En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av den avgränsade textdatauppsättningen.
Property
Beskrivning
Obligatoriskt
type
Datamängdens typegenskap måste anges till Avgränsadtext.
Ja
plats
Platsinställningar för filen eller filerna. Varje filbaserad anslutningsapp har en egen platstyp och egenskaper som stöds under location.
Ja
columnDelimiter
De tecken som används för att separera kolumner i en fil. Standardvärdet är kommatecken ,. När kolumn avgränsaren definieras som tom sträng, vilket innebär att ingen avgränsare, tas hela raden som en enda kolumn. För närvarande stöds kolumngränsare som tom sträng endast för mappning av dataflöde men inte aktiviteten Kopiera.
Nej
rowDelimiter
För aktiviteten Kopiera används det enskilda tecknet eller "\r\n" för att separera rader i en fil. Standardvärdet är något av följande värden vid läsning: ["\r\n", "\r", "\n"]; vid skrivning: "\r\n". "\r\n" stöds endast i kopieringskommandot. För Mappning av dataflöde används de enskilda eller två tecknen för att separera rader i en fil. Standardvärdet är något av följande värden vid läsning: ["\r\n", "\r", "\n"]; vid skrivning: "\n". När radgränsaren inte har angetts till någon avgränsare (tom sträng) måste kolumn avgränsaren också anges som ingen avgränsare (tom sträng), vilket innebär att hela innehållet behandlas som ett enda värde. För närvarande stöds radgränsare som tom sträng endast för mappning av dataflöde men inte aktiviteten Kopiera.
Nej
quoteChar
Det enkla tecknet för att citera kolumnvärden om det innehåller kolumn avgränsare. Standardvärdet är dubbla citattecken". När quoteChar definieras som tom sträng innebär det att det inte finns något citattecken och att kolumnvärdet inte citeras och escapeChar används för att undkomma kolumn avgränsaren och sig själv.
Nej
escapeChar
Det enkla tecknet för att undkomma citattecken i ett citerat värde. Standardvärdet är omvänt snedstreck \. När escapeChar definieras som tom sträng måste också quoteChar anges som tom sträng, i vilket fall se till att alla kolumnvärden inte innehåller avgränsare.
Nej
firstRowAsHeader
Anger om du vill behandla/göra den första raden som en rubrikrad med namn på kolumner. Tillåtna värden är true och false (standard). När den första raden som rubrik är falsk, observera att UI-dataförhandsgranskning och uppslagsaktivitet genererar kolumnnamn automatiskt som Prop_{n} (från och med 0), kräver kopieringsaktivitet explicit mappning från källa till mottagare och letar upp kolumner efter ordning (från 1) och mappar dataflödeslistor och letar upp kolumner med namn som Column_{n} (från och med 1).
Nej
nullValue
Anger strängrepresentationen av null-värdet. Standardvärdet är tom sträng.
Nej
encodingName
Kodningstypen som används för att läsa/skriva testfiler. Tillåtna värden är följande: "UTF-8",UTF-8 utan BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM86"4", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859 -3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Observera att dataflödet för mappning inte stöder UTF-7-kodning. Observera att dataflödet för mappning inte stöder UTF-8-kodning med Byte Order Mark (BOM).
Nej
compressionCodec
Komprimeringskodcen som används för att läsa/skriva textfiler. Tillåtna värden är bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy eller lz4. Standardvärdet komprimeras inte. Observera för närvarande aktiviteten Kopiera inte stöder "snappy" och "lz4", och mappning av dataflöde stöder inte "ZipDeflate", "TarGzip" och "Tar". Observera att när du använder kopieringsaktivitet för att dekomprimera ZipDeflate/TarGzip/Tar-filer och skriva till filbaserade mottagardatalager extraheras som standardfiler till mappen:<path specified in dataset>/<folder named as source compressed file>/, använd/preserveCompressionFileNameAsFolderpreserveZipFileNameAsFolderpå kopieringsaktivitetskällan för att kontrollera om namnet på de komprimerade filerna ska behållas som mappstruktur.
Nej
compressionLevel
Komprimeringsförhållandet. Tillåtna värden är optimala eller snabbaste. - Snabbast: Komprimeringsåtgärden bör slutföras så snabbt som möjligt, även om den resulterande filen inte komprimeras optimalt. - Optimal: Komprimeringsåtgärden bör komprimeras optimalt, även om åtgärden tar längre tid att slutföra. Mer information finns i avsnittet Komprimeringsnivå .
Nej
Nedan visas ett exempel på avgränsad textdatauppsättning i Azure Blob Storage:
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av den avgränsade textkällan och mottagaren.
Avgränsad text som källa
Följande egenskaper stöds i avsnittet kopieringsaktivitet *källa* .
Property
Beskrivning
Obligatoriskt
type
Typegenskapen för kopieringsaktivitetskällan måste anges till AvgränsadTextSource.
Ja
formatInställningar
En grupp med egenskaper. Läs inställningstabellen för avgränsad text nedan.
Nej
storeSettings
En grupp med egenskaper för hur du läser data från ett datalager. Varje filbaserad anslutningsapp har egna läsinställningar som stöds under storeSettings.
Nej
Inställningar för avgränsad textläsning som stöds under formatSettings:
Property
Beskrivning
Obligatoriskt
type
Typen av formatInställningar måste anges till AvgränsadeTextReadSettings.
Ja
skipLineCount
Anger antalet rader som inte är tomma att hoppa över när du läser data från indatafiler. Om både skipLineCount och firstRowAsHeader anges hoppas raderna över först, varefter rubrikinformationen läses från indatafilen.
Nej
compressionProperties
En grupp med egenskaper för hur du dekomprimeras data för en viss komprimeringskodc.
Nej
preserveZipFileNameAsFolder (under compressionProperties->type som ZipDeflateReadSettings)
Gäller när indatauppsättningen konfigureras med ZipDeflate-komprimering . Anger om käll-zip-filnamnet ska behållas som mappstruktur under kopiering. – När värdet är true (standard) skriver tjänsten uppackade filer till <path specified in dataset>/<folder named as source zip file>/. – När värdet är falskt skriver tjänsten uppackade filer direkt till <path specified in dataset>. Kontrollera att du inte har duplicerade filnamn i olika zip-källfiler för att undvika racing eller oväntat beteende.
Nej
preserveCompressionFileNameAsFolder (under compressionProperties->type som TarGZipReadSettings eller TarReadSettings)
Gäller när indatauppsättningen konfigureras med TarGzip/Tar-komprimering. Anger om källans komprimerade filnamn ska bevaras som mappstruktur under kopieringen. – När värdet är true (standard) skriver tjänsten dekomprimerade filer till <path specified in dataset>/<folder named as source compressed file>/. – När värdet är falskt skriver tjänsten dekomprimerade filer direkt till <path specified in dataset>. Kontrollera att du inte har duplicerade filnamn i olika källfiler för att undvika racing eller oväntat beteende.
Följande egenskaper stöds i avsnittet kopieringsaktivitet *mottagare* .
Property
Beskrivning
Obligatoriskt
type
Typegenskapen för kopieringsaktivitetskällan måste anges till AvgränsadTextSink.
Ja
formatInställningar
En grupp med egenskaper. Se tabellen Inställningar för avgränsad textskrivning nedan.
Nej
storeSettings
En grupp med egenskaper för hur du skriver data till ett datalager. Varje filbaserad anslutningsapp har egna skrivinställningar som stöds under storeSettings.
Nej
Inställningar för avgränsad textskrivning som stöds under formatSettings:
Property
Beskrivning
Obligatoriskt
type
Typen av formatInställningar måste anges till AvgränsadeTextWriteSettings.
Ja
fileExtension
Filnamnstillägget som används för att namnge utdatafilerna, .csvtill exempel , .txt. Det måste anges när fileName inte anges i datauppsättningen DelimitedText för utdata. När filnamnet har konfigurerats i utdatauppsättningen används det som mottagarfilnamn och filnamnsinställningen ignoreras.
Ja när filnamnet inte anges i utdatauppsättningen
maxRowsPerFile
När du skriver data till en mapp kan du välja att skriva till flera filer och ange maximalt antal rader per fil.
Nej
fileNamePrefix
Tillämpligt när maxRowsPerFile har konfigurerats. Ange filnamnsprefixet när du skriver data till flera filer, vilket resulterade i det här mönstret: <fileNamePrefix>_00000.<fileExtension>. Om det inte anges genereras filnamnsprefixet automatiskt. Den här egenskapen gäller inte när källan är filbaserad lagring eller partitionsalternativaktiverat datalager.
Mappning av dataflöden stöder "infogade datauppsättningar" som ett alternativ för att definiera din källa och mottagare. En infogad avgränsad datauppsättning definieras direkt i dina käll- och mottagartransformeringar och delas inte utanför det definierade dataflödet. Det är användbart för att parametrisera datamängdsegenskaper direkt i ditt dataflöde och kan dra nytta av bättre prestanda från delade ADF-datamängder.
När du läser ett stort antal källmappar och filer kan du förbättra prestandan för identifiering av dataflödesfiler genom att ange alternativet "Användarprojekterat schema" i Projektion | Dialogrutan Schemaalternativ. Det här alternativet inaktiverar automatisk identifiering av ADF-standardschemat och förbättrar prestandan för filidentifiering avsevärt. Innan du anger det här alternativet måste du importera projektionen så att ADF har ett befintligt schema för projektion. Det här alternativet fungerar inte med schemaavvikelse.
Källegenskaper
Tabellen nedan visar de egenskaper som stöds av en avgränsad textkälla. Du kan redigera dessa egenskaper på fliken Källalternativ .
Name
beskrivning
Obligatoriskt
Tillåtna värden
Egenskap för dataflödesskript
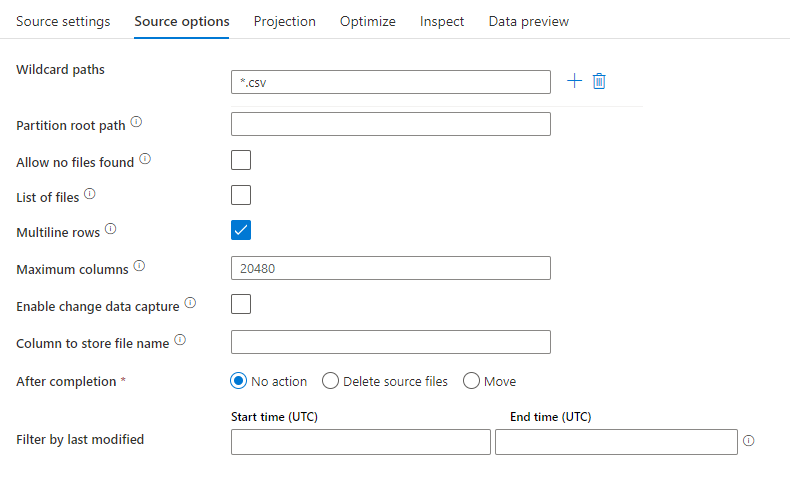
Sökvägar för jokertecken
Alla filer som matchar sökvägen för jokertecken bearbetas. Åsidosätter den mapp och filsökväg som angetts i datauppsättningen.
nej
Sträng[]
wildcardPaths
Partitionsrotsökväg
För fildata som är partitionerade kan du ange en partitionsrotsökväg för att läsa partitionerade mappar som kolumner
nej
String
partitionRootPath
Lista över filer
Om källan pekar på en textfil som visar filer som ska bearbetas
nej
true eller false
fileList
Rader med flera rader
Innehåller källfilen rader som sträcker sig över flera rader. Flerradsvärden måste vara inom citattecken.
nej true eller false
multiLineRow
Kolumn för att lagra filnamn
Skapa en ny kolumn med källfilens namn och sökväg
nej
String
rowUrlColumn
Efter slutförande
Ta bort eller flytta filerna efter bearbetningen. Filsökvägen startar från containerroten
nej
Ta bort: true eller false Flytta: ['<from>', '<to>']
purgeFiles moveFiles
Filtrera efter senast ändrad
Välj att filtrera filer baserat på när de senast ändrades
nej
Tidsstämpel
modifiedAfter modifiedBefore
Tillåt att inga filer hittas
Om sant utlöses inte ett fel om inga filer hittas
nej
true eller false
ignoreNoFilesFound
Maximalt antal kolumner
Standardvärdet är 20480. Anpassa det här värdet när kolumnnumret är över 20480
nej
Integer
maxColumns
Anteckning
Stöd för dataflödeskällor för listan över filer är begränsat till 1 024 poster i filen. Om du vill inkludera fler filer använder du jokertecken i fillistan.
Källexempel
Bilden nedan är ett exempel på en avgränsad textkällaskonfiguration i mappning av dataflöden.
 Azure Data Factory
Azure Data Factory