Zdalne debugowanie aplikacji Platformy Apache Spark za pomocą zestawu narzędzi Azure Toolkit for IntelliJ w usłudze HDInsight za pośrednictwem sieci VPN
Zalecamy zdalne debugowanie aplikacji platformy Apache Spark za pośrednictwem protokołu SSH. Aby uzyskać instrukcje, zobacz Zdalne debugowanie aplikacji platformy Apache Spark w klastrze usługi HDInsight przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ za pośrednictwem protokołu SSH.
Ten artykuł zawiera szczegółowe wskazówki dotyczące używania narzędzi HDInsight Tools w zestawie narzędzi Azure Toolkit for IntelliJ do przesyłania zadania Spark w klastrze spark usługi HDInsight, a następnie debugowania go zdalnie z komputera stacjonarnego. Aby wykonać te zadania, należy wykonać następujące ogólne kroki:
- Utwórz sieć wirtualną platformy Azure typu lokacja-lokacja lub punkt-lokacja. W krokach w tym dokumencie założono, że używasz sieci typu lokacja-lokacja.
- Utwórz klaster Spark w usłudze HDInsight, który jest częścią sieci wirtualnej typu lokacja-lokacja.
- Sprawdź łączność między węzłem głównym klastra a pulpitem.
- Utwórz aplikację Scala w środowisku IntelliJ IDEA, a następnie skonfiguruj ją na potrzeby zdalnego debugowania.
- Uruchom i debuguj aplikację.
Wymagania wstępne
- Subskrypcja platformy Azure. Aby uzyskać więcej informacji, zobacz Uzyskiwanie bezpłatnej wersji próbnej platformy Azure.
- Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
- Zestaw deweloperów Oracle Java. Można ją zainstalować z poziomu witryny internetowej Oracle.
- IntelliJ IDEA. W tym artykule jest używana wersja 2017.1. Można go zainstalować z witryny internetowej JetBrains.
- Narzędzia HDInsight Tools w zestawie narzędzi Azure Toolkit for IntelliJ. Narzędzia HDInsight dla środowiska IntelliJ są dostępne w ramach zestawu narzędzi Azure Toolkit for IntelliJ. Aby uzyskać instrukcje dotyczące sposobu instalowania zestawu narzędzi Azure Toolkit, zobacz Instalowanie zestawu narzędzi Azure Toolkit for IntelliJ.
- Zaloguj się do subskrypcji platformy Azure z poziomu środowiska IntelliJ IDEA. Postępuj zgodnie z instrukcjami w temacie Use Azure Toolkit for IntelliJ to create Apache Spark applications for an HDInsight cluster (Używanie zestawu narzędzi Azure Toolkit for IntelliJ do tworzenia aplikacji platformy Apache Spark dla klastra usługi HDInsight).
- Obejście wyjątku. Podczas uruchamiania aplikacji Spark Scala na potrzeby zdalnego debugowania na komputerze z systemem Windows może wystąpić wyjątek. Ten wyjątek został wyjaśniony w programie SPARK-2356 i występuje z powodu brakującego pliku WinUtils.exe w systemie Windows. Aby obejść ten błąd, należy pobrać Winutils.exe do lokalizacji, takiej jak C:\WinUtils\bin. Dodaj zmienną środowiskową HADOOP_HOME , a następnie ustaw wartość zmiennej na C\WinUtils.
Krok 1. Tworzenie sieci wirtualnej platformy Azure
Postępuj zgodnie z instrukcjami z poniższych linków, aby utworzyć sieć wirtualną platformy Azure, a następnie sprawdź łączność między komputerem stacjonarnym a siecią wirtualną:
- Tworzenie sieci wirtualnej z połączeniem sieci VPN typu lokacja-lokacja przy użyciu witryny Azure Portal
- Tworzenie sieci wirtualnej z połączeniem sieci VPN typu lokacja-lokacja przy użyciu programu PowerShell
- Konfigurowanie połączenia punkt-lokacja z siecią wirtualną przy użyciu programu PowerShell
Krok 2. Tworzenie klastra Spark w usłudze HDInsight
Zalecamy również utworzenie klastra Apache Spark w usłudze Azure HDInsight będącego częścią utworzonej sieci wirtualnej platformy Azure. Skorzystaj z informacji dostępnych w artykule Tworzenie klastrów opartych na systemie Linux w usłudze HDInsight. W ramach opcjonalnej konfiguracji wybierz sieć wirtualną platformy Azure utworzoną w poprzednim kroku.
Krok 3. Weryfikowanie łączności między węzłem głównym klastra a pulpitem
Pobierz adres IP węzła głównego. Otwórz interfejs użytkownika systemu Ambari dla klastra. W bloku klastra wybierz pozycję Pulpit nawigacyjny.
W interfejsie użytkownika systemu Ambari wybierz pozycję Hosty.

Zostanie wyświetlona lista węzłów głównych, węzłów procesu roboczego i węzłów dozorca. Węzły główne mają prefiks hn*. Wybierz pierwszy węzeł główny.
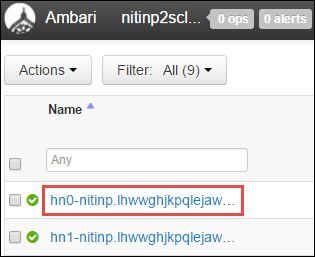
W okienku Podsumowanie w dolnej części otwieranej strony skopiuj adres IP węzła głównego i nazwę hosta.
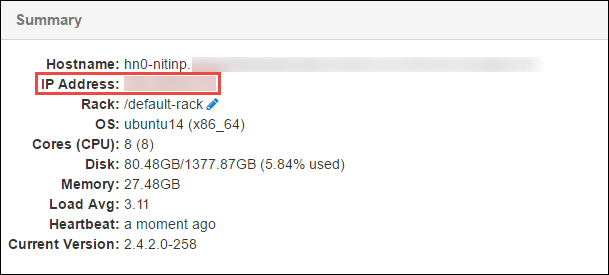
Dodaj adres IP i nazwę hosta węzła głównego do pliku hosts na komputerze, na którym chcesz uruchomić i zdalnie debugować zadanie platformy Spark. Dzięki temu można komunikować się z węzłem głównym przy użyciu adresu IP, a także nazwy hosta.
a. Otwórz plik Notatnik z podwyższonym poziomem uprawnień. W menu Plik wybierz pozycję Otwórz, a następnie znajdź lokalizację pliku hosts. Na komputerze z systemem Windows lokalizacja to C:\Windows\System32\Drivers\etc\hosts.
b. Dodaj następujące informacje do pliku hosts :
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netNa komputerze połączonym z siecią wirtualną platformy Azure, która jest używana przez klaster usługi HDInsight, sprawdź, czy możesz wysłać polecenie ping do węzłów głównych przy użyciu adresu IP, a także nazwy hosta.
Użyj protokołu SSH, aby nawiązać połączenie z węzłem głównym klastra, postępując zgodnie z instrukcjami w Połączenie z klastrem usługi HDInsight przy użyciu protokołu SSH. Z węzła głównego klastra wyślij polecenie ping na adres IP komputera stacjonarnego. Przetestuj łączność z obydwoma adresami IP przypisanymi do komputera:
- Jeden dla połączenia sieciowego
- Jeden dla sieci wirtualnej platformy Azure
Powtórz kroki dla innego węzła głównego.
Krok 4. Tworzenie aplikacji Apache Spark Scala przy użyciu narzędzi HDInsight Tools w zestawie narzędzi Azure Toolkit for IntelliJ i konfigurowanie jej na potrzeby zdalnego debugowania
Otwórz środowisko IntelliJ IDEA i utwórz nowy projekt. W oknie dialogowym Nowy projekt wykonaj następujące czynności:
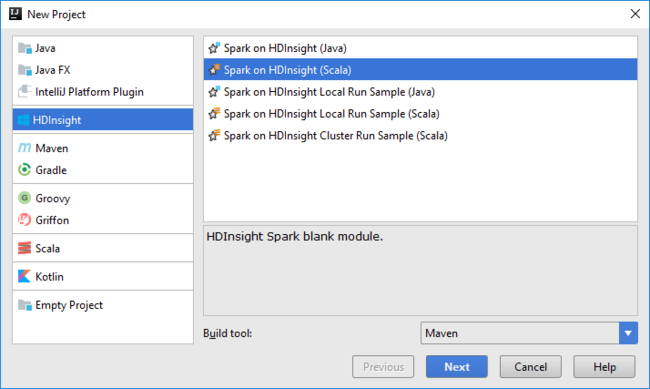
a. Wybierz pozycję HDInsight>Spark w usłudze HDInsight (Scala).
b. Wybierz Dalej.
W następnym oknie dialogowym Nowy projekt wykonaj następujące czynności, a następnie wybierz pozycję Zakończ:
Wprowadź nazwę i lokalizację projektu.
Z listy rozwijanej Zestaw SDK projektu wybierz pozycję Java 1.8 dla klastra Spark 2.x lub pozycję Java 1.7 dla klastra Spark 1.x.
Na liście rozwijanej Wersja platformy Spark kreator tworzenia projektu Scala integruje odpowiednią wersję zestawu Spark SDK i zestawu SCALA SDK. Jeśli wersja klastra Spark jest starsza niż 2.0, wybierz wartość Spark 1.x. W przeciwnym razie wybierz Spark2.x. W tym przykładzie używana jest wersja Spark 2.0.2 (Scala 2.11.8).
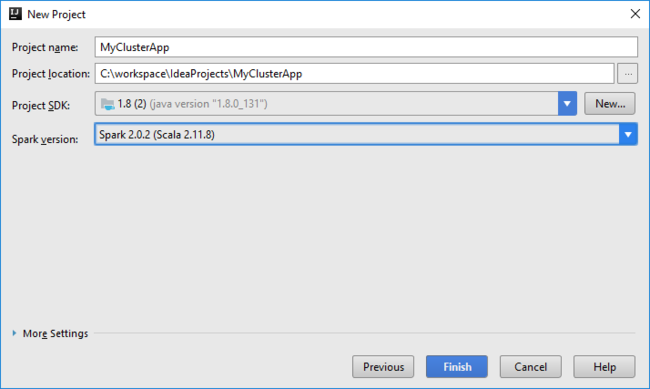
Projekt Spark automatycznie tworzy artefakt. Aby wyświetlić artefakt, wykonaj następujące czynności:
a. W menu File (Plik) wybierz pozycję Project Structure (Struktura projektu).
b. W oknie dialogowym Struktura projektu wybierz pozycję Artefakty, aby wyświetlić utworzony domyślny artefakt. Możesz również utworzyć własny artefakt, wybierając znak plus (+).
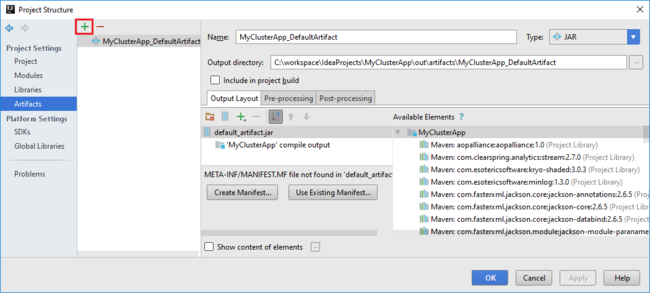
Dodaj biblioteki do projektu. Aby dodać bibliotekę, wykonaj następujące czynności:
a. Kliknij prawym przyciskiem myszy nazwę projektu w drzewie projektu, a następnie wybierz polecenie Otwórz moduł Ustawienia.
b. W oknie dialogowym Struktura projektu wybierz pozycję Biblioteki, wybierz symbol (+), a następnie wybierz pozycję Z narzędzia Maven.
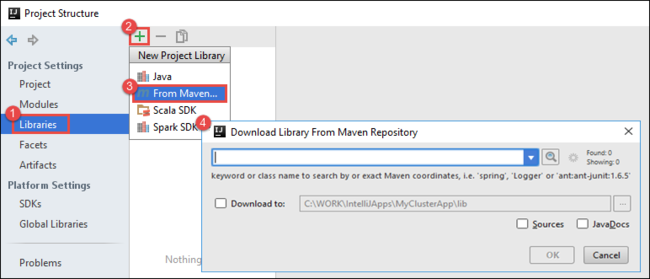
c. W oknie dialogowym Pobieranie biblioteki z repozytorium Maven wyszukaj i dodaj następujące biblioteki:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Skopiuj
yarn-site.xmlicore-site.xmlz węzła głównego klastra i dodaj je do projektu. Użyj następujących poleceń, aby skopiować pliki. Możesz użyć narzędzia Cygwin , aby uruchomić następującescppolecenia, aby skopiować pliki z węzłów głównych klastra:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Ponieważ dodaliśmy już adres IP węzła głównego klastra i nazwy hostów dla pliku hostów na pulpicie, możemy użyć
scppoleceń w następujący sposób:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Aby dodać te pliki do projektu, skopiuj je w folderze /src w drzewie projektu, na przykład
<your project directory>\src.Zaktualizuj plik,
core-site.xmlaby wprowadzić następujące zmiany:a. Zastąp zaszyfrowany klucz. Plik
core-site.xmlzawiera zaszyfrowany klucz do konta magazynu skojarzonego z klastrem. W pliku dodanymcore-site.xmldo projektu zastąp zaszyfrowany klucz rzeczywistym kluczem magazynu skojarzonym z domyślnym kontem magazynu. Aby uzyskać więcej informacji, zobacz Zarządzanie kluczami dostępu do konta magazynu.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Usuń następujące wpisy z pliku
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Zapisz plik.
Dodaj klasę główną dla aplikacji. W Eksploratorze projektów kliknij prawym przyciskiem myszy pozycję src, wskaż polecenie Nowy, a następnie wybierz pozycję Klasa Scala.
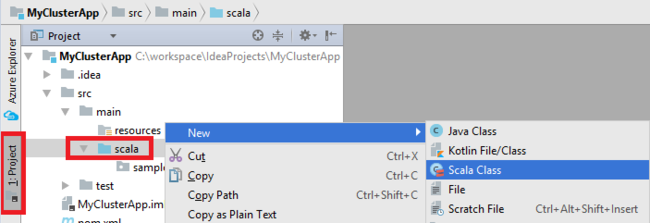
W oknie dialogowym Tworzenie nowej klasy Scala podaj nazwę, wybierz pozycję Obiekt w polu Rodzaj, a następnie wybierz przycisk OK.
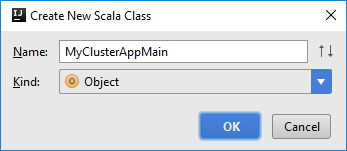
MyClusterAppMain.scalaW pliku wklej następujący kod. Ten kod tworzy kontekst platformy Spark i otwiera metodęexecuteJobzSparkSampleobiektu .import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Powtórz kroki 8 i 9, aby dodać nowy obiekt Scala o nazwie
*SparkSample. Do tej klasy należy dodać następujący kod. Ten kod odczytuje dane z HVAC.csv (dostępne we wszystkich klastrach Spark usługi HDInsight). Pobiera wiersze, które mają tylko jedną cyfrę w siódmej kolumnie w pliku CSV, a następnie zapisuje dane wyjściowe do /HVACOut w domyślnym kontenerze magazynu dla klastra.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Powtórz kroki 8 i 9, aby dodać nową klasę o nazwie
RemoteClusterDebugging. Ta klasa implementuje platformę testową Spark używaną do debugowania aplikacji. Dodaj następujący kod doRemoteClusterDebuggingklasy:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Należy pamiętać o kilku ważnych kwestiach:
- W przypadku
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")programu upewnij się, że plik JAR zestawu Spark jest dostępny w magazynie klastra w określonej ścieżce. - W polu
setJarsokreśl lokalizację, w której jest tworzony artefakt JAR. Zazwyczaj jest<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jarto .
- W przypadku
*RemoteClusterDebuggingW klasie kliknij prawym przyciskiemtestmyszy słowo kluczowe, a następnie wybierz polecenie Utwórz konfigurację RemoteClusterDebugging.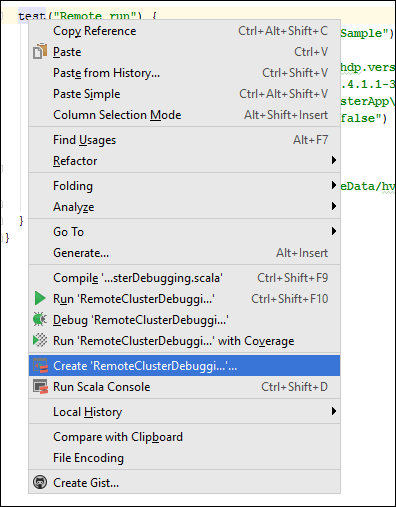
W oknie dialogowym Tworzenie konfiguracji remoteClusterDebugging podaj nazwę konfiguracji, a następnie wybierz pozycję Rodzaj testu jako nazwę testu. Pozostaw wszystkie pozostałe wartości jako ustawienia domyślne. Wybierz Zastosuj, a następnie wybierz OK.
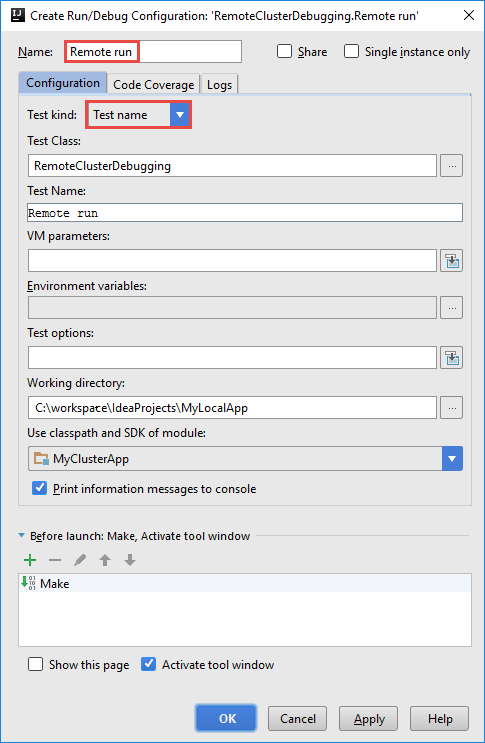
Na pasku menu powinien zostać wyświetlona lista rozwijana Konfiguracja uruchamiania zdalnego.

Krok 5. Uruchamianie aplikacji w trybie debugowania
W projekcie IntelliJ IDEA otwórz
SparkSample.scalai utwórz punkt przerwania obokval rdd1. W menu podręcznym Tworzenie punktu przerwania wybierz pozycję wiersz w funkcji executeJob.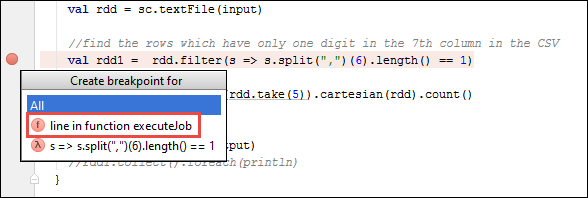
Aby uruchomić aplikację, wybierz przycisk Debuguj przebieg obok listy rozwijanej Konfiguracja uruchamiania zdalnego.

Gdy wykonanie programu osiągnie punkt przerwania, w dolnym okienku zostanie wyświetlona karta Debuger .
Aby dodać zegarek, wybierz ikonę (+).
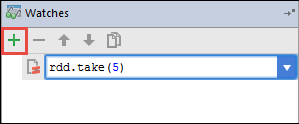
W tym przykładzie aplikacja złamała się przed utworzeniem zmiennej
rdd1. Korzystając z tego zegarka, możemy zobaczyć pięć pierwszych wierszy w zmiennejrdd. Wybierz Enter.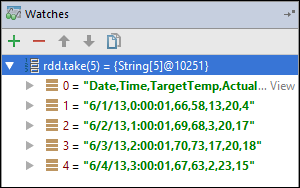
Na poprzedniej ilustracji widać, że w czasie wykonywania możesz wykonywać zapytania dotyczące terabajtów danych i debugować sposób postępu aplikacji. Na przykład w danych wyjściowych pokazanych na poprzedniej ilustracji widać, że pierwszy wiersz danych wyjściowych jest nagłówkiem. Na podstawie tych danych wyjściowych możesz zmodyfikować kod aplikacji, aby pominąć wiersz nagłówka, jeśli to konieczne.
Teraz możesz wybrać ikonę Wznów program , aby kontynuować uruchamianie aplikacji.
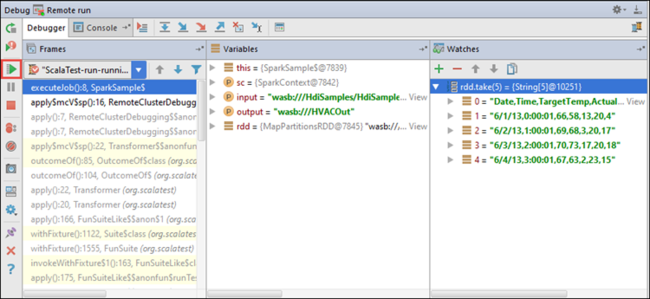
Jeśli aplikacja zakończy się pomyślnie, powinny zostać wyświetlone dane wyjściowe podobne do następujących:
Następne kroki
Scenariusze
- Platforma Apache Spark z usługą BI: wykonywanie interaktywnej analizy danych przy użyciu platformy Spark w usłudze HDInsight z narzędziami analizy biznesowej
- Platforma Apache Spark z maszyną Edukacja: używanie platformy Spark w usłudze HDInsight do analizowania temperatury budynku przy użyciu danych HVAC
- Platforma Apache Spark z Edukacja maszynowymi: przewidywanie wyników inspekcji żywności za pomocą platformy Spark w usłudze HDInsight
- Analiza dzienników witryn internetowych przy użyciu platformy Apache Spark w usłudze HDInsight
Tworzenie i uruchamianie aplikacji
- Tworzenie autonomicznych aplikacji przy użyciu języka Scala
- Zdalne uruchamianie zadań w klastrze Apache Spark przy użyciu programu Apache Livy
Narzędzia i rozszerzenia
- Tworzenie aplikacji Platformy Apache Spark dla klastra usługi HDInsight przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ
- Zdalne debugowanie aplikacji Platformy Apache Spark za pośrednictwem protokołu SSH za pomocą zestawu narzędzi Azure Toolkit for IntelliJ
- Tworzenie aplikacji platformy Apache Spark za pomocą narzędzi HDInsight Tools w zestawie narzędzi Azure Toolkit for Eclipse
- Używanie notesów Apache Zeppelin z klastrem Apache Spark w usłudze HDInsight
- Jądra dostępne dla notesu Jupyter w klastrze Apache Spark dla usługi HDInsight
- Używanie pakietów zewnętrznych z notesami Jupyter Notebook
- Instalacja oprogramowania Jupyter na komputerze i nawiązywanie połączenia z klastrem Spark w usłudze HDInsight
Zarządzanie zasobami
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla