Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,253 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERA%3C/text%3E%3C/svg%3E)
We have one large CSV file that we are looking to transfer in to Parquet and based on the recommended standard of up to 1GB parquet files, splitting across a few files however running in to a few issues
So how do we stop it generating a subfolder based on the source file name? It seems pretty restrictive and illogical to force an unwanted subfolder (a MS trait that hasn't stopped through the years!)

Hi @Ryan Abbey ,
Thank you for posting query on Microsoft Q&A platform.
Could you please help on below details. So that we can repro scenario to help you better with detailed implementation.
If we don't specify a file within the parquet definition and specify e.g. 10,000,000 rows per file, what we find is the copy activity is autogenerating a subfolder based on the input file name which we don't want.
Could you please share screenshot of your parquet dataset here along with parameter details if any declared in dataset.
If we extend 1 to specify a "File name prefix", we get error FileNamePrefixNotSupportFileBasedSource (I note the info box does say you can't specify a prefix with file based sources)
Could you please share screenshot this dataset configuration
It would be great help if we get above details to solve your issue. Thank you
Hi @Ryan Abbey ,
Could you please share details on above commented clarifications. This will help to understand issue better and provide detailed resolution
Apologies, forgot all about the questions as we moved on...
Hopefully the images actually show...


Hi @Ryan Abbey ,
Thank you for reframing your ask. Small clarifications here,
Kindly share details on above clarifications, that helps to provide detailed resolution. Thank you
Hi @Ryan Abbey ,
Just checking is below provided answer helps you? If yes please Accept Answer. Accepting answer will help community. Thank you
Hi @Ryan Abbey ,
Following up to check is below provided answer helps you? If yes please Accept Answer. Accepting answer will help community. Thank you.
Hi @Ryan Abbey ,
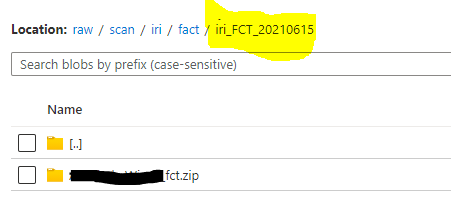
Please check detailed example, Which Copies file to folder(folder name will be dynamically created as you requested above(iri_FCT_yyyyMMdd))
Step1: Create a variable in your pipeline to hold current date. Use set variable activity to set value in it.
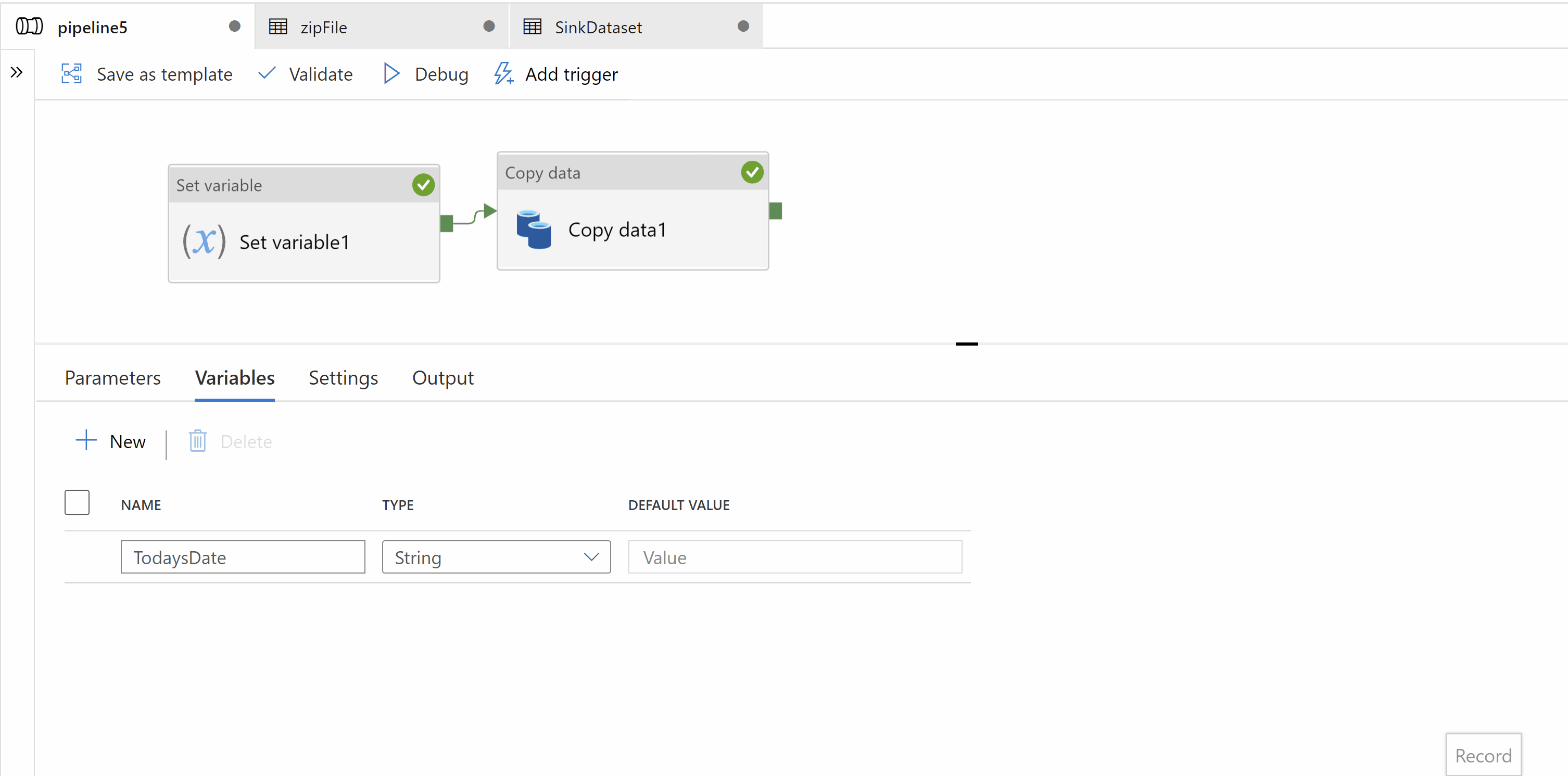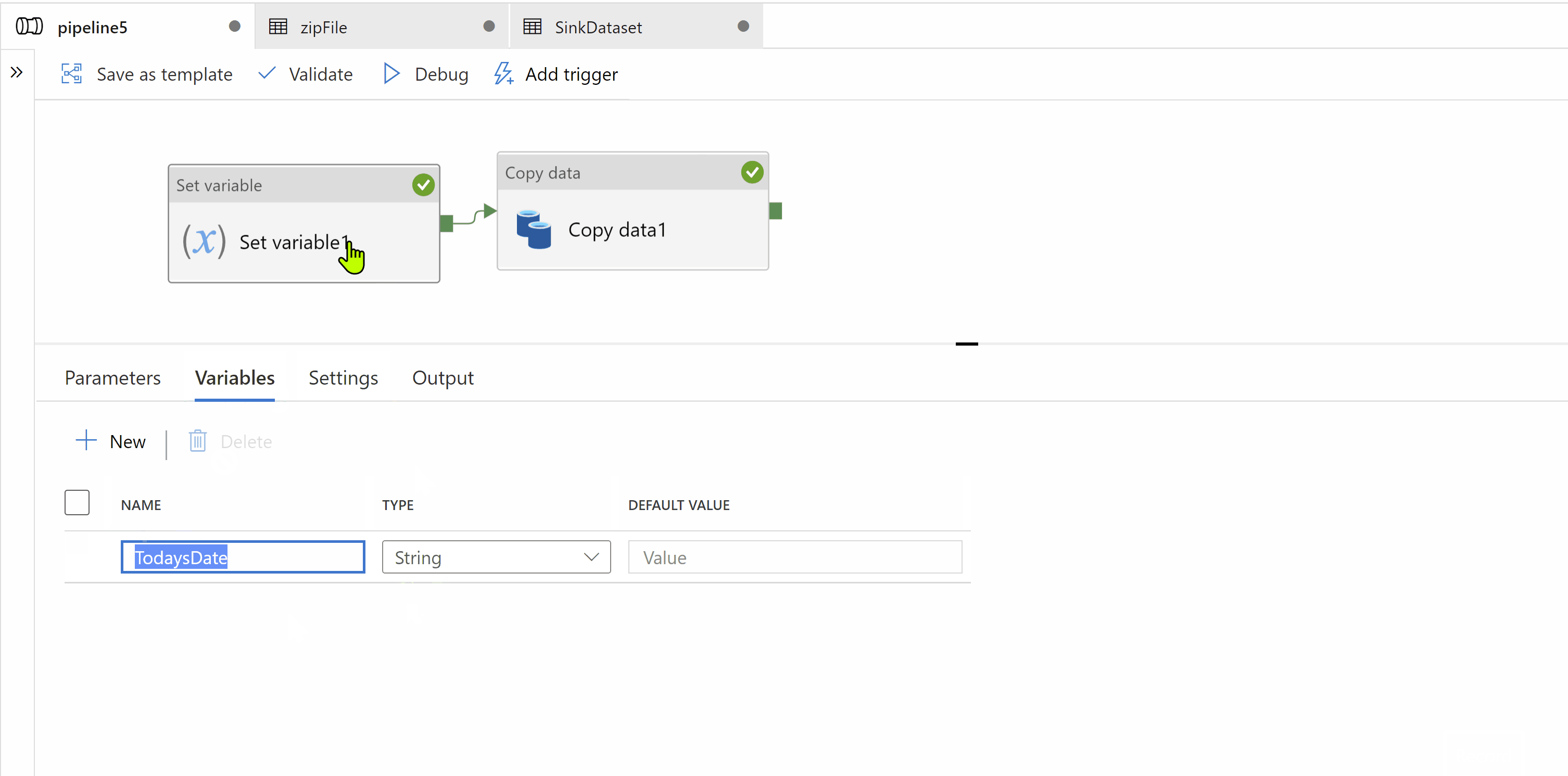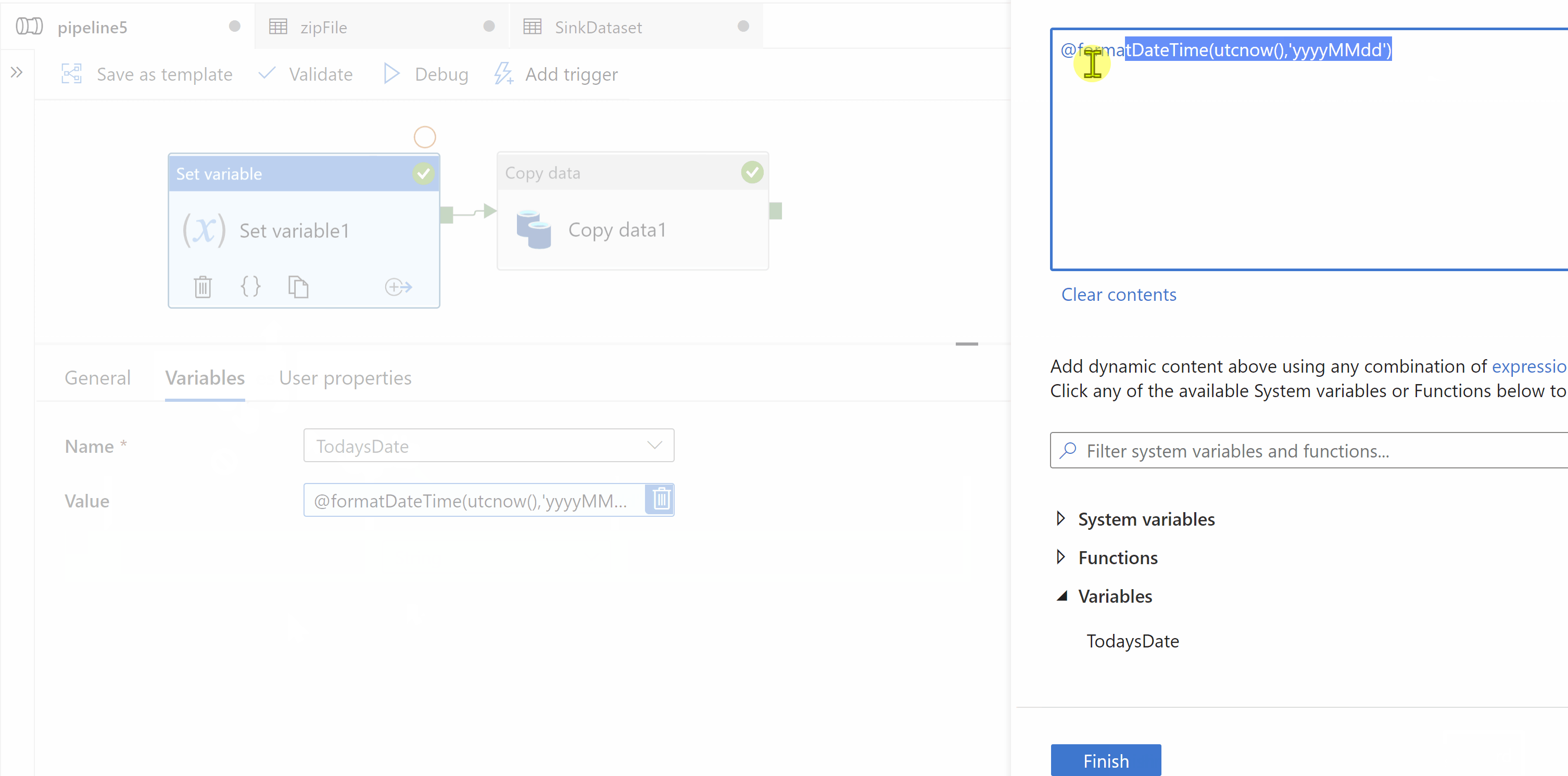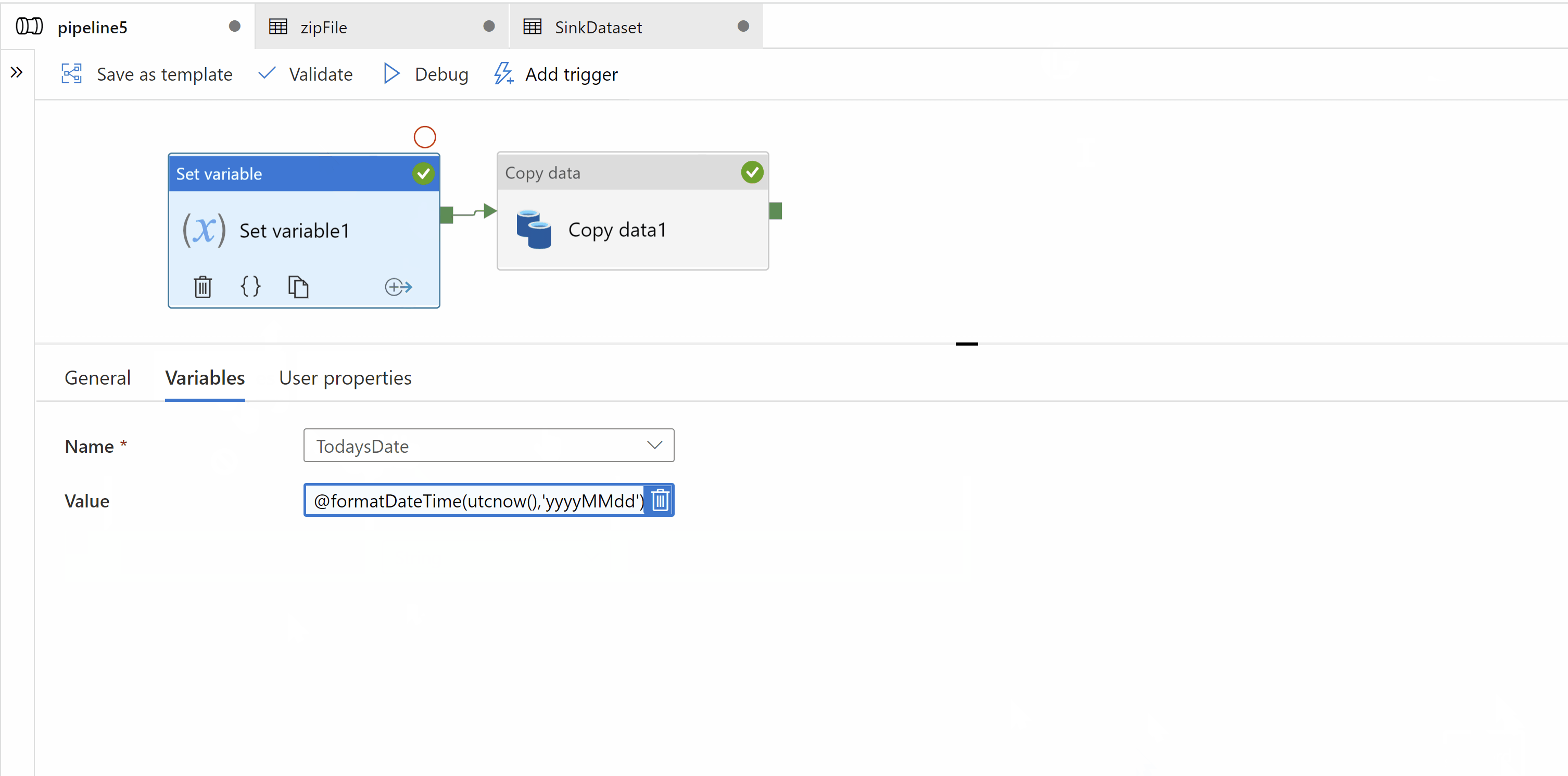
Step2: Use Copy activity to copy zip file. Source and Sink dataset types should be binary. In sink data set we should create a parameter which will dynamically give us target folder name as "iri_FCT_yyyyMMdd"
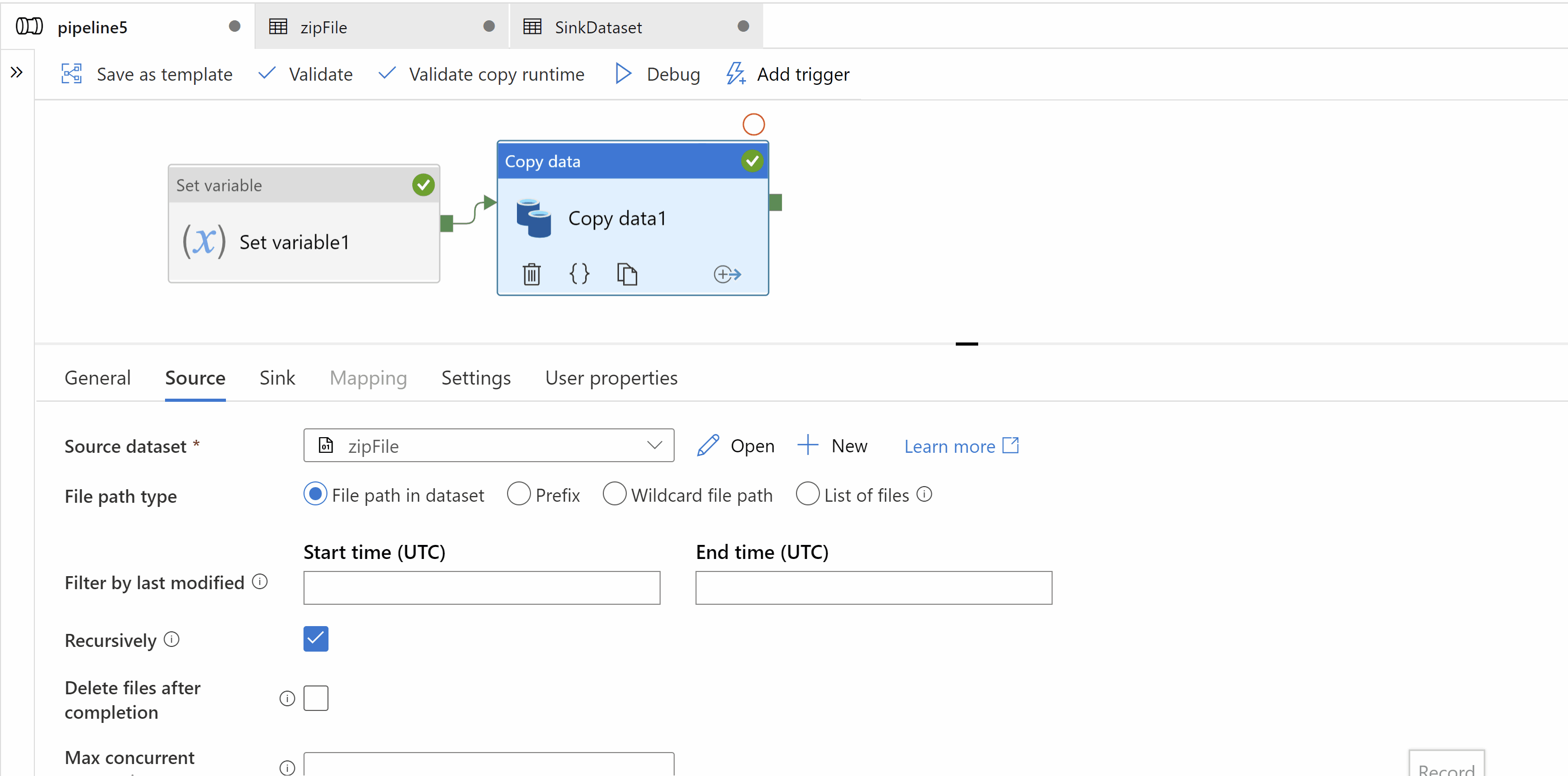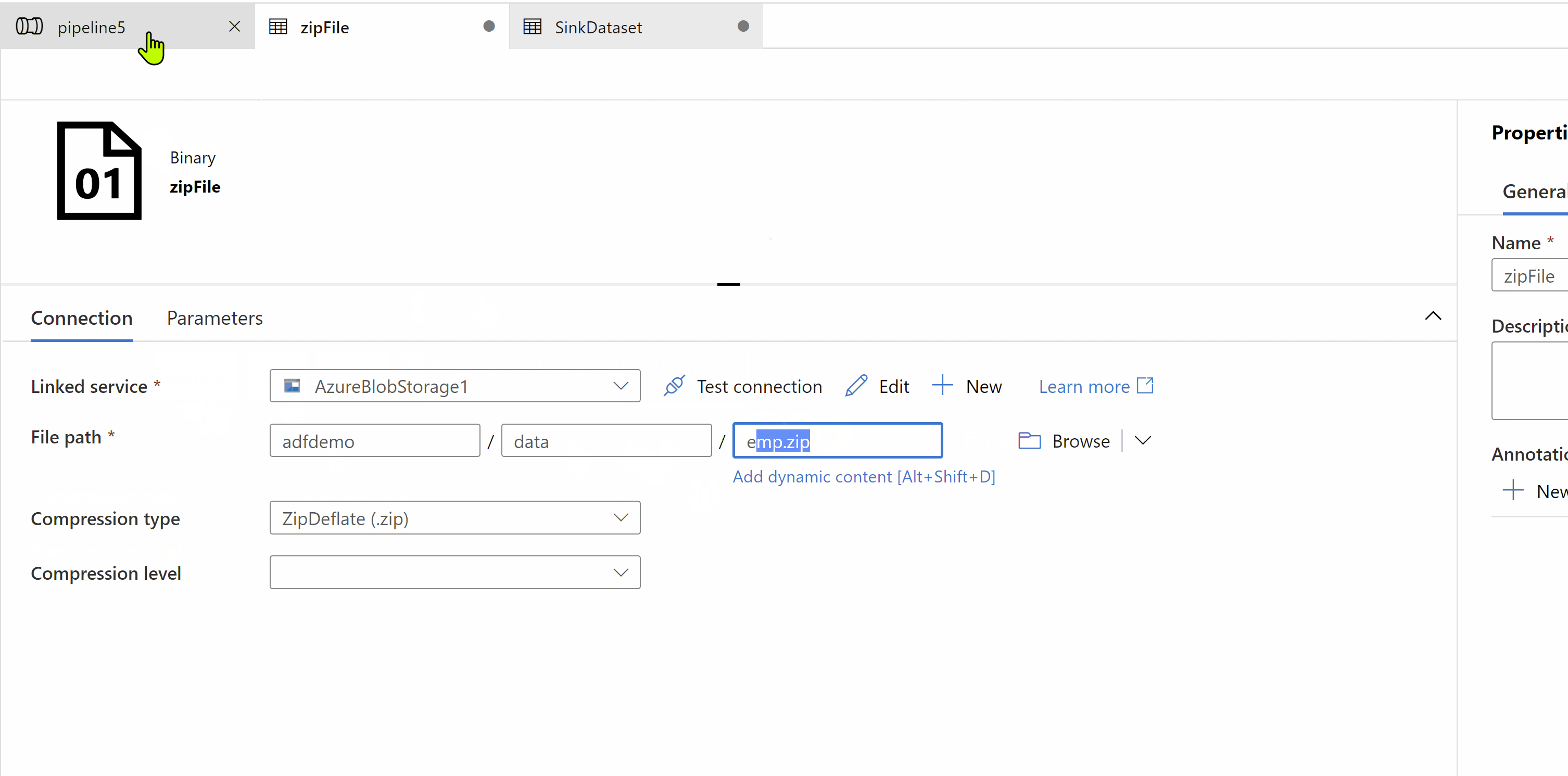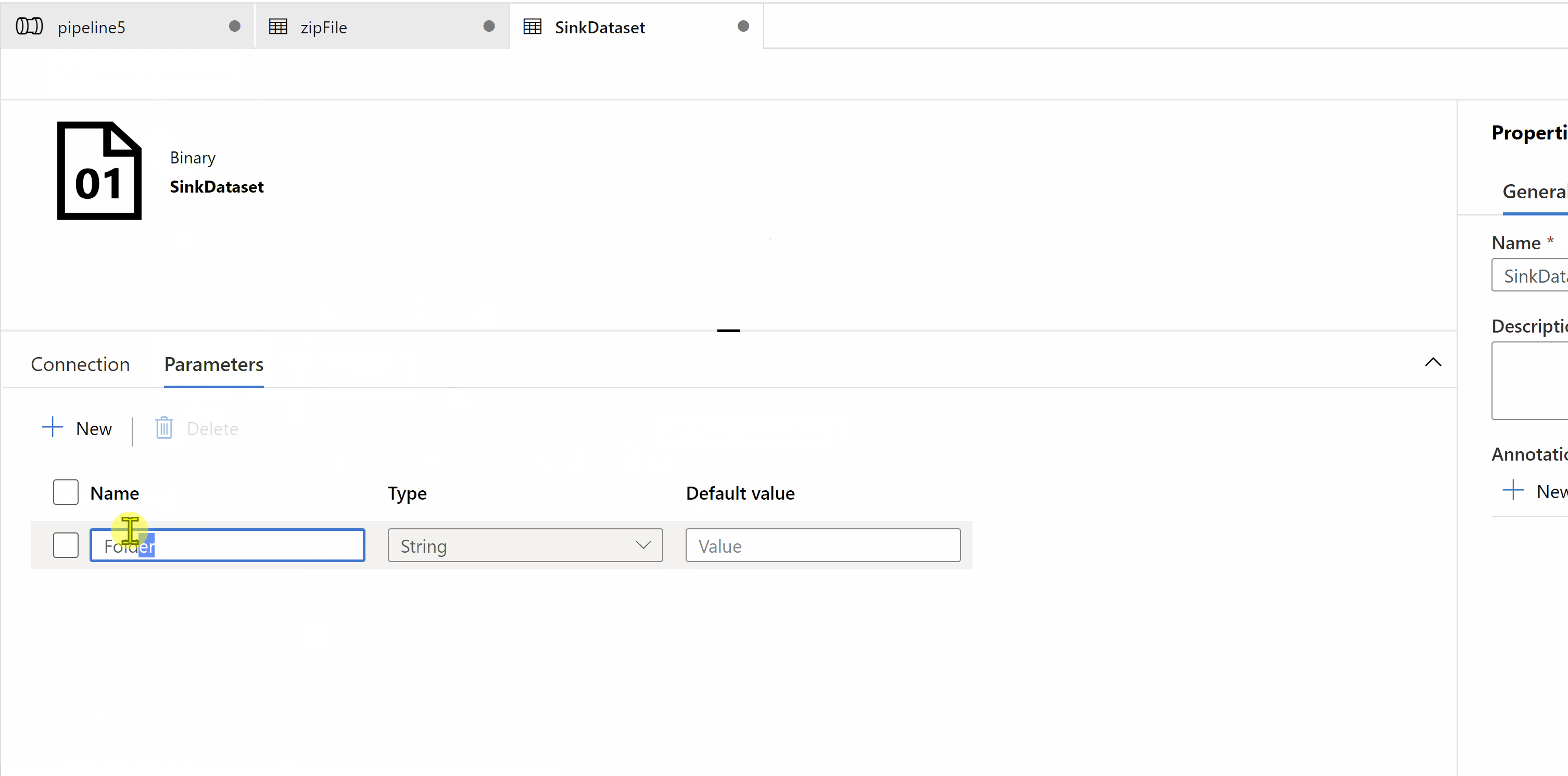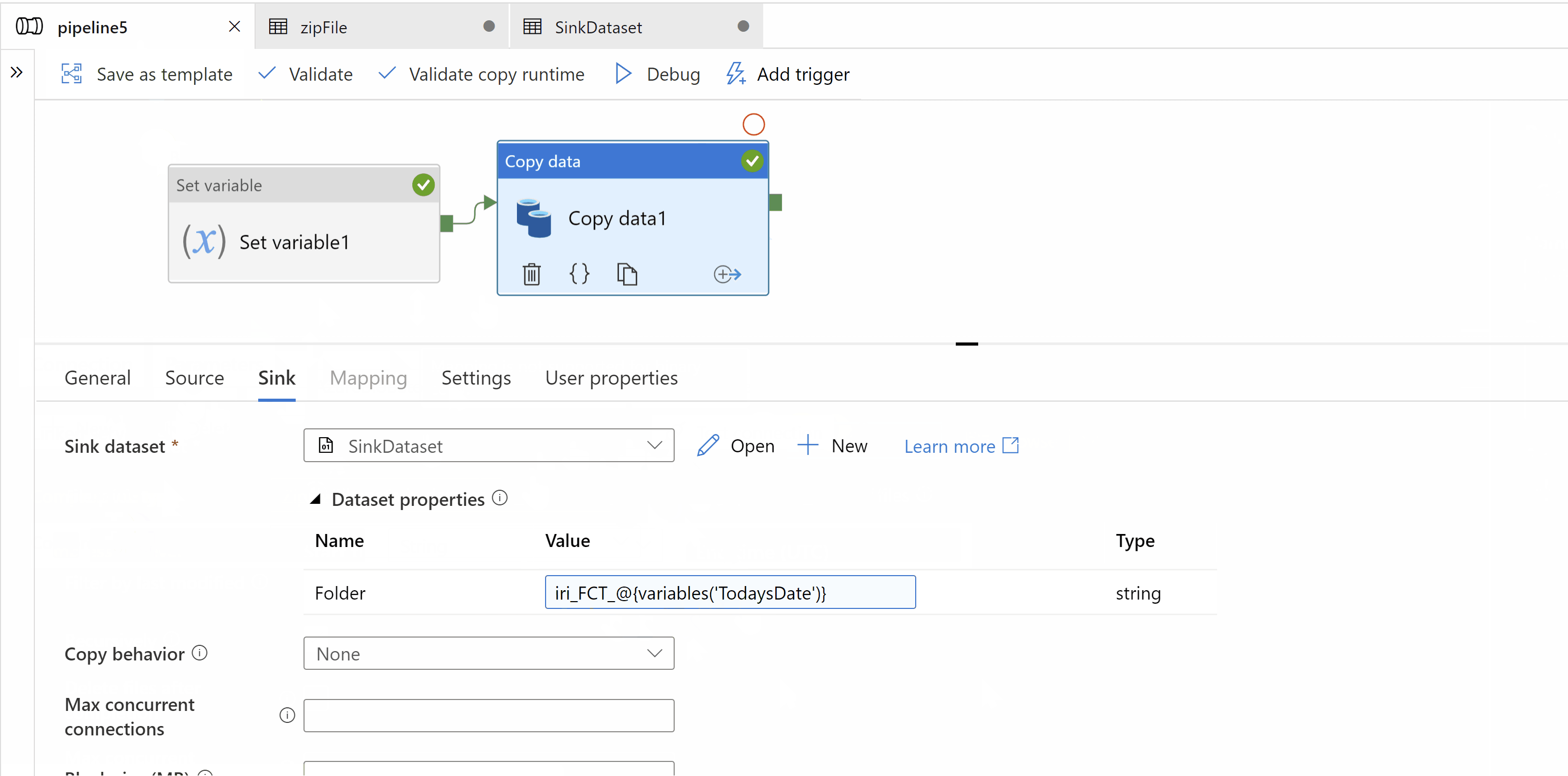
Hop this will help.
----------------------------------
accept an answer if correct. Original posters help the community find answers faster by identifying the correct answer. Here is how.
That would copy the zip file to a directory of same name? We are trying to convert to parquet and split in to multiple files at the same time
Hi @Ryan Abbey ,
You can convert single csv file to multiple parquet files using dataflows.
In data flows Sink Transformation you can use partitions to partition your data and save as separate files.
To know more about partitions in data flow, please check below link,
https://learn.microsoft.com/en-us/azure/data-factory/concepts-data-flow-performance#optimize-tab
In below example I am partitioning file in to 2 partitions.
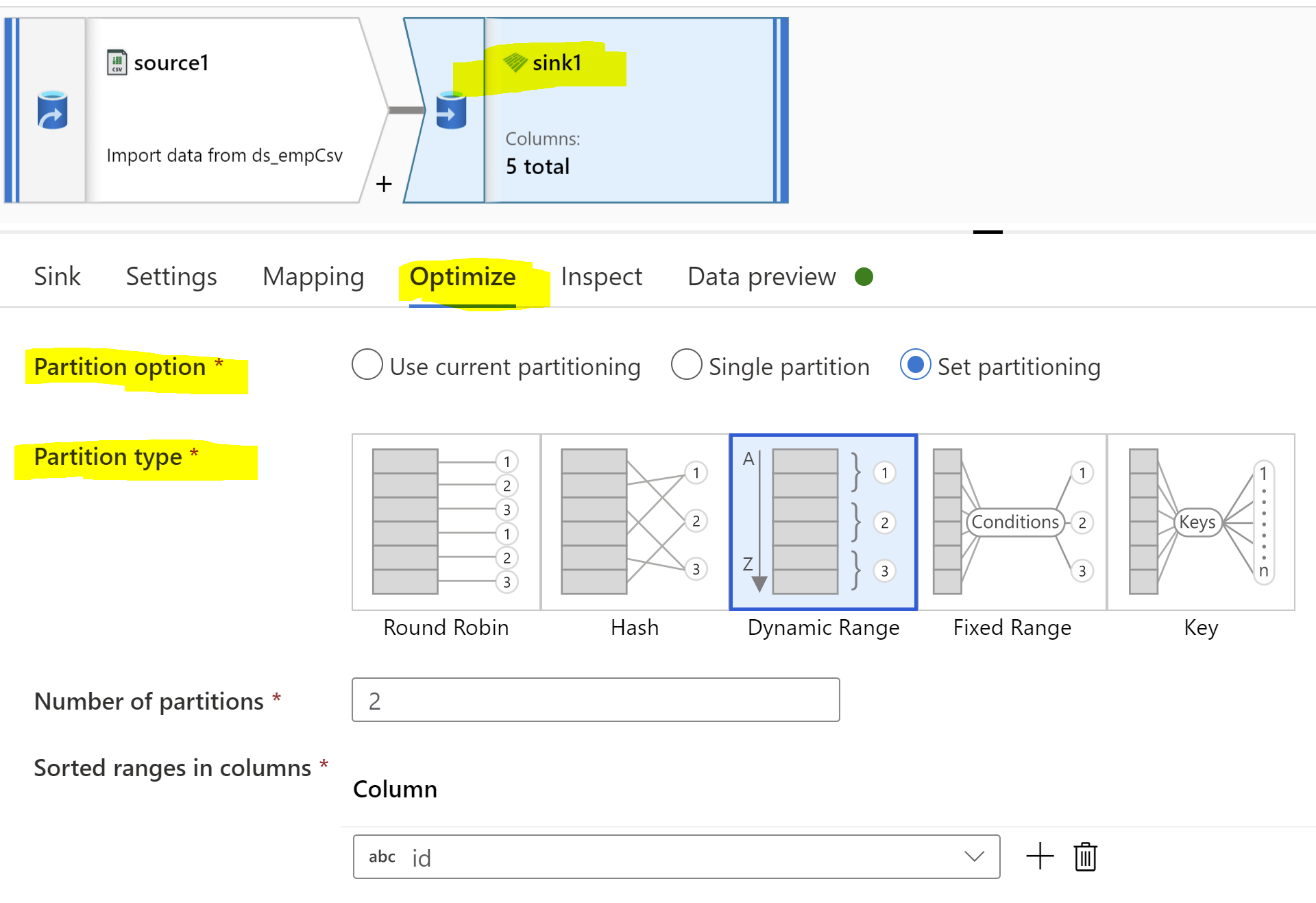
Hope this helps.
------------------------------------------
Please Accept Answer if this helps. Thank you.
Hi @Ryan Abbey ,
Just checking is below provided answer helps you? If yes please Accept Answer. Accepting answer will help community. Thank you
You go to a lot of effort, which is appreciated! However, using data mapping is known about and not sought... really, because the process is clearly capable of splitting files as well as creating folders, it should not be so difficult to split files and put them to where the user requires them... since it currently isn't capable, maybe a feature request... (can't remember if I did that or not)
Hi @Ryan Abbey ,
Thank you.
At this moment you can achieve your requirement of splitting files using dataflows only. Copy activity not supports this requirement.
Please feel free to share your feed back in below link. Azure data factory Product team closely monitor feedbacks there and consider them for future releases. Thank you.
https://feedback.azure.com/forums/270578-data-factory
Please Accept Answer. Accepting answer will help community too.