Azure Virtual Desktop is een uitgebreide desktop- en app-virtualisatieservice die wordt uitgevoerd op Microsoft Azure. Virtual Desktop helpt bij het inschakelen van een veilige extern bureaublad-ervaring waarmee organisaties de bedrijfstolerantie kunnen versterken. Het biedt vereenvoudigd beheer, Windows 10 en 11 Enterprise voor meerdere sessies en optimalisaties voor Microsoft 365-apps voor ondernemingen. Met Virtual Desktop kunt u uw Windows-bureaubladen en -apps in enkele minuten implementeren en schalen in Azure, met geïntegreerde beveiligings- en nalevingsfuncties om uw apps en gegevens veilig te houden.
Wanneer u extern werk voor uw organisatie met Virtual Desktop blijft inschakelen, is het belangrijk om inzicht te hebben in de mogelijkheden en aanbevolen procedures voor herstel na noodgevallen. Deze procedures versterken de betrouwbaarheid tussen regio's om gegevens veilig te houden en werknemers productief te houden. Dit artikel bevat overwegingen over vereisten voor bedrijfscontinuïteit en herstel na noodgevallen (BCDR), implementatiestappen en aanbevolen procedures. U krijgt meer informatie over opties, strategieën en architectuurrichtlijnen. Met de inhoud in dit document kunt u een succesvol BCDR-plan voorbereiden en kunt u meer flexibiliteit voor uw bedrijf bieden tijdens geplande en ongeplande downtimegebeurtenissen.
Er zijn verschillende soorten rampen en storingen, en elk kan een andere impact hebben. Tolerantie en herstel worden uitgebreid besproken voor zowel lokale als regiobrede gebeurtenissen, waaronder herstel van de service in een andere externe Azure-regio. Dit type herstel wordt geo-herstel na noodgevallen genoemd. Het is essentieel om uw Virtual Desktop-architectuur te bouwen voor tolerantie en beschikbaarheid. U moet maximale lokale tolerantie bieden om de impact van foutgebeurtenissen te verminderen. Deze tolerantie vermindert ook de vereisten voor het uitvoeren van herstelprocedures. Dit artikel bevat ook informatie over hoge beschikbaarheid en aanbevolen procedures.
Doelstellingen en bereik
De doelstellingen van deze handleiding zijn:
- Zorg voor maximale beschikbaarheid, tolerantie en mogelijkheid voor herstel na noodgevallen, terwijl gegevensverlies voor belangrijke geselecteerde gebruikersgegevens wordt geminimaliseerd.
- Minimaliseer de hersteltijd.
Deze doelstellingen worden ook wel de beoogde herstelpunten (RPO) en de Recovery Time Objective (RTO) genoemd.
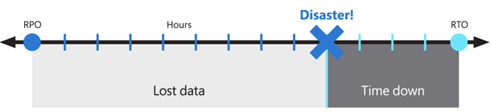
De voorgestelde oplossing biedt lokale hoge beschikbaarheid, beveiliging tegen één storing in de beschikbaarheidszone en beveiliging tegen een hele Azure-regiofout. Het is afhankelijk van een redundante implementatie in een andere of secundaire Azure-regio om de service te herstellen. Hoewel het nog steeds een goede gewoonte is, hoeven Azure-regio's niet te worden gekoppeld aan Virtual Desktop en de technologie die wordt gebruikt voor het bouwen van BCDR. Primaire en secundaire locaties kunnen elke combinatie van Azure-regio's zijn, als de netwerklatentie dit toestaat. Het uitvoeren van AVD-hostgroepen in meerdere geografische regio's kan meer voordelen bieden, niet beperkt tot BCDR.
Als u de impact van een storing in één beschikbaarheidszone wilt verminderen, gebruikt u tolerantie om hoge beschikbaarheid te verbeteren:
- Op de rekenlaag verspreidt u de Virtual Desktop-sessiehosts over verschillende beschikbaarheidszones.
- Gebruik op de opslaglaag waar mogelijk zonetolerantie.
- Implementeer op de netwerklaag zonetolerante Azure ExpressRoute- en VPN-gateways (Virtual Private Network).
- Bekijk voor elke afhankelijkheid de impact van een storing in één zone en plan de risicobeperking. Implementeer bijvoorbeeld Active Directory-domein Controllers en andere externe resources die toegankelijk zijn voor Virtual Desktop-gebruikers in meerdere beschikbaarheidszones.
Afhankelijk van het aantal beschikbaarheidszones dat u gebruikt, evalueert u het aantal sessiehosts om te compenseren voor het verlies van één zone. Zelfs als er (n-1) zones beschikbaar zijn, kunt u de gebruikerservaring en prestaties garanderen.
Notitie
Azure-beschikbaarheidszones zijn een functie voor hoge beschikbaarheid die de tolerantie kan verbeteren. Beschouw ze echter niet als een noodhersteloplossing die kan worden beschermd tegen rampen in de hele regio.

Vanwege de mogelijke combinaties van typen, replicatieopties, servicemogelijkheden en beschikbaarheidsbeperkingen in sommige regio's, wordt het onderdeel Cloud Cache van FSLogix aanbevolen om te worden gebruikt in plaats van opslagspecifieke replicatiemechanismen.
OneDrive wordt niet behandeld in dit artikel. Zie SharePoint- en OneDrive-gegevenstolerantie in Microsoft 365 voor meer informatie over redundantie en hoge beschikbaarheid.
Voor de rest van dit artikel leert u meer over oplossingen voor de twee verschillende typen Virtual Desktop-hostgroepen. Er zijn ook waarnemingen beschikbaar, zodat u deze architectuur kunt vergelijken met andere oplossingen:
- Persoonlijk: In dit type hostgroep heeft een gebruiker een permanent toegewezen sessiehost, die nooit mag worden gewijzigd. Omdat het persoonlijk is, kan deze VIRTUELE machine gebruikersgegevens opslaan. De veronderstelling is om replicatie- en back-uptechnieken te gebruiken om de status te behouden en te beveiligen.
- Gegroepeerd: gebruikers krijgen tijdelijk een van de beschikbare sessiehost-VM's uit de groep toegewezen, rechtstreeks via een bureaubladtoepassingsgroep of met behulp van externe apps. VM's zijn staatloos en gebruikersgegevens en -profielen worden opgeslagen in externe opslag of OneDrive.
Kostengevolgen worden besproken, maar het primaire doel is een effectieve implementatie van geo-noodherstel met minimale gegevensverlies. Zie de volgende bronnen voor meer BCDR-details:
Vereisten
Implementeer de kerninfrastructuur en zorg ervoor dat deze beschikbaar is in de primaire en secundaire Azure-regio. Voor hulp bij uw netwerktopologie kunt u de Netwerktopologie en connectiviteitsmodellen van Azure Cloud Adoption Framework gebruiken:
Implementeer in beide modellen de primaire Virtual Desktop-hostgroep en de secundaire omgeving voor herstel na noodgevallen in verschillende virtuele spoke-netwerken en verbind deze met elke hub in dezelfde regio. Plaats één hub op de primaire locatie, één hub op de secundaire locatie en maak vervolgens verbinding tussen de twee.
De hub biedt uiteindelijk hybride connectiviteit met on-premises resources, firewallservices, identiteitsbronnen zoals Active Directory-domein Controllers en beheerbronnen zoals Log Analytics.
U moet rekening houden met line-of-business-toepassingen en afhankelijke resourcebeschikbaarheid wanneer er een failover naar de secundaire locatie wordt uitgevoerd.
Bedrijfscontinuïteit en herstel na noodgevallen in besturingsvlak
Virtual Desktop biedt bedrijfscontinuïteit en herstel na noodgevallen voor het besturingsvlak om de metagegevens van klanten tijdens storingen te behouden. Het Azure-platform beheert deze gegevens en processen en gebruikers hoeven niets te configureren of uit te voeren.

Virtual Desktop is ontworpen om bestand te zijn tegen fouten van afzonderlijke onderdelen en om snel te kunnen herstellen van fouten. Wanneer er een storing optreedt in een regio, voert de service-infrastructuuronderdelen een failover uit naar de secundaire locatie en blijven ze gewoon functioneren. U hebt nog steeds toegang tot servicegerelateerde metagegevens en gebruikers kunnen nog steeds verbinding maken met beschikbare hosts. Verbindingen van eindgebruikers blijven online als de tenantomgeving of hosts toegankelijk blijven. Gegevenslocaties voor Virtual Desktop verschillen van de locatie van de implementatie van virtuele machines (VM's) van de hostgroepsessie. Het is mogelijk om metagegevens van Virtual Desktop te vinden in een van de ondersteunde regio's en vervolgens VM's op een andere locatie te implementeren. Meer informatie vindt u in het artikel over de Virtual Desktop-servicearchitectuur en -tolerantie .
Actief-actief versus actief-passief
Als verschillende sets gebruikers verschillende BCDR-vereisten hebben, raadt Microsoft u aan om meerdere hostgroepen met verschillende configuraties te gebruiken. Gebruikers met een bedrijfskritieke toepassing kunnen bijvoorbeeld een volledig redundante hostgroep toewijzen met mogelijkheden voor geo-noodherstel. Ontwikkel- en testgebruikers kunnen echter een afzonderlijke hostgroep gebruiken zonder herstel na noodgevallen.
Voor elke virtuele bureaublad-hostgroep kunt u uw BCDR-strategie baseren op een actief-actief- of actief-passiefmodel. In dit scenario wordt ervan uitgegaan dat dezelfde set gebruikers op één geografische locatie wordt bediend door een specifieke hostgroep.
- Actief-actief
Voor elke hostgroep in de primaire regio implementeert u een tweede hostgroep in de secundaire regio.
Deze configuratie biedt bijna nul RTO en RPO heeft extra kosten.
U hoeft geen beheerder in te grijpen of een failover uit te dienen. Tijdens normale bewerkingen biedt de secundaire hostgroep de gebruiker virtual desktop-resources.
Elke hostgroep heeft zijn eigen opslagaccounts (ten minste één) voor permanente gebruikersprofielen.
U moet latentie evalueren op basis van de fysieke locatie en connectiviteit van de gebruiker. Voor sommige Azure-regio's, zoals West-Europa en Noord-Europa, kan het verschil te verwaarlozen zijn bij het openen van de primaire of secundaire regio's. U kunt dit scenario valideren met behulp van het hulpprogramma Azure Virtual Desktop Experience Estimator .
Gebruikers worden toegewezen aan verschillende toepassingsgroepen, zoals DAG (Desktop Application Group ) en RemoteApp Application Group (RAG), in zowel de primaire als de secundaire hostgroepen. In dit geval zien ze dubbele vermeldingen in hun Virtual Desktop-clientfeed. Gebruik afzonderlijke Virtual Desktop-werkruimten met duidelijke namen en labels die het doel van elke resource weerspiegelen om verwarring te voorkomen. Informeer uw gebruikers over het gebruik van deze resources.
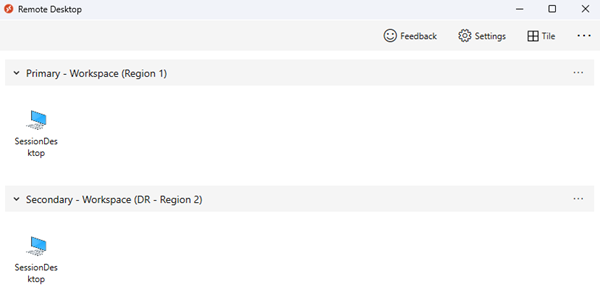
Als u opslag nodig hebt om FSLogix-profiel en ODFC-containers afzonderlijk te beheren, gebruikt u Cloud Cache om bijna nul RPO te garanderen.
- Als u profielconflicten wilt voorkomen, staat u gebruikers niet toe om tegelijkertijd toegang te krijgen tot beide hostgroepen.
- Vanwege de actieve-actieve aard van dit scenario moet u uw gebruikers op de juiste manier informeren over het gebruik van deze resources.
Notitie
Het gebruik van afzonderlijke ODFC-containers is een geavanceerd scenario met een hogere complexiteit. Het implementeren op deze manier wordt alleen aanbevolen in bepaalde specifieke scenario's.
- Actief-passief
- Net als actief-actief implementeert u voor elke hostgroep in de primaire regio een tweede hostgroep in de secundaire regio.
- De hoeveelheid rekenresources die actief zijn in de secundaire regio, wordt verminderd in vergelijking met de primaire regio, afhankelijk van het beschikbare budget. U kunt automatisch schalen gebruiken om meer rekencapaciteit te bieden, maar hiervoor is meer tijd nodig en is Azure-capaciteit niet gegarandeerd.
- Deze configuratie biedt een hogere RTO in vergelijking met de actief-actieve benadering, maar het is minder duur.
- U hebt tussenkomst van de beheerder nodig om een failoverprocedure uit te voeren als er sprake is van een Azure-storing. De secundaire hostgroep biedt normaal gesproken geen gebruikerstoegang tot Virtual Desktop-resources.
- Elke hostgroep heeft zijn eigen opslagaccounts voor permanente gebruikersprofielen.
- Gebruikers die Virtual Desktop-services met optimale latentie en prestaties gebruiken, worden alleen beïnvloed als er sprake is van een Azure-storing. U moet dit scenario valideren met behulp van het azure Virtual Desktop Experience Estimator-hulpprogramma . Prestaties moeten acceptabel zijn, zelfs als deze verslechterd zijn voor de secundaire omgeving voor herstel na noodgevallen.
- Gebruikers worden toegewezen aan slechts één set toepassingsgroepen, zoals Bureaublad- en Externe apps. Tijdens normale bewerkingen bevinden deze apps zich in de primaire hostgroep. Tijdens een storing en na een failover worden gebruikers toegewezen aan toepassingsgroepen in de secundaire hostgroep. Er worden geen dubbele vermeldingen weergegeven in de Virtual Desktop-clientfeed van de gebruiker, ze kunnen dezelfde werkruimte gebruiken en alles is transparant voor hen.
- Als u opslag nodig hebt om FSLogix-profiel en Office-containers te beheren, gebruikt u Cloud Cache om bijna nul RPO te garanderen.
- Als u profielconflicten wilt voorkomen, staat u gebruikers niet toe om tegelijkertijd toegang te krijgen tot beide hostgroepen. Omdat dit scenario actief-passief is, kunnen beheerders dit gedrag afdwingen op het niveau van de toepassingsgroep. Pas na een failoverprocedure heeft de gebruiker toegang tot elke toepassingsgroep in de secundaire hostgroep. Toegang wordt ingetrokken in de toepassingsgroep van de primaire hostgroep en opnieuw toegewezen aan een toepassingsgroep in de secundaire hostgroep.
- Voer een failover uit voor alle toepassingsgroepen, anders kunnen gebruikers die verschillende toepassingsgroepen in verschillende hostgroepen gebruiken profielconflicten veroorzaken als ze niet effectief worden beheerd.
- Het is mogelijk om een specifieke subset van gebruikers toe te staan om selectief een failover naar de secundaire hostgroep uit te voeren en een beperkt actief-actief gedrag te bieden en failovermogelijkheden te testen. Het is ook mogelijk om een failover uit te voeren voor specifieke toepassingsgroepen, maar u moet uw gebruikers opleiden om geen resources uit verschillende hostgroepen tegelijk te gebruiken.
Voor specifieke omstandigheden kunt u één hostgroep maken met een combinatie van sessiehosts in verschillende regio's. Het voordeel van deze oplossing is dat als u één hostgroep hebt, u geen definities en toewijzingen hoeft te dupliceren voor bureaublad- en externe apps. Helaas heeft herstel na noodgevallen voor gedeelde hostgroepen verschillende nadelen:
- Voor poolhostgroepen is het niet mogelijk om een gebruiker naar een sessiehost in dezelfde regio te dwingen.
- Een gebruiker kan een hogere latentie en suboptimale prestaties ervaren bij het maken van verbinding met een sessiehost in een externe regio.
- Als u opslag voor gebruikersprofielen nodig hebt, hebt u een complexe configuratie nodig voor het beheren van toewijzingen voor sessiehosts in de primaire en secundaire regio's.
- U kunt de afvoermodus gebruiken om tijdelijk de toegang tot sessiehosts in de secundaire regio uit te schakelen. Deze methode introduceert echter meer complexiteit, beheeroverhead en inefficiënt gebruik van resources.
- U kunt sessiehosts in een offlinestatus in de secundaire regio's onderhouden, maar het introduceert meer complexiteit en beheeroverhead.
Overwegingen en aanbevelingen
Algemeen
Als u een actief-actief- of actief-passieve configuratie wilt implementeren met behulp van meerdere hostgroepen en een FSLogix-cloudcachemechanisme, kunt u de hostgroep binnen dezelfde werkruimte of een andere maken, afhankelijk van het model. Voor deze aanpak moet u de uitlijning en updates onderhouden, waarbij zowel hostgroepen synchroon als op hetzelfde configuratieniveau worden gehouden. Naast een nieuwe hostgroep voor de secundaire regio voor herstel na noodgevallen hebt u het volgende nodig:
- Nieuwe afzonderlijke toepassingsgroepen en gerelateerde toepassingen voor de nieuwe hostgroep maken.
- Als u gebruikerstoewijzingen wilt intrekken in de primaire hostgroep en deze vervolgens handmatig opnieuw wilt toewijzen aan de nieuwe hostgroep tijdens de failover.
Bekijk de opties voor bedrijfscontinuïteit en herstel na noodgevallen voor FSLogix.
- Er wordt geen profielherstel behandeld in dit document.
- Cloudcache (actief/passief) is opgenomen in dit document, maar wordt geïmplementeerd met behulp van dezelfde hostgroep.
- Cloudcache (actief/actief) wordt behandeld in het resterende deel van dit document.
Er zijn limieten voor Virtual Desktop-resources die moeten worden overwogen in het ontwerp van een Virtual Desktop-architectuur. Valideer uw ontwerp op basis van de servicelimieten van Virtual Desktop.
Voor diagnostische gegevens en bewaking is het raadzaam om dezelfde Log Analytics-werkruimte te gebruiken voor zowel de primaire als de secundaire hostgroep. Met deze configuratie biedt Azure Virtual Desktop Insights een uniforme weergave van de implementatie in beide regio's.
Het gebruik van één logboekbestemming kan echter problemen veroorzaken als de hele primaire regio niet beschikbaar is. De secundaire regio kan de Log Analytics-werkruimte niet gebruiken in de niet-beschikbare regio. Als deze situatie onaanvaardbaar is, kunnen de volgende oplossingen worden vastgesteld:
- Gebruik een afzonderlijke Log Analytics-werkruimte voor elke regio en wijs vervolgens de onderdelen van Virtual Desktop aan om zich aan te melden bij de lokale werkruimte.
- Test en controleer de replicatie en failovermogelijkheden van de Logs Analytics-werkruimte.
Compute
Voor de implementatie van beide hostgroepen in de primaire en secundaire regio's voor herstel na noodgevallen moet u de VM-vloot van de sessiehost verspreiden over meerdere beschikbaarheidszones. Als beschikbaarheidszones niet beschikbaar zijn in de lokale regio, kunt u een beschikbaarheidsset gebruiken om uw oplossing toleranter te maken dan met een standaardimplementatie.
De gouden installatiekopie die u gebruikt voor de implementatie van hostgroepen in de secundaire regio voor herstel na noodgevallen moet hetzelfde zijn als u voor de primaire regio gebruikt. U moet installatiekopieën opslaan in de Azure Compute Gallery en meerdere afbeeldingsreplica's configureren op zowel de primaire als de secundaire locaties. Elke installatiekopieënreplica kan een parallelle implementatie van een maximum aantal VM's ondersteunen en u hebt mogelijk meer dan één nodig op basis van de gewenste grootte van de implementatiebatch. Zie Afbeeldingen opslaan en delen in een Azure Compute Gallery voor meer informatie.
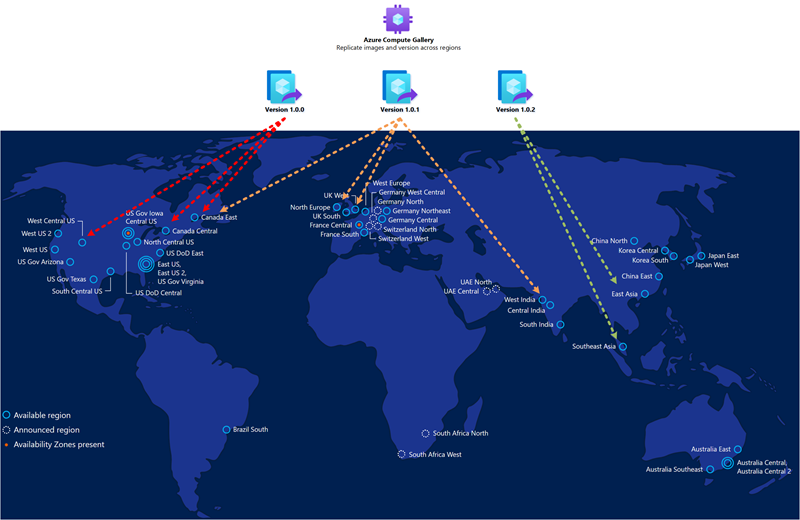
De Azure Compute Gallery is geen globale resource. Het is raadzaam om ten minste een secundaire galerie in de secundaire regio te hebben. Maak in uw primaire regio een galerie, een definitie van een VM-installatiekopieën en een versie van de VM-installatiekopieën. Maak vervolgens dezelfde objecten ook in de secundaire regio. Wanneer u de versie van de VM-installatiekopie maakt, kunt u de versie van de VM-installatiekopie kopiëren die in de primaire regio is gemaakt door de galerie, de definitie van de VM-installatiekopie en de versie van de VM-installatiekopie op te geven die wordt gebruikt in de primaire regio. Azure kopieert de installatiekopieën en maakt een lokale versie van de VM-installatiekopieën. U kunt deze bewerking uitvoeren met behulp van de Azure Portal- of Azure CLI-opdracht, zoals hieronder wordt beschreven:
Een installatiekopieëndefinitie en een installatiekopieënversie maken
Niet alle sessiehost-VM's op de secundaire locaties voor herstel na noodgevallen moeten actief zijn en altijd worden uitgevoerd. U moet in eerste instantie een voldoende aantal virtuele machines maken en daarna een mechanisme voor automatische schaalaanpassing gebruiken, zoals schaalplannen. Met deze mechanismen is het mogelijk om de meeste rekenresources offline te onderhouden of de toewijzing ervan ongedaan te maken om de kosten te verlagen.
Het is ook mogelijk om automatisering te gebruiken om sessiehosts in de secundaire regio te maken wanneer dat nodig is. Met deze methode worden de kosten geoptimaliseerd, maar afhankelijk van het mechanisme dat u gebruikt, is mogelijk een langere RTO vereist. Deze methode staat failovertests zonder een nieuwe implementatie niet toe en staat selectieve failover niet toe voor specifieke groepen gebruikers.

Notitie
U moet elke sessiehost-VM een paar uur ten minste één keer per 90 dagen inschakelen om het verificatietoken te vernieuwen dat nodig is om verbinding te maken met het besturingsvlak van Virtual Desktop. U moet ook regelmatig beveiligingspatches en toepassingsupdates toepassen.
- Als u sessiehosts offline hebt of de toewijzing ervan ongedaan hebt gemaakt, garandeert de status in de secundaire regio niet dat de capaciteit beschikbaar is in het geval van een noodgeval in de hele primaire regio. Het is ook van toepassing als er op aanvraag nieuwe sessiehosts worden geïmplementeerd wanneer dat nodig is en met Site Recovery-gebruik . De rekencapaciteit kan alleen worden gegarandeerd als de gerelateerde resources al zijn toegewezen en actief zijn.
Belangrijk
Azure-reserveringen bieden geen gegarandeerde capaciteit in de regio.
Voor cloudcachegebruiksscenario's raden we u aan om de Premium-laag voor beheerde schijven te gebruiken.
Storage
In deze handleiding gebruikt u ten minste twee afzonderlijke opslagaccounts voor elke Virtual Desktop-hostgroep. Een is voor de FSLogix-profielcontainer en een is voor de Office-containergegevens. U hebt ook nog een opslagaccount nodig voor MSIX-pakketten . De volgende overwegingen zijn van toepassing:
- U kunt Azure Files-share en Azure NetApp Files gebruiken als opslagalternatieven. Als u de opties wilt vergelijken, raadpleegt u de FSLogix-containeropslagopties.
- Azure Files-share kan zonetolerantie bieden met behulp van de optie ZRS-tolerantie (zone-gerepliceerde opslag), als deze beschikbaar is in de regio.
- U kunt de functie voor geografisch redundante opslag in de volgende situaties niet gebruiken:
- U hebt een regio nodig die geen paar heeft. De regioparen voor geografisch redundante opslag zijn vast en kunnen niet worden gewijzigd.
- U gebruikt de Premium-laag.
- RPO en RTO zijn hoger dan het FSLogix Cloud Cache-mechanisme.
- Het is niet eenvoudig om failover en failback in een productieomgeving te testen.
- Azure NetApp Files vereist meer overwegingen:
- Zoneredundantie is nog niet beschikbaar. Als de tolerantievereiste belangrijker is dan prestaties, gebruikt u de Azure Files-share.
- Azure NetApp Files kan zonegebonden zijn. Klanten kunnen bepalen in welke (één) Azure-beschikbaarheidszone moet worden toegewezen.
- Replicatie tussen zones kan worden ingesteld op volumeniveau om zonetolerantie te bieden, maar replicatie gebeurt asynchroon en vereist handmatige failover. Voor dit proces is een RPO (Recovery Point Objective) en RTO (Recovery Time Objective) vereist die groter zijn dan nul. Voordat u deze functie gebruikt, bekijkt u de vereisten en overwegingen voor replicatie tussen zones.
- U kunt Azure NetApp Files gebruiken met zone-redundante VPN- en ExpressRoute-gateways, als de standaardnetwerkfunctie wordt gebruikt, die u kunt gebruiken voor netwerktolerantie. Zie Ondersteunde netwerktopologieën voor meer informatie.
- Azure Virtual WAN wordt ondersteund wanneer deze samen met standaardnetwerken van Azure NetApp Files wordt gebruikt. Zie Ondersteunde netwerktopologieën voor meer informatie.
- Azure NetApp Files heeft een replicatiemechanisme voor meerdere regio's. De volgende overwegingen zijn van toepassing:
- Deze is niet beschikbaar in alle regio's.
- Replicatie tussen regio's van Azure NetApp Files-volumes kan verschillen van azure-opslagregioparen.
- Het kan niet tegelijkertijd worden gebruikt met replicatie tussen zones
- Failover is niet transparant en failback vereist opnieuw configureren van opslag.
- Grens
- Er zijn limieten in de grootte, invoer-/uitvoerbewerkingen per seconde (IOPS), bandbreedte-MBps voor zowel Azure Files-share - als Azure NetApp Files-opslagaccounts en -volumes. Indien nodig is het mogelijk om meer dan één te gebruiken voor dezelfde hostgroep in Virtual Desktop met behulp van instellingen per groep in FSLogix. Deze configuratie vereist echter meer planning en configuratie.
Het opslagaccount dat u gebruikt voor MSIX-toepassingspakketten moet verschillen van de andere accounts voor Profiel- en Office-containers. De volgende opties voor herstel na noodgevallen zijn beschikbaar:
- Eén opslagaccount waarvoor geografisch redundante opslag is ingeschakeld, in de primaire regio
- De secundaire regio is opgelost. Deze optie is niet geschikt voor lokale toegang als er failover van het opslagaccount is.
- Twee afzonderlijke opslagaccounts, één in de primaire regio en één in de secundaire regio (aanbevolen)
- Gebruik zone-redundante opslag voor ten minste de primaire regio.
- Elke hostgroep in elke regio heeft lokale opslagtoegang tot MSIX-pakketten met lage latentie.
- Kopieer MSIX-pakketten tweemaal op beide locaties en registreer de pakketten tweemaal in beide hostgroepen. Wijs gebruikers twee keer toe aan de toepassingsgroepen.
FSLogix
Microsoft raadt u aan de volgende FSLogix-configuratie en -functies te gebruiken:
Als de inhoud van de profielcontainer afzonderlijke BCDR-beheer moet hebben en verschillende vereisten heeft in vergelijking met de Office-container, moet u deze splitsen.
- Office-container heeft alleen inhoud in de cache die opnieuw kan worden opgebouwd of opnieuw kan worden ingevuld vanuit de bron als er een noodgeval is. Met Office-container hoeft u mogelijk geen back-ups te bewaren, waardoor de kosten kunnen worden verlaagd.
- Wanneer u verschillende opslagaccounts gebruikt, kunt u alleen back-ups inschakelen op de profielcontainer. Of u moet verschillende instellingen hebben, zoals retentieperiode, gebruikte opslag, frequentie en RTO/RPO.
CloudCache is een FSLogix-onderdeel waarin u meerdere profielopslaglocaties kunt opgeven en asynchroon profielgegevens kunt repliceren, allemaal zonder afhankelijk te zijn van onderliggende opslagreplicatiemechanismen. Als de eerste opslaglocatie mislukt of niet bereikbaar is, voert Cloud Cache automatisch een failover uit om de secundaire locatie te gebruiken en wordt er effectief een tolerantielaag toegevoegd. Gebruik CloudCache om zowel Profiel- als Office-containers te repliceren tussen verschillende opslagaccounts in de primaire en secundaire regio's.
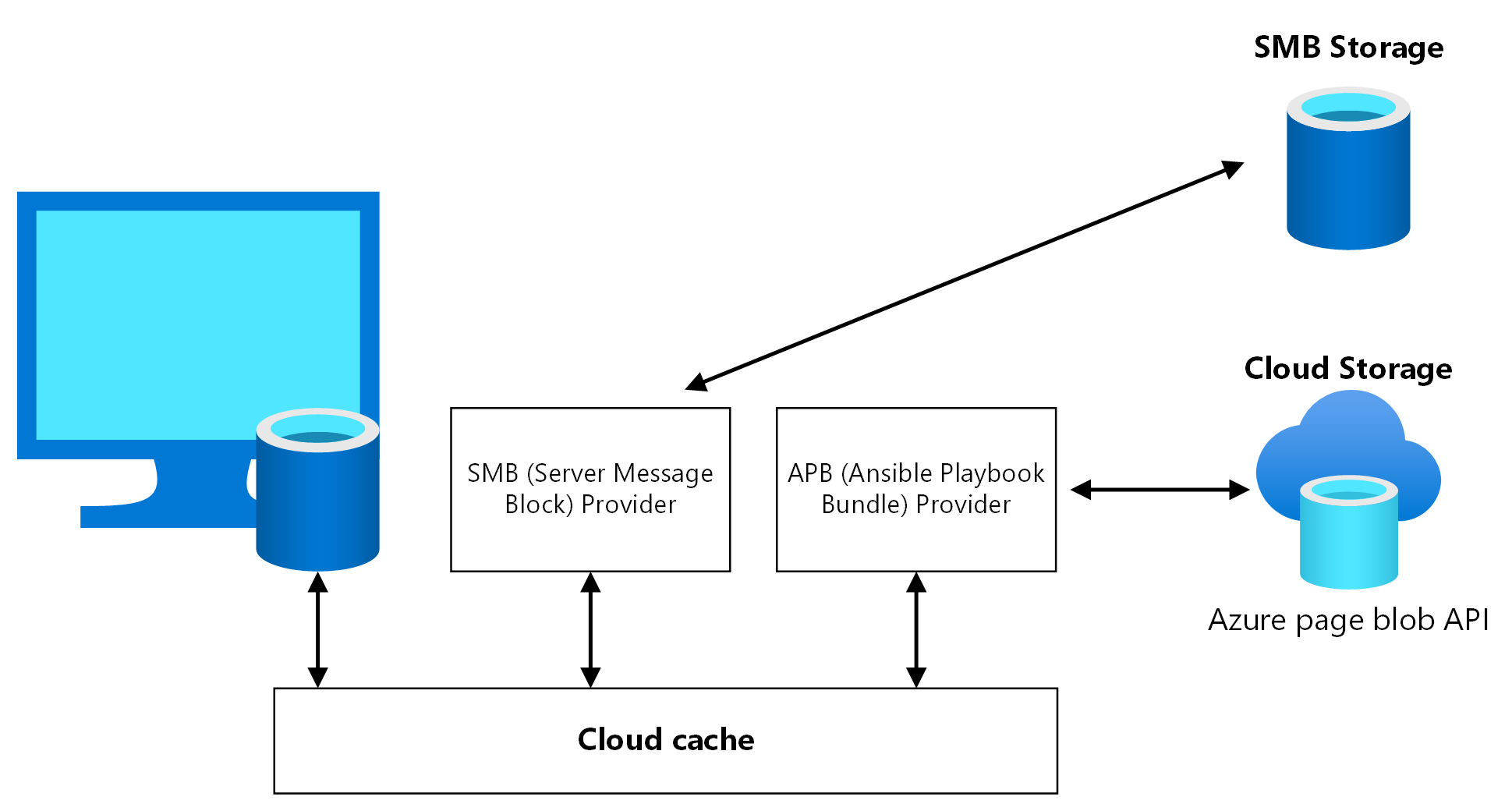
U moet Cloud Cache twee keer inschakelen in het vm-register van de sessiehost, eenmaal voor profielcontainer en één keer voor Office-container. Het is mogelijk om Cloud Cache voor Office-container niet in te schakelen, maar het niet inschakelen kan leiden tot een onjuiste uitlijning van gegevens tussen de primaire en de secundaire regio voor herstel na noodgevallen als er een failover en failback is. Test dit scenario zorgvuldig voordat u dit in productie gebruikt.
Cloudcache is compatibel met zowel profielsplitsing als instellingen per groep . per groep vereist zorgvuldig ontwerp en planning van Active Directory-groepen en lidmaatschappen. U moet ervoor zorgen dat elke gebruiker deel uitmaakt van precies één groep en die groep wordt gebruikt om toegang te verlenen tot hostgroepen.
De parameter CCDLocations die is opgegeven in het register voor de hostgroep in de secundaire regio voor herstel na noodgevallen, wordt teruggezet in vergelijking met de instellingen in de primaire regio. Zie Zelfstudie: Cloudcache configureren om profielcontainers of officecontainers om te leiden naar meerdere providers voor meer informatie.
Tip
Dit artikel is gericht op een specifiek scenario. Aanvullende scenario's worden beschreven in opties voor hoge beschikbaarheid voor FSLogix en bedrijfscontinuïteit en opties voor herstel na noodgevallen voor FSLogix.

In het volgende voorbeeld ziet u een cloudcacheconfiguratie en gerelateerde registersleutels:
Primaire regio = Europa - noord
Profielcontaineropslagaccount-URI = \northeustg1\profiles
- Registersleutelpad = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix-profielen >
- CCDLocations value = type=smb,connectionString=\northeustg1\profiles; type=smb,connectionString=\westeustg1\profiles
Notitie
Als u de FSLogix-sjablonen eerder hebt gedownload, kunt u dezelfde configuraties uitvoeren via de Active Directory-console groepsbeleidsbeheer. Raadpleeg de handleiding FsLogix-groepsbeleidssjabloonbestanden gebruiken voor meer informatie over het instellen van het groepsbeleidsobject voor FSLogix.
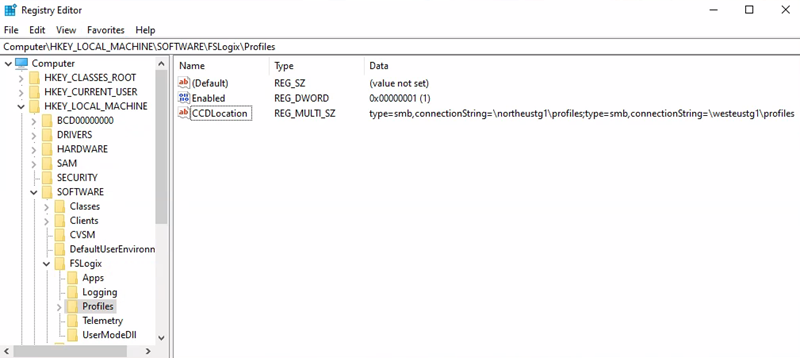
URI van Office-containeropslagaccount = \northeustg2\odcf
Registersleutelpad = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
CCDLocations value = type=smb,connectionString=\northeustg2\odfc; type=smb,connectionString=\westeustg2\odfc
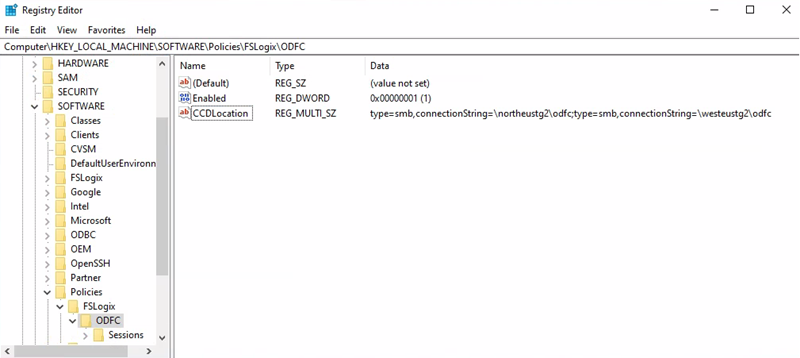


Notitie
In de bovenstaande schermafbeeldingen worden niet alle aanbevolen registersleutels voor FSLogix en Cloud Cache gerapporteerd voor beknoptheid en eenvoud. Zie FSLogix-configuratievoorbeelden voor meer informatie.
Secundaire regio = Europa - west
- Profielcontaineropslagaccount-URI = \westeustg1\profiles
- Registersleutelpad = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix-profielen >
- CCDLocations value = type=smb,connectionString=\westeustg1\profiles; type=smb,connectionString=\northeustg1\profiles
- URI van Office-containeropslagaccount = \westeustg2\odcf
- Registersleutelpad = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- CCDLocations value = type=smb,connectionString=\westeustg2\odfc; type=smb,connectionString=\northeustg2\odfc
Cloudcachereplicatie
De configuratie- en replicatiemechanismen van de cloudcache garanderen de replicatie van profielgegevens tussen verschillende regio's met minimale gegevensverlies. Aangezien hetzelfde gebruikersprofielbestand met slechts één proces kan worden geopend in de ReadWrite-modus, moet gelijktijdige toegang worden vermeden, zodat gebruikers geen verbinding met beide hostgroepen tegelijk mogen openen.

Een Visio-bestand van deze architectuur downloaden.
Gegevensstroom
Een Virtual Desktop-gebruiker start de Virtual Desktop-client en opent vervolgens een gepubliceerde bureaublad- of externe app-toepassing die is toegewezen aan de hostgroep van de primaire regio.
FSLogix haalt het gebruikersprofiel en Office-containers op en koppelt vervolgens de onderliggende opslag-VHD/X uit het opslagaccount dat zich in de primaire regio bevindt.
Tegelijkertijd initialiseert het cloudcacheonderdeel replicatie tussen de bestanden in de primaire regio en de bestanden in de secundaire regio. Voor dit proces verkrijgt Cloud Cache in de primaire regio een exclusieve lees-/schrijfvergrendeling voor deze bestanden.
Dezelfde Virtual Desktop-gebruiker wil nu een andere gepubliceerde toepassing starten die is toegewezen aan de hostgroep van de secundaire regio.
Het FSLogix-onderdeel dat wordt uitgevoerd op de sessiehost van virtual desktop in de secundaire regio, probeert de VHD/X-bestanden van het gebruikersprofiel te koppelen vanuit het lokale opslagaccount. De koppeling mislukt omdat deze bestanden zijn vergrendeld door het cloudcacheonderdeel dat wordt uitgevoerd op de host van de Virtual Desktop-sessie in de primaire regio.
In de standaardconfiguratie fslogix en cloudcache kan de gebruiker zich niet aanmelden en wordt een fout bijgehouden in de diagnostische logboeken van FSLogix, ERROR_LOCK_VIOLATION 33 (0x21).


Identiteit
Een van de belangrijkste afhankelijkheden voor Virtual Desktop is de beschikbaarheid van de gebruikersidentiteit. Als u toegang wilt krijgen tot volledige externe virtuele bureaubladen en externe apps van uw sessiehosts, moeten uw gebruikers zich kunnen verifiëren. Microsoft Entra ID is de gecentraliseerde cloudidentiteitsservice van Microsoft die deze mogelijkheid mogelijk maakt. Microsoft Entra-id wordt altijd gebruikt om gebruikers te verifiëren voor Virtual Desktop. Sessiehosts kunnen worden toegevoegd aan dezelfde Microsoft Entra-tenant of aan een Active Directory-domein met behulp van Active Directory-domein Services of Microsoft Entra Domain Services, zodat u een keuze hebt uit flexibele configuratieopties.
Microsoft Entra ID
- Het is een wereldwijde service voor meerdere regio's en flexibele services met hoge beschikbaarheid. Er is in deze context geen andere actie vereist als onderdeel van een BCDR-plan voor Virtual Desktop.
Active Directory Domain Services
- Als Active Directory-domein Services tolerant en maximaal beschikbaar zijn, zelfs als er een noodgeval in de hele regio is, moet u ten minste twee domeincontrollers (DC's) implementeren in de primaire Azure-regio. Deze domeincontrollers moeten zich in verschillende beschikbaarheidszones bevinden, indien mogelijk, en u moet ervoor zorgen dat de infrastructuur in de secundaire regio en uiteindelijk on-premises replicatie uitvoert. U moet ten minste één domeincontroller maken in de secundaire regio met globale catalogus en DNS-rollen. Zie AD DS implementeren in een virtueel Azure-netwerk voor meer informatie.
Microsoft Entra Connect
Als u Microsoft Entra ID gebruikt met Active Directory-domein Services en vervolgens Microsoft Entra Connect om gebruikersidentiteitsgegevens te synchroniseren tussen Active Directory-domein Services en Microsoft Entra ID, moet u rekening houden met de tolerantie en het herstel van deze service voor bescherming tegen een permanent noodgeval.
U kunt hoge beschikbaarheid en herstel na noodgevallen bieden door een tweede exemplaar van de service in de secundaire regio te installeren en de faseringsmodus in te schakelen.
Als er een herstelbewerking is, moet de beheerder het secundaire exemplaar promoveren door deze uit de faseringsmodus te halen. Ze moeten dezelfde procedure volgen als het plaatsen van een server in de faseringsmodus. Microsoft Entra Global Administrator-referenties zijn vereist om deze configuratie uit te voeren.
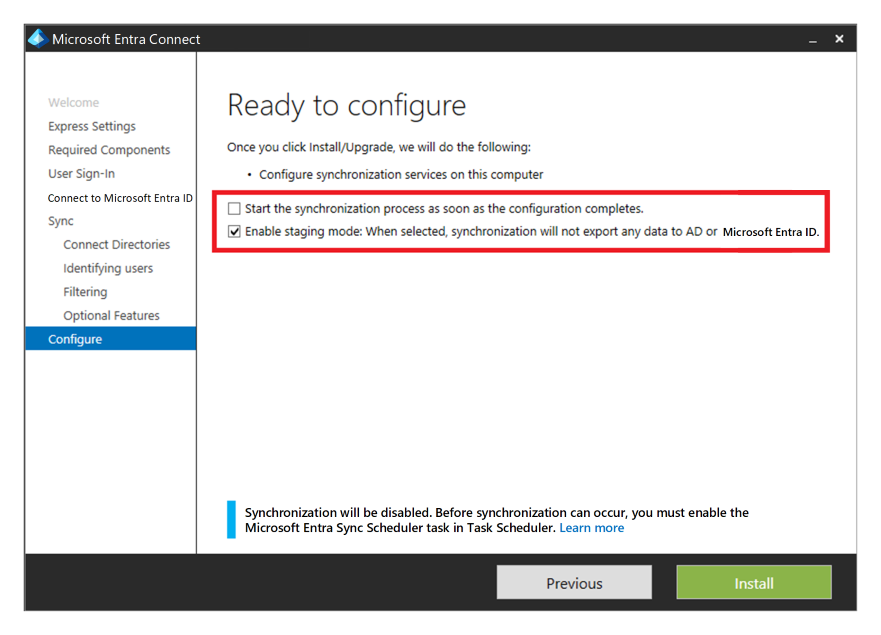
Microsoft Entra Domain Services.
- In sommige scenario's kunt u Microsoft Entra Domain Services gebruiken als alternatief voor Active Directory-domein Services.
- Het biedt hoge beschikbaarheid.
- Als herstel na een geo-noodgeval binnen het bereik van uw scenario valt, moet u een andere replica implementeren in de secundaire Azure-regio met behulp van een replicaset. U kunt deze functie ook gebruiken om hoge beschikbaarheid in de primaire regio te verhogen.
Architectuurdiagrammen
Persoonlijke hostgroep

Een Visio-bestand van deze architectuur downloaden.
Gegroepeerde hostgroep

Een Visio-bestand van deze architectuur downloaden.
Failover en failback
Scenario voor persoonlijke hostgroep
Notitie
Alleen het actief-passieve model wordt behandeld in deze sectie. Voor een actief-actief-actief hoeft geen failover- of beheerdersinval te worden uitgevoerd.
Failover en failback voor een persoonlijke hostgroep verschillen, omdat er geen cloudcache en externe opslag worden gebruikt voor profiel- en Office-containers. U kunt nog steeds FSLogix-technologie gebruiken om de gegevens op te slaan in een container vanaf de sessiehost. Er is geen secundaire hostgroep in de regio voor herstel na noodgevallen, dus u hoeft niet meer werkruimten en Virtual Desktop-resources te maken om te repliceren en uit te lijnen. U kunt Site Recovery gebruiken om vm's van sessiehosts te repliceren.
U kunt Site Recovery in verschillende scenario's gebruiken. Gebruik voor Virtual Desktop de architectuur voor herstel na noodgevallen van Azure naar Azure in Azure Site Recovery.
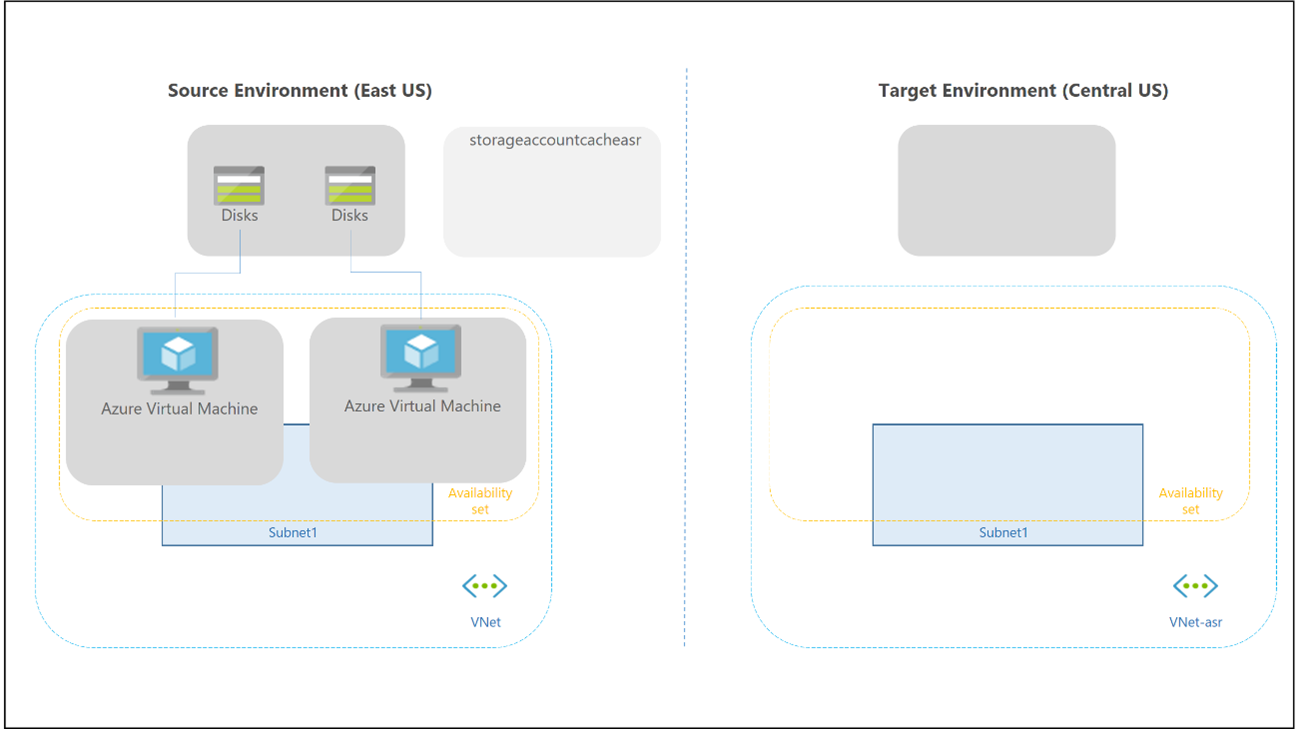
De volgende overwegingen en aanbevelingen zijn van toepassing:
- Site Recovery-failover is niet automatisch: een beheerder moet deze activeren met behulp van Azure Portal of Powershell/API.
- U kunt de volledige Site Recovery-configuratie en -bewerkingen scripten en automatiseren met behulp van PowerShell.
- Site Recovery heeft een gedeclareerde RTO binnen de SLA (Service Level Agreement). Meestal kan Site Recovery binnen enkele minuten een failover uitvoeren voor VM's.
- U kunt Site Recovery gebruiken met Azure Backup. Zie Ondersteuning voor het gebruik van Site Recovery met Azure Backup voor meer informatie.
- U moet Site Recovery op VM-niveau inschakelen, omdat er geen directe integratie is in de Virtual Desktop-portal. U moet ook failover en failback activeren op één VM-niveau.
- Site Recovery biedt testfailovermogelijkheden in een afzonderlijk subnet voor algemene Azure-VM's. Gebruik deze functie niet voor virtuele bureaublad-VM's, omdat u twee identieke Virtual Desktop-sessiehosts hebt die tegelijkertijd het servicebesturingsvlak aanroepen.
- Site Recovery onderhoudt tijdens de replicatie geen extensies voor virtuele machines. Als u aangepaste extensies inschakelt voor vm's van de Virtuele bureaublad-sessiehost, moet u de extensies na een failover of failback opnieuw inschakelen. De ingebouwde uitbreidingen van Virtual Desktop joindomain en Microsoft.PowerShell.DSC worden alleen gebruikt wanneer een sessiehost-VM wordt gemaakt. Het is veilig om ze te verliezen na een eerste failover.
- Controleer de ondersteuningsmatrix voor herstel na noodgevallen van Azure-VM's tussen Azure-regio's en controleer de vereisten, beperkingen en de compatibiliteitsmatrix voor het scenario voor herstel na noodgevallen van Azure-naar-Azure, met name de ondersteunde besturingssysteemversies.
- Wanneer u een failover uitvoert van een VIRTUELE machine van de ene regio naar de andere, wordt de VM gestart in de doelregio voor herstel na noodgevallen in een niet-beveiligde status. Failback is mogelijk, maar de gebruiker moet vm's in de secundaire regio opnieuw beveiligen en replicatie vervolgens weer inschakelen naar de primaire regio.
- Voer periodieke tests uit van failover- en failbackprocedures. Documenteer vervolgens een exacte lijst met stappen en herstelacties op basis van uw specifieke Virtual Desktop-omgeving.
Scenario met poolhostpool
Een van de gewenste kenmerken van een model voor actief-actief herstel na noodgevallen is dat er geen tussenkomst van de beheerder is vereist om de service te herstellen als er een storing is. Failoverprocedures moeten alleen nodig zijn in een actief-passieve architectuur.
In een actief-passief model moet de secundaire regio voor herstel na noodgevallen inactief zijn, waarbij minimale resources zijn geconfigureerd en actief zijn. De configuratie moet worden afgestemd op de primaire regio. Als er een failover is, worden alle gebruikers opnieuw toegewezen aan alle bureaublad- en toepassingsgroepen voor externe apps in de secundaire hostgroep voor herstel na noodgevallen.
Het is mogelijk om een actief-actief model en gedeeltelijke failover te hebben. Als de hostgroep alleen wordt gebruikt om bureaublad- en toepassingsgroepen te bieden, kunt u de gebruikers partitioneren in meerdere niet-overlapping Active Directory-groepen en de groep opnieuw toewijzen aan bureaublad- en toepassingsgroepen in de primaire of secundaire hostgroepen voor herstel na noodgevallen. Een gebruiker mag niet tegelijkertijd toegang hebben tot beide hostgroepen. Als er meerdere toepassingsgroepen en toepassingen zijn, kunnen de gebruikersgroepen die u gebruikt om gebruikers toe te wijzen overlappen. In dit geval is het moeilijk om een actief-actief strategie te implementeren. Wanneer een gebruiker een externe app start in de primaire hostgroep, wordt het gebruikersprofiel door FSLogix geladen op een sessiehost-VM. Als u hetzelfde probeert te doen op de secundaire hostgroep, kan dit een conflict veroorzaken op de onderliggende profielschijf.
Waarschuwing
Standaard verbieden fsLogix-registerinstellingen gelijktijdige toegang tot hetzelfde gebruikersprofiel vanuit meerdere sessies. In dit BCDR-scenario moet u dit gedrag niet wijzigen en een waarde van 0 laten staan voor het profiletype van de registersleutel.
Hier volgt de eerste situatie en configuratie-veronderstellingen:
- De hostgroepen in de primaire regio en secundaire regio's voor herstel na noodgevallen worden uitgelijnd tijdens de configuratie, met inbegrip van cloudcache.
- In de hostgroepen worden zowel DAG1-bureaublad- als APPG2- en APPG3-toepassingsgroepen voor externe apps aangeboden aan gebruikers.
- In de hostgroep in de primaire regio worden Active Directory-gebruikersgroepen GRP1, GRP2 en GRP3 gebruikt om gebruikers toe te wijzen aan DAG1, APPG2 en APPG3. Deze groepen kunnen overlappende gebruikerslidmaatschappen hebben, maar omdat het model hier gebruikmaakt van actief-passief met volledige failover, is dit geen probleem.
In de volgende stappen wordt beschreven wanneer een failover plaatsvindt, na een gepland of ongepland noodherstel.
- Verwijder in de primaire hostgroep gebruikerstoewijzingen door de groepen GRP1, GRP2 en GRP3 voor toepassingsgroepen DAG1, APPG2 en APPG3.
- Er is een geforceerde verbroken verbinding voor alle verbonden gebruikers uit de primaire hostgroep.
- In de secundaire hostgroep, waarbij dezelfde toepassingsgroepen zijn geconfigureerd, moet u gebruikerstoegang verlenen tot DAG1, APPG2 en APPG3 met behulp van groepen GRP1, GRP2 en GRP3.
- Controleer en pas de capaciteit van de hostgroep in de secundaire regio aan. Hier kunt u vertrouwen op een plan voor automatische schaalaanpassing om automatisch sessiehosts in te schakelen. U kunt ook handmatig de benodigde resources starten.
De failbackstappen en -stroom zijn vergelijkbaar en u kunt het hele proces meerdere keren uitvoeren. Cloudcache en het configureren van de opslagaccounts zorgt ervoor dat profiel- en Office-containergegevens worden gerepliceerd. Voordat u failback uitvoert, moet u ervoor zorgen dat de configuratie van de hostgroep en rekenresources worden hersteld. Als er gegevensverlies in de primaire regio is, repliceert Cloud Cache profiel- en Office-containergegevens uit de opslag in de secundaire regio als er gegevens verloren gaan.
Het is ook mogelijk om een testfailoverplan te implementeren met enkele configuratiewijzigingen, zonder dat dit van invloed is op de productieomgeving.
- Maak enkele nieuwe gebruikersaccounts in Active Directory voor productie.
- Maak een nieuwe Active Directory-groep met de naam GRP-TEST en wijs gebruikers toe.
- Wijs toegang toe aan DAG1, APPG2 en APPG3 met behulp van de GRP-TEST-groep.
- Geef gebruikers in de GROEP GRP-TEST instructies om toepassingen te testen.
- Test de failoverprocedure met behulp van de GROEP GRP-TEST om de toegang uit de primaire hostgroep te verwijderen en toegang te verlenen tot de secundaire noodherstelgroep.
Belangrijke aanbevelingen:
- Automatiseer het failoverproces met behulp van PowerShell, Azure CLI of een ander beschikbaar API of hulpprogramma.
- Test regelmatig de volledige failover- en failbackprocedure.
- Voer een regelmatige controle van de configuratie-uitlijning uit om ervoor te zorgen dat hostgroepen in de primaire en secundaire noodregio gesynchroniseerd zijn.
Backup
Een aanname in deze handleiding is dat er profielsplitsing en gegevensscheiding is tussen profielcontainers en Office-containers. FSLogix staat deze configuratie en het gebruik van afzonderlijke opslagaccounts toe. Eenmaal in afzonderlijke opslagaccounts kunt u verschillende back-upbeleidsregels gebruiken.
Als de inhoud voor ODFC-container alleen gegevens in de cache vertegenwoordigt die opnieuw kunnen worden opgebouwd vanuit een on-line gegevensarchief zoals Office 365, is het niet nodig om een back-up van gegevens te maken.
Als het nodig is om een back-up te maken van Office-containergegevens, kunt u een goedkopere opslag of een andere back-upfrequentie en retentieperiode gebruiken.
Voor een type persoonlijke hostgroep moet u de back-up uitvoeren op vm-niveau van de sessiehost. Deze methode is alleen van toepassing als de gegevens lokaal worden opgeslagen.
Als u OneDrive en bekende mapomleiding gebruikt, verdwijnt de vereiste om gegevens in de container op te slaan.
Notitie
OneDrive-back-up wordt niet meegenomen in dit artikel en scenario.
Tenzij er een andere vereiste is, moet back-up voor de opslag in de primaire regio voldoende zijn. Back-up van de omgeving voor herstel na noodgevallen wordt normaal gesproken niet gebruikt.
Gebruik Azure Backup voor Azure Files-share.
- Gebruik zone-redundante opslag als back-upopslag buiten de site of regio niet is vereist voor het tolerantietype van de kluis. Als deze back-ups vereist zijn, gebruikt u geografisch redundante opslag.
Azure NetApp Files biedt een eigen ingebouwde back-upoplossing.
- Zorg ervoor dat u de beschikbaarheid van de regiofuncties controleert, samen met vereisten en beperkingen.
De afzonderlijke opslagaccounts die worden gebruikt voor MSIX, moeten ook worden gedekt door een back-up als de opslagplaatsen van toepassingspakketten niet eenvoudig opnieuw kunnen worden opgebouwd.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Ben Martin Baur | Cloud Solution Architect
- Igor P partitiei | FastTrack for Azure (FTA) Principal Engineer
Andere Inzenders:
- Nelson Del Villar | Cloud Solution Architect, Azure Core Infrastructure
- Jason Martinez | Technische schrijver
Volgende stappen
- Plan voor herstel na noodgevallen van Virtual Desktop
- BCDR voor Virtual Desktop - Cloud Adoption Framework
- Cloudcache voor het maken van tolerantie en beschikbaarheid