In een typisch geval van onlinefraude maakt de dief meerdere transacties, wat leidt tot een verlies van duizenden dollars. Daarom moet fraudedetectie bijna in realtime plaatsvinden. Meer dan 800 miljoen mensen gebruiken mobiele apps. Naarmate dat aantal toeneemt, neemt ook de fraude van mobiele banken toe. De financiële sector ondervindt een toename van 100 procent van de verliezen die worden veroorzaakt door toegang vanaf mobiele platforms. Maar er is een beperking. In dit artikel wordt een oplossing beschreven die gebruikmaakt van Azure-technologie om binnen twee seconden een frauduleuze mobiele banktransactie te voorspellen. De architectuur die hier wordt gepresenteerd, is gebaseerd op een echte oplossing.
Uitdagingen: Zeldzame gevallen van fraude en rigide regels
De meeste mobiele fraude treedt op wanneer een SIM-swap-aanval wordt gebruikt om een mobiel nummer in gevaar te komen. Het telefoonnummer wordt gekloond en de crimineel ontvangt de sms-meldingen en oproepen die naar het mobiele apparaat van het slachtoffer worden verzonden. De crimineel verkrijgt vervolgens aanmeldingsreferenties met behulp van social engineering, phishing, vishing (met een telefoon naar phish) of een geïnfecteerde gedownloade app. Met deze informatie kan de crimineel een bankklant imiteren, zich registreren voor mobiele toegang en onmiddellijk geldoverdrachten en intrekkingen genereren.
Mobiele fraude is moeilijk te detecteren en duur voor consumenten en banken. De eerste uitdaging is dat het zeldzaam is. Minder dan 1 procent van alle transacties is frauduleus, dus het kan even duren voordat een fraude- of casebeheerteam door potentieel frauduleuze transacties bladert om de frauduleuze transacties te identificeren. Een tweede uitdaging is dat veel oplossingen voor fraudebewaking afhankelijk zijn van op regels gebaseerde engines. Normaal gesproken zijn op regels gebaseerde engines effectief bij het detecteren van vastgestelde patronen van fraudeachtige transacties die zijn gegenereerd op basis van riskante IP-adressen of meerdere transacties die binnen een korte periode op een nieuw account zijn gegenereerd. Maar op regels gebaseerde engines hebben een aanzienlijke beperking: regels passen zich niet snel aan nieuwe of veranderende typen aanvallen aan. Ze zijn beperkt op de volgende manieren:
- Detectie is niet realtime, dus er wordt fraude gedetecteerd nadat er een financieel verlies is opgetreden.
- Regels zijn binair en beperkt. Ze zijn niet geschikt voor de complexiteit en combinaties van invoervariabelen die kunnen worden geëvalueerd. Deze beperking resulteert in een groot aantal fout-positieven.
- Regels worden vastgelegd in bedrijfslogica. Het beheren van de regels, het opnemen van nieuwe gegevensbronnen of het toevoegen van nieuwe fraudepatronen vereist meestal toepassingswijzigingen die van invloed zijn op een bedrijfsproces. Het doorgeven van wijzigingen in een bedrijfsproces kan lastig en duur zijn.
AI-modellen kunnen de fraudedetectiepercentages en detectietijden aanzienlijk verbeteren. Banken gebruiken deze modellen samen met andere benaderingen om verliezen te verminderen. Het proces dat hier wordt beschreven, is gebaseerd op drie elementen:
- Een AI-model dat op een afgeleide set gedragskenmerken reageert
- Een methodologie voor machine learning
- Een modelevaluatieproces dat vergelijkbaar is met het proces dat door een fraudemanager wordt gebruikt om een portfolio te evalueren
Operationele context
Voor de bank waarop deze oplossing is gebaseerd, omdat klanten het gebruik van digitale services hebben verhoogd, was er een piek in fraude in het mobiele kanaal. Het was tijd voor de bank om zijn aanpak van fraudedetectie en -preventie te herzien. Deze oplossing begon met vragen die van invloed waren op hun fraudeproces en beslissingen:
- Welke activiteiten of transacties zijn waarschijnlijk frauduleus?
- Welke accounts zijn gecompromitteerd?
- Welke activiteiten hebben verder onderzoek en casebeheer nodig?
Om de waarde van de oplossing te kunnen leveren, moet u duidelijk begrijpen hoe fraude met mobiele banken in de operationele omgeving duidelijk wordt:
- Welke soorten fraude worden er op het platform voortdurend uitgevoerd?
- Hoe wordt het doorgevoerd?
- Wat zijn de patronen in frauduleuze activiteiten en transacties?
De antwoorden op deze vragen hebben geleid tot een goed begrip van de soorten gedrag die fraude kunnen signaleren. Gegevenskenmerken zijn toegewezen aan de berichten, verzameld van de gateways van de mobiele toepassing, die zijn gecorreleerd aan het geïdentificeerde gedrag. Accountgedrag dat het meest relevant is voor het bepalen van fraude, is vervolgens geprofileerd.
In de volgende tabel worden typen inbreuk, gegevenskenmerken geïdentificeerd die kunnen duiden op fraude en gedragingen die relevant waren voor de bank:
| Inbreuk op referenties* | Apparaatcompromitts | Financiële compromissen | Niet-transactionele compromissen | |
|---|---|---|---|---|
| Gebruikte methoden | Phishing, vishing. | SIM wisselen, vishing, malware, jailbreaking, apparaatemulators. | Gebruik van accountreferenties en apparaat- en gebruikers-digitale id's (zoals e-mail en fysieke adressen). | Nieuwe gebruikers toevoegen aan account, kaart- of accountlimieten verhogen, accountgegevens en klantprofielgegevens of wachtwoord wijzigen. |
| Gegevens | E-mail of wachtwoord, creditcard- of debitcardnummers, door de klant geselecteerde of eenmalige pincodes. | Apparaat-id, SIM-kaartnummer, geolocatie en IP. | Transactiebedragen, overboeking, intrekking of betalingsbegunstigden. | Accountgegevens. |
| Patronen | Nieuwe digitale klant (niet eerder geregistreerd) met een bestaande kaart en pincode. Mislukte aanmeldingen voor gebruikers die niet bestaan of onbekend zijn. Aanmeldingen tijdens tijdsbestekken die ongebruikelijk zijn voor het account. Meerdere pogingen om aanmeldingswachtwoorden te wijzigen. |
Geografische onregelmatigheden (toegang vanaf een ongebruikelijke locatie). Toegang vanaf meerdere apparaten in een korte periode. |
Patronen in transacties. Veel kleine transacties die in korte tijd voor hetzelfde account zijn geregistreerd, worden bijvoorbeeld soms gevolgd door een grote intrekking. Of betalingen, opnames of overdrachten voor de maximaal toegestane bedragen. Ongebruikelijke frequentie van transacties. |
Patronen in de aanmeldingen en volgorde van activiteiten. Bijvoorbeeld meerdere aanmeldingen binnen een korte periode, meerdere pogingen om contactgegevens te wijzigen of apparaten toe te voegen gedurende een ongebruikelijk tijdsbestek. |
* De meest voorkomende indicator van inbreuk. Het gaat vooraf aan financiële en niet-financiële compromissen.
De gedragsdimensie is essentieel voor het detecteren van mobiele fraude. Profielen op basis van gedrag kunnen helpen bij het vaststellen van typische gedragspatronen voor een account. Analyse kan wijzen op activiteit die buiten de norm lijkt te vallen. Dit zijn enkele voorbeelden van soorten gedrag die kunnen worden geprofileerd:
- Hoeveel accounts zijn gekoppeld aan het apparaat?
- Hoeveel apparaten zijn gekoppeld aan het account? Hoe vaak worden ze verwijderd of toegevoegd?
- Hoe vaak meldt het apparaat of de klant zich aan?
- Hoe vaak wijzigt de klant wachtwoorden?
- Wat is het gemiddelde bedrag van de geldoverdracht of het opnamebedrag van de rekening?
- Hoe vaak worden er intrekkingen gedaan van het account?
De oplossing maakt gebruik van een benadering op basis van:
- Functie-engineering voor het maken van gedragsprofielen voor klanten en accounts.
- Azure Machine Learning om een model voor fraudeclassificatie te maken voor verdacht of inconsistent accountgedrag.
- Azure-services voor realtime gebeurtenisverwerking en end-to-end werkstroom.
Architectuur op hoog niveau

Een Visio-bestand van deze architectuur downloaden.
Gegevensstroom
Deze architectuur bevat drie werkstromen:
Een gebeurtenisgestuurde pijplijn neemt logboekgegevens op en verwerkt logboekgegevens, maakt en onderhoudt gedragsaccountprofielen, neemt een model voor fraudeclassificatie op en produceert een voorspellende score. De meeste stappen in deze pijplijn beginnen met een Azure-functie. Azure-functies worden gebruikt omdat ze serverloos zijn, eenvoudig kunnen worden uitgeschaald en gepland. Deze workload vereist het verwerken van miljoenen binnenkomende mobiele transacties en het beoordelen van fraude in bijna realtime.
Een modeltrainingswerkstroom combineert on-premises historische fraudegegevens en opgenomen logboekgegevens. Deze workload is batchgeoriënteerd en wordt gebruikt voor modeltraining en hertraining. Azure Data Factory organiseert de verwerkingsstappen, waaronder:
- Uploaden van gelabelde historische fraudegegevens van on-premises bronnen.
- Archief van gegevensfunctiessets en scoregeschiedenis voor alle transacties.
- Extractie van gebeurtenissen en berichten in een gestructureerde indeling voor functie-engineering en het opnieuw trainen en evalueren van modellen.
- Training en hertraining van een fraudemodel via Azure Machine Learning.
De derde workstream kan worden geïntegreerd met back-end bedrijfsprocessen. U kunt Azure Logic Apps gebruiken om verbinding te maken en te synchroniseren met een on-premises systeem om fraudebeheercases te maken, accounttoegang te onderbreken of een telefooncontactpersoon te genereren.
Centraal in deze architectuur is de gegevenspijplijn en het AI-model, die verderop in dit artikel uitgebreider worden besproken.
De oplossing kan worden geïntegreerd met de on-premises omgeving van de bank met behulp van een Enterprise Service Bus (ESB) en een krachtige netwerkverbinding.
Gegevenspijplijn en automatisering
Wanneer een crimineel toegang heeft tot een bankrekening via een mobiele app, kan er binnen enkele minuten financieel verlies optreden. Effectieve detectie van fraudeactiviteiten moet plaatsvinden terwijl de crimineel communiceert met de mobiele toepassing en voordat een monetaire transactie plaatsvindt. De tijd die nodig is om te reageren op een frauduleuze transactie heeft rechtstreeks invloed op hoeveel financieel verlies kan worden voorkomen. Hoe sneller de detectie plaatsvindt, hoe minder het financiële verlies.
Minder dan twee seconden, en idealiter veel minder, is de maximale tijd nadat een mobiele bankactiviteit is doorgestuurd voor verwerking die moet worden beoordeeld op fraude. Dit is wat er moet gebeuren tijdens deze twee seconden:
- Een complexe JSON-gebeurtenis verzamelen.
- Valideer, verifieer, parseer en transformeer de JSON.
- Accountfuncties maken op basis van de gegevenskenmerken.
- Verzend de transactie voor deductie.
- Haal de fraudescore op.
- Synchroniseer met een back-end casebeheersysteem.
Latentie en reactietijden zijn essentieel in een oplossing voor fraudedetectie. De infrastructuur ter ondersteuning moet snel en schaalbaar zijn.
Gebeurtenisverwerking
Telemetriegebeurtenissen van de gateways voor mobiele en internettoepassingen van de bank worden opgemaakt als JSON-bestanden met een losjes gedefinieerd schema. Deze gebeurtenissen worden gestreamd als toepassingstelemetrie naar Azure Event Hubs, waarbij een Azure-functie in een toegewezen App Service Environment de verwerking organiseert.
In het volgende diagram ziet u de fundamentele interacties voor een Azure-functie binnen deze infrastructuur:
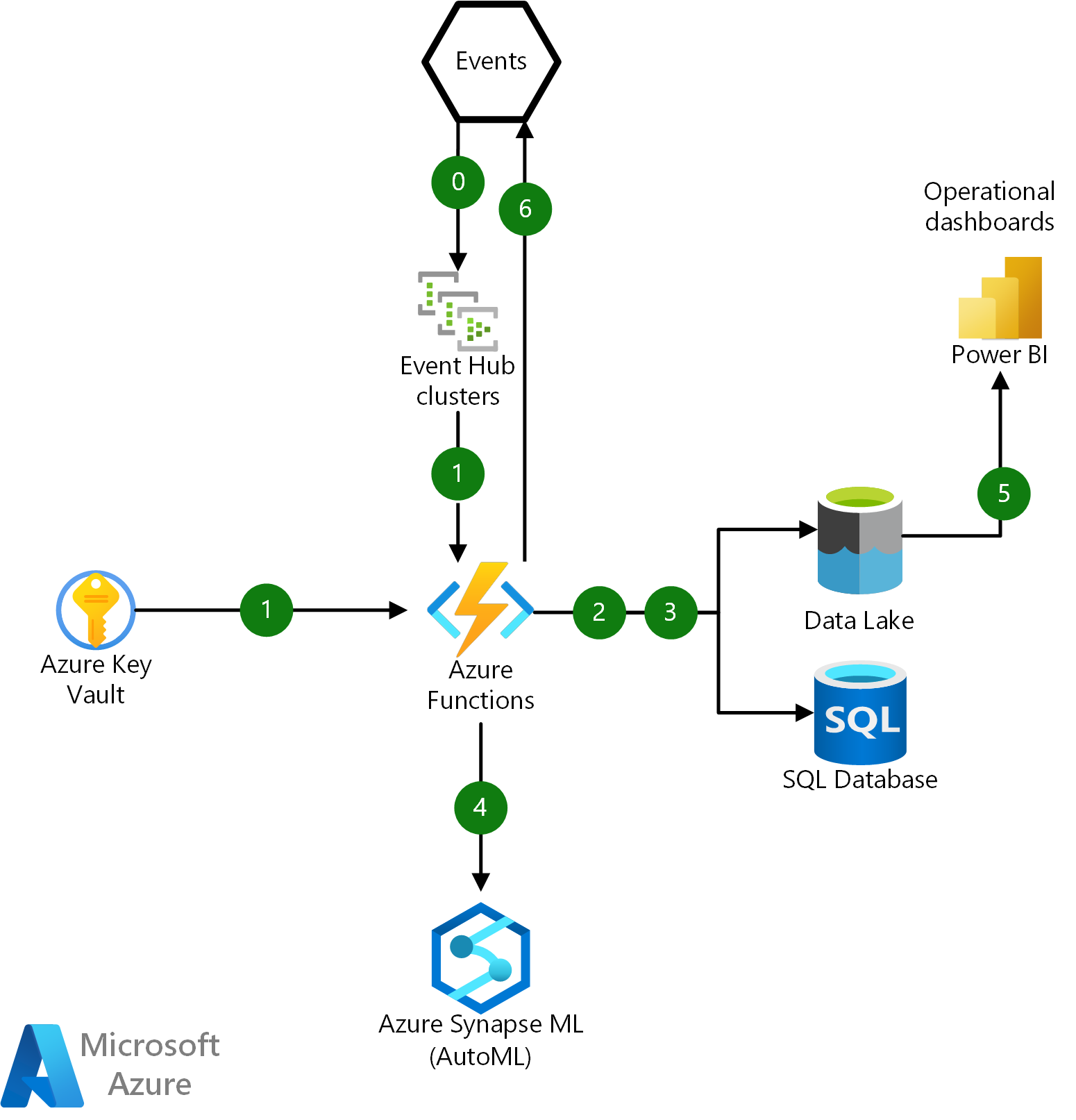
Een Visio-bestand van deze architectuur downloaden.
Gegevensstroom
- Opname van de onbewerkte JSON-gebeurtenispayload van Event Hubs en verifieer met behulp van een SSL-certificaat dat wordt opgehaald uit Azure Key Vault.
- Coördineer de deserialisatie, parsering, opslag en logboekregistratie van onbewerkte JSON-berichten in Azure Data Lake en de financiële transactiegeschiedenis van gebruikers in Azure SQL Database.
- Gebruikersaccount- en apparaatprofielen bijwerken en ophalen uit SQL Database en Data Lake.
- Roep een Azure Machine Learning-eindpunt aan om een voorspellend model uit te voeren en een fraudescore te verkrijgen. Het deductieresultaat behouden naar een data lake voor operationele analyses.
- Verbinding maken Power BI naar Data Lake via Azure Synapse Analytics voor een realtime operationele analysedashboard.
- Plaats de gescoorde resultaten als een gebeurtenis in een on-premises systeem voor verdere fraudeonderzoek en beheeractiviteit.
Gegevensvoorverwerking en JSON-transformatie
In het praktijkscenario waarop deze oplossing is gebaseerd, was het vooraf verwerken van de gegevens een integrale stap bij het opmaken van de gegevens voor de ontwikkeling en training van de machine learning-modellen. Er waren jaren van historische gebeurtenissen voor mobiel en internetbankieren, waaronder transactiegegevens uit de telemetrie van de application gateway in JSON-indeling. Er waren honderdduizenden bestanden met meerdere gebeurtenissen die moesten worden gedeserialiseerd en afgevlakt en opgeschoond voor het trainen van het machine learning-model.
Elke toepassingsgateway produceert telemetrie van de interactie van een gebruiker, waarbij informatie wordt vastgelegd, zoals de metagegevens van het besturingssysteem, metagegevens van mobiele apparaten, accountgegevens en transactieaanvragen en -antwoorden. Er was variatie tussen JSON-bestanden en -kenmerken, en gegevenstypen waren verschillend en inconsistent. Een andere complicatie met de JSON-bestanden was dat kenmerken en gegevenstypen onverwacht konden veranderen wanneer toepassingsupdates werden gepusht naar de gateways en functies werden verwijderd, gewijzigd of toegevoegd. Uitdagingen met betrekking tot gegevenstransformatie met de schema's zijn onder andere:
- Een JSON-bestand kan een of meer interacties met mobiele telefoons bevatten. Elke interactie moet worden geëxtraheerd als een afzonderlijk bericht.
- Velden kunnen anders worden genoemd of weergegeven.
- Tekens zoals nieuwe regels of regelterugloop worden inconsistent ingesloten in berichten.
- Kenmerken zoals e-mailadressen ontbreken of zijn gedeeltelijk opgemaakt.
- Er kunnen complexe, geneste eigenschappen en waarden zijn.
Een Spark-pool wordt gebruikt als onderdeel van het koude pad voor het verwerken van historische JSON-bestanden en voor het deserialiseren, plat maken en extraheren van apparaat- en transactiekenmerken. Elk JSON-bestand wordt gevalideerd en geparseerd en de transactiekenmerken worden geëxtraheerd en bewaard op een data lake en gepartitioneerd op basis van de datum van de transactie.
Deze kenmerken worden later gebruikt om functies voor de fraudeclassificatie te maken. De kracht van deze oplossing is afhankelijk van de mogelijkheid van JSON-gegevens om gestandaardiseerde, gekoppelde en samengevoegde met historische gegevens te maken om gedragsprofielen te maken.
Bijna realtime gegevensverwerking en -featurization met SQL Database
In deze oplossing worden gebeurtenissen geproduceerd uit meerdere bronnen, waaronder verificatierecords, klantgegevens en demografische gegevens, transactierecords en logboek- en activiteitsgegevens van mobiele apparaten. SQL Database wordt gebruikt om realtime gegevensparsering, preverwerking en featurization uit te voeren, omdat SQL bekend is bij veel ontwikkelaars.
HTAP-functionaliteit is nodig om de gedragsgeschiedenis van gebruikersaccounts op te halen voor een bepaald apparaat gedurende de afgelopen zeven dagen om functies in bijna realtime met lage latentie te berekenen. In SQL Database worden deze HTAP-mogelijkheden (Hybrid Transaction/Analytical Processing) gebruikt:
- Met geheugen geoptimaliseerde tabellen worden accountprofielen opgeslagen. Tabellen die zijn geoptimaliseerd voor geheugen hebben voordelen ten opzichte van traditionele SQL-tabellen, omdat ze worden gemaakt en geopend in het hoofdgeheugen. De latentie en overhead van schijftoegang worden vermeden. De vereiste voor deze oplossing is om 300 JSON-berichten/seconde te verwerken. Tabellen die zijn geoptimaliseerd voor geheugen bieden dit doorvoerniveau.
- Tabellen die zijn geoptimaliseerd voor geheugen, worden het meest efficiënt geopend vanuit systeemeigen gecompileerde opgeslagen procedures. In tegenstelling tot geïnterpreteerde opgeslagen procedures worden systeemeigen gecompileerde opgeslagen procedures gecompileerd wanneer ze voor het eerst worden gemaakt.
- Een tijdelijke tabel is een tabel die automatisch de wijzigingsgeschiedenis bijhoudt. Wanneer een rij wordt toegevoegd of bijgewerkt, wordt deze geversied en naar de geschiedenistabel geschreven. In deze oplossing worden de accountprofielen opgeslagen in een tijdelijke tabel met een bewaarbeleid van zeven dagen, zodat rijen automatisch worden verwijderd na de bewaarperiode.
Deze aanpak biedt ook de volgende voordelen:
- Toegang tot gearchiveerde gegevens voor operationele analyses, hertraining van machine learning-modellen en fraudevalidatie
- Vereenvoudigde gegevensarchivering naar langetermijnopslag
- Schaalbaarheid via sharding-gegevens en het gebruik van een elastische database
Gebeurtenisschemabeheer
De automatisering van schemabeheer is een andere uitdaging die voor deze oplossing moet worden opgelost. JSON is een flexibele en draagbare bestandsindeling, deels omdat een schema niet met de gegevens wordt opgeslagen. Wanneer JSON-bestanden moeten worden geparseerd, gedeserialiseerd en verwerkt, moet een schema dat de structuur van de JSON vertegenwoordigt ergens worden gecodeerd om de gegevenseigenschappen en gegevenstypen te valideren. Als het schema niet wordt gesynchroniseerd met het binnenkomende JSON-bericht, mislukt de JSON-validatie en worden gegevens niet geëxtraheerd.
De uitdaging is wanneer de structuur van JSON-berichten verandert vanwege nieuwe toepassingsfunctionaliteit. In de oorspronkelijke oplossing heeft de bank waarvoor deze oplossing is gemaakt meerdere toepassingsgateways geïmplementeerd, elk met een eigen gebruikersinterface, functionaliteit, telemetrie en JSON-berichtstructuur. Toen het schema niet meer werd gesynchroniseerd met de binnenkomende JSON-gegevens, hebben de inconsistenties gegevensverlies en verwerkingsvertragingen voor fraudedetectie tot stand gebracht.
De bank had geen formeel schema gedefinieerd voor deze gebeurtenissen en de constante fluctuaties in de structuur van de JSON-bestanden hebben technische schulden gecreëerd bij elke iteratie van de oplossing. Met deze oplossing wordt dit probleem opgelost door een schema voor deze gebeurtenissen tot stand te brengen en Azure Schema Registry te gebruiken. Azure Schema Registry biedt een centrale opslagplaats van schema's voor gebeurtenissen en flexibiliteit voor producenten en consumententoepassingen om gegevens uit te wisselen zonder het schema te hoeven beheren en delen. Het eenvoudige governanceframework dat wordt geïntroduceerd voor herbruikbare schema's en de relatie die het definieert tussen schema's via de groeperingsconstructies (schemagroepen), kan aanzienlijke technische schulden elimineren, naleving afdwingen en achterwaartse compatibiliteit bieden in veranderende schema's.
Functie-engineering voor machine learning
Functies bieden een manier om accountgedrag te profileren door activiteit over verschillende tijdschalen te aggregeren. Ze worden gemaakt op basis van gegevens in de toepassingslogboeken die transactioneel, niet-transactioneel en apparaatgedrag vertegenwoordigen. Transactioneel gedrag omvat monetaire transactieactiviteiten zoals betalingen en intrekkingen. Niet-transactioneel gedrag omvat gebruikersacties zoals aanmeldingspogingen en wachtwoordwijzigingen. Apparaatgedrag omvat activiteiten die betrekking hebben op een mobiel apparaat, zoals het toevoegen of verwijderen van een apparaat. Functies worden gebruikt om het huidige en eerdere accountgedrag weer te geven, waaronder:
- Nieuwe gebruikersregistratiepogingen vanaf een specifiek apparaat.
- Geslaagde en mislukte aanmeldingspogingen.
- Verzoeken om begunstigde of begunstigden van derden toe te voegen.
- Aanvragen voor het verhogen van account- of creditcardlimieten.
- Wachtwoordwijzigingen.
Een accountprofieltabel bevat kenmerken van de JSON-transacties, zoals de bericht-id, het transactietype, het betalingsbedrag, de dag van de week en het uur van de dag. Activiteiten worden samengevoegd in meerdere tijdsbestekken, zoals een uur, een dag en zeven dagen, en worden opgeslagen als gedragsgeschiedenis voor elk account. Elke rij in de tabel vertegenwoordigt één account. Dit zijn enkele van de functies:
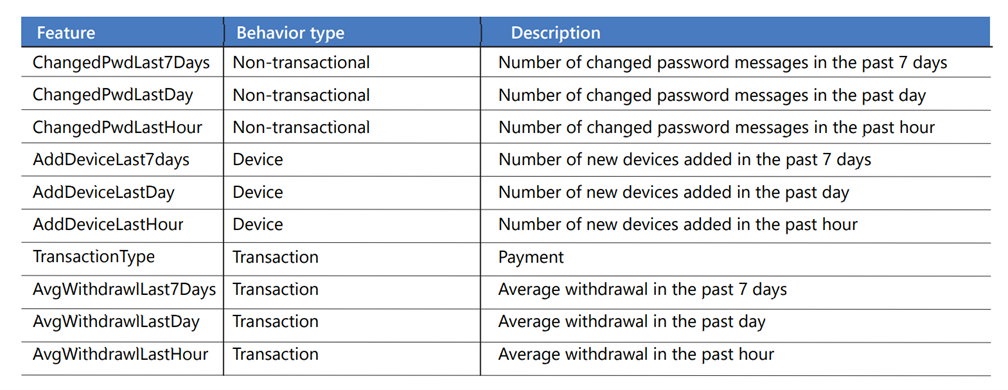
Nadat de accountfuncties zijn berekend en het profiel is bijgewerkt, roept een Azure-functie het machine learning-model aan voor het scoren via een REST API om deze vraag te beantwoorden: Wat is de kans dat dit account een fraudestatus heeft, op basis van het gedrag dat we hebben gezien?
AutoML
AutoML wordt in de oplossing gebruikt omdat het snel en eenvoudig te gebruiken is. AutoML kan een nuttig startpunt zijn voor snelle detectie en leren, omdat hiervoor geen gespecialiseerde kennis of installatie is vereist. Het automatiseert de tijdrovende, iteratieve taken van het ontwikkelen van machine learning-modellen. Gegevenswetenschappers, analisten en ontwikkelaars kunnen dit gebruiken om machine learning-modellen te bouwen met een hoge schaalbaarheid, efficiëntie en productiviteit en tegelijkertijd de kwaliteit van het model te behouden.
AutoML kan de volgende taken uitvoeren in een machine learning-proces:
- Gegevens splitsen in gegevenssets voor trainen en valideren
- Training optimaliseren op basis van een gekozen metrische waarde
- Kruisvalidatie uitvoeren
- Functies genereren
- Ontbrekende waarden invoeren
- One-hot codering en verschillende schaalders uitvoeren
Onevenwichtige gegevens
Fraudeclassificatie is lastig vanwege de ernstige klasse-onevenwichtigheid. In een fraudegegevensset zijn er veel meer niet-frauduleuze transacties dan frauduleuze transacties. Doorgaans bevat minder dan 1 procent van een gegevensset frauduleuze transacties. Als deze niet wordt aangepakt, kan deze onevenwichtigheid een geloofwaardigheidsprobleem in het model veroorzaken, omdat alle transacties kunnen worden geclassificeerd als niet-frauduleus. Het model kan alle frauduleuze transacties volledig missen en nog steeds een nauwkeurigheidspercentage van 99 procent bereiken.
AutoML kan helpen bij het herdistribueren van gegevens en het creëren van een beter evenwicht tussen frauduleuze en niet-frauduleuze transacties:
- AutoML ondersteunt het toevoegen van een kolom met gewichten als invoer, waardoor de rijen in de gegevens omhoog of omlaag worden gewogen, waardoor een klasse minder belangrijk wordt. De algoritmen die door AutoML worden gebruikt, detecteren onbalans wanneer het aantal steekproeven in de minderheidsklasse gelijk is aan of minder dan 20 procent van het aantal steekproeven in de meerderheidsklasse. Vervolgens voert AutoML het experiment uit met subsampledgegevens om te controleren of het gebruik van klassegewichten dit probleem oplost en de prestaties verbetert. Als deze bepaalt dat de prestaties beter zijn vanwege het experiment, wordt de remedie toegepast.
- U kunt een metrische prestatiemeting gebruiken waarmee onbalansgegevens beter worden verwerkt. Als uw model bijvoorbeeld gevoelig moet zijn voor fout-negatieven, gebruikt u
recall. Wanneer het model gevoelig moet zijn voor fout-positieven, gebruikt uprecision. U kunt ook een F1-score gebruiken. Deze score is het harmonische gemiddelde tussenprecisionenrecall, dus het wordt niet beïnvloed door een groot aantal terecht-positieven of terecht-negatieven. Mogelijk moet u enkele metrische gegevens handmatig berekenen tijdens de testfase.
Als u het aantal transacties wilt verhogen dat als frauduleus is geclassificeerd, kunt u ook handmatig een techniek gebruiken met de naam Synthetic Minority Oversampling Technique (SMOTE). SMOTE is een statistische techniek die gebruikmaakt van bootstrapping en k-nearest neighbor (KNN) om instanties van de minderheidsklasse te produceren.
Modeltraining
Voor modeltraining verwacht de Python SDK gegevens in een pandas-gegevensframe-indeling of als een tabellaire Gegevensset van Azure Machine Learning. De waarde die u wilt voorspellen, moet zich in de gegevensset hebben. U geeft de y-kolom door als parameter wanneer u de trainingstaak maakt.
Hier volgt een codevoorbeeld met opmerkingen:
data = https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv
dataset = Dataset.Tabular.from_delimited_files(data)
training_data, validation_data = dataset.random_split(percentage=0.7)
label_column_name = "Class"
automl_settings = {
"n_cross_validations": 3, # Number of cross validation splits.
"primary_metric": "average_precision_score_weighted", # This is the metric that you want to optimize.
"experiment_timeout_hours": 0.25, # Percentage of an hour you want this to run.
"verbosity": logging.INFO, # Logging info level, debug, info, warning, error, critical.
"enable_stack_ensemble": False, # VotingEnsembled is enabled by default.
}
automl_config = AutoMLConfig(
task="classification",
debug_log="automl_errors.log",
training_data=training_data,
label_column_name=label_column_name,
**automl_settings,
)
local_run = experiment.submit(automl_config, show_output=True)
In de code:
- Laad de gegevensset in een tabelgegevensset van Azure Machine Learning of pandas-dataframe.
- Splits de gegevensset in 70 procent training en 30 procent validatie.
- Maak een variabele voor de kolom die u wilt voorspellen.
- Begin met het maken van de AutoML-parameters.
- Configureren
AutoMLConfig.taskis het type machine learning dat u wilt doen:classificationofregression. In dit geval gebruikt uclassification.debug_logis de locatie waar foutopsporingsinformatie wordt geschreven.training_datais het dataframe of tabellaire object waarnaar de trainingsgegevens worden geladen.label_column_nameis de kolom die u wilt voorspellen.
- Voer de machine learning-taak uit.
Modelevaluatie
Een goed model produceert realistische en bruikbare resultaten. Dat is een van de uitdagingen met een fraudedetectiemodel. De meeste fraudedetectiemodellen produceren een binaire beslissing om te bepalen of een transactie frauduleus is. De beslissing is gebaseerd op twee factoren:
- Een waarschijnlijkheidsscore tussen 0 en 100 die wordt geretourneerd door het classificatie-algoritme
- Een waarschijnlijkheidsdrempel die door het bedrijf is vastgesteld. Boven de drempelwaarde wordt beschouwd als frauduleus en onder de drempelwaarde wordt beschouwd als niet-frauduleus.
Waarschijnlijkheid is een standaardmetriek voor elk classificatiemodel. Maar het is meestal onvoldoende in een fraudescenario voor beslissingen over het blokkeren van een account om verdere verliezen te voorkomen.
In deze oplossing worden metrische gegevens op accountniveau gemaakt en meegenomen in de beslissing of het bedrijf moet handelen om een account te blokkeren. De metrische gegevens op accountniveau worden gedefinieerd op basis van deze industriestandaard metrische gegevens:
| Zorg voor fraudemanager | Metrisch | Beschrijving |
|---|---|---|
| Detecteer ik fraude? | Detectiefrequentie van fraudeaccounts (ADR) | Het percentage gedetecteerde fraudeaccounts in alle fraudeaccounts. |
| Hoeveel geld bespaar ik (verliespreventie)? Hoeveel kost een vertraging bij het reageren op een waarschuwing? | Waardedetectiefrequentie (VDR) | Het percentage van de monetaire besparingen, ervan uitgaande dat de huidige fraudetransactie een blokkerende actie activeert voor volgende transacties, ten opzichte van alle fraudeverlies. |
| Hoeveel goede klanten ben ik onhandig? | Fout-positieve verhouding van account (AFPR) | Het aantal niet-frauduleuze accounts dat wordt gemarkeerd voor elke gedetecteerde echte fraude (per dag). De verhouding van gedetecteerde fout-positieve accounts ten opzichte van gedetecteerde frauduleuze accounts. |
Deze metrische gegevens zijn waardevolle gegevenspunten voor een fraudemanager. De manager gebruikt deze om een vollediger beeld te krijgen van het accountrisico en te beslissen over herstel.
Model operationalisatie en hertraining
Voorspellende modellen moeten periodiek worden bijgewerkt. Na verloop van tijd, en wanneer er nieuwe en verschillende gegevens beschikbaar komen, moet een voorspellend model opnieuw worden getraind. Dit geldt met name voor fraudedetectiemodellen waarin nieuwe patronen van criminele activiteiten vaak voorkomen. Het wordt ook nodig wanneer de telemetrie van mobiele toepassingen wijzigingen registreert vanwege wijzigingen die naar de toepassingsgateway zijn gepusht. Elke transactie die wordt ingediend voor analyse en de bijbehorende metrische modelevaluatiegegevens, worden vastgelegd om deze oplossing opnieuw te trainen. Na verloop van tijd worden de modelprestaties bewaakt. Wanneer het lijkt te afnemen, wordt een werkstroom voor opnieuw trainen geactiveerd. Er worden verschillende Azure-services gebruikt in de werkstroom voor opnieuw trainen:
U kunt Azure Synapse Analytics of Azure Data Lake gebruiken om historische klantgegevens op te slaan. U kunt deze services gebruiken om bekende frauduleuze transacties op te slaan die zijn geüpload vanuit on-premises bronnen en gegevens die zijn gearchiveerd vanuit de Azure Machine Learning-webservice, waaronder transacties, voorspellingen en metrische gegevens over modelevaluatie. De gegevens die nodig zijn om opnieuw te trainen, worden opgeslagen in dit gegevensarchief.
U kunt Data Factory- of Azure Synapse-pijplijnen gebruiken om de gegevensstroom en het proces voor opnieuw trainen te organiseren, waaronder:
- De extractie van historische gegevens en logboekbestanden van on-premises systemen.
- Het JSON-deserialisatieproces.
- Logica voor gegevensverwerking.
Zie Azure Machine Learning-modellen opnieuw trainen en bijwerken met Azure Data Factory voor gedetailleerde informatie.
U kunt blauwgroene implementaties gebruiken in Azure Machine Learning. Zie Veilige implementatie voor online-eindpunten voor informatie over het implementeren van een nieuw model met minimale downtime.
Onderdelen
- Azure Functions biedt serverloze codefuncties op basis van gebeurtenissen en een end-to-end ontwikkelervaring.
- Event Hubs is een volledig beheerde, realtime gegevensopnameservice. U kunt deze gebruiken om miljoenen gebeurtenissen per seconde te streamen vanuit elke bron.
- Key Vault versleutelt cryptografische sleutels en andere geheimen die worden gebruikt door cloud-apps en -services.
- Azure Machine Learning is een hoogwaardige service voor de end-to-end machine learning-levenscyclus.
- AutoML is een proces voor het automatiseren van de tijdrovende, iteratieve taken van machine learning-modelontwikkeling.
- Azure SQL Database is een altijd up-to-date, volledig beheerde relationele databaseservice die is gebouwd voor de cloud.
- Azure Synapse Analytics is een onbeperkte analyseservice die gegevensintegratie, zakelijke datawarehousing en big data-analyses combineert.
Technische overwegingen
Als u de juiste technologieonderdelen wilt selecteren voor een continu functionerende cloudinfrastructuur voor fraudedetectie, moet u de huidige en soms vage vereisten begrijpen. De technologische keuzes voor deze oplossing zijn gebaseerd op overwegingen die u kunnen helpen vergelijkbare beslissingen te nemen.
Vaardighedensets
Houd rekening met de huidige technologische vaardighedensets van de teams die de oplossing ontwerpen, implementeren en onderhouden. Cloud- en AI-technologieën breiden de beschikbare opties voor het implementeren van een oplossing uit. Als uw team bijvoorbeeld basisvaardigheden voor gegevenswetenschap heeft, is Azure Machine Learning een goede keuze voor het maken en eindpunt van het model. De beslissing om Event Hubs te gebruiken is een ander voorbeeld. Event Hubs is een beheerde service die eenvoudig kan worden ingesteld en onderhouden. Er zijn technische voordelen bij het gebruik van een alternatief zoals Kafka, maar hiervoor is mogelijk training vereist.
Hybride operationele omgeving
De implementatie voor deze oplossing omvat een on-premises omgeving en de Azure-omgeving. Services, netwerken, toepassingen en communicatie moeten effectief werken in beide infrastructuren om de workload te ondersteunen. De beslissingen op het gebied van technologie zijn onder andere:
- Hoe worden de omgevingen geïntegreerd?
- Wat zijn de netwerkconnectiviteitsvereisten tussen het Azure-datacenter en de on-premises infrastructuur? Azure ExpressRoute wordt gebruikt omdat het dubbele lijnen, redundantie en failover biedt. Site-naar-site-VPN biedt niet de beveiliging of QoS (Quality-of-Service) die nodig is voor de workload.
- Hoe kunnen fraudedetectiescores worden geïntegreerd met back-endsystemen? Scorereacties moeten worden geïntegreerd met back-endfraudewerkstromen om de verificatie van transacties met klanten of andere activiteiten voor casebeheer te automatiseren. U kunt Azure Functions of Logic Apps gebruiken om Azure-services te integreren met on-premises systemen.
Beveiliging
Het hosten van een oplossing in de cloud zorgt voor nieuwe beveiligingsverantwoordelijkheden. In de cloud is beveiliging een gedeelde verantwoordelijkheid tussen een cloudleverancier en een klanttenant. Workloadverantwoordelijkheden variëren, afhankelijk van of de workload een SaaS-, PaaS- of IaaS-service is. Zie Gedeelde verantwoordelijkheid in de cloud voor meer informatie.
Of u nu overstapt op een Zero Trust-benadering of werkt aan het toepassen van nalevingsvereisten voor regelgeving, het beveiligen van een oplossing end-to-end vereist zorgvuldige planning en overweging. Voor ontwerp en implementatie raden we u aan om beveiligingsprincipes te gebruiken die consistent zijn met een Zero Trust-benadering. Door principes zoals expliciet verifiëren te gebruiken, toegang tot minimale bevoegdheden te gebruiken en ervan uit te gaan dat inbreuk de beveiliging van workloads versterkt.
Controleer expliciet of het proces van het onderzoeken en beoordelen van verschillende aspecten van een toegangsaanvraag is. Hier volgen enkele van de principes:
- Gebruik een sterk identiteitsplatform zoals Microsoft Entra ID.
- Inzicht krijgen in het beveiligingsmodel voor elke cloudservice en hoe gegevens en toegang worden beveiligd.
- Gebruik indien mogelijk beheerde identiteiten en service-principals om de toegang tot cloudservices te beheren.
- Sleutels, geheimen, certificaten en toepassingsartefacten opslaan, zoals databasetekenreeksen, REST-eindpunt-URL's en API-sleutels in Key Vault.
Het gebruik van toegang met minimale bevoegdheden helpt ervoor te zorgen dat machtigingen alleen worden verleend om te voldoen aan specifieke bedrijfsbehoeften van een geschikte omgeving naar een geschikte client. Hier volgen enkele van de principes:
- Compartimenteer workloads door te beperken hoeveel toegang een onderdeel of resource heeft via roltoewijzingen of netwerktoegang.
- Openbare toegang tot eindpunten en services weigeren. Gebruik privé-eindpunten om uw services te beschermen, tenzij voor uw service openbare toegang is vereist.
- Gebruik firewallregels om service-eindpunten te beveiligen of workloads te isoleren met behulp van virtuele netwerken.
Stel dat inbreuk een strategie is voor het begeleiden van ontwerp- en implementatiebeslissingen. De strategie is om ervan uit te gaan dat een oplossing is aangetast. Het is een benadering om tolerantie in te bouwen in een workload door te plannen voor detectie van, reactie op en herstel van een beveiligingsrisico. Voor ontwerp- en implementatiebeslissingen betekent dit dat:
- Workloadonderdelen worden geïsoleerd en gesegmenteerd, zodat een inbreuk op één onderdeel de impact op upstream- of downstreamonderdelen minimaliseert.
- Telemetrie wordt proactief vastgelegd en geanalyseerd om afwijkingen en mogelijke bedreigingen te identificeren.
- Automatisering is aanwezig om een bedreiging te detecteren, erop te reageren en op te sporen.
Hier volgen enkele richtlijnen om rekening mee te houden:
- Versleutel data-at-rest en in transit.
- Schakel controle in voor services.
- Auditlogboeken en telemetrie vastleggen en centraliseren in één logboekwerkruimte om analyse en correlatie te vergemakkelijken.
- Schakel Microsoft Defender voor Cloud in om te scannen op mogelijk kwetsbare configuraties en vroegtijdige waarschuwingen te geven over mogelijke beveiligingsproblemen.
Netwerken is een van de belangrijkste beveiligingsfactoren. Azure Synapse-werkruimte-eindpunten zijn standaard openbare eindpunten. Dit betekent dat ze toegankelijk zijn vanuit elk openbaar netwerk, dus we raden u ten zeerste aan om openbare toegang tot de werkruimte uit te schakelen. Overweeg om Azure Synapse te implementeren met de functie Beheerd virtueel netwerk ingeschakeld om een isolatielaag toe te voegen tussen uw werkruimte en andere Azure-services. Zie het technisch document over beveiliging van Azure Synapse Analytics voor meer informatie over managed virtual network en andere beveiligingsfactoren: Netwerkbeveiliging.

Een Visio-bestand van deze architectuur downloaden.
Beveiligingsrichtlijnen die specifiek zijn voor elk oplossingsonderdeel in de bankoplossing, worden opgenomen in de volgende tabel. Raadpleeg Azure Security Benchmark, inclusief beveiligingsbasislijnen voor elk van de afzonderlijke Azure-services, voor een goed uitgangspunt. De aanbevelingen voor de beveiligingsbasislijn kunnen u helpen bij het selecteren van de beveiligingsconfiguratie-instellingen voor elke service.
Zie het Zero Trust Guidance Center voor meer informatie.
Schaalbaarheid
De oplossing moet end-to-end tot piektijden uitvoeren. Een streamingwerkstroom voor het verwerken van miljoenen continu aankomende gebeurtenissen vereist hoge doorvoer. Plan een testsysteem te bouwen dat het volume en de gelijktijdigheid simuleert om ervoor te zorgen dat de technologieonderdelen zijn geconfigureerd en afgestemd om te voldoen aan de vereiste latenties. Schaalbaarheidstests zijn met name belangrijk voor deze onderdelen:
- Gegevensopname om gelijktijdige gegevensstromen te verwerken. In deze architectuur wordt Event Hubs gebruikt omdat meerdere exemplaren ervan kunnen worden geïmplementeerd en toegewezen aan verschillende consumentengroepen. Een uitschaalbenadering is een betere optie omdat omhoog schalen kan leiden tot vergrendeling. Een uitschaalbenadering is ook beter geschikt als u van plan bent om fraudedetectie van mobiel bankwezen uit te breiden om een internetbankierkanaal op te nemen.
- Een framework voor het beheren en plannen van de processtroom. Azure Functions wordt gebruikt om de werkstroom te organiseren. Voor een verbeterde doorvoer worden berichten in batches in batches verwerkt en verwerkt via één Azure-functie in plaats van één bericht per functie-aanroep te verwerken.
- Een gegevensproces met lage latentie voor het verwerken van parseren, voorverwerking, aggregaties en opslag. In de echte oplossing waarop dit artikel is gebaseerd, voldoen de mogelijkheden van geoptimaliseerde SQL-functies in het geheugen aan schaalbaarheids- en gelijktijdigheidsvereisten.
- Modelscore voor het verwerken van gelijktijdige aanvragen. Met Azure Machine Learning-webservices hebt u twee opties voor schalen:
- Selecteer een productieweblaag ter ondersteuning van de gelijktijdigheidsworkload van de API.
- Voeg meerdere eindpunten toe aan een webservice als u meer dan 200 gelijktijdige aanvragen wilt ondersteunen.
Bijdragers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Kate Baroni | Principal Customer Engineer
- Michael Hlobil | Principal Customer Engineering Manager
- Cedric Labuschagne | Technical Program Manager
- Frank Garofalo | Principal Customer Engineer
- Shep Sheppard | Senior Service Engineer
Andere inzender:
- Mick Alberts | Technische schrijver
Volgende stappen
- Een snelle, serverloze big data-pijplijn mogelijk gemaakt door één Azure-functie
- Azure Functions overwegen voor een scenario voor serverloze gegevensstreaming
- Netwerkoverwegingen voor App Service Environment
- Event Hubs
- Sleutelkluis
- Azure Machine Learning