Onlineslutpunkter och distributioner för slutsatsdragning i realtid
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Med Azure Machine Learning kan du utföra realtidsinferenser på data med hjälp av modeller som distribueras till onlineslutpunkter. Slutsatsdragning är processen att tillämpa nya indata på en maskininlärningsmodell för att generera utdata. Även om dessa utdata vanligtvis kallas "förutsägelser" kan slutsatsdragning användas för att generera utdata för andra maskininlärningsuppgifter, till exempel klassificering och klustring.
Onlineslutpunkter
Onlineslutpunkter distribuerar modeller till en webbserver som kan returnera förutsägelser under HTTP-protokollet. Använd onlineslutpunkter för att operationalisera modeller för realtidsinferens i synkrona begäranden med låg svarstid. Vi rekommenderar att du använder dem när:
- Du har krav på låg latens
- Din modell kan besvara begäran på relativt kort tid
- Modellens indata får plats på HTTP-nyttolasten för begäran
- Du måste skala upp när det gäller antalet begäranden
Om du vill definiera en slutpunkt måste du ange:
- Slutpunktsnamn: Det här namnet måste vara unikt i Azure-regionen. Mer information om namngivningsreglerna finns i slutpunktsgränser.
- Autentiseringsläge: Du kan välja mellan nyckelbaserat autentiseringsläge, tokenbaserat autentiseringsläge i Azure Machine Learning eller Microsoft Entra-tokenbaserad autentisering (förhandsversion) för slutpunkten. Mer information om autentisering finns i Autentisera till en onlineslutpunkt.
Azure Machine Learning gör det enklare att använda hanterade onlineslutpunkter för att distribuera dina maskininlärningsmodeller på ett nyckelfärdigt sätt. Det här är det rekommenderade sättet att använda onlineslutpunkter i Azure Machine Learning. Hanterade onlineslutpunkter körs skalbart och helt hanterat på datorer med kraftfulla processorer och grafikkort i Azure. De här slutpunkterna tar även hand om servering, skalning, skydd och övervakning av dina modeller för att frigöra dig från kostnaderna för att konfigurera och hantera den underliggande infrastrukturen. Information om hur du definierar en hanterad onlineslutpunkt finns i Definiera slutpunkten.
Varför välja hanterade onlineslutpunkter framför ACI eller AKS(v1)?
Användning av hanterade onlineslutpunkter är det rekommenderade sättet att använda onlineslutpunkter i Azure Machine Learning. I följande tabell visas nyckelattributen för hanterade onlineslutpunkter jämfört med Azure Machine Learning SDK/CLI v1-lösningar (ACI och AKS(v1)).
| Attribut | Hanterade onlineslutpunkter (v2) | ACI eller AKS(v1) |
|---|---|---|
| Nätverkssäkerhet/isolering | Enkel inkommande/utgående kontroll med snabb växling | Virtuellt nätverk stöds inte eller kräver komplex manuell konfiguration |
| Hanterad tjänst | – Fullständigt hanterad beräkningsetablering/skalning – Nätverkskonfiguration för dataexfiltreringsskydd – Uppgradering av värdoperativsystem, kontrollerad distribution av uppdateringar på plats |
– Skalning är begränsad i v1 – Nätverkskonfiguration eller uppgradering måste hanteras av användaren |
| Slutpunkt/distributionskoncept | Skillnaden mellan slutpunkt och distribution möjliggör komplexa scenarier som säker distribution av modeller | Inget begrepp för slutpunkt |
| Diagnostik och övervakning | – Lokal slutpunktsfelsökning möjlig med Docker och Visual Studio Code – Avancerad mått- och logganalys med diagram/fråga för att jämföra mellan distributioner – Kostnadsuppdelning ned till distributionsnivå |
Ingen enkel lokal felsökning |
| Skalbarhet | Obegränsad, elastisk och automatisk skalning | – ACI är inte skalbar – AKS (v1) stöder endast skalning i kluster och kräver skalbarhetskonfiguration |
| Företagsberedskap | Privat länk, kundhanterade nycklar, Microsoft Entra-ID, kvothantering, faktureringsintegrering, serviceavtal | Stöds inte |
| Avancerade ML-funktioner | – Modelldatainsamling – Modellövervakning - Champion-challengermodell, säker distribution, trafikspegling – Ansvarsfull AI-utökningsbarhet |
Stöds inte |
Om du föredrar att använda Kubernetes för att distribuera dina modeller och hantera slutpunkter, och du är bekväm med att hantera infrastrukturkrav, kan du använda Kubernetes onlineslutpunkter. Med de här slutpunkterna kan du distribuera modeller och hantera onlineslutpunkter i ditt fullständigt konfigurerade och hanterade Kubernetes-kluster var som helst, med processorer eller GPU:er.
Varför välja hanterade onlineslutpunkter framför AKS(v2)?
Hanterade onlineslutpunkter kan hjälpa dig att effektivisera distributionsprocessen och ge följande fördelar jämfört med Kubernetes onlineslutpunkter:
Hanterad infrastruktur
- Etablerar automatiskt beräkningen och är värd för modellen (du behöver bara ange VM-typ och skalningsinställningar)
- Uppdaterar och korrigerar automatiskt den underliggande värdoperativsystemavbildningen
- Utför automatiskt nodåterställning om det uppstår ett systemfel
Övervakning och loggar
- Övervaka modelltillgänglighet, prestanda och serviceavtal med inbyggd integrering med Azure Monitor.
- Felsöka distributioner med hjälp av loggar och intern integrering med Azure Log Analytics.
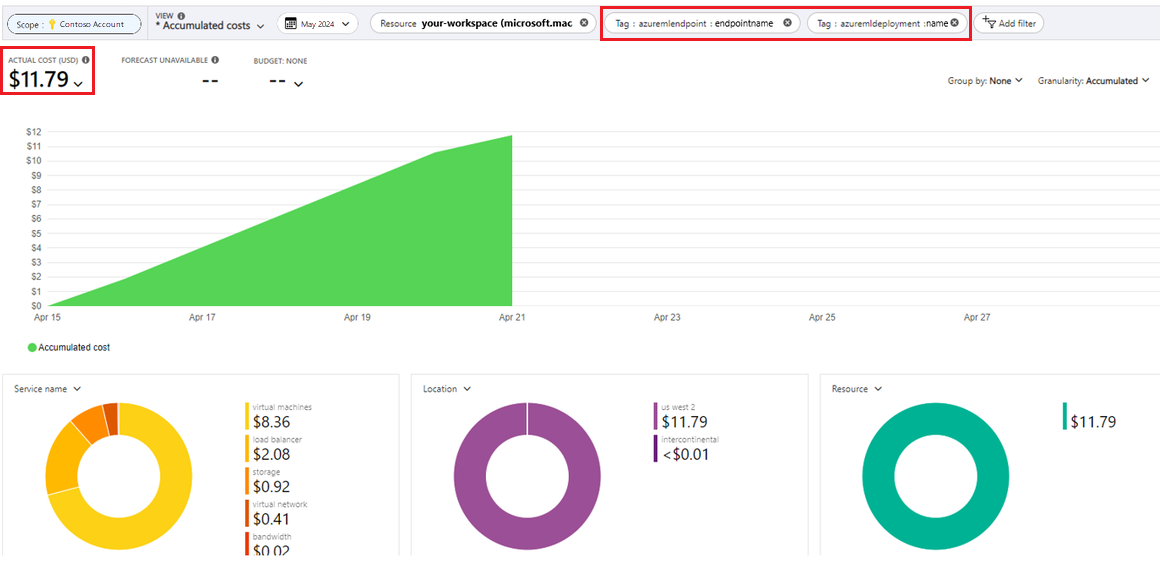
Visa kostnader
- Med hanterade onlineslutpunkter kan du övervaka kostnader på slutpunkts- och distributionsnivå
Kommentar
Hanterade onlineslutpunkter baseras på Azure Machine Learning-beräkning. När du använder en hanterad onlineslutpunkt betalar du för beräknings- och nätverksavgifterna. Det finns ingen extra tilläggsavgift. Mer information om priser finns i priskalkylatorn för Azure.
Om du använder ett virtuellt Azure Machine Learning-nätverk för att skydda utgående trafik från den hanterade onlineslutpunkten debiteras du för utgående regler för azure private link och FQDN som används av det hanterade virtuella nätverket. Mer information finns i Priser för hanterade virtuella nätverk.


Hanterade onlineslutpunkter jämfört med kubernetes onlineslutpunkter
I följande tabell visas de viktigaste skillnaderna mellan hanterade onlineslutpunkter och Kubernetes onlineslutpunkter.
| Hanterade onlineslutpunkter | Kubernetes onlineslutpunkter (AKS(v2)) | |
|---|---|---|
| Rekommenderade användare | Användare som vill ha en hanterad modelldistribution och förbättrad MLOps-upplevelse | Användare som föredrar Kubernetes och själva kan hantera infrastrukturkrav |
| Nodetablering | Hanterad beräkningsetablering, uppdatering, borttagning | Användaransvar |
| Nodunderhåll | Avbildningsuppdateringar för hanterade värdoperativsystem och säkerhetshärdning | Användaransvar |
| Klusterstorlek (skalning) | Hanterad manuell och autoskalning med stöd för ytterligare nodertablering | Manuell och autoskalning med stöd för skalning av antalet repliker inom fasta klustergränser |
| Beräkningstyp | Hanteras av tjänsten | Kundhanterat Kubernetes-kluster (Kubernetes) |
| Hanterade identiteter | Stöds | Stöds |
| Virtuellt nätverk (VNET) | Stöds via hanterad nätverksisolering | Användaransvar |
| Out-of-box-övervakning och loggning | Azure Monitor och Log Analytics drivs (innehåller nyckelmått och loggtabeller för slutpunkter och distributioner) | Användaransvar |
| Loggning med Application Insights (äldre) | Stöds | Stöds |
| Visa kostnader | Detaljerad till slutpunkt/distributionsnivå | Klusternivå |
| Kostnad som tillämpas på | Virtuella datorer som tilldelats distributionerna | Virtuella datorer som tilldelats klustret |
| Speglad trafik | Stöds | Stöd saknas |
| Distribution utan kod | Stöds (MLflow- och Triton-modeller ) | Stöds (MLflow- och Triton-modeller ) |
Onlinedistributioner
En distribution är en uppsättning resurser och beräkningar som krävs för att vara värd för den modell som utför den faktiska inferensen. En enskild slutpunkt kan innehålla flera distributioner med olika konfigurationer. Den här konfigurationen hjälper till att frikoppla gränssnittet som visas av slutpunkten från implementeringsinformationen som finns i distributionen. En onlineslutpunkt har en routningsmekanism som kan dirigera begäranden till specifika distributioner i slutpunkten.
Följande diagram visar en onlineslutpunkt som har två distributioner, blå och gröna. Den blå distributionen använder virtuella datorer med en CPU-SKU och kör version 1 av en modell. Den gröna distributionen använder virtuella datorer med en GPU SKU och kör version 2 av modellen. Slutpunkten är konfigurerad för att dirigera 90 % av inkommande trafik till den blå distributionen, medan den gröna distributionen tar emot de återstående 10 %.

Om du vill distribuera en modell måste du ha:
- Modellfiler (eller namnet och versionen av en modell som redan är registrerad på din arbetsyta).
- Ett bedömningsskript, d.v.s. kod som kör modellen på en viss indatabegäran. Bedömningsskriptet tar emot data som skickats till en distribuerad webbtjänst och skickar dem till modellen. Skriptet kör sedan modellen och returnerar svaret till klienten. Bedömningsskriptet är specifikt för din modell och måste förstå de data som modellen förväntar sig som indata och returnerar som utdata.
- En miljö där din modell körs. Miljön kan vara en Docker-avbildning med Conda-beroenden eller en Dockerfile.
- Inställningar för att ange instanstyp och skalningskapacitet.
Viktiga attribut för en distribution
I följande tabell beskrivs nyckelattributen för en distribution:
| Attribut | Beskrivning |
|---|---|
| Name | Namnet på distributionen. |
| Slutpunktnamn | Namnet på slutpunkten som distributionen ska skapas under. |
| Modell1 | Den modell som ska användas för distributionen. Det här värdet kan antingen vara en referens till en befintlig version av modellen på arbetsytan eller en infogad modellspecifikation. Mer information om hur du spårar och anger sökvägen till din modell finns i Identifiera modellsökväg med avseende AZUREML_MODEL_DIRpå . |
| Kodsökväg | Sökvägen till katalogen i den lokala utvecklingsmiljön som innehåller all Python-källkod för bedömning av modellen. Du kan använda kapslade kataloger och paket. |
| Bedömningsskript | Den relativa sökvägen till bedömningsfilen i källkodskatalogen. Den här Python-koden måste ha en init() funktion och en run() funktion. Funktionen init() anropas när modellen har skapats eller uppdaterats (du kan till exempel använda den för att cachelagra modellen i minnet). Funktionen run() anropas vid varje anrop av slutpunkten för att utföra den faktiska poängsättningen och förutsägelsen. |
| Miljö1 | Miljön som ska vara värd för modellen och koden. Det här värdet kan antingen vara en referens till en befintlig version av miljön på arbetsytan eller en infogad miljöspecifikation. Obs! Microsoft korrigerar regelbundet basavbildningarna för kända säkerhetsrisker. Du måste distribuera om slutpunkten för att använda den korrigerade avbildningen. Om du anger en egen avbildning ansvarar du för att uppdatera den. Mer information finns i Bildkorrigering. |
| Instanstyp | Den VM-storlek som ska användas för distributionen. Listan över storlekar som stöds finns i SKU-listan för hanterade onlineslutpunkter. |
| Antal instanser | Antalet instanser som ska användas för distributionen. Basera värdet på den arbetsbelastning du förväntar dig. För hög tillgänglighet rekommenderar vi att du anger värdet till minst 3. Vi reserverar ytterligare 20 % för att utföra uppgraderingar. Mer information finns i kvotallokering för virtuella datorer för distributioner. |
1 Några saker att notera om modellen och miljön:
- Modellen och containeravbildningen (enligt definitionen i Miljö) kan när som helst refereras igen av distributionen när instanserna bakom distributionen går igenom säkerhetskorrigeringar och/eller andra återställningsåtgärder. Om du använder en registrerad modell eller containeravbildning i Azure Container Registry för distribution och tar bort modellen eller containeravbildningen, kan distributionerna som förlitar sig på dessa tillgångar misslyckas när avbildningen görs igen. Om du tar bort modellen eller containeravbildningen kontrollerar du att de beroende distributionerna återskapas eller uppdateras med en alternativ modell eller containeravbildning.
- Containerregistret som miljön refererar till kan endast vara privat om slutpunktsidentiteten har behörighet att komma åt den via Microsoft Entra-autentisering och Azure RBAC. Av samma anledning stöds inte privata Docker-register förutom Azure Container Registry.
Information om hur du distribuerar onlineslutpunkter med hjälp av mallen CLI, SDK, studio och ARM finns i Distribuera en ML-modell med en onlineslutpunkt.
Identifiera modellsökväg med avseende på AZUREML_MODEL_DIR
När du distribuerar din modell till Azure Machine Learning måste du ange platsen för den modell som du vill distribuera som en del av distributionskonfigurationen. I Azure Machine Learning spåras sökvägen till din modell med AZUREML_MODEL_DIR miljövariabeln. Genom att AZUREML_MODEL_DIRidentifiera modellsökvägen med avseende på kan du distribuera en eller flera modeller som lagras lokalt på datorn eller distribuera en modell som är registrerad på din Azure Machine Learning-arbetsyta.
Som illustration refererar vi till följande lokala mappstruktur för de två första fallen där du distribuerar en enskild modell eller distribuerar flera modeller som lagras lokalt:

Använda en enda lokal modell i en distribution
Om du vill använda en enda modell som du har på din lokala dator i en distribution anger du path till model i din distributions YAML. Här är ett exempel på yaml-distributionen med sökvägen /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
När du har skapat distributionen pekar miljövariabeln AZUREML_MODEL_DIR på lagringsplatsen i Azure där din modell lagras. Innehåller till exempel /var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 modellen sample_m1.pkl.
I ditt bedömningsskript (score.py) kan du läsa in din modell (i det här exemplet sample_m1.pkl) i init() funktionen:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "sample_m1.pkl")
model = joblib.load(model_path)
Använda flera lokala modeller i en distribution
Även om Azure CLI, Python SDK och andra klientverktyg gör att du bara kan ange en modell per distribution i distributionsdefinitionen kan du fortfarande använda flera modeller i en distribution genom att registrera en modellmapp som innehåller alla modeller som filer eller underkataloger.
I föregående exempelmappstruktur ser du att det finns flera modeller i models mappen. I din distributions-YAML kan du ange sökvägen till mappen på models följande sätt:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
När du har skapat distributionen pekar miljövariabeln AZUREML_MODEL_DIR på lagringsplatsen i Azure där dina modeller lagras. Innehåller till exempel /var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 modellerna och filstrukturen.
I det här exemplet ser innehållet i AZUREML_MODEL_DIR mappen ut så här:

I ditt bedömningsskript (score.py) kan du läsa in dina modeller i init() funktionen. Följande kod läser in sample_m1.pkl modellen:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "models","model_1","v1", "sample_m1.pkl ")
model = joblib.load(model_path)
Ett exempel på hur du distribuerar flera modeller till en distribution finns i Distribuera flera modeller till en distribution (CLI-exempel) och Distribuera flera modeller till en distribution (SDK-exempel).
Dricks
Om du har fler än 1 500 filer att registrera kan du överväga att komprimera filerna eller underkatalogerna som .tar.gz när du registrerar modellerna. Om du vill använda modellerna kan du avkomprimera filerna eller underkatalogerna i init() funktionen från bedömningsskriptet. När du registrerar modellerna kan du också ange azureml.unpack egenskapen till True, för att automatiskt ta bort komprimera filer eller underkataloger. I båda fallen sker avkomprimering en gång i initieringssteget.
Använda modeller som är registrerade på din Azure Machine Learning-arbetsyta i en distribution
Om du vill använda en eller flera modeller som är registrerade på din Azure Machine Learning-arbetsyta anger du namnet på de registrerade modellerna i din distributions-YAML i distributionen. Följande YAML-konfiguration för distribution anger till exempel det registrerade model namnet som azureml:local-multimodel:3:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:local-multimodel:3
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
I det här exemplet bör du tänka på att local-multimodel:3 innehåller följande modellartefakter, som kan visas från fliken Modeller i Azure Machine Learning-studio:

När du har skapat distributionen pekar miljövariabeln AZUREML_MODEL_DIR på lagringsplatsen i Azure där dina modeller lagras. Innehåller till exempel /var/azureml-app/azureml-models/local-multimodel/3 modellerna och filstrukturen. AZUREML_MODEL_DIR pekar på mappen som innehåller roten för modellartefakterna.
Baserat på det här exemplet ser innehållet i AZUREML_MODEL_DIR mappen ut så här:

I ditt bedömningsskript (score.py) kan du läsa in dina modeller i init() funktionen. Läs till exempel in diabetes.sav modellen:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR"), "models", "diabetes", "1", "diabetes.sav")
model = joblib.load(model_path)
Kvotallokering för virtuell dator för distribution
För hanterade onlineslutpunkter reserverar Azure Machine Learning 20 % av dina beräkningsresurser för att utföra uppgraderingar på vissa VM-SKU:er. Om du begär ett visst antal instanser för de virtuella dator-SKU:erna i en distribution måste du ha en kvot för tillgänglig för ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU att undvika ett fel. Om du till exempel begär 10 instanser av en Standard_DS3_v2 virtuell dator (som levereras med fyra kärnor) i en distribution bör du ha en kvot för 48 kärnor (12 instances * 4 cores) tillgänglig. Den här extra kvoten är reserverad för systeminitierade åtgärder, till exempel OS-uppgraderingar och återställning av virtuella datorer, och den medför inte kostnader om inte sådana åtgärder körs.
Det finns vissa VM-SKU:er som är undantagna från extra kvotreservation. Om du vill visa den fullständiga listan kan du läsa SKU-listan hanterade onlineslutpunkter.
Information om hur du visar ökningar av användnings- och begärandekvoter finns i Visa din användning och dina kvoter i Azure-portalen. Information om hur du visar kostnaden för att köra en hanterad onlineslutpunkt finns i Visa kostnader för en hanterad onlineslutpunkt.
Azure Machine Learning tillhandahåller en delad kvotpool från vilken alla användare kan komma åt kvoten för att utföra testning under en begränsad tid. När du använder studion för att distribuera Llama-modeller (från modellkatalogen) till en hanterad onlineslutpunkt ger Azure Machine Learning dig åtkomst till den här delade kvoten under en kort tid.
Om du vill distribuera en Llama-2-70b- eller Llama-2-70b-chat-modell måste du dock ha en företagsavtal prenumeration innan du kan distribuera med den delade kvoten. Mer information om hur du använder den delade kvoten för distribution av onlineslutpunkter finns i Distribuera grundmodeller med hjälp av studion.
Mer information om kvoter och gränser för resurser i Azure Machine Learning finns i Hantera och öka kvoter och gränser för resurser med Azure Machine Learning.
Distribution för kodare och icke-kodare
Azure Machine Learning stöder modelldistribution till onlineslutpunkter för både kodare och icke-kodare genom att tillhandahålla alternativ för distribution utan kod, distribution med låg kod och BYOC-distribution (Bring Your Own Container).
- Distribution utan kod ger färdiga slutsatsdragningar för vanliga ramverk (till exempel scikit-learn, TensorFlow, PyTorch och ONNX) via MLflow och Triton.
- Med distribution med låg kod kan du tillhandahålla minimal kod tillsammans med din maskininlärningsmodell för distribution.
- Med BYOC-distributionen kan du praktiskt taget ta med alla containrar för att köra din onlineslutpunkt. Du kan använda alla Azure Machine Learning-plattformsfunktioner som autoskalning, GitOps, felsökning och säker distribution för att hantera dina MLOps-pipelines.
I följande tabell beskrivs viktiga aspekter av distributionsalternativen online:
| Ingen kod | Låg kod | BYOC | |
|---|---|---|---|
| Sammanfattning | Använder färdiga inferenser för populära ramverk som scikit-learn, TensorFlow, PyTorch och ONNX via MLflow och Triton. Mer information finns i Distribuera MLflow-modeller till onlineslutpunkter. | Använder säkra, offentligt publicerade granskade bilder för populära ramverk, med uppdateringar varannan vecka för att åtgärda säkerhetsrisker. Du tillhandahåller bedömningsskript och/eller Python-beroenden. Mer information finns i Azure Machine Learning-kurerade miljöer. | Du tillhandahåller din fullständiga stack via Azure Machine Learnings stöd för anpassade avbildningar. Mer information finns i Använda en anpassad container för att distribuera en modell till en onlineslutpunkt. |
| Anpassad basavbildning | Nej, en kuraterad miljö tillhandahåller detta för enkel distribution. | Ja och Nej, du kan antingen använda en kuraterad bild eller en anpassad avbildning. | Ja, ta med en tillgänglig containeravbildningsplats (till exempel docker.io, Azure Container Registry (ACR) eller Microsoft Container Registry (MCR)) eller en Dockerfile som du kan skapa/push-överföra med ACR för din container. |
| Anpassade beroenden | Nej, en kuraterad miljö tillhandahåller detta för enkel distribution. | Ja, ta med Azure Machine Learning-miljön där modellen körs. antingen en Docker-avbildning med Conda-beroenden eller en dockerfile. | Ja, detta kommer att ingå i containeravbildningen. |
| Anpassad kod | Nej, bedömningsskriptet genereras automatiskt för enkel distribution. | Ja, ta med ditt bedömningsskript. | Ja, detta kommer att ingå i containeravbildningen. |
Kommentar
AutoML-körningar skapar ett bedömningsskript och beroenden automatiskt för användare, så att du kan distribuera valfri AutoML-modell utan att skapa ytterligare kod (för distribution utan kod) eller så kan du ändra automatiskt genererade skript till dina affärsbehov (för distribution med låg kod). Information om hur du distribuerar med AutoML-modeller finns i Distribuera en AutoML-modell med en onlineslutpunkt.
Felsökning av slutpunkt online
Vi rekommenderar starkt att du testkör slutpunkten lokalt för att verifiera och felsöka koden och konfigurationen innan du distribuerar till Azure. Azure CLI och Python SDK stöder lokala slutpunkter och distributioner, medan Azure Machine Learning-studio- och ARM-mallen inte gör det.
Azure Machine Learning tillhandahåller olika sätt att felsöka onlineslutpunkter lokalt och med hjälp av containerloggar.
- Lokal felsökning med HTTP-server för Azure Machine Learning-slutsatsdragning
- Lokal felsökning med lokal slutpunkt
- Lokal felsökning med lokal slutpunkt och Visual Studio Code
- Felsökning med containerloggar
Lokal felsökning med HTTP-server för Azure Machine Learning-slutsatsdragning
Du kan felsöka ditt bedömningsskript lokalt med hjälp av HTTP-servern för Azure Machine Learning-slutsatsdragning. HTTP-servern är ett Python-paket som exponerar din bedömningsfunktion som en HTTP-slutpunkt och omsluter Flask-serverkoden och beroendena till ett enda paket. Den ingår i de fördefinierade Docker-avbildningarna för slutsatsdragning som används när du distribuerar en modell med Azure Machine Learning. Med enbart paketet kan du distribuera modellen lokalt för produktion och du kan också enkelt verifiera ditt bedömningsskript (post) i en lokal utvecklingsmiljö. Om det uppstår ett problem med bedömningsskriptet returnerar servern ett fel och platsen där felet inträffade. Du kan också använda Visual Studio Code för att felsöka med HTTP-servern för Azure Machine Learning-slutsatsdragning.
Dricks
Du kan använda Azure Machine Learning-inferensen HTTP Server Python-paketet för att felsöka ditt bedömningsskript lokalt utan Docker Engine. Felsökning med slutsatsdragningsservern hjälper dig att felsöka bedömningsskriptet innan du distribuerar till lokala slutpunkter så att du kan felsöka utan att påverkas av konfigurationerna av distributionscontainer.
Mer information om felsökning med HTTP-servern finns i Felsökning av bedömningsskript med Azure Machine Learning-slutsatsdragning av HTTP-server.
Lokal felsökning med lokal slutpunkt
För lokal felsökning behöver du en lokal distribution, dvs. en modell som distribueras till en lokal Docker-miljö. Du kan använda den här lokala distributionen för testning och felsökning innan du distribuerar till molnet. Om du vill distribuera lokalt måste du ha Docker-motorn installerad och igång. Azure Machine Learning skapar sedan en lokal Docker-avbildning som efterliknar Azure Machine Learning-avbildningen. Azure Machine Learning skapar och kör distributioner åt dig lokalt och cachelagrar avbildningen för snabba iterationer.
Dricks
Docker Engine startar vanligtvis när datorn startas. Om den inte gör det kan du felsöka Docker Engine. Du kan använda verktyg på klientsidan, till exempel Docker Desktop, för att felsöka vad som händer i containern.
Stegen för lokal felsökning omfattar vanligtvis:
- Kontrollera att den lokala distributionen lyckades
- Anropa den lokala slutpunkten för slutsatsdragning
- Granska loggarna för utdata från anropsåtgärden
Kommentar
Lokala slutpunkter har följande begränsningar:
- De stöder inte trafikregler, autentisering eller avsökningsinställningar.
- De stöder bara en distribution per slutpunkt.
- De stöder lokala modellfiler och miljöer med endast lokal conda-fil. Om du vill testa registrerade modeller laddar du först ned dem med CLIeller SDK och använder
pathsedan i distributionsdefinitionen för att referera till den överordnade mappen. Om du vill testa registrerade miljöer kontrollerar du miljöns kontext i Azure Machine Learning-studio och förbereder en lokal conda-fil som ska användas.
Mer information om lokal felsökning finns i Distribuera och felsöka lokalt med hjälp av en lokal slutpunkt.
Lokal felsökning med lokal slutpunkt och Visual Studio Code (förhandsversion)
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Precis som med lokal felsökning måste du först ha Docker-motorn installerad och igång och sedan distribuera en modell till den lokala Docker-miljön. När du har en lokal distribution använder azure Machine Learning lokala slutpunkter Docker- och Visual Studio Code-utvecklingscontainrar (dev-containrar) för att skapa och konfigurera en lokal felsökningsmiljö. Med dev-containrar kan du dra nytta av Visual Studio Code-funktioner, till exempel interaktiv felsökning, inifrån en Docker-container.
Mer information om interaktiv felsökning av onlineslutpunkter i VS Code finns i Felsöka onlineslutpunkter lokalt i Visual Studio Code.
Felsökning med containerloggar
För en distribution kan du inte få direkt åtkomst till den virtuella dator där modellen distribueras. Du kan dock hämta loggar från vissa av containrarna som körs på den virtuella datorn. Det finns två typer av containrar som du kan hämta loggarna från:
- Slutsatsdragningsserver: Loggar inkluderar konsolloggen (från slutsatsdragningsservern) som innehåller utdata från utskrifts-/loggningsfunktioner från bedömningsskriptet (
score.pykod). - Lagringsinitierare: Loggar innehåller information om huruvida kod- och modelldata har laddats ned till containern. Containern körs innan inferensservercontainern börjar köras.
Mer information om felsökning med containerloggar finns i Hämta containerloggar.
Trafikroutning och spegling till onlinedistributioner
Kom ihåg att en enda onlineslutpunkt kan ha flera distributioner. När slutpunkten tar emot inkommande trafik (eller begäranden) kan den dirigera procentandelar av trafiken till varje distribution, enligt den ursprungliga blå/gröna distributionsstrategin. Den kan också spegla (eller kopiera) trafik från en distribution till en annan, även kallad trafikspegling eller skuggning.
Trafikroutning för blå/grön distribution
Blå/grön distribution är en distributionsstrategi som gör att du kan distribuera en ny distribution (den gröna distributionen) till en liten delmängd av användare eller begäranden innan du distribuerar den helt. Slutpunkten kan implementera belastningsutjämning för att allokera vissa procentandelar av trafiken till varje distribution, där den totala allokeringen för alla distributioner uppgår till upp till 100 %.
Dricks
En begäran kan kringgå den konfigurerade belastningsutjämningen genom att inkludera ett HTTP-huvud för azureml-model-deployment. Ange rubrikvärdet till namnet på den distribution som du vill att begäran ska dirigeras till.
Följande bild visar inställningar i Azure Machine Learning-studio för allokering av trafik mellan en blå och grön distribution.

Den här trafikallokeringen dirigerar trafik enligt följande bild, där 10 % av trafiken går till den gröna distributionen och 90 % av trafiken går till den blå distributionen.
Trafikspegling till onlinedistributioner
Slutpunkten kan också spegla (eller kopiera) trafik från en distribution till en annan distribution. Trafikspegling (kallas även skuggtestning) är användbart när du vill testa en ny distribution med produktionstrafik utan att påverka de resultat som kunderna får från befintliga distributioner. När du till exempel implementerar en blå/grön distribution där 100 % av trafiken dirigeras till blått och 10 % speglas i den gröna distributionen, returneras inte resultatet av den speglade trafiken till den gröna distributionen till klienterna, men måtten och loggarna registreras.

Information om hur du använder trafikspegling finns i Valv distribution för onlineslutpunkter.
Fler funktioner för onlineslutpunkter i Azure Machine Learning
Autentisering och kryptering
- Autentisering: Nyckel- och Azure Machine Learning-token
- Hanterad identitet: Användartilldelad och systemtilldelad
- SSL som standard för slutpunktsanrop
Automatisk skalning
Med autoskalning körs automatiskt rätt mängd resurser för att hantera arbetsbelastningen i appen. Hanterade slutpunkter stöder automatisk skalning genom integrering med autoskalningsfunktionen för Azure Monitor. Du kan konfigurera måttbaserad skalning (till exempel CPU-användning >70 %), schemabaserad skalning (till exempel skalningsregler för tider med hög belastning) eller en kombination.

Information om hur du konfigurerar autoskalning finns i Så här autoskalar du onlineslutpunkter.
Hanterad nätverksisolering
När du distribuerar en maskininlärningsmodell till en hanterad onlineslutpunkt kan du skydda kommunikationen med onlineslutpunkten med hjälp av privata slutpunkter.
Du kan konfigurera säkerhet för inkommande bedömningsbegäranden och utgående kommunikation med arbetsytan och andra tjänster separat. Inkommande kommunikation använder den privata slutpunkten för Azure Machine Learning-arbetsytan. Utgående kommunikation använder privata slutpunkter som skapats för arbetsytans hanterade virtuella nätverk.
Mer information finns i Nätverksisolering med hanterade onlineslutpunkter.
Övervaka onlineslutpunkter och distributioner
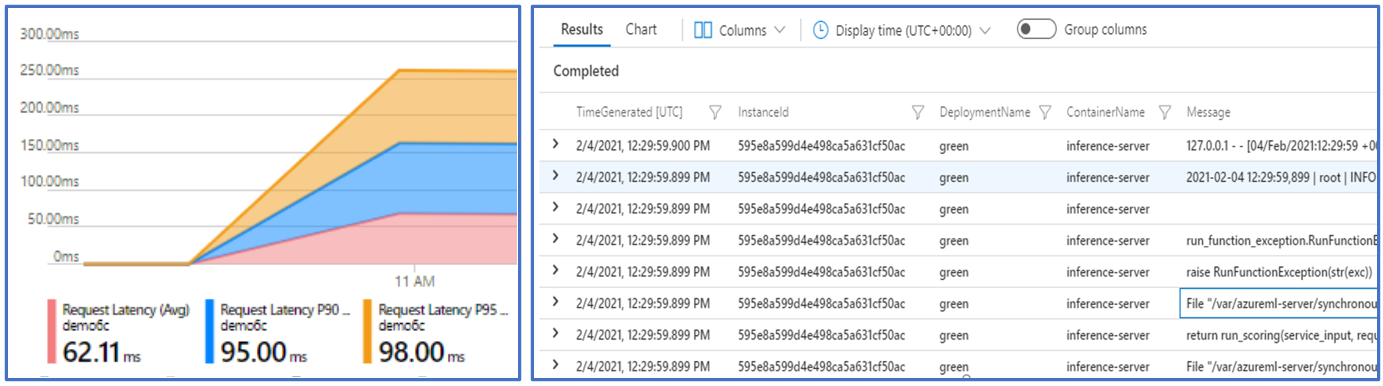
Övervakning för Azure Machine Learning-slutpunkter är möjligt via integrering med Azure Monitor. Med den här integreringen kan du visa mått i diagram, konfigurera aviseringar, fråga från loggtabeller, använda Application Insights för att analysera händelser från användarcontainrar och så vidare.
Mått: Använd Azure Monitor för att spåra olika slutpunktsmått, till exempel svarstid för begäranden och öka detaljnivån till distributions- eller statusnivå. Du kan också spåra mått på distributionsnivå, till exempel processor-/GPU-användning och öka detaljnivån till instansnivå. Med Azure Monitor kan du spåra dessa mått i diagram och konfigurera instrumentpaneler och aviseringar för ytterligare analys.
Loggar: Skicka mått till Log Analytics-arbetsytan där du kan köra frågor mot loggar med hjälp av Kusto-frågesyntaxen. Du kan också skicka mått till lagringskonto och/eller händelsehubbar för vidare bearbetning. Dessutom kan du använda dedikerade loggtabeller för onlineslutpunktsrelaterade händelser, trafik och containerloggar. Kusto-frågan tillåter komplex analys som ansluter till flera tabeller.
Application Insights: Utvalda miljöer omfattar integrering med Application Insights och du kan aktivera/inaktivera den när du skapar en onlinedistribution. Inbyggda mått och loggar skickas till Application Insights och du kan använda dess inbyggda funktioner som Live-mått, Transaktionssökning, Fel och Prestanda för ytterligare analys.
Mer information om övervakning finns i Övervaka onlineslutpunkter.
Hemlig inmatning i onlinedistributioner (förhandsversion)
Hemlig inmatning i samband med en onlinedistribution är en process för att hämta hemligheter (till exempel API-nycklar) från hemliga arkiv och mata in dem i din användarcontainer som körs i en onlinedistribution. Hemligheter kommer så småningom att vara tillgängliga via miljövariabler, vilket ger ett säkert sätt för dem att förbrukas av slutsatsdragningsservern som kör ditt bedömningsskript eller av den slutsatsdragningsstacken som du tar med med en BYOC-distributionsmetod (bring your own container).
Det finns två sätt att mata in hemligheter. Du kan mata in hemligheter själv, använda hanterade identiteter eller använda funktionen för hemlig inmatning. Mer information om hur du matar in hemligheter finns i Hemlig injektion i onlineslutpunkter (förhandsversion).
Nästa steg
- Så här distribuerar du onlineslutpunkter med Azure CLI och Python SDK
- Så här distribuerar du batchslutpunkter med Azure CLI och Python SDK
- Använda nätverksisolering med hanterade onlineslutpunkter
- Distribuera modeller med REST
- Övervaka hanterade onlineslutpunkter
- Så här visar du hanterade onlineslutpunktskostnader
- Hantera och öka kvoter för resurser med Azure Machine Learning