Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Att migrera högpresterande Exadata-databaser till molnet blir allt viktigare för Microsoft-kunder. Programvarupaket för leveranskedjan ställer vanligtvis in ribban högt på grund av de intensiva kraven på lagrings-I/O med en blandad läs- och skrivarbetsbelastning som drivs av en enda beräkningsnod. Azure-infrastrukturen i kombination med Azure NetApp Files kan uppfylla behoven för den här mycket krävande arbetsbelastningen. Den här artikeln visar ett exempel på hur den här efterfrågan uppfylldes för en kund och hur Azure kan uppfylla kraven från dina kritiska Oracle-arbetsbelastningar.
Oracle-prestanda i företagsskala
När du utforskar de övre gränserna för prestanda är det viktigt att känna igen och minska eventuella begränsningar som felaktigt kan förvränga resultat. Om avsikten till exempel är att bevisa prestandafunktioner i ett lagringssystem bör klienten helst konfigureras så att processorn inte blir en mildrande faktor innan lagringsprestandagränserna uppnås. Därför började testningen med instanstypen E104ids_v5 eftersom den här virtuella datorn är utrustad inte bara med ett nätverksgränssnitt på 100 Gbit/s, utan med en lika stor utgående gräns (100 Gbit/s).
Testningen inträffade i två faser:
- Den första fasen fokuserade på testning med hjälp av Kevin Clossons nu branschstandardverktyg SLOB2 (Silly Little Oracle Benchmark) – version 2.5.4. Målet är att köra så mycket Oracle I/O som möjligt från en virtuell dator (VM) till flera Azure NetApp Files-volymer och sedan skala ut med fler databaser för att demonstrera linjär skalning.
- Efter att ha testat skalningsgränser, pivoterade våra tester till de billigare men nästan lika kapabla E96ds_v5 för en kundfas av testning med hjälp av en sann supply chain-programarbetsbelastning och verkliga data.
SLOB2-uppskalningsprestanda
I följande diagram avbildas prestandaprofilen för en enda E104ids_v5 virtuell Azure-dator som kör en enda Oracle 19c-databas mot åtta Azure NetApp Files-volymer med åtta lagringsslutpunkter. Volymerna är spridda över tre ASM-diskgrupper: data, logg och arkiv. Fem volymer allokerades till datadiskgruppen, två volymer till loggdiskgruppen och en volym till arkivdiskgruppen. Alla resultat som samlats in i den här artikeln samlades in med hjälp av Azure-produktionsregioner och azure-tjänster för aktiv produktion.
Om du vill distribuera Oracle på virtuella Azure-datorer med flera Azure NetApp Files-volymer på flera lagringsslutpunkter använder du programvolymgruppen för Oracle.
Arkitektur med en värd
Följande diagram visar arkitekturen som testningen slutfördes mot. Observera Oracle-databasen som är spridd över flera Azure NetApp Files-volymer och slutpunkter.

Lagrings-I/O för en värd
Följande diagram visar en 100% slumpmässigt vald arbetsbelastning med ett databasbuffert-träffförhållande på cirka 8%. SLOB2 kunde köra cirka 850 000 I/O-begäranden per sekund samtidigt som en undermillisecond DB-fils sekventiella svarstider för läshändelser bibehålls. Med en databasblockstorlek på 8 K som uppgår till cirka 6 800 MiB/s lagringsdataflöde.

Dataflöde med en värd
Följande diagram visar att Azure NetApp Files för bandbreddsintensiva sekventiella I/O-arbetsbelastningar, till exempel fullständiga tabellgenomsökningar eller RMAN-aktiviteter, kan leverera de fullständiga bandbreddsfunktionerna för själva den E104ids_v5 virtuella datorn.

Anmärkning
Eftersom beräkningsinstansen har den teoretiska maximala bandbredden resulterar tillägg av ytterligare samtidighet för program endast i ökad svarstid på klientsidan. Detta resulterar i att SLOB2-arbetsbelastningar överskrider måltidsramen för slutförande och därför begränsades antalet trådar till sex.
Utskalningsprestanda för SLOB2
I följande diagram avbildas prestandaprofilen för tre E104ids_v5 virtuella Azure-datorer som var och en kör en enskild Oracle 19c-databas och var och en med sin egen uppsättning Azure NetApp Files-volymer och en identisk ASM-diskgruppslayout enligt beskrivningen i avsnittet Skala upp prestanda. Grafiken visar att med Azure NetApp Files multi-volume/multi-endpoint skalas prestanda enkelt ut med konsekvens och förutsägbarhet.
Arkitektur för flera värdar
Följande diagram visar arkitekturen som testningen slutfördes mot. Observera de tre Oracle-databaserna som är spridda över flera Azure NetApp Files-volymer och slutpunkter. Slutpunkter kan dedikeras till en enda värd som visas med Oracle VM 1 eller delas mellan värdar som visas med Oracle VM2 och Oracle VM 3.

Lagrings-I/O för flera värdar
Följande diagram visar en 100% slumpmässigt vald arbetsbelastning med ett databasbuffert-träffförhållande på cirka 8%. SLOB2 kunde köra cirka 850 000 I/O-begäranden per sekund för alla tre värdarna individuellt. SLOB2 kunde åstadkomma detta samtidigt som den kördes parallellt med totalt cirka 2 500 000 I/O-begäranden per sekund, där varje värd fortfarande upprätthåller en undermillisecond db-fil sekventiell läshändelsesvarstid. Med en databasblockstorlek på 8K uppgår detta till cirka 20 000 MiB/s mellan de tre värdarna.

Dataflöde för flera värdar
Följande diagram visar att Azure NetApp Files för sekventiella arbetsbelastningar fortfarande kan leverera de fullständiga bandbreddsfunktionerna för den E104ids_v5 virtuella datorn även när den skalas utåt. SLOB2 kunde köra I/O på totalt över 30 000 MiB/s över de tre värdarna när de kördes parallellt.

Verkliga prestanda
Efter att skalningsgränser har testats med SLOB2 utfördes tester med en programsvit för leveranskedjan med verkliga ord mot Oracle på Azure NetApp-filer med utmärkta resultat. Följande data från AWR-rapporten (Oracle Automatic Workload Repository) är en markerad titt på hur ett specifikt kritiskt jobb utfördes.
Den här databasen har betydande extra I/O på gång utöver programarbetsbelastningen på grund av att flashback har aktiverats och har en databasblockstorlek på 16k. Från I/O-profilavsnittet i AWR-rapporten är det uppenbart att det finns ett stort förhållande mellan skrivningar i jämförelse med läsningar.
| - | Läsa och skriva per sekund | Läsa per sekund | Skriv per sekund |
|---|---|---|---|
| Totalt (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Trots att den sekventiella läsväntehändelsen för db-filen visar en högre svarstid på 2,2 ms än i SLOB2-testningen såg kunden en minskning av jobbkörningstiden på femton minuter från en RAC-databas på Exadata till en enkel instansdatabas i Azure.
Begränsningar för Azure-resurser
Alla system når så småningom resursbegränsningar, som traditionellt kallas chokepoints. Databasarbetsbelastningar, särskilt mycket krävande sådana som programpaket för leveranskedjan, är resursintensiva entiteter. Att hitta dessa resursbegränsningar och arbeta med dem är viktigt för en lyckad distribution. Det här avsnittet belyser olika begränsningar som du kan förvänta dig att stöta på i just en sådan miljö och hur du arbetar igenom dem. I varje underavsnitt förväntar du dig att lära dig både metodtips och logik bakom dem.
Virtuella datorer
Det här avsnittet beskriver de kriterier som ska beaktas vid val av virtuella datorer för bästa prestanda och motiveringen bakom val som gjorts för testning. Azure NetApp Files är en NAS-tjänst (Network Attached Storage), och därför är lämplig storleksändring av nätverksbandbredd avgörande för optimala prestanda.
Kretsuppsättningar
Det första ämnet av intresse är val av chipset. Se till att den virtuella dator-SKU som du väljer bygger på en enskild kretsuppsättning av konsekvensskäl. Intel-varianten av E_v5 virtuella datorer körs på en tredje generationens Konfiguration av Intel Xeon Platinum 8370C (Ice Lake). Alla virtuella datorer i den här familjen är utrustade med ett enda nätverksgränssnitt på 100 Gbit/s. Däremot bygger E_v3-serien, som nämns som exempel, på fyra separata kretsuppsättningar, med olika fysiska nätverksbandbredder. De fyra kretsuppsättningar som används i E_v3-familjen (Broadwell, Skylake, Cascade Lake, Haswell) har olika processorhastigheter, vilket påverkar datorns prestandaegenskaper.
Läs dokumentationen om Azure Compute noggrant med fokus på kretsuppsättningsalternativ. Se även metodtips för Azure VM-SKU:er för Azure NetApp Files. Att välja en virtuell dator med en enskild kretsuppsättning är att föredra för bästa konsekvens.
Tillgänglig nätverksbandbredd
Det är viktigt att förstå skillnaden mellan den tillgängliga bandbredden för det virtuella datornätverksgränssnittet och den uppmätta bandbredden som tillämpas mot samma. När Azure Compute-dokumentationen talar om nätverksbandbreddsgränser tillämpas dessa gränser endast på utgående (skrivning). Inkommande trafik (lästrafik) mäts inte och begränsas därför endast av den fysiska bandbredden för själva nätverkskortet (NIC). Nätverksbandbredden för de flesta virtuella datorer överskrider den utgående gränsen som tillämpas på datorn.
Eftersom Azure NetApp Files-volymer är nätverksanslutna kan utgående gräns tolkas som att den tillämpas mot skrivningar specifikt medan ingress definieras som läsningar och läsliknande arbetsbelastningar. Utgående gränsen för de flesta datorer är större än nätverksbandbredden för nätverkskortet, men detsamma kan inte sägas om E104_v5 som används vid testning för den här artikeln. E104_v5 har ett nätverkskort på 100 Gbit/s med utgående gräns på 100 Gbit/s också. Som jämförelse har E96_v5, med sitt nätverkskort på 100 Gbit/s, en utgående gräns på 35 Gbit/s med ingress som är ohämmad på 100 Gbit/s. När de virtuella datorerna minskar i storlek minskar utgående gränser, men ingressen förblir ohämmad av logiskt införda gränser.
Utgående gränser är VM-omfattande och tillämpas som sådana mot alla nätverksbaserade arbetsbelastningar. När du använder Oracle Data Guard fördubblas alla skrivningar till arkivloggar och måste beaktas vid överväganden för utgående gräns. Detta gäller även för arkivlogg med flera mål och RMAN, om det används. När du väljer virtuella datorer bekantar du dig med sådana kommandoradsverktyg som ethtool, som exponerar konfigurationen av nätverkskortet eftersom Azure inte dokumenterar nätverksgränssnittskonfigurationer.
Nätverkskonkurrering
Virtuella Azure-datorer och Azure NetApp Files-volymer är utrustade med specifika mängder bandbredd. Så länge en virtuell dator har tillräckligt med processorutrymme kan en arbetsbelastning i teorin använda den bandbredd som görs tillgänglig för den, vilket ligger inom gränserna för nätverkskortet och eller utgående gräns som tillämpas. I praktiken baseras dock den mängd dataflöde som kan uppnås på samtidigheten i arbetsbelastningen i nätverket, det vill:s antal nätverksflöden och nätverksslutpunkter.
Läs avsnittet gränser för nätverksflöde i dokumentet om vm-nätverksbandbredd för att få bättre förståelse för. Takeaway: ju fler nätverksflöden som ansluter klienten för att lagra desto bättre prestanda.
Oracle stöder två separata NFS-klienter, Kernel NFS och Direct NFS (dNFS). Kernel-NFS har fram till sent stöd för ett enda nätverksflöde mellan två slutpunkter (beräkning – lagring). Direkt NFS, den mer högpresterande av de två, stöder ett variabelt antal nätverksflöden – tester har visat hundratals unika anslutningar per slutpunkt – öka eller minska som belastningskrav. På grund av skalning av nätverksflöden mellan två slutpunkter är direct NFS mycket prioriterat framför Kernel NFS, och därmed den rekommenderade konfigurationen. Azure NetApp Files-produktgruppen rekommenderar inte att du använder Kernel NFS med Oracle-arbetsbelastningar. Mer information finns i Fördelarna med att använda Azure NetApp Files med Oracle Database.
Samtidig körning
Att använda Direct NFS, en enda kretsuppsättning för konsekvens och förstå begränsningar för nätverksbandbredd, tar dig bara så långt. Till slut kör programmet prestanda. Konceptbevis med SLOB2 och konceptbevis med hjälp av en verklig programsvit för leveranskedjan mot verkliga kunddata kunde endast driva stora mängder dataflöde eftersom programmen kördes i hög grad av samtidighet. den förstnämnda använder ett stort antal trådar per schema, den senare använder flera anslutningar från flera programservrar. Kort och väl driver samtidighet arbetsbelastning, låg samtidighet – lågt dataflöde, hög samtidighet – högt dataflöde så länge infrastrukturen finns på plats för att stödja samma sak.
Snabbare nätverksanslutning
Accelererat nätverk möjliggör Single Root I/O-virtualisering (SR-IOV) till en virtuell dator, vilket avsevärt förbättrar nätverkets prestanda. Med den här högpresterande sökvägen kringgås värden från datasökvägen, vilket minskar svarstiden, jitter och processoranvändningen för de mest krävande nätverksbelastningarna på VM-typer som stöds. När du distribuerar virtuella datorer via verktyg för konfigurationshantering, till exempel terraform eller kommandorad, bör du vara medveten om att accelererat nätverk inte är aktiverat som standard. För optimala prestanda aktiverar du accelererat nätverk. Observera att accelererat nätverk är aktiverat eller inaktiverat i ett nätverksgränssnitt baserat på nätverksgränssnitt. Den accelererade nätverksfunktionen är en funktion som kan aktiveras eller inaktiveras dynamiskt.
Anmärkning
Den här artikeln innehåller referenser till termen SLAVE, en term som Microsoft inte längre använder. När termen tas bort från programvaran tar vi bort den från den här artikeln.
En auktoritativ metod för efterföljande accelererade nätverk är aktiverad för ett nätverkskort via Linux-terminalen. Om accelererat nätverk är aktiverat för ett nätverkskort finns ett andra virtuellt nätverkskort associerat med det första nätverkskortet. Det andra nätverkskortet konfigureras av systemet med SLAVE flaggan aktiverad. Om det inte finns något nätverkskort med SLAVE flaggan aktiveras inte accelererat nätverk för det gränssnittet.
I scenariot där flera nätverkskort har konfigurerats måste du avgöra vilket gränssnitt som är associerat med det nätverkskort som SLAVE används för att montera NFS-volymen. Att lägga till nätverkskort till den virtuella datorn påverkar inte prestandan.
Använd följande process för att identifiera mappningen mellan det konfigurerade nätverksgränssnittet och dess associerade virtuella gränssnitt. Den här processen verifierar att accelererat nätverk är aktiverat för ett specifikt nätverkskort på Linux-datorn och visar den fysiska ingresshastighet som nätverkskortet potentiellt kan uppnå.
-
ip aKör kommandot: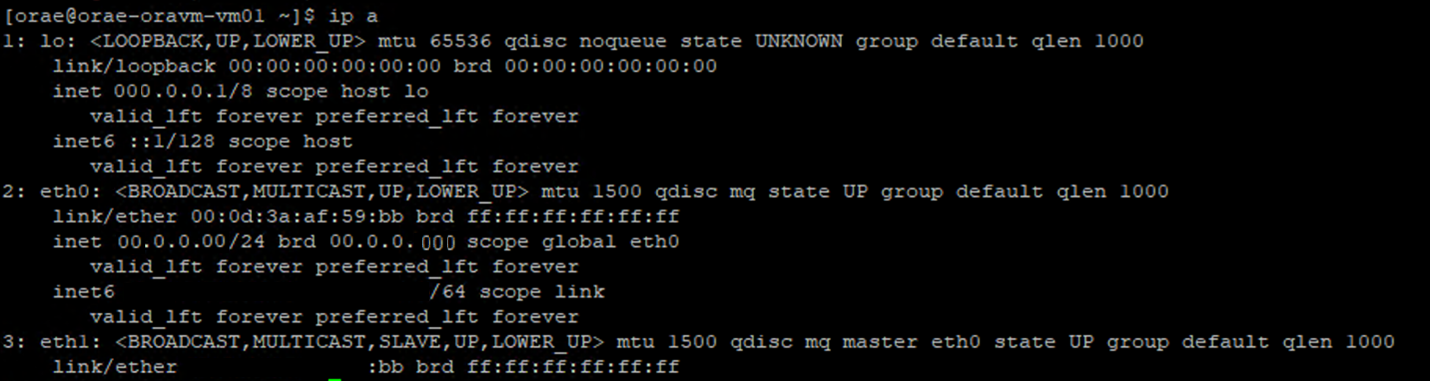
- Ange katalogen för
/sys/class/net/det nätverkskorts-ID som du verifierar (eth0i exemplet) ochgrepför ordet lägre:ls /sys/class/net/eth0 | grep lower lower_eth1 -
ethtoolKör kommandot mot ethernet-enheten som identifierades som den lägre enheten i föregående steg.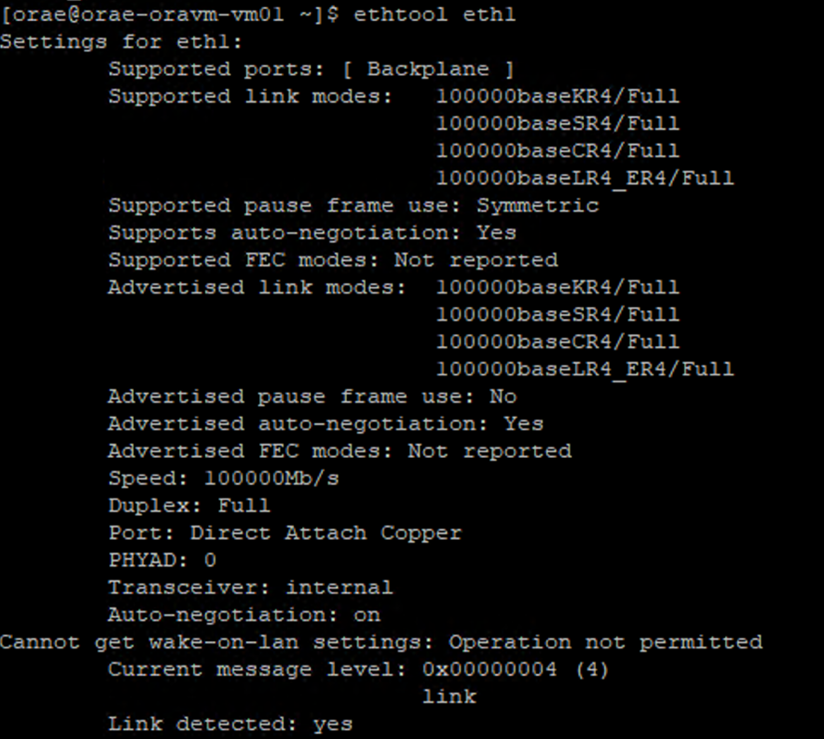
Virtuell Azure-dator: Gränser för nätverks- och diskbandbredd
En expertnivå krävs när du läser dokumentationen om prestandabegränsningar för virtuella Azure-datorer. Var medveten om:
- Temporärt lagringsdataflöde och IOPS-nummer refererar till prestandafunktionerna i den tillfälliga on-box-lagring som är direkt kopplad till den virtuella datorn.
- Oanvänd diskdataflöde och I/O-nummer refererar specifikt till Azure Disk (Premium, Premium v2 och Ultra) och har ingen betydelse för nätverksansluten lagring, till exempel Azure NetApp Files.
- Att ansluta ytterligare nätverkskort till den virtuella datorn har ingen inverkan på prestandabegränsningar eller prestandafunktioner för den virtuella datorn (dokumenteras och testas för att vara sant).
- Maximal nätverksbandbredd avser utgående gränser (dvs. skrivningar när Azure NetApp Files ingår) som tillämpas mot den virtuella datorns nätverksbandbredd. Inga ingressgränser (dvs. läsningar när Azure NetApp Files ingår) tillämpas. Med tanke på tillräckligt med PROCESSOR, tillräckligt med nätverkskonkurritet och tillräckligt många slutpunkter kan en virtuell dator teoretiskt sett driva inkommande trafik till gränserna för nätverkskortet. Som du nämnde i avsnittet Tillgänglig nätverksbandbredd använder du verktyg som för
ethtoolatt se bandbredden för nätverkskortet.
Ett exempeldiagram visas som referens:
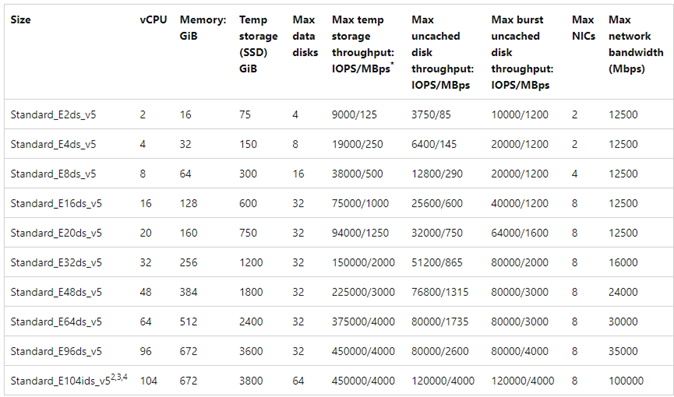
Azure NetApp Files
Azures förstapartslagringstjänst Azure NetApp Files tillhandahåller en fullständigt hanterad lagringslösning med hög tillgänglighet som kan stödja de krävande Oracle-arbetsbelastningar som introducerades tidigare.
Eftersom gränserna för lagringsprestanda för uppskalning i en Oracle-databas är väl förstådda fokuserar den här artikeln avsiktligt på skalbara lagringsprestanda. Att skala ut lagringsprestanda innebär att ge en enda Oracle-instans åtkomst till många Azure NetApp Files-volymer där dessa volymer distribueras över flera lagringsslutpunkter.
Genom att skala en databasarbetsbelastning över flera volymer på ett sådant sätt tas databasens prestanda bort från både volym- och slutpunktens övre gränser. Eftersom lagringen inte längre medför prestandabegränsningar blir vm-arkitekturen (CPU, nätverkskort och utgående gränser för virtuella datorer) den chokepoint som ska hanteras. Enligt vad som anges i avsnittet vm gjordes val av E104ids_v5- och E96ds_v5-instanser med detta i åtanke.
Oavsett om en databas placeras på en enda stor kapacitetsvolym eller sprids över flera mindre volymer är den totala ekonomiska kostnaden densamma. Fördelen med att distribuera I/O över flera volymer och slutpunkter i motsats till en enskild volym och slutpunkt är att undvika bandbreddsgränser – du får använda helt det du betalar för.
Viktigt!
Om du vill distribuera med Azure NetApp Files i en multiple volume:multiple endpoint konfiguration kontaktar du Azure NetApp Files Specialist eller Cloud Solution Architect för att få hjälp.
Databas
Oracles databasversion 19c är Oracles nuvarande långsiktiga version och den som används för att producera alla testresultat som beskrivs i det här dokumentet.
För bästa prestanda monterades alla databasvolymer med hjälp av Direct NFS, Kernel NFS rekommenderas mot på grund av prestandabegränsningar. En prestandajämförelse mellan de två klienterna finns i Oracle-databasprestanda på enskilda Azure NetApp Files-volymer. Observera att alla relevanta dNFS-korrigeringar (Oracles support-ID 1495104) tillämpades, liksom de metodtips som beskrevs i oracledatabaserna i Microsoft Azure med hjälp av Azure NetApp Files-rapporten .
Oracle och Azure NetApp Files stöder både NFSv3 och NFSv4.1, men eftersom NFSv3 är det mer mogna protokollet anses det vanligtvis ha mest stabilitet och är det mer tillförlitliga alternativet för miljöer som är mycket känsliga för störningar. Testningen som beskrivs i den här artikeln slutfördes över NFSv3.
Viktigt!
Några av de rekommenderade korrigeringar som Oracle-dokument i support-ID 1495104 är viktiga för att upprätthålla dataintegriteten när du använder dNFS. Tillämpning av sådana korrigeringar rekommenderas starkt för produktionsmiljöer.
Automatisk lagringshantering (ASM) stöds för NFS-volymer. Även om asm vanligtvis är associerat med blockbaserad lagring där ASM ersätter LVM (Logisk volymhantering) och filsystemet båda, spelar ASM en värdefull roll i NFS-scenarier med flera volymer och är värt att tänka på. En sådan fördel med ASM, dynamisk onlinetillägg av och ombalansering över nyligen tillagda NFS-volymer och slutpunkter, förenklar hanteringen så att både prestanda och kapacitet kan utökas efter behov. Även om ASM inte i sig ökar prestandan för en databas, undviker dess användning heta filer och behovet av att manuellt underhålla fildistribution – en fördel som är lätt att se.
En ASM över dNFS-konfiguration användes för att skapa alla testresultat som beskrivs i den här artikeln. Följande diagram illustrerar ASM-fillayouten i Azure NetApp Files-volymerna och filallokeringen till ASM-diskgrupperna.

Det finns vissa begränsningar med användning av ASM över Azure NetApp Files NFS-monterade volymer när det gäller ögonblicksbilder av lagring som kan övervinnas med vissa arkitektoniska överväganden. Kontakta din Azure NetApp Files-specialist eller molnlösningsarkitekt för en djupgående genomgång av dessa överväganden.
Syntetiska testverktyg och tonfisk
I det här avsnittet beskrivs testarkitektur, tunables och konfigurationsinformation i detalj. Även om det föregående avsnittet är fokuserat på varför konfigurationsbeslut fattas, fokuserar det här avsnittet specifikt på "vad" i konfigurationsbeslut.
Automatiserad distribution
- De virtuella databasdatorerna distribueras med hjälp av bash-skript som är tillgängliga på GitHub.
- Layouten och allokeringen av flera Azure NetApp Files-volymer och slutpunkter slutförs manuellt. Du måste arbeta med Azure NetApp Files Specialist eller Cloud Solution Architect för att få hjälp.
- Rutnätsinstallationen, ASM-konfigurationen, skapande och konfiguration av databaser och SLOB2-miljön på varje dator konfigureras med Ansible för konsekvens.
- Parallella SLOB2-testkörningar över flera värdar slutförs också med Ansible för konsekvens och samtidig körning.
Konfiguration av virtuell dator
| Konfiguration | Värde |
|---|---|
| Azure-regionen | Västeuropa |
| VM varunummer | E104ids_v5 |
| Antal nätverkskort | 1 OBS! Att lägga till virtuella nätverkskort har ingen effekt på antalet system |
| Maximal bandbredd för utgående nätverk (Mbit/s) | 100 000 |
| Temporär lagring (SSD) GiB | 3,800 |
Systemkonfiguration
Alla Oracle-nödvändiga systemkonfigurationsinställningar för version 19c implementerades enligt Oracle-dokumentationen.
Följande parametrar har lagts till i /etc/sysctl.conf Linux-systemfilen:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Alla Azure NetApp Files-volymer monterades med följande NFS-monteringsalternativ.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Databasparametrar
| Parameterar | Värde |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25g |
shared_io_pool_size |
500 m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
SLOB2-konfiguration
All arbetsbelastningsgenerering för testning slutfördes med SLOB2-verktyget version 2.5.4.
Fjorton SLOB2-scheman lästes in i ett Oracle-standardtabellområde och kördes mot, vilket i kombination med de slobkonfigurationsfilinställningar som anges placerar SLOB2-datauppsättningen på 7 TiB. Följande inställningar återspeglar en slumpmässig läskörning för SLOB2. Konfigurationsparametern SCAN_PCT=0 ändrades till SCAN_PCT=100 under sekventiell testning.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
För slumpmässig lästestning utfördes nio SLOB2-körningar. Trådantalet ökades med sex med varje test iteration från en.
För sekventiell testning utfördes sju SLOB2-körningar. Trådantalet ökades med två med varje test iteration från en. Trådantalet begränsades till sex på grund av att nätverksbandbreddens maxgränser nåddes.
AWR-mått
Alla prestandamått rapporterades via Oracle Automatic Workload Repository (AWR). Följande är de mått som visas i resultaten:
- Dataflöde: summan av det genomsnittliga dataflödet för läsning och skrivning från avsnittet AWR-belastningsprofil
- Genomsnittlig läsning av I/O-begäranden från avsnittet AWR-belastningsprofil
- db-fil sekventiell läsväntehändelse genomsnittlig väntetid från avsnittet AWR Foreground Wait Events
Migrera från specialbyggda, konstruerade system till molnet
Oracle Exadata är ett konstruerat system – en kombination av maskinvara och programvara som anses vara den mest optimerade lösningen för att köra Oracle-arbetsbelastningar. Även om molnet har betydande fördelar i det övergripande systemet i den tekniska världen, kan dessa specialiserade system se otroligt attraktiva ut för dem som har läst och sett de optimeringar Oracle har byggt kring sina specifika arbetsbelastningar.
När det gäller att köra Oracle på Exadata finns det några vanliga orsaker till att Exadata väljs:
- 1–2 höga I/O-arbetsbelastningar som är naturliga för Exadata-funktioner och eftersom dessa arbetsbelastningar kräver betydande Exadata-konstruerade funktioner konsoliderades resten av databaserna som körs tillsammans med dem till Exadata.
- Komplicerade eller svåra OLTP-arbetsbelastningar som kräver RAC för skalning och är svåra att skapa med egen maskinvara utan djup kunskap om Oracle-optimering eller kan vara tekniska skulder som inte kan optimeras.
- Underutnyttjade befintliga Exadata med olika arbetsbelastningar: detta finns antingen på grund av tidigare migreringar, livets slut på en tidigare Exadata eller på grund av en önskan att arbeta/testa en Exadata internt.
Det är viktigt att alla migreringar från ett Exadata-system förstås utifrån arbetsbelastningarnas perspektiv och hur enkel eller komplex migreringen kan vara. Ett sekundärt behov är att förstå orsaken till Exadata-köpet ur ett statusperspektiv. Exadata- och RAC-kunskaper är i högre efterfrågan och kan ha drivit rekommendationen att köpa en av de tekniska intressenterna.
Viktigt!
Oavsett scenario bör den övergripande take-away vara, för alla databasarbetsbelastningar som kommer från en Exadata, ju fler Exadata-proprietära funktioner som används, desto mer komplex är migreringen och planeringen. Miljöer som inte använder exadataprietära funktioner i hög grad har möjligheter till en enklare migrerings- och planeringsprocess.
Det finns flera verktyg som kan användas för att utvärdera dessa arbetsbelastningsmöjligheter:
- Lagringsplatsen för automatisk arbetsbelastning (AWR):
- Alla Exadata-databaser är licensierade för att använda AWR-rapporter och anslutna prestanda- och diagnostikfunktioner.
- Är alltid på och samlar in data som kan användas för att visa historisk arbetsbelastningsinformation och utvärdera användning. Högsta värden kan utvärdera den höga användningen i systemet,
- AWR-rapporter i större fönster kan utvärdera den övergripande arbetsbelastningen, vilket ger värdefull insikt i funktionsanvändning och hur du migrerar arbetsbelastningen till icke-Exadata effektivt. AWR-topprapporter är däremot bäst för prestandaoptimering och felsökning.
- AWR-rapporten Global (RAC-Aware) för Exadata innehåller också ett exadataspecifikt avsnitt som ökar detaljnivån för specifik användning av Exadata-funktioner och ger värdefull information om flash-cache, flashloggning, I/O och annan funktionsanvändning per databas och cellnod.
Avkoppling från Exadata
När du identifierar Oracle Exadata-arbetsbelastningar för migrering till molnet bör du tänka på följande frågor och datapunkter:
- Förbrukar arbetsbelastningen flera Exadata-funktioner utanför maskinvarufördelarna?
- Smarta genomsökningar
- Lagringsindex
- Flash-cache
- Flash-loggning
- Komprimering av hybridkolumner
- Avlastar arbetsbelastningen Exadata effektivt? Vad är förhållandet (mer än 10% db-tid) för arbetsbelastningen med hjälp av i förgrundshändelser för topptid:
- Cellens smarta tabellgenomsökning (optimal)
- Cell multiblock fysisk läsning (mindre optimal)
- Cellens fysiska läsning med ett enda block (minst optimal)
- Hybrid Columnar Compression (HCC/EHCC): Vad är de komprimerade kontra okomprimerade förhållandena:
- Spenderar databasen över 10% databastid på att komprimera och dekomprimera data?
- Granska prestandavinster för predikat med hjälp av komprimering i frågor: är det värde som erhållits värt det jämfört med mängden som sparats med komprimering?
- Cellens fysiska I/O: Inspektera besparingarna från:
- mängden som riktas till DB-noden för att balansera CPU.
- identifiera antalet byte som returneras av smart genomsökning. Dessa värden kan subtraheras i I/O för procentandelen fysiska läsningar av enskilda block när de migreras från Exadata.
- Observera antalet logiska läsningar från cacheminnet. Kontrollera om flash-cache krävs i en molnbaserad IaaS-lösning för arbetsbelastningen.
- Jämför den fysiska läs- och skrivsumman med den mängd som utförs totalt i cacheminnet. Kan minne höjas för att eliminera fysiska läskrav (det är vanligt att vissa krymper SGA för att tvinga avlastning för Exadata)?
- I Systemstatistik identifierar du vilka objekt som påverkas av vilken statistik. Om du justerar SQL kan ytterligare indexering, partitionering eller annan fysisk justering optimera arbetsbelastningen dramatiskt.
- Granska initieringsparametrar för understreck (_) eller inaktuella parametrar, som bör motiveras på grund av påverkan på databasnivå som kan orsaka prestanda.
Exadata-serverkonfiguration
I Oracle version 12.2 och senare inkluderas ett Exadata-specifikt tillägg i den globala AWR-rapporten. Den här rapporten innehåller avsnitt som ger ett exceptionellt värde för en migrering från Exadata.
Information om exadataversion och system
Information om aviseringar för cellnoder
Exadata icke-onlinediskar
Avvikande data för exadata-OS-statistik
Gul/rosa: Av oro. Exadata körs inte optimalt.
Röd: Prestanda för Exadata påverkas avsevärt.
Exadata OS CPU-statistik: de översta cellerna
- Den här statistiken samlas in av operativsystemet på cellerna och är inte begränsad till den här databasen eller instanserna
- En
voch en mörkgul bakgrund indikerar ett avvikande värde under det låga intervallet - En
^och en ljusgul bakgrund indikerar ett avvikande värde över det höga intervallet - De översta cellerna efter procent cpu visas och är i fallande ordning i procent cpu
- Genomsnitt: 39,34% CPU, 28,57% användare, 10,77% sys
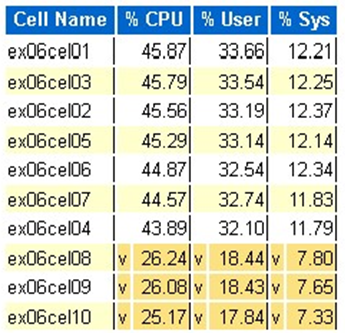
Fysiska blockläsningar för en cell
Användning av Flash-cache
Temporär I/O
Effektivitet för columnar-cache
Toppdatabas efter I/O-dataflöde
Även om storleksbedömningar kan utföras finns det några frågor om medelvärden och de simulerade topparna som är inbyggda i dessa värden för stora arbetsbelastningar. Det här avsnittet, som finns i slutet av en AWR-rapport, är exceptionellt värdefullt eftersom det visar både den genomsnittliga flash- och diskanvändningen för de 10 främsta databaserna i Exadata. Även om många kanske antar att de vill storleksanpassa databaser för högsta prestanda i molnet, är detta inte meningsfullt för de flesta distributioner (över 95% ligger i det genomsnittliga intervallet. Med en simulerad topp beräknad i är det genomsnittliga intervallet större än 98%). Det är viktigt att betala för det som behövs, även för den högsta av Oracles arbetsbelastningar för efterfrågan och att inspektera de översta databaserna efter I/O-dataflöde kan vara upplysande för att förstå resursbehoven för databasen.
Oraklet i rätt storlek med hjälp av AWR på Exadata
När du utför kapacitetsplanering för lokala system är det bara naturligt att ha betydande omkostnader inbyggda i maskinvaran. Den överetablerade maskinvaran måste hantera Oracle-arbetsbelastningen i flera år framöver, oavsett arbetsbelastningstillägg på grund av datatillväxt, kodändringar eller uppgraderingar.
En av fördelarna med molnet är att skala resurser på en virtuell datorvärd och lagring kan utföras när kraven ökar. Detta bidrar till att spara molnkostnader och licenskostnader som är kopplade till processoranvändning (relevant med Oracle).
Rätt storleksändring innebär att ta bort maskinvaran från den traditionella lift and shift-migreringen och använda arbetsbelastningsinformationen från Oracles automatiska arbetsbelastningslagringsplats (AWR) för att lyfta och flytta arbetsbelastningen till beräkning och lagring som är speciellt utformad för att stödja den i molnet som kunden väljer. Rätt storleksprocessen säkerställer att arkitekturen framöver tar bort infrastrukturens tekniska skulder, arkitekturredundans som skulle inträffa om duplicering av det lokala systemet replikerades till molnet och implementerar molntjänster när det är möjligt.
Microsoft Oracles ämnesexperter har uppskattat att mer än 80% Oracle-databaser är överetablerade och upplever antingen samma kostnad eller besparingar som går till molnet om de tar sig tid att rätt storlek på Oracle-databasarbetsbelastningen innan de migrerar till molnet. Den här utvärderingen kräver att databasspecialisterna i teamet har ändrat inställning till hur de kan ha utfört kapacitetsplanering tidigare, men det är värt intressentens investering i molnet och verksamhetens molnstrategi.
Nästa steg
- Kör dina mest krävande Oracle-arbetsbelastningar i Azure utan att offra prestanda eller skalbarhet
- Lösningsarkitekturer med Hjälp av Azure NetApp Files – Oracle
- Utforma och implementera en Oracle-databas i Azure
- Beräkningsverktyg för storleksändring av Oracle-arbetsbelastningar till virtuella Azure IaaS-datorer
- Referensarkitekturer för Oracle Database Enterprise Edition på Azure
- Förstå Azure NetApp Files-programvolymgrupper för SAP HANA