Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Usare gli strumenti HDInsight in Azure Toolkit for Eclipse per sviluppare applicazioni Apache Spark scritte in Scala e inoltrarle a un cluster Azure HDInsight Spark direttamente dall'IDE Eclipse. È possibile usare gli strumenti di HDInsight in diversi modi:
- Per sviluppare e inviare un'applicazione Spark in Scala in un cluster HDInsight Spark.
- Per accedere alle risorse cluster HDInsight Spark di Azure.
- Per sviluppare ed eseguire un'applicazione Spark in Scala localmente.
Prerequisiti
Cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
IDE Eclipse. Questo articolo usa l'IDE Eclipse per sviluppatori Java.
Installare i plug-in necessari
Installare Azure Toolkit for Eclipse
Le istruzioni di installazione sono disponibili in Installazione di Azure Toolkit for Eclipse.
Installare il plug-in di Scala
Quando si apre Eclipse, Strumenti di HDInsight rileva automaticamente se è installato il plug-in Scala. Selezionare OK per continuare, quindi seguire le istruzioni per installare il plug-in del Marketplace di Eclipse. Riavviare l'IDE al termine dell'installazione.
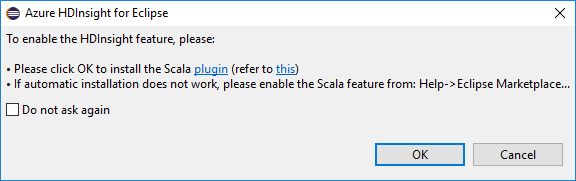
Confermare i plug-in
Passare a Guida di >Eclipse Marketplace....
Selezionare la scheda Installati.
Dovrebbero essere visualizzati almeno:
- Versione di Azure Toolkit for Eclipse<>.
- Versione> dell'IDE <scala.
Accedere alla sottoscrizione di Azure.
Avviare l'IDE eclipse.
Passare alla finestra>Mostra visualizzazione>altro...>Accedere a ...
Nella finestra di dialogo Mostra visualizzazione passare ad Azure>Azure Explorer e quindi selezionare Apri.
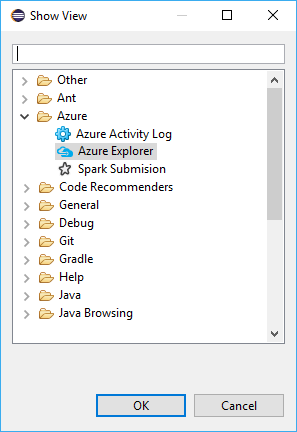
In Azure Explorer fare clic con il pulsante destro del mouse sul nodo Azure e quindi scegliere Accedi.
Nella finestra di dialogo Accesso di Azure scegliere il metodo di autenticazione, selezionare Accedi e completare il processo di accesso.

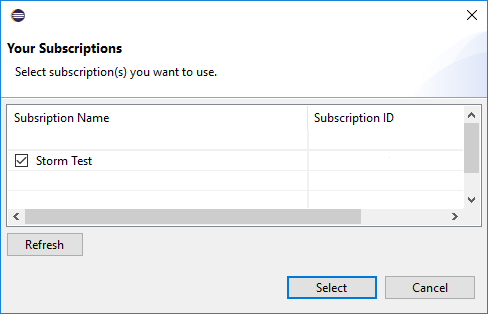
Dopo l'accesso, nella finestra di dialogo Sottoscrizioni sono elencate tutte le sottoscrizioni di Azure associate alle credenziali. Premere Seleziona per chiudere la finestra di dialogo.
Da Azure Explorer passare ad Azure>HDInsight per visualizzare i cluster HDInsight Spark nella sottoscrizione.
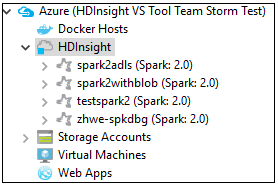
È possibile espandere ancora un nodo del nome cluster per vedere le risorse, ad esempio gli account di archiviazione, associate al cluster.
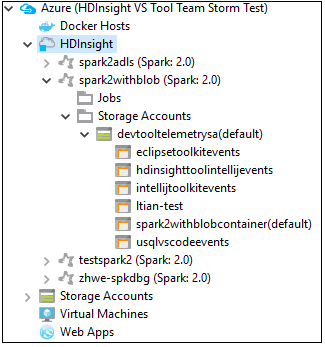
Collegare un cluster
È possibile collegare un normale cluster usando lo username gestito di Ambari. Analogamente, è possibile collegare un cluster HDInsight aggiunto al dominio tramite il dominio e il nome utente, come user1@contoso.com.
In Azure Explorer fare clic con il pulsante destro del mouse su HDInsight e scegliere Collega un cluster.
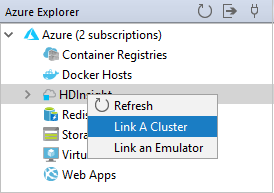
Immettere Nome cluster, Nome utente e Password, quindi selezionare OK. Facoltativamente, immettere l'account di archiviazione e la chiave di archiviazione e quindi selezionare il contenitore di archiviazione per Storage Explorer in modo da usare la visualizzazione struttura ad albero a sinistra.
Nota
Vengono usati la chiave di archiviazione, il nome utente e la password collegati se il cluster ha eseguito l'accesso alla sottoscrizione di Azure e ha collegato un cluster.
Per l'utente solo della tastiera, quando lo stato attivo corrente si trova a Archiviazione tasto, è necessario usare CTRL+TAB per concentrarsi sul campo successivo nella finestra di dialogo.
È possibile visualizzare il cluster collegato in HDInsight. È ora possibile inviare un'applicazione al cluster collegato.
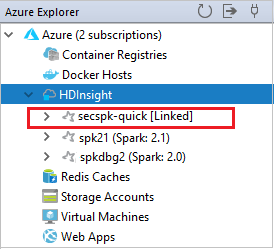
È inoltre possibile scollegare un cluster in Azure Explorer (Esplora Azure).
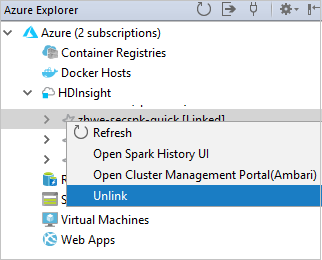
Configurare un progetto Spark in Scala per un cluster HDInsight Spark
Nell'area di lavoro IDE di Eclipse selezionare File>Nuovo>progetto....
Nella procedura guidata Nuovo progetto selezionare HDInsight Project>Spark in HDInsight (Scala). Quindi seleziona Avanti.
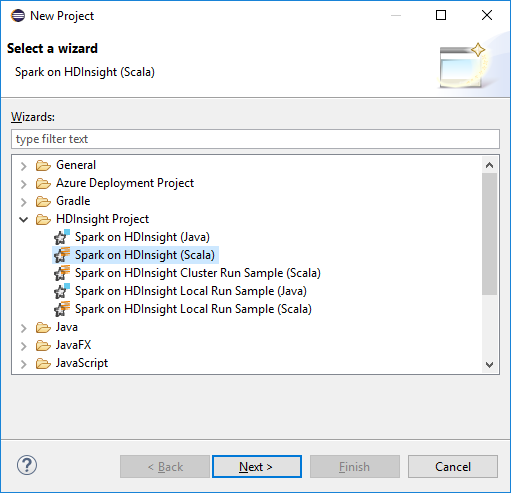
Nella finestra di dialogo New HDInsight Scala Project (Nuovo progetto HDInsight Scala) specificare i valori seguenti e selezionare su Next (Avanti):
- Immettere un nome per il progetto.
- Nell'area JRE verificare che l'opzione Use an execution environment JRE (Usa un ambiente di esecuzione JRE) sia impostata su JavaSE-1.7 o versioni successive.
- Nell'area Spark Library (Libreria Spark) è possibile scegliere l'opzione Use Maven to configure Spark SDK (Usa Maven per configurare l'SDK di Spark). Lo strumento integra la versione corretta dell'SDK di Spark e Scala. È anche possibile scegliere l'opzione Aggiungi Spark SDK manualmente , scaricare e aggiungere Spark SDK manualmente.
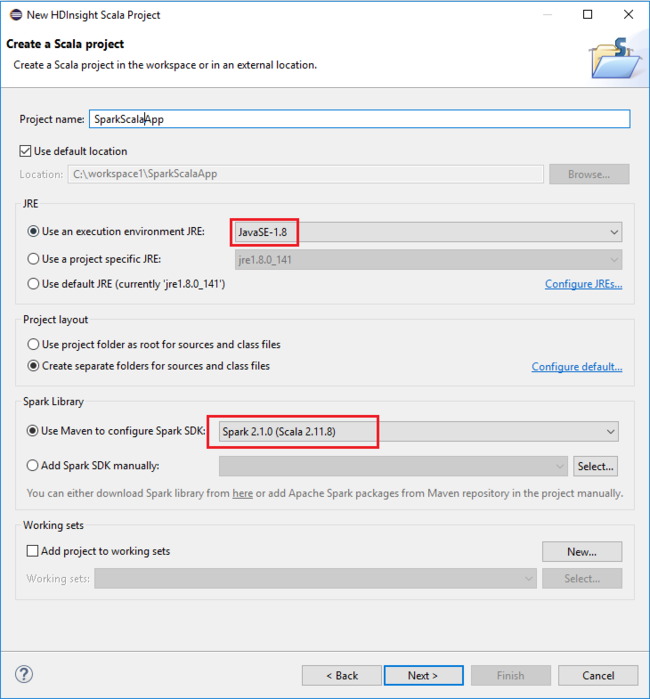
Nella finestra di dialogo successiva esaminare i dettagli e quindi selezionare Fine.
Creare un'applicazione Scala per un cluster HDInsight Spark
In Esplora pacchetti espandere il progetto creato in precedenza. Fare clic con il pulsante destro del mouse su src, scegliere Nuovo>altro....
Nella finestra di dialogo Seleziona procedura guidata selezionare Scala Wizards Scala Object (Scala Wizards>Scala Object). Quindi seleziona Avanti.
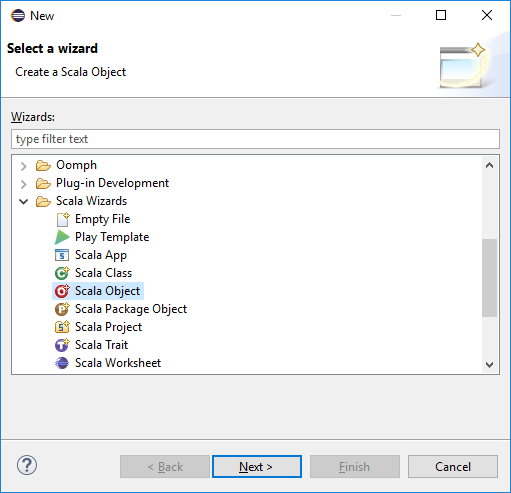
Nella finestra di dialogo Create New File (Crea nuovo file) immettere un nome per l'oggetto e quindi selezionare Finish (Fine). Verrà aperto un editor di testo.
Nell'editor di testo sostituire il contenuto corrente con il codice seguente:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Eseguire l'applicazione in un cluster HDInsight Spark:
a. In Package Explorer (Esplora pacchetti) fare clic con il pulsante destro del mouse sul nome del progetto e quindi scegliere Submit Spark Application to HDInsight (Invia applicazione Spark a HDInsight).
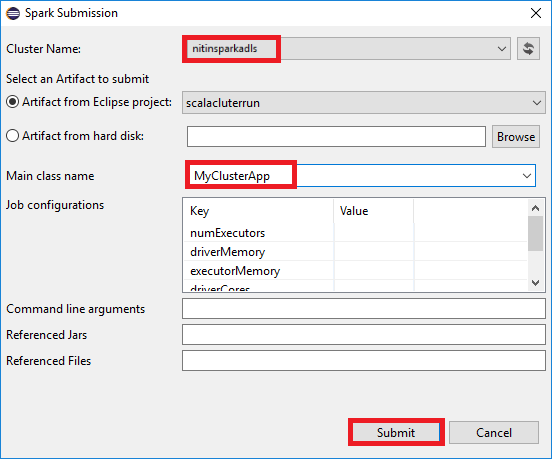
b. Nella finestra di dialogo Spark Submission (Invio Spark) specificare i valori seguenti e selezionare Submit (Invia):
Per Cluster Name(Nome cluster) selezionare il cluster HDInsight Spark in cui eseguire l'applicazione.
Selezionare un elemento nel progetto Eclipse oppure nel disco rigido. Il valore predefinito dipende dall'elemento su cui si fa clic con il pulsante destro del mouse da Package Explorer (Esplora pacchetti).
Nell'elenco a discesa Main class name (Nome classe principale) l'invio guidato mostra tutti i nomi di oggetto del progetto. Selezionare o inserire quello che si vuole eseguire. Se si seleziona un elemento da un disco rigido, è necessario immettere manualmente il nome della classe principale.
Poiché il codice dell'applicazione in questo esempio non richiede argomenti della riga di comando o file JAR o riferimenti, è possibile lasciare vuote le caselle di testo rimanenti.
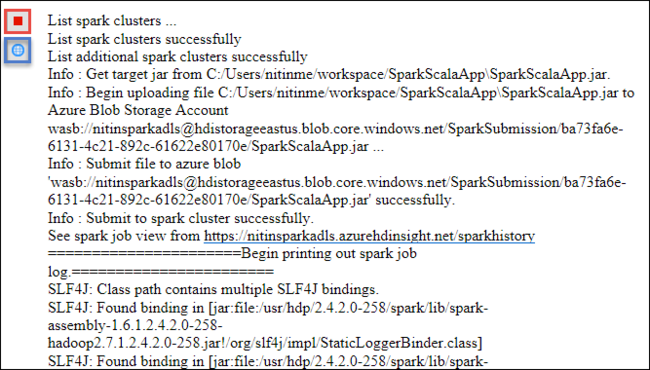
Nella scheda Spark Submission (Invio Spark) verrà visualizzato lo stato di avanzamento. È possibile arrestare l'applicazione selezionando il pulsante rosso nella finestra Spark Submission (Invio Spark). È anche possibile visualizzare i log per questa esecuzione dell'applicazione specifica selezionando l'icona del mondo, indicata dalla casella blu nell'immagine.
Accedere e gestire i cluster HDInsight Spark con gli strumenti HDInsight in Azure Toolkit for Eclipse
È possibile eseguire varie operazioni con gli strumenti HDInsight, tra cui accedere all'output dei processi.
Accedere alla visualizzazione del processo
In Azure Explorer espandere HDInsight, quindi il nome del cluster Spark e quindi selezionare Processi.
Selezionare il nodo Processi . Se la versione di Java è precedente alla versione 1.8, gli strumenti di HDInsight inviano un promemoria automatico per l'installazione del plug-in E(fx)clipse. Selezionare OK per continuare, quindi seguire la procedura guidata per installare il plug-in dal Marketplace di Eclipse e riavviare Eclipse.
Aprire la visualizzazione del processo dal nodo Processi. Nel riquadro destro la scheda Spark Job View (Visualizzazione processi Spark) visualizza tutte le applicazioni eseguite nel cluster. Selezionare il nome dell'applicazione per cui si vogliono visualizzare altri dettagli.
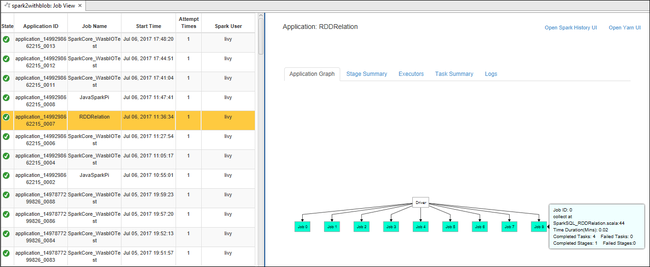
È quindi possibile intraprendere una delle seguenti operazioni:
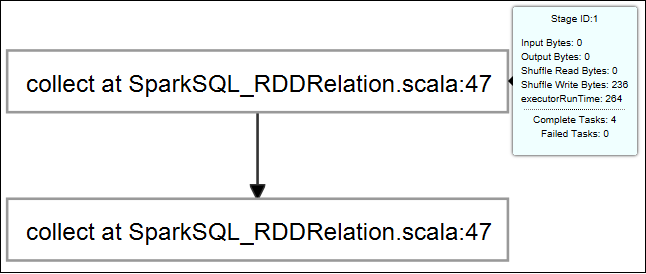
Passare il mouse sul grafico del processo. Mostra le informazioni di base sul processo in esecuzione. Selezionare il grafico del processo: vengono visualizzate le fasi e le informazioni generate da ogni processo.
Selezionare la scheda Log per visualizzare i log di uso più frequente, ad esempio Driver Stderr, Driver Stdout e Directory Info.
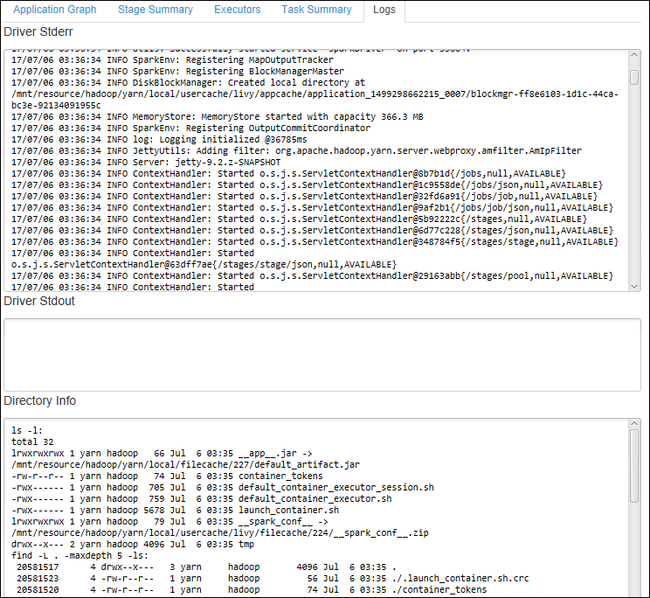
Aprire l'interfaccia utente della cronologia di Spark e l'interfaccia utente di Apache Hadoop YARN, a livello di applicazione, selezionando i rispettivi collegamenti ipertestuali nella parte superiore della finestra.
Accedere al contenitore di archiviazione per il cluster
In Azure Explorer espandere il nodo radice HDInsight per visualizzare un elenco di cluster HDInsight Spark disponibili.
Espandere il nome del cluster per visualizzare l'account di archiviazione e il contenitore di archiviazione predefinito per il cluster.
Fare clic sul nome del contenitore di archiviazione associato al cluster. Nel riquadro destro fare doppio clic sulla cartella HVACOut. Aprire uno dei file part- per visualizzare l'output dell'applicazione.
Accedere al Server cronologia Spark
In Azure Explorer fare clic con il pulsante destro del mouse sul nome del cluster Spark e quindi scegliere Open Spark History UI (Apri UI cronologia Spark). Quando richiesto, immettere le credenziali dell'amministratore per il cluster. Queste sono state specificate durante il provisioning del cluster.
Nel dashboard del Server cronologia Spark è possibile usare il nome dell'applicazione per cercare l'applicazione di cui è appena stata completata l'esecuzione. Nel codice precedente impostare il nome dell'applicazione usando
val conf = new SparkConf().setAppName("MyClusterApp"). Il nome dell'applicazione Spark era MyClusterApp.
Avviare il portale di Apache Ambari
In Azure Explorer fare clic con il pulsante destro del mouse sul nome del cluster Spark e quindi scegliere Open Cluster Management Portal (Ambari) (Apri portale di gestione cluster - Ambari).
Quando richiesto, immettere le credenziali dell'amministratore per il cluster. Queste sono state specificate durante il provisioning del cluster.
Gestire le sottoscrizioni di Azure
Per impostazione predefinita, gli strumenti di HDInsight in Azure Toolkit for Eclipse elencano i cluster Spark di tutte le sottoscrizioni di Azure. Se necessario, è possibile specificare le sottoscrizioni per cui si vuole accedere al cluster.
In Azure Explorer fare clic con il pulsante destro del mouse sul nodo radice Azure e quindi scegliere Gestisci sottoscrizioni.
Nella finestra di dialogo deselezionare le caselle di controllo della sottoscrizione alla quale non si vuole accedere e quindi fare clic su Chiudi. È anche possibile selezionare Esci per uscire dalla sessione di sottoscrizione di Azure.
Eseguire un'applicazione Spark in Scala localmente
È possibile usare gli strumenti HDInsight in Azure Toolkit for Eclipse per eseguire applicazioni Spark in Scala localmente nella workstation. Tali applicazioni in genere non richiedono l'accesso a risorse del cluster quali il contenitore di archiviazione e possono essere eseguite e testate localmente.
Prerequisito
Quando si esegue l'applicazione Spark Scala locale in un computer Windows, potrebbe essere restituita un'eccezione, come spiegato in SPARK-2356, che si verifica a causa di un file WinUtils.exe mancante in Windows.
Per risolvere questo errore, è necessario Winutils.exe in una posizione come C:\WinUtils\bin e quindi aggiungere la variabile di ambiente HADOOP_HOME e impostare il valore della variabile su C\WinUtils.
Eseguire un'applicazione Spark in Scala locale
Avviare Eclipse e creare un progetto. Nella finestra di dialogo New Project (Nuovo progetto) selezionare le opzioni seguenti e quindi fare clic su Next (Avanti).
Nella procedura guidata Nuovo progetto selezionare HdInsight Project>Spark on HDInsight Local Run Sample (Scala) (Esempio di esecuzione locale di HDInsight (Scala). Quindi seleziona Avanti.
Per specificare i dettagli del progetto, seguire i passaggi da 3 a 6 illustrati nella sezione precedente Configurare un progetto Spark in Scala per un cluster HDInsight Spark.
Il modello aggiunge un codice di esempio (LogQuery) sotto la cartella src eseguibile in locale nel computer in uso.
Fare clic con il pulsante destro del mouse su LogQuery.scala e selezionare RunAs 1 Scala Application (Esegui come>applicazione Scala). Un output come questo viene mostrato nella scheda Console:
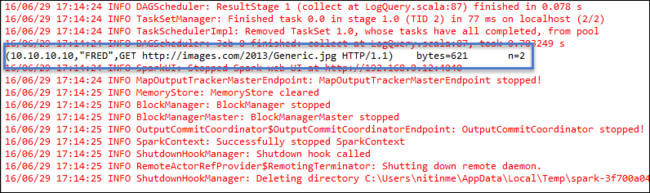
Ruolo di sola lettura
Quando gli utenti inviano processi a un cluster con autorizzazione di sola lettura, le credenziali di Ambari sono obbligatorie.
Collegare un cluster dal menu di scelta rapida
Accedere con l'account di un ruolo di sola lettura.
Da Azure Explorer espandere HDInsight per visualizzare i cluster HDInsight Spark disponibili nella sottoscrizione. I cluster contrassegnati da "Role:Reader" (Ruolo:Lettore) hanno autorizzazioni di ruolo di sola lettura.
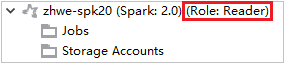
Fare clic con il pulsante destro del mouse sul cluster con autorizzazione di ruolo di sola lettura. Selezionare Link this cluster (Collega questo cluster) dal menu di scelta rapida per collegare il cluster. Immettere il nome utente e la password di Ambari.
Se il cluster è stato collegato correttamente, HDInsight viene aggiornato. La fase del cluster diventerà Linked (Collegato).
Collegare un cluster espandendo il nodo Jobs (Processi)
Fare clic sul nodo Jobs (Processi). Verrà visualizzata la finestra Cluster Job Access Denied (Accesso negato al cluster Jobs).
Fare clic su Link this cluster (Collega questo cluster) per collegare il cluster.
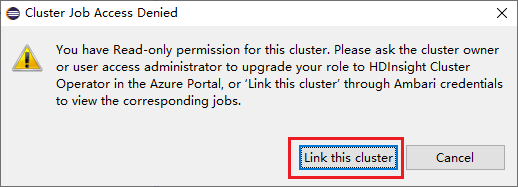
Collegare un cluster dalla finestra Invio Spark
Creare un progetto HDInsight.
Fare clic con il pulsante destro del mouse sul pacchetto. Selezionare quindi Submit Spark Application to HDInsight (Invia applicazione Spark a HDInsight).
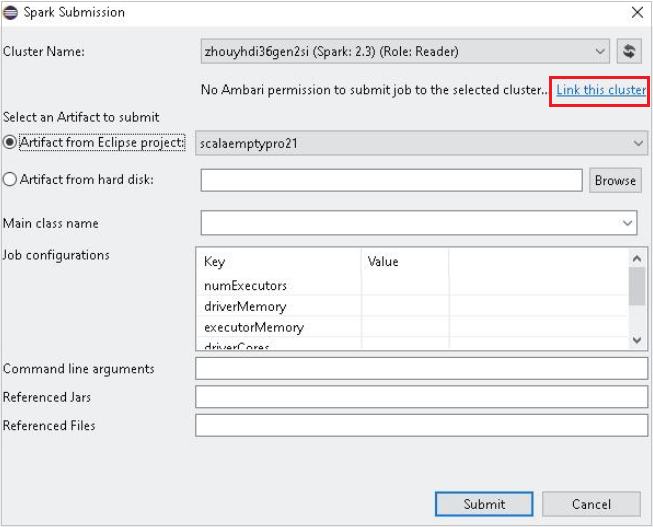
Selezionare un cluster con autorizzazioni di ruolo di sola lettura per Nome cluster. Viene visualizzato un messaggio di avviso. È possibile fare clic su Collega il cluster per collegare il cluster.
Visualizzare gli account di archiviazione
Per i cluster con autorizzazione di ruolo di sola lettura fare clic sul nodo Storage Accounts (Account di archiviazione). Verrà visualizzata la finestra Storage Access Denied (Accesso negato alla risorsa di archiviazione).
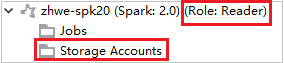
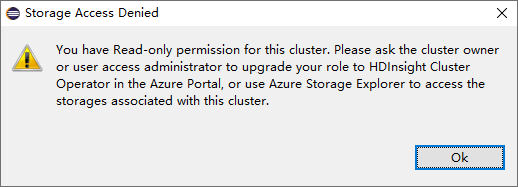
Per i cluster collegati fare clic sul nodo Storage Accounts (Account di archiviazione). Verrà visualizzata la finestra Storage Access Denied (Accesso negato alla risorsa di archiviazione).
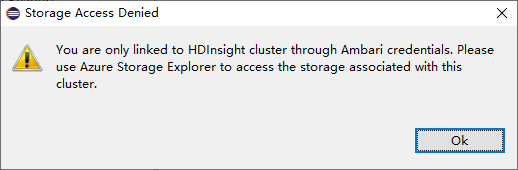
Problemi noti
Quando si usa Collega un cluster, è consigliabile fornire credenziali di archiviazione.
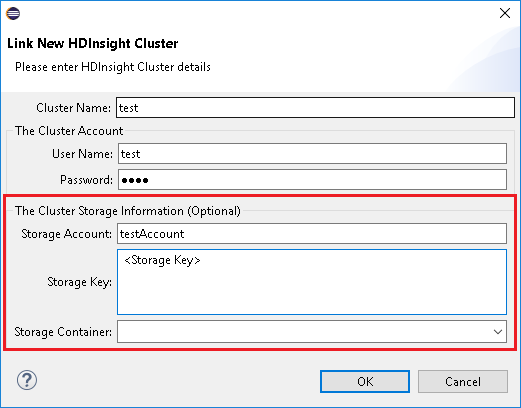
Esistono due modalità per inviare i processi. Se vengono fornite le credenziali di archiviazione, per inviare il processo verrà usata la modalità batch. In caso contrario, verrà usata la modalità interattiva. Se il cluster è occupato, è possibile che venga visualizzato l'errore riportato di seguito.


Vedi anche
Scenari
- Apache Spark con Business Intelligence: eseguire l'analisi interattiva dei dati con strumenti di Business Intelligence mediante Spark in HDInsight
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per l'analisi della temperatura di compilazione utilizzando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
Creazione ed esecuzione di applicazioni
- Creare un'applicazione autonoma con Scala
- Eseguire processi in modalità remota in un cluster Apache Spark usando Apache Livy
Strumenti ed estensioni
- Usare Azure Toolkit for IntelliJ per creare e inviare applicazioni Spark in Scala
- Usare Azure Toolkit for IntelliJ per il debug remoto di applicazioni Apache Spark tramite VPN
- Usare Azure Toolkit for IntelliJ per il debug remoto di applicazioni Apache Spark tramite SSH
- Usare i notebook di Apache Zeppelin con un cluster Apache Spark in HDInsight
- Kernel disponibili per Jupyter Notebook nel cluster Apache Spark per HDInsight
- Usare pacchetti esterni con Jupyter Notebook
- Installare Jupyter Notebook nel computer e connetterlo a un cluster HDInsight Spark