Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Aanbeveling
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u de Copy-activiteit in Azure Data Factory- en Azure Synapse-pijplijnen gebruikt om gegevens van en naar Snowflake te kopiëren en Gegevensstroom te gebruiken om gegevens in Snowflake te transformeren. Zie het inleidende artikel voor Data Factory of Azure Synapse Analytics voor meer informatie.
Belangrijk
De Snowflake V2-connector biedt verbeterde systeemeigen Ondersteuning voor Snowflake. Als u de Snowflake V1-connector in uw oplossing gebruikt, wordt u aangeraden uw Snowflake-connector vóór 30 juni 2025 te upgraden. Raadpleeg deze sectie voor meer informatie over het verschil tussen V2 en V1.
Ondersteunde mogelijkheden
Deze Snowflake-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/afvoer) | (1) (2) |
| Gegevensstroom toewijzen (bron/bestemming) | (1) |
| Zoekactiviteit | (1) (2) |
| Scriptactiviteit (versie 1.1 (preview) toepassen wanneer u de scriptparameter gebruikt) | (1) (2) |
(1) Azure integratie-runtime (2) Zelf-gehoste integratie-runtime
Voor de Copy-activiteit ondersteunt deze Snowflake-connector de volgende functies:
- Kopieer gegevens uit Snowflake met behulp van het COPY into [location]-commando van Snowflake om de beste prestaties te bereiken.
- Kopieer gegevens naar Snowflake die gebruikmaken van Snowflake's COPY into [table]-opdracht om de beste prestaties te bereiken. Het biedt ondersteuning voor Snowflake in Azure.
- Als een proxy is vereist om vanuit een zelf-hostende Integration Runtime verbinding te maken met Snowflake, moet u de omgevingsvariabelen configureren voor HTTP_PROXY en HTTPS_PROXY op de Integration Runtime-host.
Vereisten
Als uw gegevensarchief zich in een on-premises netwerk, een virtueel Azure-netwerk of een virtuele particuliere cloud van Amazon bevindt, moet u een zelf-hostende Integration Runtime configureren om er verbinding mee te maken. Zorg ervoor dat u de IP-adressen toevoegt die de zelf-hostende Integration Runtime gebruikt voor de lijst met toegestane adressen.
Als uw gegevensarchief een beheerde cloudgegevensservice is, kunt u De Azure Integration Runtime gebruiken. Als de toegang is beperkt tot IP-adressen die zijn goedgekeurd in de firewallregels, kunt u IP-adressen van Azure Integration Runtime toevoegen aan de lijst met toegestane adressen.
Het Snowflake-account dat wordt gebruikt voor bron of sink, moet de benodigde USAGE toegang hebben tot de database en lees-/schrijftoegang voor het schema en de tabellen/weergaven eronder. Daarnaast moet het ook CREATE STAGE onderdeel van het schema zijn om de Externe fase te kunnen maken met SAS URI.
De volgende waarden voor accounteigenschappen moeten worden ingesteld
| Eigendom | Beschrijving | Vereist | Standaard |
|---|---|---|---|
| OPSLAGINTEGRATIE_VEREISD_VOOR_AANMAKEN_VAN_STAGE | Hiermee specificeert u of een opslagintegratieobject vereist is als cloudauthorisatie bij het creëren van een genaamde externe fase (met CREATE STAGE) om toegang te krijgen tot een opslaglocatie in de privécloud. | ONWAAR | ONWAAR |
| OPSLAGINTEGRATIE VEREIST VOOR FASEOPERATIE | Hiermee geeft u op of u een benoemde externe fase wilt gebruiken die verwijst naar een opslagintegratieobject als cloudreferenties bij het laden van gegevens uit of het verwijderen van gegevens naar een opslaglocatie in de privécloud. | ONWAAR | ONWAAR |
Zie Strategieën voor gegevenstoegang voor meer informatie over de netwerkbeveiligingsmechanismen en -opties die door Data Factory worden ondersteund.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde service maken voor Snowflake met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken voor Snowflake in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Snowflake en selecteer de Snowflake-connector.

Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
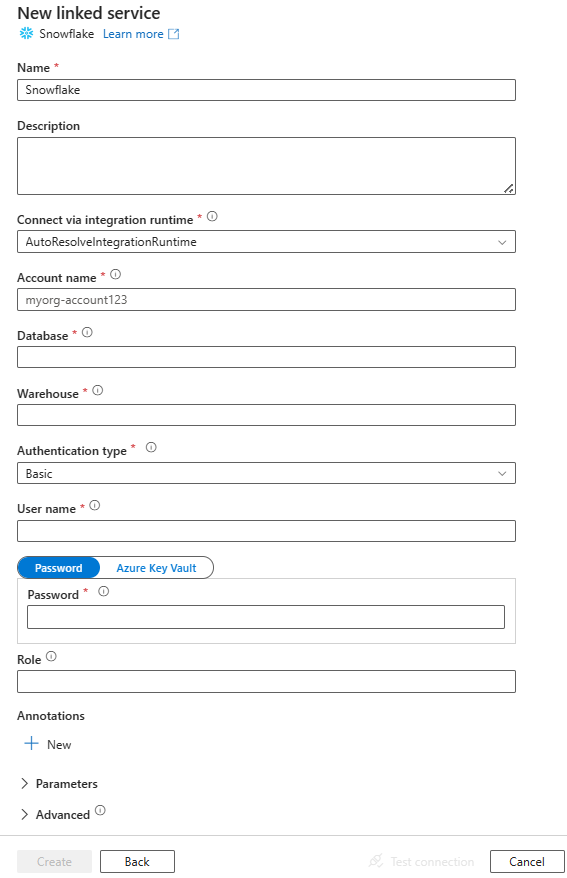
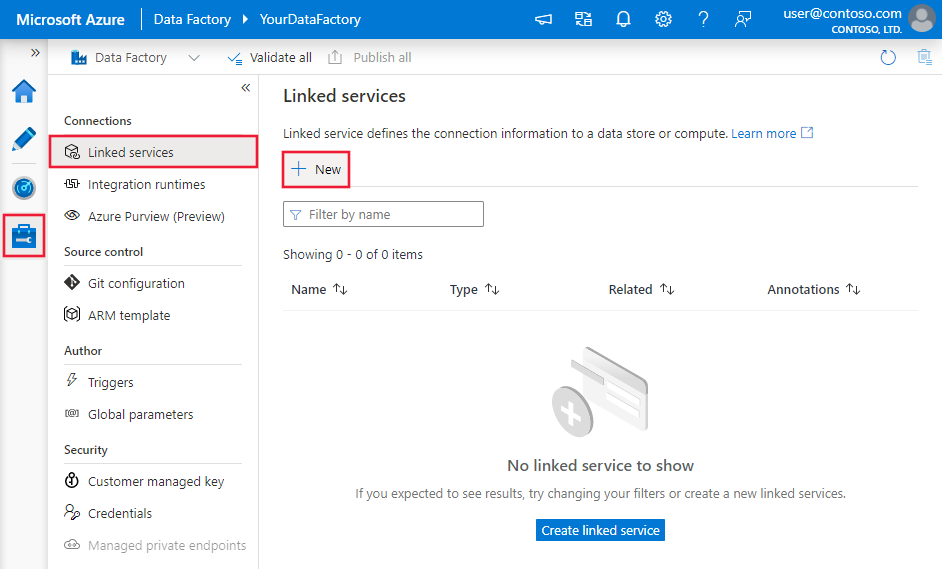
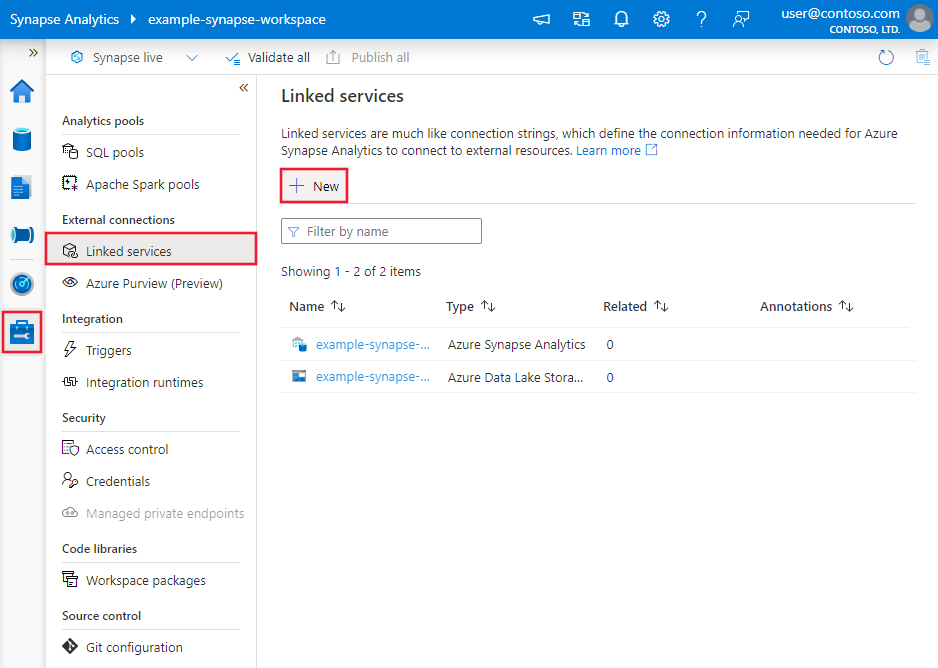
Details van de configuratie van de connector
De volgende secties bevatten details over eigenschappen waarmee entiteiten worden gedefinieerd die specifiek zijn voor een Snowflake-connector.
Eigenschappen van gekoppelde service
Deze algemene eigenschappen worden ondersteund voor de gekoppelde Snowflake-service:
| Eigendom | Beschrijving | Vereist |
|---|---|---|
| soort | De eigenschap type moet worden ingesteld op SnowflakeV2. | Ja |
| Versie | De versie die je opgeeft. U kunt het beste upgraden naar de nieuwste versie om te profiteren van de nieuwste verbeteringen. | Ja voor versie 1.1 (preview) |
| accountIdentifier | De naam van het account samen met de naam van de organisatie. Bijvoorbeeld myorg-account123. | Ja |
| gegevensbank | De standaarddatabase die wordt gebruikt voor de sessie nadat u verbinding hebt gemaakt. | Ja |
| magazijn | Het standaard virtuele magazijn dat wordt gebruikt voor de sessie nadat u verbinding hebt gemaakt. | Ja |
| authenticatietype | Type verificatie dat wordt gebruikt om verbinding te maken met de Snowflake-service. Toegestane waarden zijn: Basic (Standaard) en KeyPair. Raadpleeg de bijbehorende secties hieronder over respectievelijk meer eigenschappen en voorbeelden. | Nee |
| rol | De standaardbeveiligingsrol die wordt gebruikt voor de sessie nadat u verbinding hebt gemaakt. | Nee |
| gastheer | De hostnaam van het Snowflake-account. Voorbeeld: contoso.snowflakecomputing.com.
.cn wordt ook ondersteund. |
Nee |
| connectVia | De integratieruntime die wordt gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een privénetwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Deze Snowflake-connector ondersteunt de volgende verificatietypen. Zie de bijbehorende secties voor meer informatie.
Basisverificatie
Als u basisverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigendom | Beschrijving | Vereist |
|---|---|---|
| Gebruiker | Aanmeldingsnaam voor de Snowflake-gebruiker. | Ja |
| wachtwoord | Het wachtwoord voor de Snowflake-gebruiker. Markeer dit veld als een SecureString-type om het veilig op te slaan. U kunt ook verwijzen naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
Voorbeeld:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Wachtwoord in Azure Key Vault:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verificatie van sleutelpaar
Als u sleutelpaarverificatie wilt gebruiken, moet u een verificatiegebruiker voor sleutelpaar configureren en maken in Snowflake door te verwijzen naar sleutelpaarverificatie en sleutelpaarrotatie. Noteer daarna de persoonlijke sleutel en de wachtwoordzin (optioneel), die u gebruikt om de gekoppelde service te definiëren.
Geef naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigendom | Beschrijving | Vereist |
|---|---|---|
| Gebruiker | Aanmeldingsnaam voor de Snowflake-gebruiker. | Ja |
| privésleutel | De persoonlijke sleutel die wordt gebruikt voor de verificatie van het sleutelpaar. Om ervoor te zorgen dat de persoonlijke sleutel geldig is wanneer deze wordt verzonden naar Azure Data Factory en rekening houdend met het feit dat het privateKey-bestand newlinetekens (\n) bevat, is het essentieel om de privateKey-inhoud correct op te maken in de letterlijke vorm van de tekenreeks. Dit proces omvat het expliciet toevoegen van \n aan elke nieuwe regel. |
Ja |
| privé-sleutelwachtwoord | De wachtwoordzin die wordt gebruikt voor het ontsleutelen van de persoonlijke sleutel, als deze is versleuteld. | Nee |
Voorbeeld:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Notitie
Voor het in kaart brengen van gegevensstromen raden we aan een nieuwe RSA-privésleutel te genereren met behulp van de PKCS#8-standaard in PEM-indeling (.p8-bestand).
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets .
De volgende eigenschappen worden ondersteund voor de Snowflake-gegevensset.
| Eigendom | Beschrijving | Vereist |
|---|---|---|
| soort | De typeeigenschap van de gegevensset moet worden ingesteld op SnowflakeV2Table. | Ja |
| overzicht | Naam van het schema. Houd er rekening mee dat de schemanaam hoofdlettergevoelig is. | Nee voor bron, ja voor sink |
| tafel | Naam van de tabel/weergave. Let op: de tabelnaam is hoofdlettergevoelig. | Nee voor bron, ja voor sink |
Voorbeeld:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Snowflake-bron en -sink.
Snowflake als bron
Snowflake-connector maakt gebruik van de opdracht COPY naar [location] van Snowflake om de beste prestaties te bereiken.
Als het gegevensarchief en de indeling van de sink door de Snowflake COPY-opdracht worden ondersteund, kunt u de kopieeractiviteit gebruiken om rechtstreeks vanuit Snowflake naar de sink te kopiëren. Zie Direct copy from Snowflake voor meer informatie. Gebruik in plaats daarvan de ingebouwde stapsgewijze kopie uit Snowflake.
Als u gegevens uit Snowflake wilt kopiëren, worden de volgende eigenschappen ondersteund in de kopieeractiviteit sectie bron.
| Eigendom | Beschrijving | Vereist |
|---|---|---|
| soort | De typeeigenschap van de Copy-activiteit bron moet worden ingesteld op SnowflakeV2Source. | Ja |
| zoekopdracht | Hiermee geeft u de SQL-query op voor het lezen van gegevens uit Snowflake. Als de namen van het schema, de tabel en de kolommen kleine letters bevatten, noemt u de object-id in de query, bijvoorbeeld select * from "schema"."myTable".Het uitvoeren van een opgeslagen procedure wordt niet ondersteund. |
Nee |
| exportinstellingen | Geavanceerde instellingen die worden gebruikt om gegevens op te halen uit Snowflake. U kunt de opties configureren die worden ondersteund door het COPY-commando dat de service doorgeeft wanneer u de instructie aanroept. | Ja |
Onder exportSettings: |
||
| soort | Het type exportopdracht, ingesteld op SnowflakeExportCopyCommand. | Ja |
| opslagintegratie | Geef de naam op van uw opslagintegratie die u in Snowflake hebt gemaakt. Zie Een Snowflake-opslagintegratie configureren voor de vereiste stappen voor het gebruik van de opslagintegratie. | Nee |
| aanvullende kopieeropties | Extra kopieeropties, aangeboden als een woordenlijst van sleutel-waardeparen. Voorbeelden: MAX_FILE_SIZE, OVERWRITE. Zie Snowflake Copy Options voor meer informatie. | Nee |
| aanvullende opmaakopties | Aanvullende bestandsindelingsopties die worden aangeboden aan de opdracht COPY als een woordenboek van sleutel-waardeparen. Voorbeelden: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT, NULL_IF. Voor meer informatie, zie Opties voor het Snowflake-indelingstype. Wanneer u NULL_IF gebruikt, wordt de NULL-waarde in Snowflake geconverteerd naar de opgegeven waarde (die tussen aanhalingstekens moet staan) bij het opslaan in het tekstbestand met scheidingstekens in de faseringsopslag. Deze opgegeven waarde wordt behandeld als NULL bij het lezen van het faseringsbestand naar de sinkopslag. De standaardwaarde is 'NULL'. |
Nee |
Notitie
Zorg ervoor dat u gemachtigd bent om de volgende opdracht uit te voeren en toegang te krijgen tot het schema INFORMATION_SCHEMA en de tabelKOLOMMEN.
COPY INTO <location>
Directe kopie van Snowflake
Als uw sinkgegevensarchief en -indeling voldoen aan de criteria die in deze sectie worden beschreven, kunt u de Copy-activiteit gebruiken om rechtstreeks vanuit Snowflake naar sink te kopiëren. De service controleert de instellingen en laat de Copy-activiteit mislukken als niet aan het volgende criterium wordt voldaan.
Wanneer u
storageIntegrationin de bron opgeeftDe sink-gegevensopslag is de Azure Blob Storage waarnaar u in de externe stage in Snowflake hebt verwezen. U moet de volgende stappen uitvoeren voordat u gegevens kopieert:
Maak een gekoppelde Azure Blob Storage-service voor de sink Azure Blob Storage met ondersteunde verificatietypen.
Ken ten minste de rol Storage Blob Data Bijdrager toe aan de Snowflake-service-principal in de doellocatie Azure Blob Storage Access Control (IAM).
Wanneer u
storageIntegrationniet specificeert in de bron:De gekoppelde doelservice is Azure Blob-opslag met Shared Access Signature-authenticatie. Als u gegevens rechtstreeks naar Azure Data Lake Storage Gen2 wilt kopiëren in de volgende ondersteunde indeling, kunt u een gekoppelde Azure Blob Storage-service met SAS-verificatie maken voor uw Azure Data Lake Storage Gen2-account om gefaseerde kopie uit Snowflake te voorkomen.
De sinkgegevensindeling is van Parquet, gescheiden tekst of JSON met de volgende configuraties:
- Voor het Parquet-formaat is de compressiecodec Geen compressie, Snappy of Lzo.
- Voor tekst met scheidingstekens :
-
rowDelimiteris \r\n of een willekeurig teken. -
compressionkan geen compressie, gzip, bzip2 of deflate zijn. -
encodingNameblijft standaard of wordt ingesteld op utf-8. -
quoteCharis dubbele aanhalingstekens, enkele aanhalingstekens, of lege tekenreeks (geen aanhalingsteken).
-
- Voor JSON-indeling ondersteunt direct kopiëren alleen het geval waarin de Snowflake-brontabel of het queryresultaat slechts één kolom heeft en het gegevenstype van deze kolom VARIANT, OBJECT of ARRAY is.
-
compressionkan geen compressie, gzip, bzip2 of deflate zijn. -
encodingNameblijft standaard of wordt ingesteld op utf-8. -
filePatternin de sink voor kopieeractiviteiten is standaard ingesteld of ingesteld op SetOfObjects.
-
In bron
additionalColumnsvan kopieeractiviteit is niet opgegeven.Kolomtoewijzing is niet opgegeven.
Voorbeeld:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gefaseerde kopie van Snowflake
Wanneer uw sinkgegevensarchief of -indeling niet systeemeigen compatibel is met de opdracht Snowflake COPY, zoals aangegeven in de laatste sectie, moet u de ingebouwde gefaseerde kopie inschakelen met behulp van een tussentijdse Azure Blob Storage-instantie. De functie voor gefaseerde kopie biedt u ook een betere doorvoer. De service exporteert gegevens uit Snowflake naar faseringsopslag, kopieert de gegevens naar sink en schoont ten slotte uw tijdelijke gegevens op uit de faseringsopslag. Zie Gefaseerde kopie voor meer informatie over het kopiëren van gegevens met behulp van fasering.
Als u deze functie wilt gebruiken, maakt u een gekoppelde Azure Blob Storage-service die verwijst naar het Azure-opslagaccount als tijdelijke fasering. Geef vervolgens de enableStaging en stagingSettings eigenschappen op in de Copy-activiteit.
Wanneer u in de bron
storageIntegrationopgeeft, moet Azure Blob Storage voor tijdelijke opslag de tijdelijke opslag zijn waarnaar u in de externe fase in Snowflake hebt verwezen. Zorg ervoor dat u een gekoppelde Azure Blob Storage-service maakt met elke ondersteunde verificatie wanneer u de Azure Integration Runtime gebruikt, of met anonieme verificatie, accountsleutel, gedeelde toegangshandtekening of service-principal-verificatie wanneer u de zelf-gehoste Integration Runtime gebruikt. Bovendien moet u ten minste de rol Inzender voor opslagblobgegevens toekennen aan de Snowflake-service-principal in de staging Azure Blob Storage Access Control (IAM).Wanneer u
storageIntegrationniet opgeeft in de bron, moet de gekoppelde Azure Blob Storage-service gebruikmaken van gedeelde toegangssignatuur-verificatie, zoals vereist door het Snowflake COPY-commando. Zorg ervoor dat u de juiste toegang verleent aan Snowflake in de stagingomgeving van Azure Blob Storage. Zie dit artikel voor meer informatie.
Voorbeeld:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Wanneer u een gefaseerde kopie uitvoert vanuit Snowflake, is het van cruciaal belang om het gedrag van sinkkopie in te stellen op Bestanden samenvoegen. Deze instelling zorgt ervoor dat alle gepartitioneerde bestanden correct worden verwerkt en samengevoegd, waardoor het probleem wordt voorkomen dat alleen het laatste gepartitioneerde bestand wordt gekopieerd.
Voorbeeldconfiguratie
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Notitie
Als u het gedrag van de sinkkopie niet instelt om bestanden samen te voegen, kan dit ertoe leiden dat alleen het laatste gepartitioneerde bestand wordt gekopieerd.
Snowflake is de bestemming
De Snowflake-connector maakt gebruik van het COPY into [tabel] commando van Snowflake om optimale prestaties te bereiken. Het biedt ondersteuning voor het schrijven van gegevens naar Snowflake in Azure.
Als de brongegevensopslag en -indeling systeemeigen worden ondersteund door de opdracht Snowflake COPY, kunt u de Copy-activiteit gebruiken om rechtstreeks van de bron naar Snowflake te kopiëren. Zie Direct kopiëren naar Snowflake voor meer informatie. Gebruik anderszins de ingebouwde gefaseerde kopie naar Snowflake.
Als u gegevens naar Snowflake wilt kopiëren, worden de volgende eigenschappen ondersteund in de sectie Copy-activiteit sink.
| Eigendom | Beschrijving | Vereist |
|---|---|---|
| soort | De typeeigenschap van de Copy-activiteit sink, ingesteld op SnowflakeV2Sink. | Ja |
| preCopyScript | Geef in elke uitvoering een SQL-query op voor de Copy-activiteit die moet worden uitgevoerd voordat u gegevens in Snowflake schrijft. Gebruik deze eigenschap om de vooraf geladen gegevens op te schonen. | Nee |
| importinstellingen | Geavanceerde instellingen die worden gebruikt om gegevens naar Snowflake te schrijven. U kunt de opties configureren die worden ondersteund door het COPY-commando dat de service doorgeeft wanneer u de instructie aanroept. | Ja |
Onder importSettings: |
||
| soort | Het type importopdracht, ingesteld op SnowflakeImportCopyCommand. | Ja |
| opslagintegratie | Geef de naam op van uw opslagintegratie die u in Snowflake hebt gemaakt. Zie Een Snowflake-opslagintegratie configureren voor de vereiste stappen voor het gebruik van de opslagintegratie. | Nee |
| aanvullende kopieeropties | Extra kopieeropties, aangeboden als een woordenlijst van sleutel-waardeparen. Voorbeelden: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Zie Snowflake Copy Options voor meer informatie. | Nee |
| aanvullende opmaakopties | Aanvullende bestandsindelingsopties die beschikbaar zijn voor de opdracht COPY, opgegeven als een woordenlijst van sleutel-waardeparen. Voorbeelden: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Voor meer informatie, zie Opties voor het Snowflake-indelingstype. | Nee |
Notitie
Zorg ervoor dat u gemachtigd bent om de volgende opdracht uit te voeren en toegang te krijgen tot het schema INFORMATION_SCHEMA en de tabelKOLOMMEN.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Directe kopie naar Snowflake
Als uw brongegevensarchief en -indeling voldoen aan de criteria die in deze sectie worden beschreven, kunt u de Copy-activiteit gebruiken om rechtstreeks van bron naar Snowflake te kopiëren. De service controleert de instellingen en laat de Copy-activiteit mislukken als niet aan het volgende criterium wordt voldaan.
Wanneer u
storageIntegrationopgeeft in de ontvanger:Het brongegevensarchief is de Azure Blob Storage waarnaar u in de externe fase in Snowflake hebt verwezen. U moet de volgende stappen uitvoeren voordat u gegevens kopieert:
Maak een gekoppelde Azure Blob Storage-service voor de bron-Azure Blob Storage met ondersteunde verificatietypen.
Wijs ten minste de rol Storage Blob Data Reader toe aan de Snowflake-service-principal in de bron Azure Blob Storage Toegangsbeheer (IAM).
Wanneer u
storageIntegrationniet specificeert in de gegevensbron:De gekoppelde bronservice is Azure Blob Storage met handtekeningverificatie voor gedeelde toegang. Als u gegevens rechtstreeks vanuit Azure Data Lake Storage Gen2 wilt kopiëren in de volgende ondersteunde indeling, kunt u een gekoppelde Azure Blob Storage-service met SAS-verificatie maken voor uw Azure Data Lake Storage Gen2-account om gefaseerde kopie naar Snowflake te voorkomen.
De bron gegevens indeling is Parquet, gescheiden tekst of JSON met de volgende configuraties:
Voor het Parquet-formaat is er geen compressiecodec, of wordt Snappy gebruikt.
Voor gescheiden tekst-formaat:
-
rowDelimiteris \r\n of een willekeurig teken. Als het scheidingsteken voor rijen niet '\r\n' is,firstRowAsHeadermoet onwaar zijn en datskipLineCountniet is opgegeven. -
compressionkan geen compressie, gzip, bzip2 of deflate zijn. -
encodingNamewordt standaard gelaten of ingesteld op "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255". -
quoteCharis dubbele aanhalingstekens, enkele aanhalingstekens, of lege tekenreeks (geen aanhalingsteken).
-
Voor JSON-indeling ondersteunt direct kopiëren alleen het geval dat de sink Snowflake-tabel slechts één kolom heeft en het gegevenstype van deze kolom VARIANT, OBJECT of ARRAY is.
-
compressionkan geen compressie, gzip, bzip2 of deflate zijn. -
encodingNameblijft standaard of wordt ingesteld op utf-8. - Kolomtoewijzing is niet opgegeven.
-
In de bron van de Copy-activiteit:
-
additionalColumnsis niet opgegeven. - Als uw bron een map is, is
recursiveingesteld op waar. -
prefix,modifiedDateTimeStart,modifiedDateTimeEndenenablePartitionDiscoveryworden niet opgegeven.
-
Voorbeeld:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Gefaseerde kopie naar Snowflake
Wanneer uw brongegevensarchief of -indeling niet systeemeigen compatibel is met de opdracht Snowflake COPY, zoals vermeld in de laatste sectie, schakelt u de ingebouwde gefaseerde kopie in met behulp van een tussentijdse Instantie van Azure Blob Storage. De functie voor gefaseerde kopie biedt u ook een betere doorvoer. De service converteert de gegevens automatisch om te voldoen aan de vereisten voor gegevensindeling van Snowflake. Vervolgens wordt de opdracht COPY aangeroepen om gegevens in Snowflake te laden. Ten slotte worden uw tijdelijke gegevens uit de blobopslag verwijderd. Zie Gefaseerde kopie voor meer informatie over het kopiëren van gegevens met behulp van fasering.
Als u deze functie wilt gebruiken, maakt u een gekoppelde Azure Blob Storage-service die verwijst naar het Azure-opslagaccount als tijdelijke fasering. Geef vervolgens de enableStaging en stagingSettings eigenschappen op in de Copy-activiteit.
Wanneer u opgeeft
storageIntegrationin de sink, moet de tijdelijke fasering van Azure Blob Storage de tijdelijke fasering zijn die u in de externe fase in Snowflake hebt genoemd. Zorg ervoor dat u een gekoppelde Azure Blob Storage-service maakt met elke ondersteunde verificatie wanneer u de Azure Integration Runtime gebruikt, of met anonieme verificatie, accountsleutel, gedeelde toegangshandtekening of service-principal-verificatie wanneer u de zelf-gehoste Integration Runtime gebruikt. Bovendien verleent u ten minste de rol Storage Blob Data Reader aan de Snowflake-service-principal in de staging Azure Blob Storage Access Control (IAM).Wanneer u
storageIntegrationniet in de sink opgeeft, moet de gekoppelde service voor fasering van Azure Blob Storage gebruikmaken van shared access signature-verificatie, zoals vereist door het Snowflake COPY-commando.
Voorbeeld:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Eigenschappen van gegevensstroommapping
Wanneer u gegevens transformeert in de toewijzingsgegevensstroom, kunt u lezen van en schrijven naar tabellen in Snowflake. Voor meer informatie, zie de brontransformatie en sinktransformatie in gegevensstromen in mapping. U kunt ervoor kiezen om een Snowflake-gegevensset of een inlinegegevensset te gebruiken als bron- en sinktype.
Brontransformatie
De onderstaande tabel bevat de eigenschappen die worden ondersteund door de Snowflake-bron. U kunt deze eigenschappen bewerken op het tabblad Bronopties. De connector maakt gebruik van interne gegevensoverdracht van Snowflake.
| Naam | Beschrijving | Vereist | Toegestane waarden | Gegevensstroomscript-eigenschap |
|---|---|---|---|---|
| Tabel | Als u Tabel als invoer selecteert, haalt de gegevensstroom alle gegevens op uit de tabel die is opgegeven in de Snowflake-gegevensset of in de bronopties wanneer u inlinegegevensset gebruikt. | Nee | Snaar / Touwtje |
(alleen voor inline dataset) tabelnaam schemanaam |
| Vraag | Als u Query als invoer selecteert, voert u een query in om gegevens op te halen uit Snowflake. Met deze instelling wordt elke tabel die u in de gegevensset hebt gekozen, buiten werking gesteld. Als de namen van het schema, de tabel en de kolommen kleine letters bevatten, noemt u de object-id in de query, bijvoorbeeld select * from "schema"."myTable". |
Nee | Snaar / Touwtje | zoekopdracht |
| Incrementeel extraheren inschakelen (preview) | Gebruik deze optie om ADF te laten weten dat alleen rijen moeten worden verwerkt die zijn gewijzigd sinds de laatste keer dat de pijplijn is uitgevoerd. | Nee | Booleaans | enableCdc |
| Incrementele kolom | Wanneer u de functie incrementeel extraheren gebruikt, moet u de datum/tijd/numerieke kolom kiezen die u als watermerk in de brontabel wilt gebruiken. | Nee | Snaar / Touwtje | watermerkKolom |
| Snowflake-Wijzigingen bijhouden inschakelen (preview) | Met deze optie kan ADF gebruikmaken van de technologie voor het vastleggen van wijzigingen in Snowflake om alleen de deltagegevens te verwerken sinds de vorige pijplijnuitvoering. Met deze optie worden de deltagegevens automatisch geladen door invoeg-, bijwerk- en verwijderbewerkingen van rijen, zonder dat een specifieke incrementele kolom vereist is. | Nee | Booleaans | Schakel NativeCdc in |
| Nettowijzigingen | Wanneer u de functie wijzigingstracering in Snowflake gebruikt, kunt u deze optie gebruiken om ontdubbelde gewijzigde rijen of volledige wijzigingen op te halen. Gededupliceerde veranderde rijen tonen alleen de meest recente versies van de rijen die sinds een bepaald tijdstip zijn gewijzigd, terwijl uitgebreide wijzigingen alle versies van elke rij tonen die zijn gewijzigd, inclusief de versies die zijn verwijderd of bijgewerkt. Als u bijvoorbeeld een rij bijwerkt, ziet u een verwijderversie en een invoegversie in volledige wijzigingen, maar alleen de invoegversie in de ontdubbelde gewijzigde rijen. Afhankelijk van uw gebruiksscenario kunt u de optie kiezen die bij uw behoeften past. De standaardoptie is onwaar, wat uitgebreide wijzigingen betekent. | Nee | Booleaans | nettoveranderingen |
| Systeemkolommen opnemen | Wanneer u Snowflake-wijzigingsbeheer gebruikt, kunt u de optie systemColumns gebruiken om te bepalen of de kolommen van de metagegevensstroom die door Snowflake worden geleverd, worden opgenomen of uitgesloten in de uitvoer van het wijzigingsbeheer. SystemColumns is standaard ingesteld op true, wat betekent dat de kolommen van de metagegevensstroom worden opgenomen. U kunt systemColumns instellen op false als u ze wilt uitsluiten. | Nee | Booleaans | systeemkolommen |
| Beginnen met lezen vanaf het begin | Als u deze optie instelt met incrementeel extraheren en bijhouden van wijzigingen, wordt ADF geïnstrueerd om alle rijen bij de eerste uitvoering van een pijplijn te lezen, waarbij incrementeel extract is ingeschakeld. | Nee | Booleaans | startlaad overslaan |
Voorbeelden van Snowflake-broncode
Wanneer u de Snowflake-gegevensset als brontype gebruikt, is het bijbehorende gegevensstroomscript:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Als u een inline dataset gebruikt, is het bijbehorende dataflowscript:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Systeemeigen Wijzigingen bijhouden
Azure Data Factory ondersteunt nu een systeemeigen functie in Snowflake, ook wel wijzigingen bijhouden genoemd, waarbij wijzigingen in de vorm van logboeken worden bijgehouden. Met deze functie van snowflake kunnen we de wijzigingen in de gegevens in de loop van de tijd bijhouden, waardoor het nuttig is voor het laden en controleren van incrementele gegevens. Als u deze functie wilt gebruiken, maken we, wanneer u Change data capture inschakelt en de Snowflake Change Tracking selecteert, een Stream-object voor de brontabel die het bijhouden van wijzigingen in de bron-Snowflake-tabel mogelijk maakt. Vervolgens gebruiken we de component CHANGES in onze query om alleen de nieuwe of bijgewerkte gegevens op te halen uit de brontabel. Het is ook raadzaam om een pijplijn te plannen, zodat wijzigingen worden gebruikt binnen het interval van de gegevensretentietijd die is ingesteld voor de snowflake-brontabel, anders kan de gebruiker inconsistent gedrag zien in vastgelegde wijzigingen.
Afvoertransformatie
De onderstaande tabel bevat de eigenschappen die worden ondersteund door snowflake-sink. U kunt deze eigenschappen bewerken op het tabblad Instellingen . Wanneer u een inlinegegevensset gebruikt, ziet u aanvullende instellingen, die hetzelfde zijn als de eigenschappen die worden beschreven in de sectie eigenschappen van de gegevensset. De connector maakt gebruik van interne gegevensoverdracht van Snowflake.
| Naam | Beschrijving | Vereist | Toegestane waarden | Gegevensstroomscript-eigenschap |
|---|---|---|---|---|
| Update-methode | Geef op welke bewerkingen zijn toegestaan op uw Snowflake-bestemming. Als u rijen wilt bijwerken, toevoegen of verwijderen, is een Alter row-transformatie vereist om rijen voor deze acties te taggen. |
Ja |
true of false |
te verwijderen invoegbaar kan worden bijgewerkt voor upsert geschikt |
| Sleutelkolommen | Voor updates, upserts en verwijderingen moet je een sleutelkolom of -kolommen instellen om te bepalen welke rij wordt aangepast. | Nee | Array | sleutels |
| Tabelactie | Bepaalt of alle rijen uit de doeltabel opnieuw moeten worden gemaakt of verwijderd voordat ze worden geschreven. - Geen: Er wordt geen actie uitgevoerd met betrekking tot de tabel. - Opnieuw maken: de tabel wordt verwijderd en opnieuw gemaakt. Vereist als u dynamisch een nieuwe tabel maakt. - Trunceren: alle rijen uit de doelstellingstabel worden verwijderd. |
Nee |
true of false |
recreëren afkappen |
Voorbeelden van Snowflake-sink-scripts
Wanneer u de Snowflake-gegevensset als sinktype gebruikt, is het bijbehorende gegevensstroomscript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Als u een inline dataset gebruikt, is het bijbehorende dataflowscript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Optimalisatie van query pushdown
Door het niveau van logboekregistratie van pijplijnen in te stellen op Geen, sluiten we de overdracht van metrische gegevens voor tussenliggende transformatie uit, waardoor potentiële belemmeringen voor Spark-optimalisaties worden voorkomen en querypushdownoptimalisatie mogelijk wordt gemaakt door Snowflake. Deze pushdown-optimalisatie maakt aanzienlijke prestatieverbeteringen mogelijk voor grote Snowflake-tabellen met uitgebreide gegevenssets.
Notitie
Tijdelijke tabellen in Snowflake worden niet ondersteund, omdat ze lokaal zijn voor de sessie of gebruiker die ze maakt, waardoor ze niet toegankelijk zijn voor andere sessies en gevoelig zijn voor overschreven als gewone tabellen door Snowflake. Hoewel Snowflake tijdelijke tabellen biedt als alternatief, dat wereldwijd toegankelijk is, moeten ze handmatig worden verwijderd, wat in strijd is met het primaire doel van het gebruik van Temp-tabellen. Dit is om verwijderbewerkingen in het bronschema te voorkomen.
Toewijzing van gegevenstypen voor Snowflake V2
Wanneer u gegevens kopieert uit Snowflake, worden de volgende toewijzingen gebruikt van Snowflake-gegevenstypen naar tussentijdse gegevenstypen binnen de service. Zie Schema- en gegevenstypetoewijzingen voor meer informatie over hoe de kopieeractiviteit het bronschema en het gegevenstype toewijst aan de sink.
| Snowflake-gegevenstype | Tussentijdse servicegegevenstype |
|---|---|
| GETAL (p,0) | Decimaal |
| GETAL (p,s waar s > 0) | Decimaal |
| Drijven | Dubbel |
| VARCHAR | Snaar / Touwtje |
| VERKOLEN | Snaar / Touwtje |
| BINAIR | Byte[] |
| Booleaans | Booleaans |
| DATUM | Datum/tijd |
| TIJD | Tijdsduur |
| TIMESTAMP_LTZ | DatumTijdOffset |
| TIMESTAMP_NTZ | DatumTijdOffset |
| TIMESTAMP_TZ | DatumTijdOffset |
| Variant | Snaar / Touwtje |
| object | Snaar / Touwtje |
| ARRAY | Snaar / Touwtje |
Eigenschappen van opzoekactiviteit
Zie Lookup-activiteit voor meer informatie over de eigenschappen.
Levenscyclus en upgrade van Snowflake-connector
In de volgende tabel ziet u de releasefase en wijzigingslogboeken voor verschillende versies van de Snowflake-connector:
| Versie | Releasefase | Wijzigingslogboek |
|---|---|---|
| Snowflake V1 | Einde van de ondersteuning aangekondigd | / |
| Snowflake V2 (versie 1.0) | GA-versie beschikbaar | • Voeg ondersteuning toe voor verificatie van sleutelpaar. • Voeg ondersteuning toe aan storageIntegration in de Copy-activiteit. • De eigenschappen accountIdentifier, warehouse, database, schema en role worden gebruikt om een verbinding tot stand te brengen in plaats van de connectionstring eigenschap.• Voeg ondersteuning toe voor Decimal in Lookup-activiteit. Het getaltype, zoals gedefinieerd in Snowflake, wordt weergegeven als een tekenreeks in de opzoekactiviteit. Als u het naar een numeriek type wilt converteren in V2, kunt u de pijplijnparameter gebruiken met de int-functie of de float-functie. Bijvoorbeeld, int(activity('lookup').output.firstRow.VALUE)float(activity('lookup').output.firstRow.VALUE)• Het gegevenstype 'tijdstempel' in Snowflake wordt gelezen als 'DateTimeOffset' in de activiteiten Lookup en Script. Als u de datum/tijd-waarde nog steeds als parameter in uw pijplijn wilt gebruiken na een upgrade naar V2, kunt u het type DateTimeOffset converteren naar het type DateTime met behulp van de functie formatDateTime (aanbevolen) of een concat-functie. Bijvoorbeeld: formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE), concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') • GETAL (p,0) wordt gelezen als decimaal gegevenstype. • TIMESTAMP_LTZ, TIMESTAMP_NTZ en TIMESTAMP_TZ wordt gelezen als het gegevenstype DateTimeOffset. • Scriptparameters worden niet ondersteund in scriptactiviteit. Als alternatief kunt u dynamische expressies gebruiken voor scriptparameters. Zie Expressies en functies in Azure Data Factory en Azure Synapse Analytics voor meer informatie. • Uitvoering van meerdere SQL-instructies in scriptactiviteit wordt niet ondersteund. |
| Snowflake V2 (versie 1.1) | Preview-versie beschikbaar | • Voeg ondersteuning toe voor scriptparameters. • Voeg ondersteuning toe voor het uitvoeren van meerdere instructies in scriptactiviteit. |
De Snowflake-connector upgraden van V1 naar V2
Als u de Snowflake-connector wilt upgraden van V1 naar V2, kunt u een parallelle upgrade of een upgrade ter plaatse uitvoeren.
Upgrade naast elkaar
Voer de volgende stappen uit om een parallelle upgrade uit te voeren:
- Maak een nieuwe gekoppelde Snowflake-service en configureer deze door te verwijzen naar de eigenschappen van de gekoppelde V2-service.
- Maak een gegevensset op basis van de zojuist gemaakte gekoppelde Snowflake-service.
- Vervang de nieuwe gekoppelde service en gegevensset door de bestaande services in de pijplijnen die gericht zijn op de V1-objecten.
Upgraden op locatie
Als u een in-place upgrade wilt uitvoeren, moet u de bestaande nettolading van de gekoppelde service bewerken en de gegevensset bijwerken om de nieuwe gekoppelde service te gebruiken.
Werk het type van Snowflake bij naar SnowflakeV2.
Wijzig de payload van de gekoppelde service van het V1-formaat naar V2. U kunt elk veld invullen vanuit de gebruikersinterface nadat u het hierboven genoemde type hebt gewijzigd of de nettolading rechtstreeks bijwerken via de JSON-editor. Raadpleeg de sectie Eigenschappen van de gekoppelde service in dit artikel voor de ondersteunde verbindingseigenschappen. In de volgende voorbeelden ziet u de verschillen in nettolading voor de gekoppelde V1- en V2 Snowflake-services:
JSON-payload van de gekoppelde Snowflake V1-service:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }JSON-payload van de gekoppelde Snowflake V2-service:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Werk de gegevensset bij om de nieuwe gekoppelde service te gebruiken. U kunt een nieuwe gegevensset maken op basis van de zojuist gemaakte gekoppelde service of de typeeigenschap van een bestaande gegevensset bijwerken van SnowflakeTable naar SnowflakeV2Table.
Notitie
Wanneer u overschakelt naar gekoppelde services, wordt in de sjabloonparametersectie mogelijk alleen de database-eigenschappen weergegeven. U kunt dit oplossen door de parameters handmatig te bewerken. Daarna worden de verbindingsreeksen weergegeven in de sectie Sjabloonparameters overschrijven .
De Snowflake V2-connector upgraden van versie 1.0 naar versie 1.1 (preview)
Selecteer op de pagina Gekoppelde service bewerken 1.1 voor versie. Zie Eigenschappen van gekoppelde service voor meer informatie.
Gerelateerde inhoud
Zie ondersteunde gegevensarchieven en -indelingen voor een lijst met gegevensarchieven die door Copy-activiteit worden ondersteund als bronnen en sinks.