdat de EnableFolding=true optie is ingesteld.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
U kunt verwachten dat u de beste prestatieverbeteringen krijgt bij het ophalen van een subset van gegevens uit een groot gegevensvolume.
Tip
Prestatieverbetering kan ook afhankelijk zijn van hoe Power BI query's uitvoert op de brondatabase. Een meting die gebruikmaakt van de COUNTDISTINCT DAX-functie liet bijvoorbeeld bijna geen verbetering zien met of zonder de hint voor vouwen. Toen de metingformule opnieuw werd geschreven om de SUMX DAX-functie te gebruiken, werd de query gevouwen, wat resulteert in een verbetering van 97 procent ten opzichte van dezelfde query zonder de hint.
Zie Value.NativeQuery voor meer informatie. (De EnableFolding optie wordt niet gedocumenteerd omdat deze alleen specifiek is voor bepaalde gegevensbronnen.)
De evaluatiefase versnellen
Als u de Dataverse-connector (voorheen Common Data Service genoemd) gebruikt, kunt u de CreateNavigationProperties=false optie toevoegen om de evaluatiefase van een gegevensimport te versnellen.
De evaluatiefase van een gegevensimport doorloopt de metagegevens van de bron om alle mogelijke tabelrelaties te bepalen. Deze metagegevens kunnen uitgebreid zijn, met name voor Dataverse. Door deze optie toe te voegen aan de query, laat u Power Query weten dat u deze relaties niet wilt gebruiken. Met de optie kan Power BI Desktop die fase van het vernieuwen overslaan en doorgaan met het ophalen van de gegevens.
Notitie
Gebruik deze optie niet wanneer de query afhankelijk is van uitgevouwen relatiekolommen.
Bekijk een voorbeeld waarmee gegevens uit de accounttabel worden opgehaald. Het bevat drie kolommen die betrekking hebben op gebied: gebied, territoryid en territoryidname.
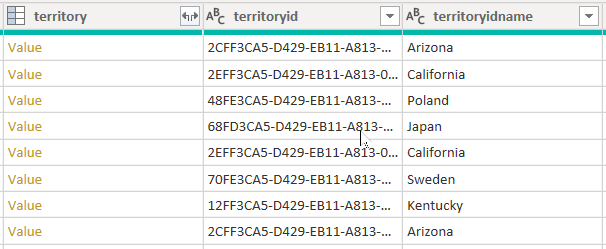
Wanneer u de CreateNavigationProperties=false optie instelt, blijven de kolommen territoryid en territoryidname behouden, maar de gebiedskolom , die een relatiekolom is (met waardekoppelingen ), wordt uitgesloten. Het is belangrijk om te begrijpen dat kolommen met Power Query-relaties een ander concept zijn dan modelrelaties, waarmee filters tussen modeltabellen worden doorgegeven.
Bekijk de volgende query die gebruikmaakt van de CreateNavigationProperties=false optie (in de bronstap ) om de evaluatiefase van een gegevensimport te versnellen.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Wanneer u deze optie gebruikt, zult u waarschijnlijk aanzienlijke prestatieverbeteringen ondervinden wanneer een Dataverse-tabel veel relaties heeft met andere tabellen. Omdat de tabel SystemUser bijvoorbeeld is gerelateerd aan elke andere tabel in de database, kunnen de prestaties van deze tabel worden vernieuwd door de CreateNavigationProperties=false optie in te stellen.
Notitie
Met deze optie kunt u de prestaties van het vernieuwen van gegevens van importtabellen of tabellen in de dubbele opslagmodus verbeteren, waaronder het toepassen van Power Query-editor vensterwijzigingen. Hiermee worden de prestaties van interactieve kruislings filteren van tabellen in de DirectQuery-opslagmodus niet verbeterd.
Lege keuzelabels oplossen
Als u ontdekt dat dataverse-keuzelabels leeg zijn in Power BI, kan dit komen doordat de labels niet zijn gepubliceerd naar het TDS-eindpunt (Tabular Data Stream).
In dit geval opent u de Dataverse Maker-portal, gaat u naar het gebied Oplossingen en selecteert u Alle aanpassingen publiceren. Tijdens het publicatieproces wordt het TDS-eindpunt bijgewerkt met de meest recente metagegevens, waardoor de optielabels beschikbaar zijn voor Power BI.
Grotere semantische modellen met Azure Synapse Link
Dataverse bevat de mogelijkheid om tabellen te synchroniseren met Azure Data Lake Storage (ADLS) en vervolgens verbinding te maken met die gegevens via een Azure Synapse-werkruimte. Met minimale inspanning kunt u Azure Synapse Link instellen om Dataverse-gegevens in Te vullen in Azure Synapse en gegevensteams in staat te stellen om diepere inzichten te ontdekken.
Azure Synapse Link maakt continue replicatie mogelijk van de gegevens en metagegevens van Dataverse naar de data lake. Het biedt ook een ingebouwde serverloze SQL-pool als een handige gegevensbron voor Power BI-query's.
De sterke punten van deze aanpak zijn aanzienlijk. Klanten krijgen de mogelijkheid om analyses, business intelligence- en machine learning-workloads uit te voeren voor dataverse-gegevens met behulp van verschillende geavanceerde services. Geavanceerde services zijn Apache Spark, Power BI, Azure Data Factory, Azure Databricks en Azure Machine Learning.
Een Azure Synapse Link voor Dataverse maken
Als u een Azure Synapse Link voor Dataverse wilt maken, hebt u de volgende vereisten nodig.
- Systeembeheerderstoegang tot de Dataverse-omgeving.
- Voor Azure Data Lake Storage:
- U moet een opslagaccount hebben voor gebruik met ADLS Gen2.
- U moet toegang krijgen tot de eigenaar van opslagblobgegevens en de inzender voor opslagblobgegevens voor het opslagaccount. Zie Op rollen gebaseerd toegangsbeheer (Azure RBAC) voor meer informatie.
- Het opslagaccount moet hiërarchische naamruimte inschakelen.
- Het is raadzaam dat het opslagaccount geografisch redundante opslag met leestoegang (RA-GRS) gebruikt.
- Voor de Synapse-werkruimte:
- U moet toegang hebben tot een Synapse-werkruimte en synapse-Beheer istrator-toegang krijgen. Zie ingebouwde Synapse RBAC-rollen en -bereiken voor meer informatie.
- De werkruimte moet zich in dezelfde regio bevinden als het ADLS Gen2-opslagaccount.
De installatie omvat het aanmelden bij Power Apps en het verbinden van Dataverse met de Azure Synapse-werkruimte. Met een wizard-achtige ervaring kunt u een nieuwe koppeling maken door het opslagaccount en de tabellen te selecteren die u wilt exporteren. Azure Synapse Link kopieert vervolgens gegevens naar de ADLS Gen2-opslag en maakt automatisch weergaven in de ingebouwde serverloze SQL-pool van Azure Synapse. U kunt vervolgens verbinding maken met deze weergaven om een Power BI-model te maken.
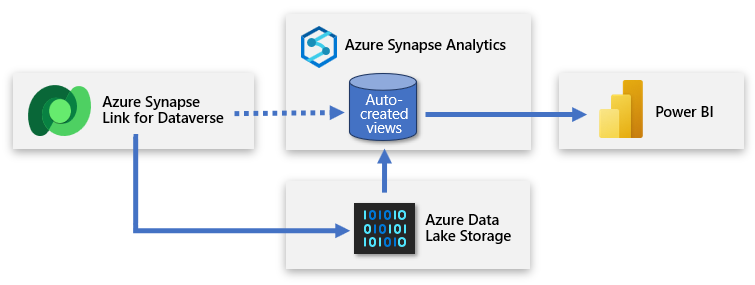
Tip
Zie Een Azure Synapse Link maken voor Dataverse met uw Azure Synapse-werkruimte voor volledige documentatie over het maken, beheren en bewaken van Azure Synapse Link.
Een tweede serverloze SQL-database maken
U kunt een tweede serverloze SQL-database maken en deze gebruiken om aangepaste rapportweergaven toe te voegen. Op die manier kunt u een vereenvoudigde set gegevens presenteren aan de Maker van Power BI waarmee ze een model kunnen maken op basis van nuttige en relevante gegevens. De nieuwe serverloze SQL-database wordt de primaire bronverbinding van de maker en een beschrijvende weergave van de gegevensbron uit de data lake.
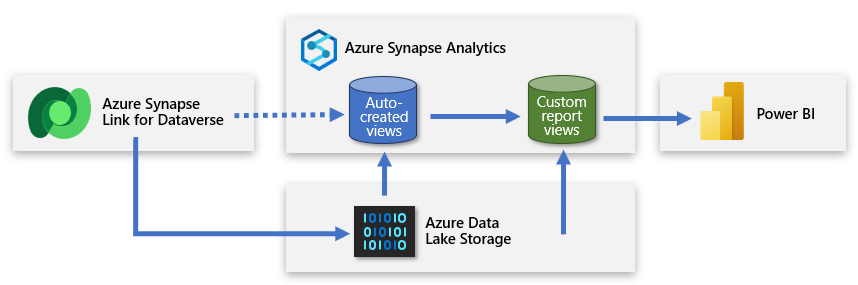
Deze benadering levert gegevens aan Power BI die gericht, verrijkt en gefilterd is.
U kunt een serverloze SQL-database maken in de Azure Synapse-werkruimte met behulp van Azure Synapse Studio. Selecteer Serverloos als het sql-databasetype en voer een databasenaam in. Power Query kan verbinding maken met deze database door verbinding te maken met het SQL-eindpunt van de werkruimte.
Aangepaste weergaven maken
U kunt aangepaste weergaven maken die serverloze SQL-poolquery's verpakken. Deze weergaven dienen als eenvoudige, schone gegevensbronnen waarmee Power BI verbinding maakt. De weergaven moeten:
- Neem de labels op die zijn gekoppeld aan keuzevelden.
- Verminder de complexiteit door alleen de kolommen op te tellen die vereist zijn voor gegevensmodellering.
- Overbodige rijen, zoals inactieve records, uitfilteren.
Bekijk de volgende weergave waarmee campagnegegevens worden opgehaald.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
U ziet dat de weergave slechts vier kolommen bevat, elke alias met een beschrijvende naam. Er is ook een WHERE component om alleen benodigde rijen te retourneren, in dit geval actieve campagnes. De weergave voert ook een query uit op de campagnetabel die is gekoppeld aan de tabellen OptionsetMetadata en StatusMetadata , waarmee keuzelabels worden opgehaald.
Tip
Zie Access-keuzelabels rechtstreeks vanuit Azure Synapse Link voor Dataverse voor meer informatie over het ophalen van metagegevens.
Query's uitvoeren op de juiste tabellen
Azure Synapse Link voor Dataverse zorgt ervoor dat gegevens voortdurend worden gesynchroniseerd met de gegevens in de data lake. Voor activiteiten met een hoog gebruik kunnen gelijktijdige schrijf- en leesbewerkingen vergrendelingen maken waardoor query's mislukken. Om betrouwbaarheid te garanderen bij het ophalen van gegevens, worden twee versies van de tabelgegevens gesynchroniseerd in Azure Synapse.
- Bijna realtime gegevens: biedt een kopie van gegevens die zijn gesynchroniseerd vanuit Dataverse via Azure Synapse Link op een efficiënte manier door te detecteren welke gegevens zijn gewijzigd sinds deze in eerste instantie zijn geëxtraheerd of voor het laatst zijn gesynchroniseerd.
- Momentopnamegegevens: biedt een alleen-lezen kopie van bijna realtime gegevens die regelmatig worden bijgewerkt (in dit geval elk uur). Namen van momentopnamegegevenstabellen hebben _partitioned toegevoegd aan hun naam.
Als u verwacht dat een groot aantal lees- en schrijfbewerkingen tegelijkertijd wordt uitgevoerd, haalt u gegevens op uit de momentopnametabellen om queryfouten te voorkomen.
Zie Toegang tot bijna realtime gegevens en alleen-lezen momentopnamegegevens voor meer informatie.
Verbinding maken naar Synapse Analytics
Als u een query wilt uitvoeren op een serverloze SQL-pool van Azure Synapse, hebt u het SQL-eindpunt van de werkruimte nodig. U kunt het eindpunt ophalen uit Synapse Studio door de eigenschappen van de serverloze SQL-pool te openen.
In Power BI Desktop kunt u verbinding maken met Azure Synapse met behulp van de Azure Synapse Analytics SQL-connector. Wanneer u om de server wordt gevraagd, voert u het SQL-eindpunt van de werkruimte in.
Overwegingen voor DirectQuery
Er zijn veel gebruiksvoorbeelden wanneer u de DirectQuery-opslagmodus gebruikt om uw vereisten op te lossen. Het gebruik van DirectQuery kan echter een negatieve invloed hebben op de prestaties van Power BI-rapporten. Een rapport dat gebruikmaakt van een DirectQuery-verbinding met Dataverse is niet zo snel als een rapport dat gebruikmaakt van een importmodel. Over het algemeen moet u waar mogelijk gegevens importeren in Power BI.
We raden u aan de onderwerpen in deze sectie te overwegen bij het werken met DirectQuery.
Zie Een Power BI-modelframework kiezen voor meer informatie over het bepalen wanneer u wilt werken met de DirectQuery-opslagmodus.
Dimensietabellen voor dubbele opslagmodus gebruiken
Er is een tabel met dubbele opslagmodus ingesteld voor het gebruik van zowel import- als DirectQuery-opslagmodi. Tijdens query's bepaalt Power BI de meest efficiënte modus die moet worden gebruikt. Waar mogelijk probeert Power BI te voldoen aan query's door geïmporteerde gegevens te gebruiken, omdat deze sneller zijn.
U moet overwegen om dimensietabellen in te stellen op de modus voor dubbele opslag, indien van toepassing. Op die manier worden slicervisuals en filterkaartlijsten, die vaak zijn gebaseerd op dimensietabelkolommen, sneller weergegeven omdat er query's worden uitgevoerd op geïmporteerde gegevens.
Belangrijk
Wanneer een dimensietabel het Dataverse-beveiligingsmodel moet overnemen, is het niet geschikt om de dual-opslagmodus te gebruiken.
Feitentabellen, die doorgaans grote hoeveelheden gegevens opslaan, moeten blijven staan als Tabellen in de DirectQuery-opslagmodus. Ze worden gefilterd op de gerelateerde dimensietabellen voor dubbele opslagmodus, die kunnen worden gekoppeld aan de feitentabel om efficiënt filteren en groeperen te bereiken.
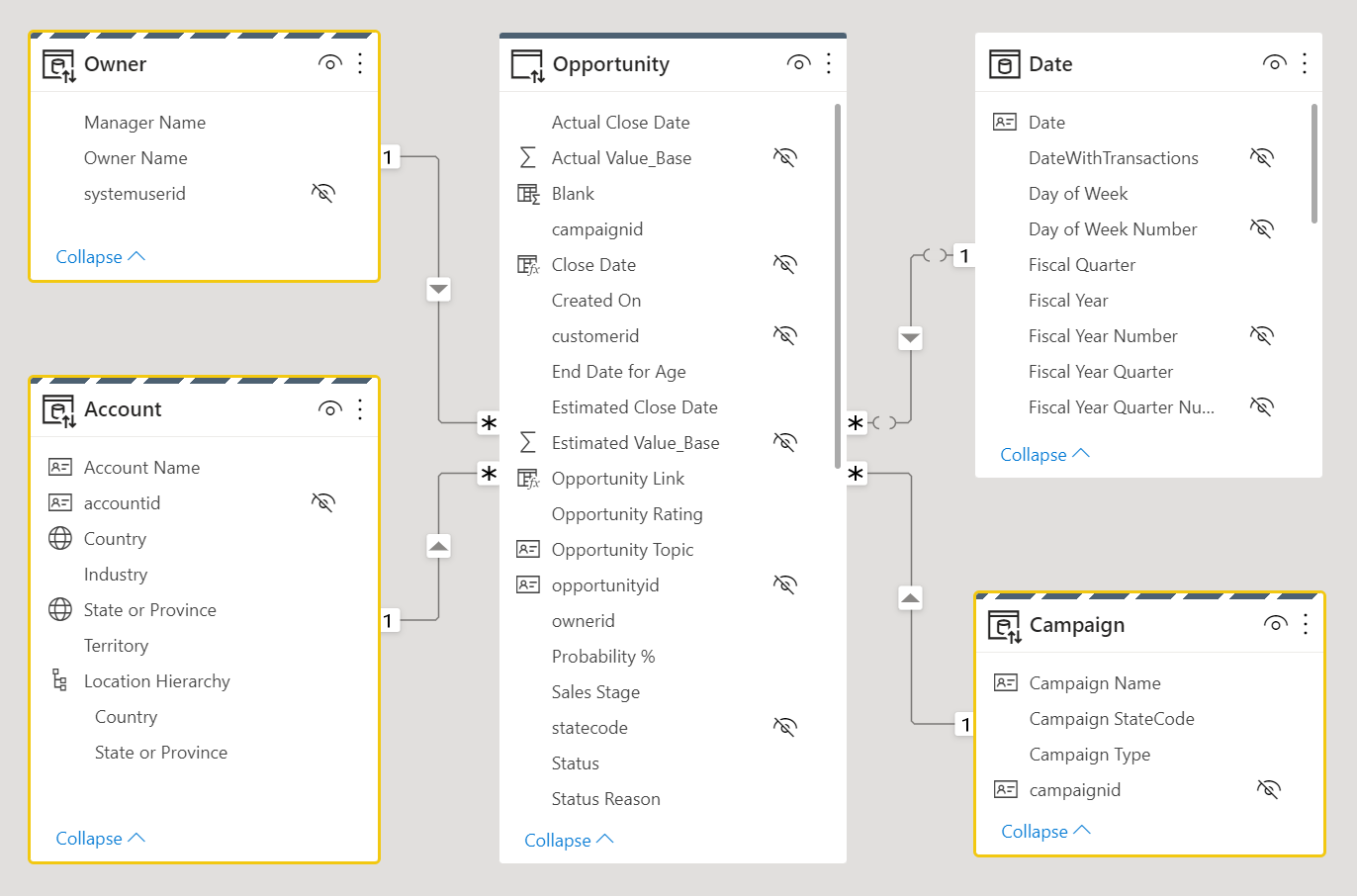
Houd rekening met het volgende ontwerp van het gegevensmodel. Drie dimensietabellen, Eigenaar, Account en Campagne hebben een gestreepte bovenrand, wat betekent dat ze zijn ingesteld op dubbele opslagmodus.
Zie Opslagmodus beheren in Power BI Desktop voor meer informatie over tabelopslagmodi, waaronder dubbele opslag.
Eenmalige aanmelding inschakelen
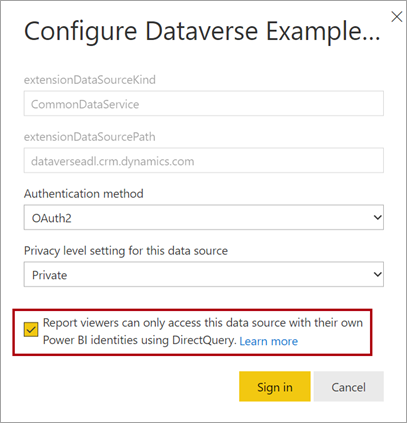
Wanneer u een DirectQuery-model publiceert naar het Power BI-service, kunt u de semantische modelinstellingen gebruiken om eenmalige aanmelding (SSO) in te schakelen met behulp van Microsoft Entra ID (voorheen Bekend als Azure Active Directory) OAuth2 voor uw rapportgebruikers. Schakel deze optie in wanneer Dataverse-query's moeten worden uitgevoerd in de beveiligingscontext van de rapportgebruiker.
Wanneer de optie voor eenmalige aanmelding is ingeschakeld, verzendt Power BI de geverifieerde Microsoft Entra-referenties van de rapportgebruiker in de query's naar Dataverse. Met deze optie kan Power BI de beveiligingsinstellingen respecteren die zijn ingesteld in de gegevensbron.
Zie Eenmalige aanmelding (SSO) voor DirectQuery-bronnen voor meer informatie.
Mijn filters repliceren in Power Query
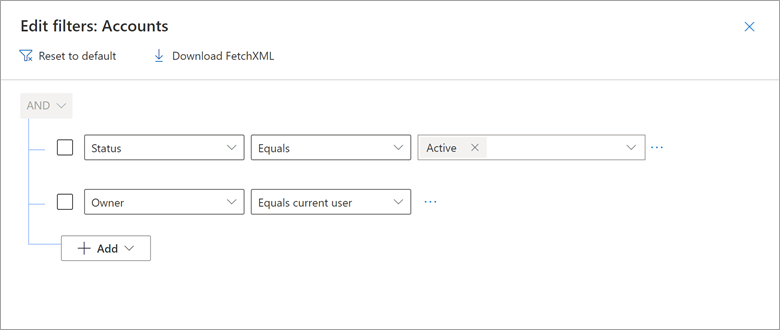
Wanneer u Microsoft Dynamics 365 Customer Engagement (CE) en modelgestuurde Power Apps gebruikt die zijn gebouwd op Dataverse, kunt u weergaven maken waarin alleen records worden weergegeven waarin een gebruikersnaamveld, zoals Eigenaar, gelijk is aan de huidige gebruiker. U kunt bijvoorbeeld weergaven maken met de naam 'Mijn openstaande verkoopkansen', 'Mijn actieve cases' en andere.
Bekijk een voorbeeld van hoe de weergave Mijn actieve Accounts van Dynamics 365 een filter bevat waarin eigenaar gelijk is aan de huidige gebruiker.
U kunt dit resultaat reproduceren in Power Query met behulp van een systeemeigen query waarmee het CURRENT_USER token wordt ingesloten.
Bekijk het volgende voorbeeld met een systeemeigen query die de accounts voor de huidige gebruiker retourneert. In de WHERE component ziet u dat de kolom ownerid wordt gefilterd op het CURRENT_USER token.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Wanneer u het model publiceert naar de Power BI-service, moet u eenmalige aanmelding (SSO) inschakelen, zodat Power BI de geverifieerde Microsoft Entra-referenties van de rapportgebruiker naar Dataverse verzendt.
Aanvullende importmodellen maken
U kunt een DirectQuery-model maken waarmee Dataverse-machtigingen worden afgedwongen, omdat u weet dat de prestaties traag zijn. U kunt dit model vervolgens aanvullen met importmodellen die gericht zijn op specifieke onderwerpen of doelgroepen die RLS-machtigingen kunnen afdwingen.
Een importmodel kan bijvoorbeeld toegang bieden tot alle Dataverse-gegevens, maar geen machtigingen afdwingen. Dit model is geschikt voor leidinggevenden die al toegang hebben tot alle Dataverse-gegevens.
Als Dataverse bijvoorbeeld op rollen gebaseerde machtigingen afdwingt per verkoopregio, kunt u één importmodel maken en deze machtigingen repliceren met behulp van RLS. U kunt ook een model maken voor elke verkoopregio. Vervolgens kunt u leesmachtigingen verlenen aan deze modellen (semantische modellen) aan de verkopers van elke regio. U kunt parameters en rapportsjablonen gebruiken om het maken van deze regionale modellen te vergemakkelijken. Zie Rapportsjablonen maken en gebruiken in Power BI Desktop voor meer informatie.
Gerelateerde inhoud
Raadpleeg de volgende bronnen voor meer informatie over dit artikel.
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor