Flytta stordatorberäkning till Azure
Stordatorer har ett rykte för hög tillförlitlighet och tillgänglighet och fortsätter att vara den betrodda ryggraden i många företag. De tros ofta ha nästan obegränsad skalbarhet och databehandlingskraft också. Vissa företag har dock vuxit ur kapaciteten för de största tillgängliga stordatorerna. Om det här låter som du erbjuder Azure flexibilitet, räckvidd och infrastrukturbesparingar.
Om du vill köra stordatorarbetsbelastningar i Microsoft Azure behöver du veta hur stordatorns beräkningsfunktioner står sig i jämförelse med Azure. Den här artikeln baseras på en IBM z14-stordator (den senaste modellen i den här skriften) och beskriver hur du får jämförbara resultat i Azure.
Kom igång genom att tänka på miljöerna sida vid sida. Följande bild jämför en stordatormiljö för att köra program med en Azure-värdmiljö.
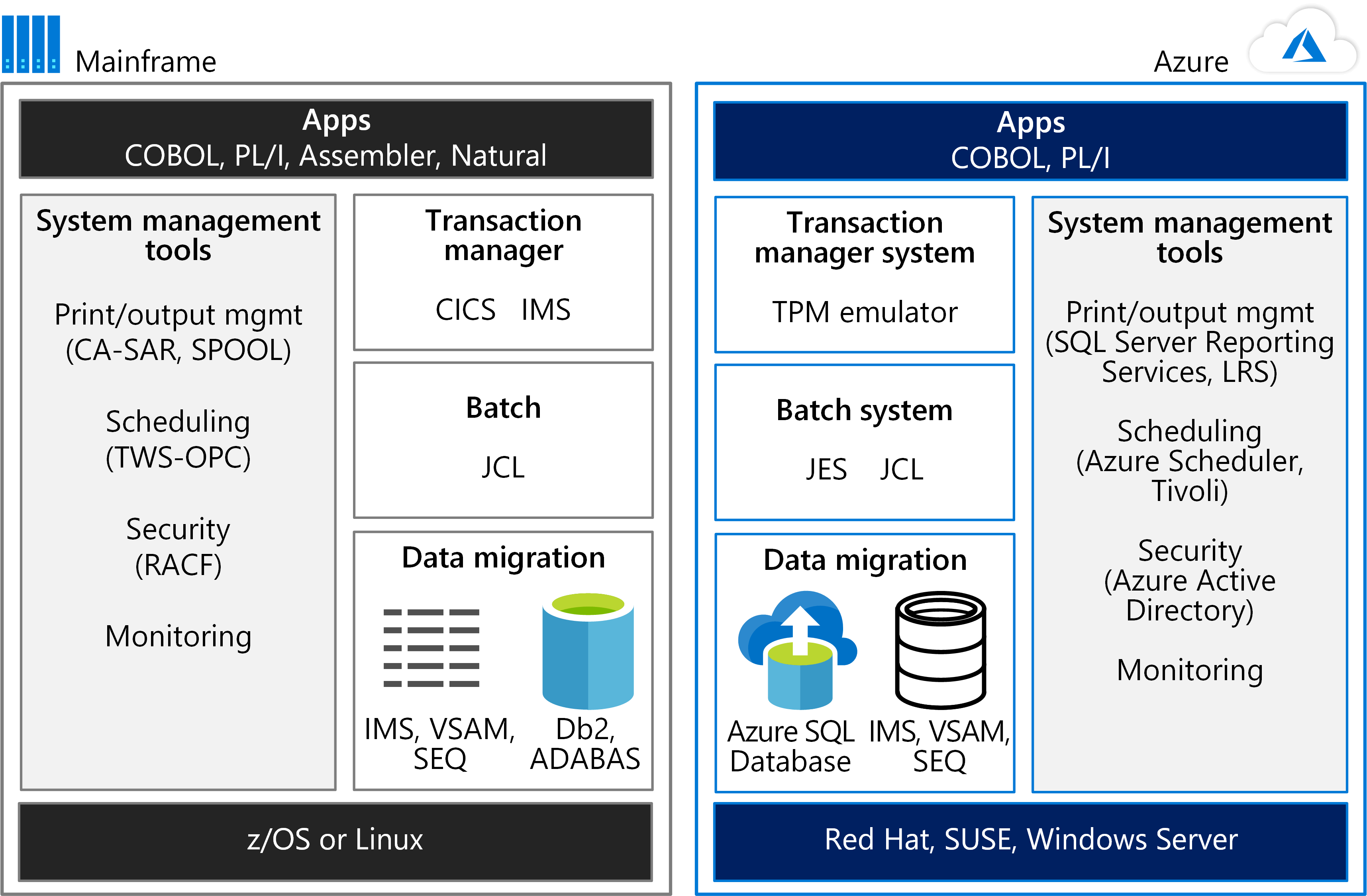
Kraften i stordatorer används ofta för OLTP-system (Online Transaction Processing) som hanterar miljontals uppdateringar för tusentals användare. Dessa program använder ofta programvara för transaktionsbearbetning, skärmhantering och formulärinmatning. De kan använda ett kundinformationskontrollsystem (CICS), informationshanteringssystem (IMS) eller ett paket för transaktionsgränssnitt (TIP).
Som bilden visar kan en TPM-emulator i Azure hantera CICS- och IMS-arbetsbelastningar. En batchsystememulator i Azure utför rollen som Jobbkontrollspråk (JCL). Stordatordata migreras till Azure-databaser, till exempel Azure SQL Database. Azure-tjänster eller annan programvara som finns i Azure Virtual Machines kan användas för systemhantering.
I z14-stordatorn ordnas processorer i upp till fyra lådor. En låda är helt enkelt ett kluster av processorer och kretsuppsättningar. Varje låda kan ha sex cp-chips (active central processor) och varje CP har 10 SC-chips (systemstyrenhet). I Intel x86-terminologi finns det sex socketar per låda, 10 kärnor per socket och fyra lådor. Den här arkitekturen ger den grova motsvarigheten till 24 sockets och 240 kärnor, maximalt, för en z14.
Den snabba z14 CP har en 5,2 GHz klockhastighet. Vanligtvis levereras en z14 med alla CD-adresser i rutan. De aktiveras efter behov. En kund debiteras ofta för minst fyra timmars beräkningstid per månad trots faktisk användning.
En stordatorprocessor kan konfigureras som en av följande typer:
- Gp-processor (General Purpose)
- System z Integrerad informationsprocessor (zIIP)
- IFL-processor (Integrated Facility for Linux)
- System Assist Processor (SAP)
- ICF-processor (Integrated Coupling Facility)
IBM-stordatorer erbjuder möjligheten att skala upp till 240 kärnor (den aktuella z14-storleken för ett enda system). Dessutom kan IBM-stordatorer skala ut via en funktion som kallas kopplingsfaciliteten (CF). MED CF kan flera stordatorsystem komma åt samma data samtidigt. Med hjälp av CF grupperar stordatorns Parallell Sysplex-teknik stordatorprocessorer i kluster. När den här guiden skrevs stöds 32 grupper med 64 processorer vardera av funktionen Parallel Sysplex. Upp till 2 048 processorer kan grupperas på det här sättet för att skala ut beräkningskapaciteten.
Med en CF kan beräkningskluster dela data med direkt åtkomst. Den används för att låsa information, cacheinformation och listan över delade dataresurser. En parallell sysplex med en eller flera CF:er kan betraktas som ett utskalningskluster för "delat allt". Mer information om dessa funktioner finns i Parallel Sysplex på IBM Z på IBM:s webbplats.
Program kan använda dessa funktioner för att ge både utskalningsprestanda och hög tillgänglighet. Information om hur CICS kan använda Parallel Sysplex med CF finns i IBM CICS och kopplingsanläggningen: Beyond the Basics redbook.
Vissa människor tror felaktigt att Intel-baserade servrar inte är lika kraftfulla som stordatorer. Men de nya kärntäta, Intel-baserade systemen har lika mycket beräkningskapacitet som stordatorer. I det här avsnittet beskrivs IaaS-alternativen (Infrastruktur som en tjänst) i Azure för databehandling och lagring. Azure tillhandahåller även paaS-alternativ (plattform som en tjänst), men den här artikeln fokuserar på de IaaS-val som ger jämförbar stordatorkapacitet.
Azure Virtual Machines ger beräkningskraft i olika storlekar och typer. I Azure motsvarar en virtuell processor (vCPU) ungefär en kärna i en stordator.
För närvarande tillhandahåller intervallet med storlekar för virtuella Azure-datorer mellan 1 och 128 vCPU:er. Typer av virtuella datorer är optimerade för vissa arbetsbelastningar. I följande lista visas till exempel vm-typerna (aktuella i den här skriften) och deras rekommenderade användning:
| Storlek | Typ och beskrivning |
|---|---|
| D-serien | Generell användning med 64 vCPU och upp till 3,5 GHz klockhastighet |
| E-serien | Minnesoptimerad med upp till 64 vCPU:er |
| F-serien | Beräkningsoptimerad med upp till 64 vCPU:er och 3,7 GHz klockhastighet |
| H-serien | Optimerad för HPC-program (databehandling med höga prestanda) |
| L-serien | Lagring som är optimerad för program med högt dataflöde som backas upp av databaser som NoSQL |
| M-serien | Största beräknings- och minnesoptimerade virtuella datorer med upp till 128 vCPU:er |
Mer information om tillgängliga virtuella datorer finns i Virtual Machine-serien.
En z14-stordator kan ha upp till 240 kärnor. Z14-stordatorer använder dock nästan aldrig alla kärnor för ett enda program eller en enda arbetsbelastning. I stället separerar en stordator arbetsbelastningar i logiska partitioner (LPAR) och LPAR:erna har klassificeringar – MIPS (miljontals instruktioner per sekund) eller MSU (Million Service Unit). När du fastställer den jämförbara VM-storlek som krävs för att köra en stordators arbetsbelastning i Azure ska du ta hänsyn till MIPS-klassificeringen (eller MSU).
Följande är allmänna uppskattningar:
150 MIPS per vCPU
1 000 MIPS per processor
Om du vill fastställa rätt VM-storlek för en viss arbetsbelastning i en LPAR ska du först optimera den virtuella datorn för arbetsbelastningen. Bestäm sedan antalet vCPU:er som behövs. En konservativ uppskattning är 150 MIPS per vCPU. Baserat på den här uppskattningen kan till exempel en virtuell dator i F-serien med 16 vCPU:er enkelt stödja en IBM Db2-arbetsbelastning som kommer från en LPAR med 2 400 MIPS.
De virtuella datorerna i M-serien kan skala upp till 128 vCPU:er (när den här artikeln skrevs). Med den konservativa uppskattningen på 150 MIPS per vCPU motsvarar den virtuella datorn i M-serien cirka 19 000 MIPS. Den allmänna regeln för att uppskatta MIPS för en stordator är 1 000 MIPS per processor. En z14-stordator kan ha upp till 24 processorer och tillhandahålla cirka 24 000 MIPS för ett enda stordatorsystem.
Den största enskilda z14-stordatorn har cirka 5 000 MIPS mer än den största virtuella datorn som är tillgänglig i Azure. Ändå är det viktigt att jämföra hur arbetsbelastningar distribueras. Om ett stordatorsystem har både ett program och en relationsdatabas distribueras de vanligtvis på samma fysiska stordator – var och en i sin egen LPAR. Samma lösning i Azure distribueras ofta med hjälp av en virtuell dator för programmet och en separat virtuell dator i lämplig storlek för databasen.
Om till exempel ett M64 vCPU-system stöder programmet och en M96 vCPU används för databasen behövs cirka 150 vCPU:er , eller cirka 24 000 MIPS som följande bild visar.
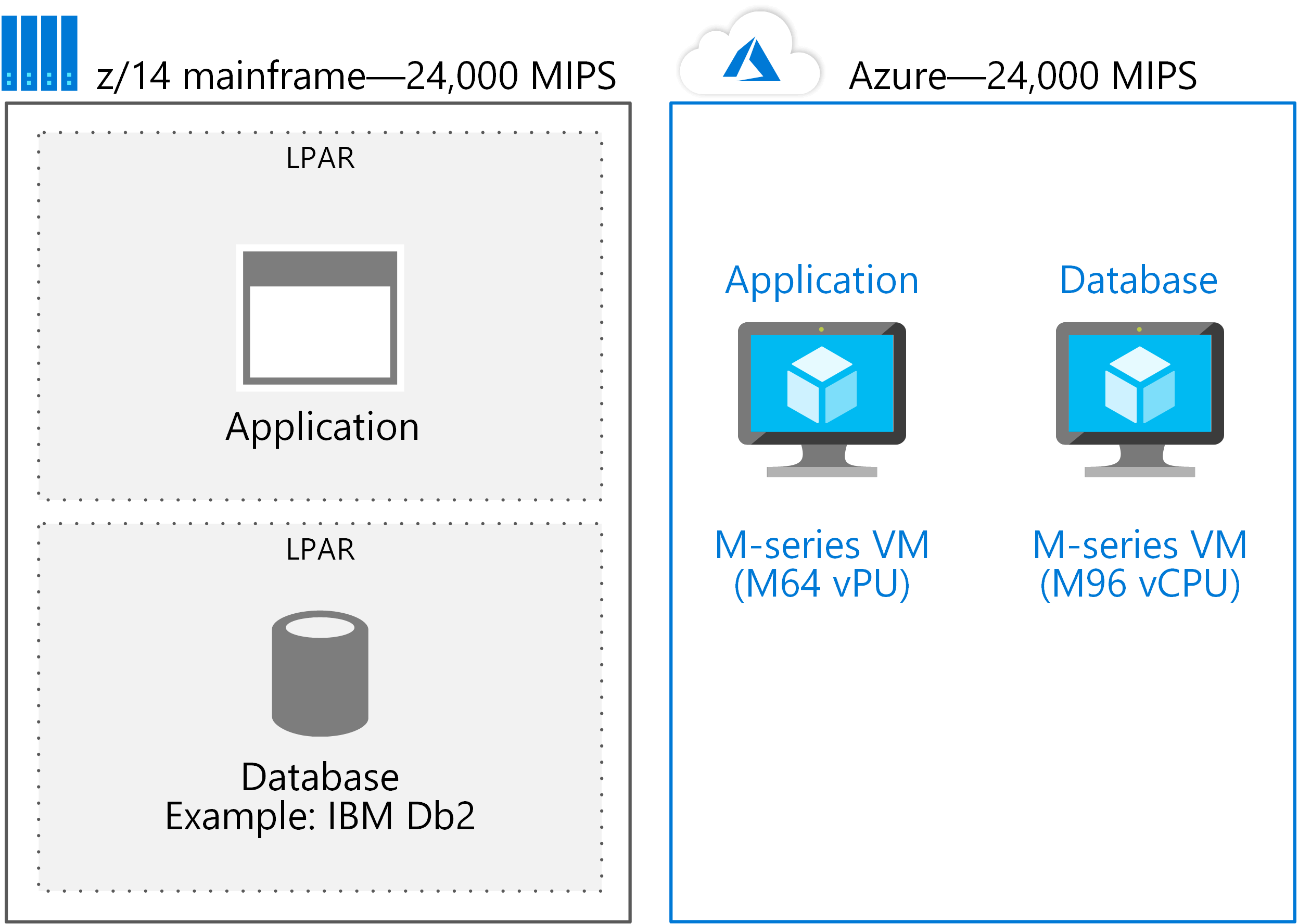
Metoden är att migrera LPAR till enskilda virtuella datorer. Sedan skalar Azure enkelt upp till den storlek som behövs för de flesta program som distribueras i ett enda stordatorsystem.
En av fördelarna med en Azure-baserad lösning är möjligheten att skala ut. Skalning gör nästan obegränsad beräkningskapacitet tillgänglig för ett program. Azure har stöd för flera metoder för att skala ut beräkningskraft:
Belastningsutjämning i ett kluster. I det här scenariot kan ett program använda en lastbalanserare eller resurshanterare för att sprida ut arbetsbelastningen mellan flera virtuella datorer i ett kluster. Om det behövs mer beräkningskapacitet läggs ytterligare virtuella datorer till i klustret.
Vm-skalningsuppsättningar. I det här burst-scenariot kan ett program skalas till ytterligare beräkningsresurser baserat på VM-användning. När efterfrågan minskar kan antalet virtuella datorer i en skalningsuppsättning också minska, vilket säkerställer effektiv användning av beräkningskraft.
PaaS-skalning. Azure PaaS erbjuder skalningsberäkningsresurser. Azure Service Fabric allokerar till exempel beräkningsresurser för att möta ökningar av antalet begäranden.
Kubernetes-kluster. Program i Azure kan använda Kubernetes-kluster för beräkningstjänster för angivna resurser. Azure Kubernetes Service (AKS) är en hanterad tjänst som samordnar Kubernetes-noder, pooler och kluster i Azure.
Om du vill välja rätt metod för att skala ut beräkningsresurser är det viktigt att förstå hur Azure och stordatorer skiljer sig åt. Nyckeln är hur – eller om – data delas av beräkningsresurser. I Azure delas data (som standard) vanligtvis inte av flera virtuella datorer. Om datadelning krävs av flera virtuella datorer i ett skalbar beräkningskluster måste delade data finnas i en resurs som stöder den här funktionen. I Azure omfattar datadelning lagring som beskrivs i följande avsnitt.
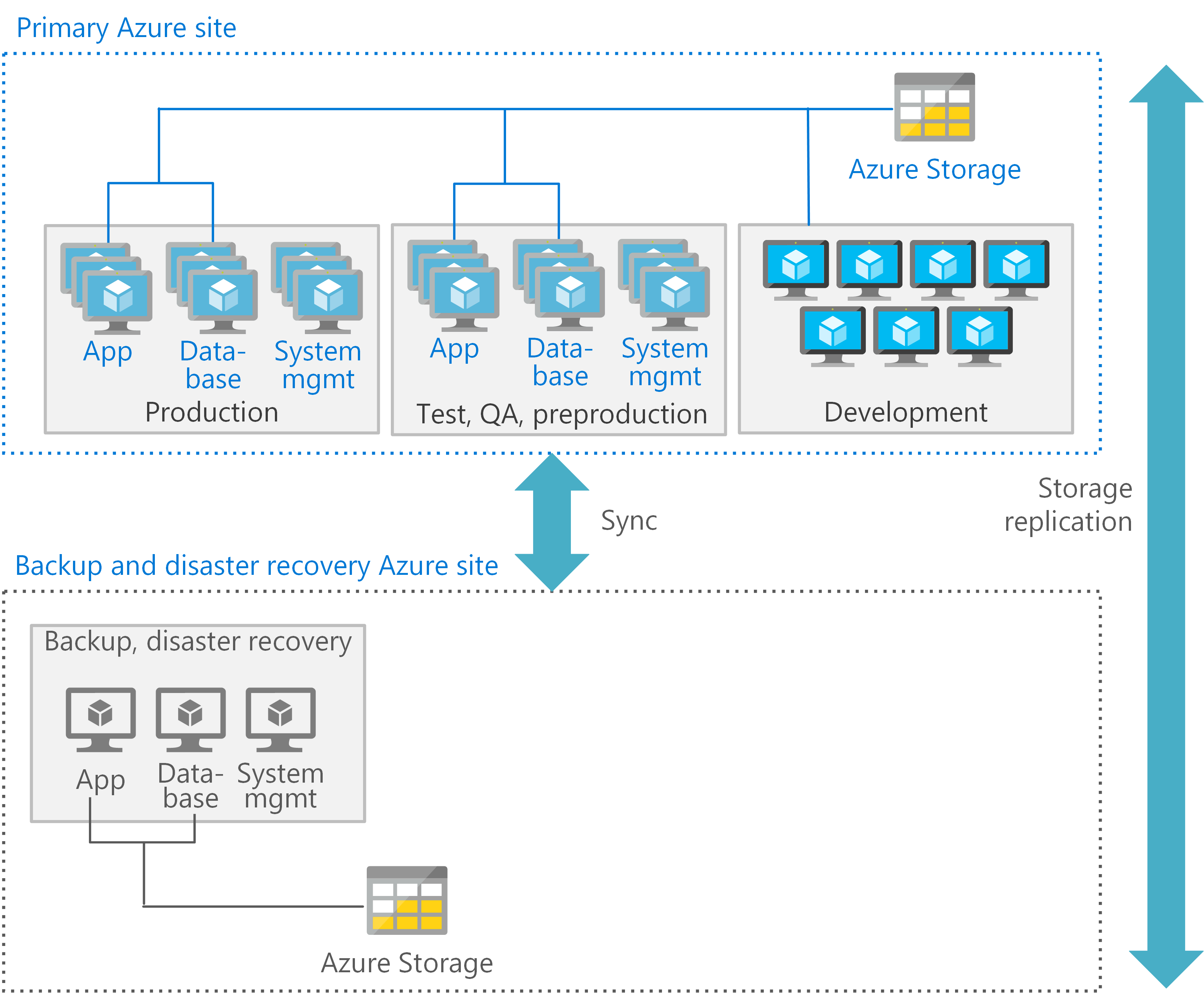
Du kan optimera varje bearbetningsnivå i en Azure-arkitektur. Använd den lämpligaste typen av virtuella datorer och funktioner för varje miljö. Följande bild visar ett potentiellt mönster för att distribuera virtuella datorer i Azure för att stödja ett CICS-program som använder Db2. På den primära platsen distribueras de virtuella datorerna för produktion, förproduktion och testning med hög tillgänglighet. Den sekundära platsen är avsedd för säkerhetskopiering och haveriberedskap.
Varje nivå kan också tillhandahålla lämpliga haveriberedskapstjänster. Till exempel kan virtuella datorer för produktion och databas kräva en varm eller varm återställning, medan de virtuella datorerna för utveckling och testning stöder en kall återställning.
- Stordatormigrering
- Omvärdning av stordator på virtuella Azure-datorer
- Flytta stordatorlagring till Azure