Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,545 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
I have a Synapse data flow that takes files from an Inline Common Data Model source and parses them to parquet format.
The CDM does a great job at flattening json files AND pointing to the data in csv format to populate the parquet file with. WHEN THE DATA EXIST.
My ADLS container has a list of json files
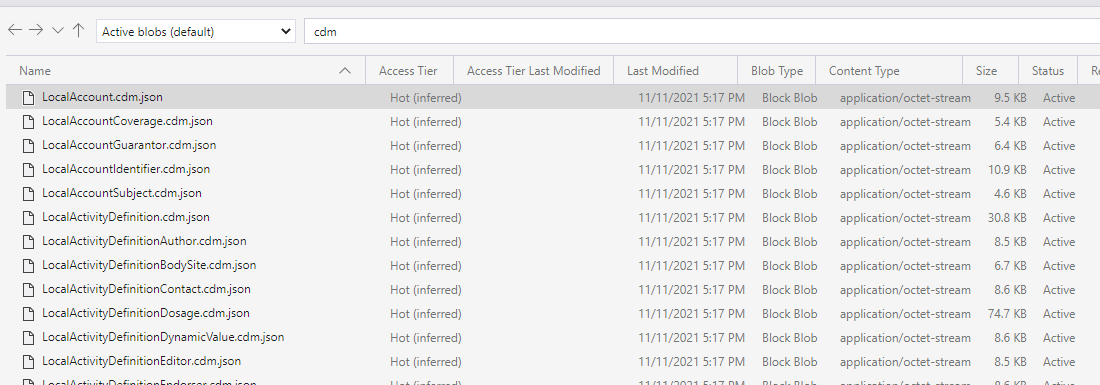
which are schema definitions.
In a "folder" called 'data' in the same root container as the json files there are "subfolders" named after the json files.
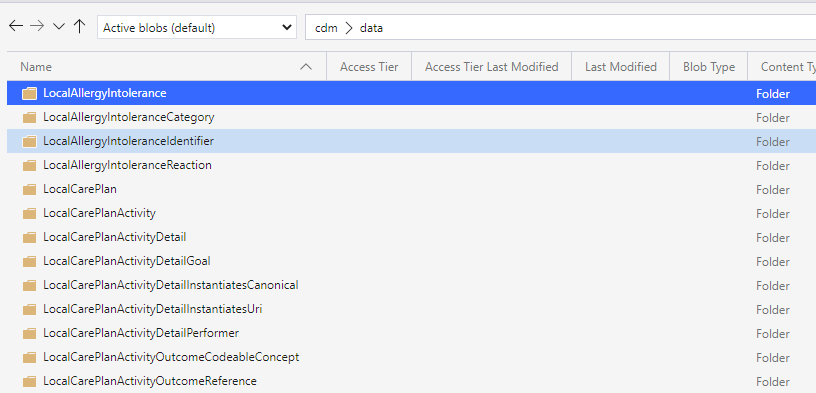
In these subfolders are the correlating data in csv format.

The process takes these data points and creates the parquet files as expected, in another container named 'parquet'.

The problem is the process works fine over the subfolders that DO have data. There are also elements that DO NOT have data, but do still have schema. The pipeline creates the parquet folders, but, b/c there are no data to put in them and the folders wind up being empty on ADLS, they are immediately deleted.
What I want to happen is for at least 1 default row of data to populate for each file regardless if there is data or not so they are not deleted by ADLS.
So my first attempt was to add a Derived Column transformation with a column named 'column1' and a static value of 'test'. My hope was that even if the other columns are null (and they are) it will still create the parquet file with only 1 row of data with all columns null except for 'column1' which has a value of 'test'. This is b/c the parquet files will later have data (they just don't right now). And I need the structure to be there in parquet b/c in the future these parquet files will be used for data analysis downstream.

But this attempt did not work. The static data seems not to persist, as evidenced by the fact the file still gets deleted as empty.
So, how do I get these parquet files to persist even with just 1 row of mock data?
@HimanshuSinha-msft thanks for your reply but I'm afraid you've misunderstood the issue.
The Common Data Model portion is critical to this issue. It uses a manifest file that contains metadata like pointers to data, schema definitions, etc. When my process runs it is correctly seeing this manifest file. It is correctly creating the parquet files, but only when the manifest file points to data. If it doesn't (meaning it only has metadata for the schema definition) it creates the parquet file, but then it is immediately deleted b/c it is empty (structure only, no data).
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @TerriblyVexed ,
Thanks for the ask and using Microsoft Q&A platform .
As I understand your ask to add a row in the sink side ( is this case its a paraquet file ) . I do not have a CDM setup but then I am using CSV to implement this logic .
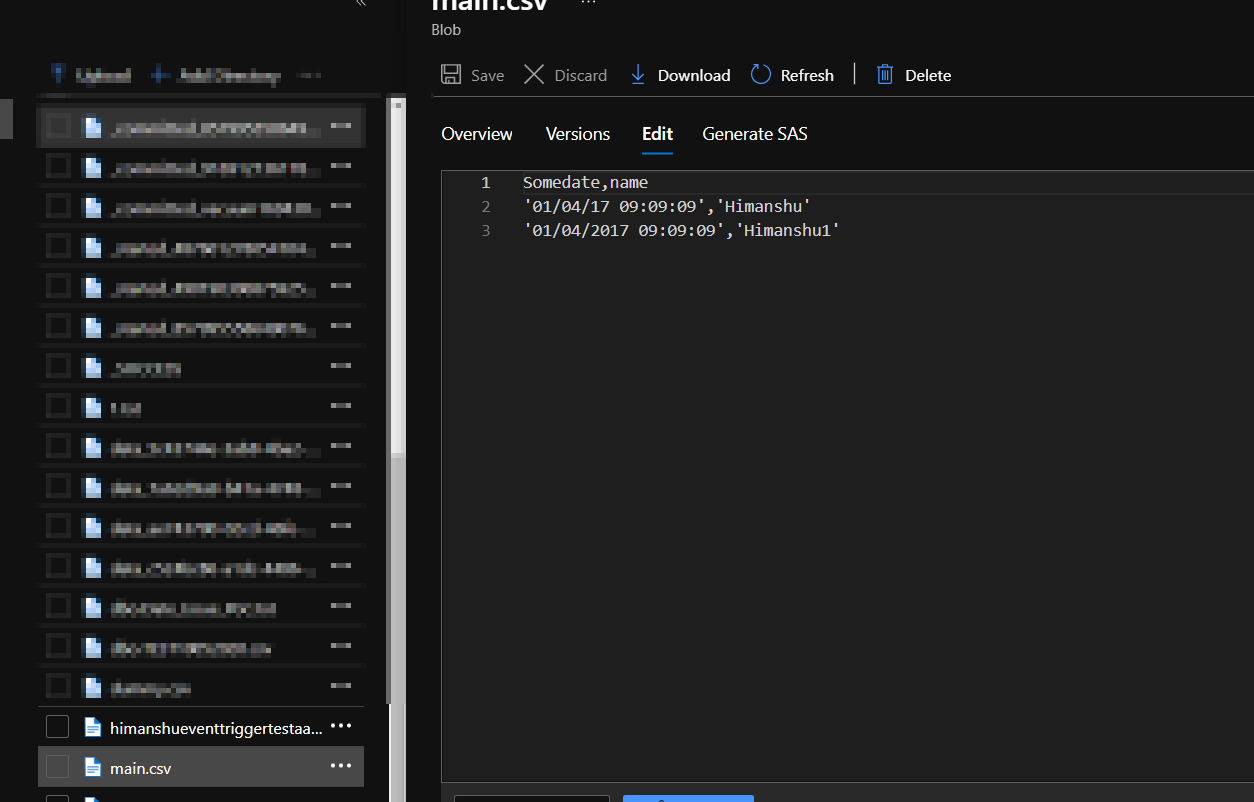
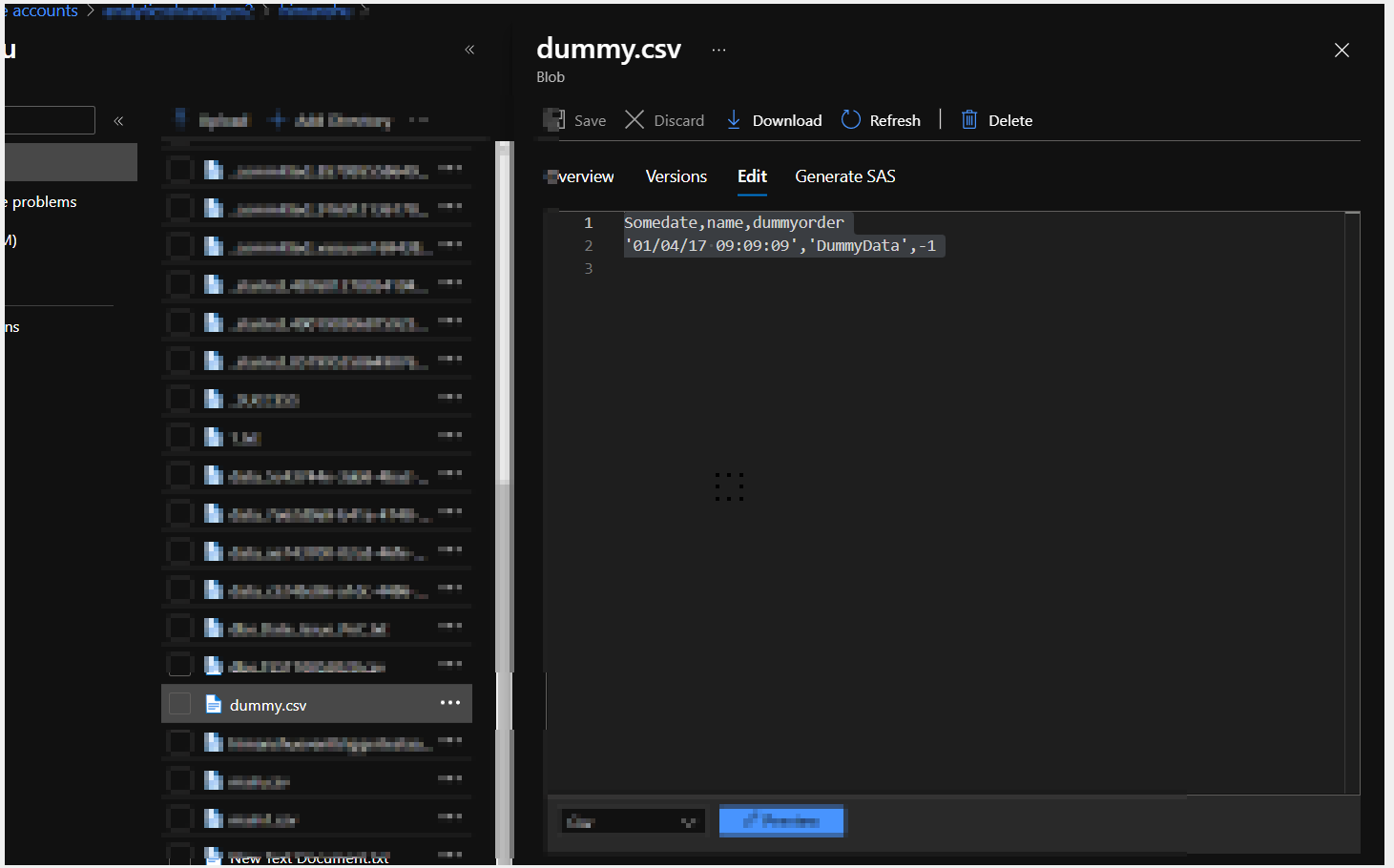
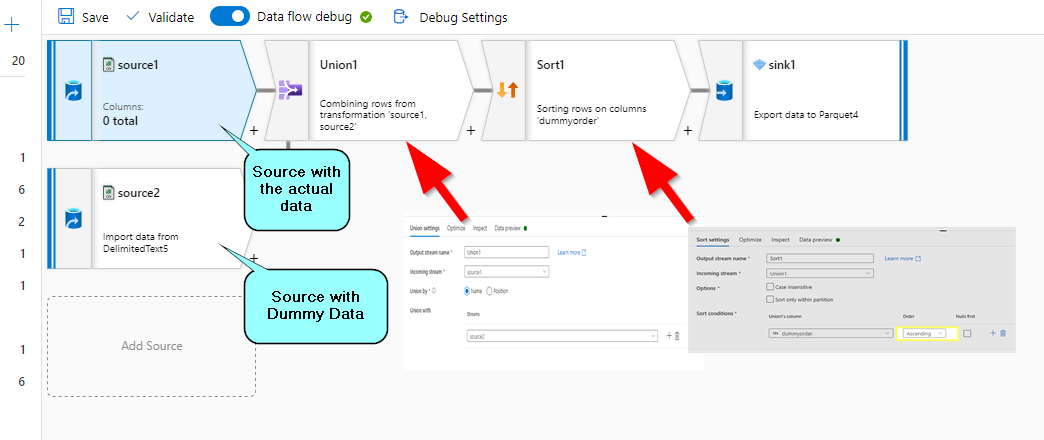
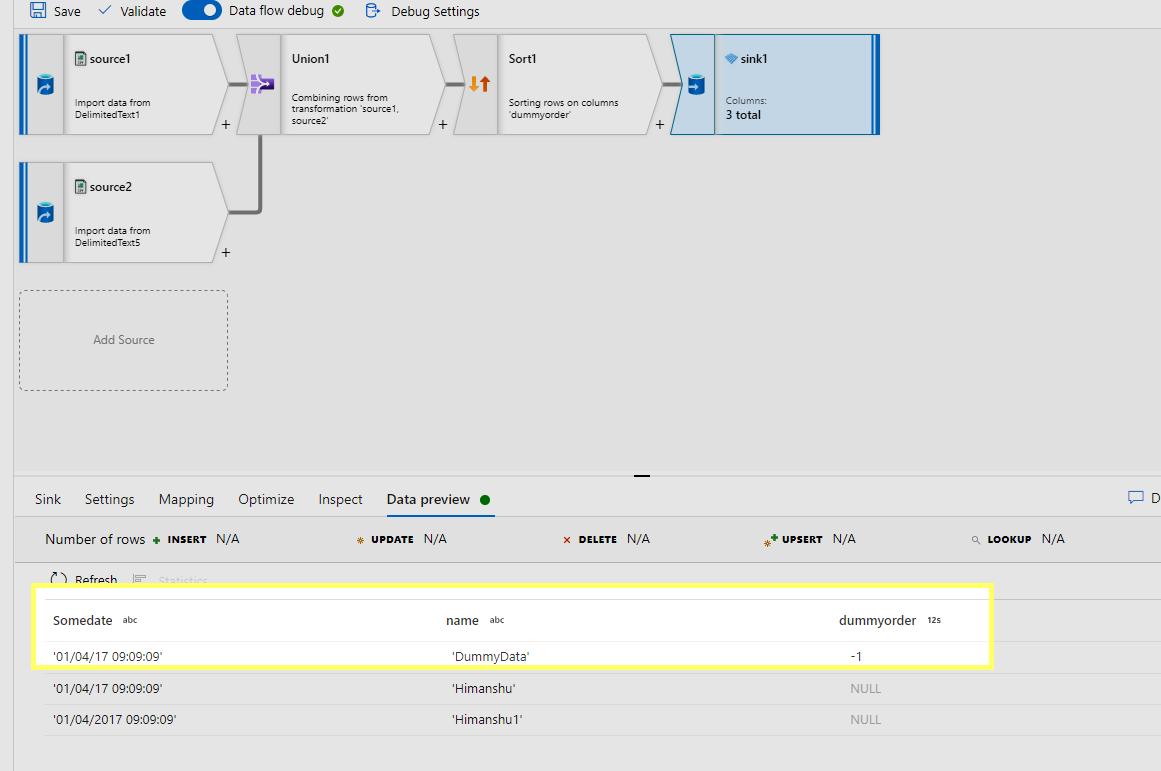
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how